
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
在上个案例分享时,有读者表示“很想知道,作者失败的时候是怎么办?”,并且看热闹不嫌事大,要求“来一篇文章呗”。好吧,正所谓,常在河边走,哪有不湿鞋。本人在SQL优化领域摸爬滚打多年,“接客”无数,难免会遇到些难以伺候的“官人”,本文就跟大家分享一次不成功的优化经历与教训。
话说某天一大早,我收到了一封来自社区的邮件,居然有人在社区提问时@我,在邀请的一众专家中,居然有我!瞬间,我受宠若惊并诚惶诚恐,要知道,这是我第一次受邀解决问题。
我战战兢兢点开邮件中的链接,提问的标题是《Oracle正则表达式作为条件执行计划会改变》。看标题,似乎是正则表达式干扰了执行计划,我的第一反应是:是不是因为使用了正则表达式,导致了索引优化器不能走索引扫描?我心存侥幸:如果是这样,该多好呀。再往下看正文内容:
SQL如下:
SELECT TA.*
FROM TAB_T1 TA
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY L.HDID_C ORDER BY L.LLID_C DESC) RN,
L.HDID_C,
L.URDID_C
FROM ESF.TAB_T2 L) R
ON (R.HDID_C = TA.APLTNN_C AND R.RN = 1)
WHERE TA.ATPY_C =
在实际应用中,会对TA.CACSS_C做过滤,当条件值为常量时,如:AND TA.CACSS_C IN ('10001'),其执行计划如下:
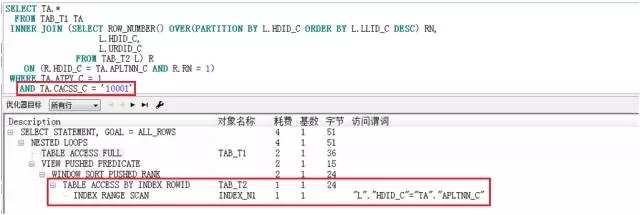
此时,TAB_T2的访问方式是通过INDEX_N1 INDEX RANGE SCAN的。
而当过滤值变成一个正则表达式的子查询时:
SELECT TA.*
FROM TAB_T1 TA
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY L.HDID_C ORDER BY L.LLID_C DESC) RN,
L.HDID_C,
L.URDID_C
FROM ESF.TAB_T2 L) R
ON (R.HDID_C = TA.APLTNN_C AND R.RN = 1)
WHERE TA.ATPY_C = 1
AND TA.CACSS_C IN
(SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+'))
执行计划如下:
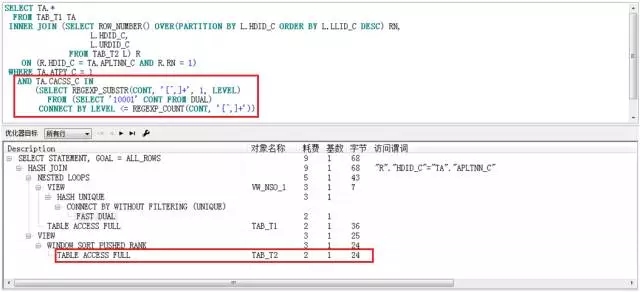
此时,TAB_T2的访问方式是TABLE ACESS FULL。
要说明的是:在该例中,无论是写成常量还是正则表达式,其值是一样的,都是1001。
请教各位专家:为何有了正则表达式,执行计划就变了呢?
