
作者介绍
梁铭图,新炬网络首席架构师,十多年数据库运维、数据库设计、数据治理以及系统规划建设经验,拥有Oracle OCM、Togaf企业架构师(鉴定级)、IBM CATE等认证,曾获dbaplus年度MVP以及华为云MVP等荣誉,并参与数据资产管理国家标准的编写工作。在数据库运维管理和架构设计、运维体系规划、数据资产管理方面有深入研究。
Active Data Guard(ADG)是ORACLE 11g企业版的新特性,需要单独的License.可以打开Physical standby至read only模式,standby可以用来做报表系统、查询、排序或Web站点。实时读写分离,以此来分担primary DB的压力。
一、ADG相关参数配置说明
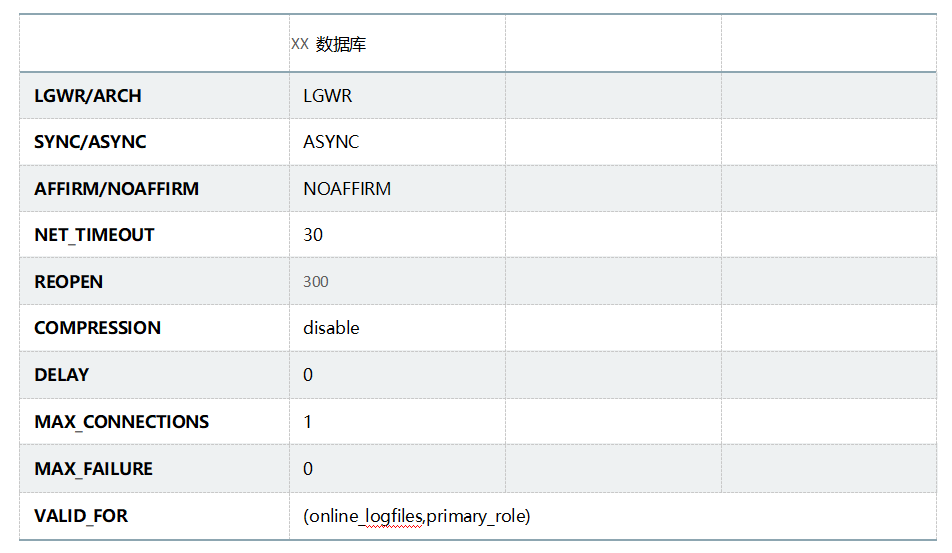
控制redo传输服务是否同步。
sync:同步服务,只有在事务产生的日志成功的传输到备库的目的地,事务才能提交。主库同步数据到备库出现延时会增加了事物提交的时间,这种同步模式一般用在最大保护,最高可用。
async:异步服务,这种模式在事务提交时不会等待此事务产生的日志成功同步到备库,这种模式一般用在最大性能。

LOG_ARCHIVE_DEST_11 到 LOG_ARCHIVE_DEST_31 需要COMPATIBLE 设置为 11.2.0.0 以上才可以用,而且不支持 SYNC 。
指定Redo传输服务在写Standby Redo Log时,磁盘I/O是否同步。
AFFIRM表示Redo传输服务在写Standby Redo Log时,只有写入成功后,Log写进程才会继续。
NOAFFIRM是默认值,表示Redo传输服务在写Standby Redo Log时是异步的,Primary端的日志写进程不会等待Standby端写Standby Redo Log。

如果该属性没有指定,默认情况下,在指定同步方式为SYNC时为AFFIRM,在指定同步方式为ASYNC时为NOAFFIRM。
如果没有指定SYNC属性,那么单独设置该属性为AFFIRM将不生效/不支持。
对SYNC/ASYNC,AFFIRM/NOAFFIRM的理解:
这2对属性单独理解比较困难,需要结合起来一起分析。这2对属性控制了Data Guard在做同步数据时的方式,同时也决定了Data Guard的保护模式。下面通过LGWR模式的过程可来理解。
在Primary数据库产生commit事件之后,Primary数据库通过LGWR进程写Online Redo Log,此时LGWR进程会同步或者异步(SYNC/ASYNC)写入Standby Redo Log。如果该归档路径是远程的(归档路径设置为SERVICE),那么LGWR进程会调用LNSn进程,通过Oracle Net建立网络连接,然后往Standby数据库传输Redo Log。
在Standby数据库,RFS进程(Remote File Server Process)在接收到LNSn进程传输来的Redo Log后,如果是AFFIRM,那么RFS进程会在成功写入Standby Redo Log之后返回给Primary数据库一个处理结果,Primary数据库的LGWR进程会进行等待直到Standby数据库返回处理结果。
