

(点击底部“阅读原文”获取朱阅岸演讲完整PPT)
讲师介绍
朱阅岸,中国人民大学博士,腾讯基础架构部高级工程师。研究方向主要为数据库系统理论与实现、新硬件平台下的数据库系统以及TP+AP型混合系统。
大家应该都看过《星际穿越》,里面有很多震撼人心的场景,我个人印象较为深刻的还是老教授鼓励库珀去探索太空、寻找人类宜居星球时念的那首诗:“Do not go gentle into that good night…Though wise men at their end know dark is right…”,意思就是不要温柔地走进那个良夜。对于技术人来说,数据库系统底层硬件面临着革新,我们也应该去探索新技术,以更好地适配这些底层硬件,而不是停留在原地,因此我拿这句诗作为本次分享的开始。
本次分享大纲:
1.现代处理器及新型储存的发展
2.现代处理器下的数据库技术
3.面向新型储存的数据库系统
4.总结
现代处理器及新型存储的发展
1、现代处理器
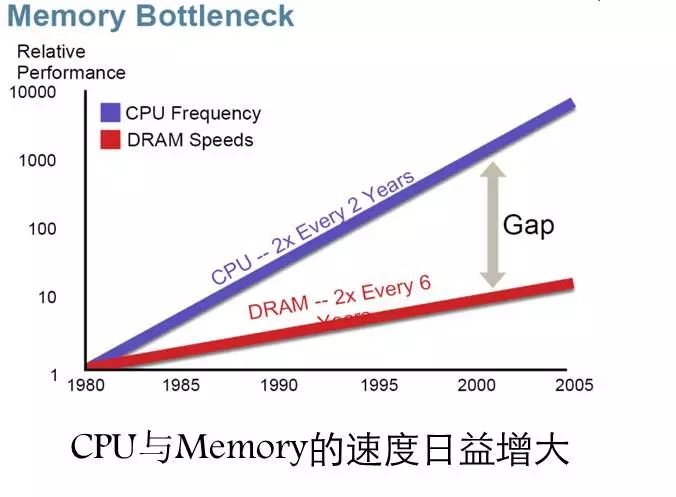
先给大家介绍一下现代处理器及新型存储的发展。大概从2005年开始,CPU的生产商就不再追求CPU的频率而转向多核技术研究,这里一个很重要的原因就是能耗和制造工艺上的问题,使得他们不能再单纯地追求提升频率。

在当前普通的服务器上,配备几十个处理核心的处理器已相当常见,众核的概念也开始流行起来。那什么是众核?众核,是在英文上有一个专门的词,叫做many-core,跟单核是对应的,主要是指集成了成百上千个处理核心的处理器。多核处理器大家可能很熟悉了,但大家有没注意到memory-wall效应这个现象呢?
以前CPU访问一个内存,大概只要一个时间周期的时间,现在需要上百个时间周期,访问内存成了一个比较昂贵的操作,特别是在如今大内存和内存计算这个环境下,memory-wall的效应更加严重,所以怎么样去克服,使得程序具有局部性,成为了最重要的一件事情,即如何克服memory wall的问题。
2、新型存储设备
大家是否听过非易失性内存?英特尔刚刚推出的3D XPoint技术,就属于这类范畴的技术,即内存掉电了以后,数据不会丢失。它兼具磁盘和内存的特性,结合了两者的优点,也就是具有磁盘的持久存储特性和内存的快速访问,主要特点是非低失、低延时、大容量,以及读写不对称。
大家可以想象一下,有了这种硬件以后,我们系统设计者需要考虑的东西就不再是所谓的I/O的问题了,而是可以专注地把注意力放在高性能计算上,通俗地讲就是关注系统的扩展性问题。
原理介绍

