
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
这个案例的主体是视图,在总结这个案例的时候,我想起了在一次以DB性能为主题的讨论会上,当谈及到视图对性能的影响的时候,主持人抛出一个问题:在数据里面,是不是视图越少性能越好。其实这个问题可以理解成这样:视图会不会影响到性能?当时,我的观点是:视图的存在不是由性能决定,而是由功能及模型架构决定的。视图影响到性能这本身就是个伪命题,因为数据库中的任何对象都有可能影响性能。由于视图本身就是一堆SQL代码,Oracle在制定执行计划的时候,会展开视图中的代码。因此,如果存在性能问题,我们可以通过SQL HINT来干预,从而实现性能优化的目的。
事实上,在大多场景下,我们的确可以通过SQL HINT这一手段来实现性能优化之目标。但是,今天要讲的案例显得有些另类:明明可以通过SQL HINT轻轻松松快快乐乐地提升性能,但是因诸多原因,不得不放弃SQL HINT,不得不调整视图结构,以适应Oracle的优化器,制定出高效的执行计划。
下班前的不速之客
某天,临近下班的时候,准确一点是17:08,桌面右下角的托盘弹出了新邮件提醒,看标题是“B3-SQL查询慢问题”,很显然这是跟我前相关的邮件,打开了邮件,内容截图如下:
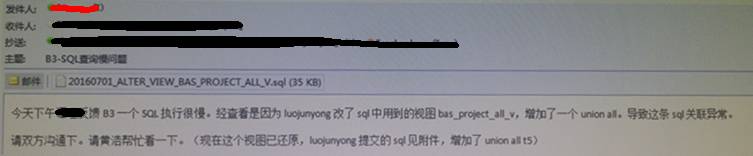
总结成一句话就是:一个视图的更新,在原本平静的性能湖面泛起了阵阵涟漪。
DBA很负责任,还贴出了业务SQL在视图更新前后执行计划的对比图:
视图变更前的执行计划:

视图变更后的执行计划:

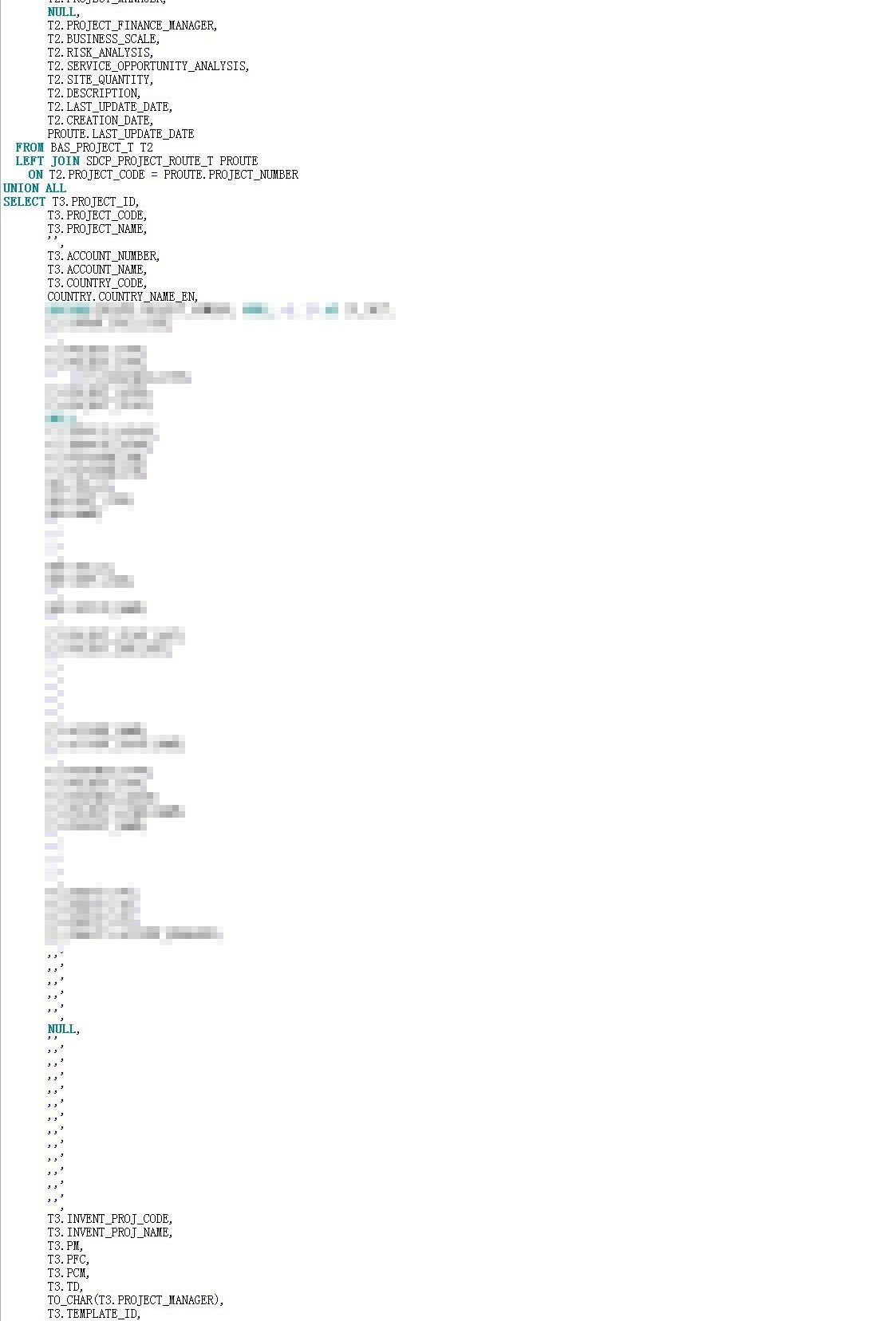
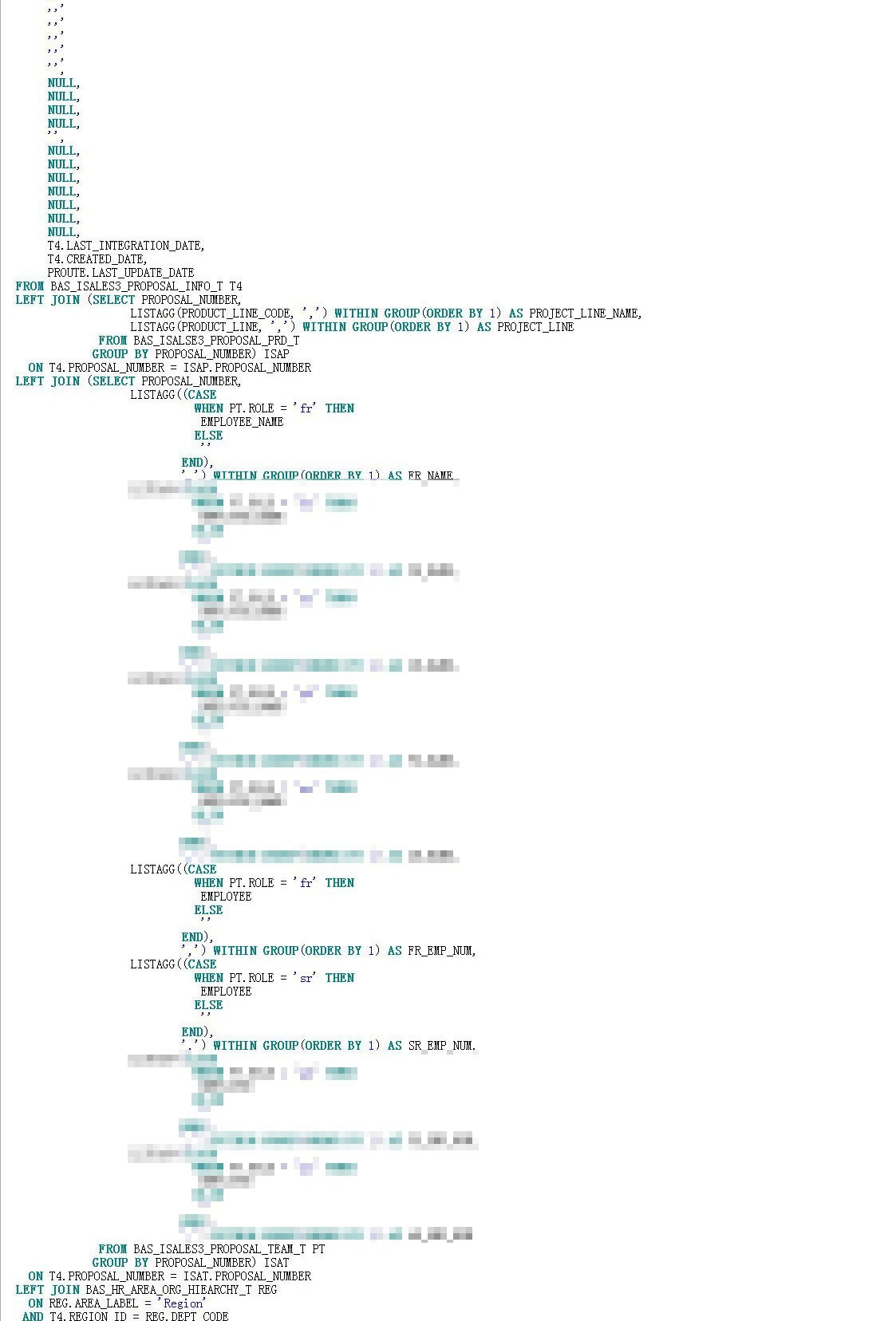
其中BAS_PROJECT_ALL_V就是本次优化的主人公,其代码长达近700多行:





复杂的问题简单化
从执行计划对比结果上看,很明显是的区别是在连接方式上,视图变更前,视图与外部结果集的连接方式是NESTED LOOP,而变更后,视图与外部结果集的连接方式变成了HASH JOIN。此时,心想着,是否可以通过hint来实现NESTED LOOP呢?因为DBA截图中很多内容被收缩,因此还需要亲自查看下完整的执行计划,因为除了简单的连接方式变化外,连接顺序也发生了变化。
详细的执行计划对比如下:
视图变更前的执行计划:
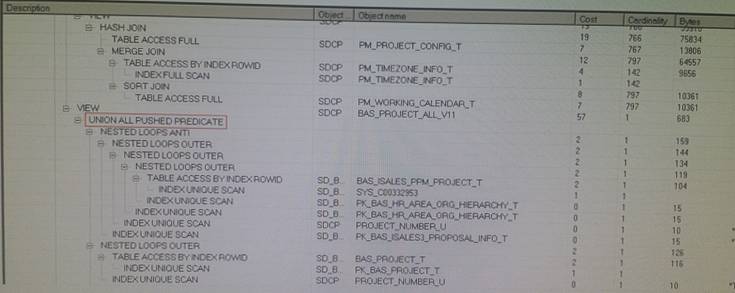
视图变更后的执行计划:
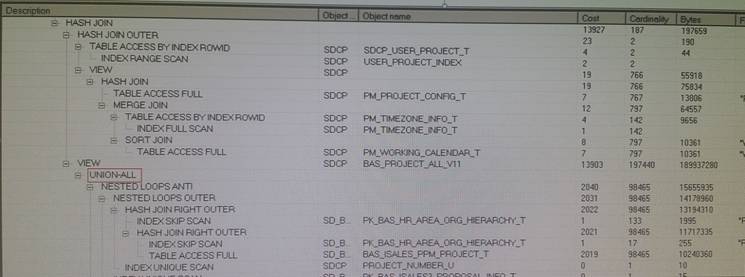
从对比结果上看,前后的差异非常明显,视图变更前是谓词推入,而视图变更后没有做谓词推入。而从结果数据集看,只有2条数据,这也合乎谓词推入的场景。于是我在SQL中增加了/*+ push_pred(p)*/ HINT,强制谓词推入,执行效率果然又回到了秒出的速度。因为已临近下班,没有更多的时间来分析原因,因此,我回复邮件:
一不留神杀气四起
