
蔡岳毅,携程酒店大数据高级研发经理,负责酒店数据智能平台研发,大数据技术创新工作。喜欢探索研究大数据的开源技术框架。
一、背景
携程酒店每天有上千表,累计十多亿数据更新,如何保证数据更新过程中生产应用高可用;
每天有将近百万次数据查询请求,用户可以从粗粒度国家省份城市汇总不断下钻到酒店,房型粒度的数据,我们往往无法对海量的明细数据做进一步层次的预聚合,大量的关键业务数据都是好几亿数据关联权限,关联基础信息,根据用户场景获取不同维度的汇总数据;
为了让用户无论在app端还是pc端查询数据提供秒出的效果,我们需要不断的探索,研究找到最合适的技术框架。
对此,我们尝试过关系型数据库,但千万级表关联数据库基本上不太可能做到秒出;考虑过Sharding,但数据量大,各种成本都很高;热数据存储到ElasticSearch,但无法跨索引关联,导致不得不做宽表,因为权限,酒店信息会变,所以每次要刷全量数据,不适用于大表更新,维护成本也很高;Redis键值对存储无法做到实时汇总;也测试过Presto、GreenPlum、Kylin......
真正让我们停下来深入研究,不断扩展使用场景的,是ClickHouse。
二、ClickHouse介绍
ClickHouse是一款用于大数据实时分析的列式数据库管理系统,而非数据库。通过向量化执行以及对CPU底层指令集(SIMD)的使用,它可以对海量数据进行并行处理,从而加快数据的处理速度。
主要优点有:
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;
数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行;
索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
写入速度非常快,50-200M/s,对于大量的数据更新非常适用。
ClickHouse并非万能的,正因为ClickHouse处理速度快,所以也是需要为“快”付出代价。选择ClickHouse需要有下面注意以下几点:
不支持事务,不支持真正的删除/更新;
不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
SQL满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似SQL的join,但性能不好;
尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;
Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数。
三、ClickHouse在酒店数据智能平台的实践
我们的主要数据源是Hive到ClickHouse,现在主要采用如下两种方式:
① Hive到MySQL,再导入到ClickHouse
初期在DataX不支持Hive到ClickHouse的数据导入,我们是通过DataX将数据先导入MySQL,再通过ClickHouse原生API将数据从MySQL导入到ClickHouse。
为此我们设计了一套完整的数据导入流程,保证数据从Hive到MySQL再到ClickHouse能自动化,稳定的运行,并保证数据在同步过程中线上应用的高可用。
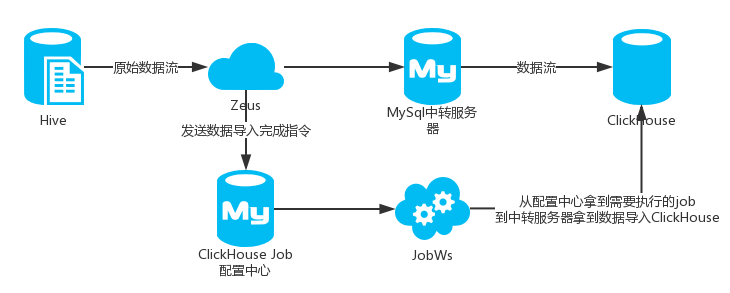
