
梁敬彬,福富研究院副理事长、公司唯一四星级内训师,国内一线知名数据库专家,在数据库优化和培训领域有着丰富的经验。多次应邀担任国内外数据库大会的演讲嘉宾,在业界有着广泛的影响力。著有多本畅销书籍,代表作有《收获,不止Oracle》。
SQL优化是一个复杂的工程,首先要讲究从整体到局部。今天我们首先学习关于数据库整体优化都有哪些性能工具,接着分析这些工具的特点,并结合案例进行探索,最后再进行总结和思考。
总体学习思路如下图所示:

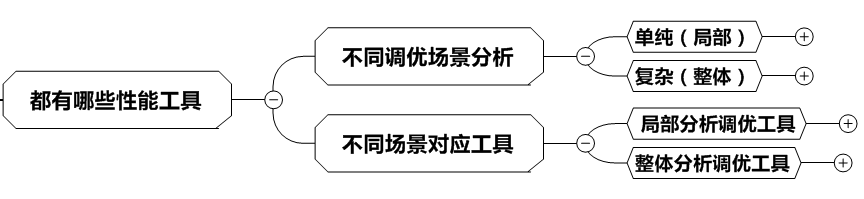
都有哪些性能工具
这里首先要分成两部分:一种是不同调优场景的分析,可分为单纯场景的优化和复杂场景的优化;而另一种是基于这些场景的工具应用,就是针对单纯场景的优化手段和复杂场景的优化手段。
那啥是复杂呢?那就是,刚才那个语句加了索引后,本应该从10s变成0.1s,结果还是10s,甚至变成30s了,这是咋回事呢?原来,现在系统是整体出问题了,数据库主机资源耗尽,啥语句都跑不快的。
还有那个逻辑读在50左右的SQL,如果一天执行几百几千万次,这要是能将逻辑读降低一点,得省多少的逻辑读啊。原来复杂环境真的很复杂,要考虑SQL本身没问题而是被环境影响,还要考虑SQL的执行频率,判断其调优价值与调优空间,这些在单纯的环境里,是不用考虑的。

