
随着互联网信息技术日新月异的发展,一个海量数据爆炸的时代已经到来。如何有效地处理、分析这些海量的数据资源,成为各大技术厂商争在激烈的竞争中脱颖而出的一个利器。可以说,如果不能很好的快速处理分析这些海量的数据资源,将很快被市场无情地所淘汰。
当然,处理分析这些海量数据目前可以借鉴的方案有很多:首先,在分布式计算方面有Hadoop里面的MapReduce并行计算框架,它主要针对的是离线的数据挖掘分析。此外还有针对实时在线流式数据处理方面的,同样也是分布式的计算框架Storm,也能很好的满足数据实时性分析、处理的要求。最后还有Spring Batch,这个完全面向批处理的框架,可以大规模的应用于企业级的海量数据处理。
在这里,我就不具体展开说明这些框架如何部署、以及如何开发使用的详细教程说明。我想在此基础上更进一步:我们能否借鉴这些开源框架背后的技术背景,为服务的企业或者公司,量身定制一套符合自身数据处理要求的批处理框架。
首先我先描述一下,目前我所服务的公司所面临的一个用户数据存储处理的一个现状背景。目前移动公司一个省内在网用户数据规模达到几千万的规模数量级,而且每个省已经根据地市区域对用户数据进行划分,我们把这批数据存储在传统的关系型数据库上面(基于Oracle,地市是分区)。移动公司的计费结算系统会根据用户手机话费的余额情况,实时的通知业务处理系统,给手机用户进行停机、复机的操作。业务处理系统收到计费结算系统的请求,会把要处理的用户数据往具体的交换机网元上派发不同的交换机指令,这里简单的可以称为Hlr停复机指令(下面开始本文都简称Hlr指令)。
目前面临的现状是,在日常情况下,传统的C++多进程的后台处理程序还能勉强的“准实时”地处理这些数据请求,但是,如果一旦到了每个月的月初几天,要处理的数据量往往会暴增,而C++后台程序处理的效率并不高。这时问题来了,往往会有用户投诉,自己缴费了,为什么没有复机?或者某些用户明明已经欠费了,但是还没有及时停机。这样的结果会直接降低客户对移动运营商支撑的满意度,于此同时,移动运营商本身也可能流失这些客户资源。
自己认真评估了一下,造成上述问题的几个瓶颈所在。
一个省所有的用户数据都放在数据库的一个实体表中,数据库服务器,满打满算达到顶级小型机配置,也可能无法满足月初处理量激增的性能要求,可以说频繁的在一台服务器上读写IO开销非常巨大,整个服务器处理的性能低下。
处理这些数据的时候,会同步地往交换机物理设备上发送Hlr指令,在交换机没有处理成功这个请求指令的时候,只能阻塞等待,进一步造成后续待处理数据的积压。
针对上述的问题,本人想到了几个优化方案。
数据库中的实体表,能不能根据用户的归属地市进行表实体的拆分。即把一台或者几台服务器的压力,进行水平拆分。一台数据库服务器就重点处理某一个或者几个地市的数据请求?降低IO开销。
由于交换机处理Hlr指令的时候,存在阻塞操作,我们能不能改成:通过异步返回处理的方式,把处理任务队列中的任务先下达通知给交换机,然后交换机通过异步回调机制,反向通知处理模块,汇报任务的执行情况。这样处理模块就从主动的任务轮询等待,变成等待交换机执行结果的异步通知,这样它就可以专注地进行处理数据的派发,不会受到某几个任务处理时长的限制,从而影响到后面整批次的数据处理。
数据库的实体表由于进行水平拆解,能不能做到并行加载?这样就会大大节约串行数据加载的处理时长。
并行加载出来的待处理数据最好能放到一个批处理框架里面,批处理框架能很好地根据要处理数据的情况,进行配置参数调整,从而很好地满足实时性的要求。比如月初期间,可以加大处理参数的值,提高处理效率。平常的时候,可以适当降低处理参数的取值,降低系统的CPU/IO开销。
基于以上几点考虑,得出如下图所示的设计方案的组件图:
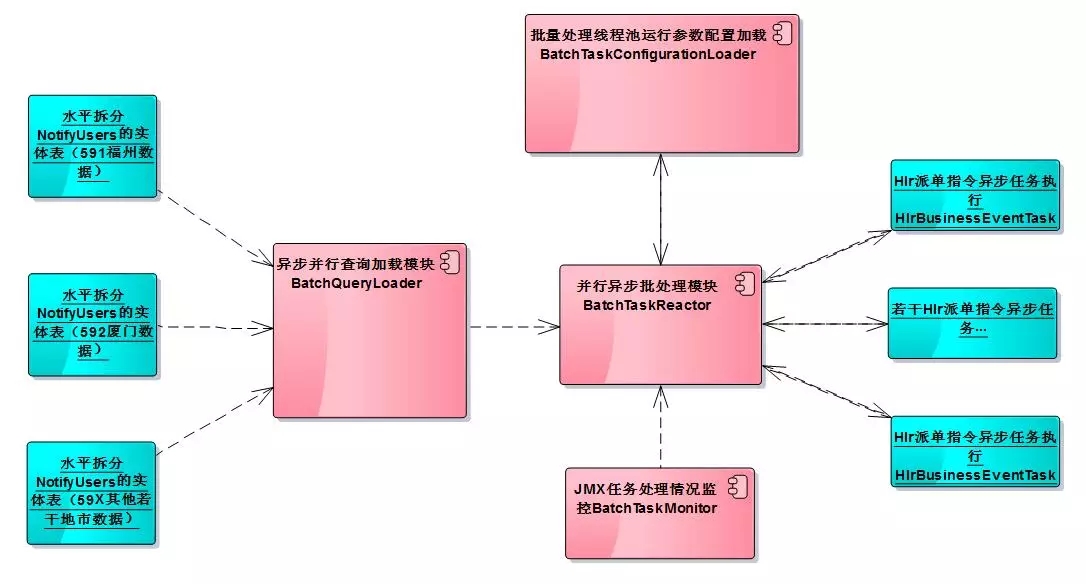
下面就具体说明一下,其中关键模块如何协同工作的。
异步并行查询加载模块BatchQueryLoader:支持传入多个数据源对象,同时利用google-guava库中对于Future接口的扩展ListenableFuture,来实现批量查询数据的并行加载。Future接口主要是用来表示异步计算的结果,并且计算完成的时候,只能用get()方法获取结果,get方法里面其中有一个方法是可以设置超时时间的。在并行加载模块里面,批量并行地加载多个数据源里面的实体表中的数据,并最终反馈加载的结果集合。
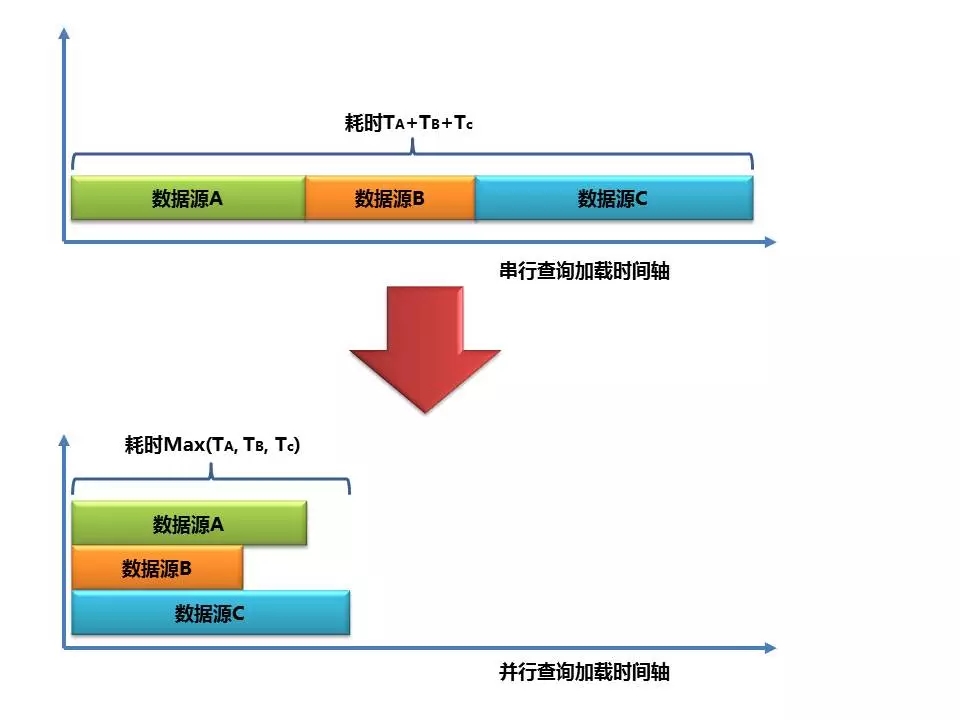
并行数据加载和串行数据加载所用的耗时可以简单用下面的图例来说明:串行加载的总耗时是每个数据源加载耗时的总和。而并行加载的总耗时,取决于最大加载的那个数据源耗时时长。(注:我们把每天要进行停复机处理的用户数据通过采集程序,分地市分布采集到水平分库的notify_users提醒用户表)
并行异步批处理模块BatchTaskReactor:内部是通过线程池机制来实现的,接受异步并行查询加载模块BatchQueryLoader得到的加载结果数据,放入线程池中进行任务的异步派发,它最终就是通过Hlr派单指令异步任务执行HlrBusinessEventTask模块下发指令任务,然后自己不断的从阻塞队列中获取,待执行的任务列表进行任务的分派。与此同时,他通过Future接口,异步得到HlrBusinessEventTask派发指令的执行反馈结果。
批量处理线程池运行参数配置加载BatchTaskConfigurationLoader:加载线程池运行参数的配置,把结果通知并行异步批处理模块BatchTaskReactor,配置文件
batchtask-configuration.xml的内容如下所示。

