
作者介绍
张冬洪,Redis中国用户组发起人。多年Linux和数据库运维经验,专注于MySQL和NoSQL架构设计与运维以及自动化平台的开发;目前在微博主要负责Feed系统相关业务的核心数据库运维和业务保障工作。
前阵子有幸现场聆听了云栖大会Redis专场的分享,可以说是不虚此行:会上见到了Redis之父Salvatore Sanfilippo,Redis labs CTO Yiftach Shoolman,Redisson 联合创始人 Jack Gu,Codis 作者王乃峥以及阿里云Redis团队的众多技术大牛。演讲的内容干货也很多,这里稍作总结跟大家分享。
一、阿里云ApsaraCache
先介绍一下阿里云开源的飞天缓存ApsaraCache项目(https://github.com/alibaba/ApsaraCache),这是在社区2.8版基础上开始维护的分支,并backport了部分3.0分支的功能。
那与社区版Redis相比有哪些特点呢?阿里云技术专家白宸在演讲中做了很详细的介绍,先从架构上有一个整体的认识:
架构图:
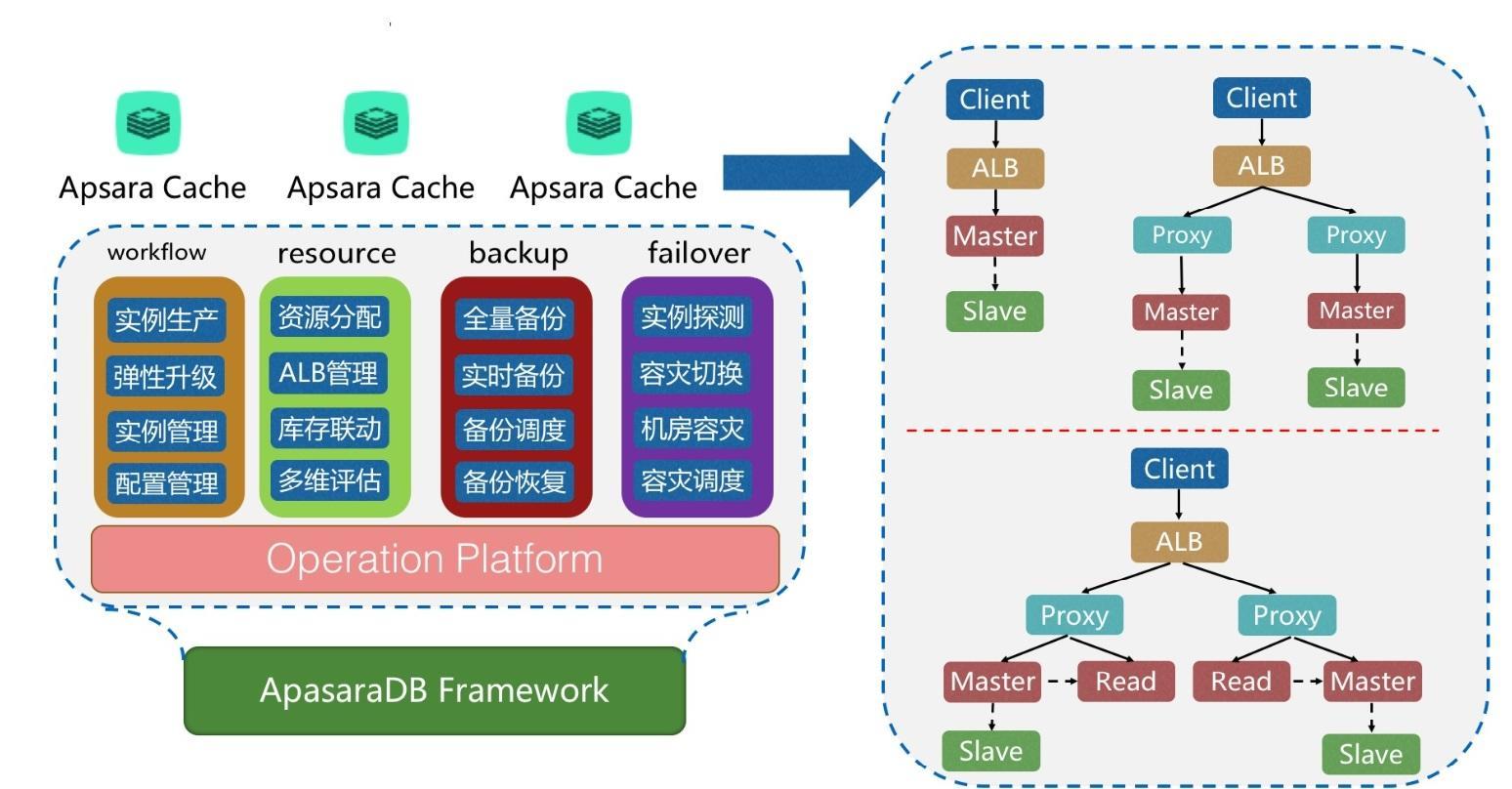
特点:

与Redis相比,ApsaraCache的显著特点是与场景有关,与数据规模无关。其技术特点和优势,主要表现在:
独特的热升级机制,增加了热升级的功能,能够在3ms内完成一个实例的热更新。(作者注:这个功能可以避免由于升级造成的业务影响)
实例的可用性检测等。
除了上面的,在Redis Cluster上面,阿里云团队也做了很多的工作,比如:
1.集群支持select、pub/sub、blpop的能力;
2.对热key的感知和处理;
3.读写分离;
4.多数据中心的灾备以及稳定可靠的基于aof log的复制等。
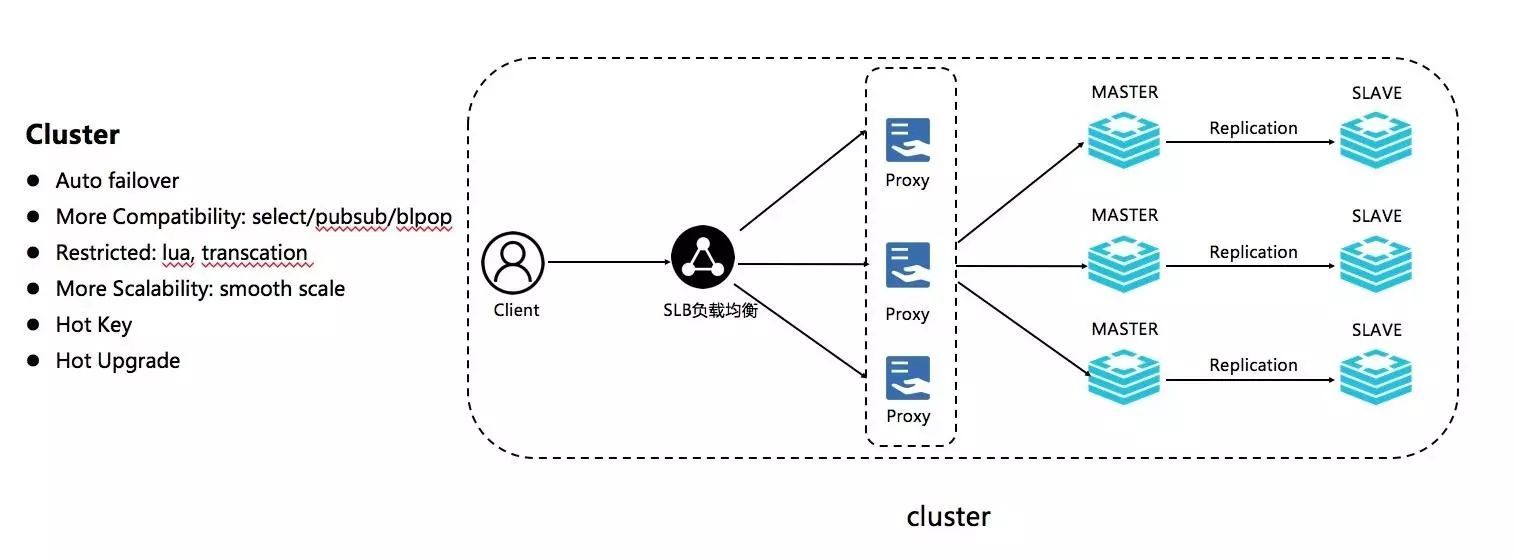
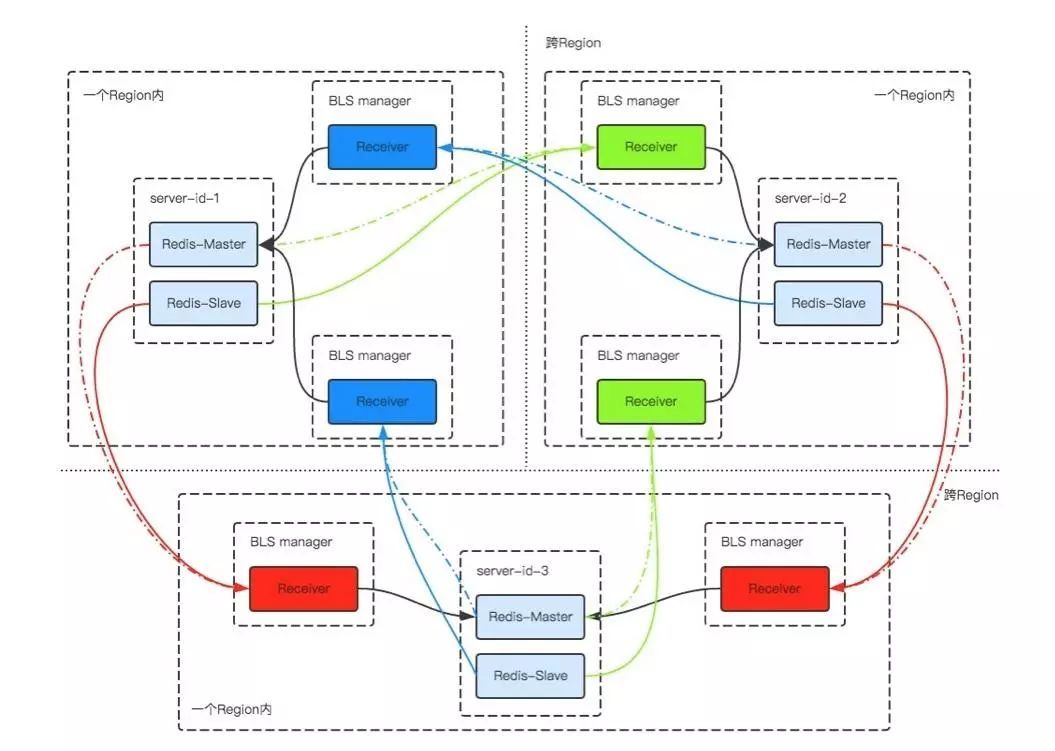
