
作者介绍
小火牛,项目管理高级工程师,具有多年大数据平台运维管理及开发优化经验。管理过多个上千节点集群,擅长对外多租户平台的维护开发。信科院大数据性能测试、功能测试主力,大厂PK获得双项第一。
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的、可划分的、冗余备份的、持久性的日志服务。它主要用于处理活跃的流式数据。分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
消息持久化及其缓存
磁盘性能:在传统的磁盘写入很慢,因为它使用随机写入50k/s(6个7200转的sata硬盘组成的raid-5),但是线性写入速度有300ms/s的速度,所以Kafka利用线性写入的方式。
线性写入:将数据调用操作系统文件接口写到文件系统里面去这样就缓存到操作系统的页面缓存中,然后传统意思来说将其flush一下到磁盘中,但是Kafka并没有这样,而是保存在页面缓存中(相当于放在内存当中)并没有进行flush操作,这样他就会提供比较高的读的性能,下次读就从内核页面缓存中读数据,但是内存中存储数量不是无限大的,所以我们配置参数(每当接收到N条信息或者每过M秒),进行一个flush操作,从而可以为系统硬件崩溃时“处于危险之中”的数据在量上加个上限。
Kafka的缓存不是在内存中保存尽可能多的数据并在需要时将这些数刷新到文件系统,而是做完全相反的事情,将所有的数据立即写入文件系统中的持久化的日志中,但不进行刷新数据的调用,实际这么做意味着数据被传输到os内核的页面缓存中去了,随后在根据配置刷新到硬盘。
安装优化主要修改config目录下的server.properties文件,需要修改的参数值主要有 broker.id、host.name、log.dirs。
brokerid是对Kafka集群各个节点的一个标识,比如xx.xxx.xx.1 当做节点一,则brokerid=1;xx.xxx.xx.2 当做节点二,则brokerid=2 ;host.name需要配置的是本机ip或者主机名映射。如下图:
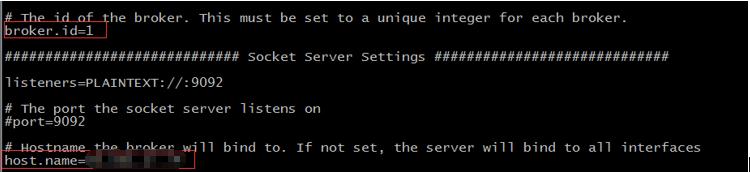
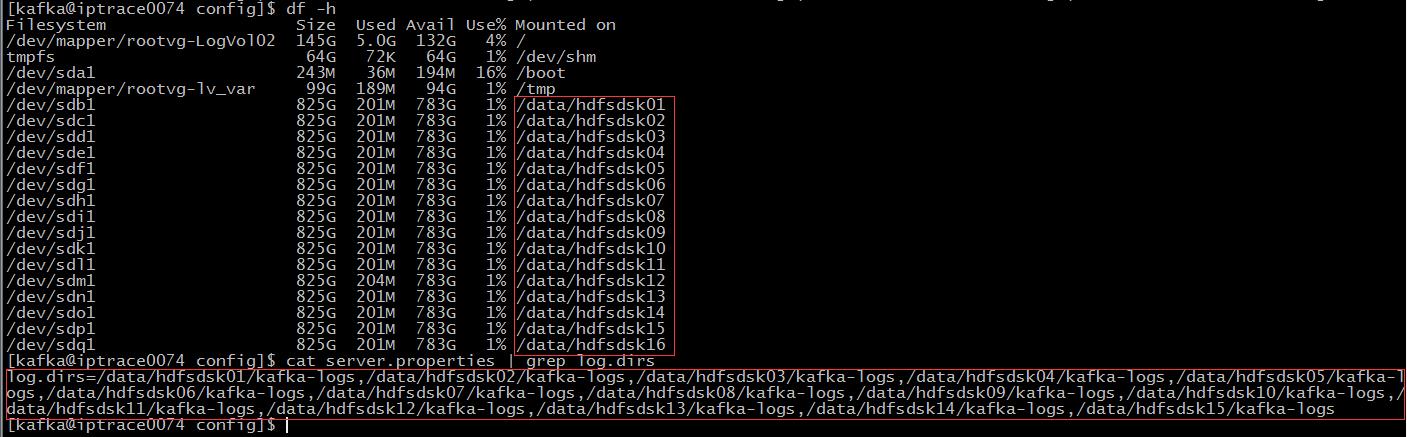
log.dirs是配置Kafka数据日志的本地磁盘。
生产集群中,我们还需要配置Kafka进程的启动内存,通过配置kafka-server-start.sh,分配10g内存,5g初始化内存。如下图:
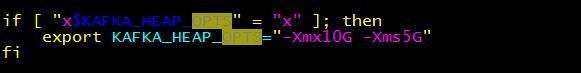
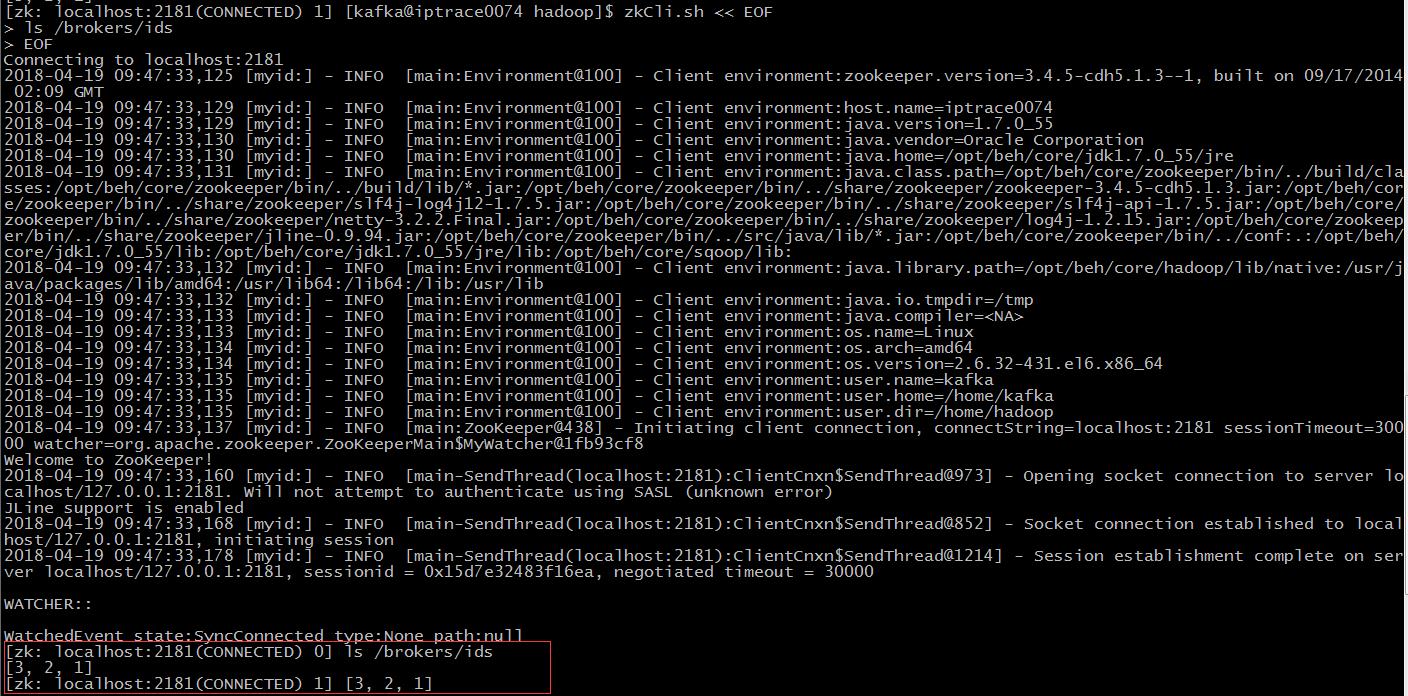
启动Kafka集群并检查zk路径上Kafka节点是否全部上线。
以下为实际生产集群Kafka优化配置项,标红部分为权限控制配置,后续会有专门一章来描述。
下面两个参数,如果在生产集群中写死了无法批量修改配置。
broker.id=2
listeners=SASL_PLAINTEXT://hosip:9092
可以按如下配置,将自动生成brokeid,自动识别host.name。
#broker.id=2
listeners=SASL_PLAINTEXT://:9092
zookeeper.connect=zkip1:2181,zkip2:2181,zkip3:2181/kafka
# Timeout in ms for connecting to zookeeper
delete.topic.enable=true
zookeeper.connection.timeout.ms=60000
zookeeper.session.timeout.ms=60000
controlled.shutdown.enable=true
#很重要
unclean.leader.election.enable=true
auto.create.topics.enable=false
#副本拉取线程数
num.replica.fetchers=4
auto.leader.rebalance.enable=true
leader.imbalance.per.broker.percentage=10
leader.imbalance.check.interval.seconds=3600
#副本拉取的最小大小1mb
replica.fetch.min.bytes=1
#副本拉取的最大大小20mb
replica.fetch.max.bytes=20971520
#多长时间拉取一次副本
replica.fetch.wait.max.ms=500
#超过多长时间副本退出isr
replica.socket.timeout.ms=60000
#replica.fetch.wait.max.ms=1000
#缓存大小
replica.socket.receive.buffer.bytes=131072
num.network.threads=7
num.io.threads=13
#每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
#每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
socket.receive.buffer.bytes=1048576
socket.send.buffer.bytes=1048576
queued.max.requests=10000
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
allow.everyone.if.no.acl.found=false
super.users=User:admin
authorizer.class.name = kafka.security.auth.SimpleAclAuthorizer
security.inter.broker.protocol=SASL_PLAINTEXT
启动Kafka进程:
nohup kafka-server-start.sh /usr/local/kafka/config/server.properties >/dev/null 2>&1 & 注意
创建主题:
$KAFKA_HOME/bin/kafka-topics.sh --create --topic logstash-yarnnodelog --replication-factor 3 --partitions 9 --zookeeper zkip:2181/kafka