其中corePoolSize表示保留的线程池大小,workQueueSize表示的是阻塞队列的大小,maxPoolSize表示的是线程池的最大大小,keepAliveTime指的是空闲线程结束的超时时间。其中创建线程池方法ThreadPoolExecutor里面有个参数是unit,它表示一个枚举,即keepAliveTime的单位。说了半天,这几个参数到底什么关系呢?
我举一个例子说明一下,当出现需要处理的任务的时候,ThreadPoolExecutor会分配corePoolSize数量的线程池去处理,如果不够的话,会把任务放入阻塞队列,阻塞队列的大小是workQueueSize,当然这个时候还可能不够,怎么办。只能叫来“临时工线程”帮忙处理一下,这个时候“临时工线程”的数量是maxPoolSize-corePoolSize,当然还会继续不够,这个时候ThreadPoolExecutor线程池会采取4种处理策略。
现在具体说一下是哪些处理策略。
首先是ThreadPoolExecutor.AbortPolicy 中,处理程序遭到拒绝将抛出运行时 RejectedExecutionException。然后是ThreadPoolExecutor.CallerRunsPolicy 中,线程调用运行该任务的 execute 本身。
此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。其次是,ThreadPoolExecutor.DiscardPolicy 中,不能执行的任务将被删除。最后是ThreadPoolExecutor.DiscardOldestPolicy 中,如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)。如果要处理的任务没有那么多了,ThreadPoolExecutor线程池会根据keepAliveTime设置的时间单位来回收多余的“临时工线程”。你可以把keepAliveTime理解成专门是为maxPoolSize-corePoolSize的“临时工线程”专用的。
线程池参数的设定
正常情况下我们要如何设置线程池的参数呢?我们应该这样设置:I、workQueueSize阻塞队列的大小至少大于等于corePoolSize的大小。II、maxPoolSize线程池的大小至少大于等于corePoolSize的大小。III、corePoolSize是你期望处理的默认线程数,个人觉得线程池机制的话,至少大于1吧?不然的话,你这个线程池等于单线程处理任务了,这样就失去了线程池设计存在的意义了。
JMX(Java Management Extensions)批处理任务监控模块BatchTaskMonitor:实时地监控线程池BatchTaskReactor中任务的执行处理情况(具体就是任务成功/失败情况)。
介绍完毕了几个核心模块主要的功能,那下面就依次介绍一下主要模块的详细设计思路。
我们把每天要进行停复机处理的用户数据通过采集程序,采集到notify_users表。首先定义的是,我们要处理采集的通知用户数据对象的结构描述,它对应水平分库的表notify_users的JavaBean对象。notify_users的表结构为了演示起见,简单设计如下(基于Oracle数据库):

