
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
谨以该优化方案,纪念里约奥运会中国女排4强赛战胜巴西女排。
2016年8月17日,这本是一个平常的日子,如果硬是要与其他重要事件关联在一起,那就是里约奥运会了。或许是08北京奥运的疯狂激奋严重透支了国人的奥运热情,而产生了审美疲劳;也或许是在经过几代人的奋发图强,国人不再需要奥运金牌数量来证明自我,从而看淡了奥运赛场的剑拔弩张人喊马嘶。而与我而言,是由于工作、家庭的缘故,无暇奥运。
中午小憩后,将醒未醒中打开电脑,一封未读邮件让我瞬间惊醒睡意全无:
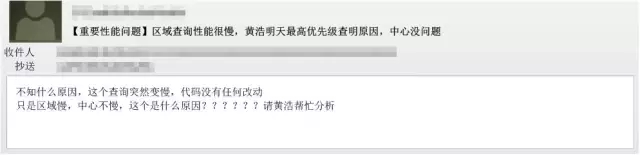
从邮件内容看,透露了如下几个信息:
是突然变慢:也就是说在此之前是没有性能问题的,性能问题是突然性的;
代码没有改动:也就是说本次性能变慢并非代码变更引起;
区域慢,中心不慢:也就是说同样的SQL,在不同的DB服务器上性能表现不一样。
我首先想到的是执行计划走偏导致的,因为第一点和第二点很符合执行计划走偏导致性能问题的表象。于是,我找到开发人员拿到了SQL,SQL如下:
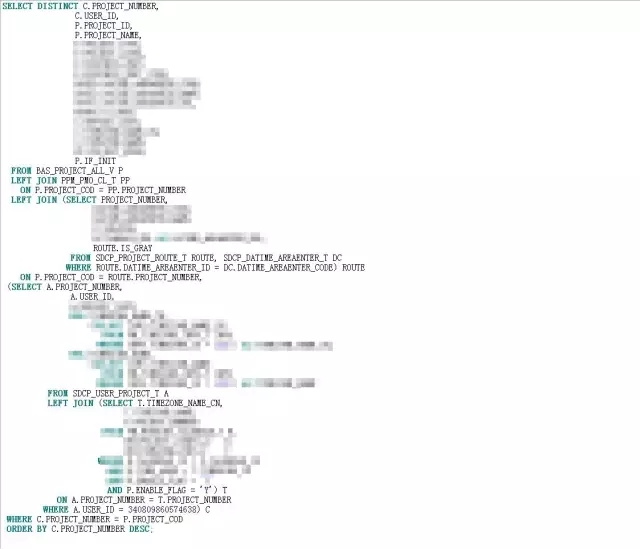
通过SQL TEXT,我找到了SQLID,从ASH获得的信息如下:
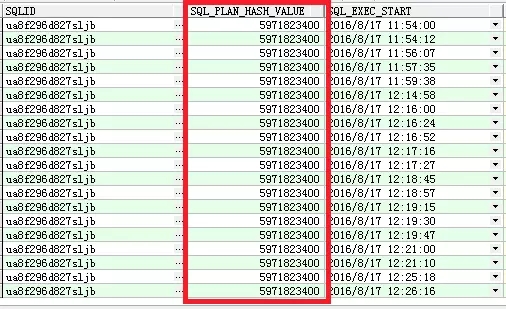
从ASH中我们发现:执行计划很稳定,并没有发生“走偏”的异象。
难道是数据量发生了变化,导致了性能的突然变慢?
正当我计划咨询相关人员的时候,ESPACE弹出了消息,是多人讨论组,里面的人员名单中有开发人员、SE及性能测试人员。经过一番你来我往的讨论后,信息归纳如下:
这是个查询基础数据的SQL,数据量并没有发生变化;
由于是基础数据,原始数据都是存放在中心库,各个区域库是通过OGG同步,因此,中心库和个区域库的数据量是一样的;
经确认,所有的区域库都变慢了,而中心库则很好很快;
在变慢之前,没有做任何的代码变更;
由于一线业务对首页加载突然变慢很不适应,影响面非常广,因此勒令务必在当天予以解决;
同样的代码,同样的表,同样的数据量,为何中心和区域性能相差这么大?因此,SE要求在不修改代码的基础上解决该问题,很明显,他认为这不是代码的问题。
在上述6条信息中,第5条信息是最要命的,我瞄了下屏幕右下方,发现当时已是14:26,离下班只有3个半小时。而至于第6条的要求,我心里面已经有了解决方案的腹稿。
在排除了执行计划走偏、数据量变化的因素后,我把目光瞄准了“中心快,区域慢”这一现象。于是我决定对比下中心和区域的执行计划,看是否一致?
