
作者介绍
程君杰,曾就职于阿里巴巴移动事业部,数据技术专家。主要负责业务数据分析挖掘系统架构和设计,包括大规模数据采集、分析处理、数据挖掘、数据可视化、高性能数据服务等。
最近同事在总结关于业界各种埋点技术,在此基础上,结合之前我的一些经验和想法,讲讲数据的生产和采集。
很早之前,也就是当年的PC时代,由于受限于存储和计算能力, 大家一般很少用日志来分析业务。 而是在业务逻辑里,将业务需要分析的数据事先写入到库里, 针对库的数据进行统计分析。 所以之前做OLAP, 需要很高级的硬件支持, 大家都去IOE等买昂贵的服务器来做数据仓库以及进行数据分析。 由于成本的问题, 我们拿到的数据是很少的, 所以进行统计分析和挖掘所得到的收益微乎其微。
随着Hadoop的兴起, 分布式文件系统和分布式计算大大降低了存储成本和计算成本, 使得我们现在用日志分析业务成为了可能。
对于移动端的App来说, 分析的数据大致上都可以分为俩种, 一种是在线数据,一种是离线数据。 在线数据, 即App后端服务所产生的日志数据,例如服务接口的性能数据, 服务接口的调用及其参数等, 通过服务端的日志数据, 我们不但可以统计服务接口的性能指标,还可以针对具体的业务逻辑,做相关的分析,一些常见的App分析指标如新增,活跃,累计,留存等,也都可以通过服务日志来统计出来。
对应的离线数据即是App客户端本身产生的数据, 这种情况一般是发生在客户端不调用底层服务的情况下,需要了解用户在客户端的行为,就需要用到离线数据。 离线日志一般记录用户在客户端的具体行为,如用户在客户端的拖动,上下滚动,翻页等不涉及到后端服务的操作,以及App本身的崩溃行为产生的数据, 都可以被记录, 一般的,记录的内容包括事件类型,控件编号,控件属性及相关参数,事件时间等。

在线日志,一般来讲,有两种:
web服务器的配置化log(如Nginx, apache等web服务器的access.log)
这一类日志不需要用户自己做实现, 只需要开启web服务器的相关日志功能,即可完成日志记录。
应用服务器的log
一般包括应用服务器的配置化log 以及 用户自定义的log。 用户自定义log包括用户通过相关日志组件自己的debug, waring ,error, info等级别的日志。 这一类日志没有固定的格式,完全有用户自行控制。在线日志一般会伴随业务直接产生在相关的业务服务器上(web服务器日志产生在web服务器上),但是有的时候,为了将相关服务的监控日志与业务分析日志分离,会将业务日志直接记录在一台独立的日志服务器上。
离线日志,一般也有两种:
客户端的行为日志:用户在操作App的时候,产生的行为,都可以记录下来。 行为日志一般是用来研究用户使用习惯, 分析应用的使用热度的。 同时可以结合客户端异常日志来分析异常原因。
客户端的异常日志:用来监控客户端异常原因, 帮助解决相关问题。
不管是在线日志,还是离线日志,我们首先都要确认在什么地方记录日志, 于是我们就引入了埋点的概念。 通俗的讲,在正常业务代码逻辑上, 添加记录日志的代码, 都叫做埋点。 但是一般的,埋点只用来描述客户端日志记录。
由于在线日志是直接产生在服务器端, 日志采集工具可以直接从含有日志的服务器上采集日志数据到相应的文件系统, 所以不存在日志上传的问题。但是对于离线日志来说, 数据是产生在客户端的, 所以上传机制必须考虑。
业界采用的离线日志上传机制如下:
服务端提供日志记录接口,当客户端有事件时,直接调用日志记录接口将日志记录在服务器端。
