作者介绍
柯圣,货拉拉 监控平台负责人。曾任职于携程、饿了么的核心中间件团队,深入参与多个自研日志平台、监控平台、时序数据库等系統的研发,深耕可观测性领域近10年。目前在货拉拉技术中心负责整体监控体系与监控平台建设。
一、多云架构下的一站式监控平台
二、服务运维与研发的监控平台
三、面向未来的监控基础能力
点击此处获取本期PPT(提取码:0628)
如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721


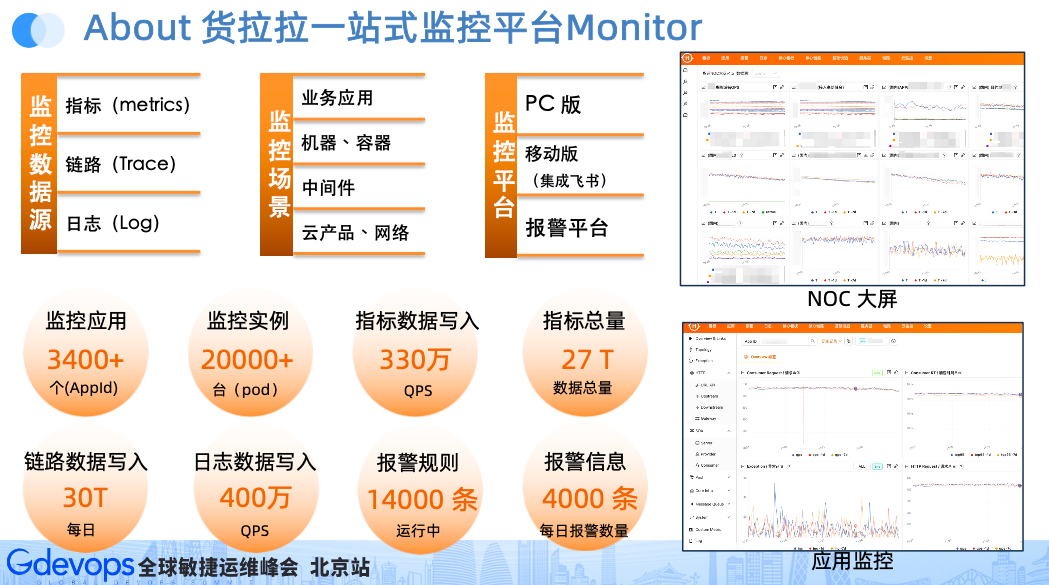
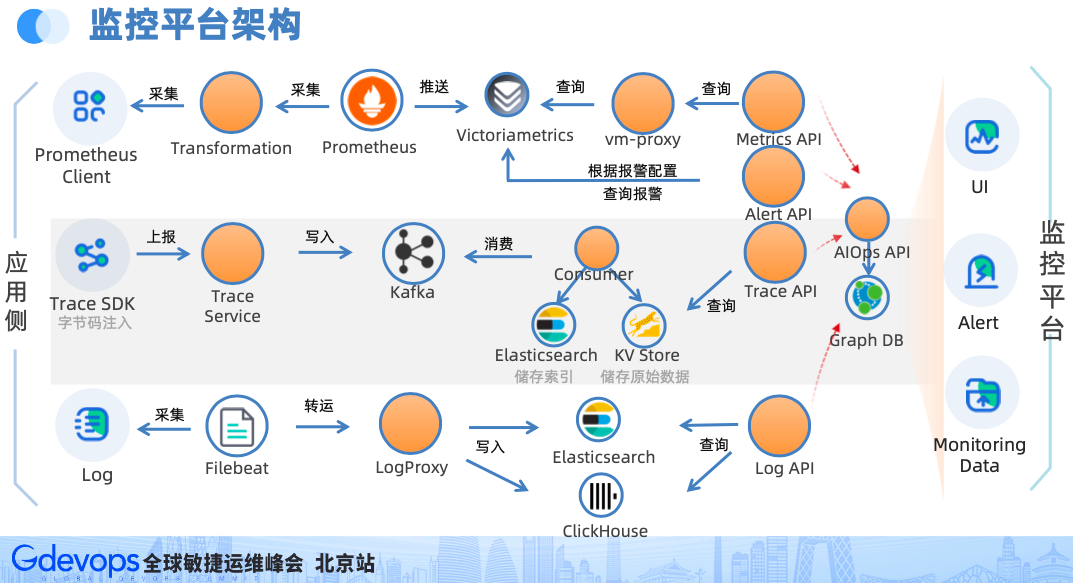
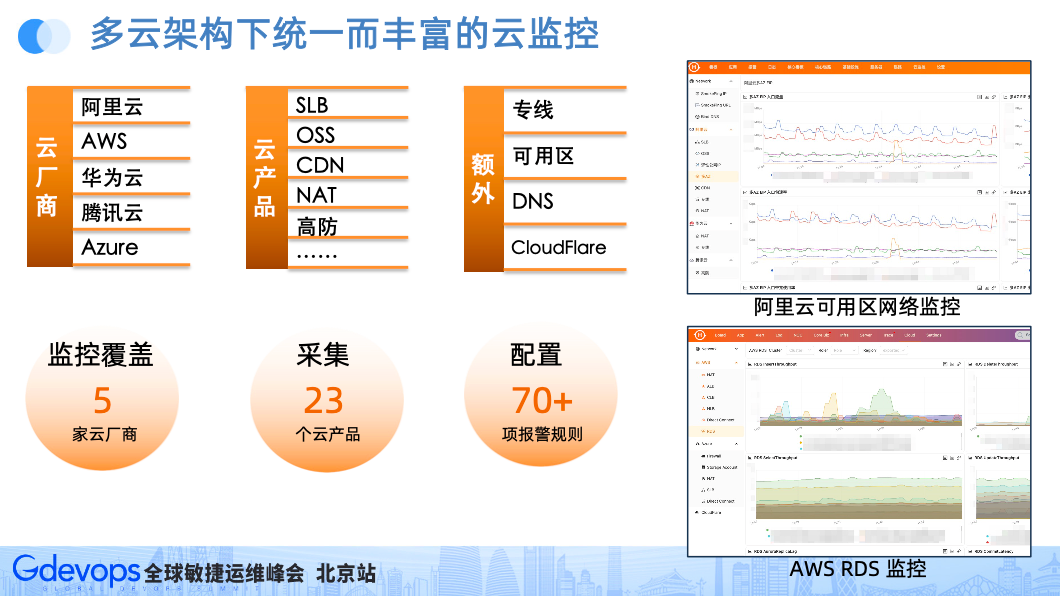


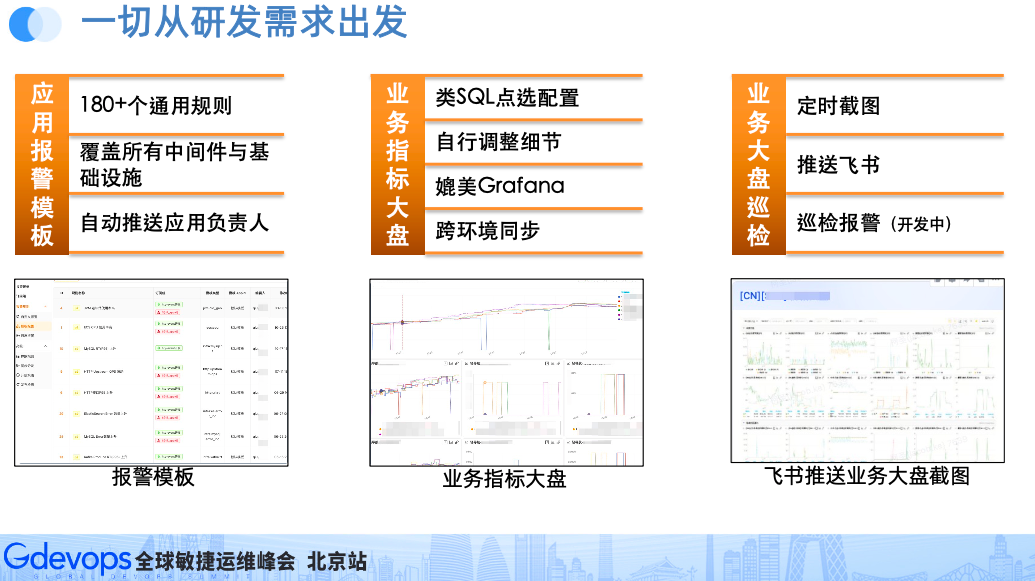