如果是NOAFFIRM,那么Standby数据库的RFS进程在接收到Redo Log后,在写入Standby Redo Log之前就返回给Primary数据库处理结果,此时Primary数据库的LGWR进程不会等待Standby数据库的RFS进程写Redo Log,因为已经提前收到了处理结果。
关于SYNC和AFFRIM的区别 :
SYNC指的是网络传输同步,AFFIRM指的是远端归档写入同步。
LGWR SYNC AFFIRM意味着主要的事务提交正在等待 网络I / O +磁盘I / O,这种模式可以确保零数据丢失。
LGWR SYNC NOAFFIRM表示主要事务提交仅等待网络I / O,这种模式无法确保零数据丢失。
建议:
未发现参数配置存在问题 。

指定等待多少秒后,LGWR不再继续等待目标端发回redo数据到达的确认,同时报错并终止和目标端连接。
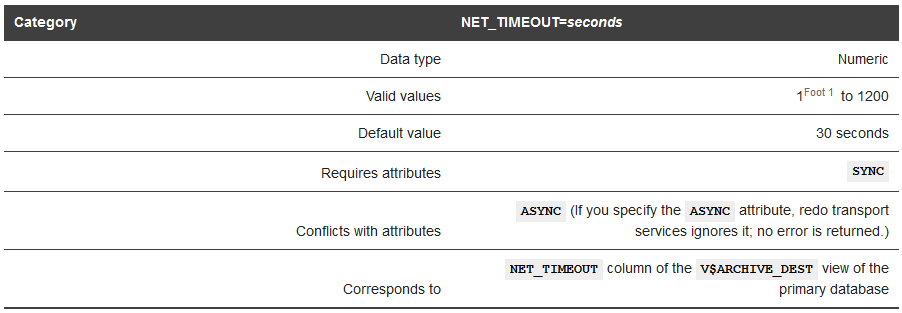
设置NET_TIMEOUT要求同步模式为SYNC,否则参数不生效(timeout 也不会报错) 。
尽管最小值可以设置为1秒,但为了避免网络传输问题导致断链,建议设置最小值在8-10秒;不指定该值,默认为30秒,可能导致主库挂起问题,建议设置为较小的值,主库在等待超时后可以继续其他操作。
建议:
当前采用默认值,未发现网络传输故障,但是由于采用异步传输, 不需要设置该参数 。

指定目标端传输失败后,REDO传输服务尝试多少次。
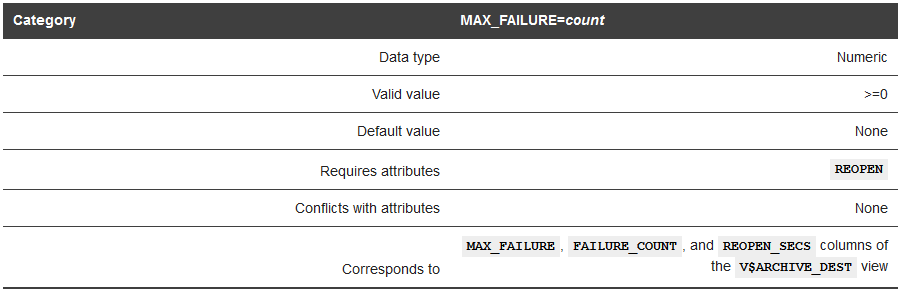
到达最大失败次数后,必须使用alter system set修改参数来清零。
只有在传输归档时候才使用,允许使用多个归档进程来并行传输一个归档 。
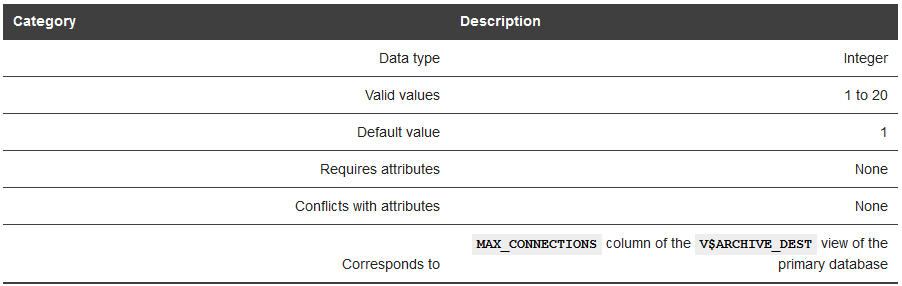
MAX_CONNECTIONS属性是可选的。如果指定,则仅在redo传输服务使用ARCn进程进行归档时使用。
如果MAX_CONNECTIONS设置为1(默认值),redo传输服务使用单个ARCn进程将redo数据传输到远程目标。
如果MAX_CONNECTIONS设置为大于1的值,则redo传输服务使用多个ARCn进程并行地将redo数据传输到远程目标上的redo日志文件。每个归档程序(ARCn)进程使用单独的网络连接。
建议:当前使用LGWR 传输,设置为1 , 如果有带宽压力,可以加大概参数。

二、ADG同步性能评估
DATAGUAD中redo 传输的主要影响因素是网络带宽,文档736755.1介绍了对网络带宽的要求的计算方法。
《How To Calculate The Required Network Bandwidth Transfer Of Redo In Data Guard Environments (Doc ID 736755.1) 》。
通过以下可统计主库REDO数据的产生速率:
select thread#,
sequence#,
blocks * block_size / 1024 / 1024 MB,
(next_time - first_time) * 86400 sec,