区域执行计划:
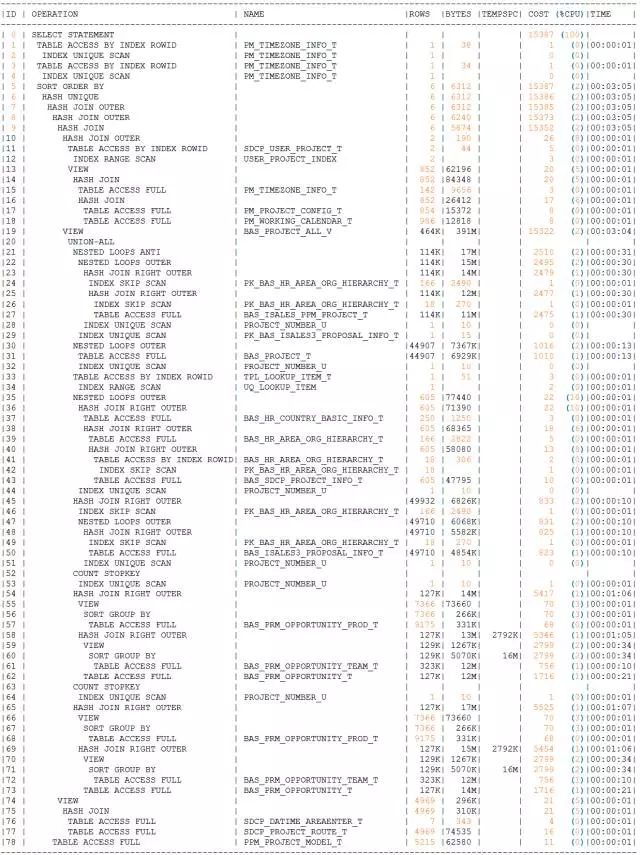
中心执行计划:

果真,两个执行计划有明显的偏差:
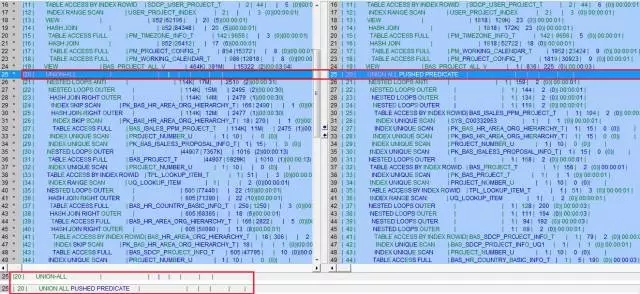
而在差异中,最扎眼的莫过于执行计划的第20行,区域环境是UNOIN ALL,中心库是UNION ALL PUSHED PREDICATE。即中心库对VIEW做了谓词推入,而区域库则没有,而这个视图就是臭名昭著的该死的BAS_PROJECT_ALL_V。
由于SQL返回的结果集很少,一般都是在50条以内,所以对该视图进行PUSHED PREDICATE是最优方案。从执行计划中的COST中也可以看出,中心库在VIEW上的COST消耗为225,而区域库的消耗竟达到了15322,相差两个数据量级,套用对中国足球的评语“想不输都难”,区域库“想不慢都难”呀。
区域库和中心库执行计划的差异是我想要的结果,因为有了这个结果,才能实施我的方案:绑定执行计划,即将中心库的执行计划绑定到区域库。我将临时方案与SE沟通后,SE同意先通过绑定执行计划的方式解决一线业务的性能之需。于是我将SQLID及PLAN_HASH_VALUE发给DBA,由DBA通过SQL_PROFILE的方式将中心库的执行计划绑定到了区域。
至此,按照正常的剧情设计,接下来的画面应该是这样的:通过绑定执行计划,区域的性能得到飞速提升,临时方案不战而屈人之兵,兵不血刃的完成了优化,开发人员、SE、测试人员、一线业务人员都皆大欢喜。而接下来的就可以有充裕的时间来分析区域库不进行谓词推入的原因,从而从根本上解决性能问题。
但是,生活终究是没有剧本的。
当DBA通过SQL_PROFILE完成绑定后,测试人员则反馈:还是不行,感觉更慢了……原来是4-5秒,现在出不来。什么情况?剧情也太反转了。DBA懵了、SE懵了、我也懵了:没道理呀!!!!DBA赶紧回滚,我再次去到区域库,当我看到执行计划的时候,我和我的小伙伴惊呆了,执行计划中明明显示是绑定了执行计划的:

但是,谓词却没有被推入。绑定执行计划的方案最终以失败告终。经过这一番折腾,时针转到了4点半的方向,仍然是套用评论中国足球的一句话“留给中国队的时间不多了”。
