
作者介绍
李海龙,Qunar PostgreSQL DBA 总监,负责Qunar的PostgreSQL、PgVector、TimescaleDB、GreenPlum、Pgbouncer及Oracle 的运维;Qunar TC成员;PostgreSQL中文社区常委;中国PostgreSQL ACE&MVP。
郭浩然,2022年硕士毕业后加入Qunar,热爱数据库技术,在技术运营中心担任DBA,目前主要负责Qunar的PostgreSQL、PgVector及TimescaleDB的运维及自动化运维工具/平台的开发工作。
分享概要
为什么需要向量数据库
PostgreSQL生态
向量数据库分类和选型
PgVector安装及使用
PgVector运维实践
PgVector在Qunar及途家应用落地案例
总结与展望
一、 为什么需要向量数据库
1、缘起
随着AI相关技术的发展尤其是大语言模型(LLM)的广泛应用,海量的非结构化数据随之而来,如何存储以及高效检索这些数据成为热点问题,在此背景下AI时代的DB基座——向量数据库便应运而生了!
向量数据库支持存储AI算法经过Embedding后产生的向量类型数据,通过索引技术和向量相似度距离查询方法来支持向量数据的高效检索,解决了AI领域对于向量数据存储和高效检索的问题。
2、LLM的局限性
LLM,比如ChatGPT、Gemini、Claude、Llama ,一般都有如下局限性[12-15]
token限制问题
token可以是一个单词、单词的一部分或部分字符,由于上下文本越长LLM越难集中注意力,并且提高了算力成本,目前ChatGPT3的token限制为4k即 4096个,ChatGPT4的限制为4k-32k个
幻觉问题
生成的内容与用户提供的输入不符,生成的内容与之前生成的信息相矛盾,生成的内容与已知的世界知识不符
知识局限性问题
缺乏领域知识和常识推理能力,可能生成不符合业务逻辑的结果
知识的时效性
大模型训练成本高、时间长,无法补充新知识,无法应对时效性高的场景
数据的安全性
企业不会将私域数据暴露到公开的模型数据集中,需要在数据安全和效果进行取舍
3、向量数据库在AI中的生态位
针对LLM的诸多局限性,向量数据库可以较好的解决这些问题,目前业界较为成熟的方法是检索增强生成(Retrieval Augmented Generation)简称 RAG。
流程图如下所示,向量数据库作为知识库存储embedding数据,数据安全有保障,新知识可以即时添加进来解决时效性问题;先从向量数据库中检索到与用户的输入相关的短文本上下文,从而让LLM有了领域知识,解决了知识的局限性问题和幻觉问题;最后将检索到的多个短文本和用户问题输入到大模型中得到检索结果,由于只需加载必要的短文本作为背景知识,避免了长文本带来的token限制问题。
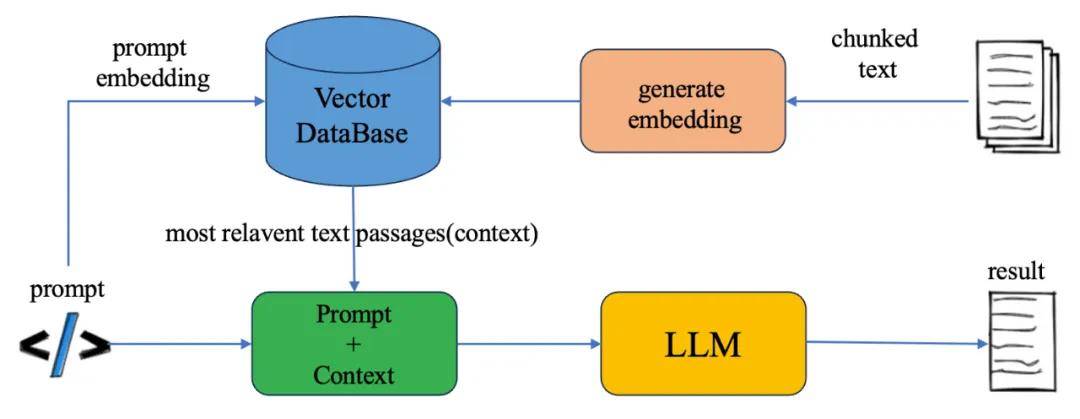
RAG流程图
目前市场上的向量数据库类型多样且各有特色和优势,本文主要介绍Qunar的选型——基于PostgreSQL的PgVector[1],并展示其在Qunar&途家运维实践过程中相关的技术总结,最后给出真实的落地业务案例。
二、PostgreSQL生态
下图截选自全球数据库最权威的数据库的流行度排名网站DB-Engines Ranking-Trend Popularity(https://db-engines.com/en/ranking_trend ),选取TOP-5的数据库产品,其中橙色曲线为PostgreSQL,可以看到10几年来流行度一骑绝尘!
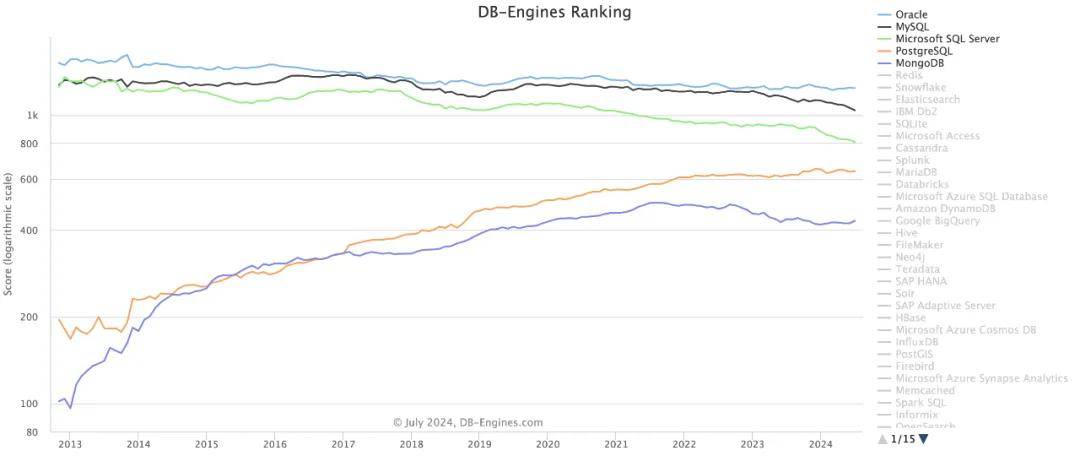
DB-Engines Ranking - Trend Popularity
PostgreSQL如此受欢迎有很重要的一方面就是得益于其优秀的扩展能力!如图下所示,PostgreSQL位于中央,针对具体领域形成周边丰富的开源扩展,其中PgVector就是众多的开源扩展之一,在继承PostgreSQL所有功能基础上添加了存储和检索向量的能力成为向量数据库[2]。

PostgreSQL生态图
PostgreSQL历史悠久,生态完备,国内外企业使用广泛,目前动能强、势能足,潜能深[3]

PostgreSQL生态图
三、向量数据库分类和选型
向量数据库分类如下图表所示[4][5][11]

|
数据库类型 |
开源/商业 |
SQL/NoSQL |
|
|
|---|---|---|---|---|
|
专用的向量数据库 |
开源或商业均有 |
绝大部分是NoSQL |
|
事务、容灾备份、可观察性等方面还不够完善 |
|
支持向量功能的传统DBMS |
开源或商业均有 |
SQL或NoSQL均有 |
|
并非专为向量设计,处理向量数据的能力有限 |
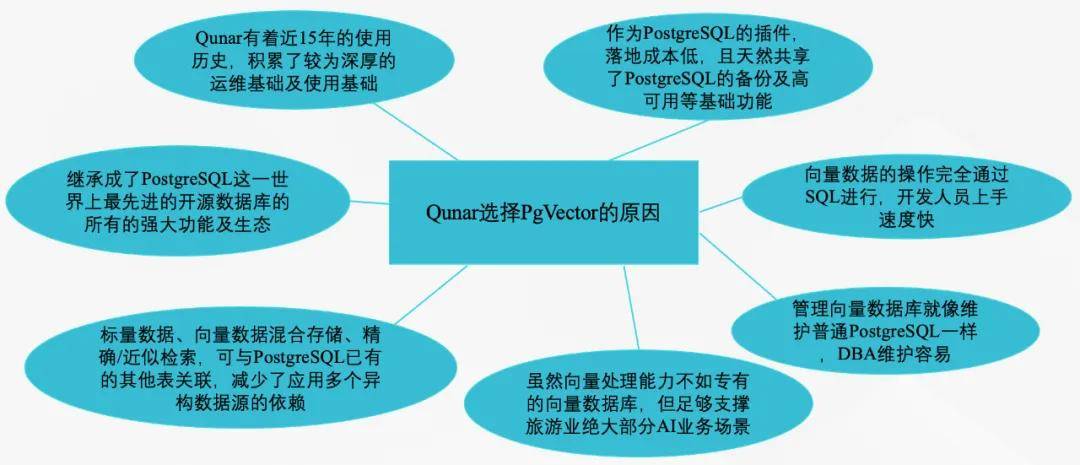
PgVector作为Qunar及途家的向量数据库选型,主因如下:
四、PgVector安装及使用
1、 PgVector与PostgreSQL 匹配矩阵
