
过去三年我一直在面试工程师,并问他们问同一个问题:“请告诉我一次你遇到数据库性能问题的经历。”
答案出奇地一致:
这些都是有效的解决方案,但它们都是治标不治本。
真正的问题是什么?大多数团队把数据库当作愚蠢的存储桶,而不是强大的处理引擎。

我是付出了惨痛代价才明白这一点的!接下来,让我告诉你我们是如何让应用程序濒临崩溃,以及我们如何通过减少代码中的工作、增加数据库中的工作来修复它。
仪表板的缓慢死亡
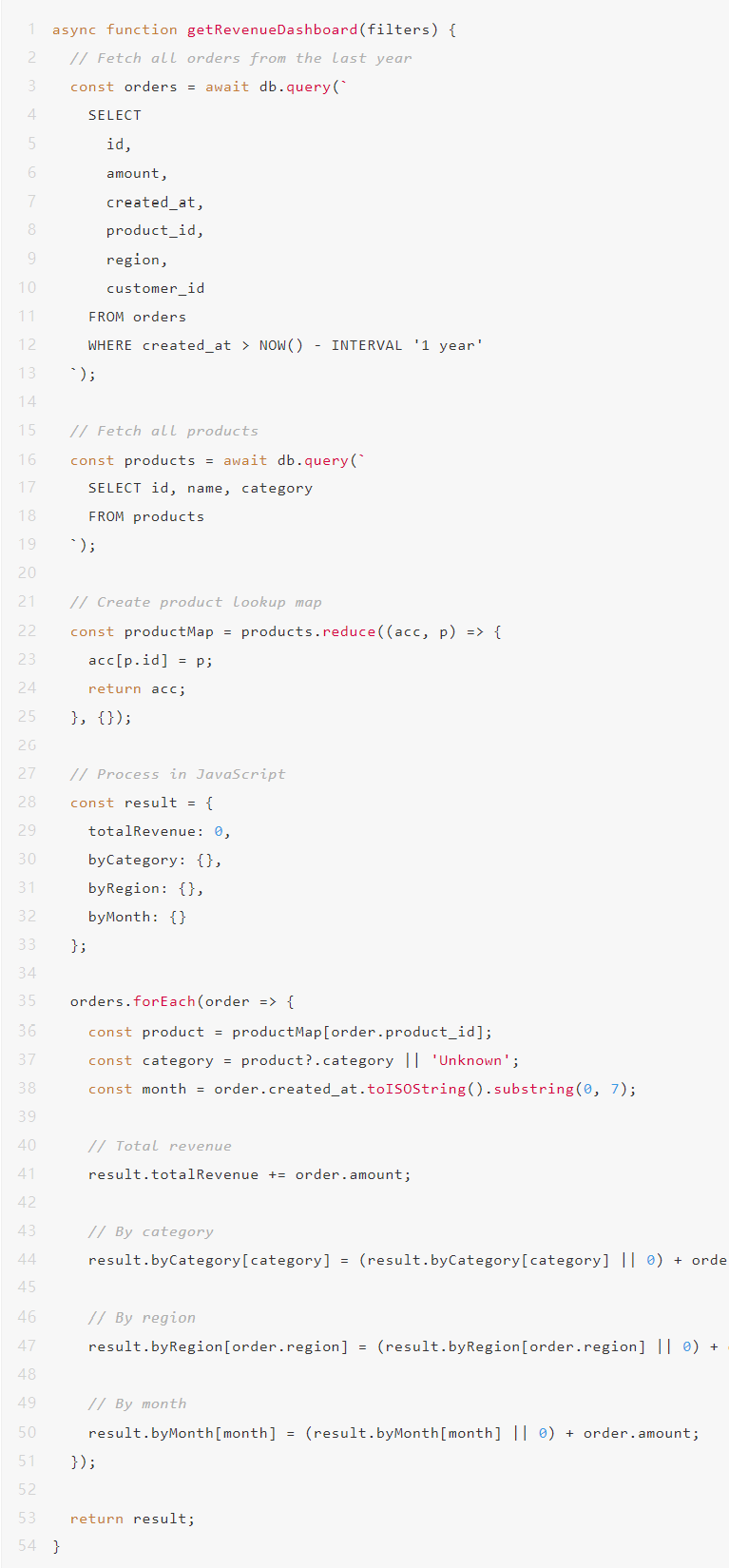
我们构建了很普遍的一个分析仪表板:显示不同时间段、区域和产品类别的收入指标(基本的企业智能内容)。
我们最初的实现很简单,获取所有数据,在Node.js中处理,发送到前端:
我们尝试了通常的修复方法:
没什么真正管用!根本问题仍然存在:我们正在通过网络拉取数十万行数据,将它们保存在内存中,并做那些数据库本可以快1000倍完成的数学运算。
顿悟
我们的数据库顾问(是的,我们雇了一个)看了我们的代码大约30秒,然后说:“你们为什么要在Node里做所有这些事?”
“因为……业务逻辑就在那里?”
他重写了我们的查询:

拥有350000个订单时的响应时间:47毫秒。
不是打字错误!从7.8秒到47毫秒,提升了166倍。
我们新的Node.js代码:

就这样,数据库完成所有工作,Node只返回结果。
为什么会出现这种情况
大多数开发者(包括过去的我)都犯了同样的错误。我们这样看待数据库:
所以我们这样写代码:
但现代数据库并非愚蠢的存储,PostgreSQL、MySQL、SQL Server——这些都是复杂的计算引擎,它们可以:
当你从数据库中取出数据并在应用程序中处理时,你正在:
数据库可以跳过步骤1-6,直接给你答案。
真实的错误例子
例子1:N+1查询问题
我经常看到这种情况:

如果有1000个用户,这就执行了1001次数据库查询。

一次查询,数据库完成所有工作。
例子2:在代码中进行复杂过滤

你刚刚通过网络拉取了50000个产品,只为了找到12个。
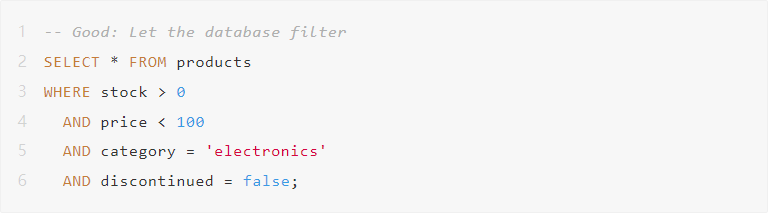
数据库有索引,它知道如何高效过滤,利用它。
例子3:计算衍生值

SQL为此做了优化,JavaScript没有。
这在什么时候真正重要
“但我的查询足够快”,你可能会说。
也许现在是够快。但是考虑一下:
这就是数据库端处理能带来巨大差异的地方:
场景1:报告和分析
任何类型的聚合、分组或统计分析都应该在数据库中进行。毫无疑问。
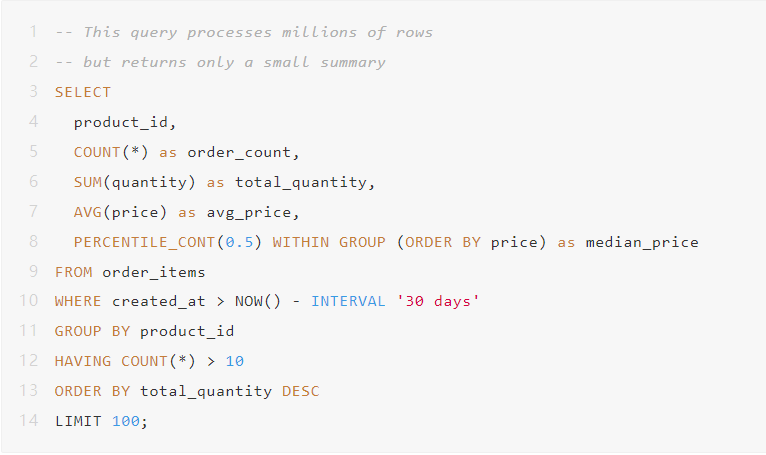
尝试在应用程序代码中做这个?你会把数百万行加载到内存里。数据库在毫秒内完成。
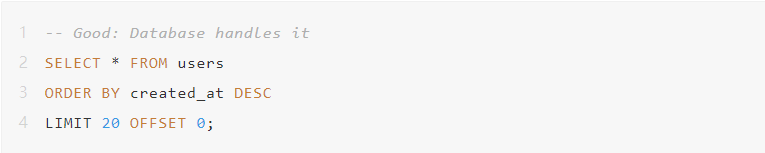
场景2:带排序的分页