第二天早上一上班,我就接着昨天的结果继续分析不做谓词推入的根本原因。这倒不是兴趣使然,并不是因为我的好奇心促使我一探究竟,而是根据我在该项目上的经验,想这种通过hint来解决性能问题的做法,多半是不被采纳的,至少你得要解释下原因。果不其然,正当我展开架势抽丝剥茧之际,开发人员直接到我的位子,表示了他们的诉求:增加SQL HINT固然能解决该SQL的性能问题,但是这种解决方案的实施性不高,原因是该视图是基础视图,大量的SQL在访问该视图,不可能对每一个访问该视图的SQL都增加SQL HINT。
这个前因后果有理有据,我完全可以理解。但是接下来的一句话,却让我嗅到了腾腾杀气:如果不能从视图上解决性能问题,这个版本的视图变更我们将选择取消。嘛意思,言下之意就是到时候视图变更取消的原因将会被描述为:引发的性能问题不能得到解决。
一顿折腾,各种乱炖
在之前的优化案例中,也曾与该视图相逢,大致明白该视图是个基础数据集,集成了多个来源的project基础数据。而根据邮件中的描述,本次变更是增加了一个数据源的数据集成。于是我打开了视图代码,500多行的代码,这也够狠的。我将鼠标定位到了新增集成部分的代码,如下:

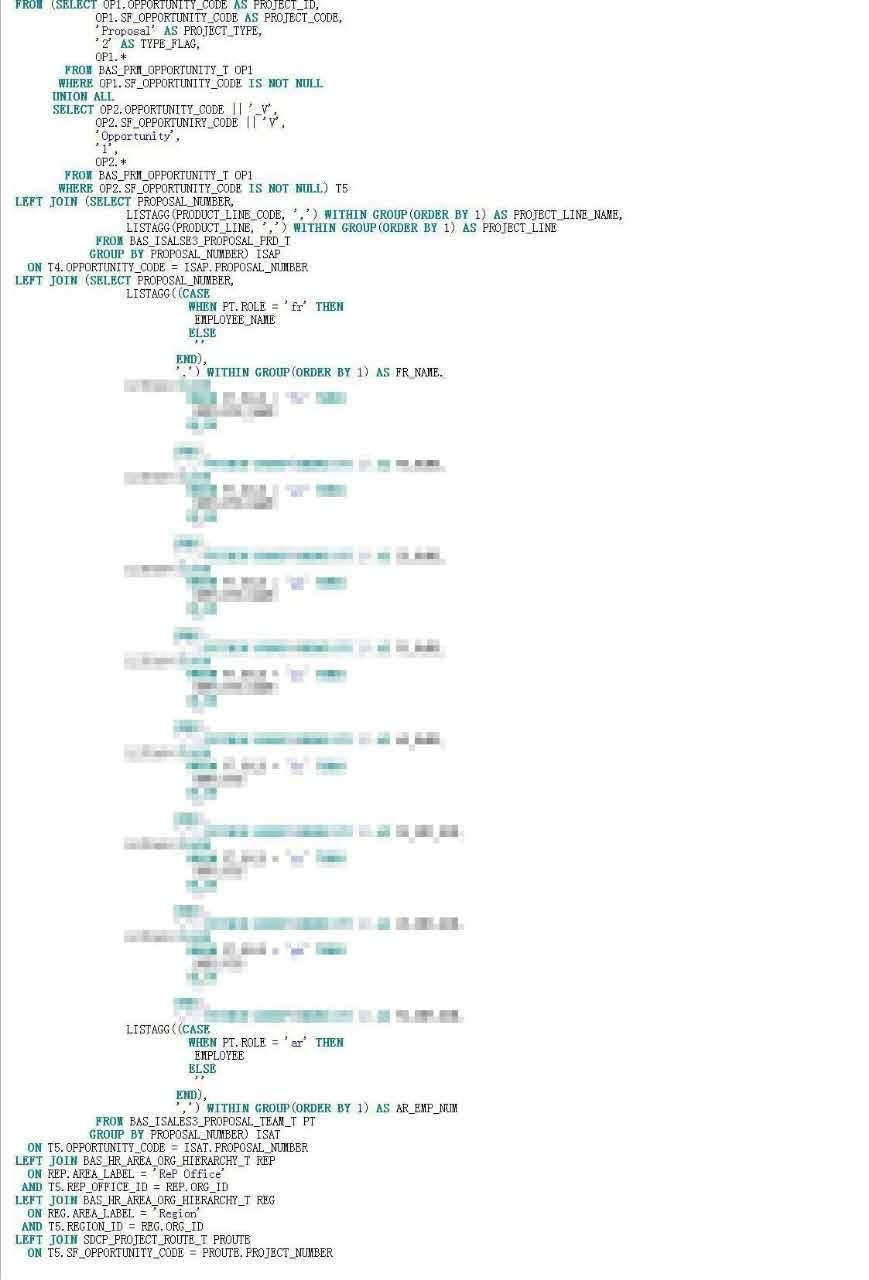
这段代码,首先吸引我的是T5子查询,即:
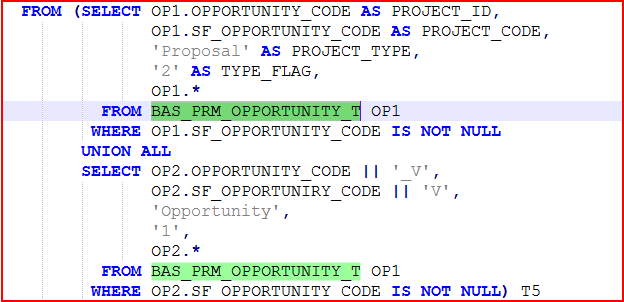
因为这个子查询是一段unoin all,而事实上unoin all的表对象都是BAS_PRM_OPPORTUNITY_T ,而且条件都是一样的,也就是说这个子查询是将一个结果集拷贝了两份。
以下是当时的天马行空神游四海的过程:
会不会是union all导致的呢?注释掉unoin all,发现问题依旧。继而又突发奇想,难道是视图中unoin all的数量干扰了执行计划?我把整个T5的这部分数据集成替换成了T4数据集成,也就是视图中,T4的数据被集成了两次,再执行,发现执行计划中出现了谓词推入。自此,有一点是可以肯定的了:谓词未推入,与新集成的表BAS_PRM_OPPORTUNITY_T 有关。我立马查看了该表的数据量,发现并不大,才7千多条?是碎片吗?我重建了表,发现问题依旧。既然不是数据问题,那就有可能是模型问题。再结合pushed predicate的原理:Oracle之所以会选择pushed predicate,是因为“有利可图”,利在何处?当然就是能快速根据谓词获取记录,在什么情况下能快速根据谓词获取数据?当然是在走索引。
我赶紧打开表BAS_PRM_OPPORTUNITY_T 的模型结构,如下:

该表只有一个unique index,再回过头看下外部SQL与视图关联的字段,是SF_OPPORTUNITY_CODE ,也就是说连接条件字段上没有创建索引。问题的原因应该就是这个了,因为没有索引,Oracle当然有可能认为谓词推进非最佳选择了。
不仅仅是索引缺失
既然诊断是索引缺失引发的性能问题,那就根据需求创建索引,脚本如下:
CREATE INDEX ind_BPO_n1 ON BAS_PRM_OPPORTUNITY_T(SF_OPPORTUNITY_CODE);
CREATE INDEX ind_BPO_n2 ON BAS_PRM_OPPORTUNITY_T(SF_OPPORTUNITY_CODE||'V');
创建了索引后,再次查看执行计划,仍然没有做谓词推进,Oracle依然顽固的舍弃了谓词推进,即便是重新采集了表的统计信息。这简直让人抓狂,问题到底是出在哪里呢?