(blocks * block_size / 1024 / 1024) / ((next_time - first_time) * 86400) "MB/s"
from v$archived_log
where ((next_time - first_time) * 86400 <> 0)
and first_time between
to_date('2018/01/29 08:00:00', 'YYYY/MM/DD HH24:MI:SS') and
to_date('2018/01/29 11:00:00', 'YYYY/MM/DD HH24:MI:SS')
and dest_id = 2
order by first_time;
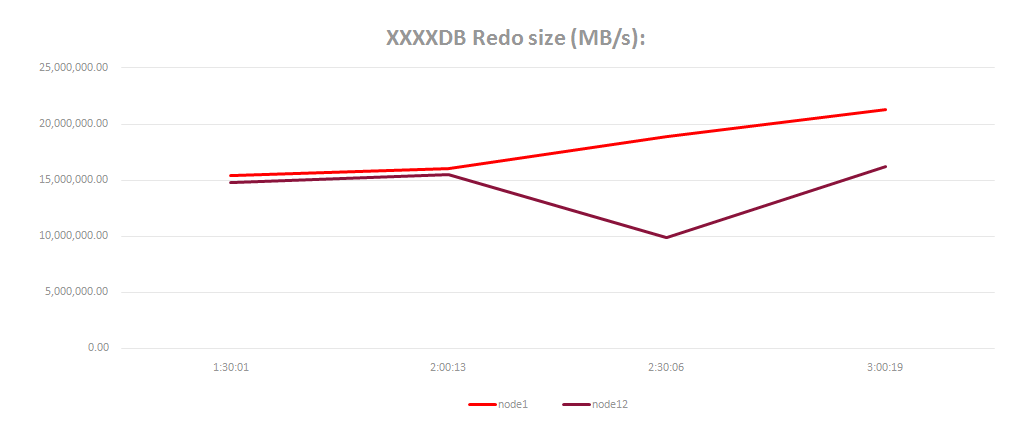
通过主库REDO数据的产生速率来计算所需要的网络带宽:
Required bandwidth = ((Redo rate bytes per sec. / 0.75) * 8) / 1,000,000 = bandwidth in Mbps
(除以0.75表示网络传输中其他的网络开销占用25%左右)。

同时可以考虑在 连接串上 设置 RECV_BUF_SIZE 和 SEND_BUF_SIZE来增加传输效率。
Setting SEND_BUF_SIZE and RECV_BUF_SIZE (文档 ID 260984.1)。

standby = (DESCRIPTION=
(SEND_BUF_SIZE=6997500)
(RECV_BUF_SIZE=6997500)
(ADDRESS=(PROTOCOL=tcp)(HOST=stby_host)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=standby)))
LISTENER = (DESCRIPTION= (ADDRESS=(PROTOCOL=tcp) (HOST=stby_host)(PORT=1521) (SEND_BUF_SIZE=9375000) (RECV_BUF_SIZE=9375000)))
根据redo的产生速率来设置redo组的大小。
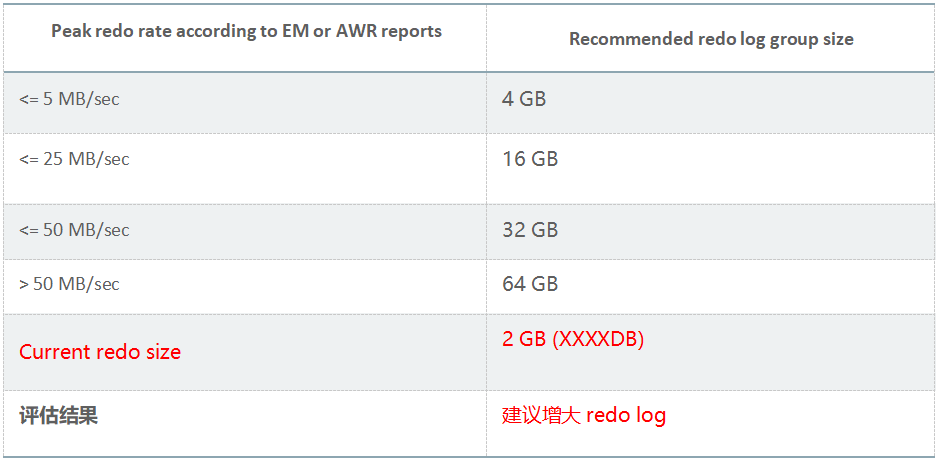
另外建议:
standby redo log groups 只包含一个 member 有助于提高性能。
三、11g ADG应用最佳实践推荐
适用场景:在ADG切换时对切换时间有要求的应用 。
How To Configure Client Failover For Dataguard Connections Using Database Services (Doc ID 1429223.1).
11.2上新增的特性 role-based database services,通过该特性创建不同数据库角色的service并在客户端创建一致的连接字符串,通过数据库角色的改变,客户端自动连接到对应数据库。
方法:
1)在PRIMARY和STANDBY都创建一个PRIMARY角色的service并在PRIMARY启动。
