
一、软件里的爱马仕
Linear 是硅谷这两年涌现出的一家明星公司。它做的是类似于 Jira, Asana 的项目管理工具,但定位聚焦在软件研发的项目管理上。Linear 很早就实现盈利了,Vercel,Arc 浏览器,Mercury 这些当红公司也都是 Linear 的客户。

因为创始人强大的设计背景,其在创办 Linear 前曾先后负责过 Coinbase 和 Airbnb 的设计团队。所以 Linear 的产品设计尤其突出,以致在行业里掀起了 Linear style 的设计潮流。

而就是这样一支全身散发着光环的顶级硅谷团队,也在前不久迎来了 5 年公司历史上最大的一次故障。而元凶依然是我们熟悉的桥段「删库跑路」。
二、故障时间线
此前 Linear 团队已经在官网公开了完整的复盘报告。下面我们来详细梳理一下时间线:

04:47: 全量备份完成 (事发前)。
07:01: 造成数据丢失的变更合并入主干。
07:20: 变更完成。
07:52: 发现异常,开始自查。
08:10: 启动严重事故预案,呼叫更多的工程师。
08:36: 更新公开渠道, 包括 status page 和 X,提示正在调查数据访问问题。
09:20: 进一步更新。
09:56: Linear 进入维护模式,防止进一步的变更操作,并且开始从备份进行恢复。
10:48: 数据库恢复到 4:47 的备份,Linear 重新开始可以访问。
11:09: 更新 Status page 到观察状态。
11:30: 开始恢复 4:47 到 9:56 之间的数据。
13:50: 给 4:47 到 9:56 之间新建了 workspace 的用户发送了邮件,因为 Linear 无法重建这些 workspace。
15:35: 给所有受到影响的用户和 workspace 管理员发送邮件,告知故障的信息和恢复方式。
14:00: 通知管理员上线了专门的数据还原页面。
14:25: 修复了数据还原页面的 bug,强制客户端刷新 (这又打挂了 API 导致了应用加载的问题).
16:40: 数据恢复试运行启动。
17:49: 正式的数据恢复开始。
19:48: 恢复了 98% 受影响的 workspace。
23:20: 恢复了 99% 受影响的 workspace。
07:37: 除了一个 workspace 之外,所有的都恢复了。
08:39: 完成了最后一个 workspace 的恢复。
读着时间线应该也能感受到紧张。事实上笔者所在团队也是 Linear 的用户,受到了波及。这是当时我们收到的邮件。

用户故障群里也有比较着急的用户:

三、故障原因
Linear 使用的是 PostgreSQL 数据库,它官网上没有提。但在另一个生成 PG 测试数据的产品 snaplet.dev 的官网上,列了 Linear。

导致删数据的是这条语句:

CASCADE 关键词会把所有有外健关联到 new_table 的表数据都清空掉。
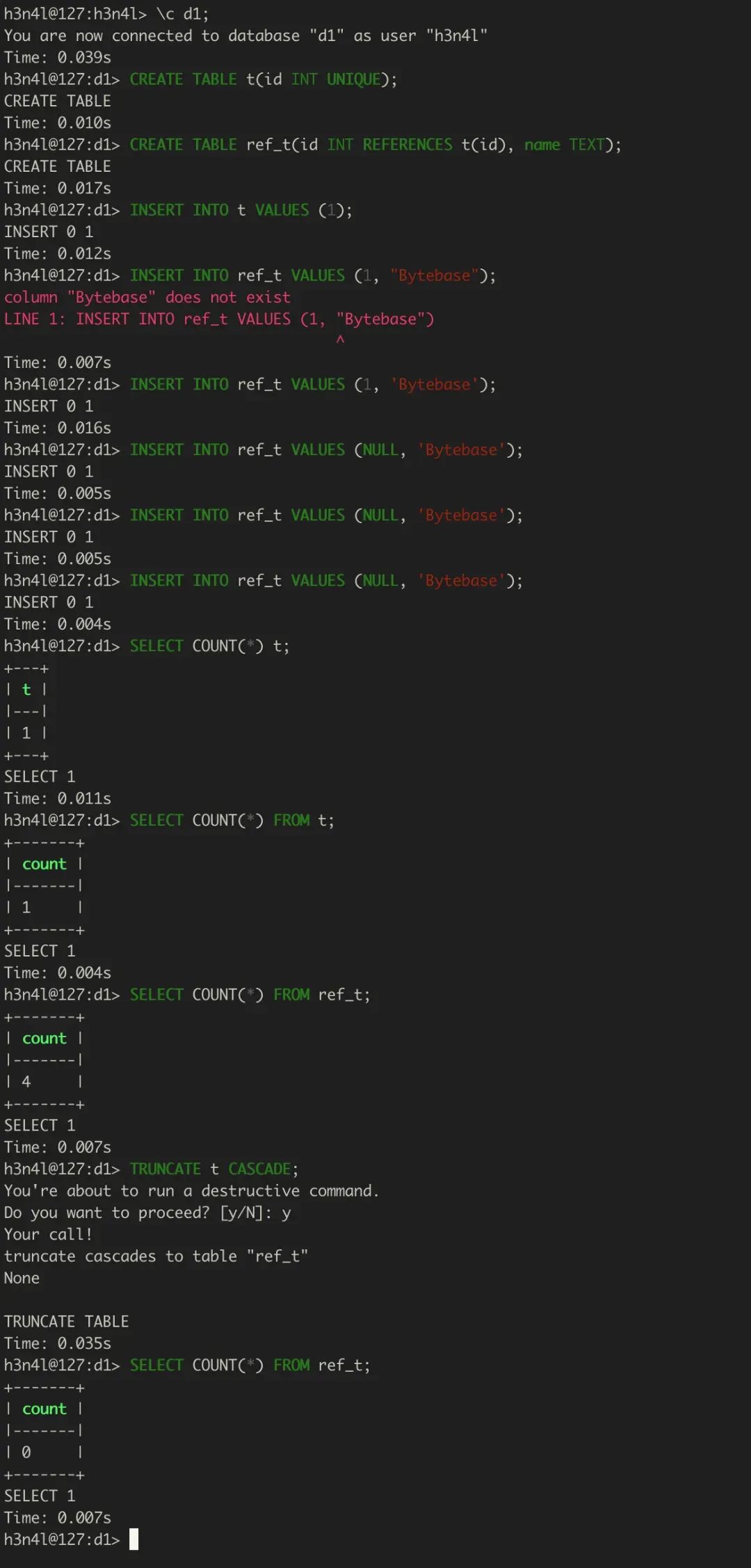
上面我们简单模拟了一下场景,可以看到当我们 TRUNCATE t CASCADE 后,会把 ref_t 的数据也都清空。我们看到通过命令行操作是有提示的,但是变更生产环境的流程通常不会采用命令行直连的方式。

