
作者介绍
李万雪, eBay软件开发工程师,2017年毕业于上海交通大学。目前负责日志在大数据平台上的分析和opentracing在ebay日志平台的实现。
eBay的CAL(Central Application Logging)系统负责收集eBay各种应用程序的日志数据,并且通过Hadoop MapReduce job生成日志报告,应用程序开发人员与运维人员通过报告可获得以下内容:
API调用响应时间的百分位值;
服务调用关系;
数据库操作。
eBay每天产生PB量级的CAL日志,其数据量每天都在增加。对于日益增长的数据量,Hadoop MapReduce job的优化将会大大节省计算资源。本文将分享eBay团队如何对这些Hadoop job进行优化,希望为大家带来启发,解决Hadoop MapReduce(MR)job实践中存在的问题。
一、为什么要优化
CAL报告的Hadoop job现状如下:
数据集:CAL每天的日志量为PB量级,并以每年70%的速度增加,CAL收集的日志来自不同的应用程序,其日志的内容也有所不同。有些属于数据库操作密集型,有些则包含着复杂的嵌套事务,且每个应用程序日志的数据量差异大。
计算资源:CAL使用的是共享Hadoop集群。优化前,CAL Hadoop job需要使用约50%整个集群的资源才能完成。CAL报告Hadoop job在一天中,其中有9个小时只能使用19%的集群计算资源,不能在这段时间获得资源执行的job将会等待在队列中,直到这9小时结束,它才能有80%的集群计算资源可以使用。
成功率:CAL MapReduce job的成功率仅92.5%。
二、eBay团队如何优化
在分享我们的经验之前,我们先简单介绍Hadoop MapReduce的流程。
Hadoop MR job一般分为五个阶段,即CombineFileInputFormat、Mapper、Combiner、Partitioner以及Reducer:

我们的优化工作主要从执行时间和资源使用两方面考虑:
Hadoop job的执行时间取决于最慢的Mapper任务和最慢的reducer任务的时长。
假设:
TMap:Map任务执行时间;
CountMap:Map任务个数;
TReduce:Reduce任务执行时间;
CountReduce:Map任务个数。
那么,MR job执行时间T则可表示为:
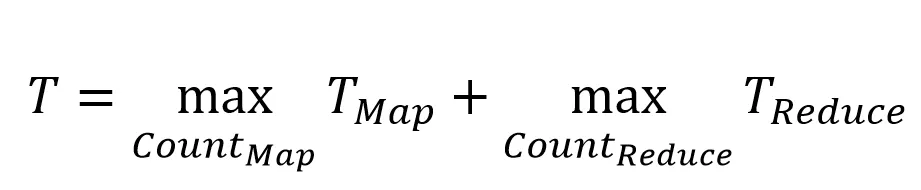
Map任务的执行时间与Map任务的输入记录个数、输出记录个数成正比:
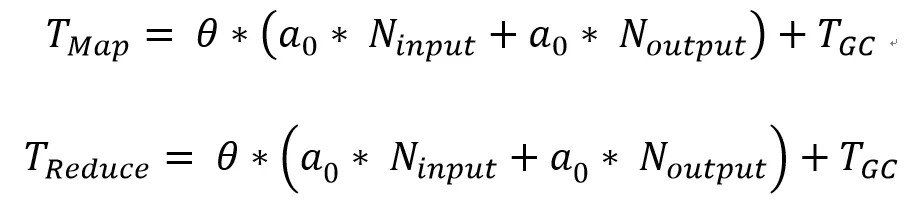
此外,Hadoop job的计算复杂度也会影响Hadoop job的执行时间。同时对于某些极端的job,我们应关注job的GC时间。
综上所述,我们从以下三个方面来减少Hadoop的执行时间:
GC时间;
尽量避免Mapper和Reducer的数据倾斜;
