
作者介绍
一、大数据综述
随着DT(数据技术)时代的到来,人们能比以往更容易地获取更丰富的数据。数据作为一种新的能源形式,正在源源不断地发挥其巨大的价值,帮助我们激发更多的技术驱动力,提供更优质的服务。
在京东,有着EB级规模的历史数据,每天有近PB级的数据增长,同时每天有百万级的数据处理任务在执行。数据井喷式的增长给数据采集、数据处理、数据管理、数据应用、数据质量、数据运维带来了极大的考验。
京东的数据目前包含了电商、金融、广告、配送、智能硬件、运营、线下、线上等场景的数据,每个场景的数据背后都存在着众多复杂的业务逻辑。为了帮助业务人员降低获取数据的门槛,简化数据获取的流程,同时帮助分析人员方便快捷地进行数据统计分析, 进而挖掘数据的潜在价值,京东搭建了一套完整的数据解决方案。
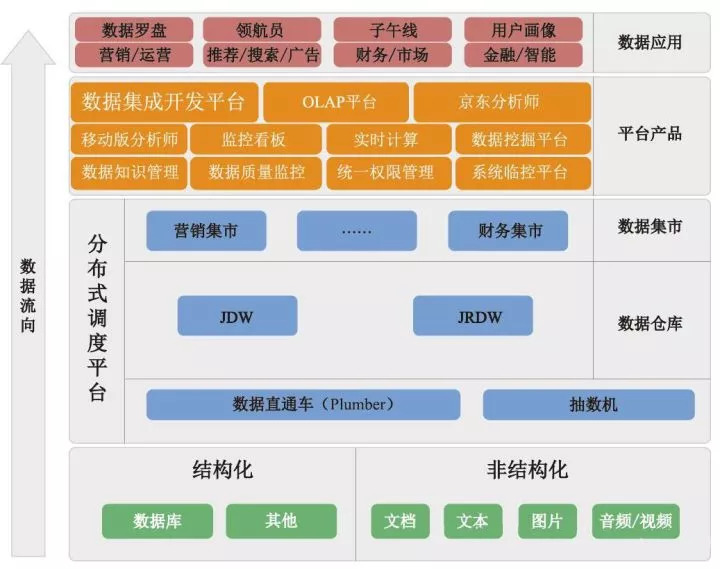
大数据平台技术架构
上图为大数据平台技术架构,分散在四处的线上系统数据(多为结构化的业务数据),或者是各种日志文件、文档、图片、音频、视频等非结构化数据,需要进行采集。我们分别借助实时和离线的数据处理平台,将数据抽取至实时数据仓库和离线仓库,然后借助平台内的工具对数据进行加工处理,同时辅以各种平台产品对数据进行统一管理、监控、处理、查询、分析等, 并结合具体的业务需求,形成相应的数据应用产品。
二、技术平台
京东包含了电商所涉及的营销、交易、仓储、配送、售后等环节,每个环节中都会产生大量的业务数据,同时用户在网站上进行的浏览、购物、消费等活动,以及用户在移动设备上对应用的使用情况,包括各种系统的操作行为,也会生成海量的行为数据。为了将上述的结构化业务数据以及用户非结构化的用户行为日志进行采集,京东搭建了一套标准化采集方案,能够将业务分析所需的数据进行标准化采集,并将数据传输到大数据平台,以便后续的加工处理及上层的数据应用。
目前京东的数据采集方案主要分为两大类:用户行为日志采集方案(点击流系统)和通用数据采集方案(数据直通车),下面将做详细介绍。
点击流系统
目前京东有着丰富的入口平台及展示形式,包括PC网页、H5页面、App应用、App内部的H5页面、智能设备、微信、手Q以及微信生态下的新场景微信小程序。其中PC网页、H5页面、App内部的H5页面、微信、手Q以及微信小程序由网页方式呈现, 用户通过浏览器进行访问;而智能设备,例如手机、移动手环、智能家电等,则是以App应用的方式呈现,用户访问App即可获得相应的服务。
以下是浏览器和App用两种使用场景的日志采集方案:
浏览器端的日志采集
