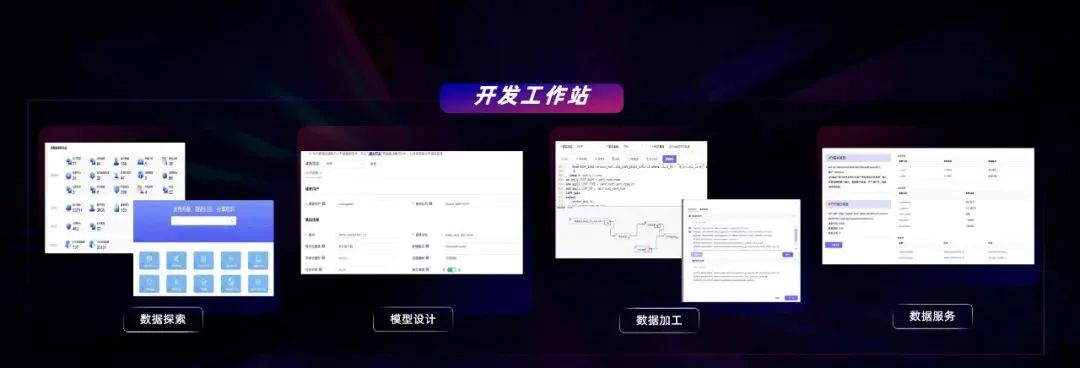
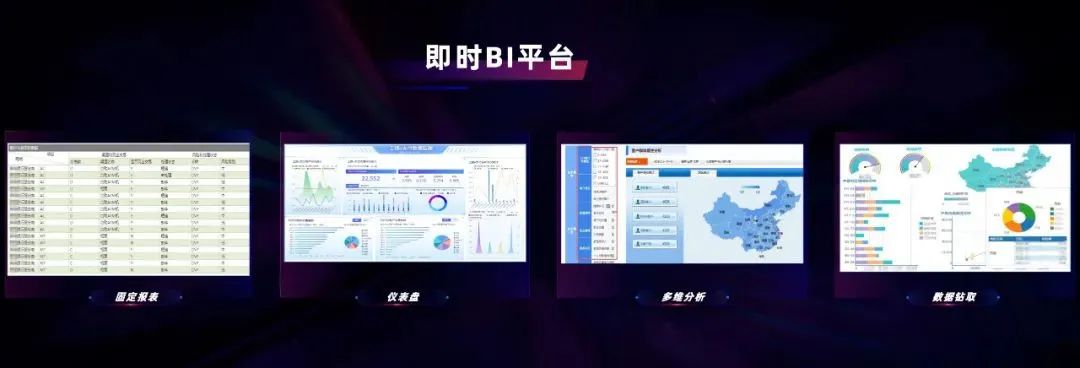
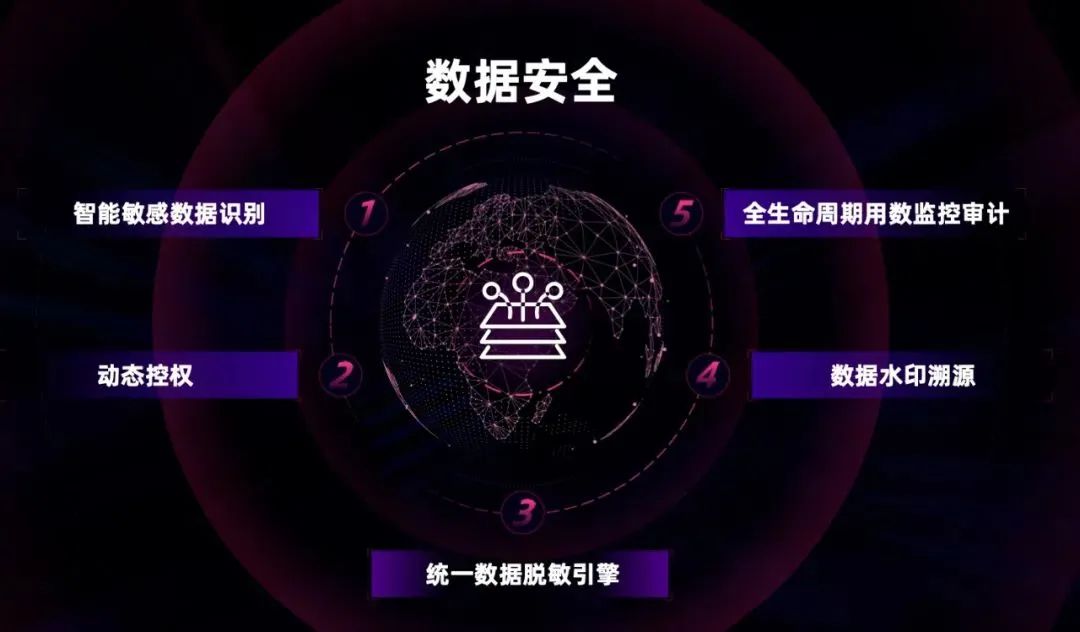
为了满足数据时效,以及企业级大规模普惠用数的诉求,企业内部的大数据平台需要不仅支持批量计算,还需要满足各类用数场景全栈覆盖的技术体系。以工行为例,大数据平台内部除批量计算之外,包含实时计算,联机分析、数据 API 等平台,主要以 Flink 作为内部引擎,用于缩短数据端到端闭环时间,形成联机高并发的访问能力,提升数据赋能业务的时效。除此之外,还包含数据交换、数据安全等面向特定技术领域的二级平台。在最上面一层,我们向开发人员、数据分析师、运维人员提供了可视化的支撑工具。
二、工行实时大数据平台建设思路
工行实时大数据平台建设思路,主要会围绕时效、易用、安全可靠和降本增效来展开。