还得要分析下执行计划,看看Oracle是如何做的?如下:
从执行计划上看,在集成BAS_PRM_OPPORTUNITY_T数据源时,oracle提前做了union all,即代码中的:

如果注释掉其中一个union all呢?执行计划如下:
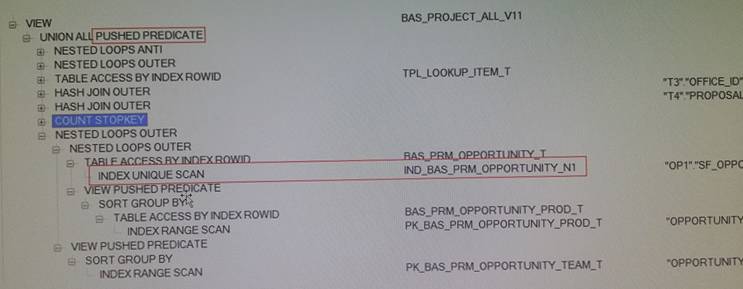
哈哈,又回到了pushed predicate,索引也用上了。那么从执行计划上看,是由于在集成BAS_PRM_OPPORTUNITY_T数据源时,嵌套的UNION ALL干扰了ORACLE的执行计划。
现在要做的就是将嵌套的UNION ALL提出来,重写视图的代码(代码见附件 BAS_PROJECT_ALL_V_第一次优化.txt),前后的逻辑简化如下:
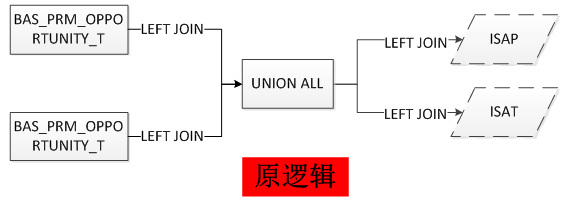
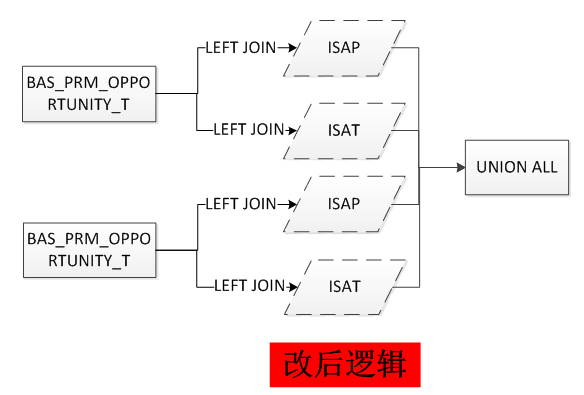
重新编译视图后,执行计划终于回到了pushed predicate。

事情还没有过去
仅过了一天的时间,又收到一份熟悉的邮件,如下:
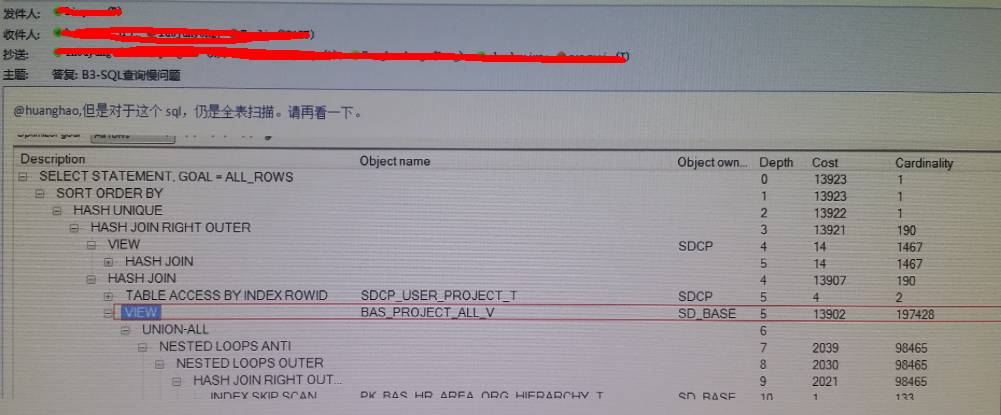
真是怕什么来什么。该死的谓词又没有推进去,又会是哪里出了问题呢?急躁无意于问题的解决,唯有冷静才是解决问题的法宝。深呼吸后,我把目光又聚焦在执行计划上,看看执行计划到底发生了什么?
当我找到BAS_PRM_OPPORTUNITY_T数据源时,发现居然又内嵌了一个union all,如下:

昨天明明是已经将嵌套的union all提到了最外层,难道是视图又被覆盖回去了?这种可能性相对较大,赶紧view了视图代码。很是让人沮丧和失望,因为代码并没有被覆盖。那就是说,我得要继续与视图,与Oracle搏斗了。
顺着性子,牵着鼻子
顺着执行计划往下看,当看完这段执行计划后,Oracle的心思也“昭然若揭”。这还得从代码的逻辑结构说起,简化如下:
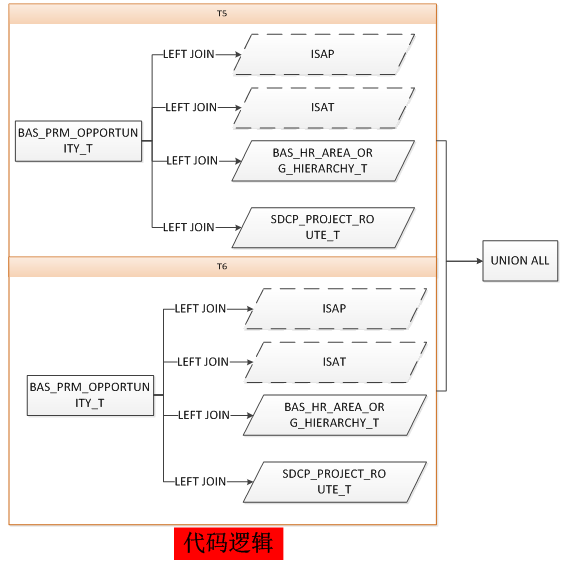
从上图可以看出,代码逻辑中,两段union all的数据是独立的,尽管各自LEFT JOIN的对象及关联条件都是完全一样的。但是Oracle的执行计划却破坏了这种独立性,执行计划的逻辑结构如下:
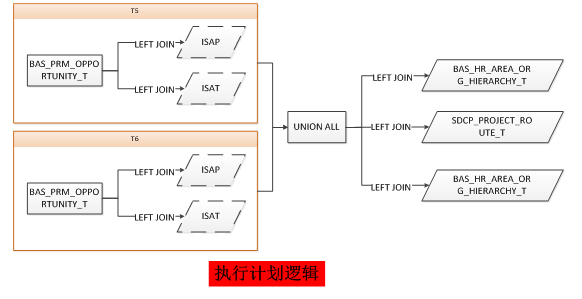
Oracle在制定执行计划的时候,将BAS_HR_AREA_ORG_HIERARCHY_T、BAS_HR_AREA_ORG_HIERARCHY_T、SDCP_PROJECT_ROUTE_T三个对象剥离出来,强制将BAS_PRM_OPPORTUNITY_T与ISAP\ISAT视图关联的结果集union all形成一个VIEW后,在与这三个对象left join。我们不得不佩服oracle优化器的强大,这种改写是有明显的收益,改写后,三个对象只需要各自访问一次,而改写前是需要分别访问两次的(至于为何不将IASP\ISAT两个子查询也一并剥离出来,我想ORACLE也懂得“柿子挑软的捏”这个中国式道理,毕竟对视图的分析要比单表的分析复杂得多)。很明显,强大不等于高效。这次Oracle优化器是好心帮倒忙。
接下来就是如何通过改写SQL,已达到破坏掉Oracle“自作聪明”的改写?
