

一、微服务治理暴露出的数据存储问题
随着微服务架构在好大夫的推进,带来了诸多便利,同时服务间调用越来越复杂,也面临了一系列难题:
如何离线分析识别出不合理的服务依赖?
基于链路分析如何快速定位问题?
如何控制成本存储亿级日志数据?
如何从亿级数据里提炼分析出有价值的指标?
如何实时分析亿级数据及时触发告警?
针对长期指标如何选存储引擎?
如何聚拢不同的数据源打造友好的可视化界面?
...
运营好微服务离不开三种数据分析:Metrics,Tracing,Logging。
首先 Tracing 日志反映微服务间的链路拓扑,分析服务性能,追踪定位链路问题。也就是常说的 APM (Application Performance Management) 即应用性能管理分析。好大夫 APM 分析,是基于自研的 TraceLog 模型。
另外一类日志是服务运行时产生的 log,如 nginx,tomcat,服务自定义的日志等,好大夫服务运行时产生的日志 LocalLog 也有自己的一套规范。
Metrics 主要用于监控告警,大部分指标提炼于 Tracing 和 Logging。好大夫早期日志存储分析基于 ELK 体系,服务运行监控告警也是实时从 ES 数据源读取。APM 则是离线分析后进行数据展示。
随着业务的发展,日志在不断增加,Elasticsearch 存储压力越来越大,磁盘 IO 瓶颈逐渐显现。
另外告警项的增加,对时效性要求也越来越高,ES 实时查询压力骤增。
APM 部分场景需要实时查询,聚合,计算同比、环比等,原先的 spark 体系按不同维度离线分析的模式不再灵活,离线还带来了存储成本的骤增,分析后的数据比原始数据还要大,聚合的时间维度比较粗。不太满足实时异常定位分析。
再加上云原生的推进,产生的日志事件,传统的模式对云原生资源监控更加力不从心,从而引入了 Prometheus 体系。而 Prometheus 生态对长期持久化指标不太友好。
针对以上问题,一种主流的方案会选择拥抱大数据生态,Hadoop、Hiv、Storm、Spark、Flink 等。
二、十字路口的抉择
基于成本和应用场景考虑,我们否定了 Hadoop/Spark 解决方案!
世间没有银弹,Hadoop 体系也不例外。Hadoop/Spark 体系高度集成化,在提供了巨大的方便同时,也带来了臃肿和复杂,各种组件强强组合,有时候显得过于笨重,也带来了巨大成本。
机器资源成本 + 运维成本 + 人力成本。
Hbase/Hiv 存储基于物理机,再加上计算节点需要十多台物理机。整体部署的成本和运维成本都比较高。
再者系统架构组内成员趋向 Golang 开发,而大数据生态偏向 Java。
同时大数据部门和系统架构部分属两个不同的组织架构,根据“康威定律”,这将带来的巨大的无形沟通成本。
那有没有不依赖 Hadoop 生态体系的解决方案呢?
回到原点
其实我们更多的使用场景是:
实时性: 实时查询服务 QPS/P99
按不同维度聚合数据生成相应的指标: 服务接口维度指标,QPS/P99/错误率
长期存储数据支持降准稀疏: 服务长期趋势指标,QPM/P99/服务拓扑关系
高频大批量写入,低频查询: 亿级 TPS 日志写入,分钟级别读取
多维度列式查询:不同维度的下钻,上卷,切面,切块,旋转
数据压缩比高:吃住原先由 Elasticsearch/Prometheus 每日生成 TB 级别的日志
丰富的函数库,丰富的数据类型: 统计函数/分位数/数组函数等
原生支持分布式集群,多副本,多分区,高效的索引,丰富的引擎: 查询秒级响应
先看一下数据库全景图,数据存储种类比较丰富,关系型数据库 OLTP/OLAP,非关系型 NoSQL。有支持列式存储,有支持时序性存储等等,针对不同的应用场景,精细划分。
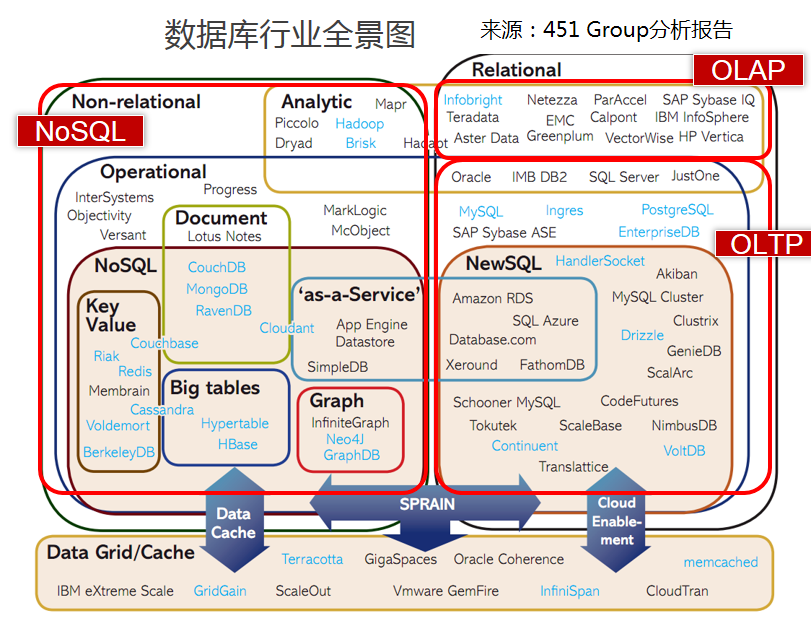
经过调研我们的应用场景是一种典型的 OLAP 模式,随着调研的深入 Clickhouse 进入视野,它高效的性能让我们感到惊叹。
在单个节点的情况下,对一张拥有 133 个字段的数据表分别在 1000 万、1 亿和 10 亿三种数据体量下执行基准测试,基准测试的范围涵盖 43 项 SQL 查询。在 1 亿数据集体量的情况下,ClickHouse 的平均响应速度是 Vertica 的 2.63 倍、InfiniDB 的 17 倍、MonetDB 的 27 倍、Hive 的 126 倍、MySQL 的 429 倍以及 Greenplum 的 10 倍。不同类型的数据库对比参考附录,这里给一个 ClickHouse 与 MySQL 性能对比图。
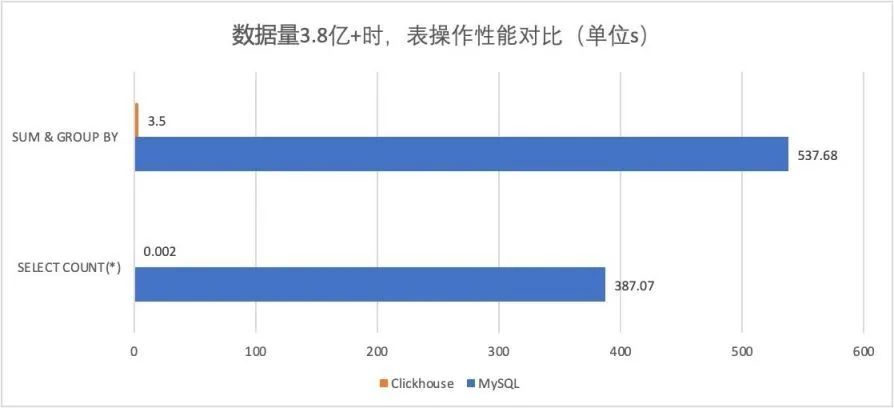
最终基于功能、性能、成本考虑,我们选择了 Clickhouse。