srvctl add service -d ora11gR2 -s prim_db -l PRIMARY -e SESSION -m BASIC -w 10 -z 10。
*service prim_db 只有在PRIMARY角色数据库上生效 。
2)在PRIMARY和STANDBY都创建一个PRIMARY角色的service并在STANDBY启动。
srvctl add service -d ora11gR2 -s stby_db -l PHYSICAL_STANDBY -e SESSION -m BASIC -w 10 -z 10。
*service stby_db 只在PHYSICAL_STANDBY角色数据库上生效 。
PRIM_DB =
(DESCRIPTION =
(ADDRESS_LIST =
(FAILOVER = ON)
(LOAD_BALANCE = OFF)
(ADDRESS = (PROTOCOL = TCP)(HOST = primary)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = standby)(PORT = 1521)) )
(CONNECT_DATA =
(SERVICE_NAME = prim_db)
)
)
STBY_DB =
(DESCRIPTION =
(ADDRESS_LIST =
(FAILOVER = ON)
(LOAD_BALANCE = OFF)
(ADDRESS = (PROTOCOL = TCP)(HOST = primary)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = standby.)(PORT = 1521)))
(CONNECT_DATA =
(SERVICE_NAME = stby_db)
)
)
安装 STANDBY STATSPACK。
参考MOS文档 Installing and Using Standby Statspack in 11g (Doc ID 454848.1)。
通过在PRIMARY上安装 STANDBY STATSPACK,对STANDBY 进行数据性能快照收集和分析。
Installing and Using Standby Statspack in 11g (Doc ID 454848.1) .
使用 ASH in memory.
适用场景:分析备库性能问题。
To generate an ASH report on a physical standby instance, the standby database must be opened read-only.
The ASH data on disk represents activity on the primary database and the ASH data in memory represents activity on the standby database. You must specify whether to generate the report using data sampled from the primary or standby database.
