
一、背景
在当前整个行业及公司内部降本增效的大背景下,B站内部也在积极推进实时与在线业务资源的整合,往云原生架构迁移,统一资源池与调度,提升资源利用效率。不过面临的现实问题就是,不同业务场景下,资源的规格诉求不尽相同。
在线的业务资源池,由于在线业务的属性,一般只具备很强的计算能力而基本不带存储以及io能力。Flink虽然是一个计算引擎,但是由于其stateful的特性,在很多计算场景下,对存储和io其实有比较强的诉求,因此实时的资源池,同时具备很强的存算能力。两种资源池的整合,必然面临兼容性问题,考虑到大数据整体的存算分离发展趋势,我们尝试对Flink进行存算分离的改造,核心工作就是statebackend的远程化。
二、痛点
Flink里面的StateBackend,是用来存储任务状态的。从用途上划分为OperatorStateBackend和KeyedStateBackend,OperatorStateBackend一般存的是一些与计算逻辑本身无关的数据,如Kafka的offset,体量比较小,不会受数据规模与计算逻辑影响,而KeyedStateBackend相反,存储的是与计算逻辑强绑定的状态数据,如agg/双流Join的中间结果,大小受着数据规模和计算逻辑影响,一般大流量,计算复杂的任务State会非常大。
B站的流计算任务有4000+个,95%的任务均是sql任务,其中50%的任务带状态,且有上百个任务状态大小超过500GB。目前内部的默认StateBackend使用的是RocksDBStateBackend,其在实现上支持了增量快照,可以减少大量重复State数据上传到文件系统,另外历史的Flink集群机器都配置了比较高性能的磁盘,可以支持TaskManager的本地保存大State到RocksDB中,当任务做Checkpoint时,再将增量的State文件上传至文件系统,这一现状及配置能支持所有的流计算任务,无论其KeyedState大小是0或者TB级别。现有的这一环境会有如下两个痛点:
所有的Flink机器都配置了高性能的大磁盘,能支持超大State任务的健康运行,我们对State做了RetentionTime默认配置,有百分之八十的任务是百GB以内的小状态或者无Keyed State,这些任务TaskManager所运行的机器整体利用率明显偏低,如果所在机器没有大State存在,当前机器的高性能大磁盘存在较为明显的浪费。
超大State在做Rescale时,任务会先将State数据从文件系统下载本地并实例化成RocksDB,然后TaskManager之间根据KeyGroup对数据做重分布操作,本质是对RocksDB根据KeyGroupId做seek和BatchWrite操作,当State在TB级别时,State数据的重分布成本是比较大的,恢复时间需要半个小时左右,用户体验会比较差,且易增加引擎侧的值班成本。