三、OLAP 领域的黑马
Clickhouse 是俄罗斯 yandex 公司于 2016 年开源的一个列式数据库管理系统,在 OLAP 领域像一匹黑马一样,以其超高的性能受到业界的青睐。
完备的 DBMS 功能(Database Management System,数据库管理系统)
支持 DDL/DML/权限控制/备份恢复/分布式管理等等
列式存储与数据压缩
同一列的数据往往有更高的共性,这意味着能有更高的压缩比。在 Yandex.Metrica 的生产环境中,数据总体的压缩比可以达到 8:1(未压缩前 17PB,压缩后 2PB)。列式存储除了降低 IO 和存储的压力之外,还为向量化执行做好了铺垫。
向量化引擎与 SIMD 提高了 CPU 利用率,多核多节点并行化大查询。
为了实现向量化执行,需要利用 CPU 的 SIMD 指令。SIMD 的全称是 Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在 CPU 寄存器层面实现数据的并行操作。
1)多样化的表引擎
ClickHouse 共拥有合并树、内存、文件、接口和其他 6 大类 20 多种表引,根据不同的场景选择不同的引擎,而不是开发一种引擎适配多种场景。
2)多线程与分布式
由于 SIMD 不适合用于带有较多分支判断的场景,ClickHouse 也大量使用了多线程技术以实现提速,以此和向量化执行形成互补。
3)多主架构
ClickHouse 采用 Multi-Master 多主架构,集群中的每个节点角色对等,天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
4)数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段。ClickHouse 提供了本地表(Local Table)与分布式表(Distributed Table)的概念。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
不支持事务、异步删除与更新
不适用高并发场景
ClickHouse 更适用于作为一个数据分析的数据库,它非常擅长针对于干净的,结构化的,不变的日志/事件数据进行分析。例如下述场景:
网页及 APP 分析(Web and App analytics)
广告网络以及广告投放(Advertising networks and RTB)
通信领域(Telecommunications)
在线电商以及金融(E-commerce and finance)
信息安全(Information security)
监控遥测(Monitoring and telemetry)
时序数据(Time series)
商业分析(Business intelligence)
网友(Online games)
物联网(Internet of Things)
如下场景一般不适用 ClickHouse:
事务处理[Transactional workloads (OLTP)]
高频次的 K-V 请求(Key-value requests with a high rate)
文件块存储(Blob or document storage)
过度 normalized 的数据(Over-normalized data)
四、Clickhouse 在微服务治理中的具体实战
1)选择合适的引擎
Clickhouse 有众多的数据库引擎,
MergeTree 是基础引擎,有主键索引、数据分区、数据副本、数据采样、删除和修改等功能,
ReplacingMergeTree 有了去重功能,
SummingMergeTree 有了汇总求和功能,
AggregatingMergeTree 有聚合功能,
CollapsingMergeTree 有折叠删除功能,
VersionedCollapsingMergeTree 有版本折叠功能,
GraphiteMergeTree 有压缩汇总功能。
在这些的基础上还可以叠加 Replicated 和 Distributed。
Integration 系列用于集成外部的数据源,常用的有 HADOOP,MySQL。
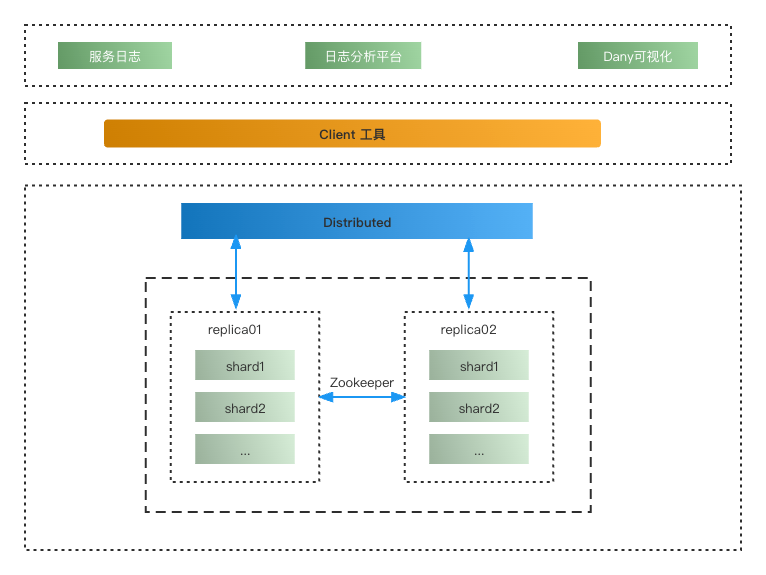
例如日志存储,目前 Es 也冗余了全量的日志,于是对 Clickhouse 存储异常有较高的容忍度。我们选取了 Distributed + MergeTree 模式,这里为了控制成本,采用多分片零副本的模式,当然为了高可用,最好还是要冗余多副本。