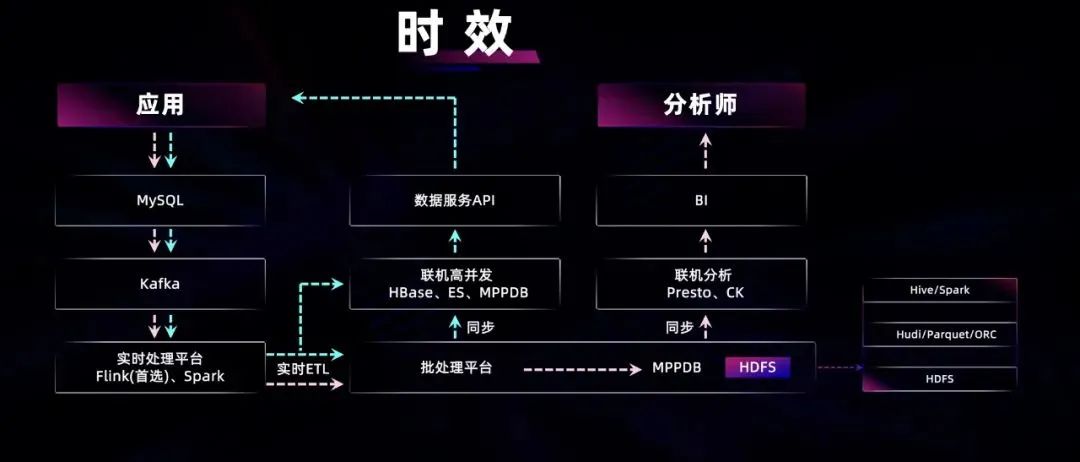
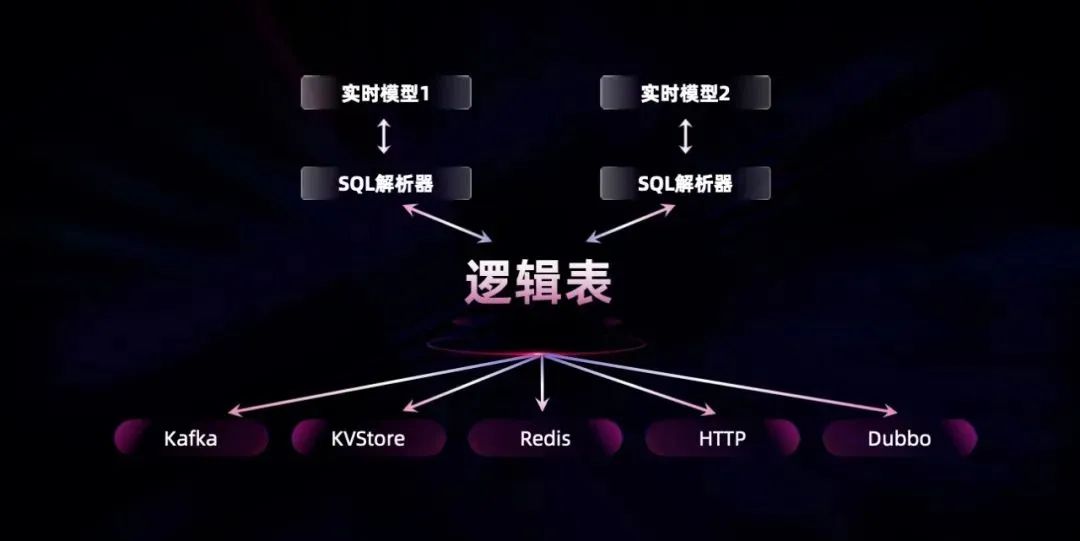
在数据时效方面,上图是描述数据流向的示意图,原始数据从左上角的应用产生,经过蓝色和粉色两条链路。其中,蓝色链路是业务视角上端到端闭坏的链路,应用产生的数据会写入 MySQL 或者 Oracle 等关系型数据库,之后通过 CDC 相关技术,将数据库产生的日志复制到 Kafka 消息队列中,将同一份数据的共享,避免多次读取数据库日志。在 Kafka 之后,是实时计算平台。实时计算平台除了实现对时效要求较高的计算处理场景之外,它还可以通过 Flink 结合 HUDI/IceBerg 等产品实现实时数据入湖。而且能将 Flink 的结果输出到 HBase\ES 等联机数据库中。将这部分数据以服务的形式暴露,即数据中台服务,从而提供给应用调用。粉色链路的数据,最终回到数据分析师那里,是蓝色链路的衍生。