

作者介绍
陈永庭,货拉拉 技术总监。货拉拉技术中心核心基础设施部(CI)负责人,带领CI团队负责公司整体基础架构的演进,填补、维护基础技术能力(中间件、框架、工具)保障技术团队的研发效率,负责全局稳定性和技术保障、资源交付和IT成本治理优化等主要工作。曾就职饿了么、腾讯、WebEx/Cisco,主要专注于中间件和基础服务的研发、异地多活架构的设计与实施落地。(联系邮箱:sam1.chen@huolala.cn)
分享概要
一、背景介绍
二、基础架构的演进
三、技术保障的取舍
四、IT成本如何管治
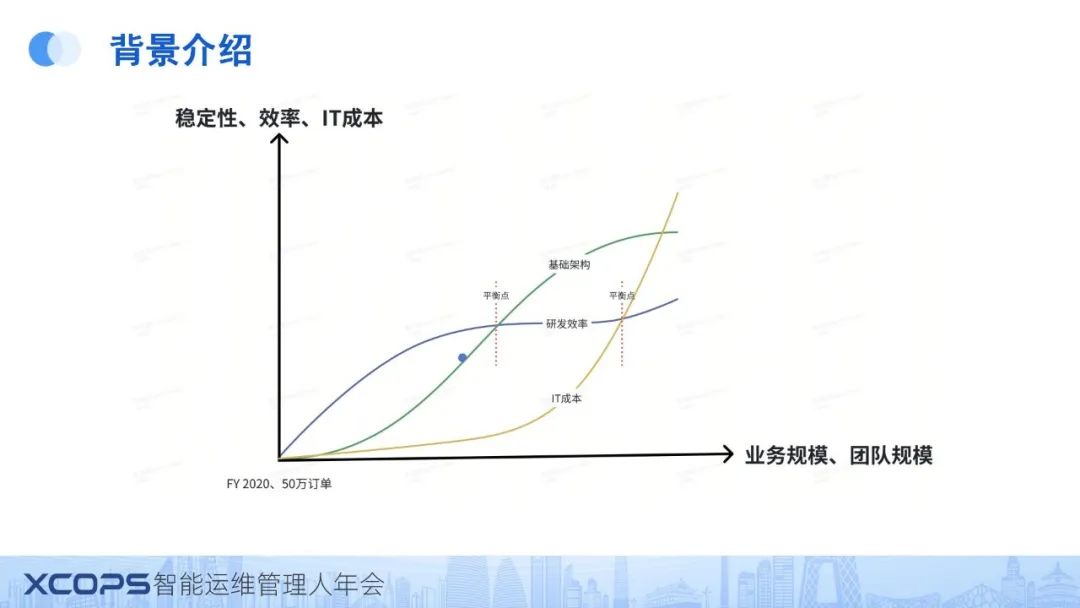
一、背景介绍
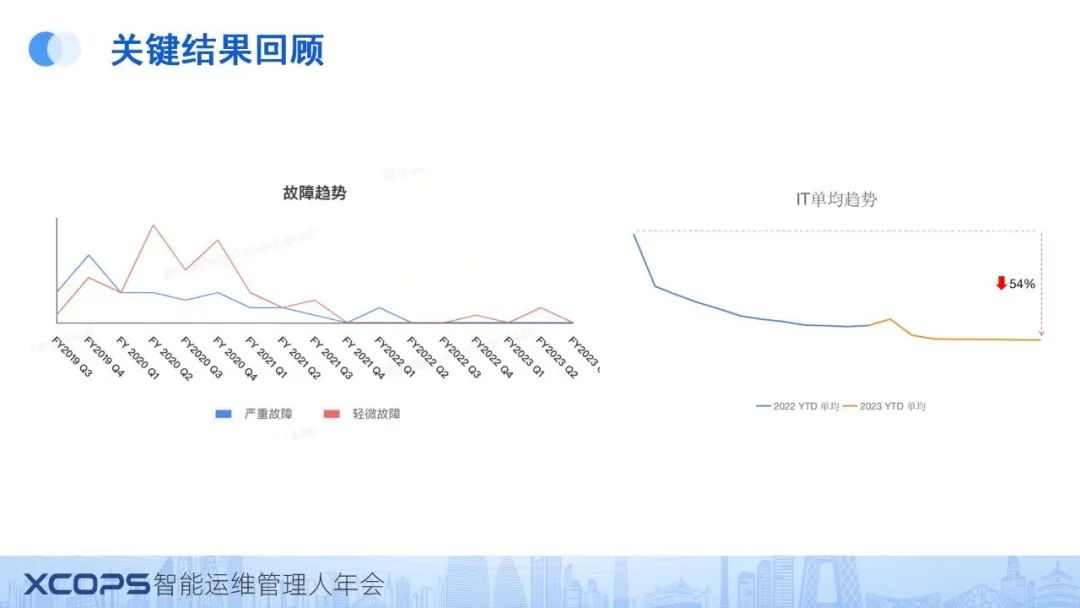