日志采集:浏览器的日志采集方式,首先需要在统计页面日志的页面中预先植入一段Java Script脚本,当页面被浏览器加载时,会执行该脚本。脚本中预设了一些采集需求,包括收集页面信息、访问信息(访次、上下文)、业务信息、运行环境信息(浏览器信息、访问时间、访问地址)等。日志采集脚本在被执行后,会向服务器端发送一条HTTPS的请求,请求内容包含了收集到的日志信息。
服务器日志接收:日志服务器在成功接收到浏览器发送的日志请求后,立刻向浏览器发送一个请求成功的响应,日志请求的响应不影响页面的加载。日志服务器在接收到日志请求后,会对日志请求进行分析处理,包括判断其是否为爬虫、是否为刷流量行为、是否为恶意流量、是否为正常的日志请求等,对日志请求进行屏蔽和过滤,以免对下游解析和应用造成影响。
日志存储:服务器接收到日志请求后,会依据请求的内容及约定的格式对其进行格式化落地。例如,当前页面、上一页面、业务信息、浏览器等信息以特定的字段标识,字段之间使用特定的分隔符,整条日志以特定的格式记录下来。结合业务的时效性需求,将日志分发到实时平台或者落地成离线文件。
经过数据的收集(采集—上报—接收—存储),我们将用户在浏览器端的行为日志实时记录下来。除植入代码人工干预外,可以保证数据的准确性,数据的过滤和筛选保证了异常流量的干扰,格式化数据方便了后续的数据解析处理。
移动设备的日志采集
移动设备的页面有别于浏览器页面,移动设备主要为原生页组成的App应用,原生页使用原生预研开发完成。例如Android系统使用Java语言,iOS系统使用Objective-C原生语言开发,原生页运行速度快,效率高。
采集方式:移动设备上App应用的数据采集主要使用的是SDK工具,App应用在发版前将SDK工具集成进来,设定不同的事件行为场景,当用户触发相应的场景时,则会执行SDK相应的脚本,采集对应的行为日志。
日志存储:用户的各种场景都会产生日志,为了减少用户的流量损耗,我们将日志先在客户端进行缓存,并对数据进行聚合,在适当时机对数据进行加密和压缩后上报至日志服务器,同时数据的聚合和压缩也可以减少对服务器的请求情况。
数据直通车
数据直通车为京东线上数据提供接入京东数据仓库的完整解决方案,为后续的查询、分发、计算和分析提供数据基础。直通车提供丰富多样、简单易用的数据处理功能,可满足离线接入、实时计算、集成分发等多种需求,并进行全程状态监控。
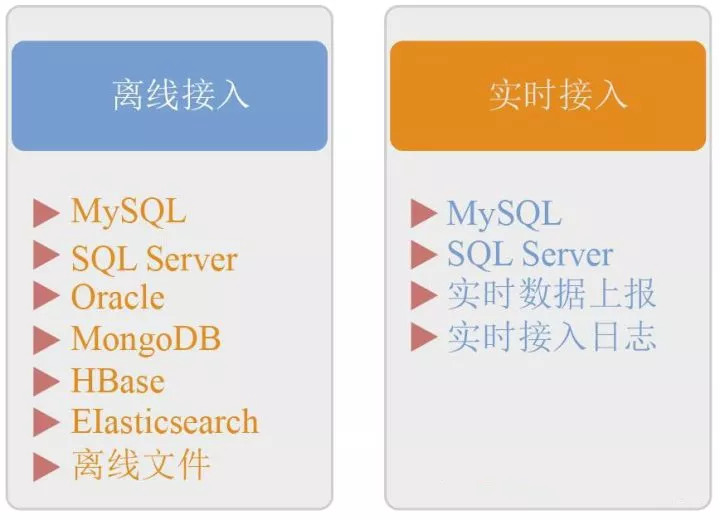
上图所示的数据直通车接入数据类型,根据抽取的数据量及抽取对线上的影响,会分为定时的离线接入和实时接入两种抽取方式。每种抽取方式支持不同的数据类型,每天在零点后可以获取前一天完整的数据,然后将一整天的数据进行集中加工处理,并将数据最终储存到目标表对应的分区中。