针对海量数据的存储,一种主流的做法就是实现 Sharding 方案。可以在客户端做 Balance,也有数据库的中间件模式。Clickhouse Distributed 表引擎就相当于 Sharding 方案中的中间件层,Distributed 表不真实存储数据,对外提供插入和查询的路由功能。
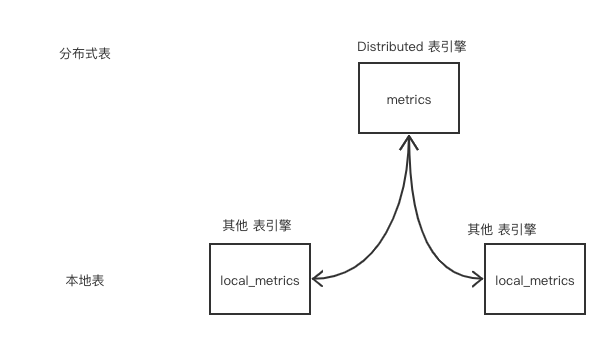
2)表名的规范
为了适配常见的 ORM 模型,本地表一般采用"local_"开头如 local_metrics,分布式表采用实际表如 metrics。当然每个公司有自己的规范,主要还是为了方便区分和使用。
3)过期时间
由于存储的是日志类型,一般具有一定的时效性,我们设置表的 TTL(Time To Live)时间,方便到期后数据自动删除。所以在建表的时候一般会带有 Timestamp 字段,一般我们是设置表级别 TTL,当然 Clickhouse 还有支持更丰富的 TTL 类型,支持数据 TTL,列 TTL。
关于 TTL 小贴士:[注 1]
TTL默认的合并频率由MergeTree的merge_with_ttl_timeout参数控制,默认86400秒,即1天。它维护的是一个专有的TTL任务队列。有别于MergeTree的常规合并任务,如果这个值被设置的过小,可能会带来性能损耗。
除了被动触发TTL合并外,也可以使用optimize命令强制触发合并。例如,触发一个分区合并:
optimize TABLE table_name
触发所有分区合并:
optimize TABLE table_name FINAL
ClickHouse目前虽然没有提供删除TTL声明的方法,但是提供了控制全局TTL合并任务的启停方法:
SYSTEM STOP/START TTL MERGES
4)分区
Clickhouse 数据分区和数据分片是两个不同的概念,数据分区是一种纵切,数据分片是一种横切。目前只有 MergeTree 类型的才支持分区策略。分区用 PARTITION BY 修饰。借助分区能提升查询性能,过滤掉不再分区的的数据。由于日志的时效性,大部分查询条件都会带上时间,所有按时间分区非常合适。但分区的粒度不能过度或者过小,当然没有区分度的字段也不能用来设置分区,一般按月或者按日来进行分区。关于分区的设置可以参考[注 3]
分区的合并过程可查看下图:
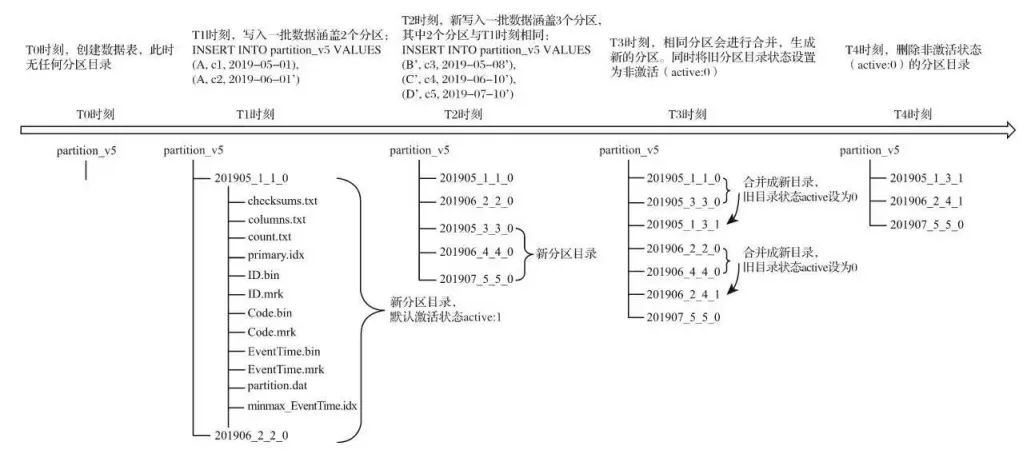
5)分片副本策略
Clickhouse 分片分区策略配置在/etc/metrika.xml 中,前面说了基于成本和容错性考虑,我们采用多分片 0 副本的策略。
<log_nshards_0replicas><shard><replica><host>clickhouse1</host><port>9000</port><user>user</user><password>password</password></replica></shard><shard><replica><host>clickhouse2</host><port>9000</port><user>user</user><password>password</password></replica></shard><log_nshards_0replicas>
由于日志类型没有很好的字段用于分片,这边采用 rand()随机划分策略,尽量让分片数据均衡。另外 Clickhouse 集群配置有个分片权重设置,权重越大,分片写入数据越多,我们在新节点加入的时候会提高权重用于均衡数据。当然了这种靠手工的运维的模式不太适合频繁的节点上下线,如果有这方面的需求可以考虑引入数据均衡的中间件。更多关于分片的数据写入的细节可以参考[注 2]。
6)索引
一级索引,PRIMARY KEY 一般用于 ORDER BY 指定,由于我们存的大部分都是日志或指标类型,从而采用 timestamp 做一级索引。
稀疏索引,MergeTree 每一行索引标记对应的是一段数据,仅需使用少量的索引标记就能够记录大量数据的区间位置信息,默认的索引粒度(8192)。由于稀疏索引占用空间小,所以 primary.idx 内的索引数据常驻内存,取用速度自然极快。
二级索引,除了一级索引之外,MergeTree 同样支持二级索引。二级索引又称跳数索引。关于索引的更多细节可以参考附录[索引]
7)参数配置
最大并发查询数 max_concurrent_queries 原则上 Clickhouse 建议查询 QPS 小于 100,但我们有按每分钟聚合查询的需求,这时候 100 就比较小了,调整 max_concurrent_queries=500,需要注意的是,关注 SQL 的执行时间及机器负载设置合理值,避免高并发的查询影响 Clickhouse 性能。