又回到问题的本质,影响Oracle执行计划的是COST计算,而COST的计算基础则是表的统计信息、索引、数据分布等因素。因为区域的数据是通过OGG从中心库同步过来的,因此数据分布应该是一致的,否则就不是性能问题,而是更严重的功能问题了。我收集了该SQL涉及到的所有表对象,通过对比两套环境,发现区域的统计信息和中心基本上是一致的;而索引也是一致的。为了确保万一,DBA手工对这些表对象进行了一次统计信息收集。而Oracle依旧无动于衷,固执的抛弃了“谓词推入”,即便是在SQL中加上/*+ push_pred(p)*/hint。
情况变得越来越复杂,越来越糟糕,越来越不可控。
就在百思不得其解,一筹莫展之际,DBA发来了一封邮件,内容如下:
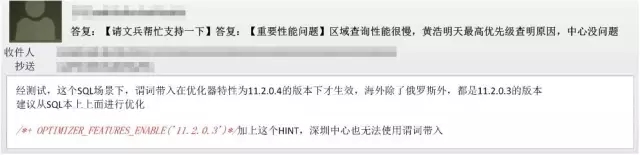
意思是说:造成中心和区域执行计划不一致的原因是Oracle的版本不一致,针对视图这种场景,中心库的版本高,支持谓词推入;而区域库的版本低,不支持谓词推入。
这封邮件并没有解决问题,但是却价值千金,因为它证明了:在区域库现有版本的基础上,很难通过后台技术(比如绑定执行计划)来完成优化。
SE也无奈的接受了DB的建议:从SQL上进行优化。而此时,时针又顺时针方向移动了30°,也就是说我必须得在半小时内完成SQL优化。
看着这个SQL,有种似曾相识的感觉,一打听,才知道上次也优化过一个类似的SQL(详见《从SQL改写到SQL重写,什么样的SQL才是好SQL?》)。我对比了下两个SQL,天呐,这哪里是类似呀,此前案例中的SQL包含两部分数据,如图:
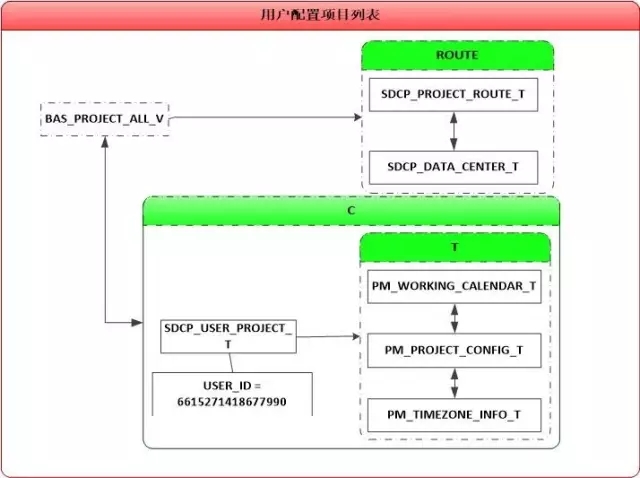
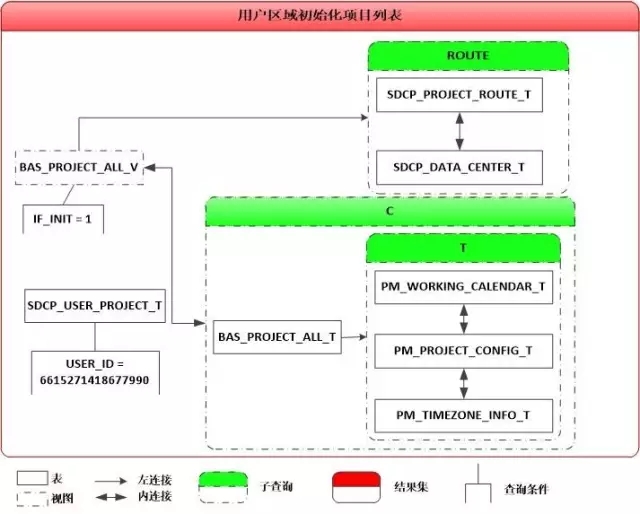
而这个SQL就是“用户配置项目列表”的代码呀:
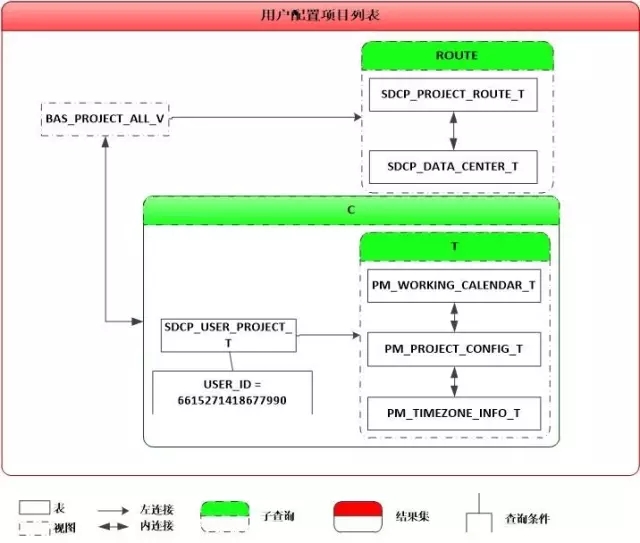
我立马找到上次优化的SQL,一对比,果然99%的吻合。于是我沿用上次优化后的SQL,重新改写了该SQL:




一执行,飞快秒出。