实时平台
业务数据处理的需求已经逐渐从离线转向了实时,在电商的应用场景中,越来越多的需求更加倚重实时数据的处理和分析,越来越多的面向用户和商家的业务场景开始尝试实时技术带来的收益。京东实时技术平台协助业务更快地帮助用户发现自己想要的商品(推荐搜索),为商家更快地制订销售策略(实时数据分析报表)提供了强有力的支撑。
京东实时数据平台一共包括三大部分:实时数据接入(MAGPIE),实时数据传输(JDQ)和实时数据计算(JRC)。
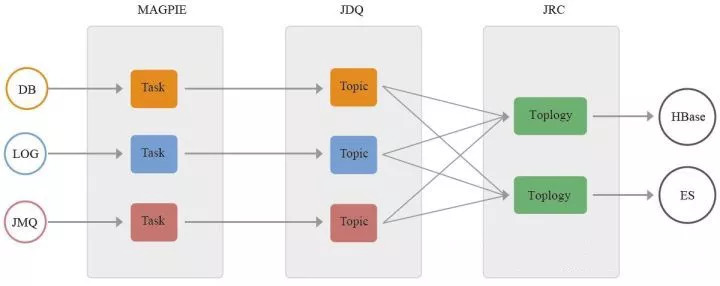
京东实时数据平台
下面就实时数据处理分析在京东的技术流程进行阐述:
实时数据接入
实时数据的源头是各个线上业务系统的各种类型数据源,在京东内部主要包括三个部门:
线上业务系统数据库:MySQL、SQL Server、Oracle。目前京东内部线上系统基本都已经切换MySQL。实时数据接入系统Magpie完全支持上述三个关系型数据库的数据实时接入,原理为数据库的主从复制模式,通过伪装从库的方式,把关系型数据库的Binlog日志实时抓取并解析发送到JDQ内。对于MySQL数据库,实时接入程序按照服务粒度抓取MySQL单服务上的所有Binlog,在程序内部进行Binlog的实时解析并过滤出所需要的库表,再发送到表粒度的Topic上,方便下游用户进行业务表粒度的实时处理。
线上业务日志系统:统一流量(用户浏览点击日志),统一日志(各业务系统服务日志)。业务日志由线上系统先发送到JDQ的写集群,再由Magpie任务实时同步到JDQ的读集群。通过这种方式做到了日志数据的读写分离,极大地提高了系统稳定性和服务能力。
线上消息系统:JMQ。JMQ是京东内部线上系统的消息中间件服务,很多业务数据在落数据库之前都会经过JMQ系统在不同业务系统之间进行传递。Magpie同样可以把JMQ内的线上系统消息实时地同步到JDQ内,再面向数据处理用户进行消费,极大地提高了数据处理系统的服务能力。
京东内部所有系统的实时数据都会经过Magpie系统进行接入和转发到JDQ系统,统一由JDQ对数据处理的业务需求提供消息服务。该方案帮助业务用户在技术层面屏蔽了接入的复杂度问题,并把服务稳定性和能力提高到了大数据实时处理的要求。
实时数据总线
实时数据在由Magpie进行统一接入处理后,需要一个面向业务研发用户的消息消费服务。我们基于Kafka的JDQ服务就是满足这个需求的产品。
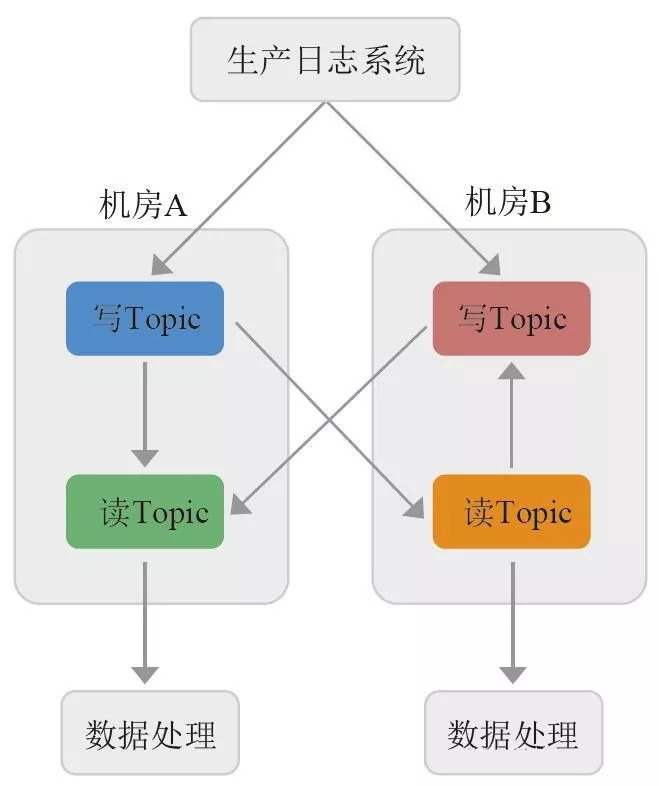
实时数据总线