在安装之前,我们要确定 PgVector与PostgreSQL之间的版本匹配关系,这个在PgVector的changelog中有零散的说明,现总结如下:
|
|
|
|
|---|---|---|
| PgVector 0.7.x | PG12 至 PG17 |
|
| PgVector 0.6.x | PG12 至 PG17 |
|
| PgVector 0.5.x | PG11 至 PG16 |
|
| PgVector 0.4.x |
PG11 至 PG15 |
|
| PgVector 0.3.x | PG10 至 PG15 |
|
由于高版本的PgVector有诸多新功能及性能增强,强烈建议使用支持您生产上的PostgreSQL的最高版本的PgVector!
2、PgVector安装与基本用法
体验向量数据库功能之前确保搭建好PostgreSQL数据库并安装PgVector扩展,以下步骤简要介绍PgVector的安装与基本使用方法。
1)安装PgVector
Linux and MacCompile and install the extension (supports Postgres 12+)cd /tmpgit clone --branch v0.7.2 https://github.com/pgvector/pgvector.gitcd pgvectormakemake install # may need sudo
2)创建扩展
postgres=# create extension vector ;CREATE EXTENSIONpostgres=# \dx vectorList of installed extensionsName | Version | Schema | Description--------+---------+--------+------------------------------------------------------vector | 0.7.2 | public | vector data type and ivfflat and hnsw access methods(1 row)
3)建带有向量数据类型的表
create table my_img_emb(id bigserial primary key,img_uuid varchar(64),img_name varchar(256),img_annotation_name varchar(256),img_type varchar(64),img_embedding vector(512), -- 根据特征提取输出的向量维度指定vector(x)维度create_time timestamptz default now() not null,update_time timestamptz default now() not null);comment on table my_img_emb is '图片embedding表';comment on column my_img_emb.img_uuid is '图片uuid';comment on column my_img_emb.img_name is '图片名称';comment on column my_img_emb.img_annotation_name is '图片标注文件名称';comment on column my_img_emb.img_type is '图片类别';comment on column my_img_emb.img_embedding is '图片向量';-- 必要查询加索引create unique index concurrently on my_img_emb(img_uuid);create index concurrently on my_img_emb(img_type);-- 根据向量相似度检索的操作符选择对应的vector_xxx_ops建立对应的hnsw向量索引create index concurrently on my_img_emb using hnsw (img_embedding vector_cosine_ops);
4)使用特征提取算法将图片embedding并写入到PG
此步骤由应用完成
5)检索数据
-- 使用cosine相似度距离操作符"<=>"检索与给定向量相似的top5结果select img_uuid, img_name, img_typefrom my_img_emborder by img_embedding <=> '[xx.xx,xx.xx, ... ,xx.xx]'limit 5;-- 使用cosine相似度距离操作符"<=>"检索与id为1的图片相似的top5结果select img_uuid, img_name, img_typefrom my_img_embwhere id != 1order by img_embedding <=> (select img_embedding from my_img_emb where id = 1)limit 5;-- 带有where过滤条件的检索select img_uuid, img_name, img_typefrom my_img_embwhere img_type = 'xxx'order by img_embedding <=> '[xx.xx,xx.xx, ... ,xx.xx]'limit 5;
