
林德智,网易云音乐消息队列负责人,具有多年分布式消息系统等中间件架构设计及研发经验,对分布式系统有较深刻理解。目前负责云音乐消息队列及云音乐部分稳定性性能相关工作。
本文大纲:
消息队列改造背景
业务对消息队列的要求
架构设计
部分高级特性
落地使用情况
未来规划
背景
网易云音乐从13年4月上线以来,业务和用户突飞猛进。后台技术也从传统的 Tomcat 集群到分布式微服务快速演进和迭代,在业务的不断催生下,诞生了云音乐的 RPC,API 网关和链路跟踪等多种服务,消息队列也从 RabbitMQ 集群迁移到 Kafka集群。
对于消息队列,更多处于使用阶段,也在使用中出现很多问题。因此我们期望提供一种完全可控,出现问题我们自己能排查,能跟踪,可以根据业务需求做定制改造的消息队列。
调研结果:

RabbitMQ 由于持久化场景下的吞吐量只有2.6万,不能满足我们业务吞吐量的需求,云音乐在 2017 年将消息队列从 RabbitMQ 迁移到 Kafka 也是这个原因,因此不再考虑范围之内。由于云音乐整体业务的 QPS 较高,因此,ActiveMQ 也不在考虑范围。
这里主要对比 RocketMQ 与 Kafka:

Kafka 更偏向大数据,日志处理,缺少死信,消费失败自动重试,事务消息,定时消息,消息过滤,广播消息等特性,另外 Kafka 没有同步刷盘。
云音乐的业务更偏向于多 Topic,死信可溯源,消费失败可收敛自动重试,高可用,自动 Failover 等特性。对于商城和社交业务来说,事物,顺序 Topic 使用会比较多。
「Kafka和RocketMQ对比」参考链接:http://jm.taobao.org/2016/03/24/rmq-vs-kafka