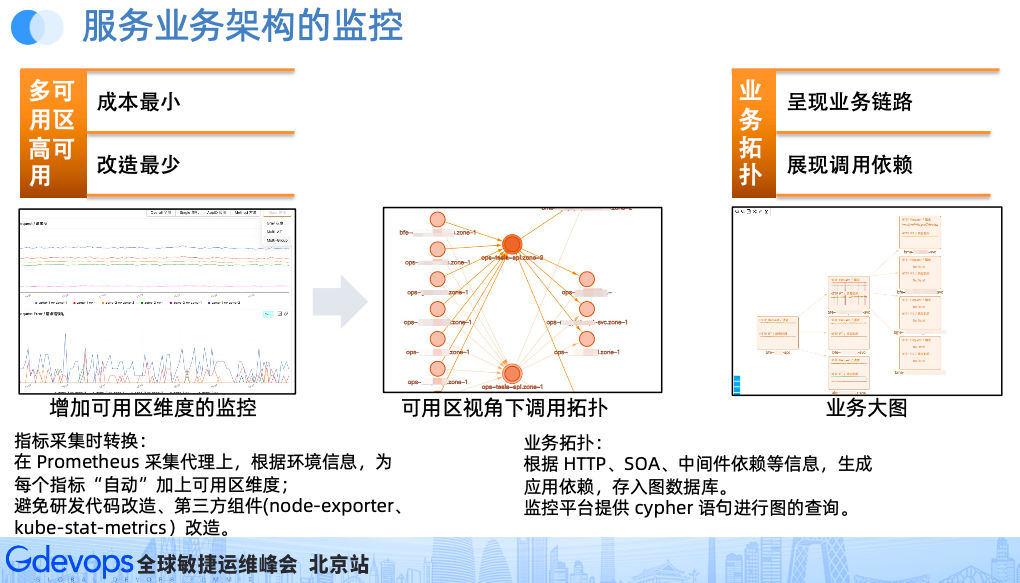
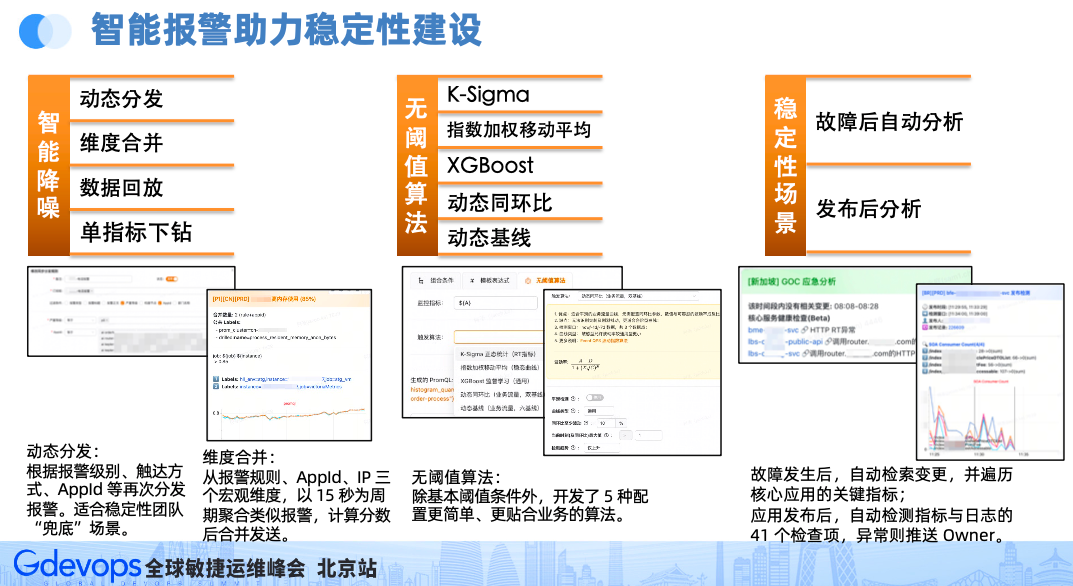
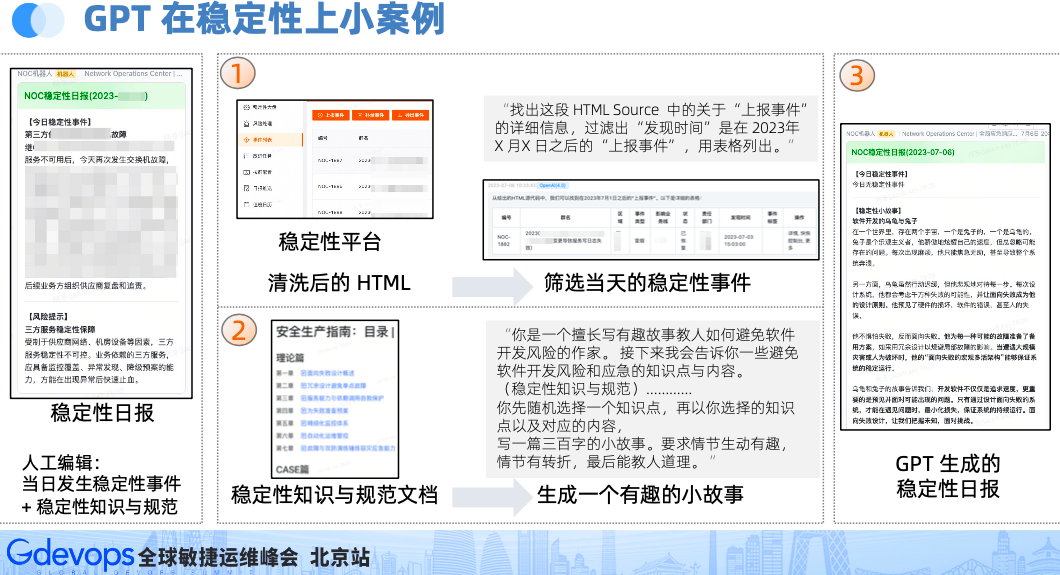










如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721