刚才所说的新型存储——非易失性内存主要有以下四种实现,其中最为成熟、最具市场前景的就是这个称之为相变存储的技术。
相变存储器:材料可以在结晶状态与非结晶状态转变
自旋磁矩:改变两层磁性材料磁矩方向
铁电材料:材料所形成的电荷高低,二元状态
忆阻器:是一种有记忆功能的非线性电阻
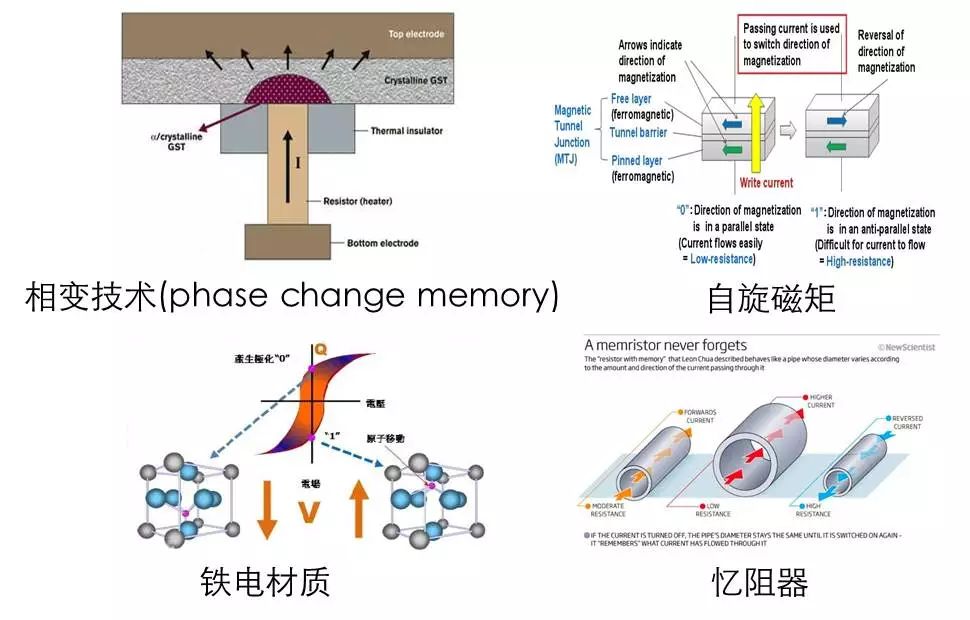
根据国外工程师的逆向工程,英特尔的3D XPoint(傲腾),采用的就是这种技术。它的技术特点是利用相变材料,具有结晶和非结晶两种状态,这两种状态对应着低电阻和高电阻,对应着1和0。相比存储器的单元结构主要有以下部件组成:双层的导热片,然后加热绝缘体,以及相变材质。通过加热器,对这个相变材质进行加热,它就会呈现结晶和非结晶两种状态。其它的技术实现,有兴趣可私下讨论,这里就不多讲了。
相关参数
主要还是PCM的技术,是目前最为重要的一种技术。我们来看一下它的参数,这里主要是一些相关文献上摘取的数据,其中我们比较关注的是读写延迟、带宽、寿命,以及密度(容量)。

从表格中可以看到,PCM和Flash相比,它的读写延迟要低两个数量级,而它的寿命要高两个数量级,并且容量的大小和Flash差不多,而跟内存相比,它的读延迟已经是很接近了,但这个写延迟和带宽上还有差距,所以目前而言,PCM代替内存是不可能的事情,而在一段时间内这两种存储是会共同存在于计算机体系结构中。
另外一个有意思的现象就是PCM的密度,它的容量要比内存大2到4倍,而且在空闲功耗,即系统空闲的时候,这个功耗是内存的1%。因为内存要不断地去刷新,维护内存单元里面的数据,所以这是一个很耀眼的特性,特别是对于数据中心而言。
DBMS的设计
我们都知道系统的底层硬件决定着上层软件的设计,现在数据库系统最主要的矛盾是飞速发展的硬件与始于上世纪70年代的数据库系统的陈旧设计思想。众所周知,磁盘I/O是那个时期系统性能的主要瓶颈,而该系统的设计者主要考虑的是自己怎样把这个系统设计得更好,以规避这个磁盘I/O的问题。在我们的数据库系统里面,同样随处可见这种设计思想。针对这种磁盘时代而提出的算法思想,在大并发下将会呈现相当严重的性能问题。
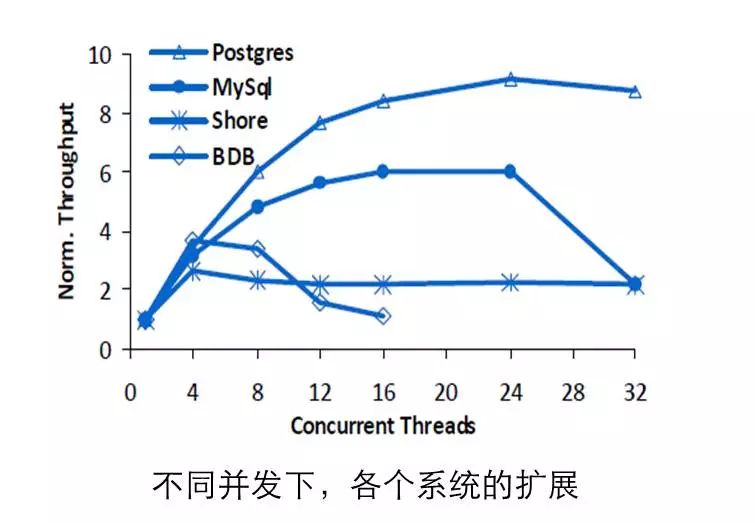
这个研究是在2010年卡内基梅隆大学的数据库研究小组,对几个开源数据库的性能测试结果。可以看到,在多核处理器下这些数据库系统的性能、扩展性都不能够令人满意。这篇论文拉开了数据库系统多核优化的序幕,特别是开源软件,例如MySQL、PG在该时期就开始重视多核扩展性的问题,他们意识到原来在多核环境下,系统会有如此表现。
时间都去哪儿了呢?