三、RemoteStateBackend
如需解决上面的痛点,一个是需要将State数据能实时的存储在远程服务中,减少Flink集群对磁盘的强依赖,实现存算分离,这一目的也正和云原生架构演进目标契合;另一个是State数据可以以KeyGroup为单位来存储,避免数据的重分布操作。
经过与分布式存储团队沟通后,其自研的Taishan(B站分布式KV存储[1])存储基本能满足我们的诉求,Taishan存储是基于RocksDB和SparrowDB改造,采用raft一致性协议保证多副本数据一致性而构建的高可靠、高可用、高性能、高拓展的存储系统。Taishan存储提供了Java的put/get/del/scan等api,且能具备snapshot的功能,在api层面和RocksDB的功能基本一致,且能支持水平扩容和在线升级,完全能满足Flink的需求,经过多次沟通和功能支持后具备构建TaishanStateBackend条件。
在KeyedStateBackend中,每条待计算的数据进入subtask中,会根据数据的key通过"MathUtils.murmurHash(key's HashCode) % maxParallelism"计算出一个ID作为KeyGroupId,这样可以保证相同key的数据会在同一个subtask中计算,不会导致在计算引擎内出现乱序的现象,maxParallelism则为最大并行度,其值在任务启动之后就不会发生改变。每条数据根据KeyGroupId会归属到一个Key-Group分片中,Key-Group分片总数为maxParallelism,每个分片是无法分裂的,因为maxParallelism的值在重启前后均不允许被修改,当任务做rescale时,对State来说是将Key-Group下的数据做移动,如下图所示。
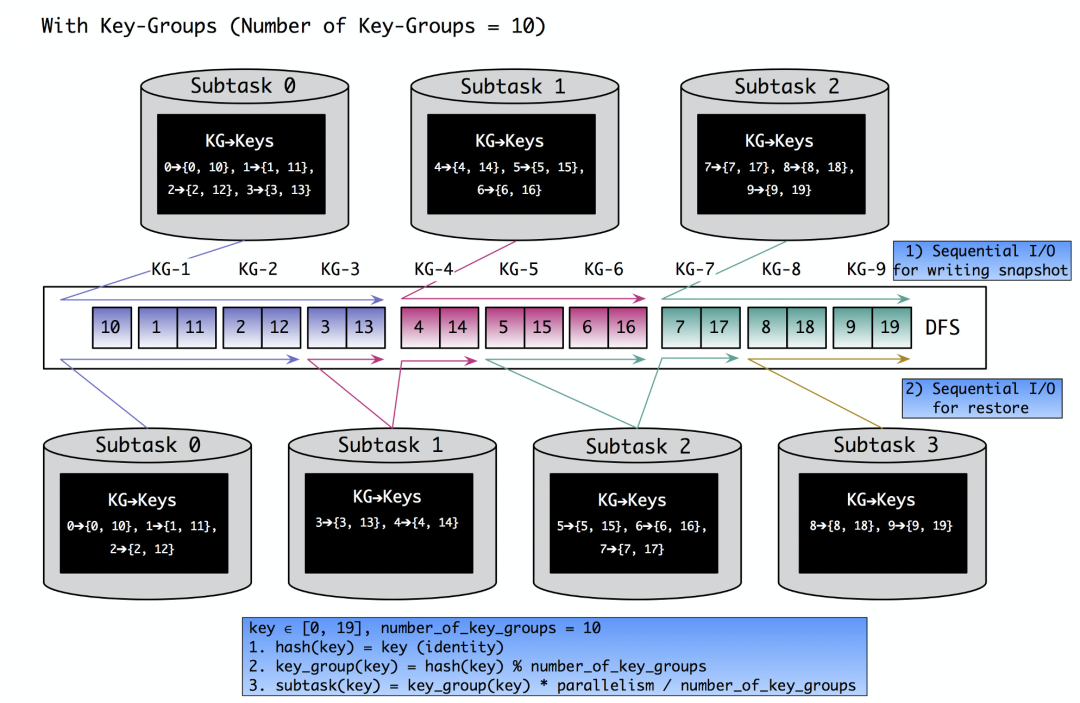
Taishan存储有shard分片概念,正好与Flink的KeyGroup类似,Taishan的shard具备分裂和合并的能力,我们仅需约定Flink的Taishan表关闭此功能即可。Flink还有另一个关键的点是Checkpoint,RocksDBStateBackend的增量Checkpoint是同步过程对RocksDB做snapshot,异步过程将变动的SST文件上传至文件系统以便任务重启时恢复,Taishan存储提供了可在每个shard上做snapshot的create和restore能力,Flink可以在做Checkpoint时,在每个subtask内按照KeyGroupRange的start至end依次做snapshot,snapshotID与Flink的CheckpointID保持一致。