果然是正则表达式干扰了优化器对索引的选择。但是仔细一看,又不是那么回事:
我们常见的正则表达式干扰索引扫描的场景是这样的:regexp_like(column_name, 'a')。如果我们在column_name字段上创建了索引,该条件自然无法选择index range scan的访问方式。
而在该提问中,正则表达式REGEXP_SUBSTR的参数并非表的字段,而是一个常量。
在没有正则表达式的时候,INDEX RANGE SCAN的INDEX是INDEX_N1对应的字段是HDID_C,该字段来自TAB_T2,是关联字段,而非过滤字段。
正则表达式是出现在IN子查询中,而IN表达式的字段为CACSS_C,一方面,没有正则表达式情况下使用的索引也非CACSS_C字段对应的索引,另一方面,该字段并没有创建索引。
看来,得要重新审视这个提问,我开始解读这个SQL的逻辑。该SQL的逻辑示意如下:

因为TAB_T1在经过ATPY_C = 1 AND CACSS_C = 10001过滤后,数据量并不大,而R子查询存在如下特性:
表TAB_T2的数据量非常大;
子查询内部没有过滤条件;
子查询存在ROW_NUMBER分析函数;
TAB_T2是通过HDID_C字段与外部表关联的,而HDID_C字段上是创建了索引(INDEX_N1)的。
因此,通过HDID_C上的索引INDEX_N1,对子查询进行谓词推入(PUSH PRED)是比较理想的。此种场景也是非常适用谓词推入的(PUSH PRED)。因此,原始的提问应该转换成:过滤条件变成正则表达式时,Oracle优化器不再选择谓词推入(PUSH PRED)。
此时此刻,自然而然,我给提问者提供了如下优化建议:增加SQL HINT/*+ push_pred(r)*/。很快,提问者又回复了我:增加SQL HINT也无济于事。我有些纳闷,同时也见怪不怪,因为push_pred不生效的案例也屡见不鲜(详见《SQL Hint都无法解救DB性能时,如何通过视图曲线救国?》)。
但是,我仍然对HINT抱有一丝侥幸心理。我在拿到Oracle数据库环境信息后,尝试着其他HINT,比如/*+ index(l, index_n1)*/,/*+ use_nl(ta,l)*/。但是Oracle优化器依旧无动于衷。
当时的我,有如“鬼压床”,无论自己怎样用力,就是使不上力来,想大叫也叫不出声,想睁开眼或翻身起床,却一动也不能动。拼命挣扎数分钟后,才终于醒来:HINT之法已然成为了死胡同。
按照惯例,当无法通过SQL HINT之轻撬动性能之重时,我会退一步,通过SQL等价改写,换取一片海阔天空。
既然子查询无法谓词推入,那么是否可以去子查询呢?这是一个值得尝试的想法,因为在过往的案例中,我多次通过去子查询来实现性能提升。去子查询R的等价改写SQL如下:
SELECT *
FROM (SELECT TA.*,
ROW_NUMBER() OVER(PARTITION BY L.HDID_C ORDER BY L.LLID_C DESC) RN
FROM TAB_T1 TA, TAB_T2 L
WHERE HDID_C = TA.APLTNN_C
AND TA.ATPY_C = 1
AND TA.CACSS_C IN
(SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+')))
WHERE RN = 1;
再看执行计划,果然是“想什么来什么”。

我又读了一遍SQL,心里在想:
TAB_T1在通过ATPY_C = 1 AND CACSS_C = 10001条件过滤后,数据量不会大;
然后再与TAB_T2表关联,此时,由于TAB_T2在关联条件HDID_C上创建了索引,因此可以采用USE_NL的关联方式,以提升性能;
由于TAB_T2过滤后的数据量小,而TAB_T2的数据量大,这就满足小表关联大表的场景要求,此种场景下,USE_NL的性能是可观的。
一切似乎都是美好的,突然,我意识到这个方案有一个致命的缺陷,那就是过程数据量。
在SQL中有个ROW_NUMBER的分析函数,要知道,分析函数的性能对数据量是非常敏感的。在原SQL中,ROW_NUMBER分析函数的数据量是TAB_T2表,而在去子查询的改写SQL中,ROW_NUMBER分析函数的数据量则是TAB_T1和TAB_T2关联后的结果集。如果关联关系是多对多的,那么关联产生的过程数据量将是不可预估的,同样对性能的影响也是灾难性的,虽然TAB_T1和TAB_T2的关联方式为NESTED LOOP。
这样一想,真是被吓出了一身冷汗。我立马找到TAB_T1和TAB_T2的关联条件:HDID_C = TA.APLTNN_C。这里,需要确定APLTNN_C的唯一性,如果TAB_T1表的APLTNN_C是唯一的,就不会产生多余的过程数据量,否则必然会“泛滥成灾”。
我查看了TAB_T1的表结构,很遗憾,在APLTNN_C上没有创建唯一性的约束。那么就意味着这个去子查询的等价改写就此被宣告“流产”。
但是,我的等价改写之心还没有死掉,我还要继续尝试等价改写。
SQL等价改写的基础是要彻底读懂SQL代码背后蕴含的逻辑功能。那么这个SQL的逻辑功能是什么呢?