对应JavaBean实体类NotifyUsers,具体代码定义如下:

异步并行查询加载模块BatchQueryLoader的类图结构:
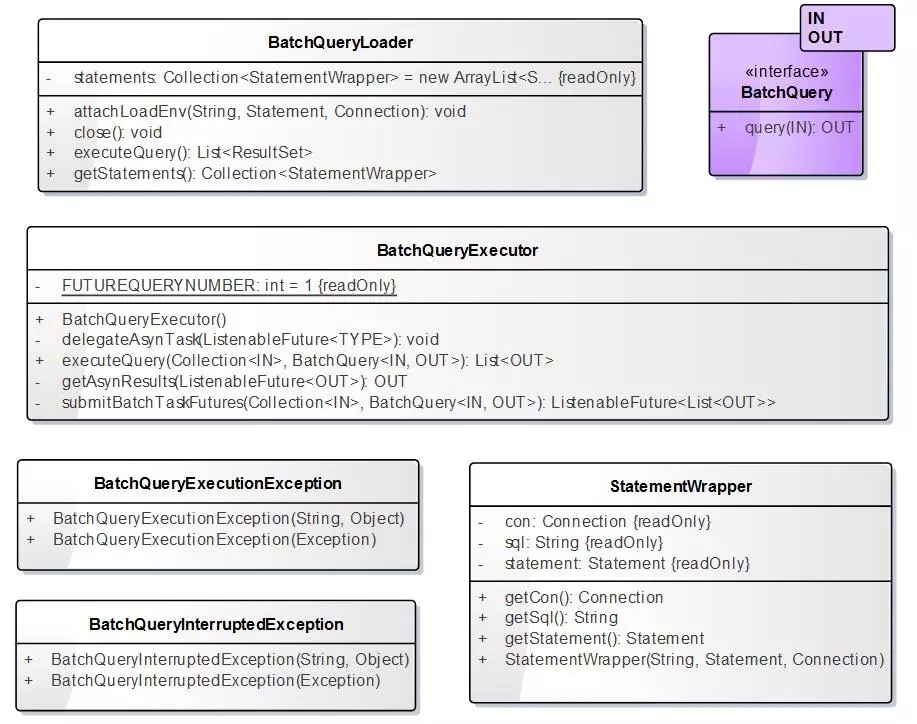
我们通过并行查询加载模块BatchQueryLoader调用异步并行查询执行器BatchQueryExecutor,来并行地加载不同数据源的查询结果集合。
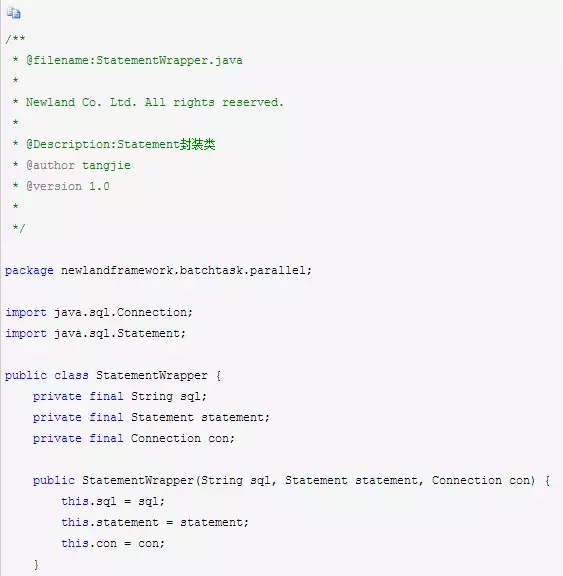
StatementWrapper则是对JDBC里面Statement的封装。具体代码如下所示:

