
本文将重点探讨UUID v4与UUID v7作为聚集索引时的性能比较。
UUID v4
UUID(Universally Unique Identifier)是一个由128位构成的标识符,通常以32个十六进制数字表示,并通过破折号分为五组,形成8-4-4-4-12的格式。例如,"123e4567-e89b-12d3-a456-426655440000"。UUID v4的每个十六进制字符可取值范围为0至f。在数据库中,UUID v4可以以字符串形式或直接以16字节的二进制形式存储。
UUID v4通过完全随机或伪随机数生成器生成,确保了其高度的唯一性。据估计,生成的UUID v4样本具有3.26*10¹⁶的基数,重复概率低于0.01%。【详情请阅读参考资料2】
UUID v7
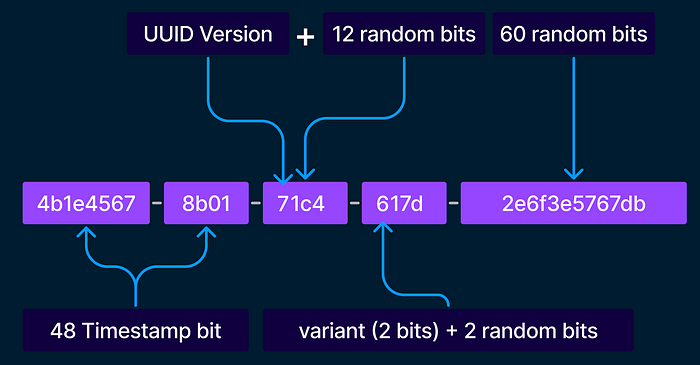
UUID v7同样是一个128位的标识符,格式遵循8-4-4-4-12的十六进制表示。UUID v7的创新之处在于其时间排序特性,它在前48位中嵌入了以毫秒为单位的Unix时间戳。UUID v7的格式中,前6位定义了版本号和变体号,剩余74位通过随机生成确保唯一性。
在聚集索引的性能考量中,UUID v7由于其有序性,可能在插入和查询操作上提供更好的性能,尤其是在需要维护数据顺序的场景中。
为什么选择UUID而非顺序ID?
UUID与顺序ID的比较
1)优点
唯一性:UUID的设计确保了极低的冲突概率,允许在记录插入前独立生成ID,无需中央协调。
安全性:UUID通过隐藏记录的创建顺序,增强了数据库的安全性,防止了潜在的恶意推断。
2)缺点
存储开销:与INT(4字节)或BIGINT(8字节)相比,UUID需要更多的存储空间(16字节)。
输入难度:UUID的复杂性使得手动输入变得困难。
查询效率:较大的UUID尺寸可能会降低查询性能,因为它们增加了记录的体积,减少了每个数据库页面能够存储的记录数量,从而增加了I/O操作的需求,影响了整体性能。
索引和数据碎片化:UUID可能会引起索引和数据的碎片化,这可能会降低数据库的效率,这一点需要进一步的探讨和优化。
具体实验
概述:本实验采用了MySQL、Docker、Node.js和Go语言。通过docker-compose文件配置并运行MySQL,并将数据持久化到卷中(实验结束后自动清理该卷)。
注意:MySQL被选中的原因是其默认使用聚集索引,而PostgreSQL则不具备此特性。
实验通过Node.js脚本和Go程序逐条插入100万条记录(避免使用批量插入,以防止数据库引擎对记录进行排序,影响实验结果)来评估插入性能。同时,使用Go语言和goroutines模拟多服务器连接,插入200万条记录,每个核心分配7个线程,保留一个核心运行Docker守护进程。
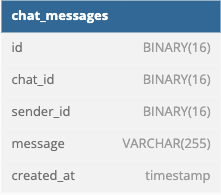