各个应用产生的数据,通过 Flink 和 HUDI 的实时数据入湖,通过 Presto 或 CK 等分析型引擎,供数据分析师进行 BI 分析。通过这条链路,数据时效得以提升,让分析师访问到分钟级延时的热数据,更加实时、准确地做出运营决策。一般高时效的业务场景,都包含在这条技术链路的体系之内。
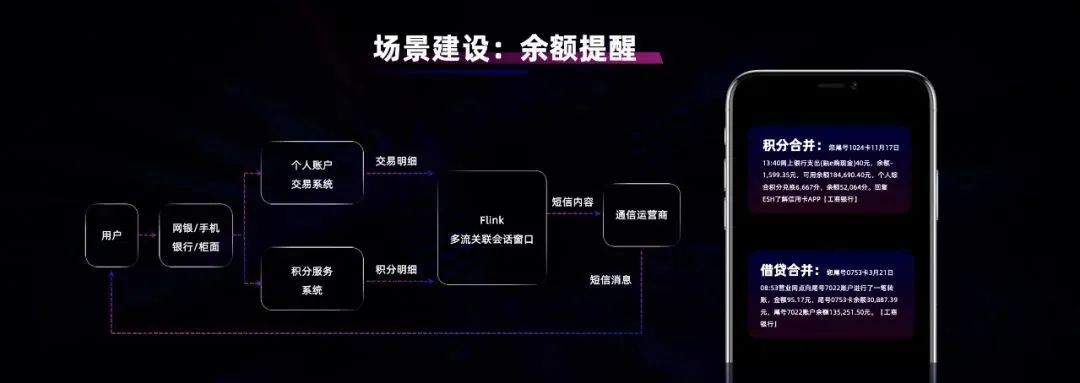
在余额变动场景,客户进行一次动账交易,可能触发多种通知内容,例如账户支出提醒、账户收入提醒、积分消费提醒等,造成客户手机连续收到短信提醒,用户体验不佳。因此,工行基于 Flink 多流合并和会话窗口的能力,将同一时刻发生的多条消息关联,将通知的逻辑合并在一起发送给客户。而当一条消息出现晚到的情况,通过会话窗口的 GAP 设置能自动降级,将逻辑分为两条消息发出去。大幅提升对用户的友好性。



















如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721