接下来,我们说说这两种场景对应的工具的使用。关于局部分析调优工具,这个其实就是在说SQL的执行计划了,这是SQL优化最重要的手段之一,通过分析执行计划,我们可以知道SQL语句的访问路径,知道它慢在哪里,从而进行SQL优化。由于在随后的章节中我们会详细介绍执行计划相关知识,这里就不再细述了。
关于整体的调优工具,这里我们先撇开主机、网络、存储等层面的因素,暂时从数据库的整体层面入手。主要工具有AWR、ASH、ADDM、AWRDD这四个工具。其中AWR是关注数据库的整体性能的报告;ASH是数据库中的等待事件与哪些SQL具体对应的报告;ADDM是Oracle给出的一些建议;而AWRDD是Oracle针对不同时段的性能的一个比对报告,比如今天早上9点系统很慢,而昨天这个时候很正常,很多人就想知道今天早上9点和昨天早上9点有什么不同,于是就有了这个报告。
整体分析调优是必需的,那么我们对此的学习也有规律可循。首先是获取系统整体信息的手段,一般通过报告和日志获取。好比破案一样,这就是收集证据的阶段。接下来要找到蛛丝马迹,那就是如何发现问题。在本书中就是需要关注提取到的这些报告的哪些要点、哪些关键字,具体流程图如下:
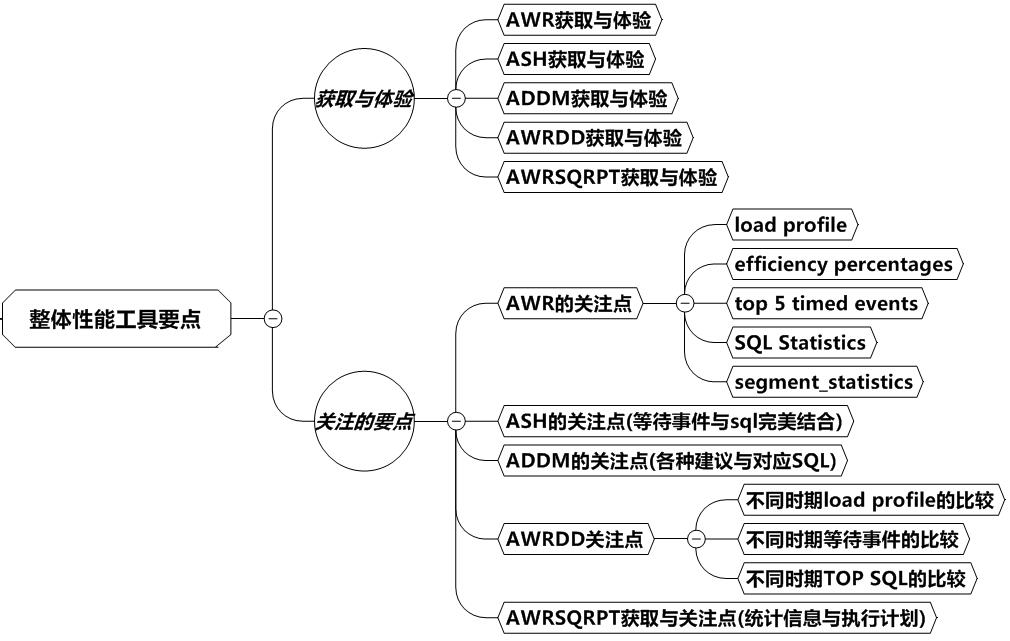
整体性能工具的要点
现代人对健康都比较重视,每年都会进行健康体检。其实数据库性能工具的应用(报告获取和关注要点)和体检是非常类似的。
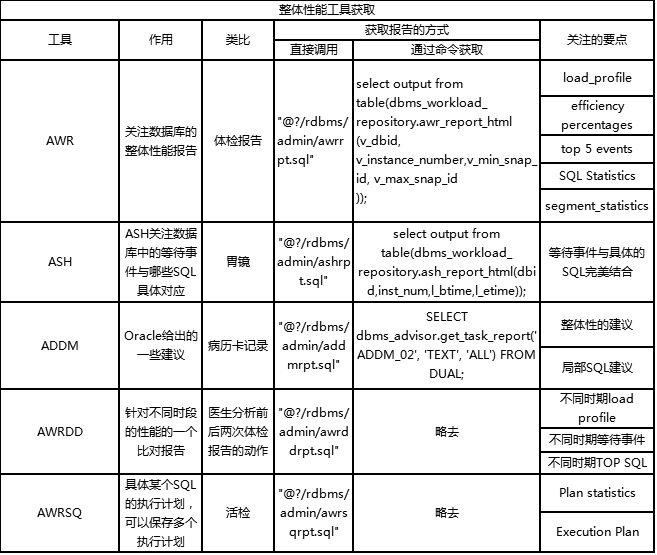
Oracle性能报告分成AWR、ASH、ADDM、AWRDD和AWRSQRPT这5个类型。
什么?这么多,好复杂啊,记也记不住,我不想听不想听!
别急,你只要去医院体检过,你就能听懂。
Really?
我们去医院体检,最终会得到一份体检报告,往往能看到很多总体性指标,这些指标会判断你是否健康。没毛病最好,万一有毛病,报告里要进一步判断是什么毛病,是高血压,还是骨质增生,还是胃有毛病……这就是现实中的体检报告。
而Oracle提供的一种性能收集和分析工具,它能提供一个时间段内整个系统资源使用情况的报告,这个报告里有很多总体性指标来判断系统是否健康。没毛病最好,万一有毛病,问题出在什么模块,是日志切换过于频繁,还是硬解析过大,还是某些SQL相关等待事件在耗资源……这就是AWR报告。这样看来,体检报告和AWR报告非常类似。
假设体检报告说你有胃病,很可能只告诉你胃有问题,却无法告诉你具体啥毛病,因为你手上的体检报告不会详细到拥有你胃部所有相关指标。你要得到这些指标需要做进一步信息收集,那就是胃镜。同样假设你的数据库是SQL相关等待事件问题,AWR报告很可能只告诉你有这个问题而无法告诉你是哪些SQL引发的。你要得到这些指标,想了解具体某些SQL和相关等待事件的对应需要做进一步的信息收集,那就是ASH报告。看来对比胃镜和ASH报告,二者也非常类似。
刚才说的胃病,或许是医生告诉你的,因为上面有很多指标你无法读懂,这时如果你能拿到一张医生的病历卡记录,这里没有指标,只有白底黑字用文字描述的病情,告诉你要如何治疗,那你一定会看得很明白。同样假设,如果将含各种晦涩的指标的数据库体检报告用一些白底黑字的文字代替,用文字直接说明数据库遇到了什么问题,告诉你该如何去优化,那新手一定会看得很明白,这就是ADDM报告。看来病历卡记录和ADDM报告,二者也非常类似。