那么,数据库系统的事务执行时间都耗费到哪去了?下面是麻省理工大学的研究结论——数据库系统大部分的时间都耗费在缓存池管理、日志子系统上,只有12%左右的时间是耗费在真正有用的工作上。
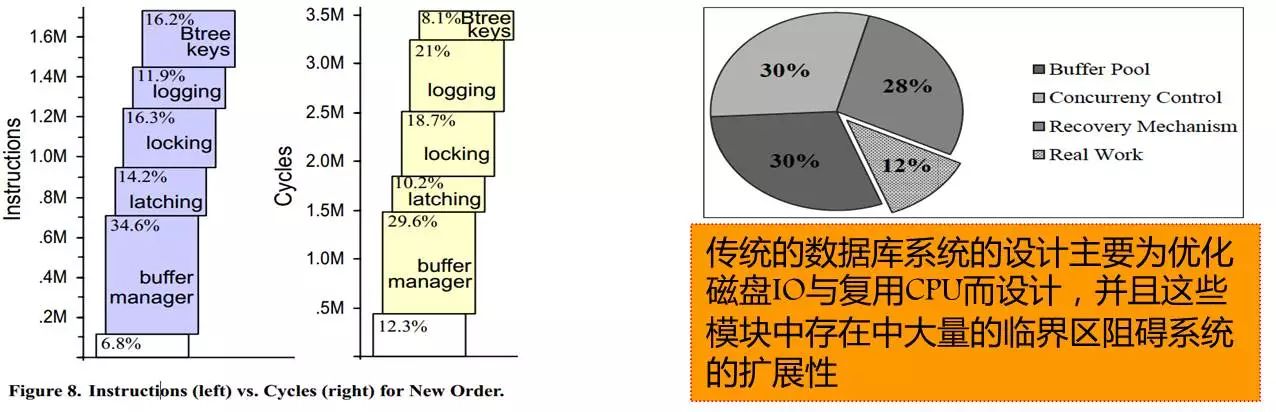
这些模块当中存在着大量的临界区,这个临界区设计得相当粗糙,下面我们可通过分析一个代码片段来进行解析。在系统的设计上,经常是一把大锁,不假思索地加上去保护临界区,几百行的代码。正如刚才看到的,在这种情况下,当系统并发度起来时,数据库系统的性能是相当差的。
现代处理器下的数据库技术
James Gray大家是否听过呢?在现在数据库系统里,跟事务相关的技术基本都是James Gray提出来的。但可惜的是,在2007年,他驾着一艘帆船出海,然后消失了。美国出动了海军陆战队都没有找到他。作为一个神奇人物,他凭借着对数据库事务的突出贡献获得图灵奖。
为了克服刚才所谓的内存墙技术,James Gray曾说过这么一句话:RAM Locality Is King,就是说数据和程序行为的局部性才是克服CPU和内存的速度不匹配的终极武器。
RAM-Locality设计原则
数据库里面主要采用以下几种技术优化性能,一种是列存储技术。列存储技术,主要用在OLAP,像MySQL、PG等OLTP型数据库都是用行存储技术。为什么要用列存储技术呢?是因为进行数据分析的时候,经常会出现宽表或有几百个字段的表,但通常只需要访问表中的某一些字段,比如要访问销售字段,对销售字段进行累加,做一个聚集操作。采用列存储,可以更好地优化高速缓存的使用率,减少cache miss,克服内存墙问题。
另外就是设计高速缓存友好的数据结构或算法。像现在的数据库采用一次一元组的查询处理方式对程序局部性很不友好。
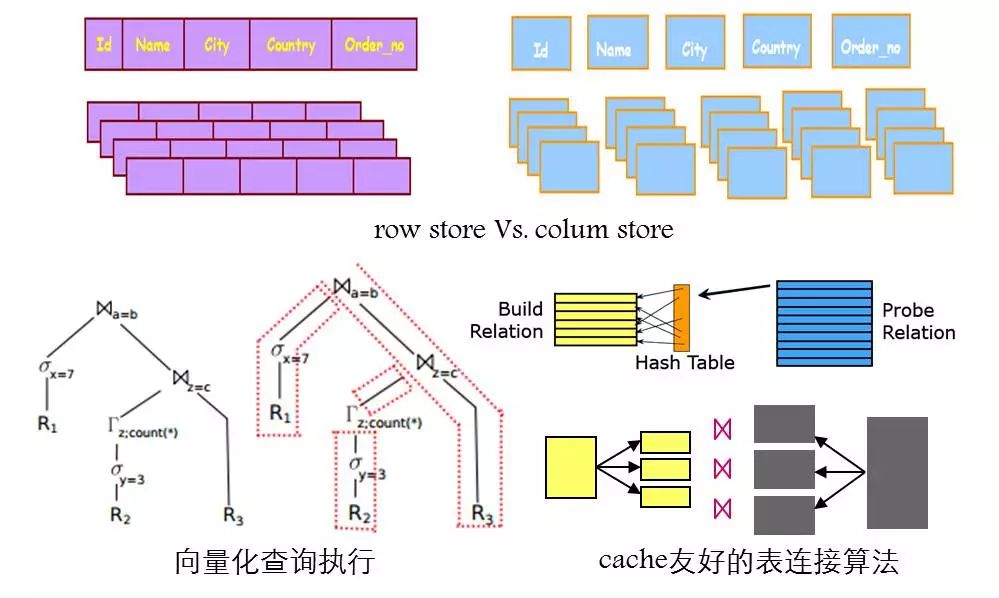