更多使用方法参考官网:
https://github.com/pgvector/pgvector
五、PgVector运维实践
2023年4月第一个PgVector向量数据库落地到Qunar&途家生产环境,以下是在运维实践中的相关技术总结。
1、向量类型介绍
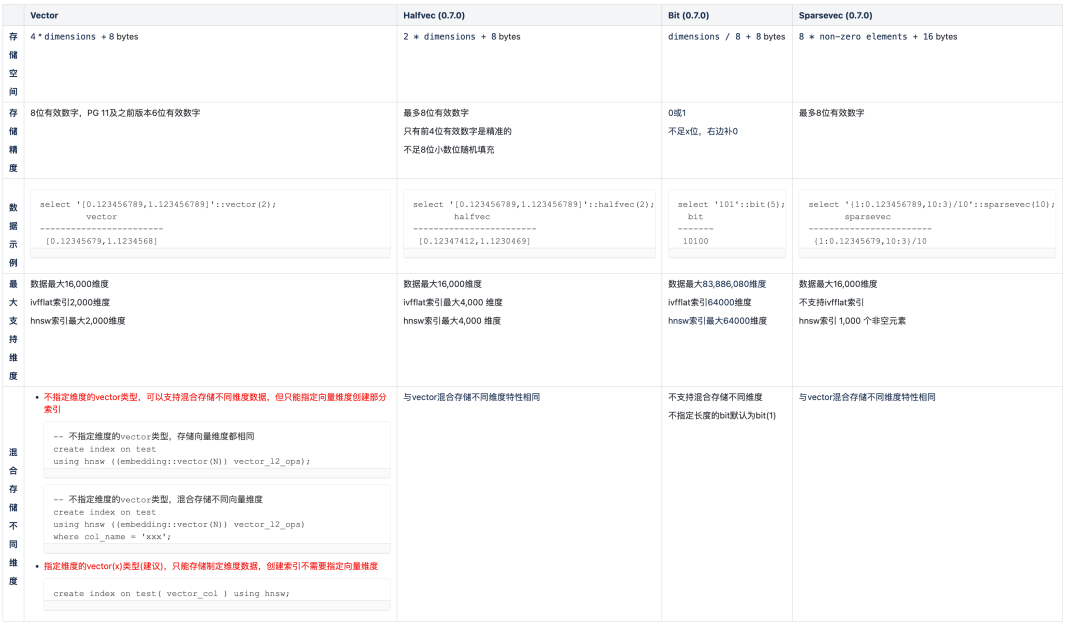
PgVector提供的能够存储向量数据的类型是vector、halfvec(0.7.0)、bit(0.7.0)、sparsevec(0.7.0),详细介绍如下表所示。
向量数据库中的向量索引对近似检索速度起到关键的作用,目前vector类型使用最广泛建议使用带有维度的向量类型,向量维度不超过向量索引支持最大维度,并建立向量类型索引。
vector类型介绍
2、向量索引性能对比
向量索引实现了检索性能和结果准确性之间的平衡,因此使用向量索引检索到的结果不是精确的,PgVector支持2种类型的向量索引HNSW和IVFFlat,推荐使用HNSW类型索引,原理介绍与特性对比如下。
1)IVFFlat索引介绍
如图所示IVFFlat(Inverted File - Flat)索引基于聚类技术,将已有的样本划分聚蔟并生成聚蔟中心点,然后搜索这些聚蔟中最接近查询向量的子集,因此没有样本的空表创建索引没有意义。当IVFFlat 创建完成后,随着数据的插入、更新和删除,新的向量将被添加到索引中,而不再使用的向量将被删除,然而各个聚蔟的中心点将不会被更新。随着时间的推移,这可能会导致在创建索引时建立的初始聚簇不再准确地代表数据的情况 ,解决此问题的唯一方法就是定期重建索引。与HNSW相比,它具有更快的索引构建时间和更少的内存使用,但查询性能较低[6]。

IVFFlat索引原理示意图
2)HNSW索引介绍
如图所示HNSW(Hierarchical Navigable Small World)索引[7]是一种基于图的索引结构,并结合跳表的思想确保了多层图的连通性;当一个新节点被插入到索引时会被随机分布到任意一层中,避免了数据输入顺序影响到图的结构分布,具有空表建索引,数据插入、更新和删除不影响搜索召回率、不需要定期重建索引等特性,并且相比于IVFFlat索引具有更快的检索时间和更高的召回率(搜索引擎检索到的相关文档数占实际上所有相关文档总数的比例)。
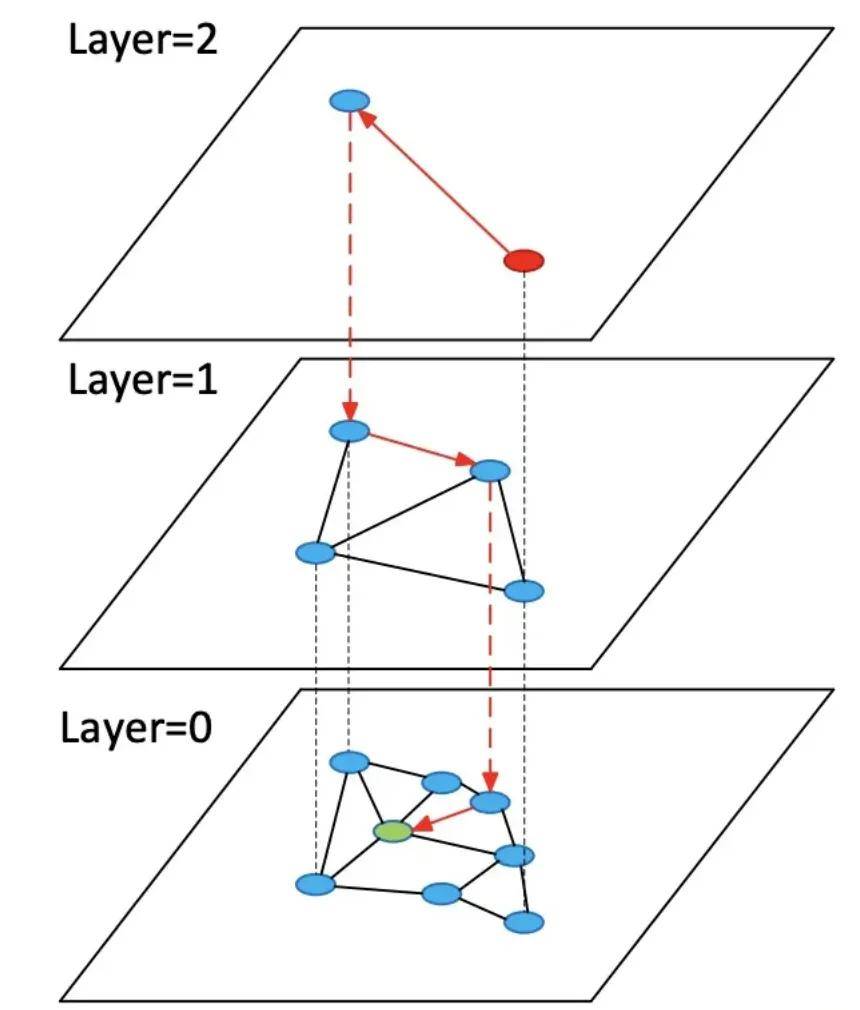
HNSW索引原理示意图
3)HNSW vs IVFFlat 索引性能测试
引用JONATHAN KATZ对PgVector的HNSW索引性能测试结果如图所示[8]:
红色图例pg_embedding_hnsw是另一种向量数据库实现的HNSW索引,
浅蓝色图例PgVector实现的IVFFlat索引,
深蓝色图例pgvctor_hnsw是PgVector实现的HNSW索引,
如图所示当横轴召回率固定时pgvctor_hnsw具有更高的QPS,当纵轴QPS固定时pgvctor_hnsw具有更高的召回率,可以看到PgVector实现的HNSW索引性能更好。
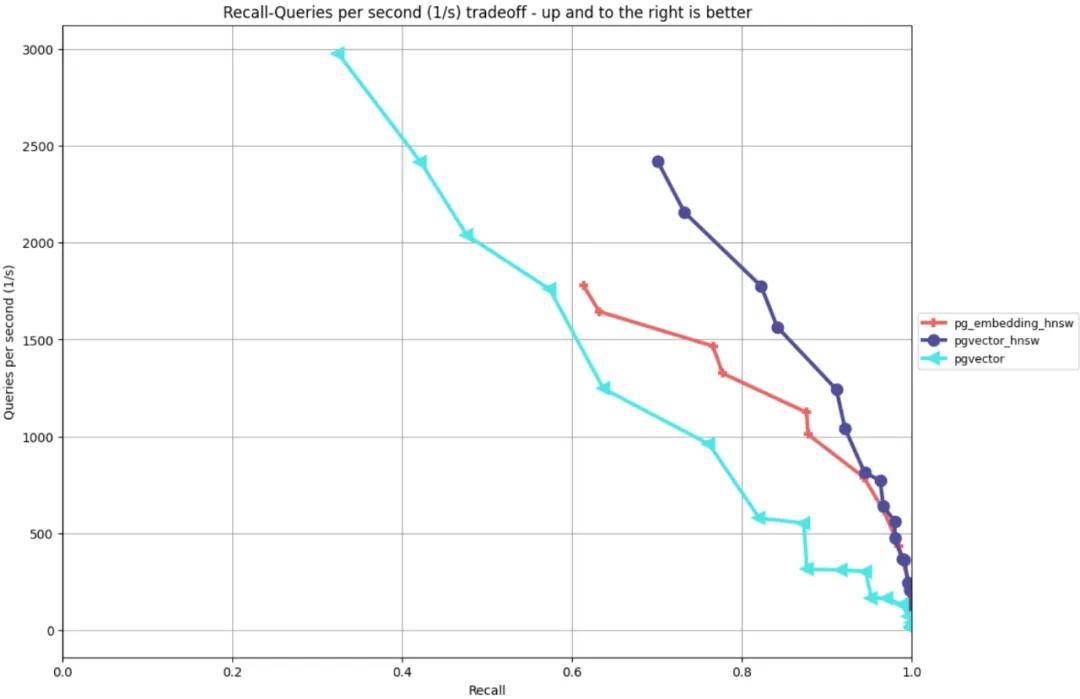
hnsw索引QPS和召回率对比
4)HNSW vs IVFFlat向量索引综合对比
HNSW与IVFFlat向量索引对比如表所示,2种索引最大支持vector维度维度都是2000,IVFFlat索引空表建索引无作用并且需要定期重建索引这就意味着对于数据分布经常发生变化的表需要定期维护;HNSW解决了这个问题并且具有更高的召回率、qps,但是需要更多的建立索引时间和内存占用。因此推荐使用HNSW类型索引。
HNSW与IVFFlat向量索引对比
|
HNSW(推荐使用) |
IVFFlat |
|
|---|---|---|
| 空表建索引 | 有作用 | 无作用 |
| 建立索引时间 | 慢 | 快 |
| 建立索引内存占用 | 高 | 低 |
| 定期重建索引 | 不需要 | 需要 |
| 召回率、qps | 高 | 低 |
| 支持向量类型 |
vector halfvec bit sparsevec |
|
3、版本升级对HNSW索引性能优化
Pgvector版本更新频率较快,每个版本会带来新的功能和性能优化,以HNSW索引为例来对比各版本建立hnsw索引指标。测试环境与测试结果如下表,在0.5.0版本PgVector首次支持HNSW类型索引,此时创建索引的时间成本是巨大的,随后的2个版本对HNSW索引性能进行优化。尤其是0.6.0版本大幅缩短了建立索引的时间,并且减少了内存和wal占用量,从运维实践经验上看,hnsw索引空间占用为数据空间的30% ~ 100%。由此可见PgVector版本升级是十分必要的!