在受到子查询ISAP\ISAT成功避开Oracle优化器改写的启发,我就想着能不能将三个left join的对象也分别封装成子查询呢?而事实上,简单的select * from table子查询也无法逃脱被优化器改写的命运。此路不同,只能另觅他方了。既然表值子查询不行,那么是否可以尝试下标量子查询呢?分析了视图的代码,发现三个对象完全满足标量子查询的条件:
三个对象的关联字段都是唯一键,也就是说结果集的唯一性得到了保证;
三个对象的关联方式都是left join,也就是说改成标量子查询不影响结果集数据量;
SQL从三个对象中只获取了一个或两个字段,也就是说不会导致大量标量子查询
有了以上三点的支撑,我将这三个对象的访问改成了标量子查询:


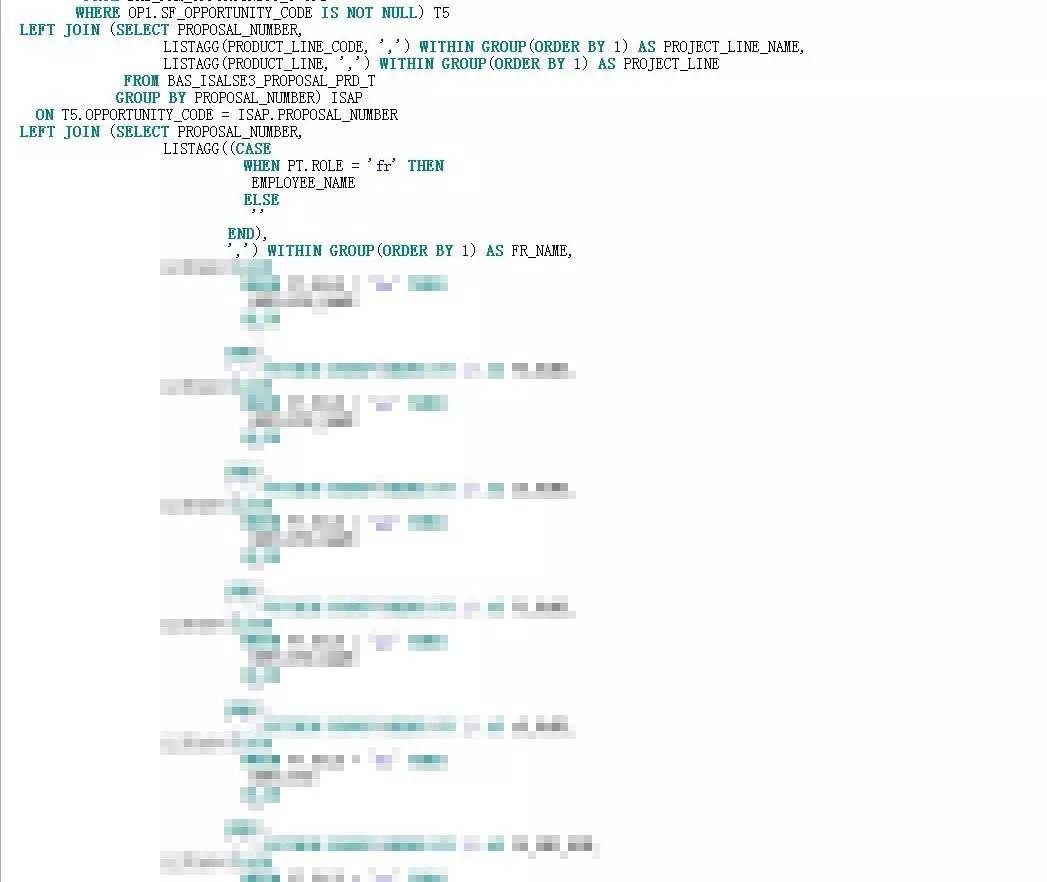

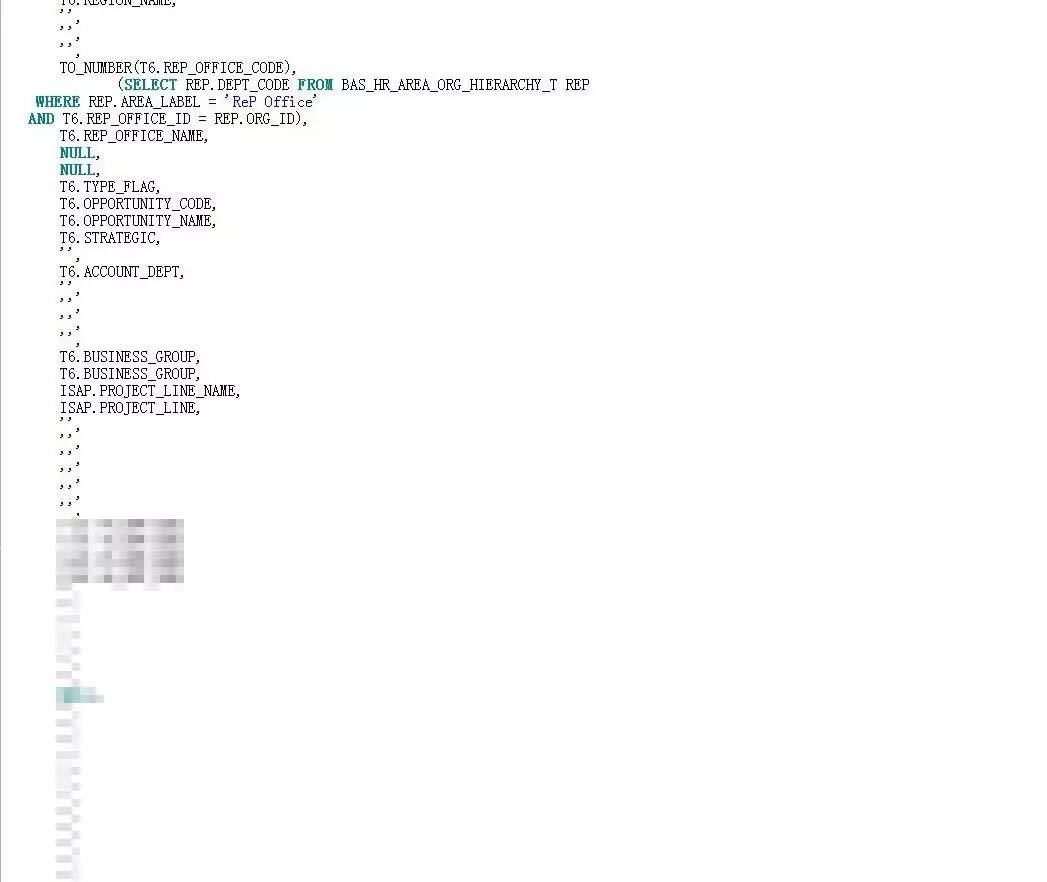


编译了视图代码后,再执行SQL语句,果然又回到了最开始的“pushed predicate”。
总结
视图对性能的影响是什么?
很多时候,开发人员拿着一个视图,让我分析诊断下性能,对此我往往只能从常规性的角度分析,比如是否使用了毫无意义的union、distinct、group by等影响性能的关键字?比如是否出现了冗余的表对象、关联等等。因为每个访问视图的SQL都是有特定的应用场景的,性能也会因不同应用场景而原因不同:
大视图:视图很大(字段多,基表多,条件多),而SQL很小(只访问视图的某几个字段,而这几个字段也来自某几个基表),这样就导致了无效的表关联、表访问。导致这种现象的原因是:因为某种业务场景访问某个视图,而这个视图并非为了这个业务场景量身打造的。随着业务的发展,视图会变得越来越大,而在开发过程中,本着“宁可错杀一千,不可放过一个”的心态,毫无性能原则的使用大视图。就像本案例中的视图,事实上,上述两个SQL都不需要访问新集成的数据源,而恰恰是新集成的数据源导致了性能问题;
深视图:视图嵌套层次太深,这对性能的影响也不容小觑,首先表现在对执行计划的影响,嵌套越深,对执行计划的干扰就越大,执行计划就越是不稳定;其二是对性能分析的影响,嵌套越深,执行计划就越大,对分析带来了难度







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721