经过 RabbitMQ,Kafka 和 RocketMQ( ActiveMQ 性能较差,暂不考虑)的调研和分析后,我们发现 RocketMQ 比较适合云音乐的通用业务,但是开源 RocketMQ 也有一些缺陷,只有我们解决了这些缺陷才能在业务中大规模使用。
开源 RocketMQ 的基本架构如下:(基本介绍参考)

开源 RocketMQ 主要问题有:
Broker 仅提供了 Master 到 Slave 的复制,没有 Failover 切换的能力;
事务消息不开源(我们开始研发时不开源);
消息发送消费无追踪(我们开始研发时不开源);
没有告警与监控体系;
开源控制台不完善。
云音乐业务对消息队列的要求

我们期望消息队列具备宕机 Failover 能力,根据不同业务场景提供不同 QOS 能力,如商城消息不能丢失,交易事务消息支持,消息发送消费追踪,失败排查等能力。
同时对业务比较关心的发送耗时、消费耗时、消费延迟、消费失败异常等提供监控和告警能力。对运维比较关心的整体运行水位和各项指标提供监控大盘,以及排查发现消息队列自身问题与长期运维能力。
另外云音乐少部分业务是 Nodejs 和 Python 的,我们提供 HTTP 协议接入能力。
架构设计
整体架构如下:
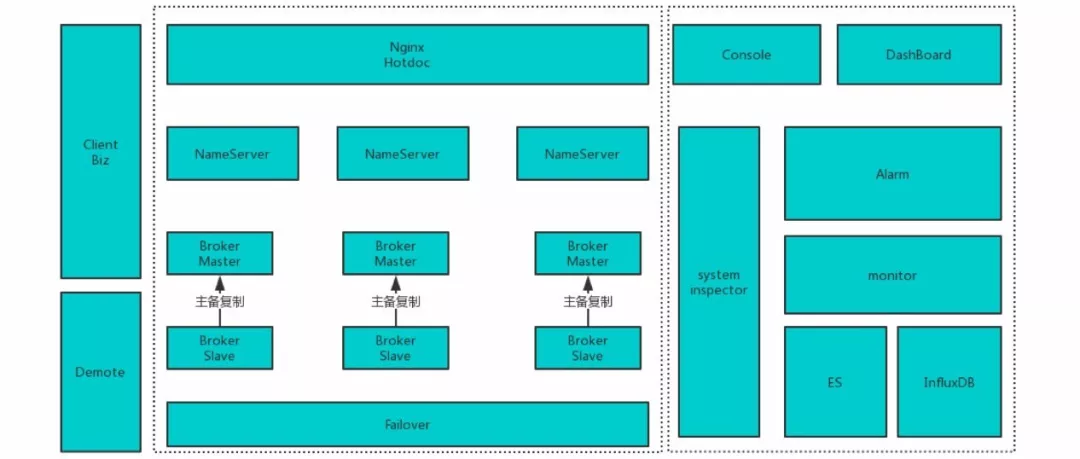
以开源 RocketMQ 为内核,完全继承开源 RocketMQ 具备的特性。为满足高可用,我们增加了 failover 组件,对 broker 进行健康检查提供快速切换能力。其中nginx 的 hotdoc 在开源 RocketMQ 里面是个 jmenv,这一块直接使用。