再次审视这个SQL,一行一行代码看下去,发现这是一个很特别的SQL:
SELECT的字段全部来自TAB_T1表,没有从子查询R中获取字段;
R子查询与外部表TAB_T1表的通过INNER JOIN关联。
从上可知,子查询R只具有过滤功能。那么通过INNER JOIN过滤了什么数据呢?
子查询R与外部表TAB_T1的关联条件是:R.HDID_C = TA.APLTNN_C AND R.RN = 1。我们根据谓词推入法推演一下逻辑功能:
如果外部表TAB_T2的某条APLTNN_C,其对应的HDID_C在TAB_T2中没有记录,那么通过INNER JOIN,该条记录就会被过滤掉,因为它不满足R.HDID_C = TA.APLTNN_C这个关联条件;
如果外部表TAB_T2的某条APLTNN_C,其对应的HDID_C在TAB_T2中存在记录,可能是一条,也有可能为多条。这就满足了第一个关联条件:R.HDID_C = TA.APLTNN_C。此时,子查询中ROW_NUMBER分析函数得到的结果肯定是大于或等于1的,这也就是说满足了第二个条件RN=1。
我们可以举例说明下,比如TAB_T1表中,APLTNN_C字段有三个值,分别是100、101、102,而在TAB_T2表中HDID_C只有两个值,其中100对应三条记录,而101对应一条记录,如下:

那么TAB_T1和TAB_T2关联后的结果,就只剩下100和101,因为只有100和101的RN有1的值。
这样一分析发现,原来这个看起来非常古怪的SQL,其本质是非常单纯的,其功能就是查询TAB_T1的数据,其条件是除了WHERE TA.ATPY_C = 1 And TA.CACSS_C = 10001外,还需要满足其APLTNN_C必须在要TAB_T2中存在,对应的字段为HDID_C。
我想,看到这里,如果要你来写这个SQL,我相信十之八九的人会写成这样的:
SELECT TA.*
FROM TAB_T1 TA
WHERE TA.ATPY_C = 1
AND TA.CACSS_C IN
(SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+'))
AND EXISTS
(SELECT 1 FROM ESF.TAB_T2 L WHERE L.HDID_C = TA.APLTNN_C)
没错,子查询R完全可以由EXISTS来等价改写。再看执行计划,果然对TAB_T2的访问又回到了INDEX RANGE。执行计划如下:
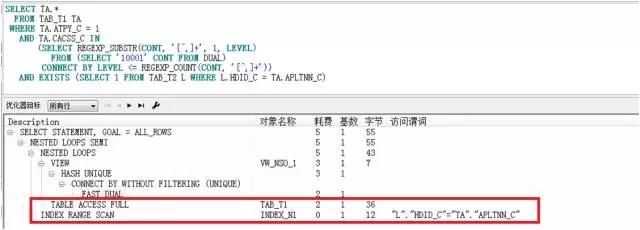
我将上述方案提交给提问者,我想这次总该满足要求了。但是,我得到的答复却是:不行。原因是他在提问中贴出来的SQL仅仅是个片段,整段SQL是非常复杂的,而且随着查询条件的变化,整段SQL也会发生相应的变化,因此,最佳的方案就是在不改变SQL的情况下提升性能。
看来,这次真的是遇到麻烦了,而且是大大的麻烦了。
当下,我想着,要弄清楚为何使用了IN子查询的时候,谓词推入会失效?即便是增加了HINT/*+ PUSH_PRED(R)*/。
再次回到提问的内容,说是正则表达式导致了不走索引扫描。通过分析,发现不走索引的直接原因是执行计划没有采用谓词推入的方式。也就是说,问题可以转换成:正则表达式导致了谓词推入失效。当时,我就想,正则表达式仅仅是一个运算符,应该不至于干扰到谓词推入。于是,我将目光移到了子查询最后一行代码:CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+')。会不会是这个递归查询惹的祸呢?