服务端提供日志上传接口, 客户端先将日志暂存客户端本地,当达到一定的大小,网络环境允许的情况下, 通过上传接口,将日志文件打包压缩后上传。
第一种上传方式,时效性方面有一定的保障, 在网络环境允许的情况下,能及时的将信息记录到服务器,但是当埋点较多时,记录日志产生的流量会很大,占据很大的带宽,给用户带来损失。 同时, 前端的某些行为,如在某个activity停留时间等也无法通过这种在线的方式捕获。 还有一个重要的问题是, 由于客户端数据没有暂存机制, 当网络暂时无法使用时, 日志记录接口无法正常调用, 所有的日志也就随之丢失。 第二种方式,在时效性上较差,因为它需要等待数据累计到一定程度,或者网络允许的情况下,如在wifi情况下,才发送,但是占用的带宽相对较小, 对客户端动作的捕获较为灵活。
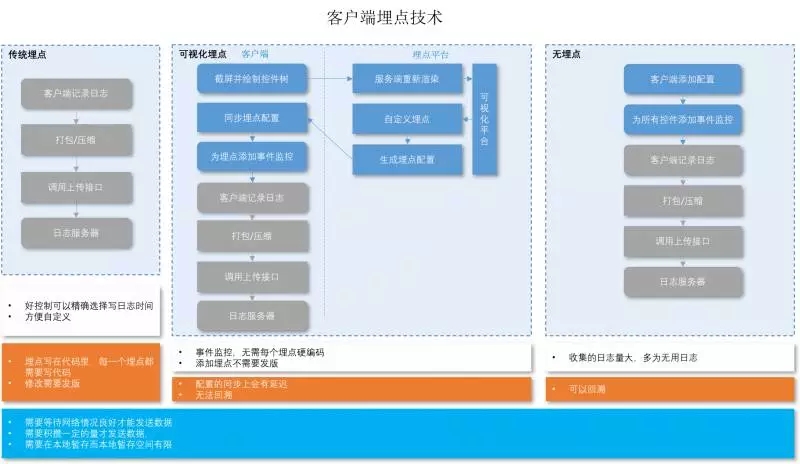
1、传统埋点:开发者直接在客户端埋点。
优点: 开发者可以随意的在任何地方添加埋点。
缺点: 成本高,每次埋点的增删改都需要发版,很难控制。启明星现在采用的就是传统的埋点方式, 由于之前没有统一的规划, 相关页面的同一个按钮,不同的版本功能不同, 但却埋了同一个点, 造成统计比较混乱。之后我们引入了埋点下发平台,虽然一定程度上缓解了这种问题,但是由于其灵活性以及主观性, 问题依然无法避免。
2、可视化埋点:由于传统埋点的一系列问题, 自然而然的就产生了可视化埋点的方案, 用可视化交互的手段来代替写代码,将核心代码和配置,资源分开, 在App启动是通过网络更新配置和资源来实现埋点功能。
可视化埋点的大体流程如下:
首先埋点服务平台与埋点客户机做关联, 包括客户机包含的埋点模块扫描当前整个客户端页面的控件,形成控件树,并将当前页面截图,发送给埋点服务端平台;
埋点服务端平台接收到截图和控件树数据后,在服务端重新绘制App界面,通过可视化交互的方式,给当前页面需要埋点的控件上添加事件,添加完毕后,形成配置文件, 并发布上线;
装有埋点模块的所有客户端,接收到配置文件并解析, 根据配置为页面中相关的控件添加监听事件, 当这些控件出发事件时记录日志。
其中有很多细节的地方需要注意:
可视化埋点也需要考虑不同版本之间埋点的差异;
可视化埋点在分发埋点配置文件的时候,会有延迟或者丢失的情况, 有的客户端有可能收不到或者很久才能收到配置文件,这样埋点的时效性会大打折扣。
3、无埋点:所谓的无埋点,其实也就是全埋点, 它和可视化埋点很像, 可视化埋点是根据埋点配置来收集数据,而无埋点方案则是尽可能的收集所有控件的操作数据。 实现原理也很简单, 客户端添加扫描代码, 为每个扫描到的控件添加监听事件。 当事件被触发后,记录日志。
其实我想,大家对此也不陌生,比如很早之前,对PC站点的统计, 各大分析平台,都需要在网页
这里强调一下, 由于可视化埋点是在需要的时候才埋点, 所以它并不能回溯事件,也就是说,我们只能统计需求提出后,埋点开始的所有的数据,埋点之前的数据我们是拿不到的。 而无埋点方案, 在开始埋点的时候,所有的数据已经都被记录了, 所以它可以查看之前的数据 (这里的之前也是相对与提统计需求的时间,而不是相对于埋点的时间), 也就是说它可以做回溯。 而这种回溯是建立在大量存储要求的基础上的。
不管是哪种解决方案,我们的目的只有一条,就是尽可能多的收集需要的数据, 所以在实际操作过程中, 我们可以根据具体情况,多种方案相结合使用。
◆ 近期热文 ◆
◆ 专家专栏 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721