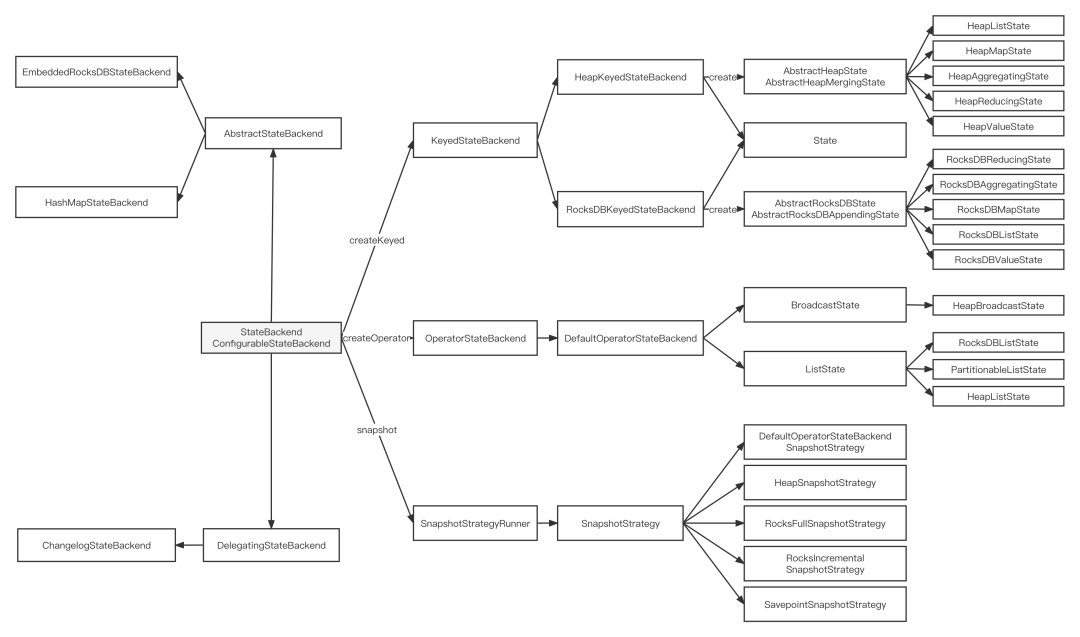
Keyed StateBackend承担核心的状态数据管理,管理的State分为Keyed State和Priority Queue State。其中Keyed State有基础的InternalValueState和InternalMapState,以及复杂的InternalListState、InternalAggregatingState、InternalReducingState和InternalFoldingState,不同类型的State会应用于SQL不同场景的算子上;Priority Queue State则需由InternalPriorityQueue实现。Flink流计算的Checkpoint机制是其可靠性的基石,当一个任务在运行过程中出现故障时,可以根据Checkpoint的信息恢复到故障之前的某一状态,然后从该状态恢复任务的运行,而Checkpoint的执行策略根据SnapshotStrategy的实现决定,Checkpoint的恢复策略根据RestoreOperation的实现决定,我们需要对如上提到的关键接口做好Remote StateBackend的实现,整体拓扑结构如下图所示。
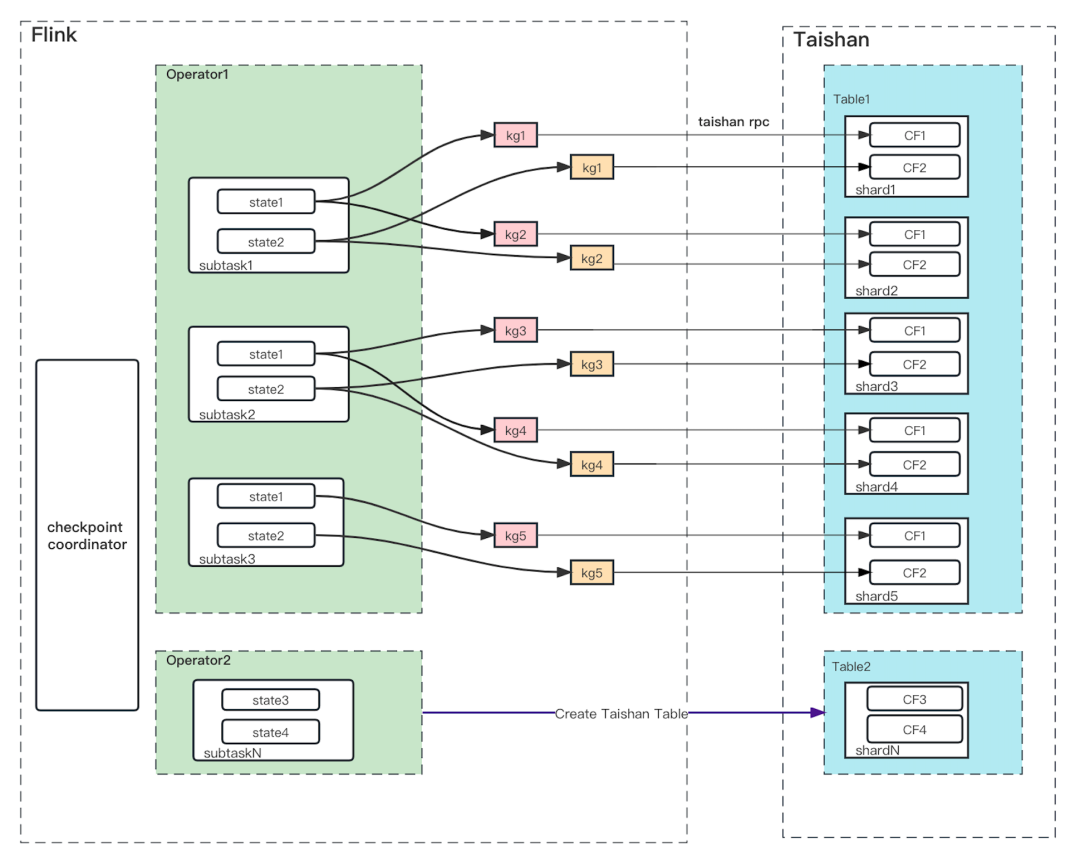
TaishanStateBackend基于如上规则和Taishan存储做了如下约定:
KeyGroupId和Taishan Table的shardID做一一对应。
Taishan表的shard分片数和Flink的maxParallelism保持一致,且始终不可分裂和合并。
任务在第一次启动时,每个带有KeyedState的Operator会有且仅创建一张Taishan表。
一个Operator下可能存在多个State,发送的KV数据的K会加上ColumnFamily前缀。
Flink做Checkpoint时,会对Taishan的每个shard做一次snapshot的创建,且每个shard的snapshotID一样。
Flink做任务恢复时,本质是对Taishan的每个shard根据snapshotID做restore。
通过修改成远端存储架构后,主要优势如下:
1)Checkpoint更轻
RocksDBStateBackend的State均是存放在subtask的本地RocksDB中的,仅在做Checkpoint时会根据SnapshotStrategy决定是增量还是全量的方式上传至FileSystem,上传的内容分metadata和KeyedState内容,当修改成TaishanStateBackend之后仅需上传metadata元数据文件至FileSystem即可,单shard的snapshot过程基本上在毫秒内可以可以完成。