对于业务开发关心的监控,我们修改客户端,把耗时、异常等数据采用系统消息方式上报,由 Monitor 组件消费消息并写入 ES,并提供控制台查询能力。
同时客户端上报的数据,Alarm 也会消费一份,根据业务配置的监控项检查告警,超出阀值直接发出告警。
另外消息系统也会出现宕机,宕机选主也有一段时间(秒级),虽然客户端有重试能力,但是有些场景不能很好满足。
因此,消息队列提供了降级组件,在系统异常时,客户端会将消息发送本地或者发送到容灾集群,降低系统宕机时对业务的影响。
对于运维比较关心的系统巡检,我们提供系统巡检能力,将系统比较关键的状态定时巡检,异常则快速发出告警。
对于运维比较关心的整体大盘,我们在 Monitor 组件中加入系统数据采集,将数据写入 Influxdb,提供以 Grafana 为前端的 dashboard。
另外我们也提供控制台资源管控能力,将 Topic、ProducerGroup、ConsumerGroup以及上下游应用关联并管控起来。
各组件交互流程如下:
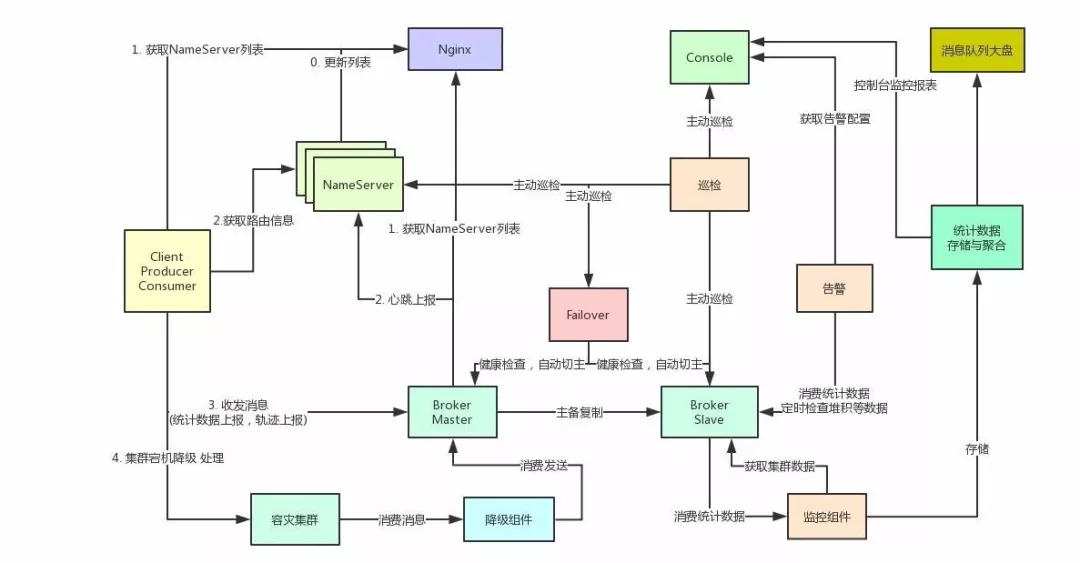
① NameServer 提供 topic 路由信息发现、配置中心能力。
② Broker 提供 topic 消息存储、索引、查询。同时 Broker 自身提供 HA 需要的复制、角色修改、探活、状态获取等 API。同时 Broker 定时向所有Nameserver 注册。
③ Nginx 提供发现 NameServer 能力,由运维将 nameserver 列表填写到hotdoc 中。避免 NameServer 变更业务重新配置上线。