主题列表:
$KAFKA_HOME/bin/kafka-topics.sh --list --zookeeper zkip:2181
启动消费者进程:
$KAFKA_HOME/bin/kafka-console-consumer.sh --zookeeper zkip:2181 --topic topic-test --from-beginning
kafka-console-consumer.sh --bootstrap-server brokerip:9092 --from-beginning --topic logstash --new-consumer --consumer.config=/opt/beh/core/kafka/config/consumer.properties
启动生产者进程:
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list brokerip:9092 --topic topic-test
删除主题:
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper zkip:2181 --delete --topic topic-test
描述主题:
$KAFKA_HOME/bin/kafka-topics.sh --describe --zookeeper zkip:2181/ --topic test20160807
配置服务端权限控制属性server.properties:
vi /opt/beh/core/kafka/config/server.properties
修改brokerid
zookeeper.connect=zkip1:2181, zkip2:2181, zkip3:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
listeners=SASL_PLAINTEXT://:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
auto.create.topics.enable=false
allow.everyone.if.no.acl.found=false
delete.topic.enable=true
super.users=User:admin
authorizer.class.name = kafka.security.auth.SimpleAclAuthorizer
配置服务端权限控制用户:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin"
user_admin="admin"
user_hadoop="hadoop"
user_producer1="producer1_test"
user_consumer1="consumer1_test"
user_producer2="producer2_test"
user_consumer2="consumer2_test";
};
配置客户端权限控制用户:
vi kafka_client_consumer_jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="consumer1"
password="consumer1_test";
};
Vi kafka_client_producer_jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="producer1"
password="producer1_test";
};
配置生产及消费权限控制属性producer.properties:
consumer.properties
echo security.protocol=SASL_PLAINTEXT >> producer.properties
echo sasl.mechanism=PLAIN >> producer.properties
echo security.protocol=SASL_PLAINTEXT >> consumer.properties
echo sasl.mechanism=PLAIN >> consumer.properties
vi producer.properties
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
vi consumer.properties
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
配置服务端启动脚本:
/opt/beh/core/kafka/bin/
vi server-start
export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/beh/core/kafka/config/kafka_server_jaas.conf"
nohup kafka-server-start.sh /opt/beh/core/kafka/config/server.properties &
配置生产消费运行脚本:
vi kafka-console-producer.sh
if [ "x$KAFKA_OPTS" ]; then
export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/beh/core/kafka/config/kafka_client_jaas.conf"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx512M"
fi
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleProducer "$@"
vi kafka-console-consumer.sh
if [ "x$KAFKA_OPTS" ]; then
export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/beh/core/kafka/config/kafka_client_jaas.conf"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx512M"