2)存算分离
改用TaishanStateBackend后,带状态的Operator无需此节点机器拥有高性能磁盘,State数据均存储于远端的Taishan系统,这样使得Flink的container机器减少了对磁盘的强依赖性,从而达到了存算分离的效果。
3)加速任务rescale
RocksDBStateBackend中当任务做扩缩时,由于subtask下对应的KeyGroupRange的start和end有变化,需要和其他subtask之间对本地的rocksDB实例按照KeyGroupId前缀做State的seek和batchPut操作,从而对State数据按照KeyGroup做重新分布,当State越大时,State数据重分布成本越大,任务rescale对延迟的影响也就越大。而使用TaishanStateBackend后,任务做扩缩操作无需State数据的搬迁操作,因为每个KeyGroup与shard一一对应,仅需修改KeyGroupRange的开始和结束即可。
四、优化
我们前期在RocksDBStateBackend中已经对State的Read、Write、Delete、ReadNull、Seek等请求做了耗时、请求量和数据包长度的metric统计。通过对线上运行的任务指标做分析可以得知,State的每秒读写请求量最高可达百万级别,每秒十万级别的读写请求量任务也有百来个,另外每个请求数据包的大小在group agg和window agg场景下一般为几十bytes,而在Join场景下单条State的value即使做了zstd压缩后大小依旧会有百KB级别的存在。
在做功能测试时,发现一个任务在同等资源情况下,使用TaishanStateBackend的CPU负载更高,经过诊断发现当State的rpc请求量越大时,网络消耗CPU占比越大。当我们State的数据从本地转换成远端存储后,每次请求均走网络rpc请求,虽然没有RocksDB堆外内存的消耗了,但是对网络的依赖会较大,当rpc请求达到一定阈值时,网络必然会成为当前场景下的瓶颈。为了解决这一问题,我们选择在State与远端KV存储之间添加了一层缓存层,减少对网络的请求读,另外参考Flink的MiniBacth,希望在缓存层也能做到攒批写的效果。整体结构如下,并在下文中逐步展开说明。
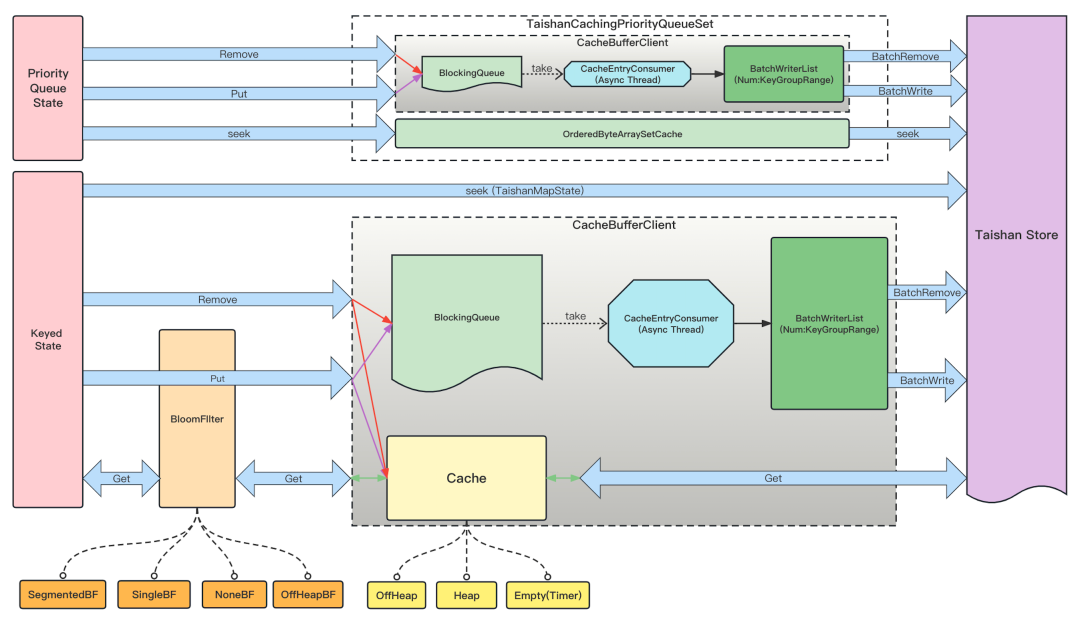
1)攒批优化写