④ 降级组件提供消息发送失败的处理,在消息发送失败的情况下 client 会将消息发送到容灾集群,由降级组件统一处理保证发送方业务的稳定性。
⑤ Failover 组件检查 Broker 状态,Broker 宕机根据 QOS 要求切主。
⑥ Console 提供资源管控、消息查询、轨迹跟踪、监控报表、监控告警配置、死信重投等能力。
⑦ 巡检组件巡检消息队列自身集群所有组件健康与服务状态,有异常提前通知运维和消息队列相关人员。
⑧ 监控组件提供监控报表数据采集处理、消息队列大盘数据采集处理。
⑨ 告警组件主要采集告警信息,根据控制台配置的告警阀值和人员信息通知相应业务方。
⑩ 消息队列大盘提供消息队列集群自身的监控状态、主备复制状态、QPS等集群大盘报表展示。
部分高级特性介绍
这部分是云音乐根据自己业务的需求,对开源的修改和扩充。我们对开源 RocketMQ 的改动较多,由于篇幅的关系,这里仅介绍这几个特性,如 HTTP 协议实现和秒级延迟、高可用等这里不做介绍,有兴趣的同学可以交流。
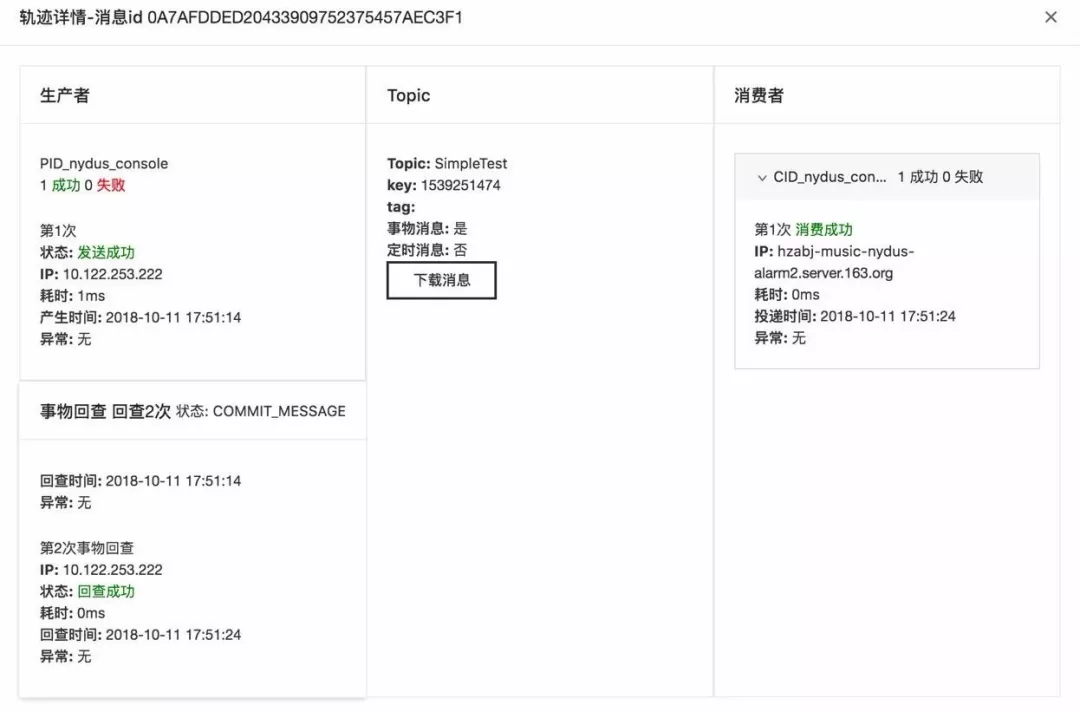
这个特性和开源4.4中提供的消息轨迹实现机制一样。和开源不同的是,云音乐消息队列提供发送消费、事物消息回查轨迹,同时消费失败时,也在轨迹中提供失败异常信息,这样就能够追踪失败原因。
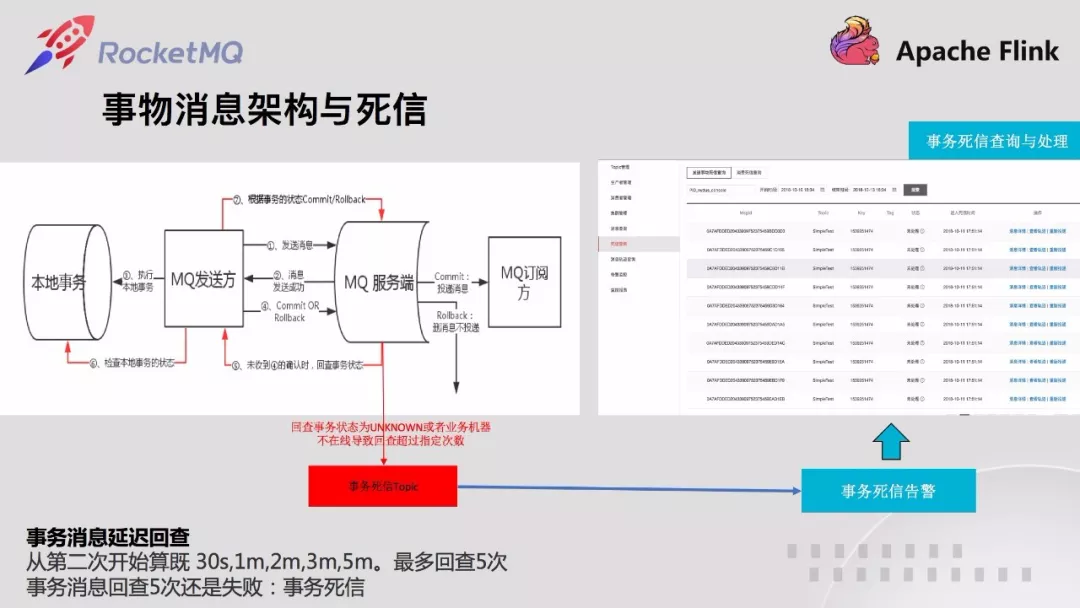
这个特性和开源4.4中提供的消息轨迹实现机制一样。和开源不同的是,云音乐消息队列提供发送消费、事物消息回查轨迹,同时消费失败时,也在轨迹中提供失败异常信息,这样就能够追踪失败原因。