什么叫一次一元组呢?数据库系统的查询语句,都是翻译成操作树。在树的节点之间,操作符通过get_next函数驱动子节点获取一条元组,递归调用下去,叶子节点将数据返回。函数的频繁调用会产生严重的cache miss问题,所以现在新型的OLAP系统都是采用向量化查询执行引擎,上层操作符不再是一条一条数据地处理了,而是一批一批数据处理,减少函数调用的开销和上下文的切换以最大化数据和程序指令的局部性。此外,hash join也针对cache大小将hash table进行划分以增强数据与指令的数据性减少cache miss。
一个例子
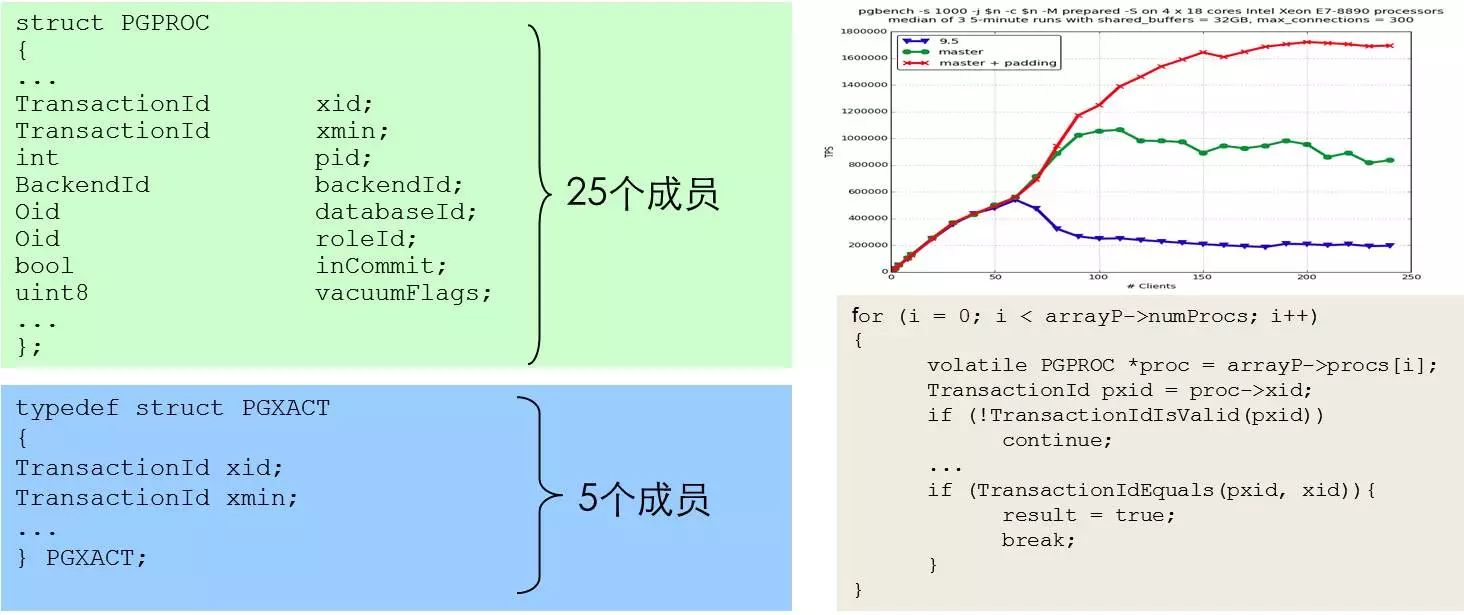
这是针对Cache友好而设计算法的例子。在PG 9.5之前,系统判断事务活跃性或获取系统快照时,要用到事务的起始时间、事务ID等。这些字段都放在PGPROC这个结构体里,这个结构体有25个成员,但做可见性判断时,只需要用到几个成员就够了。因此采用这种设计系统会把其它无关字段读入,污染其它cache line,造成严重的cache miss以及Cache浪费问题。所以后面他们就把用于可见性判断等经常访问的字段放在另一个结构体里面叫做PGXACT。打了这个补丁之后,在大并发下这个性能收益是相当客观的,性能数据如图中右上红色数据所示。
因此,针对Memory Wall这个问题,设计cache友好的数据结构与算法是一个很奏效的方法。
避免热点与简化临界区
针对多核的问题,我们还要避免热点的问题,简化临界区。就像我们经常看到的,并发一大,系统性能就掉了下来。

这是微软的内存数据库Hekaton的一个实验结果。截取了事务在提交时的一个时间戳。这个全局的原子操作都会导致这个性能的问题。但针对MySQL、PG这两种数据库,性能问题还远远轮不到像类似于这种原子操作来引发。
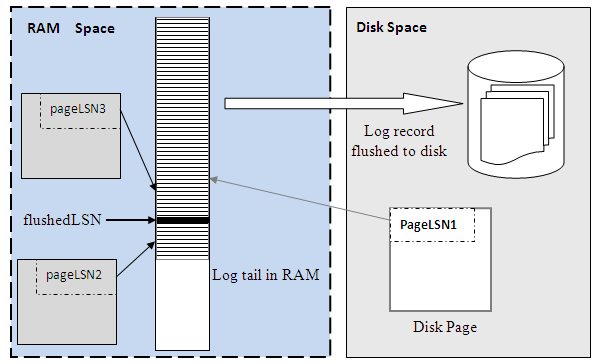
这就是我刚才所提到的问题,我们的磁盘数据库的设计原则是优化磁盘IO。事务在提交时,不需要刷脏,以避免随机IO。我们有一个专门的术语,叫做No force,也就是说事务提交时,不用去刷脏页,但系统会把日志先刷下去。它这种集中式的设计,很容易导致性能的问题。针对更新密集型的工作负载,这个模块的性能问题更加突出。