SQL> @?/rdbms/admin/ashrpti.sql.
ashrpt.sql (适用于单实例) ashrpti.sql (RAC) 提供 HTML 格式 ASH report enables you to specify a database and instance for which the ASH report will be generated.
适用场景:1)ADG同步进度监控。
2)网络传输能力评估。
SQL> SELECT * FROM V$STANDBY_EVENT_HISTOGRAM
2 WHERE NAME = 'apply lag' AND COUNT > 0 order by LAST_TIME_UPDATED;
NAME TIME UNIT COUNT LAST_TIME_UPDATED
----------------- ------------- ----- --------------------
apply lag 42 minutes 60 04/09/2015 01:28:28
apply lag 43 minutes 60 04/09/2015 01:29:28
apply lag 44 minutes 60 04/09/2015 01:30:28
适用场景:对standby查询可用性较高的应用,避免apply实例crash导致rac所有实例close。
MOS 文档 Behavior of Active Dataguard(ADG) When Apply Node Aborts/Crash (Doc ID 1613719.1)。
默认场景下,当APPLY实例crash后,剩余的实例都会自动关闭到mount状态。
12c上对此进行增强并backport到11.2.0.4版本上,当apply实例crash后,其他实例将进行ADG instance recovery并保持数据库OPEN状态,如果使用broker,MRP将会自动在其他实例启动继续同步。
the new feature is enabled by default in 12.1. We backported it to 11.2.0.4, you can enable it on 11.2.0.4 by setting "_adg_instance_recovery=TRUE".
* 目前在11.2.0.4上该功能有2个已知bug 18331944 和 19516448,建议启用功能前应用fix。
适用场景:ORA-4021 错误,减少ADG hang 或者宕机。
故障 Bug 16717701 影响及修复版本:
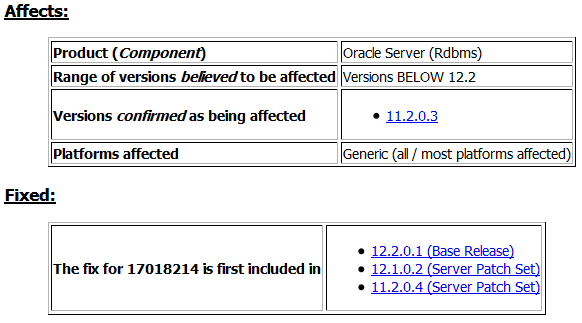
适用场景:ORA-4021 错误, ORA-600 [krdrsb_end_qscn_2],减少ADG hang 或者宕机。
在版本低于 11.2.0.4(比如11.2.0.3), 需要 打补丁(one-off patch 17018214),并设置 EVENT="16717701 trace name context forever, level 104887600"。
如果版本是 11.2.0.4 或者 12C,该补丁(one-off patch 17018214)已经存在,但是默认并没有打开。
需要设置隐含参数“_adg_parselock_timeout=<value in centiseconds>. 来打开该补丁,无需设置 event 16717701。
目前该参数推荐设置为3000,相当于30秒。是因为后台研发认为 让 LGWR 在在等待取得 X parselock 的时候,最多等30秒是比较合理的设置。
如果该值为0,则说明 LGWR 取得 X parselock 没有 timeout.
适用场景:ORA-4020 错误,减少ADG hang 或者宕机。
故障现象:
由KGL进程检测到死锁并报告ORA-4020错误。
观察生成的LGWR Trace 文件。
ORA-04020: deadlock detected while trying to lock object SYS.****
Alert日志显示实例被进程LGWR关闭。
ORA-04020: deadlock detected while trying to lock object SYS.****
LGWR (ospid: 3080778): terminating the instance due to error 4020
原因和触发条件
根据设计,ADG库上的LGWR进程会持有exclusive parse lock (X mode lock)。
在ADG上的其他session对SQL进行编译时同样需要以X模式持有对应的library cache lock。
如果LGWR和其他session在同一个对象上request lock并造成死锁,LGWR进程会出现ORA-04020错误异常终止并导致实例crash。
故障 Bug 18515268 影响及修复版本:

适用场景:ORA-600 [kdsgrp1] ORA-1555 / ORA-600 [ktbdchk1: bad dscn].