实验模拟了一个聊天数据库,包含一个名为“chat_messages”的表,字段包括id、chat_id、sender_id、message和created_at。字段类型根据输入数据是整数、UUID v4还是UUID v7,分别设置为INT或BINARY(16)。
记录:尽管使用触发器或存储过程可以更精确地记录插入时间,但为了提高速度,实验中采用了应用程序记录时间。实验在不同机器和程序(Node.js和Go)上重复多次,结果误差较小。
实验在专用机器上进行,确保实验过程中不会共享系统资源,从而最大限度地减少外部干扰,提高结果的可靠性。
步骤(以下是实验的伪代码概览):
1.运行docker-compose文件。
2.连接到MySQL数据库。
3.创建“chat_messages”表(使用UUID v4)。
4.插入记录并记录时间(UUID v4)。
5.停止Docker并删除卷(防止影响UUID v7的插入测试)。
6.等待1秒(让系统清理内存和交换空间)。
7.创建“chat_messages”表(使用UUID v7)。
8.插入记录并记录时间(UUID v7)。
9.停止Docker并删除卷。
10.等待1秒。
11.创建“chat_messages”表(使用整数ID)。
12.插入记录并记录时间(整数ID)。
13.停止Docker并删除卷。
14.等待1秒。
如有需要,可复制此repo在你的机器上再次运行实验。地址:
GitHub—RimonTawadrous/uuidv7-vs-uuidv4-sql
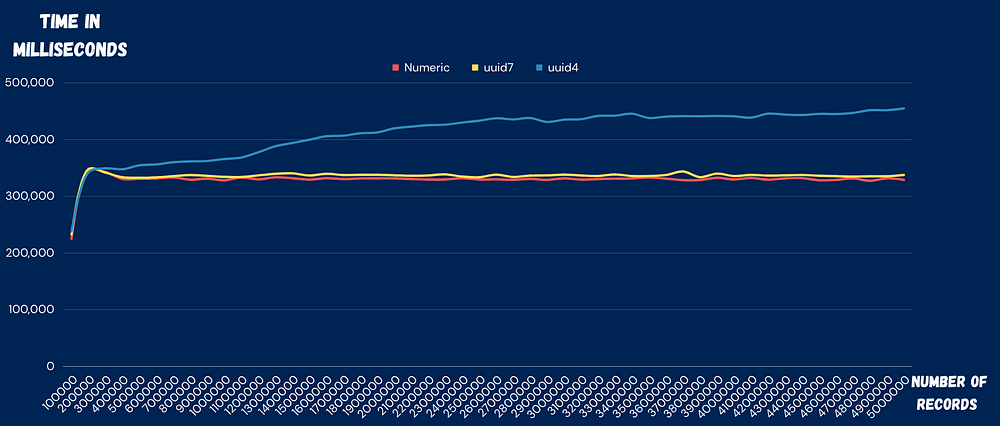
实验结果
单线程插入性能
UUID v4:耗时 24,345,338.406 ms
UUID v7:耗时 23,579,840.357 ms
INT:耗时 23,678,315.195 ms
UUID v4 与 UUID v7 性能比:1.0324 (即 UUID v4 比 UUID v7 慢 3.24%)。
GoLang 多线程插入性能
UUID v4:耗时 263,207,709.854 ms
UUID v7:耗时 255,926,080.539 ms
INT:耗时 257,598,898.253 ms
UUID v4 与 UUID v7 性能比:1.0284 (即 UUID v4 比 UUID v7 慢 2.84%)。
多线程Go程序插入性能
在使用 7 个线程进行 500 万条记录插入的情况下,每个线程绑定到一个核心上。
UUID v4:耗时 20,634,873.510 ms
UUID v7:耗时 16,750,775.022 ms
INT:耗时 164,567,295.364 ms
UUID v4 与 UUID v7 性能比:1.2318 (即 UUID v4 比 UUID v7 慢 23.18%),与 INT 性能比:1.2530 (即 UUID v4 比 INT 慢 25.30%)。
请注意,每次运行的结果可能会有变化。
为什么UUID v7比UUID v4更高效?