State的写操作,并未选择从Cache中遍历结果后写出到远端,也并未选择put/remove时直接与远端交互,而是选择将put/remote请求放入当前subtask的BlockingQueue中,使用异步线程去消费put/remote请求,当请求量达到一定阈值(最大攒批量或最大延迟时间)后会flush到远端KV存储,或者是Flink做Checkpoint时主动触发一次flush操作。经过添加指标和压测发现当最大攒批量设置为800时,对远端KV存储的put请求仅会有2-4倍的耗时增加,整体的网络写请求量成百倍的减少,增加了State的写速率。
1)缓存加速读
State的写操作,并未选择从Cache中遍历结果后写出到远端,也并未选择put/remove时直接与远端交互,而是选择将put/remote请求放入当前subtask的BlockingQueue中,使用异步线程去消费put/remote请求,当请求量达到一定阈值(最大攒批量或最大延迟时间)后会flush到远端KV存储,或者是Flink做Checkpoint时主动触发一次flush操作。经过添加指标和压测发现当最大攒批量设置为800时,对远端KV存储的put请求仅会有2-4倍的耗时增加,整体的网络写请求量成百倍的减少,增加了State的写速率。
在实践的过程中,会发现如下两种场景下会存在较大的ReadNull请求,也就是Cache获取结果为null,且从远端获取结果也为null。
当任务的key比较稀疏时,通过指标发现存在大量的ReadNull的请求,一般在去重以及window agg的hop场景下尤为明显。
当任务的key存在天或小时这种周期性变化属性时,会导致大量的ReadNull请求产生,一般在Group Agg场景下尤为明显。
既然是ReadNull请求较多,经过调研后,初步尝试使用Hadoop的BloomFilter来做ReadNull请求的过滤,当Flink做Checkpoint时,将BloomFilter结果写到远端存储系统,任务restore时亦可恢复。然而无论如何调整BloomFilter的系数和容量大小,随着时间的递增,由于BloomFilter无法做有效的delete,导致BloomFilter的过滤效果越来越低,假阳性越来越高,亦不能解决ReadNull的根本问题。
我们内部的Flink BSQL任务目前对State均有24小时的默认TTL设置,当State的数据超过24小时未访问后,State会失效过期,并随后在RocksDB做compaction时被移除,这样的配置也基本上能满足大多数用户的实际使用的。