fi
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleConsumer "$@"
赋权命令
未赋予任何权限时:

测试命令:
启动服务:
nohup kafka-server-start.sh /opt/beh/core/kafka/config/server.properties &
确认环境无授权信息:
kafka-acls.sh --list --authorizer-properties zookeeper.connect=localhost:2181
赋予某个用户处理集群的权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:admin --operation ClusterAction --cluster --add (更新metedata权限)
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:admin --cluster --add
创建主题:
$KAFKA_HOME/bin/kafka-topics.sh --create --topic topic-test1 --replication-factor 2 --partitions 4 --zookeeper localhost:2181
赋予topic权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --allow-principal User:Alice --allow-host xxx.xx.xx.0 --allow-host xxx.xx.xx.1 --operation Read --operation Write --topic Test-topic
- 指定主题指定用户 -
为主题赋予*某个*用户的*生产*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:producer1 --topic=topic-test --operation Write --add
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:producer1 --topic=test1 --operation Write --add
为主题赋予*某个*用户在*所有*消费者组*下*消费*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:producer1 --consumer --topic=topic-test --group=* --add
为主题赋予*某个*用户在*某个*消费者组*下*消费*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:hadoop --consumer --topic=topic-test1 --group=test-consumer-group --add
- 指定主题全部用户 -
为主题赋予*全部*用户的*生产*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --producer --topic=topic-test1 --add
为主题赋予*全部*用户在*所有*消费者组*下*消费*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --consumer --topic=topic-test1 --group=* --add
为主题赋予*全部*用户在*某个*消费者组*下*消费*权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --consumer --topic=topic-test1 --group=test-consumer-group --add
- 所有主题指定用户 -
为所有主题赋予某个用户的生产权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:producer1 --topic=* --operation Write --add
为所有主题赋予某个用户在某个消费者组消费权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:hadoop --consumer --topic=* --group=test-consumer-group --add
为所有主题赋予某个用户在全部消费者组消费权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:hadoop --consumer --topic=* --group=* --add
- 所有主题全部用户 -
为所有主题赋予全部用户的生产权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --topic=* --operation Write --add
为所有主题赋予全部用户在某个消费者组消费权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --consumer --topic=* --group=topic-test --add
为所有主题赋予全部用户在全部消费者组消费权限:
kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --allow-principal User:* --consumer --topic=* --group=* --add
移除权限:
bin/kafka-acls.sh --authorizer-properties zookeeper.connect=data-rt-dev02:2181/kafka_test10 --remove --allow-principal User:Bob --allow-principal User:Alice --allow-host xxx.xx.xx.0 --allow-host xxx.xx.xx.1 --operation Read --operation Write --topic test
查看权限:
查看所有用户的所有权限:
kafka-acls.sh --list --authorizer-properties zookeeper.connect=localhost:2181
查看某个用户所拥有的权限:
kafka-acls.sh --list --authorizer-properties zookeeper.connect=localhost:2181 User:hadoop
查看某个主题所拥有的权限:
kafka-acls.sh --list --authorizer-properties zookeeper.connect=localhost:2181 --topic=topic-test1
生产消费测试
启动生产者:
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list broker1:9092 --topic topic-test --producer.config=/opt/beh/core/kafka/config/producer.properties
启动消费者:
kafka-console-consumer.sh --bootstrap-server broker1:9092 --from-beginning --topic topic-test --new-consumer --consumer.config=/opt/beh/core/kafka/config/consumer.properties
Kafka权限控制的java代码示例:
put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"consumer1\" password=\"consumer1_test\";");
put("security.protocol", "SASL_PLAINTEXT");
put("sasl.mechanism", "PLAIN");
评估数据量:要求研发提前评估topic一个周期全量的数据大小。
计算磁盘总存储:如一块盘825g,一个节点20快盘,10个节点。那么磁盘总存储就是165000g。
预估实际数据存储占比:topic一个周期全量数据大小占磁盘总存储的百分比,超过百分之六十,即要求研发减少存储周期。
计算磁盘总块数:一个节点20快盘,10个节点,总磁盘块数200个。
合理预分区:分区数量为磁盘总数的整数倍。如所有的topic总数据量为50000gb,磁盘个数为200,那么就可以设置总分区数为200,400,600.具体多少分区数视业务决定。若分区数为400,那么一个分区的大小约125g。例如某一个topic:cbss001的预估数据量是210g,那么通过计算可以将其分成两个分区。这样根据Kafka副本落盘策略,各个主机磁盘就能保证最大限度的存储均衡。
坏盘会导致节点宕掉,及时更换坏盘,重启节点即可。
unclean.leader.election.enable 该参数为true配置到topic中会引起消息重复消费。但为false时,会引起节点9092端口断开连接,导致Kafka进程假死。
内存溢出,其会导致节点副本不能上线isr。
进程,文件数限制也会造成节点报错,后续调优中会给出优化参数。
flower副本不能及时同步leader副本,同步超时导致副本下线isr。
消费offset越界,这种情况首先重启节点,若还是报错,则找到该offset越界的分区,删除几条message,再次查看。知道不报错为止。
使用自动迁移工具
下面的示例将把foo1,foo2两个主题的所有分区都迁移到新的broker机器5,6上。最后,foo1,foo2两个主题的所有分区都厚在brokers 5,6上。
vi topics-to-move.json
{"topics": [{"topic": "foo1"}, {"topic": "foo2"}], "version":1 }
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181
--topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate Current partition replica assignment
{"version":1,
"partitions":[
{"topic":"foo1","partition":2,"replicas":[1,2]}, {"topic":"foo1","partition":0,"replicas":[3,4]}, {"topic":"foo2","partition":2,"replicas":[1,2]}, {"topic":"foo2","partition":0,"replicas":[3,4]}, {"topic":"foo1","partition":1,"replicas":[2,3]},{"topic":"foo2","partition":1,"replicas":[2,3]}
]
}
Proposed partition reassignment configuration
{"version":1,
"partitions":[
{"topic":"foo1","partition":2,"replicas":[5,6]},{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]},{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[5,6]}
]
}
工具生成了一个把主题foo1,foo2所有分区迁移到brokers 5,6上的计划。注意,分区迁移还没有开始。它只是告诉你当前分配计划和新计划的提议。为了防止万一需要回滚,新的计划应该保存起来。
新的调整计划应该保存成一个json文件(如:expand-cluster-reassignment.json),并以–execute选项的方式,如下:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
Current partition replica assignment
{"version":1,
"partitions":[