传统的先写日志的算法(Write-ahead Logging),PG也好、MySQL也好,一般分为三个步骤,首先获取一把大锁,保护shared Log Buffer的这个数据结构;然后把日志记录拷贝到相应的日志缓冲区;最后释放这把锁。这是最传统的做法。

我们现在也跟社区里面去探讨了是否可以废弃集中式设计,采用分布式日志的问题。就是不采用一个日志管理器,转而使用多个Log Buffer同时把日志序列号改成逻辑时间戳。
在PG9.4版本以前,就采用刚才那么一个粗放的形式,加一把大锁,然后临界区里面进行捣鼓,例如长度计算、拷贝日志、一些边界检查等。这个临界区的代码大概有300行左右。但后来他们发现这个模块的性能问题实在太严重了。
解决的方法是把日志文件抽象成线性长度,写入日志时把位置预留出来。位置确定以后就把锁放掉,因为系统知道往哪里去写入数据,根本就不需要把日志拷过去再放锁。并且事务之间可以并行地去拷贝日志。优化以后,性能提升了大概20%到30%左右,PG社区里面有相应的测试报告。

注:更多分布式日志可读我在社群发表过的另一篇文章《用分布式日志优化单机数据库系统将成未来标配?》
锁管理器(锁申请)
另外一种是数据库里逻辑锁的问题。数据库里面的加锁,是通过一个哈希表实现的,表里面的维护有很多锁的信息。这个锁其实就是一个标记,例如要加一个行锁,就把这个锁的Table ID、Row ID拿过来作为key,然后哈希到这个锁表里。同时标记这个锁属于哪种类型,是共享锁还是排他锁等。
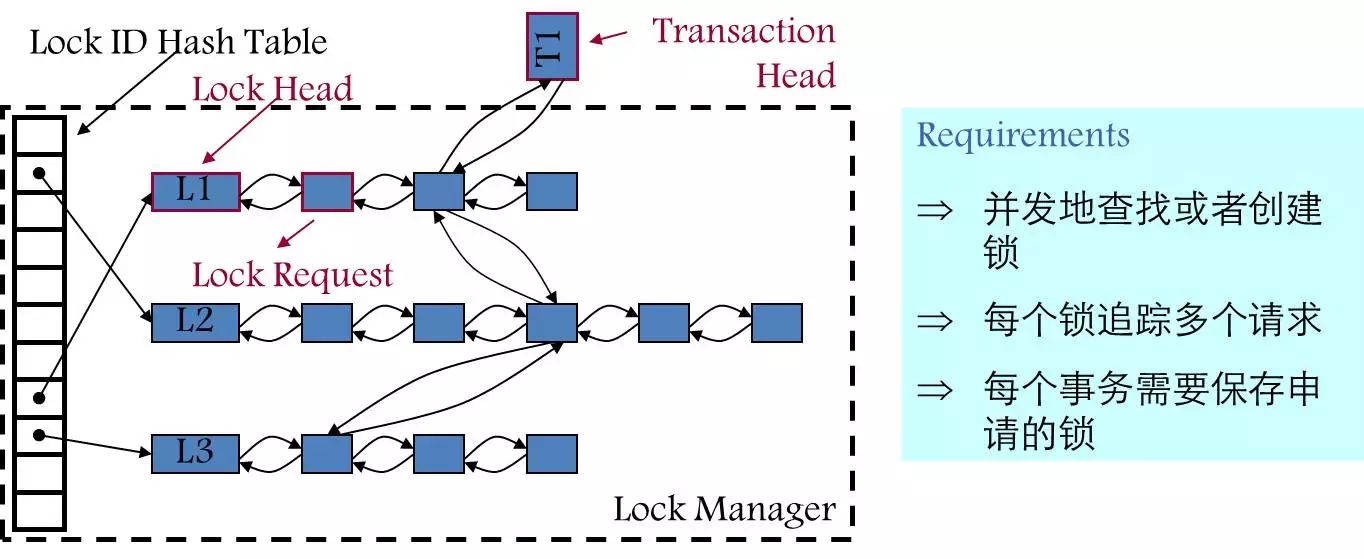
但在大并发或冲突比较严重的情况下,这个锁表是会引发问题的。因为它是一个共享的数据结构,很多事务都要跟锁表打交道,频繁地加锁以及释放锁引发热点问题。
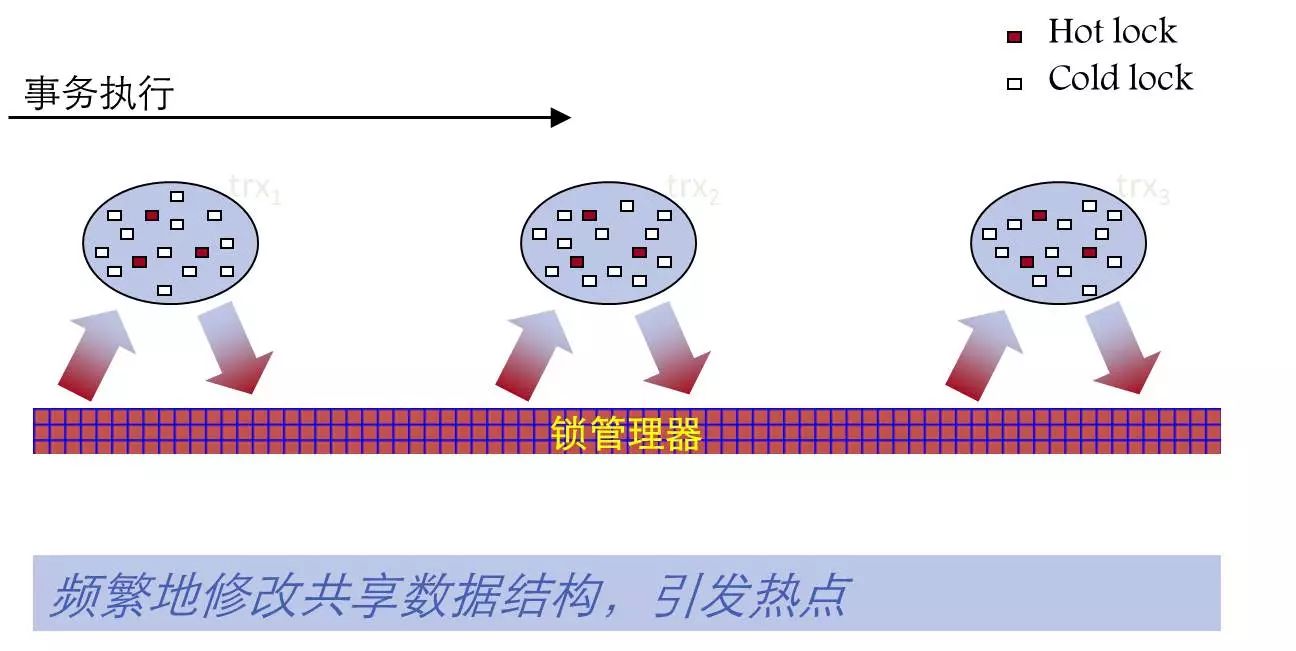
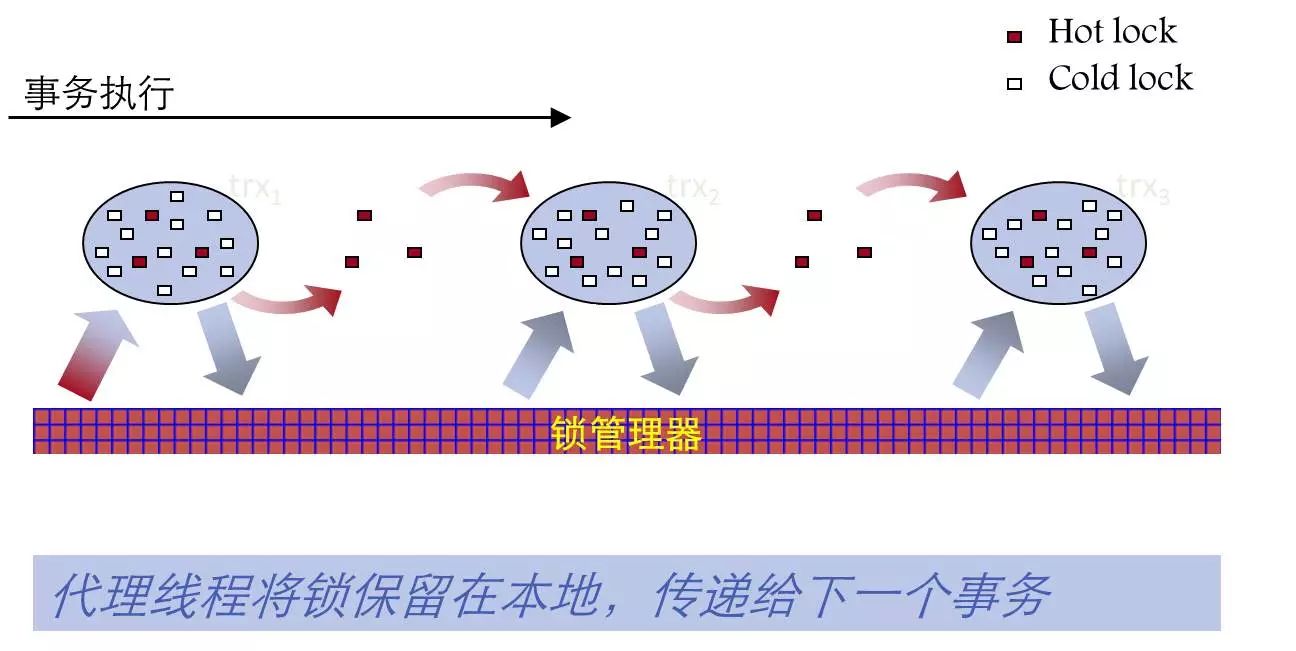