假如你在一年前也做过体检,并将报告带到了医院,负责任的医生就一定会让你将旧的体检报告也提供给他。他会认真地比对两张报告,查看他关注的健康指标是否有异常波动,这些波动对医生很有参考意义,往往预示着病情的发展趋势。好了,别紧张,这只是比喻。
假设你有系统新旧两个时段的两份AWR报告,负责任的DBA一定会让你将旧的AWR报告也提供给他。他会认真地比对两份报告,查看他关注的数据库指标是否有异常波动,这些波动对DBA很有参考意义,往往预示着数据库性能瓶颈的发展趋势。Oracle提供了一个工具能够将两个时段的AWR报告合并,并能方便地显示出比对信息,这个工具就是AWRDD。看来医生分析前后两次体检报告的动作和AWRDD报告比起来,两者也非常类似。
大家知道做胃镜是一件很麻烦的事(类似ASH报告),如果没毛病就没必要让我们遭这罪。可万一体检报告无情地告诉你胃有毛病,甚至是医生分析你前后两次体检报告(类似ADDM)后告诉你胃病在加速中,你被迫无奈只好去做胃镜了。做完后医生发现你胃部有大量息肉,却无法判断这些息肉是否为良性。于是还要做进一步的检查,这就是活检。不要紧张,平时注意健康生活就好。同样ASH报告判断出某些SQL有问题,却无法得到执行计划等更详细的信息,只能依靠AWRSQRPT去获取这些信息。看来活检和AWRSQRPT报告比起来,两者也非常类似。
最后恭喜你,活检报告显示未产生癌变,只要好好治疗,注意身体,胃就能恢复健康!看本书的读者们,你们都是IT人士,生活无规律加班熬夜者居多,一定要注意身体哦!
对了,还有一件最重要的事没交代。大家似乎搞懂了Oracle五大性能报告,可是这些好东西在哪里才能得到呢?别着急,后续章节马上就会告诉你如何获取这五大性能报告。
如果患者拿着有各种晦涩指标的体检报告来到门诊请教医生,他一定会关注各种指标来判断患者具体是什么毛病。同样你也会对Oracle的性能报告中的各种指标进行关注来判断数据库出了什么毛病。两者非常类似,关注不同的指标,都是为了施救,前者救人,后者救数据库。
听起来是不是很激动,恨不得马上就要开始当救库英雄了!别急,接下来还要告诉你关注什么,然后在案例中让你感受一下什么叫救库英雄。
特别提醒:
这里有一个特别值得注意的地方,那就是性能报告的采样时间。Oracle默认是每小时产生一个采样点,你可以收集每个小时的性能报告。我们对此要敏感,比如你的性能故障是发生在今天早上7点~8点。然后系统自动恢复了,你获取一张8点~9点的性能报告来查问题,就毫无意义了。
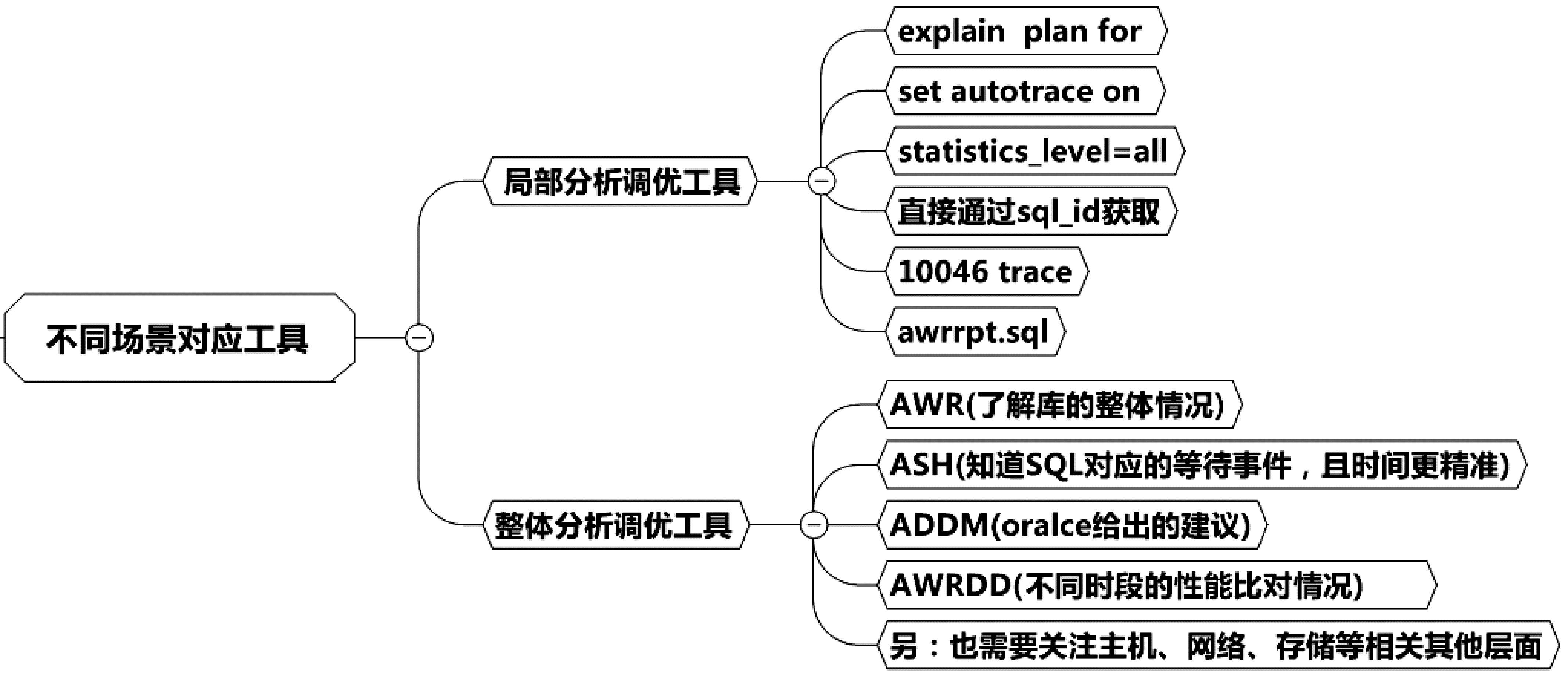
获取AWR报告的方式有两种:一种是直接获取方式,调后台脚本awrrpt.sql来获取,执行方式一般是在sqlplus下执行@?/rdbms/admin/awrrpt.sql;
另一种则是通过调用命令包,获取dbms_workload_repository这个包的awr_report_html程序,用SQL命令的形式输出内容。
|
Select output from table(dbms_workload_repository.awr_report_html (v_dbid, v_instance_number,v_min_snap_id,v_max_snap_id)) |
试验1(未使用批量提交):