压缩比 Clickhouse 默认 lz4 压缩算法,MergeTree 引擎压缩后和 Elasticsearch 对比,存储空间大约只有后者的 1/10。更多关于压缩参考[ClickHouse 数据的压缩和原理]。
多用户支持默认 Clickhouse 安装后用户是 default,空密码,需要做修改,避免安全问题。同时按不同的 database 设置不同的用户角色。同时注意密码加密方式,我们采用 password_double_sha1_hex。另外我们为 web 可视化终端单独设置了用户,单独配置用户行为。[注释 4]
熔断机制基于用户设置 sql 最大执行时间 execution_time=5,类似 pt-kill,超过阈值会终止查询。防止查询造成 Clickhouse Server 过载。还可设置 result_rows/read_rows。为了避免内存耗尽造成异常,按需设置 max_memory_usage。[注释 5]
<web><interval><duration>3600</duration><queries>500</queries><errors>100</errors><result_rows>100</result_rows><read_rows>2000</read_rows><execution_time>5</execution_time></interval></web><web_user><password_double_sha1_hex>***</password_double_sha1_hex><networks incl="networks" replace="replace"><ip>::/0</ip></networks><profile>default</profile><quota>web</quota> // 引用用户策略<access_management>1</access_management></web_user>
8)可视化
一般采用tabix。为了支持 Prometheus,Elasticsearch,Clickhouse,我们选择 Grafana。Clickhouse-Data-Source
五、实战场景
主要功能是实时查询,目前 Clickhouse 已对接好大夫在线绝大多数原始日志数据。包括入口流量日志 KongLog,链路日志 TracingLog,业务自定义日志 LocalLog,组件及框架可用性日志如小程序日志、JS 异常日志、页面性能日志等等。
表结构示例:
CREATE TABLE {database}.{local_table} ON CLUSTER {cluster}(`date` Date,`timestamp` DateTime,...)ENGINE = MergeTreePARTITION BY dateORDER BY timestampTTL timestamp + toIntervalDay(30)SETTINGS index_granularity = 8192CREATE TABLE {database}.{table} ON CLUSTER {cluster}AS {database}.{local_table}ENGINE = Distributed({cluster}, {database}, {table}, rand())
那么基于这些原始日志就能实时监控趋势了,产品形态如图:
主要用于分析服务的性能,我们存储了 Tracing 日志,依然是 Distributed + MergeTree 模式。
Tracing 日志记录了服务的上下游服务及接口,上下游机器 ip,RPC 请求耗时,请求状态等。
这样我们就可以分析上下游细节了,如上下游 QPM,依赖接口的延迟 P99。
比如分析服务的上下游 QPM,依赖接口的延迟 p99,服务的网络延迟 P99,接口的错误率等等。
这依赖 Clickhouse 丰富的函数,常用统计函数/分位数/中位数/数组函数等等,针对大量数据还可以基于采样查询 SAMPLE BY.
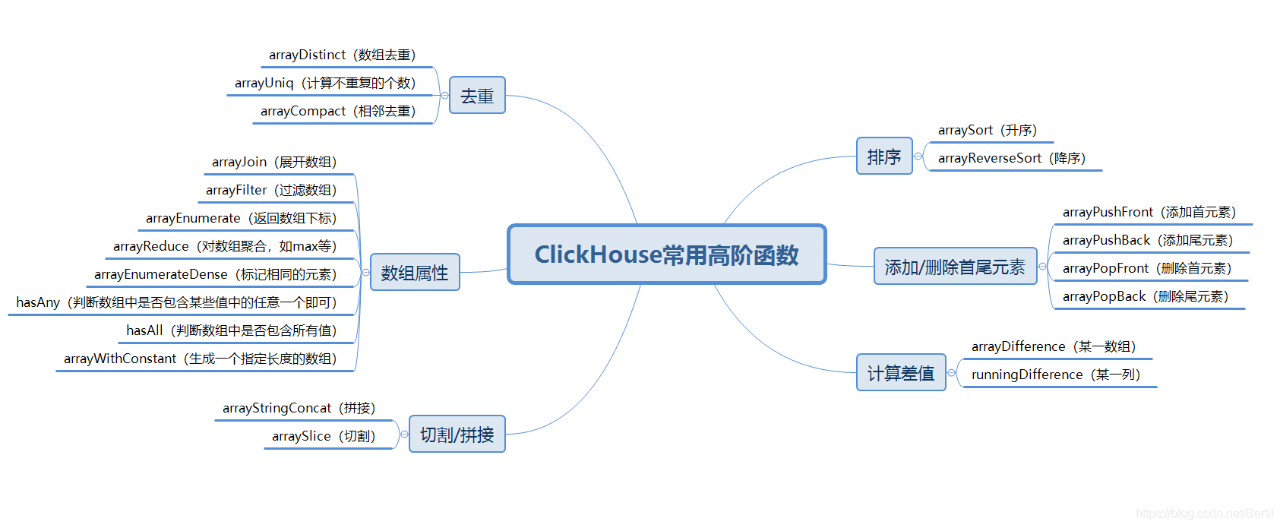
如 P99(由于延迟具有长尾效应,一般统计第 99 分位数据)
SELECT(intDiv(toUInt32(timestamp), 1) * 1) * 1000 as t,quantile(0.99)(consume) as p99FROM apm.trace_logsWHEREtimestamp >= toDateTime(1605147889)AND app_name = 'app'GROUP BYtORDER BY t
APM 常见的场景就是提供链路画像,需要按 TraceID 搜索,TraceID 类似 UUID 字符串,不具备索引区分度。每次查询都会全表扫描,如何能快速查找 TraceID 对应的链路数据呢?