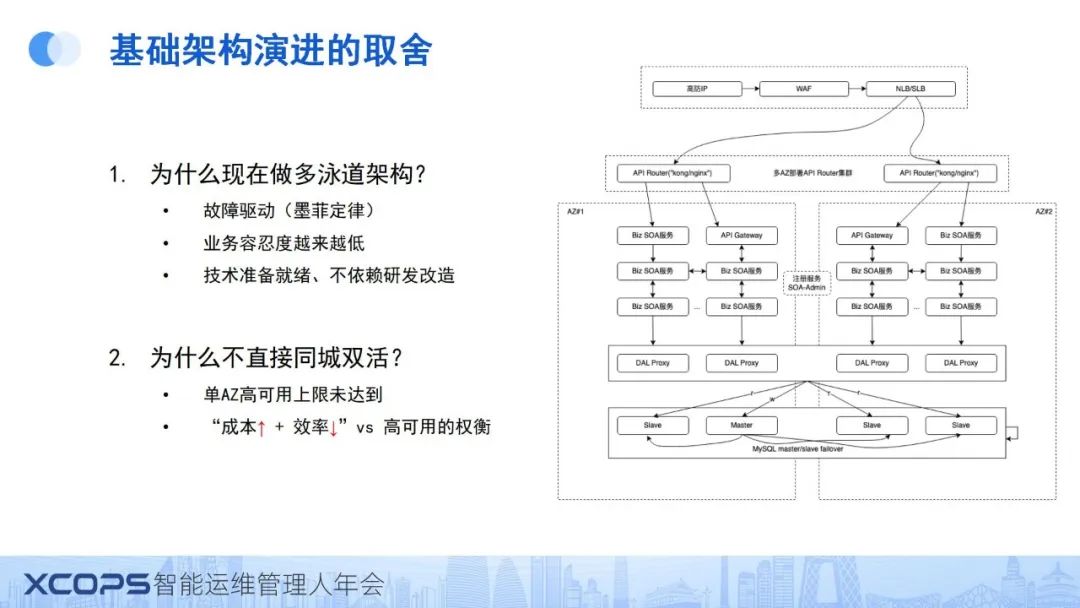
二、基础架构的演进


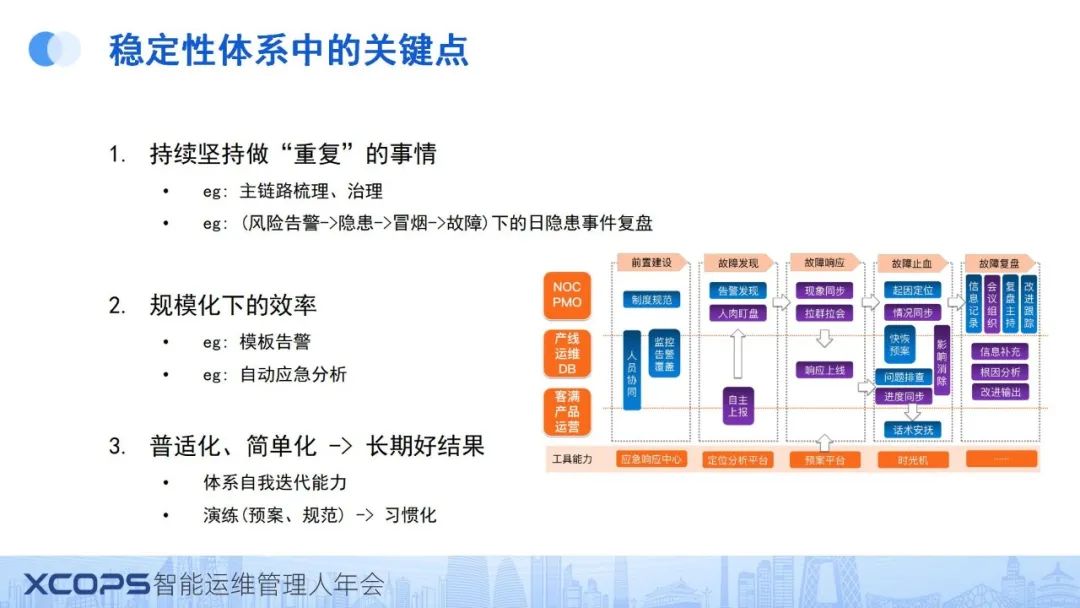
三、技术保障的取舍

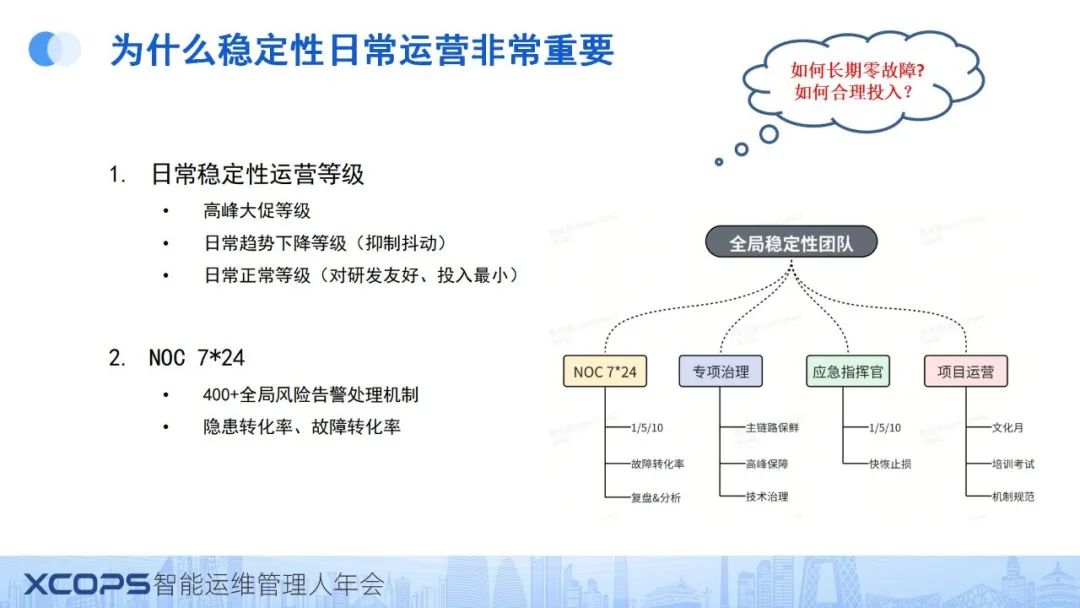