② Hive到ClickHouse
DataX现在支持Hive到ClickHouse,我们部分数据是通过DataX直接导入ClickHouse。但DataX暂时只支持导入,因为要保证线上的高可用,所以仅仅导入是不够的,还需要继续依赖我们上面的一套流程来做ReName,增量数据更新等操作。
针对数据高可用,我们对数据更新机制做了如下设计:
1)全量数据导入流程
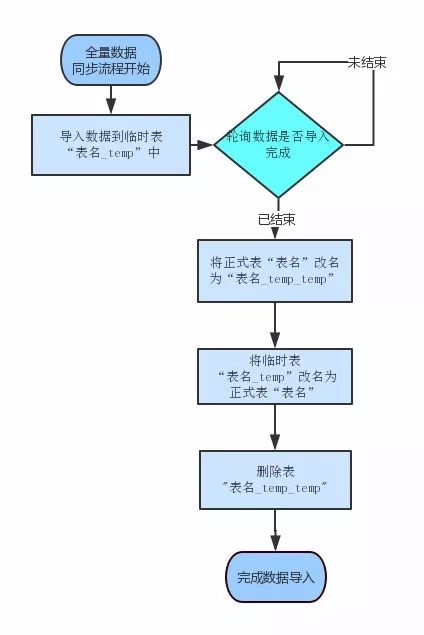
全量数据的导入过程比较简单,仅需要将数据先导入到临时表中,导入完成之后,再通过对正式表和临时表进行ReName操作,将对数据的读取从老数据切换到新数据上来。
2)增量数据的导入过程
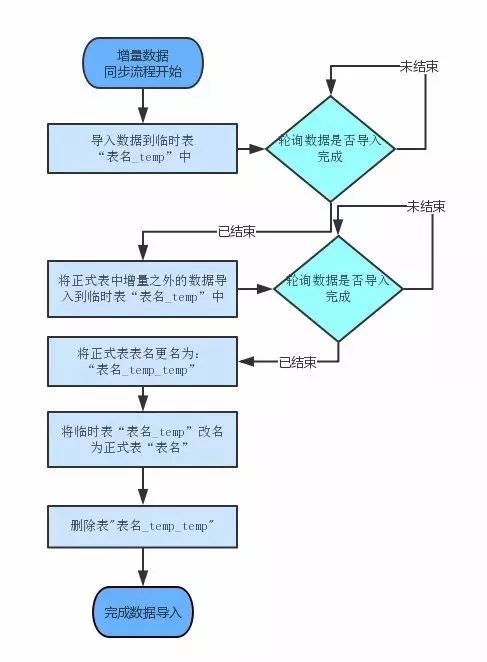
增量数据的导入过程,我们使用过两个版本。
由于ClickHouse的delete操作过于沉重,所以最早是通过删除指定分区,再把增量数据导入正式表的方式来实现的。
这种方式存在如下问题:一是在增量数据导入的过程中,数据的准确性是不可保证的,如果增量数据越多,数据不可用的时间就越长;
二是ClickHouse删除分区的动作,是在接收到删除指令之后内异步执行,执行完成时间是未知的。如果增量数据导入后,删除指令也还在异步执行中,会导致增量数据也会被删除。最新版的更新日志说已修复这个问题。
针对以上情况,我们修改了增量数据的同步方案。在增量数据从Hive同步到ClickHouse的临时表之后,将正式表中数据反写到临时表中,然后通过ReName方法切换正式表和临时表。
通过以上流程,基本可以保证用户对数据的导入过程是无感知的。
由于数据量大,数据同步的语句经常性超时。为保证数据同步的每一个过程都是可监控的,我们没有使用ClickHouse提供的JDBC来执行数据同步语句,所有的数据同步语句都是通过调用ClickHouse的RestfulAPI来实现的。
调用RestfulAPI的时候,可以指定本次查询的QueryID。在数据同步语句超时的情况下,通过轮询来获得某QueryID的执行进度。这样保证了整个查询过程的有序运行。在轮询的过程中,会对异常情况进行记录,如果异常情况出现的频次超过阈值,JOB会通过短信给相关人员发出预警短信。
现在主要根据场景分国内,海外/供应商,实时数据,风控数据4个集群。每个集群对应的两到三台服务器,相互之间做主备,程序内部将查询请求分散到不同的服务器上做负载均衡。
假如某一台服务器出现故障,通过配置界面修改某个集群的服务器节点,该集群的请求就不会落到有故障的服务器上。如果在某个时间段某个特定的数据查询量比较大,组建虚拟集群,将所有的请求分散到其他资源富于的物理集群上。

我们会监控每台服务器每天的查询量,每个语句的执行时间,服务器CPU,内存相关指标,以便于及时调整服务器上查询量比较高的请求到其他服务器。

四、ClickHouse使用探索
我们在使用ClickHouse的过程中遇到过各种各样的问题,总结出来供大家参考:
1)关闭Linux虚拟内存。在一次ClickHouse服务器内存耗尽的情况下,我们Kill掉占用内存最多的Query之后发现,这台ClickHouse服务器并没有如预期的那样恢复正常,所有的查询依然运行的十分缓慢。