# 本地表存储tracing日志CREATE TABLE apm.local_trace_logs ON CLUSTER {cluster}(`date` Date,`timestamp` DateTime,`trace_id` String, // uuid 随机32字符串...)ENGINE = MergeTreePARTITION BY dateORDER BY timestampTTL timestamp + toIntervalDay(30)SETTINGS index_granularity = 8192# 分布式表DistributedCREATE TABLE apm.trace_logs ON CLUSTER {cluster}AS apm.local_trace_logsENGINE = Distributed({cluster}, apm, trace_logs, rand())# 提取入口trace_id数据即level=1,生成物化视图,这个视图的数据只有原表的10%的量级。CREATE MATERIALIZED VIEW apm.local_entrances(`date` Date,`timestamp` DateTime,`trace_id` String,...)ENGINE = MergeTreePARTITION BY dateORDER BY timestampTTL timestamp + toIntervalDay(6)SETTINGS index_granularity = 8192 ASSELECTdate,timestamp,trace_id,...FROM apm.local_trace_logsWHERE level = '1'# Distributed 暴露给外查询的引擎CREATE TABLE apm.entrances ON CLUSTER {cluster}AS apm.local_entrancesENGINE = Distributed({cluster}, apm, entrances, rand())
统计发现这样提取后物化视图的数据只有原表的 10%了,在查询的时候,我们先从 entrances 表中查询给定的{trace_id}的数据,拿到{timestamp}、{date}后。再将{trace_id}、{timestamp±5min}、{date}带去 trace_logs 表中查询,因为 trace_logs 按 date 分区,并且有 timestamp 索引,这样就不用全部扫描了,只用查询timestamp between {timestamp-5min} and {timestamp+5min} and date = {date}的数据即可。
当然如果后续 trace_logs 数据再翻翻,我们还有优化的空间。根据前缀索引模型,我们截取 trace_id 前 n 位记作 sub_id,然后根据 sub_id 做索引,根据数据量的大小调整 n 的值,这样我们能将单次查询数据控制在一定的范围内。
如果数据量过大,还可以根据特征字段配置采样策略。
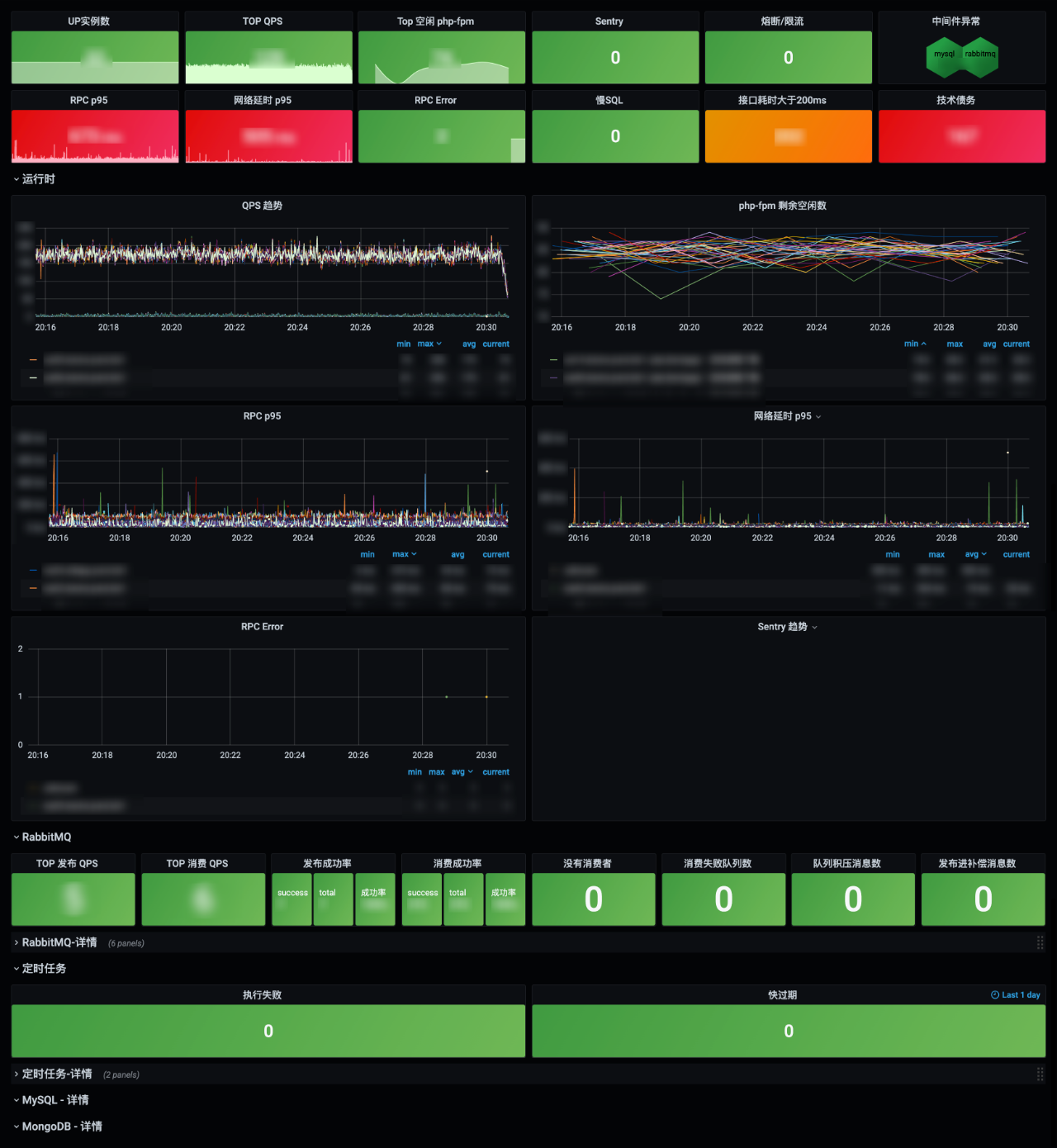
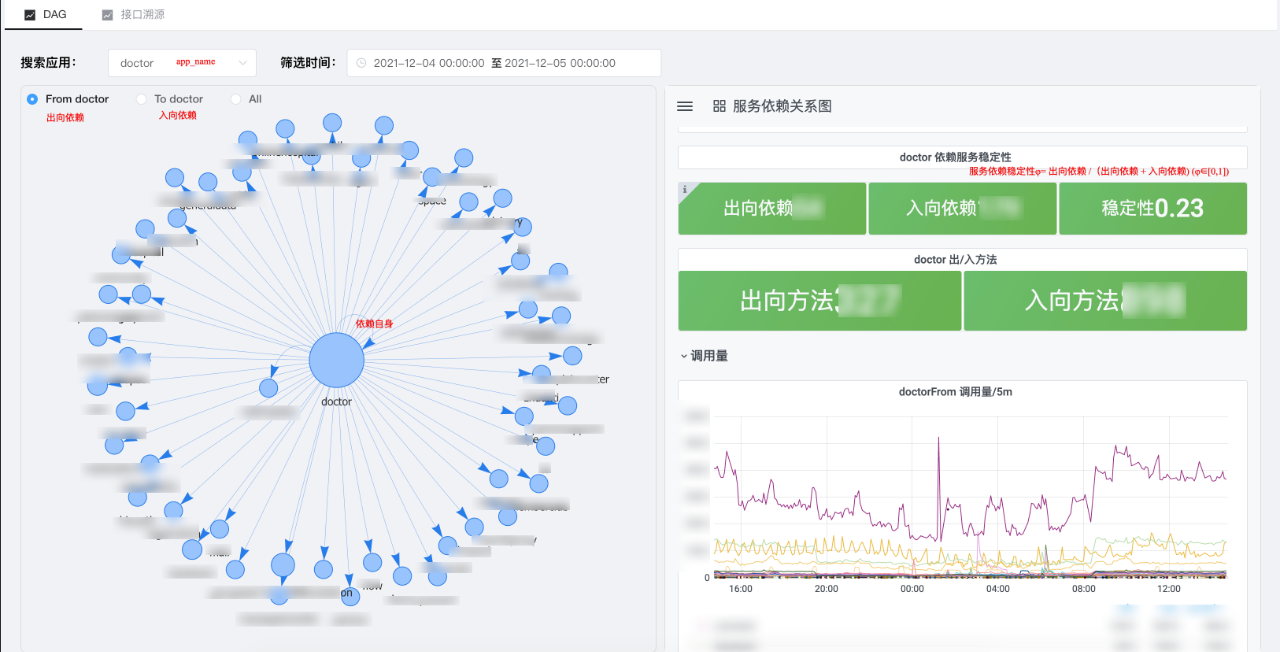
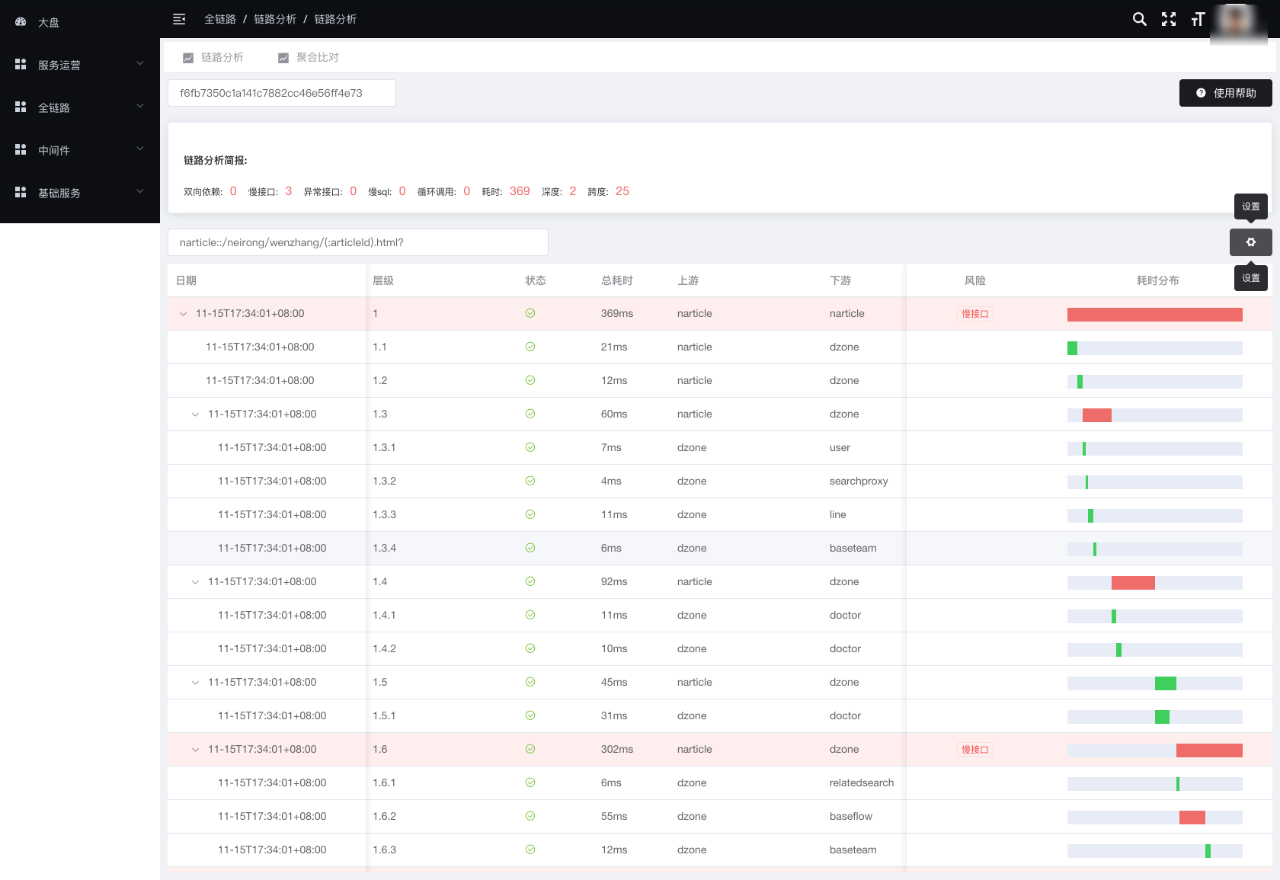
产品形态:
①运行时
②拓扑分析
③链路分析
好大夫早期的监控告警是依托于 Elasticsearch,数据可视化也是基于 Elasticsearch。随着告警项的增加,并发查询增加,导致 Elasticsearch 负载过高,无法正常提供服务,同时 Elasticsearch 写入面临磁盘 I/O 瓶颈。为了监控的高可用及时效性,我们全面迁移到 Clickhouse。
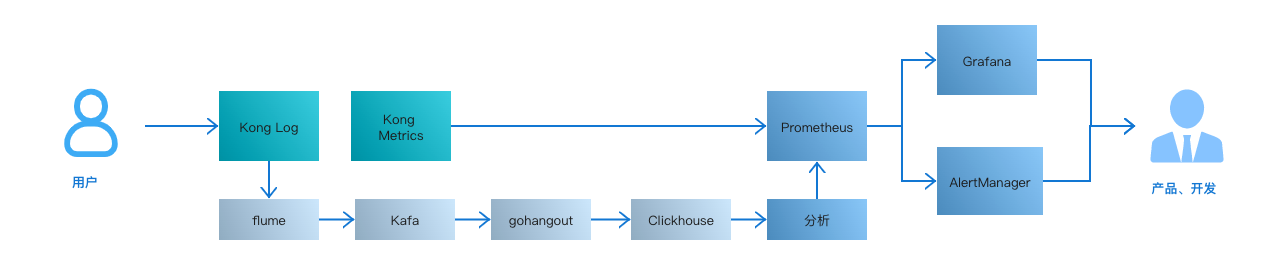
目前大约每分钟有 2000+SQL 并发执行,5s 内能分析完毕,分析后的数据按分钟聚合后存储到 Clickhouse 中。
这里采用了 GraphiteMergeTree 引擎,同理由于是临时存储,依然采用多分片零副本的分片策略。GraphiteMergeTree 类似于 Graphite 数据库,是一个图表数据库,这里我们参考 Prometheus 时序数据库的思想,将原始数据按不同的维护聚合分析后转换成 key-value 的数据类型。其中 name 为指标名,tags 为指标的多维度标签,是一个数组类型,date 用于分区,ts 指标插入时间,val 是指标的具体值是 Float64 格式,update 用于降准稀疏。
Prometheus 就可以通过 exporter 拉取这些分析后的指标,进过判定触发告警。
如 app 的 QPM 可以表示为:
date: 2021-11-25name: app_request_qpmtags: ['app_name=demo','ttl=forever']val: 336608ts: 2021-11-26 23:00:00updated: 2021-11-26 23:00:22
查询最近 5min demo 的访问量:
SELECT sum(val) as totalFROM metricsWHERE (name = 'app_request_qpm')AND has(tags, 'app_name=demo')AND date=today() and ts>now()-300
表结构
# 本地表用于存储指标CREATE TABLE apm.local_metrics ON CLUSTER {CLUSTER}(`date` Date DEFAULT toDate(0),`name` String,`tags` Array(String),`val` Float64,`ts` DateTime,`updated` DateTime DEFAULT now())ENGINE = GraphiteMergeTree('graphite_metric')PARTITION BY dateORDER BY (name, tags, ts)TTL ts + toIntervalDay(30)# 分布式表CREATE TABLE apm.metrics ON CLUSTER {CLUSTER}AS apm.local_metricsENGINE = Distributed('{CLUSTER}', 'apm', 'local_metrics', rand())
前面看到我们存储了大量的原始日志数据,也看到物化视图的威力,那还有哪些场景能使用这把利器。目前提供给业务方的自定义的日志 LocalLog,常用 event 和 app_name 来标识不同的类型。LocalLog 记录了全服务的日志,数据量级非常大,为了更好地检索数据,避免查询大表 LocalLog,我们把常用的 event 剥离出来,单独生成物化视图,从而提升查询性能。
比如为配合 Tracing 日志,我们在框架中集成了调用中间件的日志,复用了 LocalLog,记录微服务调用中间件的详情,如 mysql sql 详情,RabbitMQ 发布、消费记录等。这时我们就可以基于 event 事件分离出中间件日志单独生成视图。这类场景还有很多,比如分离出客户端慢交互数据,特定埋点的用户行为日志等。
CREATE MATERIALIZED VIEW apm.local_middleware_logs(`date` Date,`timestamp` DateTime,`trace_id` String,`event` String,...)ENGINE = MergeTreePARTITION BY dateORDER BY timestampTTL timestamp + toIntervalDay(6)SETTINGS index_granularity = 8192 ASSELECTdate,timestamp,trace_id,event,...FROM apm.local_biz_logsWHERE event in ('mysql','rabbitmq'...)CREATE TABLE apm.middleware_logs ON CLUSTER {cluster}AS apm.local_middleware_logsENGINE = Distributed({cluster}, apm, middleware_logs, rand())
前面我们存储了基于原始日志分析后等到聚合指标 metrics,有些数据需要长期存储,比如存储一个 Q,一年等。如微服务的 QPM,P99 需要永久存储,方便从长期时间维度查看趋势,从而评估服务整体健康度演化趋势。我们可以对感兴趣的 metrics 打上 tags TTL="forever"。这样我们设置 local_view_metrics 的引擎策略 GraphiteMergeTree roll_up 上卷模式,graphite_metric_view。按不同的策略对同名指标包含相同 tags 的数据进行降准稀疏,<=7d 内存储原始指标,7d~30d 按小时进行上卷,>30d 按天进行上卷,上卷的策略有 sum/avg/min/max 等。