0.6.0版本对于HNSW建立索引时间的大幅缩短得益于使用了内存临时文件系统/dev/shm的空间,也就是说/dev/shm中的文件是直接写入内存的而不占用硬盘空间,在Redhat/CentOS等linux发行版中默认大小为物理内存的一半,docker默认为64M。当maintenance_work_mem大于/dev/shm的剩余空间大小时建立HNSW索引报错如下,所以注意在0.6.0版本之后要确保maintenance_work_mem要小于/dev/shm的剩余空间。
ERROR: could not resize shared memory segment "/PostgreSQL.xxx" to 69790211424 bytes: No space left on device
测试环境
|
机器基础软硬件参数 |
PG版本及参数 |
测试表数据量 |
|---|---|---|
|
系统 CentOS 7 CPU 32 threads 内存 128GB 硬盘 SSD |
PostgreSQL 14 effective_cache_size 64GB shared_buffers 32GB maintenance_work_mem 8GB |
向量字段类型 vector(512) 数据条数 1695375 数据大 |
各版本建立hnsw索引指标对比
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PgVector各版本changelog 详见:
https://github.com/pgvector/pgvector/blob/master/CHANGELOG.md,从上表也可以看出升级PgVector版本(PostgreSQL也需要随之升级)的必要性。
4、向量检索中的问题
向量索引可以进行近似最近邻检索(Approximate Nearest Neighbor Search, ANN),在检索时间、准确性、算力资源进行权衡,所以检索到的结果可能不是精确的,因为很多检索相关参数和业务使用场景相关,需要个性化定制。如果检索的召回率不满足业务要求时可以结合业务场景进行调整。
在某个运维案例场景中,开发人员反馈现有的系统功能允许用户上传图片样本并选择一些标签,系统将图片embedding后根据标签范围在向量数据库中检索最近似的top k结果返回;发现同一个图片样本在标签范围选择少的情况下,反而比标签选择多检索到的结果多,为了说明此案例问题和解决方法进行如下实验。
实验使用VOC2012开源数据集[9],vgg16算法进行图片特征的embedding,其中包含20种类别的图片,如下展示了表结构和每种图片类型数据量分布。
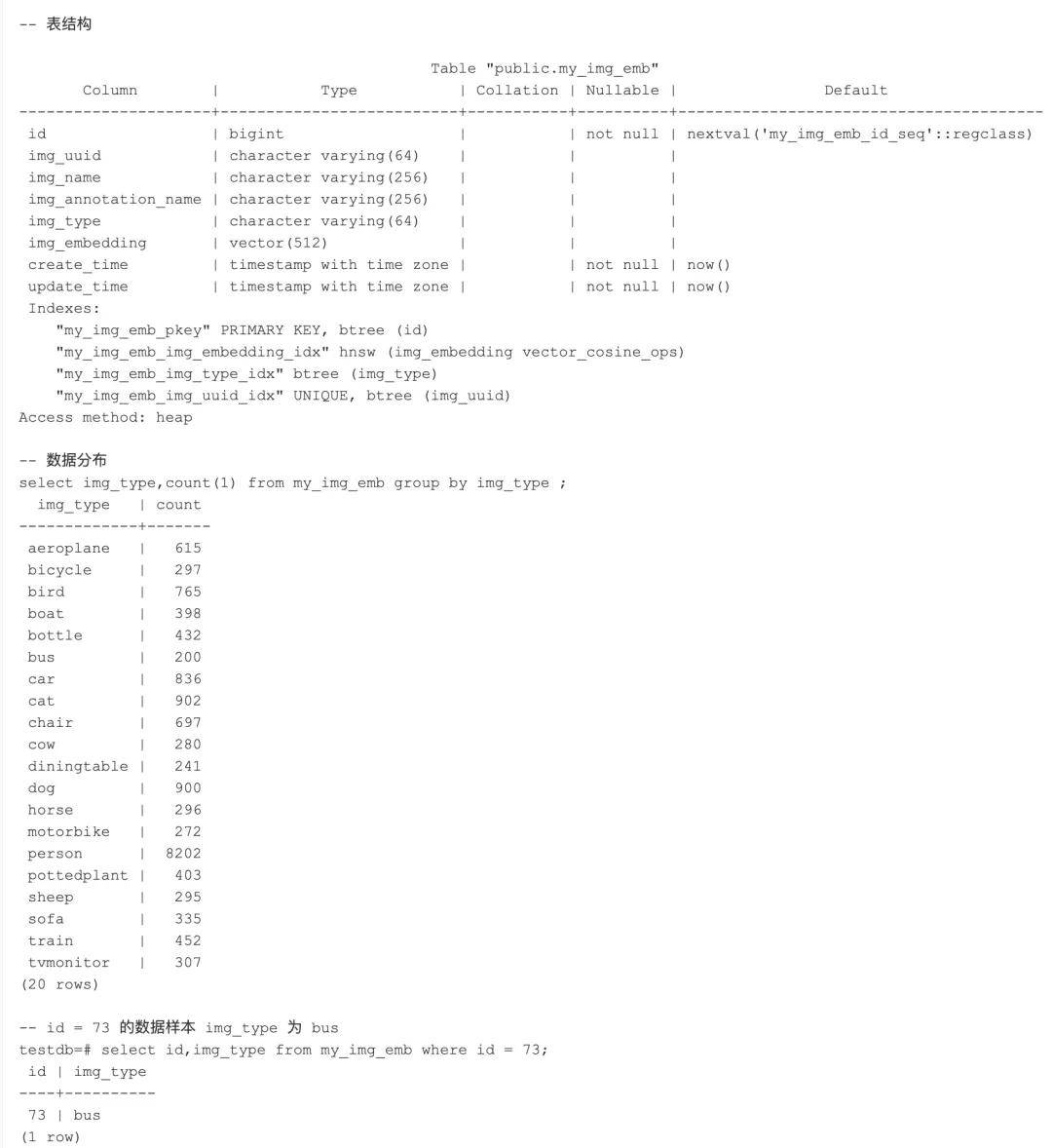
实验中涉及到3个SQL业务含义如下,每个sql都嵌套了select count(1) from (...) as a where img_type in ('bus'); 来检验检索结果中找到类型为 bus 的数量。

1)问题描述
如下表所示,SQL 1 检索结果数量为2,仅有1条为bus类型;业务中的另一种 SQL 2 相较于 SQL 1 减少了条件中的('sofa','sheep','dog')类型,检索结果数量和bus类型数量都远高于SQL 1;如何提高SQL1的检索效果,以及为什么扩大了图片类型的检索范围后,检索结果数量反而变少了,带着2个问题进行探究。