经过Team内部与用户排查故障总结中发现,用户业务行为中存在不少的window 5/10min,以及双流Join 1/2Hour的场景,这样24小时的TTL对这类Case显得是十分的富裕,既然如此,我们可以假设用户多数场景下数据不会存在延迟,那么任务的Key在5min或者1小时内的实际有效key相对24小时会少很多。这时可以选择在缓存中划出一定比例的内存,用来创建一个独立的KV Cache,其中K用来存储TTL时间内State的key,而V使用Int类型存储当前K失效的绝对时间,单位为秒,当Cache使用驱逐策略删除数据时,可以自定义删除逻辑,删除逻辑为判断当前时间与失效的绝对时间大小对比即可,如果当驱逐数据不满足当前时间小于失效时间时,抛OOM异常,并提示增加相关内存或者调整KV Cache的比例即可。
由于堆内内存受限于GC的压力,再加上调研使用了堆外内存作为缓存的默认选择,故仅在使用堆外内存时,才允许使用这个独立的KV Cache,我们称之为OffHeapBloomFilter,有关堆内外选择的事项会在下文中做展开说明。OffHeapBloomFilter会将所有有效的Key缓存在内存中,用以充当BloomFilter的效果,从而来过滤大量的ReadNull请求。
流计算任务做Checkpoint时,不会将OffHeapBloomFilter的数据flush到远端KV系统,当任务重启时,OffHeapBloomFilter会在第一个TTL时间内失效,但是会记录State的key前后数据,当第一个TTL时间之后OffHeapBloomFilter才会开始正常work,这样可以保障BloomFilter的准确与有效。
由于Window Agg的Keyed State使用的是Priority Queue State按照window的顺序来做清理的,所以其Keyed State默认是没有TTL的,我们对TumblingWindowAssigner、SlidingWindowAssigner、CumulativeWindowAssigner三种Assigner做了TTL的添加,TTL为Assigner的窗口时间加允许延迟时间,延迟时间一般是用来做任务的重启、失败或堆积的缓冲时间,避免因任务异常时间过长,导致State获取为null,从而引发数据结果不理想问题。同理,我们对Interval Join以及内部自研的两种延迟双流Join的Keyed State也分别提供了相应的支持,TTL设置为左右流的最大时间加允许延迟时间。
在缓存读优化中,最初Cache使用的内存是Task Heap的堆内内存,与用户代码的JVM堆内存共享,Cache使用的是高性能缓存库Caffeine。当一个Operator存在至少一个State时,创建一个Taishan表,subtask会根据拥有多少个Keyed State而决定创建多少个Caffeine Cache,结构如下。
这样的结构遇见了如下两个问题:
1) Caffeine Cache的创建个数等于N*M,其中N为当前TaskManager的Slot数,M为Keyed State个数。由于流计算前后可能存在AGG或Filter导致前后Cache处理的State数据量不一样,从而导致对Cache按照时间或数量的驱逐策略难以配置,并且Cache对象之间是不共享的,低频更新的Cache内存无法充分利用。
2) 使用中发现经过多次G1参数[2]调整后,依旧存在GC耗时较高,且存在不定时的GC高耗时抖动现象,从而使得任务不那么丝滑,影响用户体验。
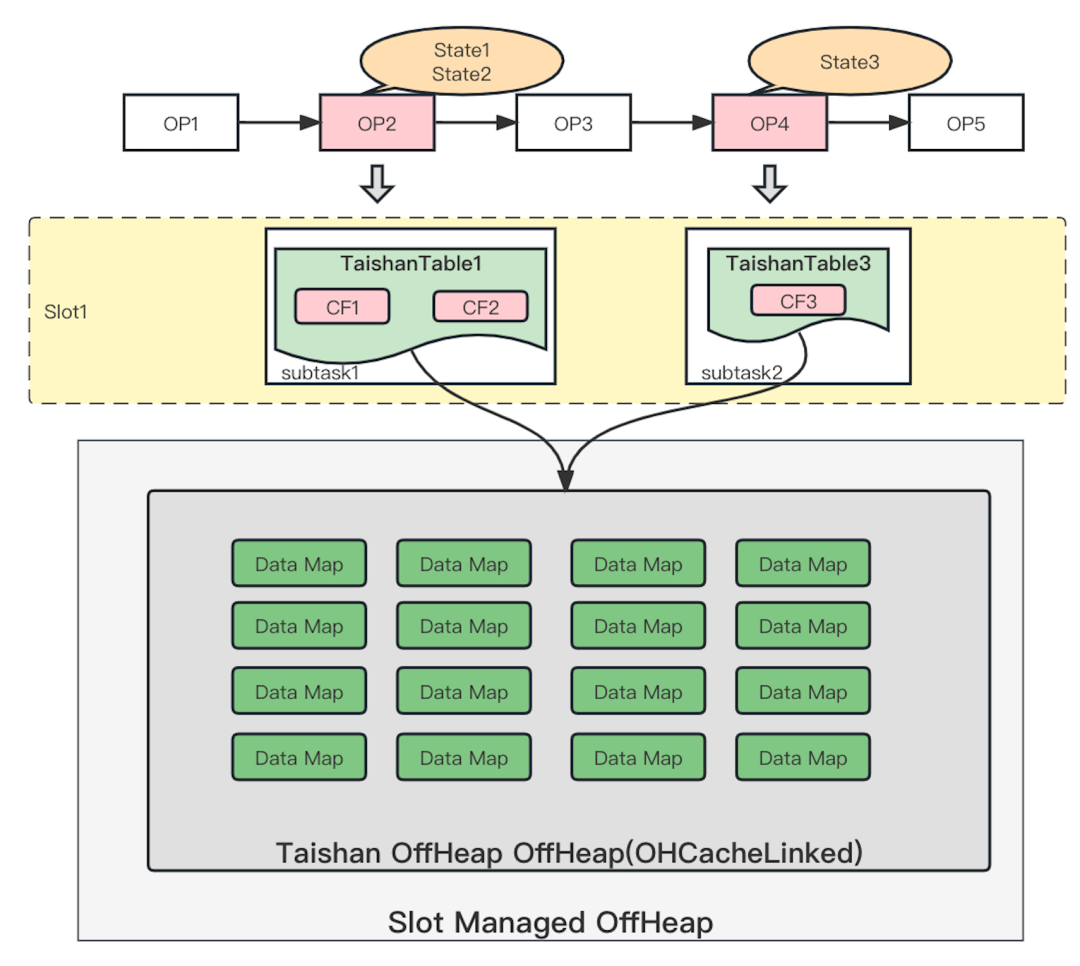
经过调研RocksDBStateBackend的堆外内存机制[3],以及市面上的堆外内存框架后,选择了使用off heap cache(简称OHC)框架[4]来做Cache,并产生了如下的结构。Caffeine Cache被替换成OHC Cache,内存从Task Heap转换成了使用Managed OffHeap,多个subtask共享当前Slot分配的OHC Cache,且分配的Cache对象唯一共享,经过如此替换后可以充分解决上面的两个主要问题,并且执行效率基本符合预期。
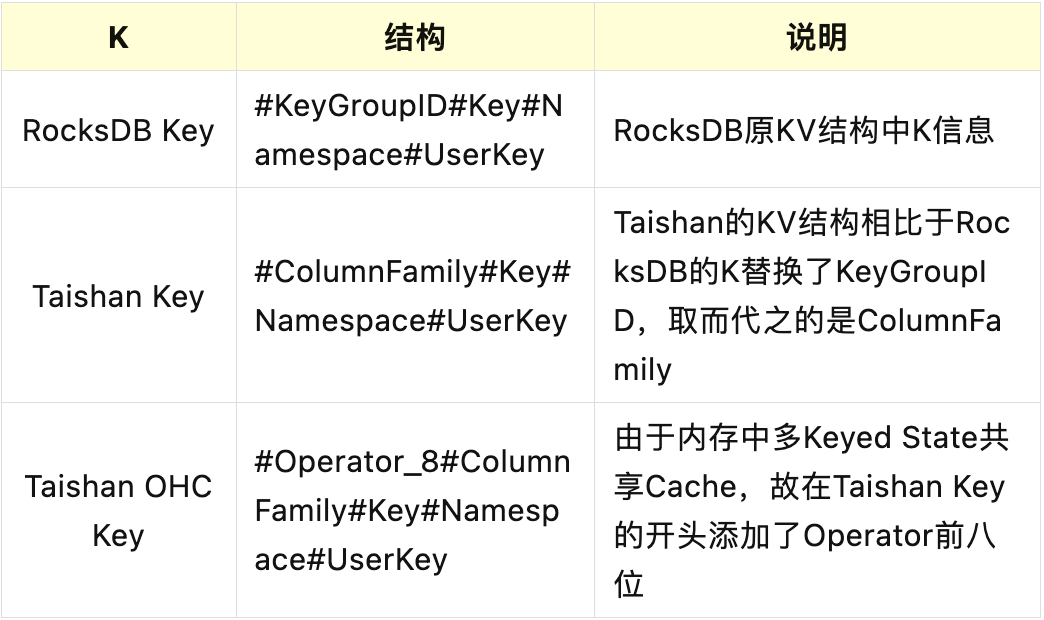
由于Taishan存储中早期未使用ColumnFamily的概念,且API层面将KeyGroupId放在了API作为参数,故将原RocksDB的K中KeyGroupId替换成了ColumnFamily,另外由于OHC Cache在堆外共享,可能存在多个State的ColumnFamily和Key均一致,为了避免Operator之间互相影响State数据,故将Taishan State的K添加了Operator前八位作为前缀。
另外针对OHC缓存,我们内部默认选择OffHeapLinkedLRUMap,其内存模型结构如下图所示,并做些许适配:
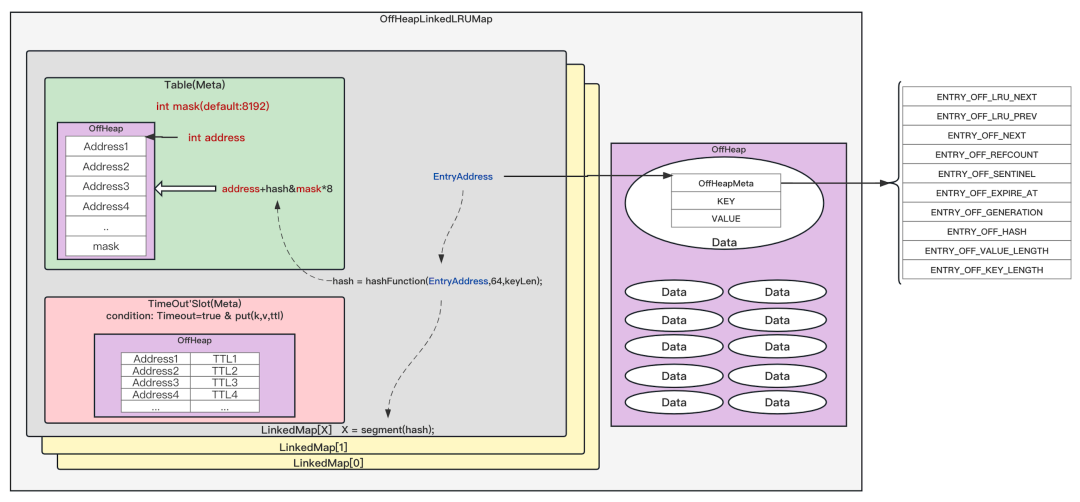
1)修改了hashTableSize,并关闭了Map的自动rehash,防止因KeyIterator的调用导致数据不准确。
2)修改了LRU的驱逐逻辑,OHC在CacheSerializer中添加elementCouldRemove方法,OHC驱逐数据前会调用此方法判断数据是否可以移除,Flink端Value Serializer仅需对elementCouldRemove做实现判断当前时间是否大于失效时间即可,这样的好处一个是可以和异步延迟时间flush做对齐,保证失效数据均已被写到了远端存储,另一个是在OffHeapBloomFilter中数据失效的驱逐策略逻辑中有使用。
3)修改OHC的TimeOut触发逻辑,虽然能通过指标精准查看Cache堆外内存的实际使用量,但是对任务的吞吐存在负面影响,故后续默认关闭了TimeOut功能。