二、Redis Enterprise
来自Redis labs的联合创始人&CTO YiftachShoolman先生在会上提到的一点非常有意思,根据similarweb.com的统计,在Redis使用者TOP5中,中国排第一,远超第二名美国,可见国内Redis用户群体之多。
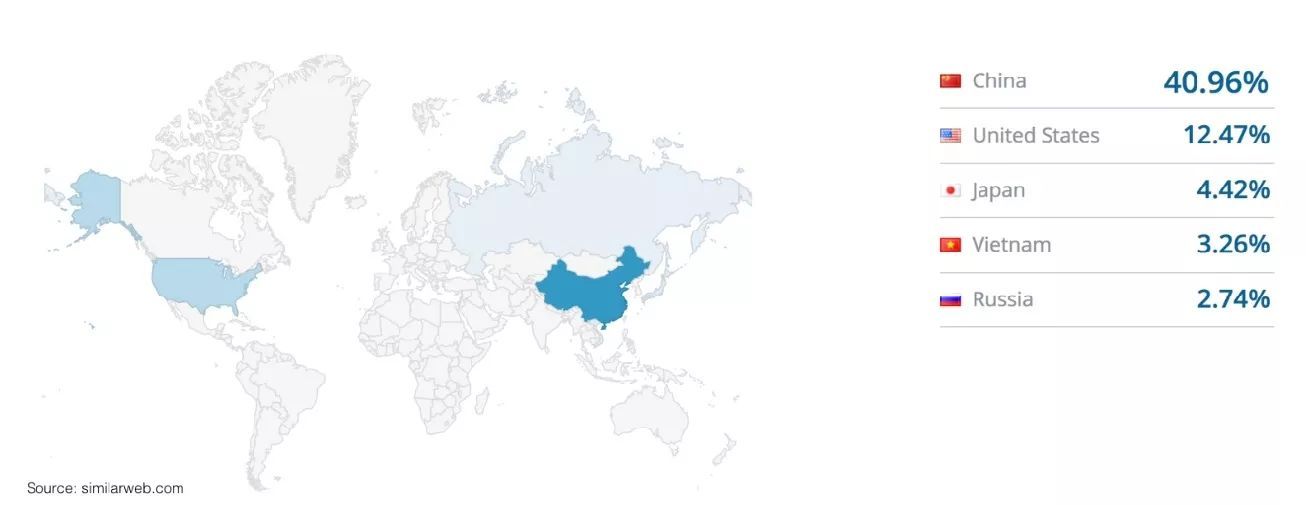
另外,他还给大家普及了一下Redis的基础,比如Redis的数据结构。
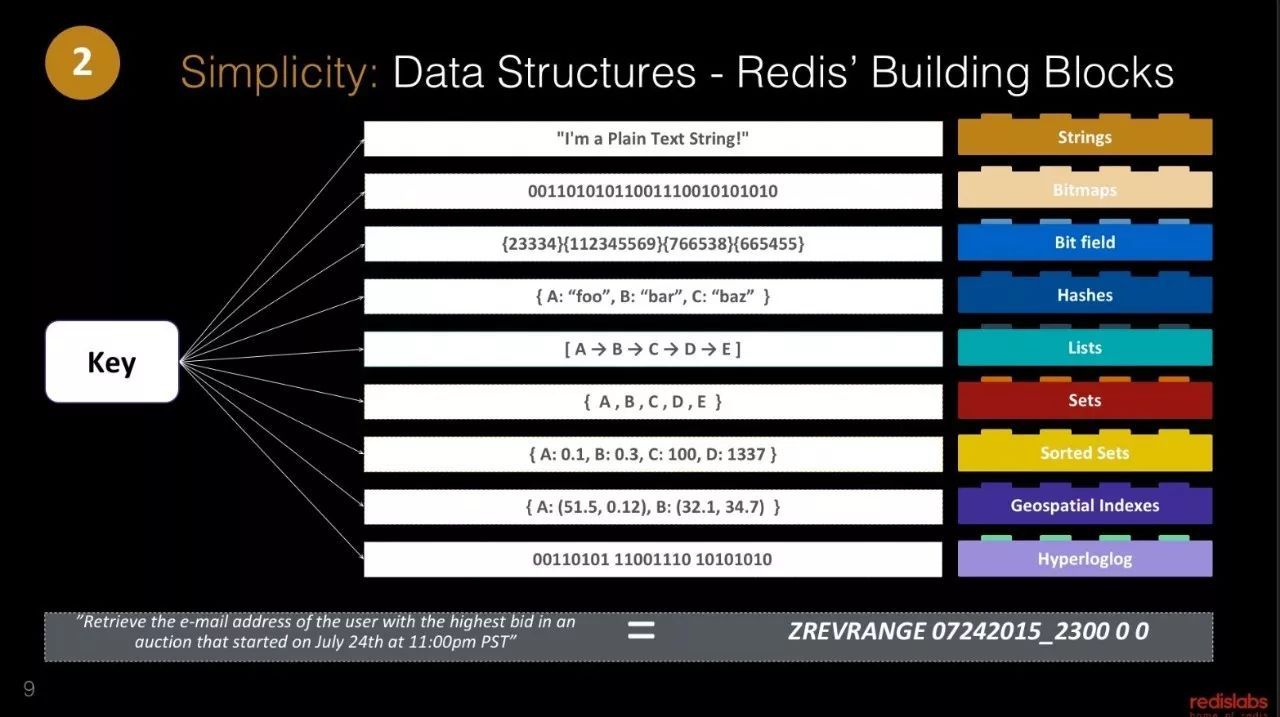