优化算法。
考虑到内存的资源使用,假设:
SizeMap:MR job中的Mapper容器内存大小;
SizeReduce:Reducer容器内存大小;
SizeAM:MR job中的应用程序管理器容器内存大小;
CountMap:MR job中,Mapper任务个数;
CountReduce:Reducer任务的个数。
那么, Hadoop job的内存资源使用量R与Mapper/Reducer任务的执行时间成正比,可表示为:

因此,为了降低资源使用,我们可以从以下几个方面下功夫:
减少Map或Reduce任务个数;
减少Map或Reduce任务容器大小;
优化job的执行时间。
三、解决方法
GC是我们遇到的很明显的问题。job失败的原因通常是“GC overhead”或“Out of Memory”。即便job成功了,通过Hadoop job计数器,可以看到其GC时间也很长,同时GC也会消耗大量的CPU资源。
1) Mapper中的GC
所有发到CAL的日志,都会使用CALrecord的数据结构。CAL事务是由多个CALrecord组成的逻辑概念。
CAL事务一般可以对应到用户的请求上。
当应用程序对用户的请求作出响应时,应用程序都会记录CAL事务到CAL服务,而为了完成用户请求,这个CAL 事务往往会调用多个子CAL事务协同完成。
也就是说,CAL 事务是一个树状结构,每个CAL事务都是这个树状结构的一个节点,而报告中需要的指标(Metrics)需要让每个节点知道其根节点信息,而在构建这个树状结构的过程中,节点是无序的。
因此,需要保留所有节点信息以便帮助后来节点追溯其根节点。
例如,下图展示了典型的树状事务层次结构:
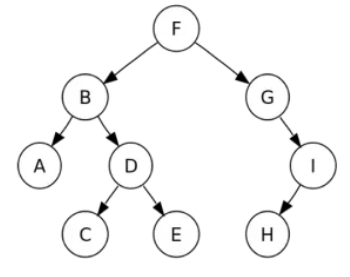
CAL事务 F是根。它会调用B和G来处理用户请求。如果我们已经有了F、 B、 C,C要等到D节点出现,才能找到根 F。同时,这棵树上的所有节点都需要保存在内存中,否则其子节点将不能找到其根。
显然,这种情况没有清理机制,会导致OOM。
为了解决这个问题,从日志的业务逻辑上,CAL事务应该具有时间窗属性,涉及同一个用户请求的所有CAL事务都应该发生在一个时间窗内。如果时间窗为t,并且CAL事务的开始时间戳为ts,则所有子CAL事务应在ts + t之前发生。
在我们的实验中,我们假设时间窗为5分钟。
我们对12个日志量最大的应用程序的日志数据来验证此假设。即,若现在正在处理数据时间戳为ts的CAL事务,则时间戳在ts-5分钟之前的CAL事务都将从内存中移除。12个应用程序日志中,有10个可以保证几乎100%的准确性。同时,其他2个应用程序,此功能将会影响其正确性,我们对其设置了白名单,暂时不对其做处理。
时间窗口的设置有效地减少了Hadoop job执行时间,并将其成功率从93%提高到97%。
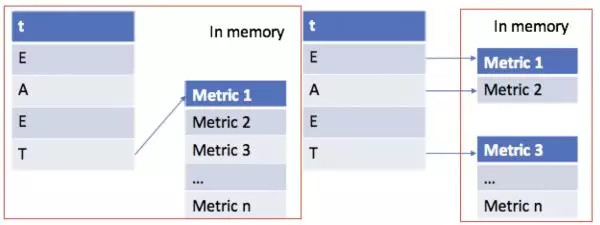
