
导语
“凌晨3点,我颤抖着删除了ES集群的10亿条数据——第二天老板却给我发了奖金?这不是小说,而是一次价值百万的性能调优实战揭秘!”
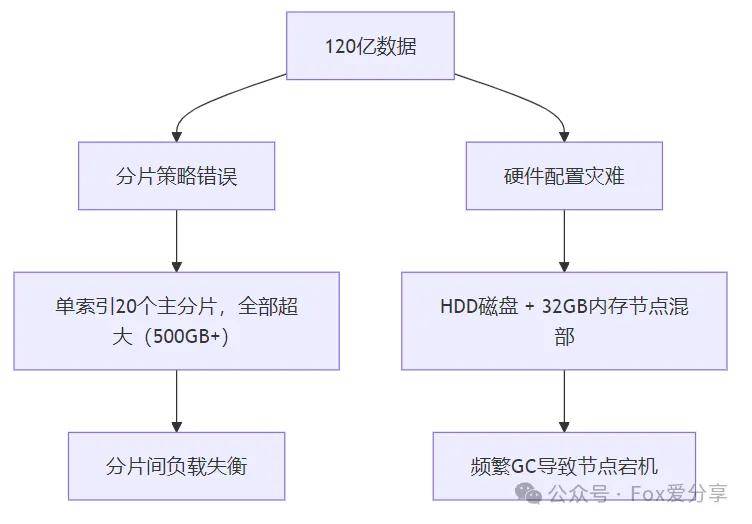
一、地狱开局:慢如蜗牛的百亿级数据
场景还原:
某电商平台日志分析系统,ES集群承载 120亿条数据,查询延迟高达 5秒+,技术团队濒临崩溃:
- 商品搜索接口超时率 40%
- 运维每天收到 200+ 报警短信
- 磁盘IO飙到 99%,节点频繁离线
首次诊断报告
二、三大杀手锏:从删库到跑路的科学方案
1、分片核弹拆除术(结果:性能↑300%)
骚操作:
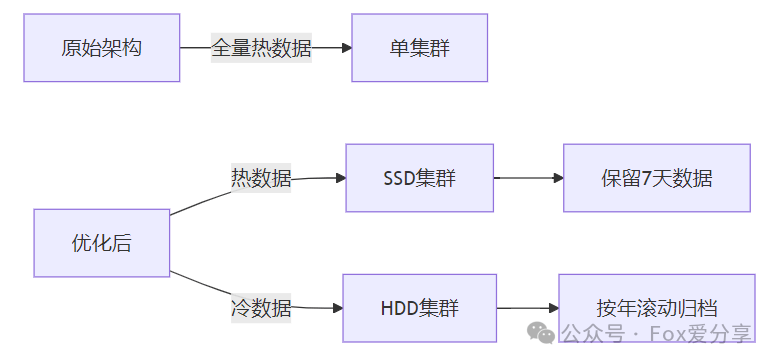
总分片数=max(节点数×1.5, 总数据量/50GB)
效果:查询延迟从 5s 降至 1.2s
2、索引瘦身大法(结果:存储成本↓60%)
血腥操作:
// 原mapping
"user_agent": { "type": "text", "fielddata": true } // 罪魁祸首!