索引布局
首先,理解聚集索引的概念对于评估性能至关重要。
聚集索引的存储方式:
每个数据记录存储在数据库的一个页面上,而聚集索引以B+树结构组织在这些页面中。B+树确保了索引键的有序性。当向索引中插入新键时,可能需要重新组织索引结构,这涉及到页面的获取、读取和调整节点间的指针,以及可能的新页面插入。
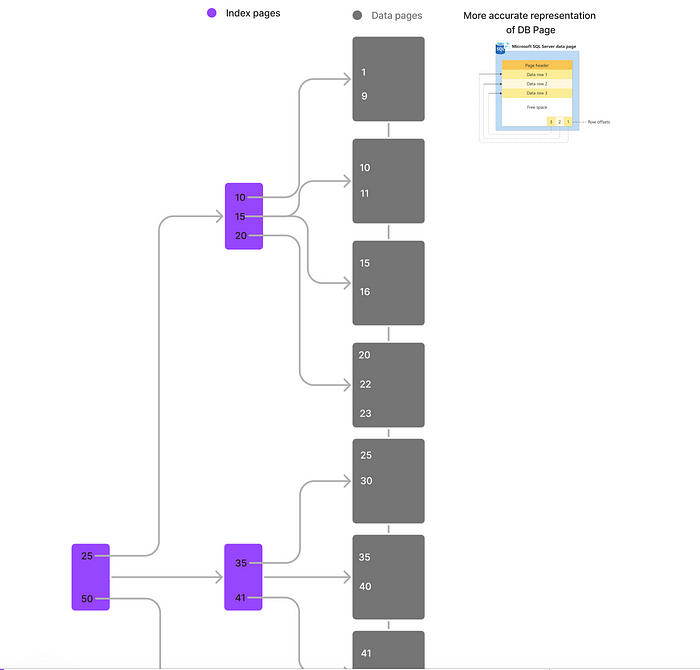
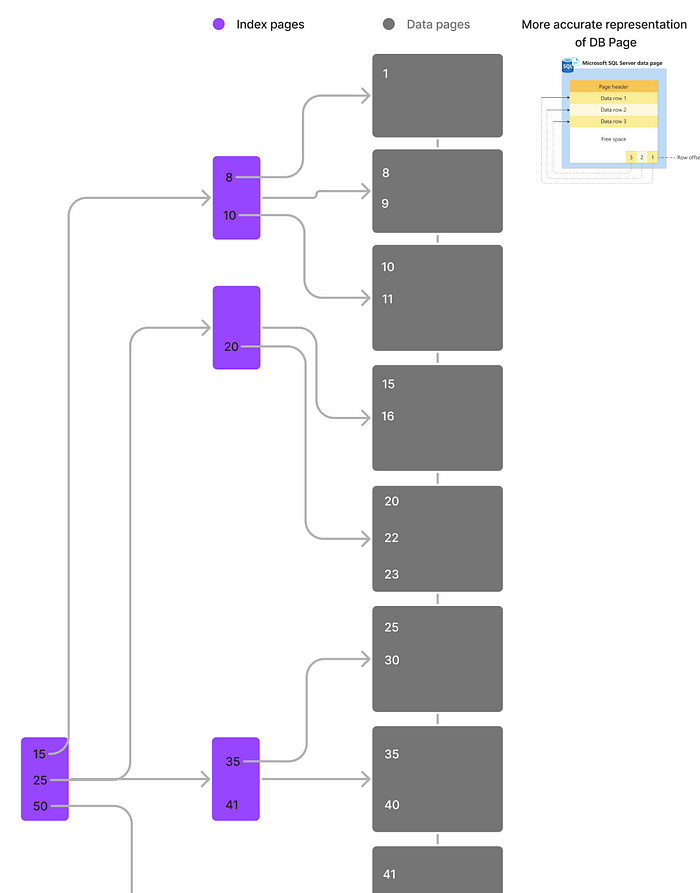
例如,在根页面中插入ID为15的记录后,包含键值10、15和20的页面可能需要进行拆分。重要的是,数据页面的拆分也会影响索引的维护。
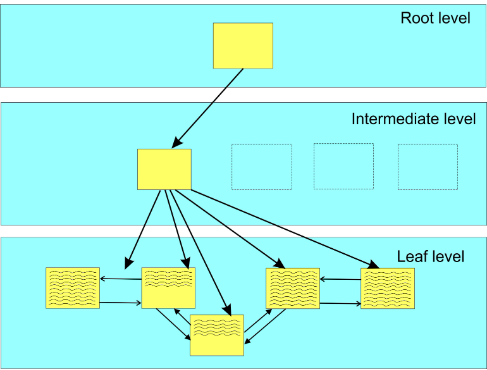
无序ID对性能的影响
UUID v4的ID由于其完全随机性,导致索引的局部性差。新生成的UUID v4可能在排序上位于旧UUID v4之前,这与聚集索引的有序性要求不符,因此需要进行页面的重新排序或拆分。
相比之下,UUID v7由于其基于时间戳的生成机制,具有内在的有序性。这意味着UUID v7的值几乎是连续的,并且可以一致地插入到聚集索引的末尾,从而有效避免了索引局部性问题,提高了插入操作的效率。
缓冲池
数据库与系统中其他应用程序一样,受内存资源限制,需向操作系统申请有限的内存空间。该引擎负责执行包括查询优化、数据解析、排序和连接等操作。最关键的是,数据库使用这部分内存来缓存从磁盘加载的数据页以及为新记录创建的数据页,这一内存区域被称为“缓冲池”。
缓冲池的功能不仅限于支持读取操作,它还用于处理数据的插入、更新和删除。数据库引擎必须首先从缓冲池中检索或激活包含目标记录的数据页,然后在该页上执行相应的数据修改操作。

为什么讨论缓冲池?