|
|
bus类型数量 |
|
|---|---|---|
| SQL 1 | 2 | 1 |
| SQL 2 | 100 | 100 |

2)原因解析
探究原因之前先介绍2个概念预过滤(pre-filtering)、后过滤(post-filtering)[10]:
|
|
|
|
|
|---|---|---|---|
| 预过滤(pre-filtering) | 先条件过滤,再相似度检索 | 是总会返回要查询到top k结果 | 耗费时间、算力 |
| 后过滤(post-filtering) | 先相似度检索,再条件过滤 | 降低检索时间,节省算力 | 牺牲了检索结果的准确性 |
对比2个SQL查询计划如下表所示:
SQL 1 使用img_embedding类型上的hnsw向量索引 my_img_emb_img_embedding_idx 对于索引上的数据先进行相似度排序得到40条数据,再使用条件 Filter: ((img_type)::text = ANY ('{bus,sofa,sheep,dog}'::text[])) 过滤掉38条数据,再通过 Filter: ((a.img_type)::text = 'bus'::text) 过滤掉1条数据,最终返回1条数据,由于向量索引使用的是近似搜索,所以实际检索结果少于期待的数据量。这种情况属于后过滤(post-filtering)。
SQL 2 使用img_type类型上的索引my_img_emb_img_type_idx先使用img_type条件过滤出全部符合的数据得到200条,再使用暴力检索进行相似度排序取出前100条数据;这种情况属于预过滤。
由此得出结论,当使用了向量索引属于后过滤情况,没有使用向量索引属于预过滤情况,在包含where过滤条件的向量检索中具体使用哪个索引与选择某个索引的代价(用于估算查询时间)有关。

3)提高检索召回率
当默认的HNSW索引检索结果的召回率(recall)不满足业务要求时,可以通过查询选项或索引选项的参数来微调,这也是适用于各种场景的通用方法,实验效果如下表所示。
①调整查询选项
hnsw.ef_search 参数指定要搜索的动态候选列表的大小(默认为40),最大值为1000。测试结果如下表所示,使用默认参数 hnsw.ef_search = 40 ,SQL 1 检索到2条数据,bus类型数量为1,查询时间2.4ms,执行计划使用hnws类型索引my_img_emb_img_embedding_idx;当设置hnsw.ef_search = 1000时,SQL 1 检索到28条数据,bus类型数量为17,查询时间16.8ms相较于 SQL 1 使用 hnsw.ef_search = 1000 与默认 hnsw.ef_search = 40 查询参数的检索对比,扩大 hnsw.ef_search 参数后检索结果召回率显著提高,但是检索时间有所增加,执行计划没有改变。
SQL 1 微调查询选项参数
|
|
|
|
bus类型数量 |
|---|---|---|---|
| 40(默认) | 1.9 ms | 2 | 1 |
| 1000 | 16.8 ms | 28 | 17 |

②调整索引选项
建立 HNSW 索引可以指定如下参数,以索引构建时间/插入速度为代价,官方文档给出ef_construction的值越高会提供更好的召回率的结论。