通过查看服务器的各项指标,发现虚拟内存占用量异常。因为存在大量的物理内存和虚拟内存的数据交换,导致查询速度十分缓慢。关闭虚拟内存,并重启服务后,应用恢复正常。
2)为每一个账户添加join_use_nulls配置。ClickHouse的SQL语法是非标准的,默认情况下,以Left Join为例,如果左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准SQL中的Null值。对于习惯了标准SQL的我们来说,这种返回值经常会造成困扰。
3)JOIN操作时一定要把数据量小的表放在右边,ClickHouse中无论是Left Join 、Right Join还是Inner Join永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
4)通过ClickHouse官方的JDBC向ClickHouse中批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好通过Order By语句对需要导入的数据进行排序。无序的数据或者数据中涉及的分区太多,会导致ClickHouse无法及时的对新导入的数据进行合并,从而影响查询性能。
5)尽量减少JOIN时的左右表的数据量,必要时可以提前对某张表进行聚合操作,减少数据条数。有些时候,先GROUP BY再JOIN比先JOIN再GROUP BY查询时间更短。
6)ClickHouse版本迭代很快,建议用去年的稳定版,不能太激进,新版本我们在使用过程中遇到过一些bug,内存泄漏,语法不兼容但也不报错,配置文件并发数修改后无法生效等问题。
7)避免使用分布式表,ClickHouse的分布式表性能上性价比不如物理表高,建表分区字段值不宜过多,太多的分区数据导入过程磁盘可能会被打满。
8)服务器CPU一般在50%左右会出现查询波动,CPU达到70%会出现大范围的查询超时,所以ClickHouse最关键的指标CPU要非常关注。我们内部对所有ClickHouse查询都有监控,当出现查询波动的时候会有邮件预警。
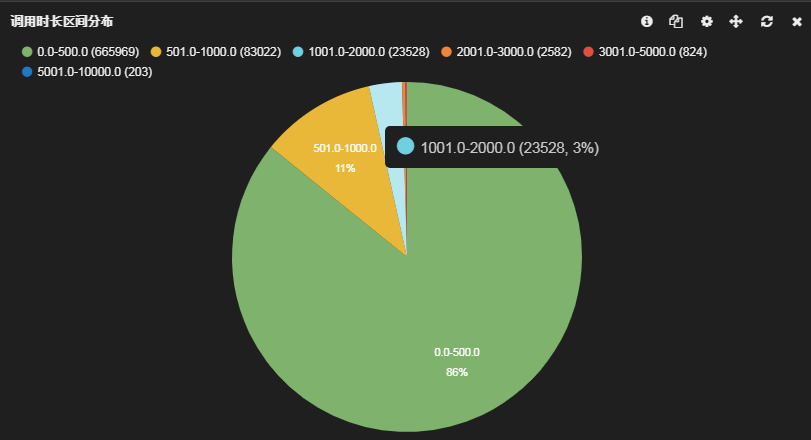
9)查询测试Case有:6000W数据关联1000W数据再关联2000W数据sum一个月间夜量返回结果:190ms;2.4亿数据关联2000W的数据group by一个月的数据大概390ms。但ClickHouse并非无所不能,查询语句需要不断的调优,可能与查询条件有关,不同的查询条件表是左join还是右join也是很有讲究的。
五、总结
酒店数据智能平台从去年7月份试点,到现在80%以上的业务都已接入ClickHouse。满足每天十多亿的数据更新和近百万次的数据查询,支撑app性能98.3%在1秒内返回结果,pc端98.5%在3秒内返回结果。
从使用的角度,查询性能不是数据库能相比的,从成本上也是远低于关系型数据库成本的,单机支撑40亿以上的数据查询毫无压力。与ElasticSearch、Redis相比ClickHouse可以满足我们大部分使用场景。
我们会继续更深入研究ClickHouse,跟进最新的版本,同时也会继续保持对外界更好的开源框架的研究,尝试,寻找到更合适我们的技术框架。
作者:蔡岳毅
来源:携程技术中心(ID:ctriptech)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721