# 物化视图 提取特定tags的指标CREATE MATERIALIZED VIEW apm.local_view_metrics ON CLUSTER {CLUSTER}(`date` Date DEFAULT toDate(0),`name` String,`tags` Array(String),`val` Float64,`ts` DateTime,`updated` DateTime DEFAULT now())ENGINE = GraphiteMergeTree('graphite_metric_view')PARTITION BY dateORDER BY (name, tags, ts)SETTINGS index_granularity = 8192 ASSELECTdate,name,tags,val,ts,updatedFROM apm.local_metricsWHERE has(tags, 'ttl=forever') = 1CREATE TABLE apm.view_metrics ON CLUSTER {CLUSTER}AS apm.local_view_metricsENGINE = Distributed('{cluster}', 'apm', 'local_view_metrics', rand())# graphite_metric_view 配置策略<graphite_metric_view><path_column_name>tags</path_column_name><time_column_name>ts</time_column_name><value_column_name>val</value_column_name><version_column_name>updated</version_column_name><default><function>avg</function><retention><age>0</age><precision>30</precision></retention><retention><age>604800</age><precision>3600</precision></retention><retention><age>2592000</age><precision>86400</precision></retention></default><pattern><regexp>rollup_sum</regexp><function>sum</function><retention><age>0</age><precision>30</precision></retention><retention><age>604800</age><precision>3600</precision></retention><retention><age>2592000</age><precision>86400</precision></retention></pattern>...</graphite_metric_view>
随着监控体系向云原生靠拢,我们整体也是采用了 Prometheus。但是 Prometheus 官方并没有提供长期数据持久化的方案,但有些业务指标需要长期存储。我们采用本地存储 15d+远程存储的模式。远程存储采用 CLickhouse,这也是进过对比后选定的,业内也有选择 InfluxDB,但社区版的 InfluxDB 不支持集群模式,加上引入新的 DB 产生的运维成本,最终还是选择了 Clickhouse,毕竟有一定的经验积累了。
我们自研了 Prometheus2CLickhouse_adapter,将数据从 Prometheus 同步到 CLickhouse。有兴趣的同学可以查看源码,目前已经开源到 GitHub remote_storage_adapter:https://github.com/weetime/remote_storage_adapter。
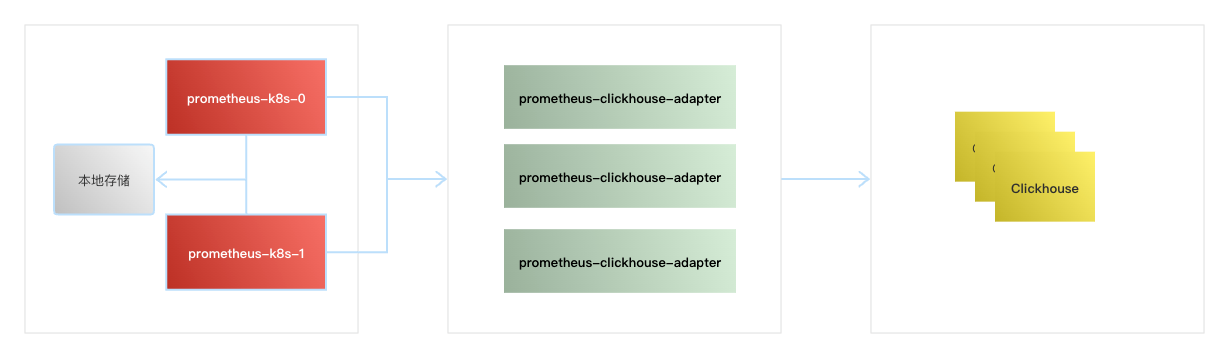
目前有一个业务方对接了 Clickhouse,主要场景是多方向聚合数据,然后按不同的维度检索数据。一开始考虑 Mysql/MongoDB,都有性能瓶颈问题,千万级数据查询可能会到大于 10s。改用 Clickhouse 后查询在 200ms 内。由于业务数据需要高可用,数据不可丢失,这里采用了三分片一副本的策略。准备了 6 个节点,ck1~6。类似于 RedisCluster 模式,实现两两备份。
另外为了提升写入性能,我们设置了异步同步模式 internal_replication=true,Distributed 表在该 shard 中只会选择一个合适的 replica,并写入数据,多 replica 副本间的数据复制则交给本地表引擎如 ReplicatedMergeTree。
集群配置