PG 9.2采用了继承锁技术,把共享表级锁缓存在本地,然后在事务之间传递,不用把共享表锁归还给锁管理器,减少跟共享的数据结构的交互,提高系统的并发性。
面向新型存储的数据库系统
接下来我们来探讨一下面向新型存储的数据库系统。底层的存储变了,数据库系统架构各方面肯定都要去改变。
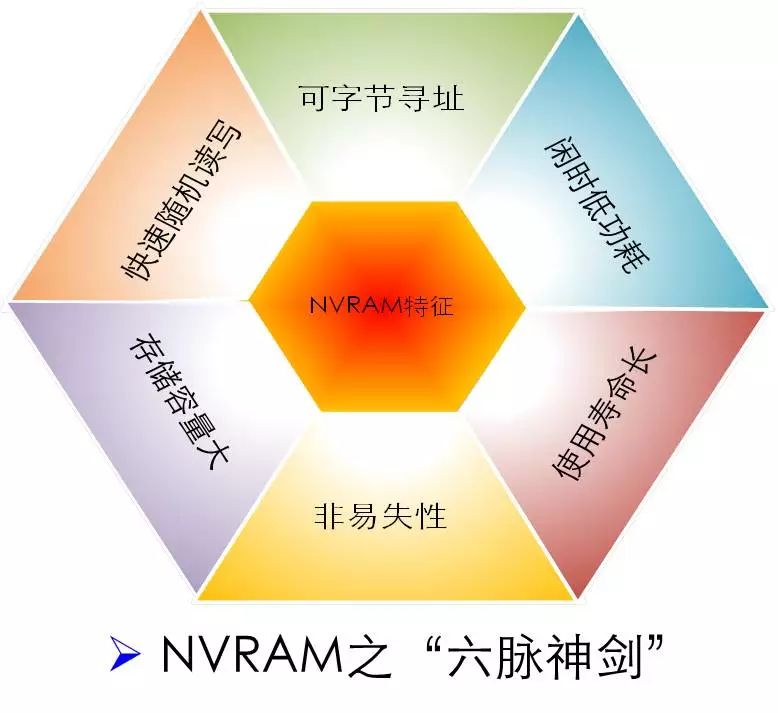
这里我做了一下总结,NVRAM具有的六个主要特性:一种是可字节寻址,它的行为模式就相当于内存,可以字节寻址,而不再像磁盘采用Block寻址了,然后是闲时低功耗、使用寿命长、非易失性、存储容量大、快速地随机读写。
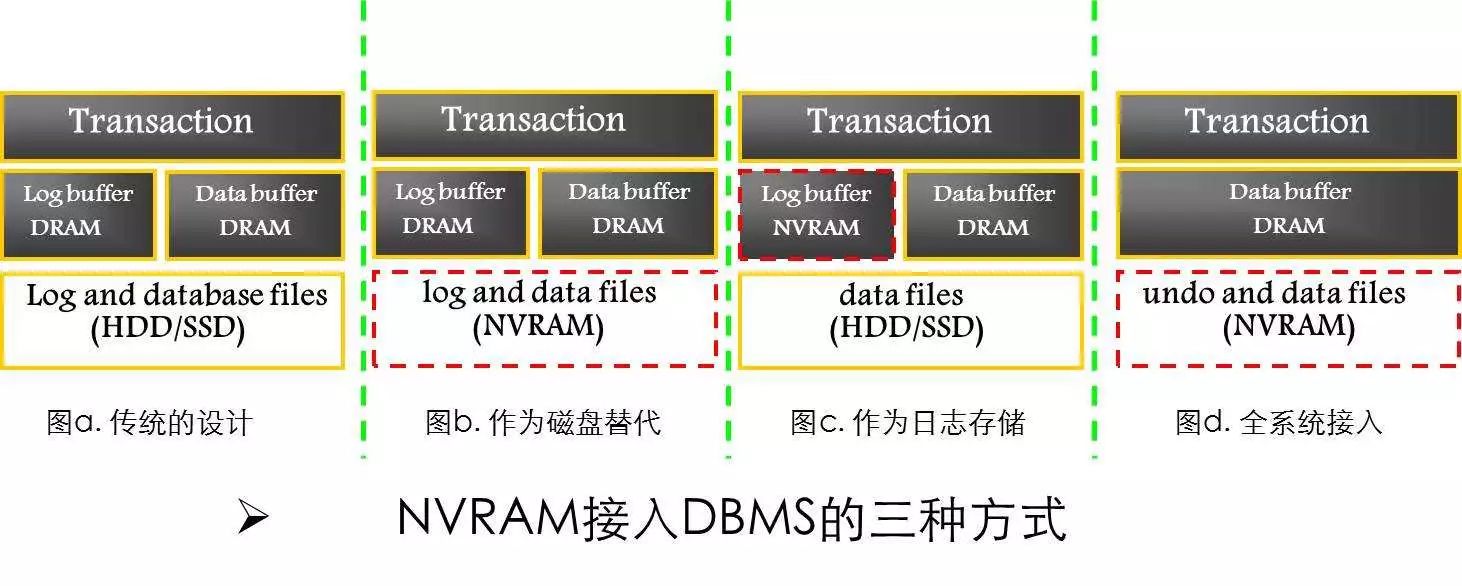
目前而言,NVRAM接入DBMS主要有三种方式,最左边的是我们传统的数据库系统架构,维护两个Buffer,一个是Log Buffer,另外一个是Data Buffer。Log Buffer是事务日志集中写入的内存区域;DATA Buffer用于缓存数据页,事务访问数据时首先在这个buffer里面寻找所需的数据。MySQL里面的Buffer Pull就是指这个DATA Buffer。
第一种接入方式就是我们可以直接把它作为磁盘的替代直接拿过来,数据库系统软件不需要改动。这种方式当然是可以获得收益,因为底层I/O速度变快了,但没有发挥它最大的收益,软件的复杂度还是在那里,不多不少。
第二种是作为日志的存储,现在大家使用的机器内存都很大了,我们的I/O基本上发生在一个地方,就是写日志。为了不丢数据,日志是必须落盘的。把NVRAM作为日志存储的设备,可以用比较小的代价获得比较好的收益,第二种接入方式就是把它作为日志存储,而设计相应的算法与优化临界区。
第三种方式,是全系统接入的,系统经过全面的改造,把数据放在NVRAM。这个可以跟第二种接入方式对比一下,系统不再维护Log Buffer这个数据结构,完全被废弃掉。
write-behind logging