接下来通过提示就可以生成AWR报告了,具体步骤略去,详情请扫本章最后的二维码。
试验2(单机下,正确使用批量提交):

接下来通过提示就可以生成awr报告了,具体步骤略去。
直接调用工具包的方式,特别适合用在程序自动获取报告的场景。

注:其中977587123是数据库的主机标识,可以在数据库的数据字典中查到,1是标识实例,如果是RAC,就有1和2两个,单机就只有1。1920和1921是两个断点时间,比如9点和10点之间。
获取ASH报告的方式也有两种:一种是直接获取方式,调后台脚本ashrpt.sql来获取,执行方式一般是在sqlplus下执行@?/rdbms/admin/ashrpt.sql;另一种则是通过调用命令包,获取dbms_workload_repository这个包的ash_report_html程序。用SQL命令的形式输出内容。
select output from table(dbms_workload_
repository.ash_report_html( dbid,inst_num,l_btime,l_etime)

说明:
如果你是一路回车,就是获取最近5分钟的ASH报告。
如果你根据Oldest ASH sample available 时间,然后回车,选择的是目前可收集的最长ASH运行情况。
你可以选择Oldest ASH sample available和Latest ASH sample available之间时间,然后输入时长,比如30表示30分钟,取你要取的任何时段的ASH报告。
ASH报告的获取不同于AWR的地方在于,快照之间有无重启动作不影响报告的获取。
ASH报告可以直接手工获取,比如select output from table(dbms_workload_ repository.ash_report_html( dbid,inst_num,l_btime,l_etime)。
直接调用工具包的方式,特别适合用在程序自动获取报告的场景。
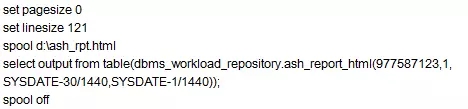
注:其中977587123是数据库的主机标识,可以在数据库的数据字典中查到,1是标识实例,如果是RAC,就有1和2两个,单机就只有1。SYSDATE-30/1440,SYSDATE-1/1440 分别是开始时间和结束时间。
获取ADDM报告的方式也有两种,一种是直接获取方式:调后台脚本addmrpt.sql来获取,执行方式一般是在sqlplus下执行@?/rdbms/admin/addmrpt.sql。另一种则是通过调用命令包的方式获取:调用dbms_workload_repository这个包的addm_report_html程序。用SQL命令的形式输出内容。
- Create an ADDM task.
DBMS_ADVISOR.create_task (
advisor_name => 'ADDM',
task_name => 'MYADDM',
task_desc => 'MYADDM');
@?/rdbms/admin/addmrpt.sql
具体执行过程略去。
注:直接调用工具包的方式,适合用在自动获取报告的场景。