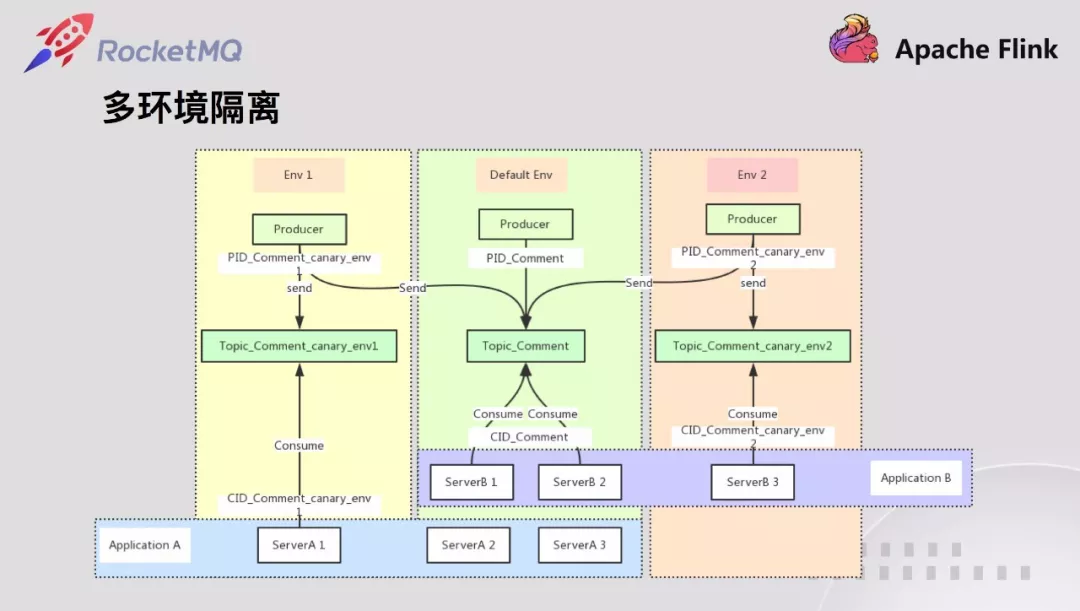
云音乐有很多条业务线,每条业务线都有很多个需求在做,同时各个业务线之间的访问都是通过服务化的方式进行。为提升开发和测试效率,通过对 RPC 流量打标的方式将流量隔离到相应环境,并一路透传下去。
消息也一样,同一个需求发送的消息需要相应的环境开发,测试,和其他互不影响。因此云音乐设计实现了消息队列的隔离,加快业务开发测试,预发快速验证能力。

开源 RocketMQ 消费端仅有一个消费线程池,多个 topic 的消费会互相影响。另外同一个消费端仅有一个 listener,如果是多个 topic,需要上层业务分发。
云音乐同一个应用都会有多个 topic 消费,有的多达 30+个。因此优先级高的 topic 需要自定义自己的消费线程池,优先级低的使用公共的。另外,每个 topic 也要有自己的 listener,这样就不用上层分发。基于上述要求,我们增加订阅可以同时指定 listener 和 consumeThreadExecutor 的方式。
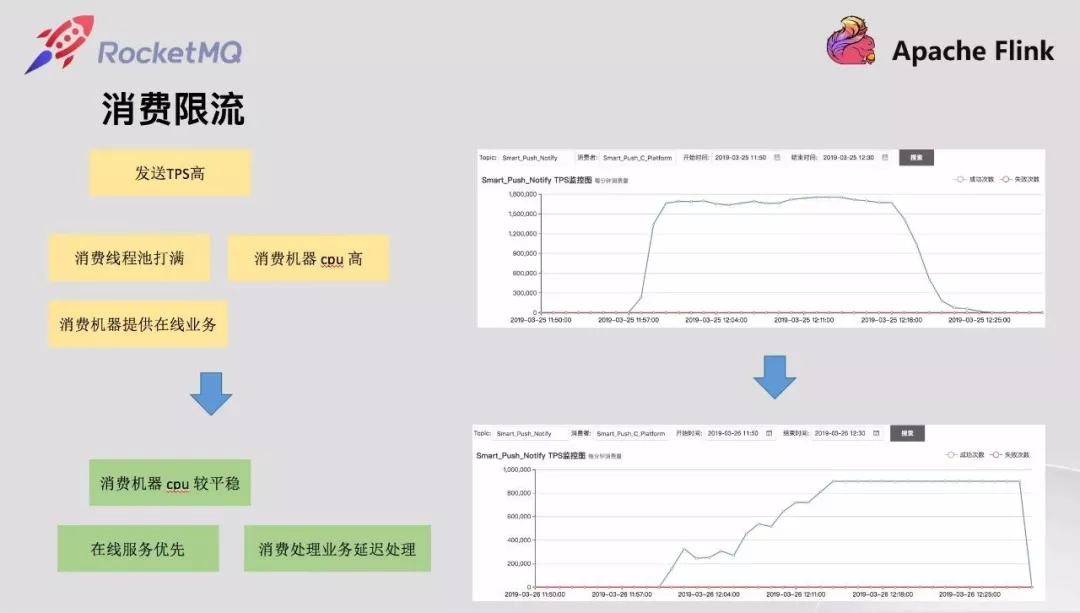
开源 RocketMQ 并没有提供消费限流能力,基于 Sentinel 的是 pull 模式,而不是 push 模式,不能很好满足云音乐的业务需求。
云音乐的消息消费不少都要写数据库或者访问第三方,这些消费和在线业务都是同一个应用,消息队列自身虽然具备削峰填谷的能力,但是消费端会最大化使用消费线程池,这会对在线业务也产生影响。为保证在线业务优先,需要限制消费的速度,减少瞬时高峰消息消费对在线业务的影响。