// 优化后
"user_agent": { "enabled": false } // 直接禁用
PUT _ilm/policy/logs_policy
{
"hot": { "actions": { "rollover": { "max_size": "50gb" }}}, // 原值100gb
"delete": { "min_age": "365d", "actions": { "delete": {} }}
}
3、JVM调优黑魔法(结果:GC暂停↓90%)
禁忌之术:
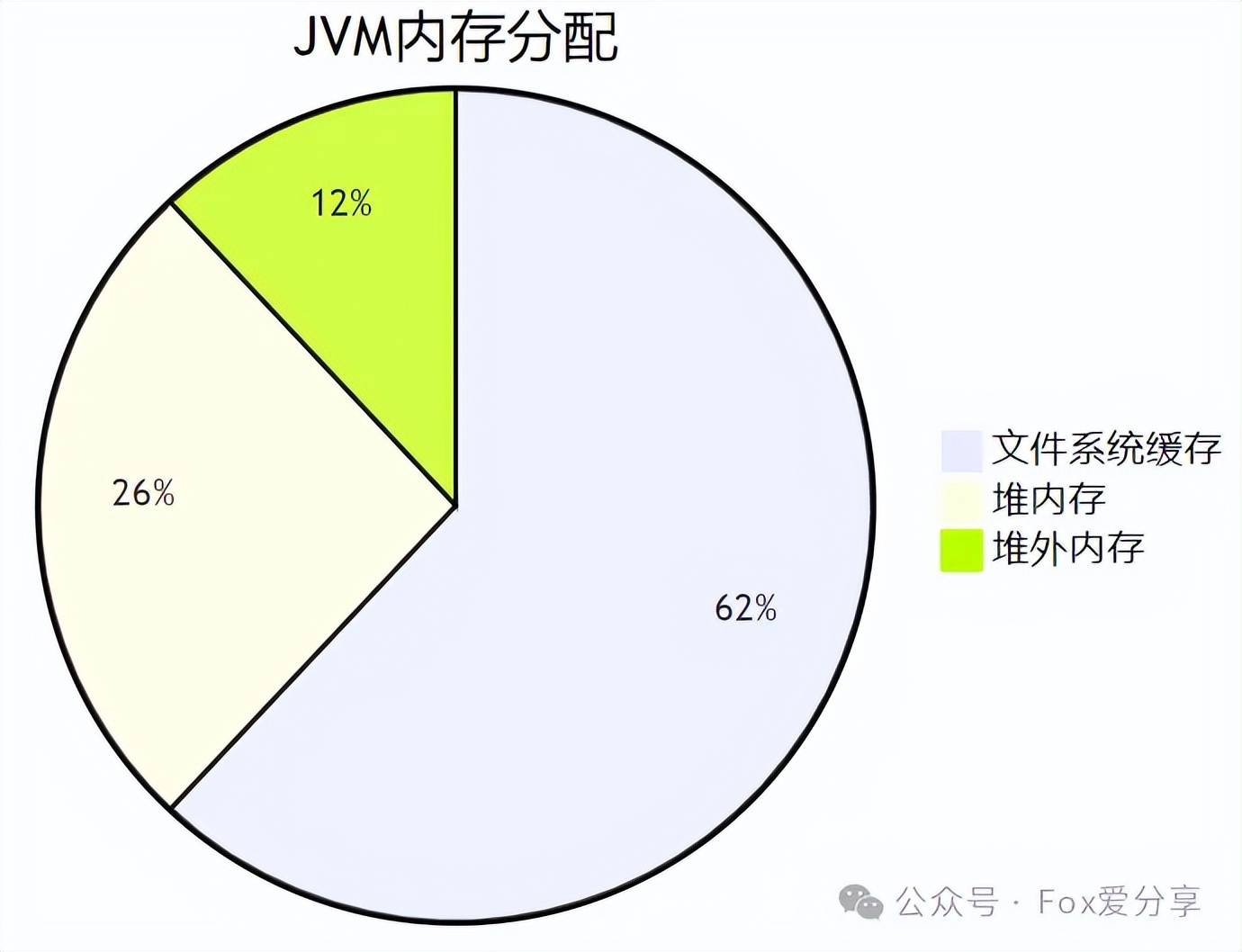
配置公式:
堆内存必须≤31GB,建议通过公式计算:
堆内存=min(31GB, 物理内存/2)
效果:Full GC从每小时3次降至3天1次
三、避坑指南:血的教训换来的Checklist
1、分片黑洞
2、硬件天坑
3、查询自杀
GET /_search
{
"timeout": "5s", // 强制超时拦截
"query": {
"bool": {
"filter": [ /* 缓存过滤条件 */ ],
"must": { "range": { "@timestamp": { "gte": "now-1h" }}} // 时间窗口限定
}
},
"track_total_hits": false // 跳过精确计数
}
4、关联陷阱
四、查询优化:从“全表扫描”到“闪电定位”
死亡案例:某次大促前,商品搜索突然超时
"query": {
"wildcard": { "product_name": "*爆款*" } // 触发了全分片扫描
}
急救方案