获取AWRDD报告一般是用直接获取的方式,这个脚本的交互部分需要输入要进行对比的两个awr报告的begin snap_id与end snap_id,然后输入对比结果报告的名称,这里就不详细介绍了,请读者自行试验完成。
@?/rdbms/admin/awrddrpt.sql
具体略去。
获取AWRSQRPT报告的关键之处在于,交互部分要输入所要分析的SQL的SQL_ID,这是关键之处。而这个SQL_ID可以从AWR报告中获取。

以上5个报告的获取本身并不难,操作一遍就会了,笔者也会再提供在线操作视频,让大家实际体会一遍。现在关键在于,要明白这5个报告的作用和相互之间的区别,搞懂这些,调优之路就算完成过半了。当然,接下来如何分析读懂这五大报告的关键指标就非常重要了,有一些指标你必须关注,否则你就当不了“医生”了。
AWR报告是五大报告中最全面最重要的一个报告,它的相关指标也显得格外重要。这里我们列出DB Time、load_profile、efficiency percentages、top 5 events、SQL Statistics、Segment_statistics这6个指标入手分析。
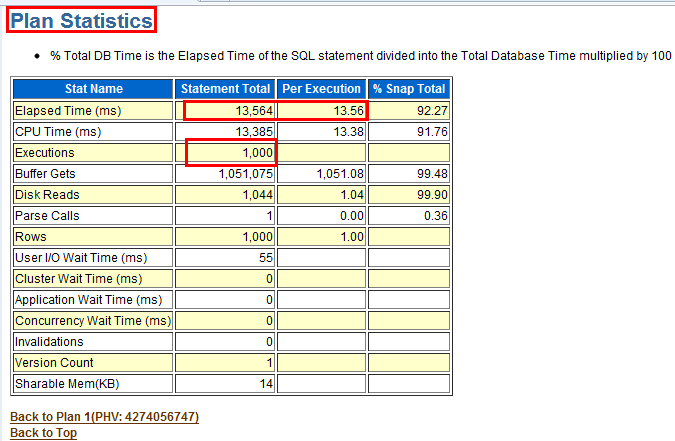
DB Time这个指标主要用来判断当前系统有没有遇到相关瓶颈,是否较为繁忙导致等待时长很长。一般来说,Elapsed时间乘以CPU个数的时间如果结果大于DB Time,我们认为系统压力不大,反之则压力较大。如下例子中,60.11×64=3847.04<5990.6,说明系统现在还是比较繁忙的。

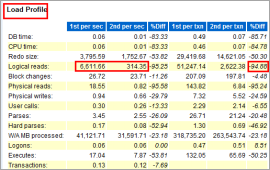
load_profile这个指标主要用来展现当前系统的一些指示性能的总体参数,比如经典的Redo size就是用来显示平均每秒的日志尺寸和平均每个事务的日志尺寸,结合Transactions这个每秒事务数的指标,就可以分析出当前事务的繁忙程度。
下图中显示每秒有6777.1个事务数,这在现实中几乎不可能,现实中的运营商系统一般在200上下比较正常,超过1000就属于非常繁忙了。
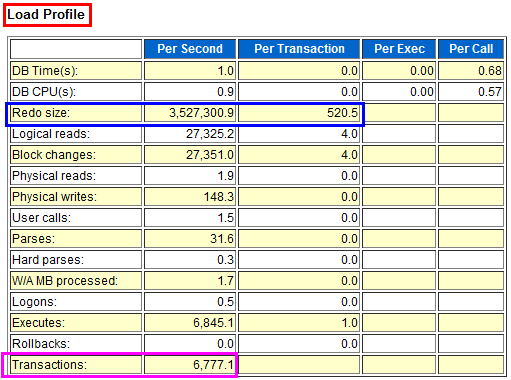
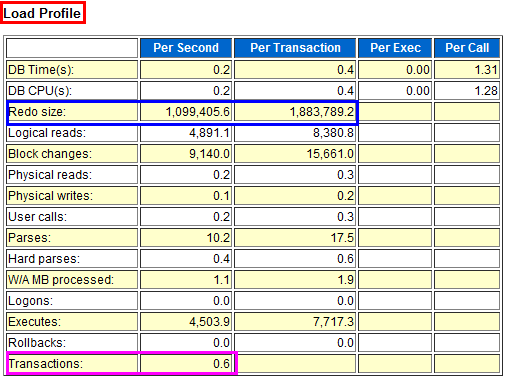
把上图和下面的图进行比较,就非常明显了,下图显示每秒有0.6个事务,平均每个事务产生的日志尺寸是7位数。这说明系统是一个提交不频繁的处理大任务事件的系统。而上图的尺寸是3位数。这里非常容易看出,这是一个提交非常频繁且每个事务都非常小的密集提交系统。
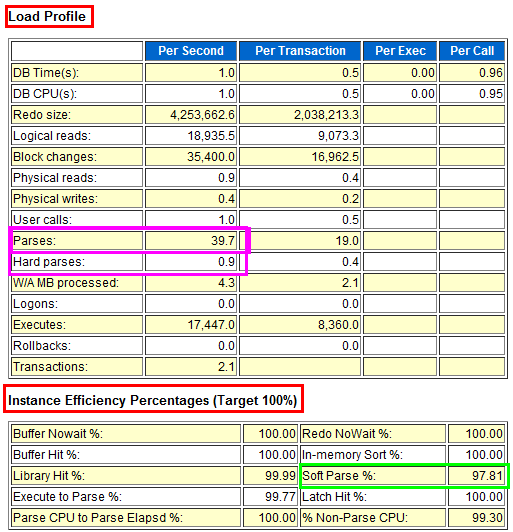
efficiency percentages是一些命中率指标,其中Buffer Hit、Library Hit等都表示SGA(System global area)的命中率。在下图中Soft Parse指标表示共享池的软解析率,在OLTP系统中如果该指标低于90%应当引起你的注意,这表示存在未使用绑定变量的情况。我们通过比对两个报告,可以看出明显差异,如下面系列图所示。
报告1(未有效地使用绑定变量,产生大量硬解析的场景)。