m - the max number of connections per layer (16 by default),Valid values are between "2" and "100"
ef_construction - the size of the dynamic candidate list for constructing the graph (64 by default),Valid values are between "4" and "1000"
使用默认的查询参数 hnsw.ef_search = 40 对比默认的 m=16, ef_construction=64 参数建立hnsw类型索引,和 m=100, ef_construction=1000 参数建立hnsw类型索引,本数据集中未发现检索结果改变,但是建索引时间和执行时间都有上升,效果与数据集分布、embedding算法等有关,可以结合业务场景微调索引选项。
SQL 1 微调索引选项参数
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| 40(默认) | 16(默认) | 64(默认) | 00:11.71 min | 1.9 ms | 2 | 1 |
| 40(默认) | 100 | 1000 | 04:03.51 min | 16.8 ms | 2 | 1 |

③SQL改写
通过以上调参如果仍然不满足业务要求,还可以通过改写SQL的方法绕过hnsw索引(仍可使用非hnsw索引)提高召回率。
相似度计算操作符与相似度计算函数对应关系
| 描述 | 向量操作符 | 函数 | 常用使用场景 |
|
Euclidean distance |
<-> | l2_distance(vector, vector) |
推荐系统、机器视觉 (反映向量的绝对距离,适用于需要考虑向量长度的相似性计算 ) |
|
negative inner product |
<#> 注意:<#>是负的内积,等价于 -inner_product(vector, vector) 点积是实数域的内积 |
-inner_product(vector, vector)
|
图像识别、语义搜索和文档分类 (对向量长度敏感,高维向量的相似性可能会出现问题)
|
|
cosine distance |
<=> | cosine_distance(vector, vector) |
语义搜索和文档分类 (对向量长度不敏感,只关注向量的方向,适用于高维向量的相似性计算 ) |
将前文 SQL 1 进行改写,按照上表将相似度操作符"<=>"替换为"cosine_distance(vector, vector)"得到 SQL 3 ,可以看到 SQL 3 检索效果相比于SQL 1 已经显著提高,查询计划不再使用向量索引,但是查询时间从 1.9 ms 升高到了 3.8 ms。
SQL 1 改写
|
执行时间 |
|
bus类型数量 |
|
|---|---|---|---|
| SQL 1 | 1.9 ms | 2 | 1 |
| SQL 3 | 3.8 ms | 100 | 59 |

4)解决方案总结
通过向量类型和普通类型联合查询时,如果发现召回率较低,一般有如下建议:
可以尝试 查询选项和索引选项的参数微调