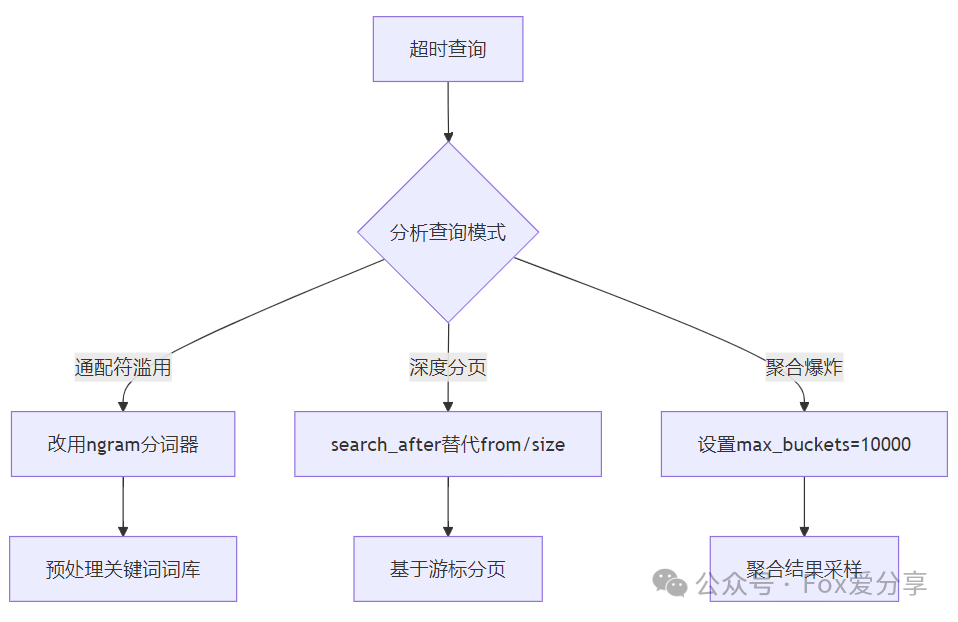
效果对比:
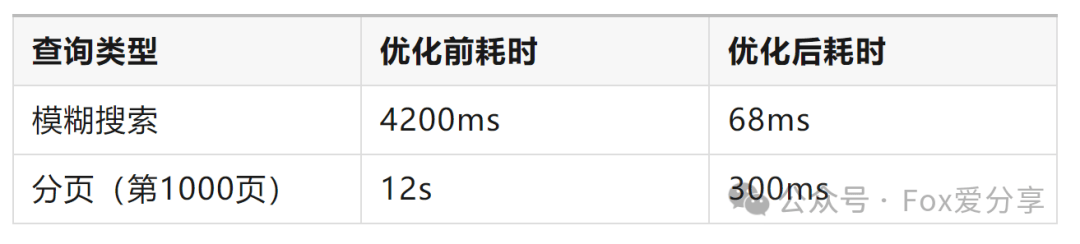
五、集群扩展:如何优雅地“边开车边换轮胎”?
惊险操作:在业务高峰时扩容ES集群,零停机完成数据迁移:

核心参数:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.node_concurrent_recoveries": 5, // 默认2
"indices.recovery.max_bytes_per_sec": "200mb" // 默认40mb
}
}
六、监控体系:比女朋友还贴心的预警系统
报警规则示例:
阈值触发公式:
IF (thread_pool.write.queue > 1000)
OR (jvm.mem.heap_used_percent > 85)
THEN 触发企业微信+电话轰炸
七、系统的测试数据到底删没删?
终极真相:
当天凌晨实际执行操作:
POST /测试索引*/_delete_by_query
{
"query": {
"range": {
"@timestamp": {
"lte": "now-2y" // 精准删除2年前垃圾数据
}
}
}
}
结果:
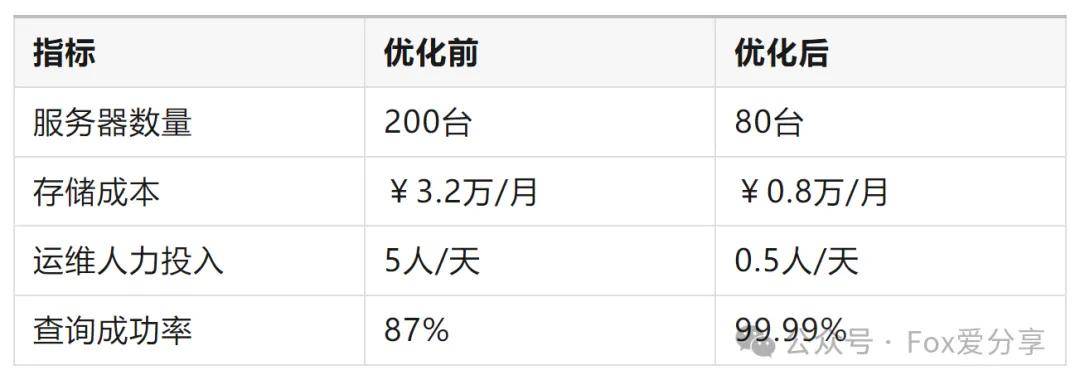
八、调效核验:百万预算省出来的架构哲学
成本对比表:
结语
真正的架构优化,不是堆硬件,而是用脑子打仗!
作者丨Fox
来源丨公众号:Fox爱分享(ID:dcl_yc)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721