故障现象:
该BUG触发后会导致index block上的ITL SCN版本不一致,block scn产生逻辑错误,session执行失败异常终止。并可能伴随如下报错:
ORA-1555
ORA-600 [ktbdchk1: bad dscn]
ORA-600 [2663]
ORA-600 [ktbdchk1: bad dscn]
注意:corruption只发生在Index Block上,但是并不会造成任何数据丢失。
原因和触发条件
关于这个itl SCN的不一致,是通过以下几个步骤发生的,问题出现在索引块的itl事物槽的SCN比索引块的SCN更高,因此逻辑上存在问题:
第一步:主库和备库上都正常,没有scn corruption存在。
Primary A (no corruptions) -----> Physical Standby B (no corruptions)
第二步:主库进行了switchover变成新的备库,并应用了新的主库传过来的redo日志,此时可能触发bug产生索引块scn不一致。
Physical Standby A (corrupted indexes) <---- Primary B (no corruptions)
第三步:新的主库再次进行switchover或failover,此时已存在的scn 无效的索引块,主库打开会发现报错。
Primary A (corrupted indexes) -----> Standby B (no corruptions)
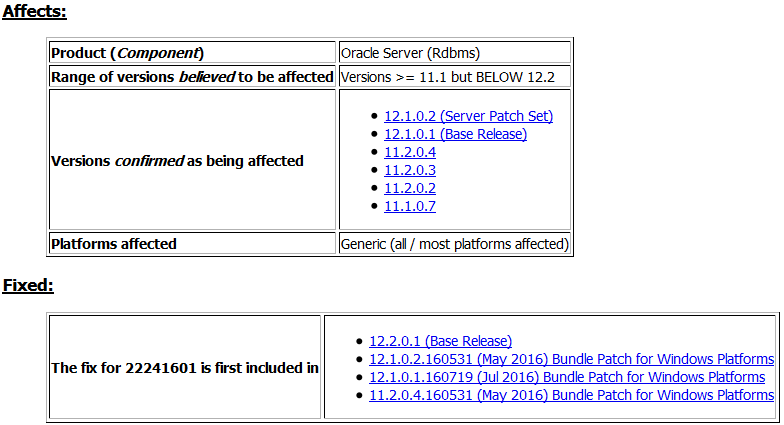
ALERT Bug 22241601 ORA-600 [kdsgrp1] / ORA-1555 / ORA-600 [ktbdchk1: bad dscn] / ORA-600 [2663] due to Invalid Commit SCN in INDEX (Doc ID 1608167.1) .
故障 Bug 22241601 影响及修复版本:
适用场景:有助于提高 media recovery performance.
Set DB_CACHE_SIZE to a value greater than that for the primary database.
Set DB_KEEP_CACHE_SIZE and DB_RECYCLE_CACHE_SIZE to 0.
Because media recovery does not require DB_KEEP_CACHE_SIZE and DB_RECYCLE_CACHE_SIZE or require a large SHARED_POOL_SIZE, the memory can be reallocated to the DB_CACHE_SIZE.
适用场景:设置为异步同步,并且 Redo 生成量较大。
Doing so will allow the asynchronous redo transport to read redo from the log buffer and avoid disk I/Os to online redo logs.
适用场景:检查主备库的坏块。
设置 DB_BLOCK_CHECKSUM 和 DB_BLOCK_CHECKING.
如果设置后备库无法追平 redo 生成速度,可以考虑临时设置 DB_BLOCK_CHECKING=FALSE. 设置后apply rate 可以提升。
In addition set the DB_LOST_WRITE_PROTECT parameter to FULL on the standby database to enable Oracle to detect writes that are lost in the I/O subsystem. The impact on redo apply is less than 5 percent for OLTP applications.
考虑在备库设置 db_ultra_safe.
适用场景:降低对PRIMARY数据库的压力。
MOS 文档 Benefits and Usage of RMAN with Standby Databases (Doc ID 602299.1).
在STANDBY上进行的RMAN BACKUP文件和PRIMARY上执行的BACKUP文件是完全相同的。
一致性的备份产生过程有4步:
1)备份当前存在的归档日志。
2)备份数据文件。
3)切换日志。
4)备份在备份过程中产生的新归档日志 *。
在11.2.0.4之前,步骤4在STANDBY上无法实现,需要加入手工脚本在主库执行切换,11.2.0.4上对RMAN进行了增强,实现可以在STANDBY侧简单完成一致性备份。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721