在原生Kafka的基础上,我们封装了权限、限速、监控报警等一系列服务。针对重要业务进行了双机房读写分离的部署方案,大大提高了消息服务的可靠性和服务能力。618当天日生产291TB、8000亿行数据,日消费1000TB。各个系统越来越重视通过日志进行数据分析,每次618的业务日志量均以150%的速度增长。
生产日志系统向最近机房内的JDQ系统的写Topic发送业务日志消息,如遇机房故障,自动切换到可用机房的服务。
JDQ系统通过实时同步不同写集群数据到每个机房的读集群,实现每个机房都有一份完整的业务日志数据可供业务研发消费。
业务研发就近机房选择读集群进行消费,同时通过JDQ可以实现不同用户的消费限速,最大限度地保证集群服务的稳定可靠。
JDQ实时数据总线服务作为实时数据的中转缓存服务,屏蔽了业务研发对不同数据源的接入难度,同时通过一系列的数据格式使用方式的标准化,打通了实时数据从接入到业务处理的传输环节,实现了京东内部实时数据通道的目标。
实时数据计算
实时数据要想体现业务价值,最终还需要业务研发方进行计算和分析。京东内部主流的实时计算平台是JRC计算平台,该平台脱胎于早期的Storm版本,由平台研发进行了深度的改造和产品化,实现了业务研发用户完全的Web产品任务管理和监控的需求,同时整合了JDQ数据来源,实现了用户在数据计算平台的无缝对接实时数据。本次618达到1.1万亿次日处理次数。
2017年618,JRC基于容器的新架构已经开始支撑部分线上业务,未来容器化的JRC方案会进一步提高Storm平台的稳定性和资源利用率。JRC架构图如图:
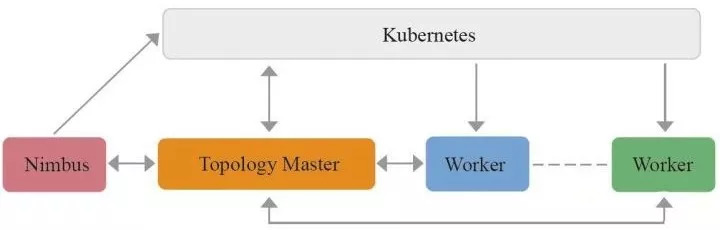
该方案的特点如下:
通过Kubernetes实现Topology执行节点的容器化,资源随用随申请,提高资源利用率。
通过Kubernetes和二级调度的方案,把Topology调度逻辑放在Kubernetes层面和Topology内部,提高了调度的效率,避免了不同Topology之间的干扰。
心跳只在Timbus和Topology Master以及Topology Master和Worker之间进行,避免了传统方案任务量大时的心跳压力。
由于实时计算的场景多样,针对不同场景业内提出了多个流行的计算框架。目前京东内部实时计算的场景也趋于多样,我们平台已经开始在线上正式提供Spark Streaming和Flink等多种计算框架的产品化服务。
由于实时计算程序必须由程序代码进行开发,对于传统离线业务,SQL研发人员进行离线需求转实时还有较高的门槛,我们平台正在进行SQL形式和拖曳形式的实时计算产品化研发工作。该方案上线后,将进一步帮助业务方把离线数据处理需求转移到实时数据处理上,帮助京东的业务更快速地服务于广大的用户和商家。