可以尝试 在非向量数据类型上单独创建btree index,供查询规划器根据查询计划的代价自动选择hnsw或btree index
可以尝试 改写SQL替换 order by 中的相似度计算操作符为对应的相似度计算函数,从而引导查询规划器不使用召回率低的hnsw索引(虽然可能hnsw的速度较快)
注意:使用此种方案时要确保where过滤的非向量条件上有索引,并且执行过滤条件后不会得到海量数据,否则会严重增加检索时间并消耗大量算力
5、PgVector&PostgreSQL集群性能调优
由于向量数据的特点,向量数据的读写是比较消耗PG集群的计算及存储资源。
比如说在对向量数据表进行初始化读写,或需要大量刷数据时,会产生大量WAL;以及如果对包含向量数据表的实例做基础备份,复制实例datadir的时间会比原生PG耗时更长,此时也会导致无条件开启full_page_writes 的时间更长,导致写放大。
可以通过调整 full_page_writes = off & wal_compression = on 减少WAL的产生,如下是模拟刷数据及做备份时的场景,为了让效果更明显每20s执行一次checkpoint。
如下图是每分钟的wal写入速度监控:
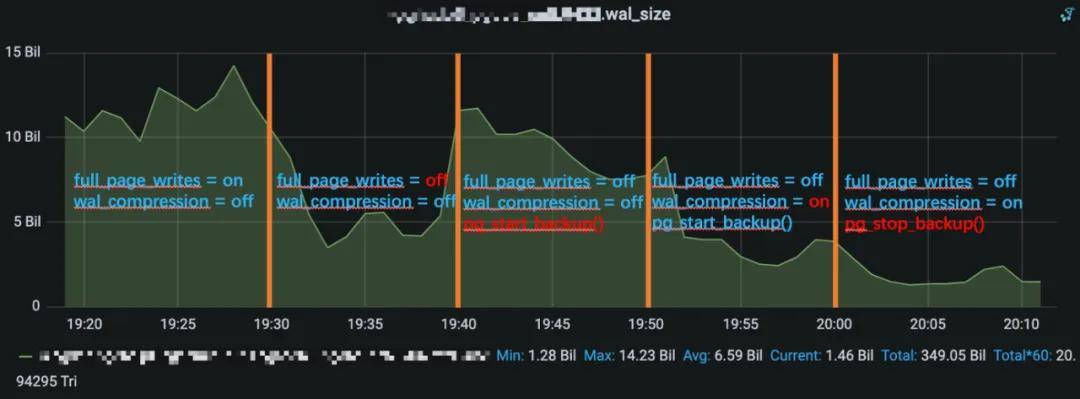
DB参数调整对wal产生速度变化对比
19:20 ~ 19:30 时段配置为full_page_writes = on、wal_compression = off ,19:30~19:40 full_page_writes 改为 off 后WAL生成速度明显下降;19:40 ~ 19:50 时段调用pg_start_backup() DB处于备份阶段,PG内部会无条件开启full_page_writes = on(即使该参数配置为off),使得WAL量继续增加;19:50 ~ 20:00 继续调整wal_compression改为on,开启wal压缩,看到wal量明显下降;20:00 ~ 20:10 调用pg_stop_backup()停止DB的备份状态,WAL量继续下降;由此实验可以看到向量数据库刷数据可以调优PG相关参数来缓解WAL的量。
六、PgVector在Qunar及途家应用落地案例

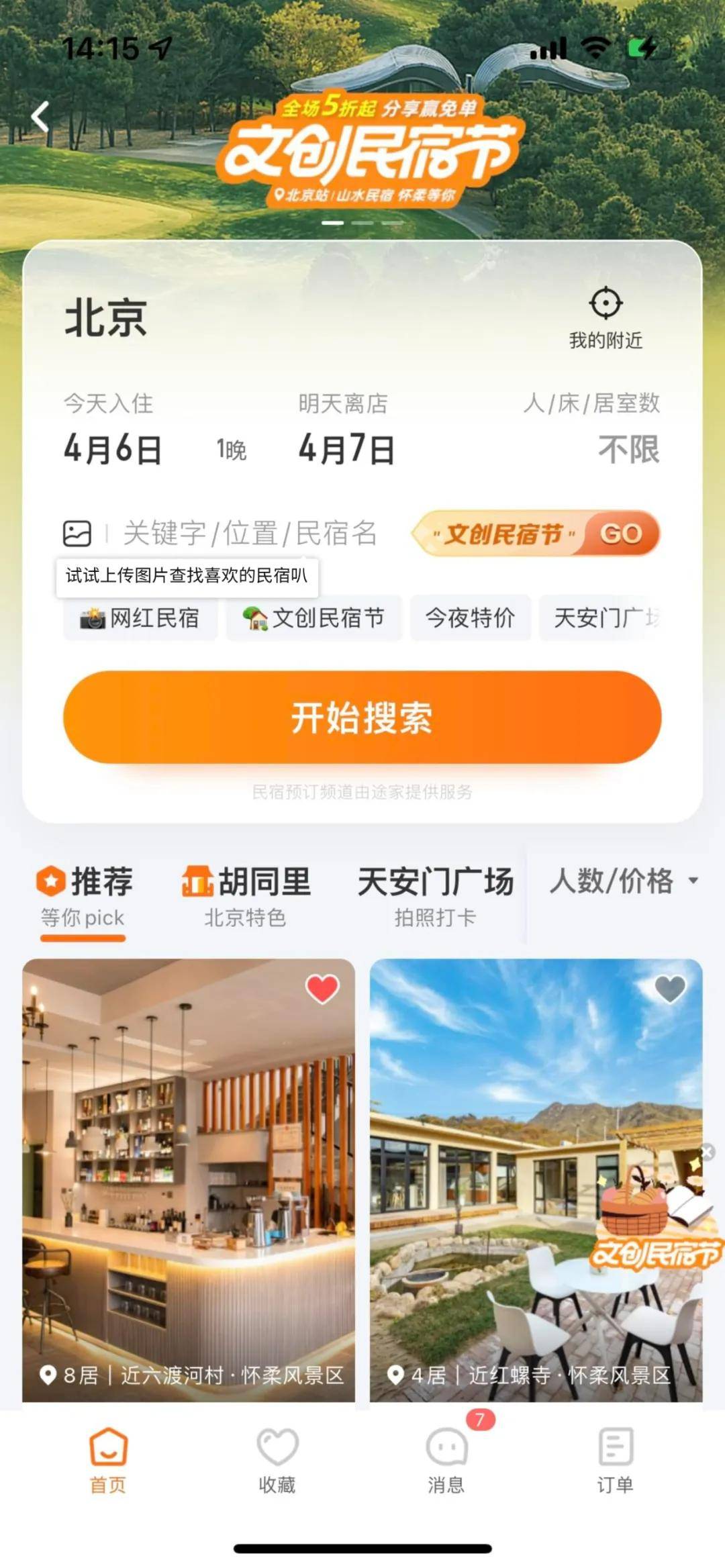
1、途家以图搜房
用户可以通过上传图片搜索近似的房型,迅速预定心仪的民宿,基本流程如下:
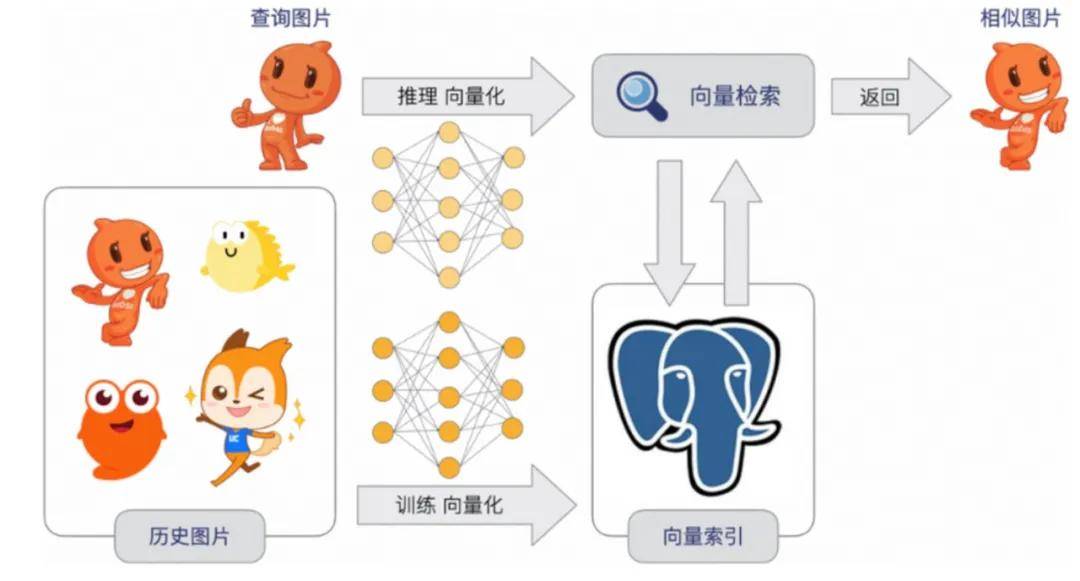
具体界面如下:
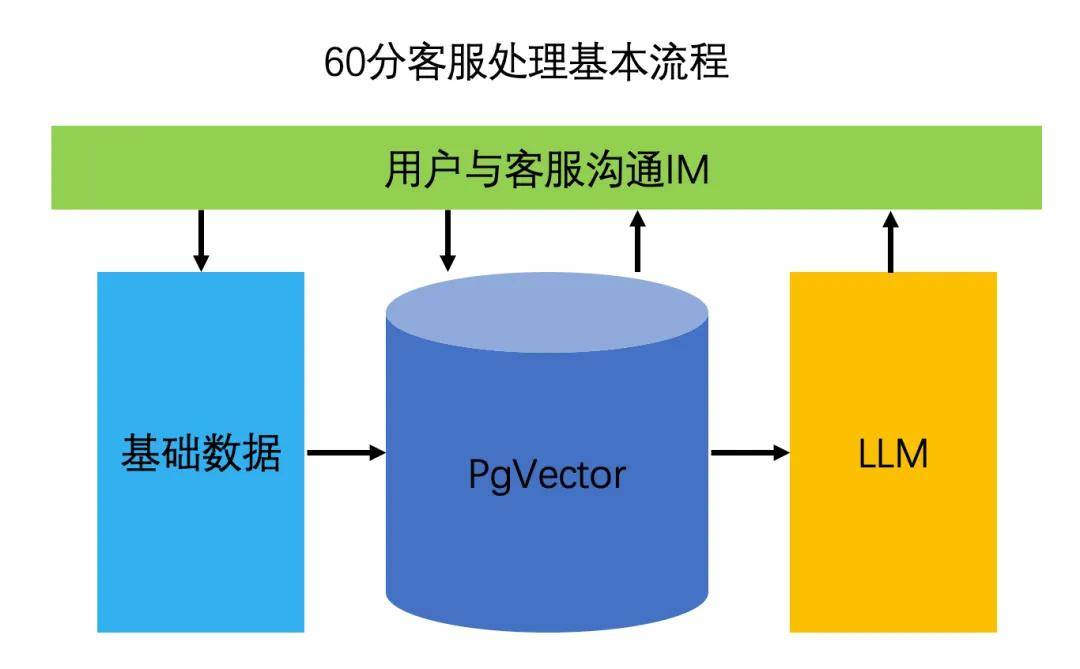
2、Qunar60分客服
在客户服务领域应用了AI技术,其中关键技术就包含向量数据库 + LLM,去哪儿开发了“客服智能助手”。
该项目并不是说我们只给用户提供60分的服务,该项目名称的含义是:60分AI+40分人工=100分服务。我们利用AI技术,来解决基础的服务问题,把我们非常宝贵的人工投入到另外40分的服务体验上。
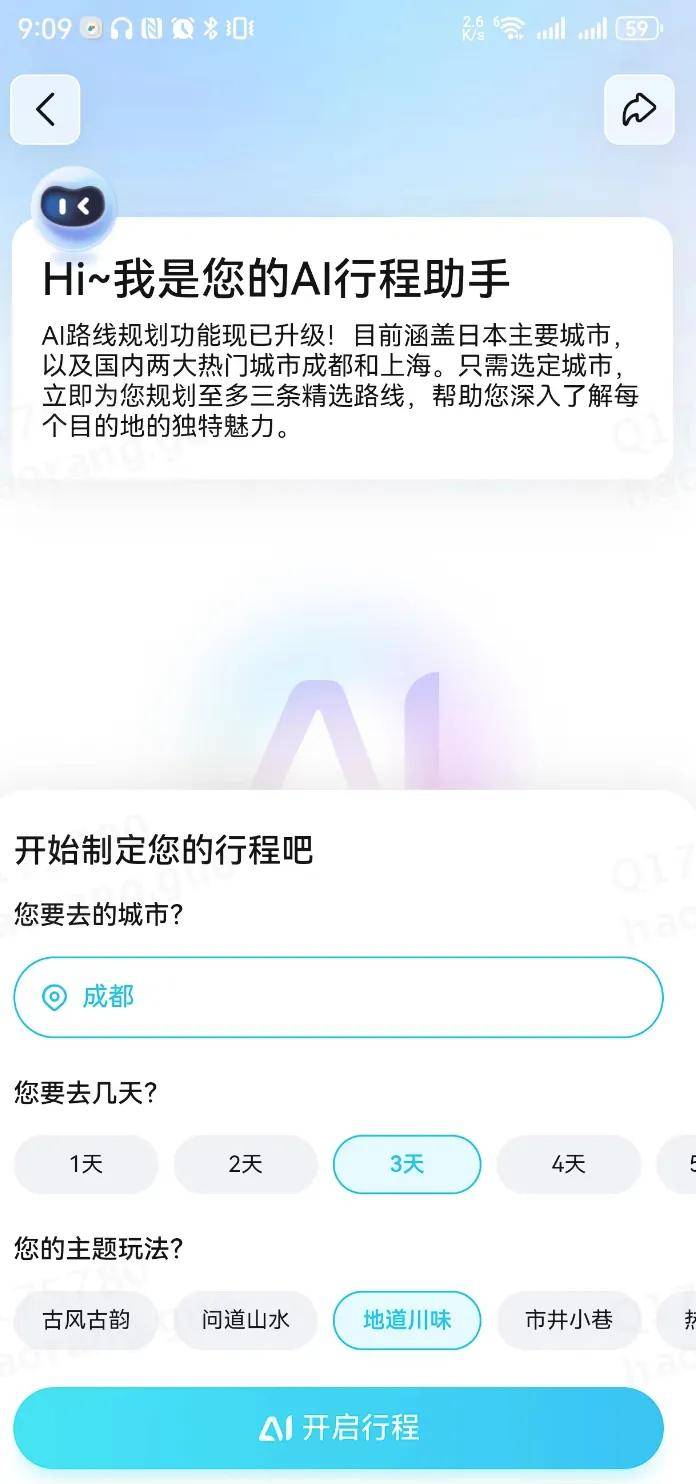
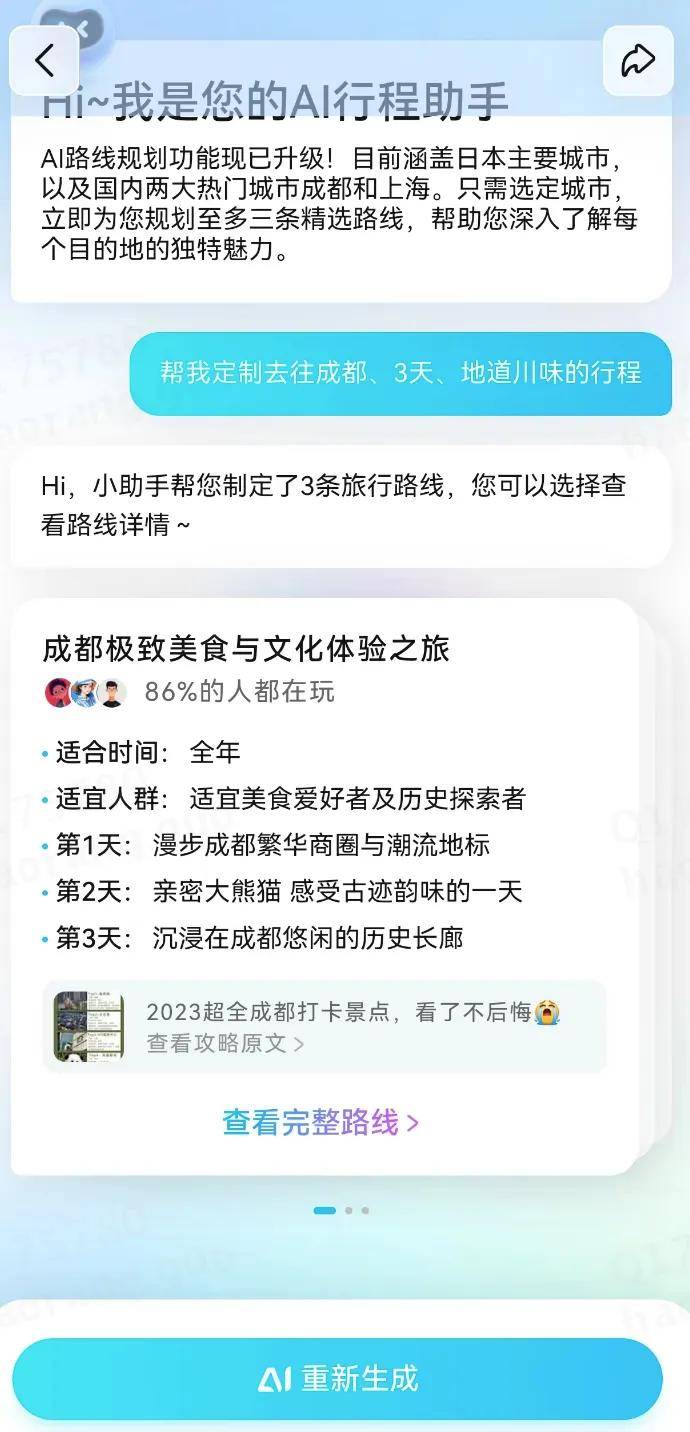
3、Qunar旅行助手
旅行助手基本工作流程如下:离线任务挖掘时下热门且优质的出行攻略或旅行线路;线上服务结合LLM的语言理解能力,通过对话的形式了解用户诉求,推荐给用户高质量且符合需求的优质游玩路线;其中数据落库用的就是PgVector。