这部分可以通过调整消费线程池和消费 qps 来调整。我们选择了调整消费 qps消费限流的方式,这样能和监控数据对起来并提供控制台动态调整能力,消费线程池调整虽然我们也提供动态调整线程池能力但是并不是线性的,调整起来没有参考,比较困难。
消费限流做在了底层而不是让应用层自己做,和上层的区别时,上层限流了会触发消息消费一次并且失败,底层不会失败也不算消费一次,因为还没投递上层业务。
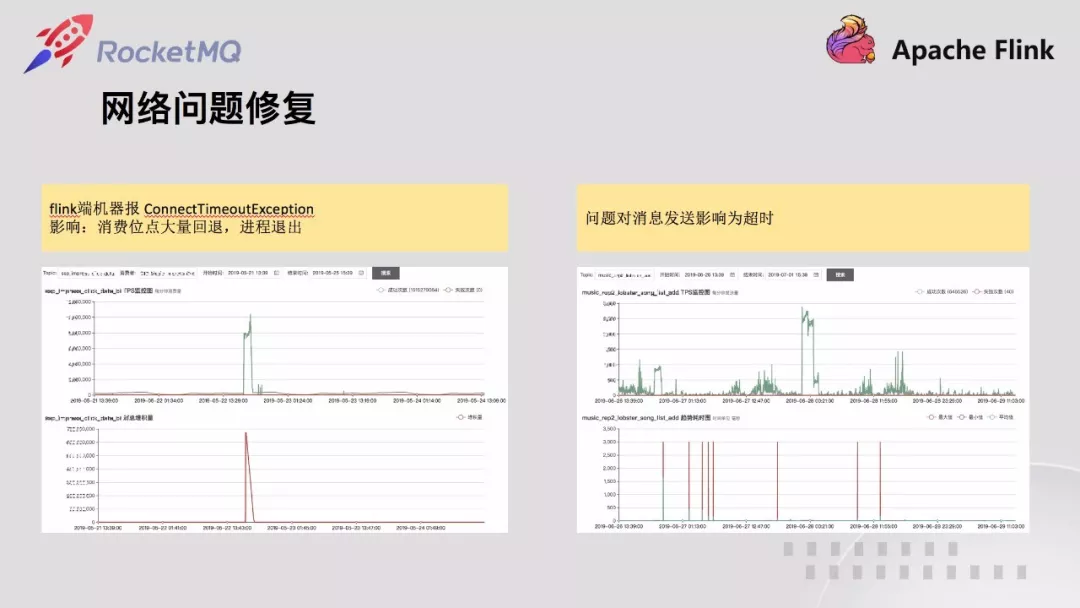
云音乐有部分业务部署在建德,需要消费杭州的数据。这部分消费的机器总是隔三差五报 timeout。经过排查,发现 client 新建的连接总是在关闭创建循环,非常不稳定,这部分排查 remoting 层的代码发现 client 建立连接存在并发问题,会将建立好的链接关闭。定位待开源 client 的 remoting bug 后,我们进行了修复。
另外后来几天,曲库的业务同学也报发送 3s 超时,经过仔细排查,发现异常日志和连接建立日志和网络建立并发问题的日志一致,协同业务升级到最新修复的客户端解决。业务升级上线后如上所示,发送非常平稳,不再超时。
作为开源的受益者,部分改动我们会提交到 Apache RocketMQ 官方,如消费限流,消费线程池,网络 bug 修复等。
消息队列在云音乐的使用情况
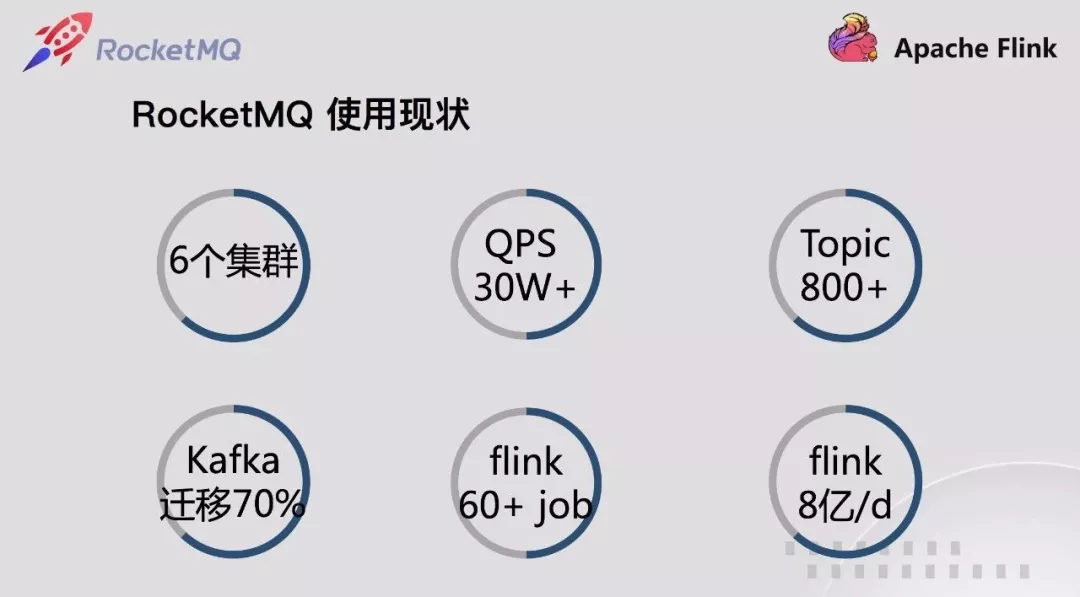
截止目前为止,基于 RocketMQ 改造实现的消息队列在网易云音乐生产环境已经有 6 个集群。涉及顺序消息,普通消息,多种高可用高可靠要求。