缓冲池管理是数据库性能优化的关键。UUID v4 由于其生成的 ID 具有高度随机性,可能导致缓冲池迅速达到容量上限。由于每个记录可能散布在不同的数据页中,数据库引擎需要频繁地从缓冲池中检索数据。当缓冲池满载时,它必须将部分数据页写回磁盘,以腾出空间加载新的数据页。这个过程可能导致性能瓶颈,因为每次写入操作都可能涉及磁盘I/O,增加了延迟。
相比之下,使用 UUID v7 或连续整数(Serial Integer)作为主键的记录,其 ID 值是顺序生成的。这意味着当达到数据页的容量限制时,新记录可以被顺序添加到当前页的末尾,或者在必要时由数据库引擎创建新的数据页。这种顺序访问模式减少了对缓冲池的随机访问,从而降低了因缓冲池满载而频繁写回磁盘的需要。此外,数据库引擎可能会采用延迟写入策略,例如仅在 WAL(Write-Ahead Logging)中记录变更,以进一步优化性能。
最后:为什么序列号(Serial)比UUID更快?
这个问题的答案相对简单。
以MySQL和PostgreSQL为例,数据库页面的默认大小分别为16KB和8KB。在记录大小方面,假设每条记录仅包含基本字段,序列号(INT类型)的记录可能大约为271字节(包括INT类型字段和VARCHAR(255)类型字段等),而UUID(16字节的固定长度)的记录通常为307字节(包括额外的16字节UUID和其他字段)。
如果我们假设每个页面仅存储一条记录(实际情况可能有所不同),那么使用序列号的页面可以存储更多的记录。这导致需要进行更少的I/O操作,从而提高了访问速度。
此外,UUID v1已经采用了基于时间戳的GUID概念,尽管存在一些限制。一些现代系统,如Instagram的ShardingID、Shopify的ULID以及MongoDB的ObjectID,都采用了类似UUID v1的有序和紧凑的ID生成策略。
希望这些信息对您有所帮助。如果您有任何改进建议或其他问题,欢迎随时交流。
未来工作计划
Rust性能测试:计划使用Rust语言进行性能测试,以评估其与现有技术栈相比的性能表现。
索引结构分析:计划测量不同索引类型(如UUID v4、UUID v7和INT)的B+树索引结构大小,以了解不同数据类型对索引存储需求的影响。
数据库连接池优化:计划实施数据库连接池以优化数据库连接管理,提高资源利用率和系统性能。
参考资料
【1】https://www.youtube.com/watch?v=f53-Iw_5ucA&t=416s
【2】https://www.intl-spectrum.com/Article/r848/IS_UUID_V4_UUID_V4_Random_Generation#:~:text=All%20a%20Version%204%20UUID,same%20UUID%20more%20than%20once.
【3】https://towardsdatascience.com/are-uuids-really-unique-57eb80fc2a87?gi=a4abdb675d18
【4】https://datatracker.ietf.org/doc/html/rfc4122
【5】https://blog.bhanunadar.com/pros-and-cons-of-using-uuid-as-primary-key-in-postgres/
【6】https://www.ietf.org/archive/id/draft-peabody-dispatch-new-uuid-format-04.html#timestamp_granularity
【7】https://www.sqlservercentral.com/articles/how-bad-are-bad-page-splits
【8】https://buildkite.com/blog/goodbye-integers-hello-uuids








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721