CMU在VLDB 2017刚刚发表的研究称之为,write-behind logging,就是NVRAM全系统接入的一种方式。他们的idea是,write-ahead Logging是磁盘时代的算法,现在我不用先写日志了。先写日志的问题就是数据库系统宕掉以后,可能需要很长时间地去恢复。它为了避免随机IO不将数据刷盘,转而顺序写出日志。系统恢复时要先拿到一个检查点,然后从检查点开始去扫描日志,把日志记录拿出来,一条条地重放。数据量大的时候,这是相当耗时的一个工作。
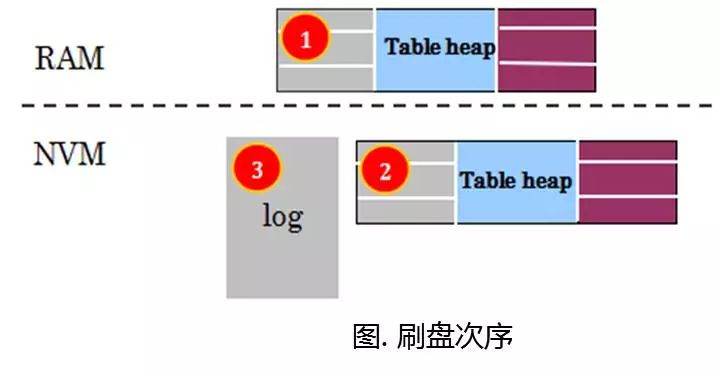

他们针对NVRAM提出一个新算法称之为write-behind Logging,就是事务提交的时候,直接把脏页写入NVRAM(因为NVRAM的随机IO也是相当快的)。脏页刷盘以后,再去写日志。
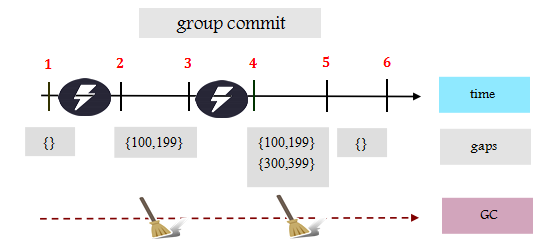
他们所设计的日志记录是这样子,不用再去构造什么After-image,直接就写上事务提交的时间区间(Cp,Cd)就行了。小于CP这个时间点的事务都已经提交了,而落在这个时间区间(Cp,Cd)里面的事务,就是还没有提交的。在事务恢复的时候,系统知道这个时间区间的事务没有提交,对其它事务不可见。系统没有必要去进行Redo操作了,因为数据都已经持久化。系统崩溃恢复时,需要一趟扫描日志,建立崩溃时候的时间区间(检点可以减少需要扫描的日志量)。建立这个时间窗口相当于undo操作。
TPC-C benchmark
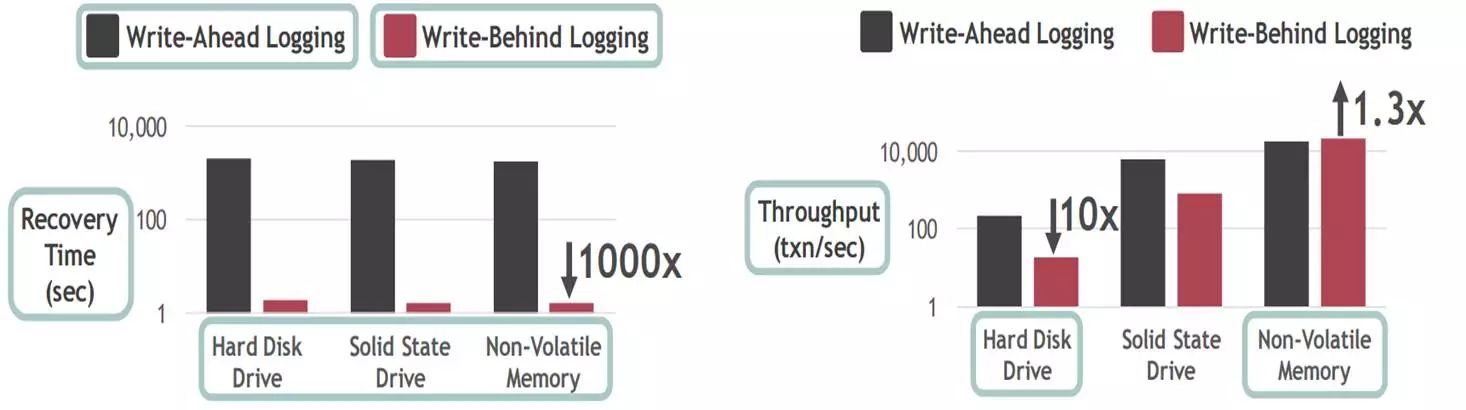
他们对采用不用算法的系统的恢复时间做了一个比较,可以看到write-behind Logging的恢复时间,大概可以达到即时恢复的效果。系统起来,马上就可以对外提供服务,但这个协议是专门针对非易失性内存而设计的,在这个磁盘SSD上,性能比较差。在这个NVM上,WBL的性能有30%左右的提升。
总结
应用需求、行业数据以及计算机硬件是拉动这个数据库系统发展的三驾马车;
在这个多核与内存计算的时代下,系统设计人员更应该将精力放在系统的扩展性上,更应该注重数据访问的局部性,克服所谓的内存墙问题;