客户虐我千百遍,我待客户如初恋。我赶紧将这个SQL提交给了SE,满以为可以定气收工了。但是SE看了SQL后,说了一句:这个SQL改动太大了,存在很大的风险。言下之意就是否决了这个优化方案。而此时,时间已经走到了17:45,距离下班只剩下15分钟,此刻,我能感觉到手心都渗出汗来了。15分钟,已经没有时间再与SE争论方案的可靠性(上次的优化方案已经实施了一段时间,足以证明方案的正确性),我必须要在15分钟内找出一个更保险的方案。
还得回到功能逻辑上。这个SQL是根据USER_ID获取所属的PROJECT_NUMBER列表,然后再通过视图BAS_PROJECT_ALL_V中匹配某些属性,而显然单个USER_ID的PROJECT_NUMBER的数是非常少的。此时,我灵机一动,心里在想:是否可以先通过with子查询获取该用户的所有PROJECT_NUMBER列表,然后在与视图BAS_PROJECT_ALL_V关联呢?
死马当成活马医。我来不及多想,就改写了这个SQL:


再次执行,1S。再次提交给SE,由于只是将普通子查询改成了WITH子查询,SE认为风险可控。此时时间已是17:58,离18:00只剩2分钟。我长舒了口气,望窗外,路面湿漉漉的,低洼处还明显有积水;而残阳如血,云淡天高。刚过去的一场暴风雨冲刷了炎炎烈日,带来了秋后的丝丝凉意。
在班车上浏览起新闻来,立马被头条吸引住了:中国女排3:2战胜了巴西队。天呐,这无疑是一个奇迹呀,大写的奇迹呀。巴西女排,两届奥运冠军,又坐拥东道主之利,可谓是占尽了天时地利人和。赛前也了解过,中国女排无论是技战术还是大战经验,都不及巴西队,而就是这些被低看的中国姑娘们,用女排魂拼出了一个奇迹,而就在中国女排姑娘们在赛场上“像老虎一样撕咬”巴西女排、“打哭巴西小球迷”时,我也在拼力在为首页加载的性能问题不折不饶。
虽然两者的价值成果不可同日而语,但是其内在的精神是一致的:不到最后不放弃的执着,心无旁骛心力齐的专注,排除万难大无畏的拼搏,不到楼兰死不休的勇气;有的时候,的确需要一股子狠劲,一股子对自己的狠劲,这样才能激发自己的潜能,去完成不可能完成的任务。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721