报告2(有效地使用绑定变量,进行绑定变量优化后的场景)。
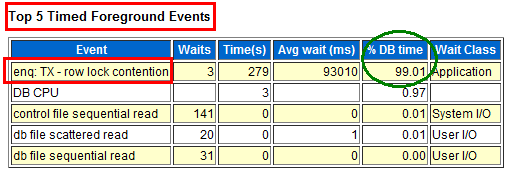
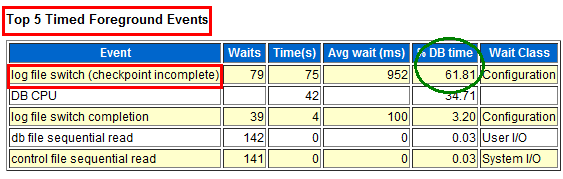
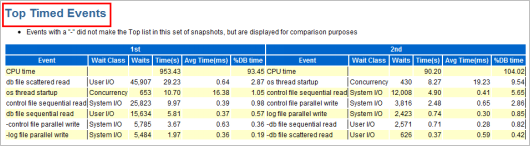
等待事件是衡量数据库整体优化情况的重要指标,通过观察Top 5 Timed Foreground Events模块的Event和%DB time两列,可以非常直观地看出当前数据库面临的主要等待事件是什么。下图两个例子分别告诉我们数据库面临锁等待和日志切换等待的情形。
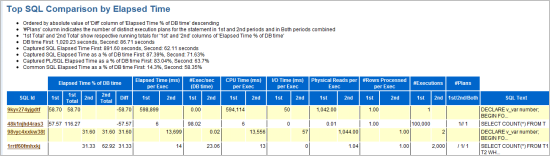
SQL Statistics分别从几个维度来罗列出TOP的SQL,这是一种简单粗暴但有效的方法。看看执行时长,直接拿出来优化一般都是对的做法。


ASH是啥?哦,有人想起来了,胃镜。
完成了ASH报告的获取后,打开获得的ASH报告,其实对于该报告可关注的东西非常直接,就是看看哪些SQL和哪些等待事件是相关联的。
如下图所示:

ADDM是啥?哦,是医生的门诊报告。
由于这是Oracle的一些分析建议,所以ADDM的阅读非常简单,基本上从FINDING 1、FINDING 2顺序往下看就可以了。一般是从数据库整体配置和局部SQL两方面给出建议。我们看看都能明白,如下图所示:
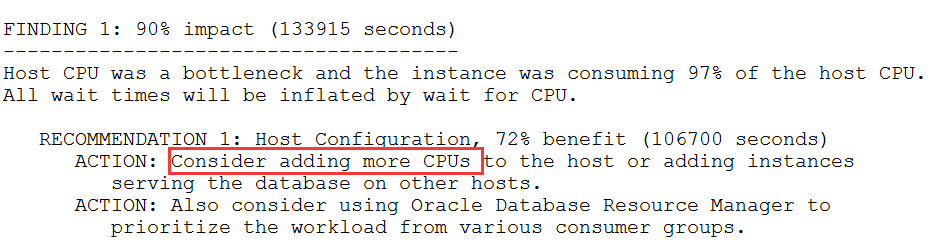


AWRDD是啥?哦,是医生在看你前后两次体检报告,在比较指标的变化。其实这个关注点很简单,基本上就是AWR关注什么,AWRDD就关注什么,没什么特别的,简单列举如下。