# 分片副本<nshards_1replicas><shard><internal_replication>true</internal_replication><replica><host>clickhouse1</host><port>9000</port><user>user</user><password>password</password></replica><replica><host>clickhouse4</host><port>9000</port><user>user</user><password>password</password></replica></shard>...<nshards_1replicas># 变量用于建表时的占位符,策略将存在zookeeper中.<macros><layer>02</layer><shard>01</shard><replica>ck2-01-01</replica></macros>
表结构
CREATE TABLE default.local_tests ON CLUSTER nshards_1replicas(`id` Int64,`diseaseid` Int64,`ctime` DateTime,...)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/local_tests', '{replica}')PARTITION BY toYYYYMMDD(ctime)ORDER BY (ctime, diseaseid)TTL ctime + toIntervalDay(7)SETTINGS index_granularity = 8192CREATE TABLE default.tests ON CLUSTER nshards_1replicasAS {database}.local_testsENGINE = Distributed(nshards_1replicas, default, tests, rand())
六、展望
Clickhouse 管理平台的演进由于 Clickhouse 迭代升级非常频繁,每个月会更新一版,但是部署运维偏向手动。故障转移,参数配置等运维成本较高。做好权限控制,将集群下发给业务方使用。为了高可用及稳定性,后续会向 PaaS 平台演进。
拓宽 Clickhouse 使用场景,对接更多的业务方需求。
减少 Clickhouse 黑盒模式,要知其然知其所以然,加深对 Clickhouse 的深入研究。
提升 Clickhouse 中间件的稳定性,借助混沌工程思想,做好周期性故障演练。
七、小结
在大数据时代,人人都是数据分析师,OLAP 也一直在进化,适应着时代的发展。当下微服务治理产生的数据也越来越大,为了辅助开发更好的治理服务,OLAP 数据库发挥着越来越重要的作用。尤其是实时查询,不同的人关注的不同的维度,通过上卷,下钻及时定位异常问题。今天我们一起探讨了 Clickhouse 在微服务治理中发挥的作用,后续我们一起发掘更多的应用场景,期待大家共同讨论。
参考资料
docs What Is ClickHouse?
https://clickhouse.com/docs/en/
clickhouse vs elasticsearch benchmark
https://www.alibabacloud.com/blog/clickhouse-vs--elasticsearch_597898
clickhouse vs mysql benchmark
http://mmedojevic.com/2020/03/09/clickhouse-vs-mysql/
Performance comparison of analytical DBMS
https://clickhouse.com/benchmark/dbms/
索引 朱凯著.ClickHouse 原理解析与应用实践.机械工业出版社华章分社.2020:215.
[注 1] TTL朱凯著.ClickHouse 原理解析与应用实践.机械工业出版社华章分社.2020:255.
[注 2] 分片写入核心流程 朱凯著.ClickHouse 原理解析与应用实践.机械工业出版社华章分社.2020:473.]
[注 3] 数据的分区规则朱凯著.ClickHouse 原理解析与应用实践.机械工业出版社华章分社.2020:208.
[注释 4] 用户配置
https://clickhouse.com/docs/en/operations/settings/settings-users/
[注释 5] 配额
https://clickhouse.com/docs/en/operations/quotas/
ClickHouse数据的压缩和原理
https://blog.csdn.net/weixin_43975771/article/details/115861032








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721