接入应用数量200+,每条业务线核心业务都有涉及。峰值 QPS 已达 30w+,topic 800+。在测试环境单个集群,由于环境很多,Topic 数量也疯长,单个达到 4000+,未来随着 kafka迁移的更多,Topic 数量还会不断上涨。
从 2018 年 11 月开始,云音乐 Kafka 禁止在线业务接入,新的全部使用 RocketMQ,另外 2019 Q1 开始组织协调业务,将在线业务以前使用 Kafka 的迁移到 RocketMQ,截止目前,已经迁移 70%+,业务整体稳定性得到极大提升。
随着业务接入 RocketMQ 的增多,也不断催生下游大数据生态的接入和使用。云音乐大数据主要使用 flink,目前 flink 在运行 job 60+,其中 RocketMQ 消息量每天达8亿+,这一块未来还有不少增长空间。
未来规划与展望
目前云音乐消息队列的特性已经很多,并且能够很好的满足业务的需求。从核心歌单、曲库业务到 QPS 很高的 push 业务,但在日志方面还未涉及。
涉及到日志传输开源 RocketMQ 有部分性能问题,需要做优化,目前我们已经完成这部分优化,由于优先级的关系,还没推广到日志传输相关应用。
我们期望云音乐的消息队列能够拓展到日志方面,将消息队列具备的完善监控告警等能力赋能到大数据,NDC 订阅(数据库更新订阅服务)。同时增加路由能力减少多机房间跨机房访问。
另外,消息队列 RocketMQ 在整个网易除云音乐外并没有其他大产品在使用,未来我们会联合杭研,将消息队列推广到其他大产品线,将云音乐对消息队列的改进和特性普惠到其他大产品。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721