{"topic":"foo1","partition":2,"replicas":[1,2]}, {"topic":"foo1","partition":0,"replicas":[3,4]}, {"topic":"foo2","partition":2,"replicas":[1,2]}, {"topic":"foo2","partition":0,"replicas":[3,4]}, {"topic":"foo1","partition":1,"replicas":[2,3]}, {"topic":"foo2","partition":1,"replicas":[2,3]}
] }
Save this to use as the --reassignment-json-file option during rollback Successfully started reassignment of partitions
{"version":1,
"partitions":[
{"topic":"foo1","partition":2,"replicas":[5,6]}, {"topic":"foo1","partition":0,"replicas":[5,6]}, {"topic":"foo2","partition":2,"replicas":[5,6]}, {"topic":"foo2","partition":0,"replicas":[5,6]}, {"topic":"foo1","partition":1,"replicas":[5,6]}, {"topic":"foo2","partition":1,"replicas":[5,6]}
]
}
执行验证:–verify
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --verify
Status of partition reassignment: Reassignment of partition [foo1,0]
completed successfully
Reassignment of partition [foo2,1]
completed successfully
log.retention.bytes (一个topic的大小限制 =分区数*log.retention.bytes)
log.retention.minutes
log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行数据删除
kafka-configs.sh --zookeeper zkip1:2181 --describe --entity-type topics --entity-name CdrNormal
Configs for topics:CdrNormal are retention.ms=86400000
Python脚本监控Kafka存活节点:
#!/usr/bin/python
#_*_coding:utf-8_*_
import pycurl
import json
import StringIO
import time
import sys
import zookeeper
zk=zookeeper.init("zkip1:2181")
t = zookeeper.get_children(zk,"/brokers/ids")
d=0
for i in t:
d=d+1
b=16-d
if d == 16:
print "ok cb实时kafka1节点存活正常"
sys.exit(0)
else:
print "Critical cb实时kafka1节点有:",b,"个死去节点"
sys.exit(2)
Python脚本监控Kafka各节点磁盘存储:
#!/usr/bin/python
#_*_coding:utf-8_*_
import paramiko
import sys
hostname = ['IP1',' IP2']
username = sys.argv[1]
password = sys.argv[2]
percent = sys.argv[3]
disk={}
error=""
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
for i in range(0,len(hostname)):
ssh.connect(hostname[i],22,username,password)
stdin,stdout,stderr = ssh.exec_command("df -TPh|awk '+$6>%s {print $7}'" % percent)
path = stdout.readlines()
#print path
disk[hostname[i]]=path
#print disk
#it=iter(disk.keys())
#print disk.values()
#for key in hostname:
# print i
#print disk[hostname[i]]
#print disk[next(it)]
#print len(disk[next(it)])
#if len(disk[next(it)])==0:
if not disk:
print("未采集到集群信息!")
sys.exit(0)
else:
for i in disk.keys():
#print disk.get(i)
if not disk.get(i):
continue
else:
error += "节点"+i+":"
for j in range(0,len(disk[i])):
if j == len(disk[i])-1:
error += disk[i][j].encode('utf-8')+"。"
else:
error += disk[i][j].encode('utf-8')+","
if not error:
print("cb_rt_kafka业务数据采集集群正常")
sys.exit(0)
else:
#print ("cb_rt_kafka业务数据采集集群,%s,磁盘存储超出百分之七十") % error.replace("\n", "")
print ("cb_rt_kafka业务数据采集集群,%s,磁盘存储超出百分之%s") % (error.replace("\n", ""),percent)
sys.exit(2)
ssh.close()








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721