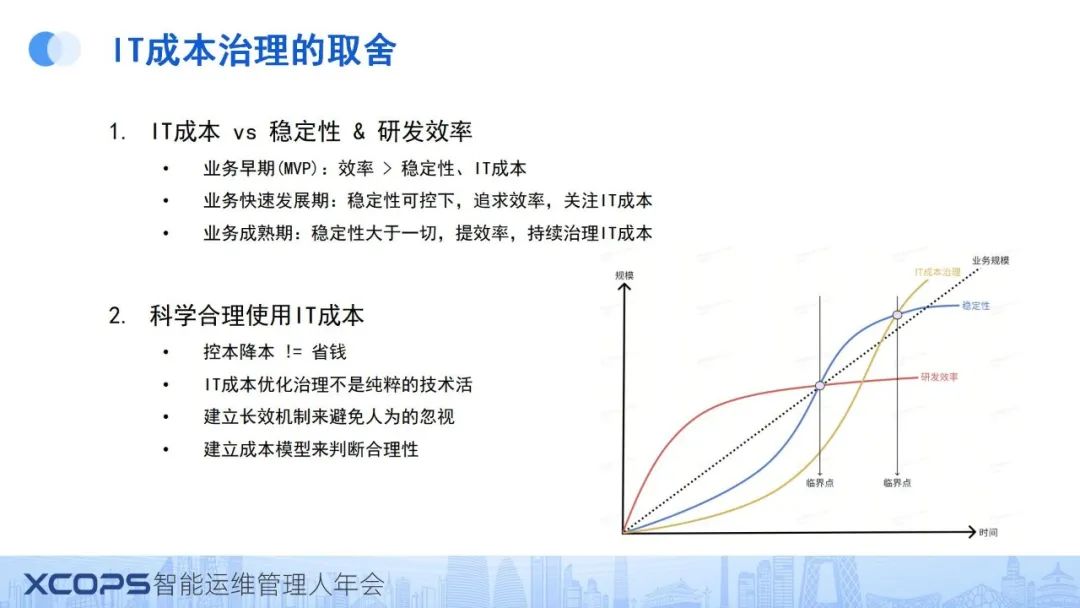
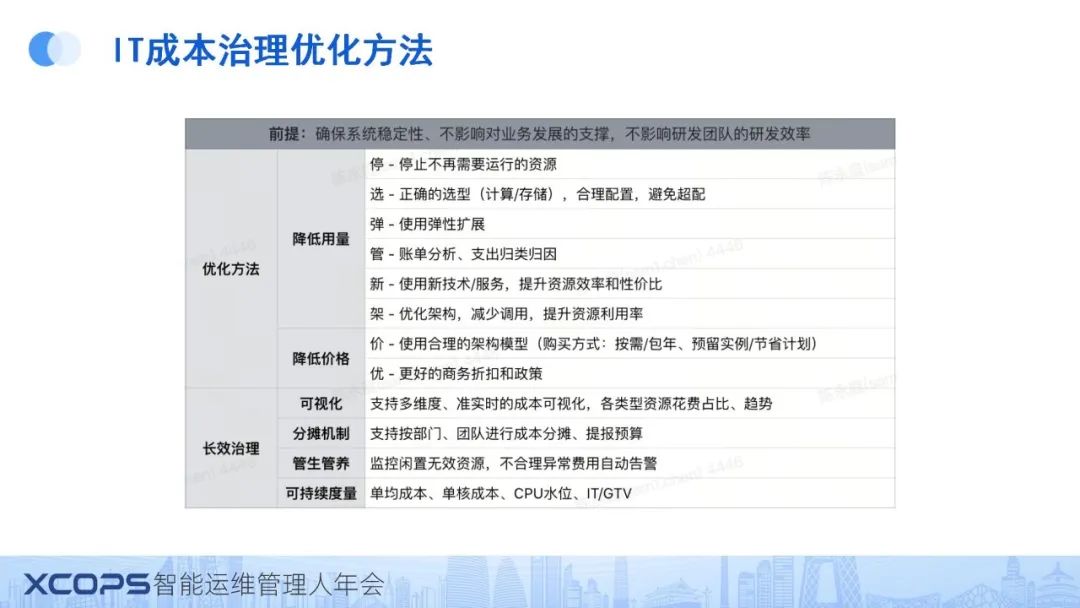
四、IT成本如何管治
点击此处链接获取本期PPT(提取码:1124)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721