AWRSQRPT是啥?哦,有人想起来了,活检。别打颤!
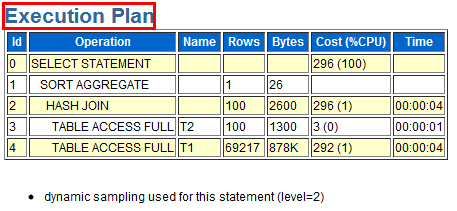
其实没啥,就是看看AWR和ASH里看不到的东西。都有啥呢?比如执行计划的相关细节,关于执行计划我们会在后面详细说明。这里要特别注意一点,Oracle的执行计划可能会随着环境的变化而变化,会随着数据的变化而变化,因此可能会产生多个执行计划,这个AWRSQRPT就会出现多个执行计划。具体详见下面系列图。
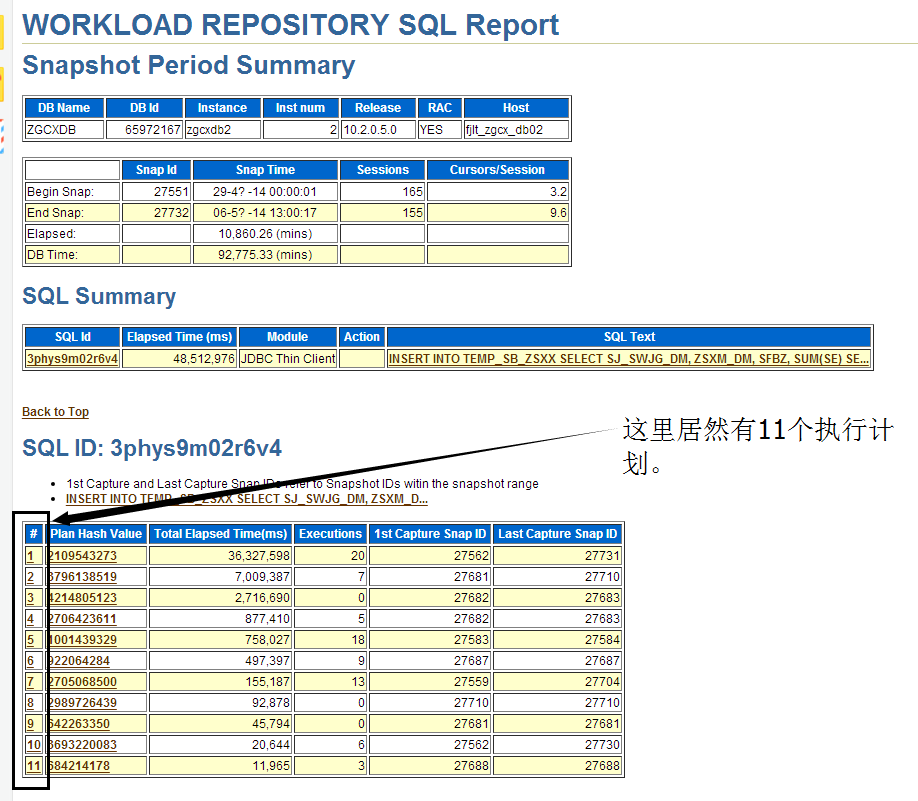
案例的分享与交流
说了这么多,我们来看几个相关案例,体会使用工具进行整体优化的重要性。
这是来自某政府系统的一个平台的案例,请看下图,这是AWR报告的Top 5 Timed Events的展现,可以看出当前数据库的等待事件主要是PX Deq相关的等待,这属于滥用并行等待导致系统资源紧张的一个案例。