具体界面如下:
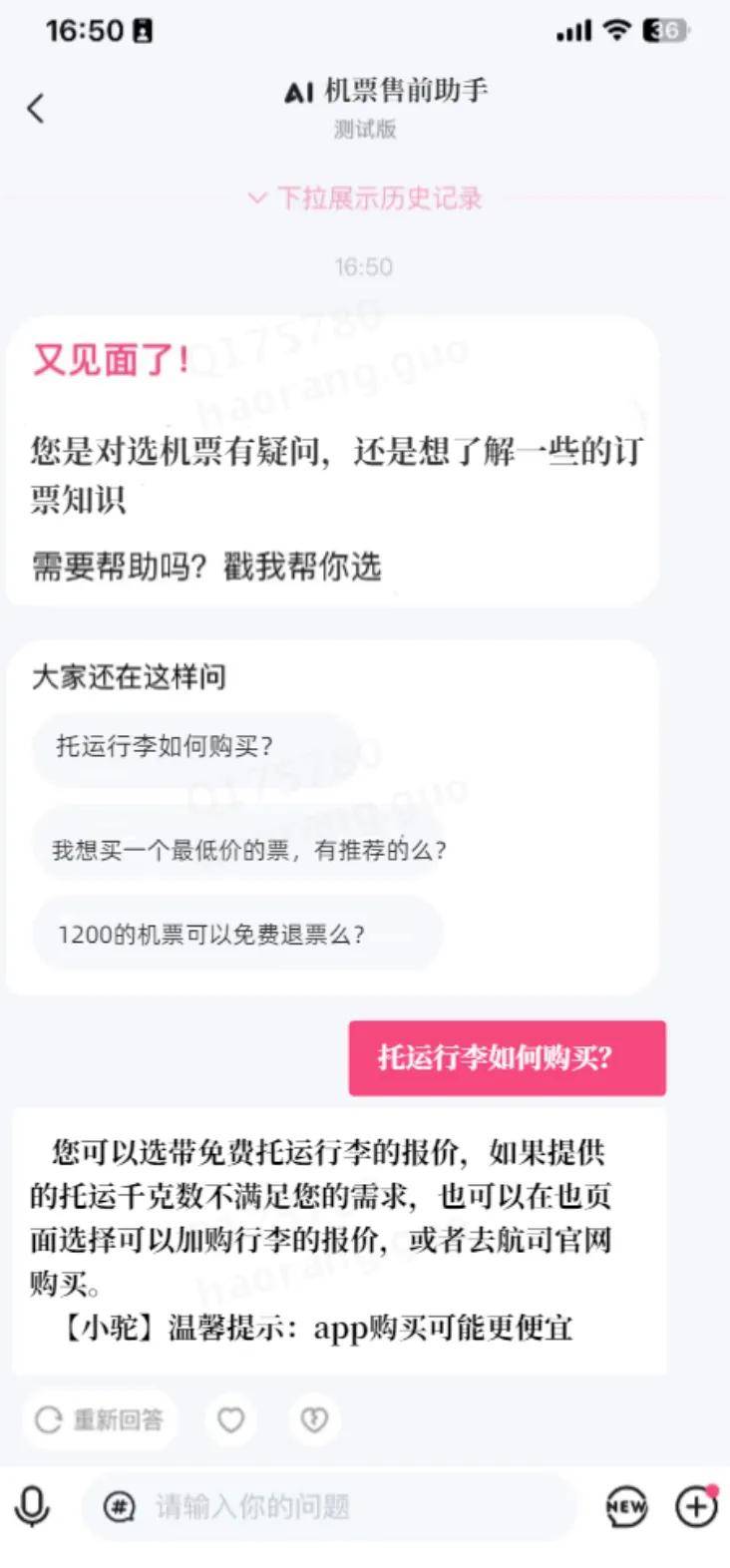
4、Qunar机票智能售前AI助手
机票智能售前AI助手通过自建静态知识库并借助LLM的智能解决用户订前咨询的问题,由于实现涉及较多敏感业务逻辑此处不做介绍,助手界面如下:
七、总结与展望
参考资料
[1] https://github.com/pgvector/pgvector
[2] PostgreSQL正在吞噬数据库世界
https://www.modb.pro/db/1764473385338343424
[3] 云程发轫,万里可期——PostgreSQL与向量数据库_xiongcc
[4] 向量数据库简介和5个常用数据库介绍
https://developer.aliyun.com/article/1405009?spm=a2c6h.12873581.technical-group.dArticle1405009.13cc42c9UQ82m1
[5] 向量数据库的分类概况
https://blog.csdn.net/m0_71917549/article/details/134384595
[6] PostgreSQL向量数据库pgvector之ivfflat实践
https://blog.51cto.com/molu2013/6655707
[7] Yury,A,Malkov,et al.Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs.[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018.DOI:10.1109/TPAMI.2018.2889473.
[8] 向量索引算法HNSW和NSG的比较
https://juejin.cn/post/6844904067043442695
[9] AN EARLY LOOK AT HNSW PERFORMANCE WITH PGVECTOR
https://jkatz05.com/post/postgres/pgvector-hnsw-performance/
[10] The PASCAL Visual Object Classes Homepage, http://host.robots.ox.ac.uk/pascal/VOC/
[11] 集成向量数据库对比:MyScale vs. PostgreSQL & OpenSearch
https://blog.csdn.net/MyScale_VectorDB/article/details/135090701
[12] 大模型为什么会有 tokens 限制制
https://zhuanlan.zhihu.com/p/681829798
[13] 大型语言模型LLM应用
https://zhuanlan.zhihu.com/p/666278645
[14] 大语言模型LLM的幻觉问题
https://zhuanlan.zhihu.com/p/666278645
[15] 向量数据库关键技术及其在电信大模型中的应用,中兴通讯尚长军








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721