CAL日志与指标
优化之前,Mapper在处理一个CAL事务的时候,将组成该事务的CAL record完全读取到内存中,然后提取出CAL事务有关的所有指标,如上图左侧所示。而CAL事务的原始信息并不完全需要保存在内存中,我们只需要保存必要的指标即可,如上图右侧所示。
Combiner可以减少Mapper和Reducer任务之间的数据传输。在实际应用中,由于Mapper的输出数据量很大,Hadoop对Mapper的输出数据做排序时,将带来较长的GC。我们的解决方案是在Mapper端使用Combiner做预处理,减少Mapper与Reducer间的传输数据量,有效降低执行时间。
2) Reducer中的GC
Reducer与Mapper具有类似的GC问题。
用于生成CAL报告的Hadoop job输出两种类型的数据——15分钟粒度的指标数据和用1小时粒度的指标数据。其中Mapper负责将日志映射为对应的指标,指标格式为三元组<时间戳,指标名称,指标的值>,其中时间戳粒度为15分钟,当Mapper将这些信息发送给reducer时候<时间戳,指标名称>将作为键值,<指标的值>作为值,在reducer中,将不同Mapper任务输出的指标聚合(如计数,求和等),聚合的结果包括15分钟和1小时两种粒度。
在MR中,Reducer收到的数据,Hadoop将根据其键值排好顺序。优化前,Mapper发送给Reducer的数据以“时间戳+指标名称”作为键值,Reducer收到的数据格式和顺序如下图左侧部分:

Reducer 收到的数据
当计算指标Metrics1一小时粒度的值时,需要得到当前小时最后15分钟(Timestamp4)的数据,并保存Metrics1的其他时间的数据。即为了计算N个指标的一小时粒度的值,需要保存3N条数据在内存中。当N很大时,内存溢出在所难免。
为了解决这个问题,我们将键值从“时间戳+指标名称”调整为“指标名称+时间戳”。 为了计算指标Metrics1的一小时粒度的值,我们仅需保存3条数据在内存中,解决了Reducer中内存过量使用导致的问题。
该方法解决了Reducer中的问题,并增强了Reducer的可扩展性。
在检查Hadoop job里map任务和reduce任务时,我们发现一个Job中的多个map任务的执行时间从3秒到超过1小时不等。Reducer任务也有类似的问题。
由之前章节中的公式,我们将输入记录平均分配给Mapper或Reducer,以最小化 和
和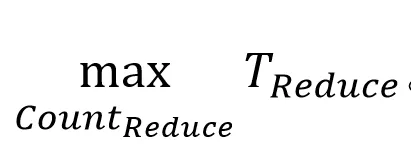 。
。
CombineFileInputFormat可以帮助解决Mapper中的数据倾斜问题。之前,CAL MR job没有使用CombineFileInputFormat,使用CombineFileInputFormat后,其将多个小文件合并成一个分片,分片大小设置为256MB,每个Mapper处理一个分片,这使Mapper任务数量减少到之前的一半。