该案例暴露出的问题比想象中更严重,因为该系统的不少表和索引的属性被设置了并行度,这导致所有对这些表和索引的访问都成了并行访问。后续解决思路就是将表和索引的并行属性去掉。将一些需要并行处理的大任务进行时间切割,确认部分大任务是可以放在凌晨业务低峰期执行的,就设置了并行的Hint任务,让部分SQL在夜间并行执行,大部分SQL在白天正常执行,从而系统恢复正常,业务也能顺利开展。
接下来我们再看一个案例,这是某运营商的系统,从AWR报告的Top 5 Timed Events等待事件主要是gc buffer busy来看,当前系统主要等待事件是热块竞争的等待。
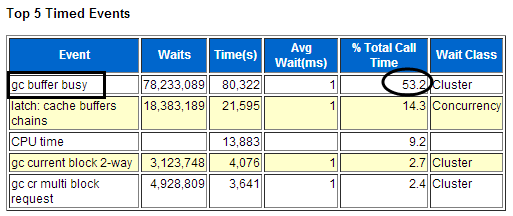
等待事件对应的SQL主要有哪些,我们其实可以通过对应时间段的ASH报告分析出来,比如下图就是和AWR的对应。
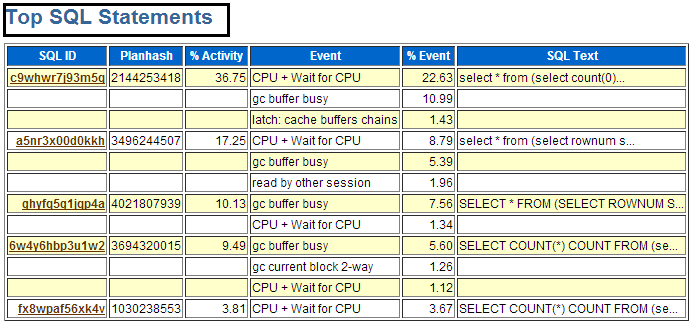
将AWR报告和ASH报告结合起来看,往往可以找出具体需要优化的SQL。在本案例中,我们发现两个节点共同访问一些对象导致热块竞争。后续通过一系列改造,让不同的业务跑在不同的节点上,从而避免了两个节点访问同一个对象,问题得以缓解。
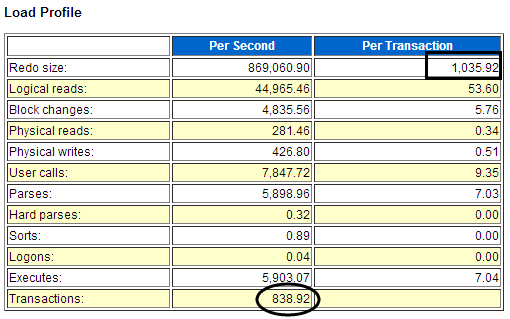
这是一个典型的案例,从Transactions达到800多,可以看出事务非常繁忙,再从Per Transaction才1000左右,可以看出每个事务非常小。这说明了系统存在事务未批量提交的情况。这种情况一般出现在循环中,把提交写到循环里面的情况。后续通过排查,发现果真是如此原因。
接下来的log file switch(checkpoint incomplete) 和log file sync的相关等待正是由于日志切换过于频繁导致的等待,这正是如前所述,未批量提交导致。

如下是新疆某运营商的优化案例,我们通过Top 5 Timed Events等待事件发现了瓶颈主要在IO。接下来我们迅速到Tablespace IO Stats模块去查看,如下图所示:
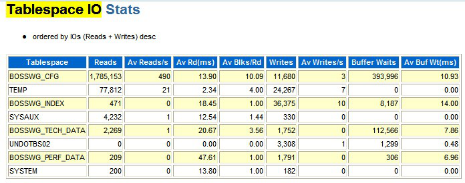
果然是有点问题。这个AV RD(MS)项表示平均一次物理读花费的时间(单位为ms)。有一种说法是, AV RD(MS)大于7就说明系统有严重的IO问题,其中BOSSWG_PERF_DATA居然达到了47,这说明当前的存储IO存在瓶颈。后续通过改善存储解决了问题。
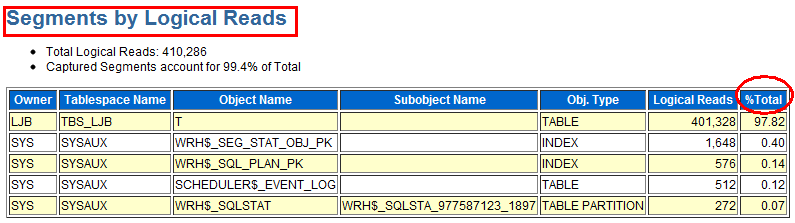
这个案例来自浙江某生产系统,我们通过Top 5 Timed Events等待事件发现了瓶颈主要在gc buffer busy等待事件,这和新疆某系统的前台优化案例类似。不过AWR报告非常强大,你通过各个细节都可以很有收获,从而找到解决问题的方法,比如你此时直接定位到Segments by Global Cache Buffer Busy模块,如下图所示:
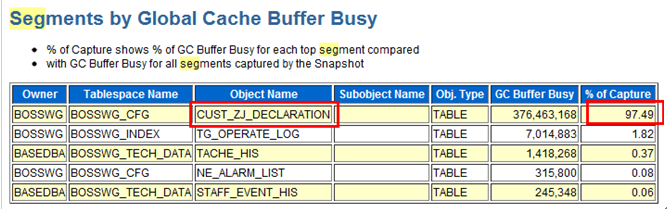
通过观察segments by global cache buffer busy的对象,我们找到了相关需要优化的表。最后我们结合业务,通过对该表瘦身、增加分区、避免两个节点同时访问的方案,优化了对应SQL的性能。
总结








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721