目前京东实时数据解决方案整套流程已经接入了线上的上千张业务表数据流和数百个业务日志数据流,覆盖京东内部所有核心业务系统和大部分实时处理业务,主要面向京东内部各个业务部门的个性化推荐、秒杀、实时运营、商家报表等。未来,离线数据处理需求会越来越多地迁移到实时数据处理上。
离线平台
京东大数据离线平台的整体架构如下图:
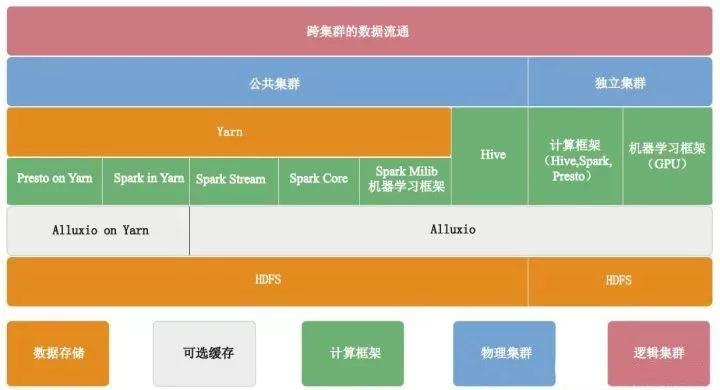
平台详解
离线处理架构为数据存储+数据缓存+数据处理+数据应用。
数据存储:以前数据仓库是LZO,线上业务是SQL Server、Oracle。现在数据仓库是ORC,线上业务是MySQL、HBase。
数据缓存:Alluxio是一个基于内存的分布式文件系统,它是架构在底层分布式文件系统和上层分布式计算框架之间的一个中间件,主要职责是以文件形式在内存或其他存储设施中提供数据的存取服务。
数据处理:混合型引擎,按需按量分配,以及根据不同业务场景,选择不同处理方式,统一由Yarn做资源管理。
数据应用:服务京东消费数据的几乎所有场景,如数据挖掘、分析报告、常规报表、即席查询等。
具体介绍
在京东大数据平台中有多个物理集群、十几个集群应用软件、十几个大数据产品、三十多个数据集市、六千多个平台用户,日运行job数量超过40万,日计算数据量超过15PB。在如此庞大的业务场景、海量数据计算、复杂数据处理流程的场景下,一个高效实用的大数据离线平台显得尤为重要。
为此,我们对大数据平台建设以来支持的各类业务服务,大数据平台自身的升级与运维技术工作进行了梳理分析,对大数据平台从前端服务到后台技术进行了整体服务框架设计。完成了从多出口的臃肿服务到统一服务管理、自助化服务管理、自动化服务实现的有机“瘦身运动”,大数据平台服务时效得到了几倍乃至几十倍的提升。
大数据平台已经实现了海量数据的实时与离线计算,同时也达到高并发、高容错、高扩展、低成本的集团发展需要。同时,在保证现有大数据平台稳定的基础上,通过与京东集市三十多个业务集市的深入接触沟通,在业务发展基础上,结合最新、最适合的前沿技术,不断提高大数据平台的业务实现范围、大数据平台技术创新(如异构集群、多引擎支持、即席查询、多维分析、登月平台等)、大数据平台更好的运营管控机制(如大数据平台运营规范、数据仓库与集市建设规范、运营值班方案、流程中心等),不断满足业务高速发展对未来大数据平台的技术需要,实现战略价值目标。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721