你获取了100000个用户只为了显示20个。
场景3:复杂的业务逻辑
人们认为业务逻辑必须存在于应用程序代码中,但数据库可以处理它:
这种逻辑写成SQL,通常比写成带有多个循环和条件判断的应用程序代码,更具可读性和可维护性。
ORM怎么样?
“但是我用ORM!那不是正确的方法吗?”
ORM对于CRUD操作来说很棒。但对于复杂查询来说它们很糟糕,因为它们强迫你从对象的角度思考,而不是集合的角度。
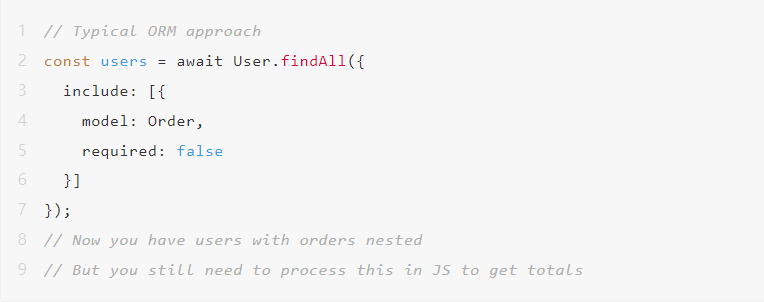
ORM获取了比需要多得多的数据,而你仍然需要处理它。
我的原则是用ORM进行简单的读写操作。对于任何涉及以下内容的操作,降级到原始SQL:

你没在用的数据库功能
现代数据库拥有令人难以置信的功能,但大多数开发者从未接触过:
窗口函数

试试在应用程序代码中做这个,我等着你!
公共表表达式(CTEs)
将复杂查询拆分成可读的部分:

这比用多个循环编写的等效应用程序代码更具可读性。
JSON操作
PostgreSQL可以直接处理JSON:

不需要在你的应用中反序列化JSON。数据库处理它。
生成列
让数据库维护衍生值:

永远不要再在代码中计算 price_with_tax 了。它总是正确的。
约束
使用数据库来强制执行业务规则:
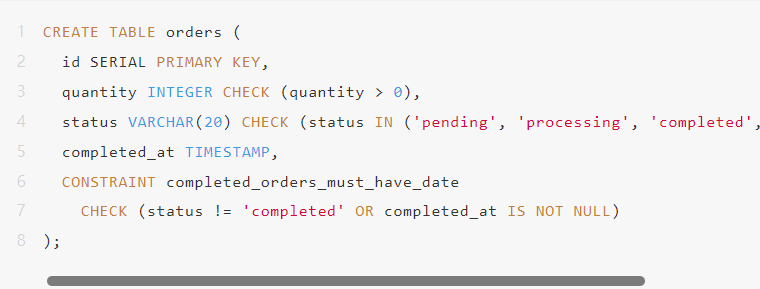
你的应用程序代码无法意外违反这些规则。
思维模式的转变
停止这样想:
“数据库存储我的数据。我的应用程序处理它。”
开始这样想:
“数据库是一个强大的处理器。我的应用程序协调它。”
你的应用程序应该:
你的数据库应该:
这并不意味着什么
我并不是说:
我是说:
需要平衡。有些逻辑属于应用程序代码:
但是数据聚合、过滤和转换呢?那是数据库的领域。
结果
在我们转变了思维模式并重写了关键查询之后,我们的应用程序发生了转变:
我们仍然在使用Node.js和React,我们仍然在使用ORM进行基本操作。
但是我们不再把数据库当作愚蠢的存储桶,而是开始把它当作强大的计算引擎来使用,这一点带来了天壤之别的体验。
作者丨Bhavyansh
来源丨网址:https://bhavyansh001.medium.com/the-single-biggest-mistake-teams-make-with-databases-e6ed980c0655
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721