Linear 采用的是主干开发,要变更的 SQL 脚本是保存在代码仓库里的。每次变更时,先提交 SQL 语句进行审核,审核会进行一些 CI 的自动检查和人工审核,没有问题后,SQL 脚本合并入主干,然后触发变更。因为代码发布和数据库变更是分离的,为了保持代码能同时兼容新旧两个数据库版本,会使用 feature flag。
Linear 的 CI 自动检查没有捕捉到这个问题,因为 CI 里没有针对 TRUNCATE 的规则。而在本地测试和人工审核时也都没有发现这个问题,也是因为这个 TRUNCATE 的隐蔽性更强。Linear 这次是在开发一个新功能时从现有的生产数据库表里创建了一份测试数据库表。工程师在测试完成后,打算清理测试数据库表。但因为生产数据表也关联了测试数据表的外键。所以 TRUNCATE 测试数据表时,也把生产数据表跟端掉了。
四、故障排查和恢复
因为 Linear 使用了好几层缓存,所以在误删了生产数据后,客户端因为缓存的关系,还没有直接报错,识别到问题的时间就靠后了些。
不过 Linear 因为本身要实现同步的需要,把用户的每一次操作都以日志的形式记录了下来,这部分的数据是单独存放的,所以他们可以基于 4:47 的全量备份,回放所有的用户操作。但还是会有少部分操作,因为冲突的原因是无法自动回放的,这就还是需要用户手动介入。
另外 Linear 的 PostgreSQL 数据库是开启了 Point-in-time recovery (PITR),但因为团队之前没有测试过 PITR,所以在恢复时没有选择这个方案,不然的话,其实可以通过 PITR 恢复到 7:01 这个变更发生的时间点,然后再回放接下来的用户操作。这样可以缩小回放的数据量。
五、故障影响面
所有用户都经历了 1 个小时的不可用,这段时间 Linear 在从备份中恢复数据。Linear 在 36 小时内恢复了 99% 的误删数据,剩下的因为冲突的原因没有办法自动解决。Linear 也说这是它 5 年历史上最严重的一次故障。

从故障发生的 1.24 到发出复盘报告的 1.30,整个团队显然是在连轴转 (work around the clock)。

六、故障反思
Linear 自己列了如下的改进措施:
剥夺所有用户在生产数据库上的 TRUNCATE 权限。
改进如何创建和执行数据库的变更操作。其中包括通过 DBA 的审核实践,和代码审核分离,以及自动检查高危操作。
改进预发环境的数据库变更测试流程。
构建和演练使用 PITR 的数据恢复流程。
改进内部事故处理的流程。
改进数据完整性检查。
给 Linear 添加只读模式。这样即使数据库不可写时,依然可以能让用户访问。
Linear 在意识到问题的第一时间就完全公开了所有情况,整个复盘报告也非常详细,对于其它研发团队也是一份很好的参考。
前车之鉴,后世之师。我们要是看 Linear 之前的流程,已经有审核,有自动 CI 检查,还有定期的备份恢复演练。但数据库变更就是一个高危又精细的操作流程,专业性极强。这也是我们团队扎根这个方向的原因,看似 1 个人 2 周时间可以糊出来的 SQL 工单平台,背后有数不清的细节,而漏掉任何一个,都可能引起误操作,导致公司历史上最大的故障。事实上我们从 Linear 的这次事故中,也吸取了教训,在下一版本中添加了关于 TRUNCATE 操作的自动检查。
读罢 Linear 的整个报告,还是要感慨它的透明度,所谓的 blameless postmortem(对事不对人的复盘)在这个报告中体现的淋漓尽致。再联想到去年国内上热搜的大故障,即使到现在,好多官方也没有一个正式的故障复盘。可能因为定责到个人,个人背后有主管,会影响到绩效,绩效挂钩奖金和晋升,各种利益夹杂在一起,就很难开诚布公地聊了。定责在国内是一种约定俗成,现阶段也很难去改变它,下次再写写怎么样让定责可以更加客观吧。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721