我将CONNECT BY递归查询注释掉,再看执行计划:
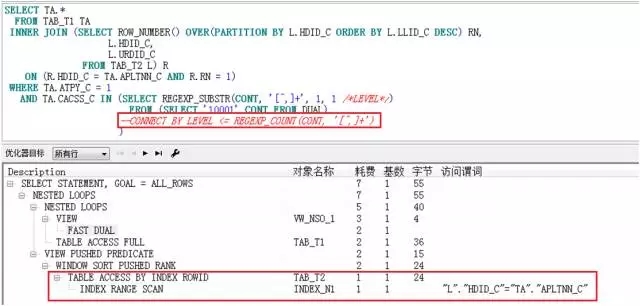
果然,注释掉CONNECT BY递归子查询后,又回到了INDEX REANGE SCAN。由此来看,其罪魁祸首应该是CONNECT BY递归子查询才对。
因一个不经意间的注释,似乎于黑暗中又看到了丝丝光明。
分析到这里,我还是比较兴奋的,找到了问题的根本点。接下来,我就要正面直视这个包含了递归查询的IN子查询,看看这个子查询到底是实现了什么样的逻辑功能?
SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+');
这个SQL的写法是有一定讲究的,它其实是为了实现行列转换:
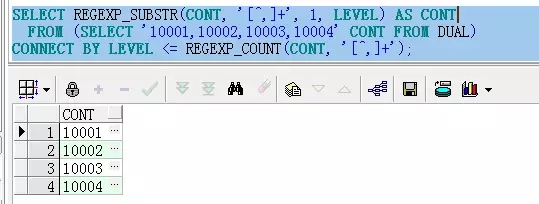
也就是说,这个正则表达式的目的就是将一串由逗号分割的字符串转换成一个结果集。也就是说,如下的IN子查询:
TA.CACSS_C IN
(SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001,10002,10003,10004' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+'))
完全等价于:TA.CACSS_C IN(10001,10002,10003,10004)
这种写法,我也曾遇到过,诸如'10001,10002,10003,10004'常量是由前端应用传入的,由于传入的是一个字符串,如果直接写成TA.CACSS_C IN('10001,10002,10003,10004'),显然是不能实现过滤功能的。所以就只能通过这个子查询来实现过滤。其实,在执行SQL前,完全可以由前端应用java程序来分解'10001,10002,10003,10004'这串字符串。一个简单的for each就可以实现了,但是为了少些代码,开发人员便将这种分解推给了Oracle。
我想,如果真的是为了性能,做这样的改动应该不致于被拒绝吧。于是,我将该方案提交给提问者。同样的,也被提问者否定了。给的理由是:这种参数传递是框架内置的,框架的代码不是你想改就能改的。
好吧,我承认,以我的能力,还不能推动框架性代码修改。
此时,我并没有因为提问者的否定而火急火燎抓头搔耳,反而变得异常冷静,因为至此,我能做的,就是继续探究:为何一个递归子查询会导致谓词推入失效?希望能从中找出问题的根源,从而制定一个可行的优化方案。
为了便于分析,我在本地环境模拟了问题,附件《数据准备脚本.sql》为本地环境数据准备脚本(点击文末“阅读原文”即可查看)。
我们先来模拟index rangescan的场景:
SELECT *
FROM EMP E
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY JOB ORDER BY CREATE_DTIM DESC) RN,
JOB
FROM JOBS J) R
ON E.JOB = R.JOB
AND R.RN = 1
WHERE E.DEPTNO = 20
AND SAL IN (SELECT '800' CONT FROM DUAL);
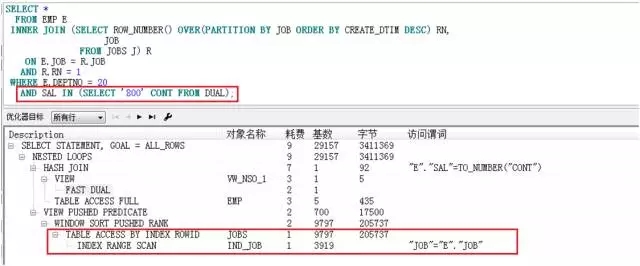
再模拟IN子查询包含CONNECT BY递归查询的场景:
SELECT /*+ push_pred(r)*/
*
FROM EMP E
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY JOB ORDER BY CREATE_DTIM DESC) RN,
JOB
FROM JOBS J) R
ON E.JOB = R.JOB
AND R.RN = 1
WHERE E.DEPTNO = 20
AND SAL IN (SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '800' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+'));
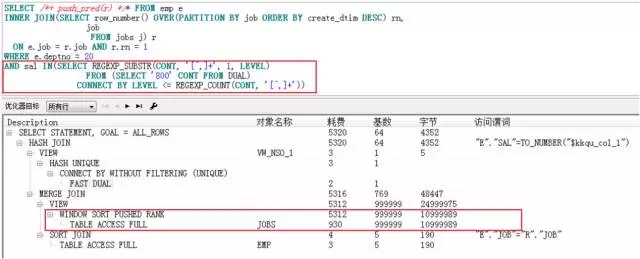
我们发现hint/*+ push_pred(r)*/并没有生效。
在确保模拟的可用性后,我首先收集了10046事件(点击文末“阅读原文”详见附件“10046.txt”),但是,从内容上,并不能看出所以然来。与此同时,我也向社区其他专家发起了求助。借助社区其他专家,我得到了如下信息:
向Oracle技术支持求助,其建议利用SQLT收集全部执行计划,但在结果中,并没有发现有PUSH PRED的执行计划;
于是,我转而收集了10053事件(点击文末“阅读原文”详见附件“10053.trc”)。我采用对比分析法,即对比有谓词推进和无谓词推进两个SQL的10053事件。我发现:
1、在谓词推进的SQL中,SQL最终被等价转换成如下:

2、在无谓词推进的SQL中,SQL最终被等价转换成如下:

3、可见,在等价转换时,两个SQL的转换逻辑都是一样的,即将IN子查询的半连接转换成了全连接;
4、能推入谓词的SQL,在PM的时候,内容为:
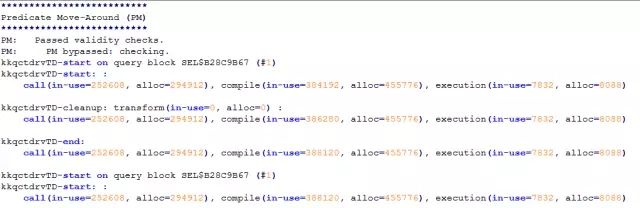
5、不能推入谓词的SQL,在PM的时候,内容为:

看来,谓词推入果真是受START WITH/CONNECT BY的影响。至此,我也是绝了优化之心,彻底放弃了,心不甘情不愿地接受了这个无情的事实:第一次受邀解决问题,就这样无疾而终。
此时,我灰头土脸地跟提问者说明了我了解的一切。我当时并不清楚我是否已经表达清楚了,也不知道提问者是否真的明白了我所说的。总之,在提问者一头雾水的脸及“哦”“哦”“哦”的应答中,我就像一个心虚的答辩者,希望尽早结束这一切。
写此文纪念这次不成功的优化经历,目的在于:
1、优化并不是绝对的,优化的结果会受很多因素的影响,而其中最大的因素便是人,不同的人,优化的方法和手段会不一样,优化的深度也会有差异。此案例,我相信,不成功,是因为我的道行还不够高,对Oracle的认知还不够深。换而言之,我相信,该案例肯定是有优化之道的。
2、再次验证了性能优化空间是线性的,通常性能优化收益图例如下:

优化空间包括:优化手段、优化方法、性能收益等。
3、SQL往往扮演了“背锅”的角色。从业务用户感知应用响应迟钝,到确定SQL出现性能瓶颈,这中间,不知道经过了多少层代码结构。但,最终,被人们记住的总是那条出现性能瓶颈的SQL,而忽略了导致这条SQL性能瓶颈的大环境大因素,这其中的原因很多很深很玄妙。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721