定义两个并行加载的异常类BatchQueryInterruptedException、BatchQueryExecutionException

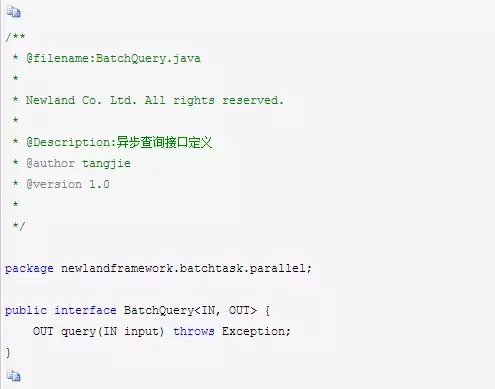
再抽象出一个批量查询接口,主要是为了后续能扩展在不同的数据库之间进行批量加载。接口类BatchQuery定义如下:
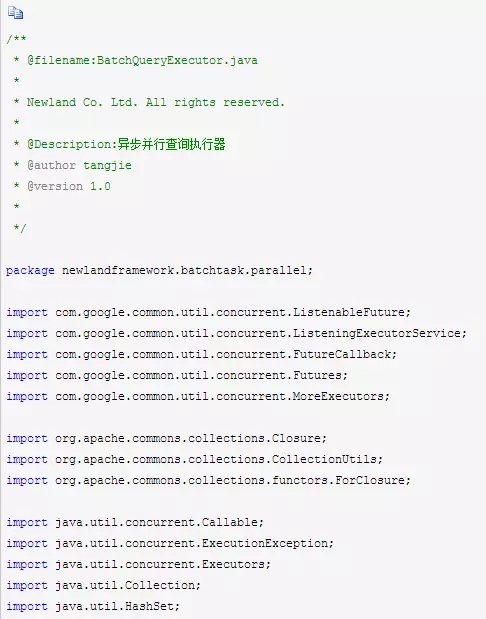
好了,现在封装一个异步并行查询执行器BatchQueryExecutor



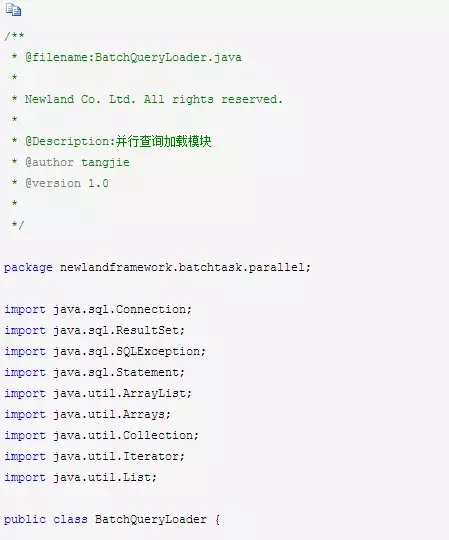
最后的并行查询加载模块BatchQueryLoader直接就是调用上面的异步并行查询执行器BatchQueryExecutor,完成不同数据源的数据并行异步加载,代码如下:

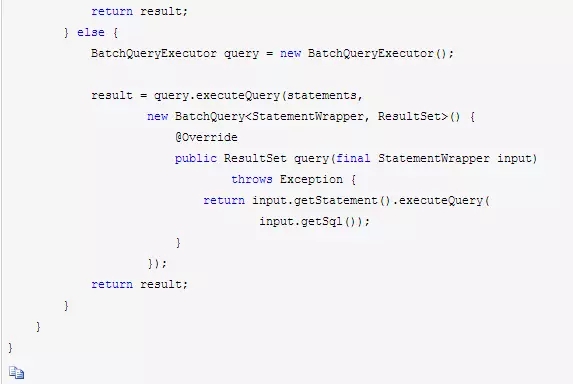
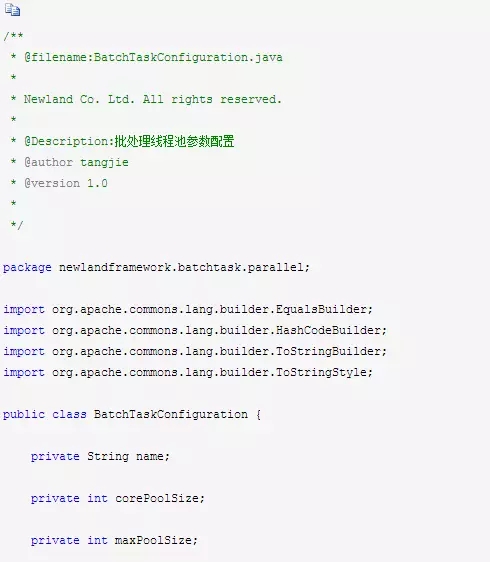
批量处理线程池运行参数配置加载BatchTaskConfigurationLoader模块,主要从负责从batchtask-configuration.xml中加载线程池的运行参数。
BatchTaskConfiguration批处理线程池运行参数对应的JavaBean结构:


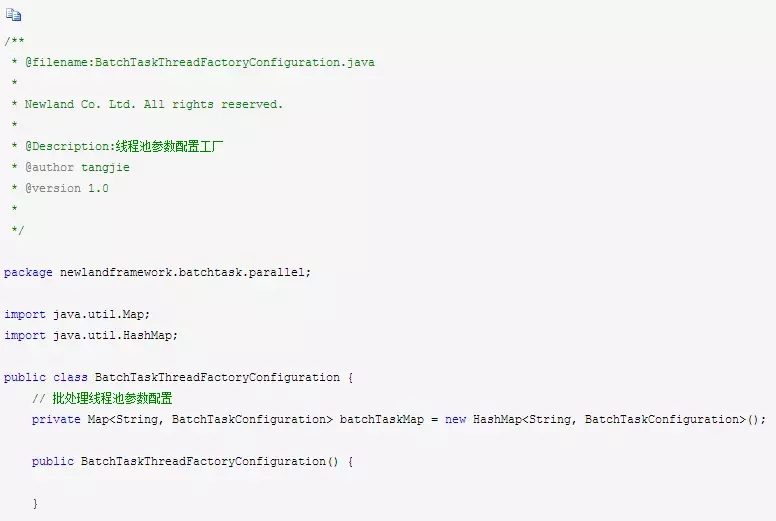
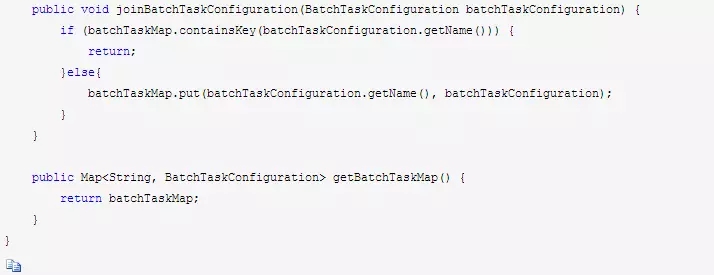
当然了,你进行参数配置的时候,还可以指定多个线程池,于是要设计一个:批处理线程池工厂类BatchTaskThreadFactoryConfiguration,来依次循环保存若干个线程池的参数配置。
剩下的是,加载运行时参数配置模块BatchTaskConfigurationLoader



上面的这些模块主要是针对线程池的运行参数可以调整而设计准备的。
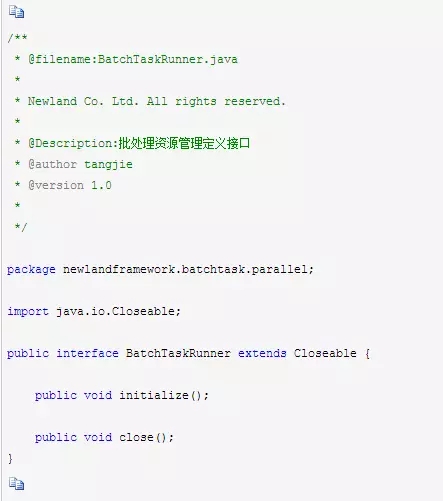
并行异步批处理模块BatchTaskReactor主要类图结构如下 :
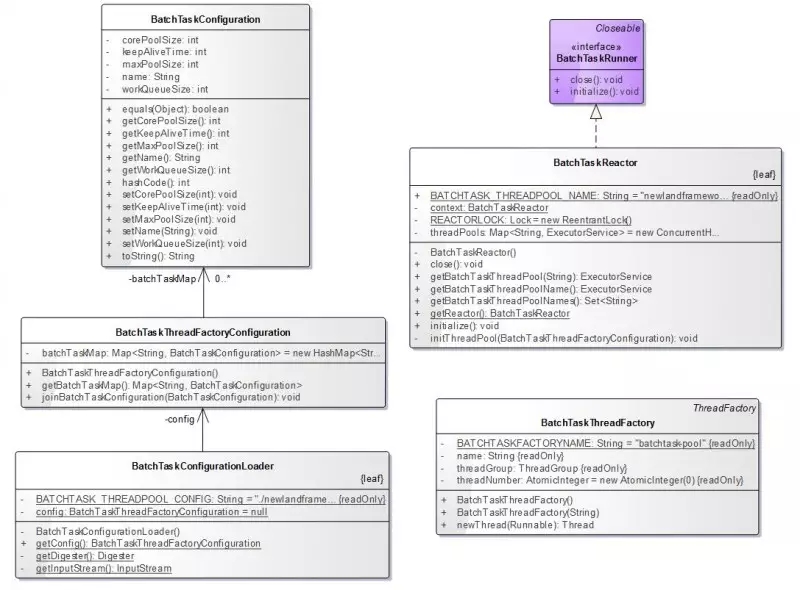
BatchTaskRunner这个接口,主要定义了批处理框架要初始化和回收资源的动作。
我们还要重新实现一个线程工厂类BatchTaskThreadFactory,用来管理我们线程池当中的线程。我们可以把线程池当中的线程放到线程组里面,进行统一管理。比如线程池中的线程,它的运行状态监控等等处理,你可以通过重新生成一个监控线程,来运行、跟踪线程组里面线程的运行情况。
当然你还可以重新封装一个JMX(Java Management Extensions)的MBean对象,通过JMX方式对线程池进行监控处理,本文的后面,有给出运用JMX技术,进行批处理线程池任务完成情况监控的实现,实现线程池中线程运行状态的监控可以参考一下。这里就不具体给出,线程池线程状态监控的JMX模块代码了。言归正传,线程工厂类BatchTaskThreadFactory的实现如下:


下面是关键模块
并行异步批处理模块BatchTaskReactor的实现代码,主要还是对ThreadPoolExecutor进行地封装,考虑使用有界的数组阻塞队列ArrayBlockingQueue,还是为了防止:生产者无休止的请求服务,导致内存崩溃,最终做到内存使用可控采取的措施。



下面设计实现的是:交换机Hlr指令处理任务模块。当然,在后续的业务发展过程中,还可能出现,其他类型指令的任务处理,所以根据“开闭”原则的定义,要抽象出一个接口类:BusinessEvent

然后具体的Hlr指令发送任务模块HlrBusinessEvent要实现这个接口类的方法,完成用户停复机Hlr指令的派发。代码如下:

实际运行情况中,我们可能要监控一下指令发送的时长,于是再设计一个:针对Hlr指令发送任务模块HlrBusinessEvent,切面嵌入代理的Hlr指令时长计算代理类:HlrBusinessEventAdvisor,具体的代码如下:


剩下的,我们由于是要异步并行计算得到执行结果,于是我们设计一个:批处理Hlr任务执行模块HlrBusinessEventTask,它要实现java.util.concurrent.Callable接口的方法call,它会返回一个异步任务的执行结果。
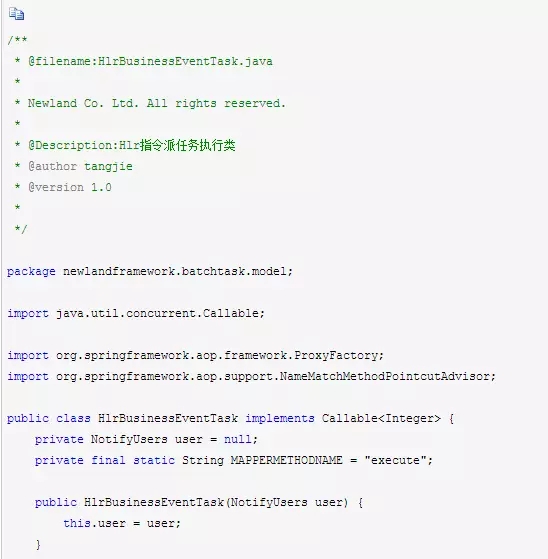
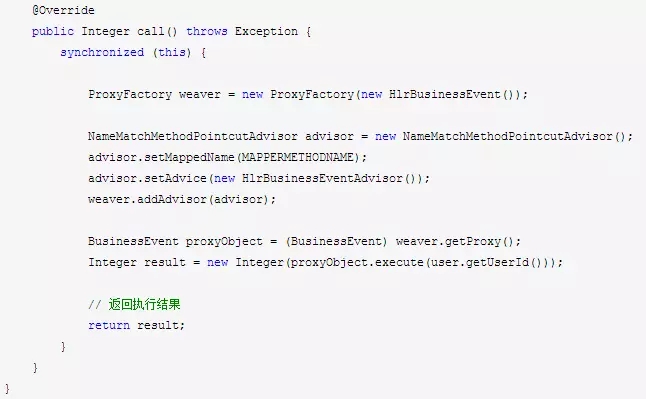
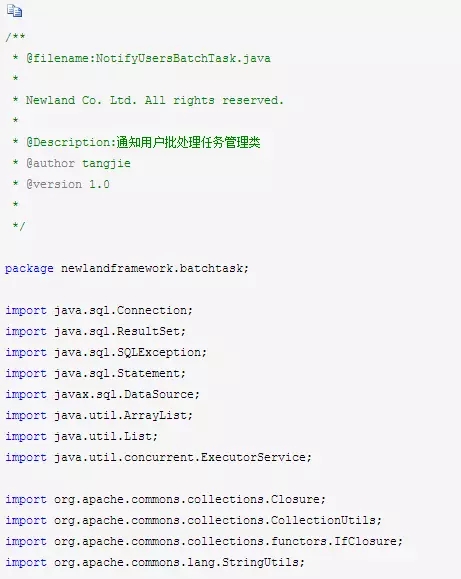
接下来,我们要把并行异步加载的查询结果,和并行异步处理任务执行的模块,给它组合起来使用,故重新封装一个,通知用户批处理任务管理类模块:NotifyUsersBatchTask。
它的主要功能是:批量并行异步加载查询待停复机的手机用户,然后把它放入并行异步处理的线程池中,进行异步处理。然后我们打印出,本次批处理的任务一共有多少,成功数和失败数分别是多少(当然,本文还给出了另外一种JMX方式的监控)。NotifyTaskSuccCounter类,主要是统计派发的任务中执行成功的任务的数量,而与之相对应的类NotifyTaskFailCounter,是用来统计执行失败的任务的数量。具体的代码如下:




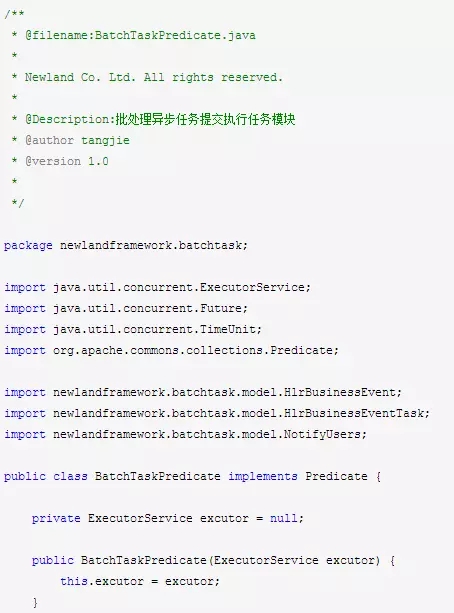
异步处理任务执行提交模块BatchTaskPredicate,主要是从线程池中采集异步提交要处理的任务,然后根据异步的执行结果,反馈给线程池:这个任务执行成功还是执行失败了。具体代码如下:

最后,我们通过,通知用户批处理任务管理类NotifyUsersBatchTask,它构造的时候,可以通过指定数据库连接池,批量加载多个数据源的数据对象。这里我们假设并行加载cms/ccs两个数据源对应的notify_users表的数据,它的spring配置batchtask-multidb.xml配置内容如下:


我们再来实现一种,通过JMX方式进行线程池批处理任务完成情况的监控模块。首先定义一个MBean接口,它根据计数器的名称,返回计数结果。
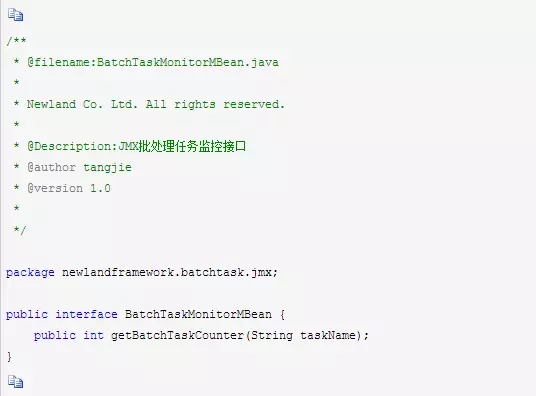
我们再来实现这个接口,于是设计得到BatchTaskMonitor模块
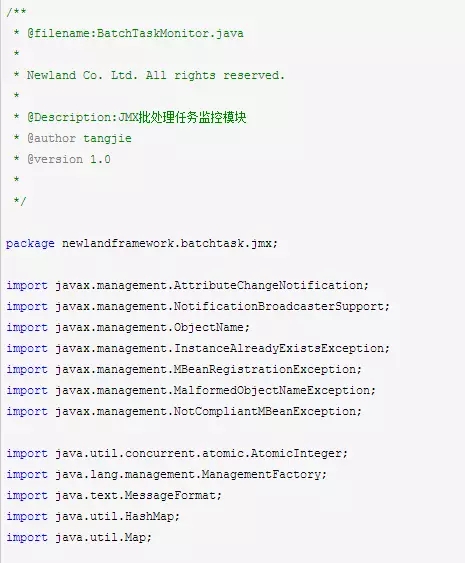


其中,计数器的名称,我已经在NotifyUsersBatchTask模块中已经指定了。批处理任务执行成功计数器叫做:String NOTIFYTASKSUCCCOUNTER = "TASKSUCCCOUNTER"。批处理任务执行失败计数器叫做String NOTIFYTASKFAILCOUNTER = "TASKFAILCOUNTER"。这样我们就可以通过JConsole实现,监控线程池任务的运行处理情况了。
最终,我们要把上面所有的模块全部“组装”起来。客户端调用方式的参考代码,样例如下所示:

我们再来运行一下,看下结果如何?先在数据库中分别插入福州591、厦门592一共80条的待处理数据(实际上,你可以插得更多,越多越能体现出这种异步并行批处理框架的价值)。运行截图如下:

正如我们所预想地那样。很好。
现在,我们再通过JMX技术,查看监控一下,并行批处理异步线程池任务的完成情况吧。我们先连接上我们的MBean对象BatchTaskMonitor。
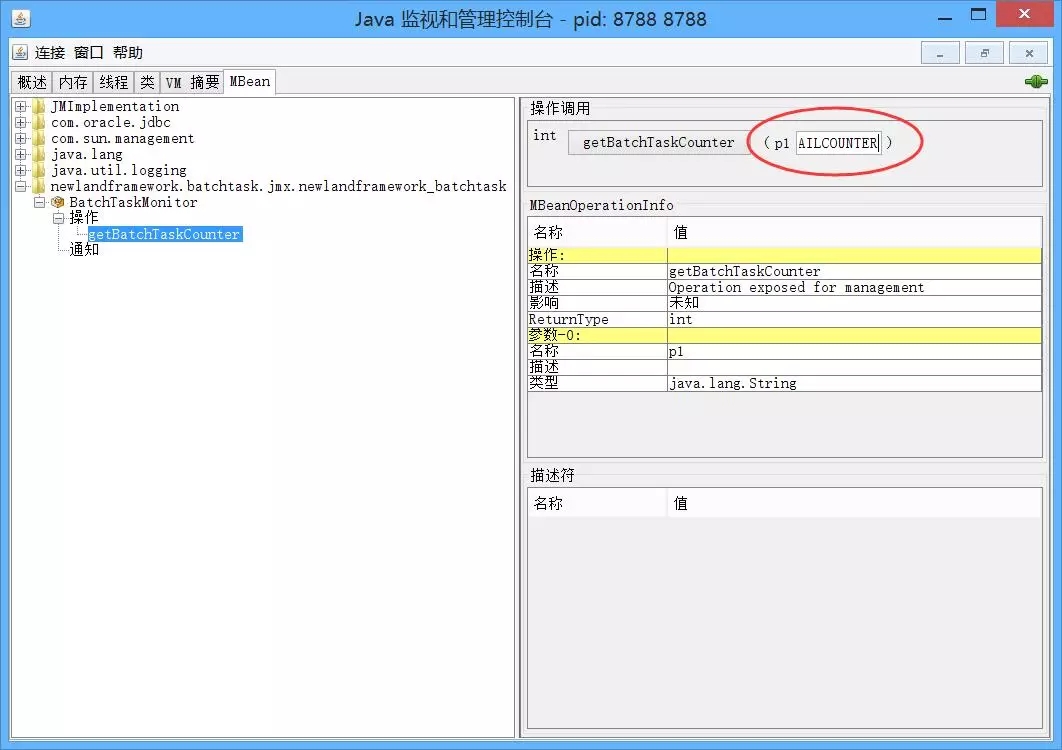
发现里面有个暴露的操作方法getBatchTaskCounter(根据计数器名称返回计数结果)。我们在上面红圈的输入框内,输入统计失败任务个数的计数器TASKFAILCOUNTER,然后点击确定。最后运行结果如下所示:
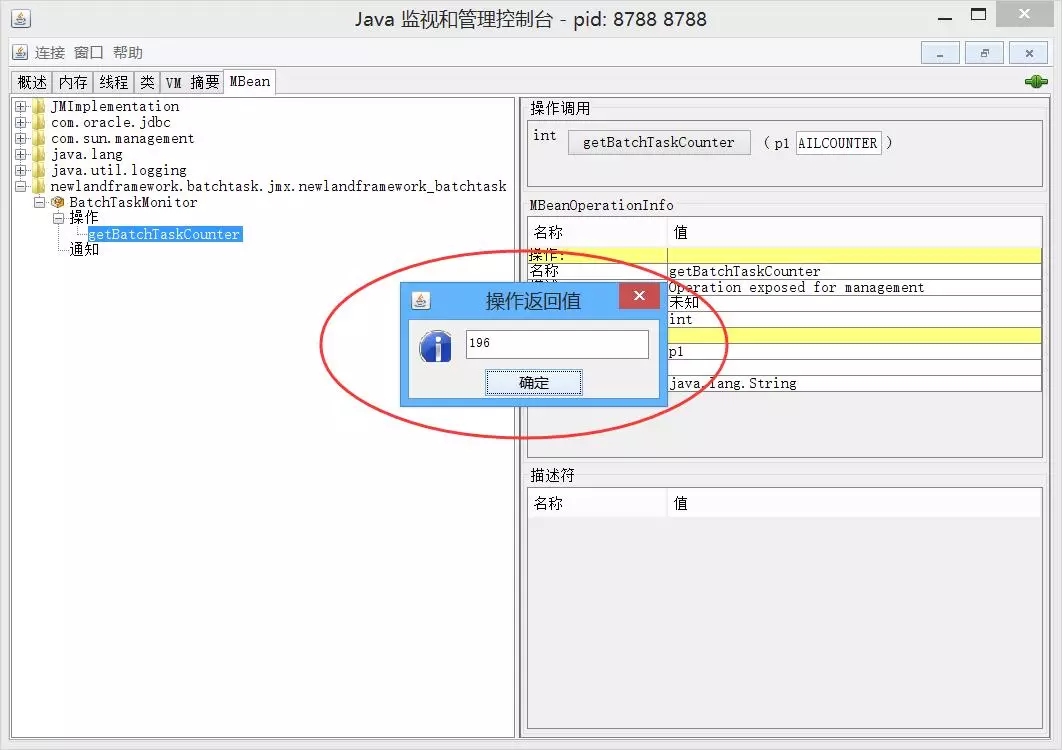
发现我们批处理任务,目前已经处理失败了196个啦!正如我们希望的那样,可视化实时监控的感觉非常好。
最终,我们通过并行异步加载技术和线程池机制设计出了一个精简的批处理框架。上面的代码虽然不算多,但是,有它很独特的应用场景,麻雀虽小五脏俱全。相信它对于其他的同行朋友,还是很有借鉴意义的。况且现在的服务器都是多核、多CPU的配置,我们要很好地利用这一硬件资源。对于IO密集型的应用,可以根据上面的思路,加以改良,相信一定能收到不错的效果!
好了,不知不觉地写了这么多的内容和代码。本文的前期准备、编码、调试、文章编写工作,也消耗了本人大量的脑力和精力。不过还是挺开心的,想着能把自己的一些想法通过文字的方式沉淀下来,对别人有借鉴意义,而对自己则是一种“学习和总结”。路漫漫其修远兮,吾将上下而求索。故在此,抛砖引玉。如果本人有说得不对的地方,望各位同行批评指正!不吝赐教!
作者介绍 唐洁
福建新大陆软件工程有限公司后端开发工程师,研究方向:C++/Java服务端应用、大数据、云计算
经作者同意授权转载
来源:博客园
原文链接:http://www.cnblogs.com/jietang/p/5353220.html









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721