Partition能够处理Reducer中的数据倾斜问题。
在CAL报告中存在着两个概念:一是报告名称,二为指标名称。对于每种报告,都有多个指标。优化前,分区策略是使用报告名称的哈希值。现在,使用报告名称和指标名称的哈希值作为分区策略,极大的改善了数据倾斜的状况。
在Hadoop job执行时间的公式中,job执行时间与输入记录个数成正比。实验中,有两个数据集。数据集A为20MB,数据集B为100MB。数据集A的MR job需要90分钟才能完成;以B作为输入的job仅需8分钟就能完成。
分析CAL日志内容,有两种类型的日志:SQL日志和事件日志。SQL日志即数据库操作有关的日志。事件日志可能会引用SQL日志,而解析SQL日志则更为耗时。
因此,我们计算了A和B中的SQL日志数目,结果显示它们的数目接近。而在A中,引用了SQL的事件日志数目更多。
显然,对处理引用了SQL的日志上,出现了一些重复的计算——每次引用都会重新解析被引用的SQL日志。为了解决这个问题,我们缓存了SQL的解析结果,在引用时直接使用缓存结果。优化之后,A的job可以在4分钟内完成。
四、优化结果
通过以上三个方面的优化,除了执行时间,任务的资源使用情况也得到了优化。
在优化之前,CAL报告job需要Hadoop集群中50%的资源才能执行完成。优化后,只需19%的资源就能执行完成。下图显示了Hadoop Cluster上的内存资源使用情况,左侧是优化前的情况,右侧是当前的情况:
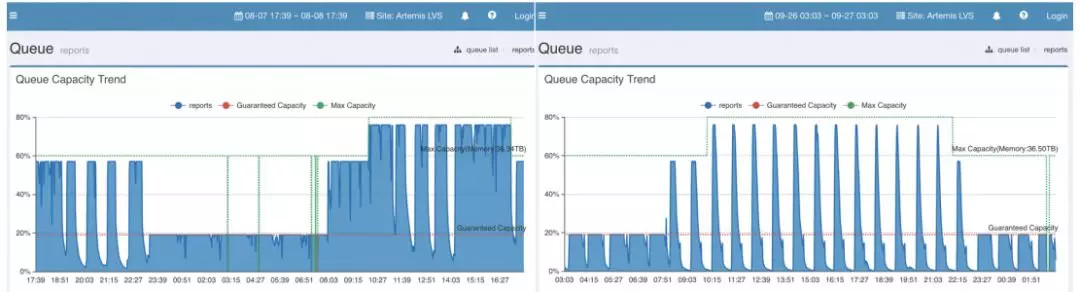
Hadoop Eagle中的资源使用情况
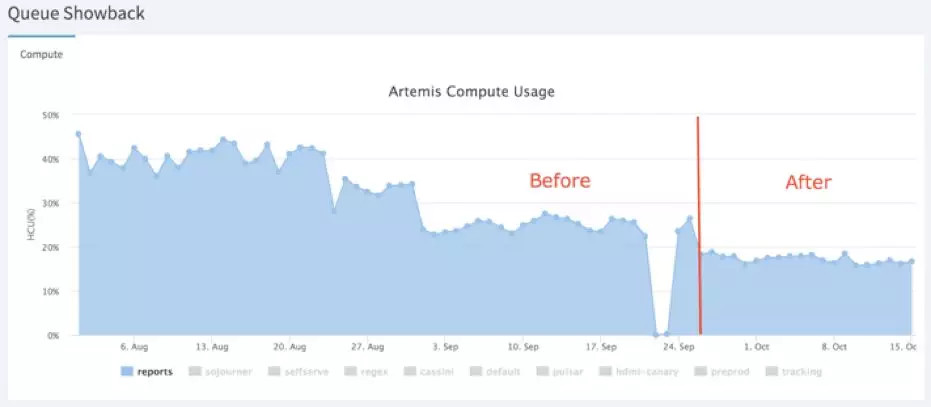
Hadoop Eagle中的计算资源使用率
Job的成功率从92.5%增加到约99.9%。从Hadoop平台服务质量考虑,Hadoop将会终止执行时间超过1小时的job,而部分应用程序的数据需要更复杂的计算,所以很难在1小时内完成。优化后95分位的Hadoop job执行时间约为40分钟,远低于优化前的90分钟。
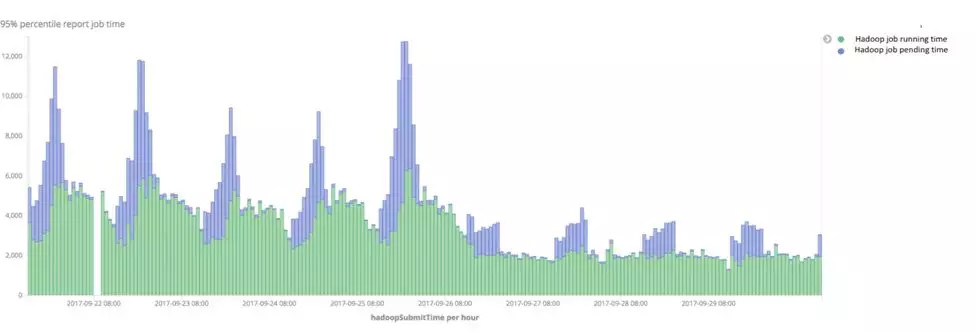
CAL报告MR job执行时间趋势
本次优化后,我们节省了超过60%的相对计算资源,相当于Hadoop集群中大约200个Hadoop节点,并且Job的成功率增加到99.9%。
五、总结
当对线上项目做优化工作时,应始终关注数据质量。因此,在优化之前,应最先制定验证方案,使用具有幂等属性的数据来验证数据质量。
同时监控也是优化工作的重点——我们把所关心的KPI,如成功率、资源使用情况和job执行时间收集起来,有助于优化过程中观察优化效果。
作者:李万雪
来源:eBay技术荟订阅号(ID:eBayTechRecruiting)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721