此外,NVM的出现可能会颠覆系统架构。它的出现使得系统设计人员可以将注意力完全地从I/O上移除,专注系统扩展性设计。
狄更斯说:“这是最坏的时代,同时也是最好的时代”,这个时代给了我们挑战,同时也为数据库系统从业人员带来了机遇!
【问题1】:请教老师,我们是做金融行业的,想问一下目前有哪些场景这一块会用得比较多?刚刚听了分享,感觉这一块硬件上的性能还是相对比较好的。
答:现在这个应用的场景,简单来说可以提升IO性能,例如用来存储日志,可以快速提升系统性能。还有就是在大数据分析的场景,用来提升系统的IO能力。
【问题2】:现在有哪些厂家有提供刚刚讲的这一块?具体有哪些厂商?
答:腾讯现在有在做这一块的优化,英特尔年初推出了相应的硬件,这个硬件我们也拿到了,也在做相关的优化。跟着社区,我们也在做一些交流来提升系统的扩展性的问题。
追问:腾讯在数据库这边有支持和服务?
答:现在我们还没有放到云上去,目前在内部做一些相应的开发。很快就会在云上推出相关产品。
追问:刚才讲了很多是PG的,腾讯应该也做了一些优化,那这方面会不会有一些开源?
答:有,这都是开源的。
追问:哪里可以拿到?
答:PG或者MySQL社区里面,这些优化都是会提交到社区里面的。
【问题3】:刚看到老师PPT里有对TPCC的测试,因为现在TPCC基本上快被淘汰了,有没有去做过TPCE和TPCDS相关的测试呢?
答:这个你可能有点误会,因为这两个场景是不同的,我们数据库里面有很多benchmark,比如TPCC、TPCH、TPCDS,他们是针对不同的场景,有些是针对OLAP,有些是针对OLTP。像大家比较熟悉的sysbench,其实是针对OLTP去做的,刚才你说的那个就是OLAP的应用场景。
追问:H和DS是对OLAP性能测试吗?C是对TP的。
答:对,他们的应用场景不同。TPCC是衡量一个事务型数据库,到底能达到一个什么样性能的标准,这个比较具有说服力。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721