五、现状与未来
目前B站从2022年11月初开始逐步切换了100+个线上带KeyState的任务,目前因增加了rpc网路开销导致整体资源使用有微量增加,但是基本已实现存算分离和加速任务rescale的目的,整体是符合预期的。
当然还存在一些特殊case,留存的主要待优化事项如下:
高QPS场景:部分业务场景中key十分稀疏,缓存命中率低,当State数据量足够大时,OffHeapBloomFilter对内存需求过高,降本增效的大环境下实施起来比较困难且收益比较低,而关闭OffHeapBloomFilter会导致出现大量的ReadNull现象,整体表现为单subtask的GRPC请求的QPS过高,网络压力较大。
大Key/Value场景:双流Join下存在超大Value以及多字段去重的场景下存在大Key,在运行一段时间后会存在WriteStall现象,从而影响任务的健康运行,这也是下一阶段需要和存储团队做进一步联调优化的地方。
状态的分层存储:目前的缓存的实现是使用堆外内存作为存储介质,上面提到的高QPS和大key/value场景中会因为内存空间限制而导致缓存命中率下降。未来我们计划参考Flink Forward Asia 2022中提到的Tiered State Backend的思路,将机器上的磁盘和内存都作为缓存加速的资源,同时保持状态数据完整保存在远程存储上,形成一套分层状态存储的架构,这样的架构除了能够解决单一缓存介质的容量限制,还有能够更加有效地提高混部情况下机器的资源利用率。接下来Flink的实时任务会通过K8S平台与在线业务实现混部和统一管理,而随着B站在线业务正在积极推进“无盘化”的改造,本地空闲的SSD磁盘资源能够更好地被Flink任务用作分层状态存储的缓存资源,进一步提高混部技术下的机器资源利用率。
在如上优化项进行的同时,会进一步推进TaishanStateBackend的覆盖率,并选择合适的任务在离在线混部集群中做部署,最终希望能达到默认开启的效果。
参考资料
[1] https://mp.weixin.qq.com/s/AqG0jCbDGjpjGTDdG7pSLw
[2] https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html
[3] https://github.com/facebook/rocksdb/wiki/Write-Buffer-Manager
[4] https://github.com/snazy/ohc








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721