Redis modules 这个功能,相信大家不陌生吧?就是Redis labs这个公司所提出的,并且在此基础上开发了很多的扩展功能,其中本文作者就翻译过其中几篇介绍的文章,比如有:ReJSON、Redis-ML、RediSearch等。
链接:
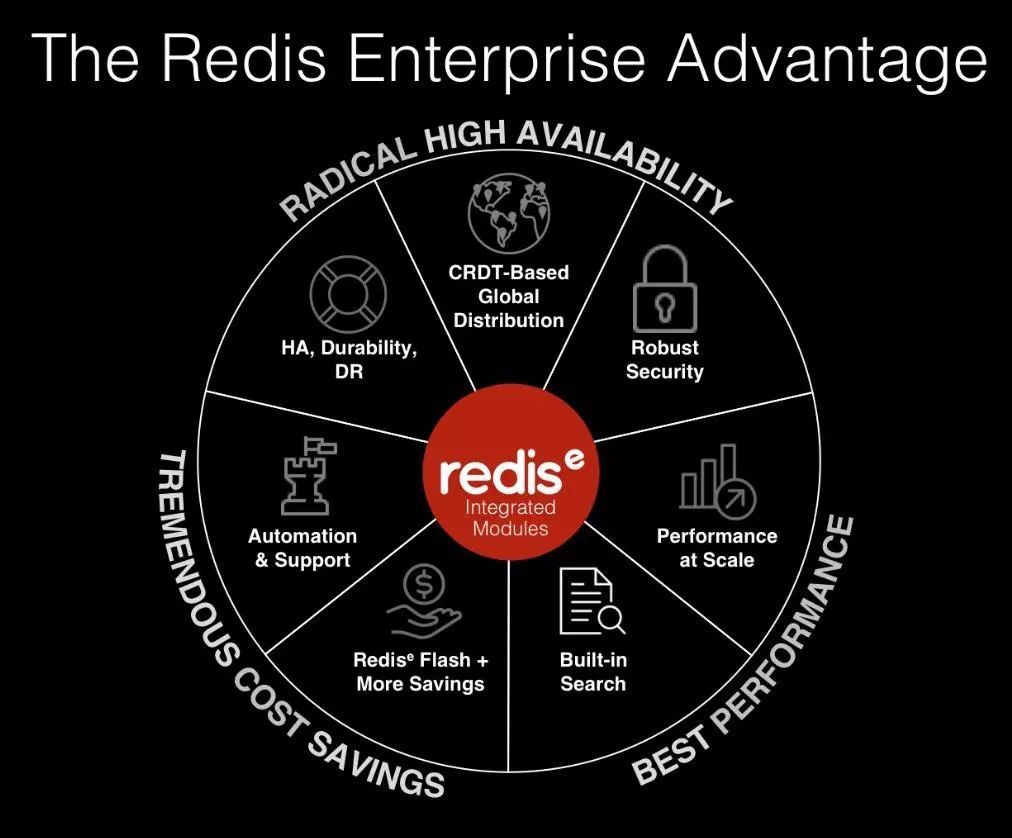
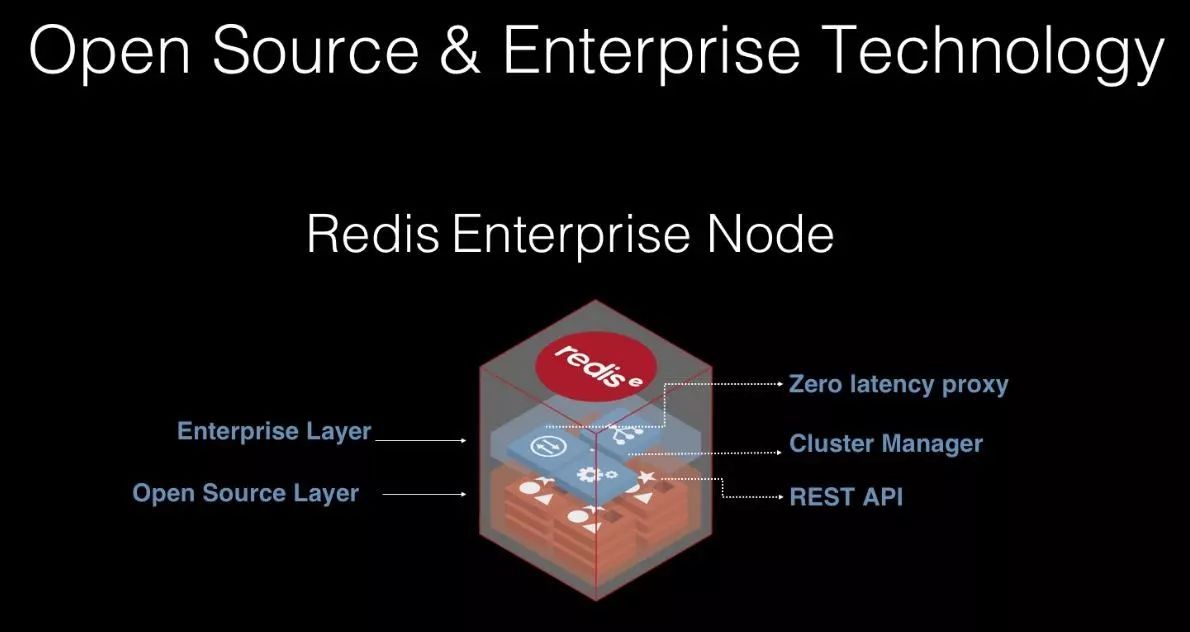
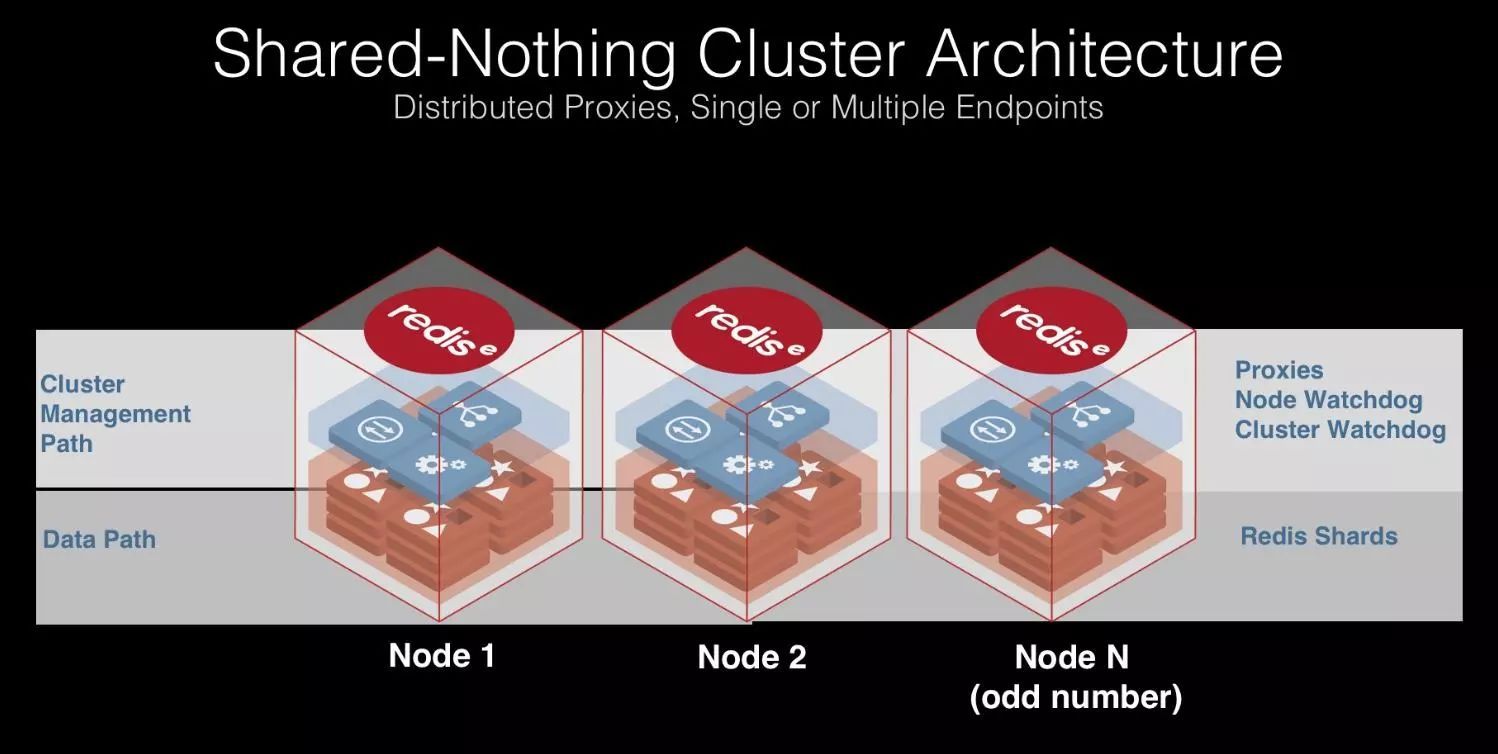
还讲了很多关于Redis labs产品相关的内容,最后讲到了Redis 企业版的优势,听上去他们真的做了很多的事情,有很多值得学习地方。如下:
三、Codis集群演化和Redis异步迁移
1、Codis集群演化
Codis作者spinlock9首先分享了Codis出现的背景和开发中的挑战,他们也跟大多公司一样,也经历过多次的技术选型上的迭代,也曾在Redis + Twemproxy和Redis Cluster进行过尝试,踩过坑,比如twitter 在2015年就不再贡献Twemproxy代码,它最大的缺点是一个静态的Sharding 策略,随着业务的增长也几乎没有办法进行动态的扩缩容。
而当时Redis Cluster也只是推出了beta版本,对于线上的业务存在风险。故最终确定在2014年酝酿要开发Codis,15年开始Release出来,会上他介绍了开发过程需要解决的问题,比如:
兼容所有语言的客户端
能支持GB到TB级别的水平扩展能力
也能提供Redis同样的高吞吐和低延迟的优势
高可用等
挑战:

Redis Cluster和Codis的特性比较:

需要特别提醒一下的是:Codis在3.2版本的时候就允许异步迁移,能够进行平滑的扩容缩容,这是比Redis Cluster进步的地方。
架构设计:
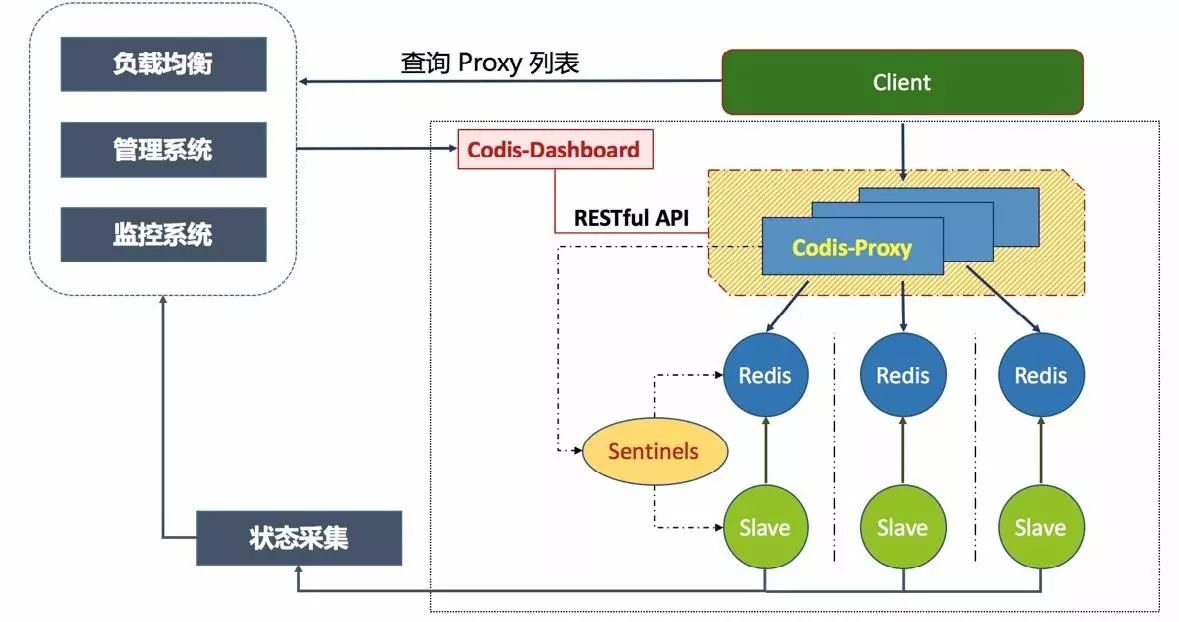
优缺点:

特性介绍
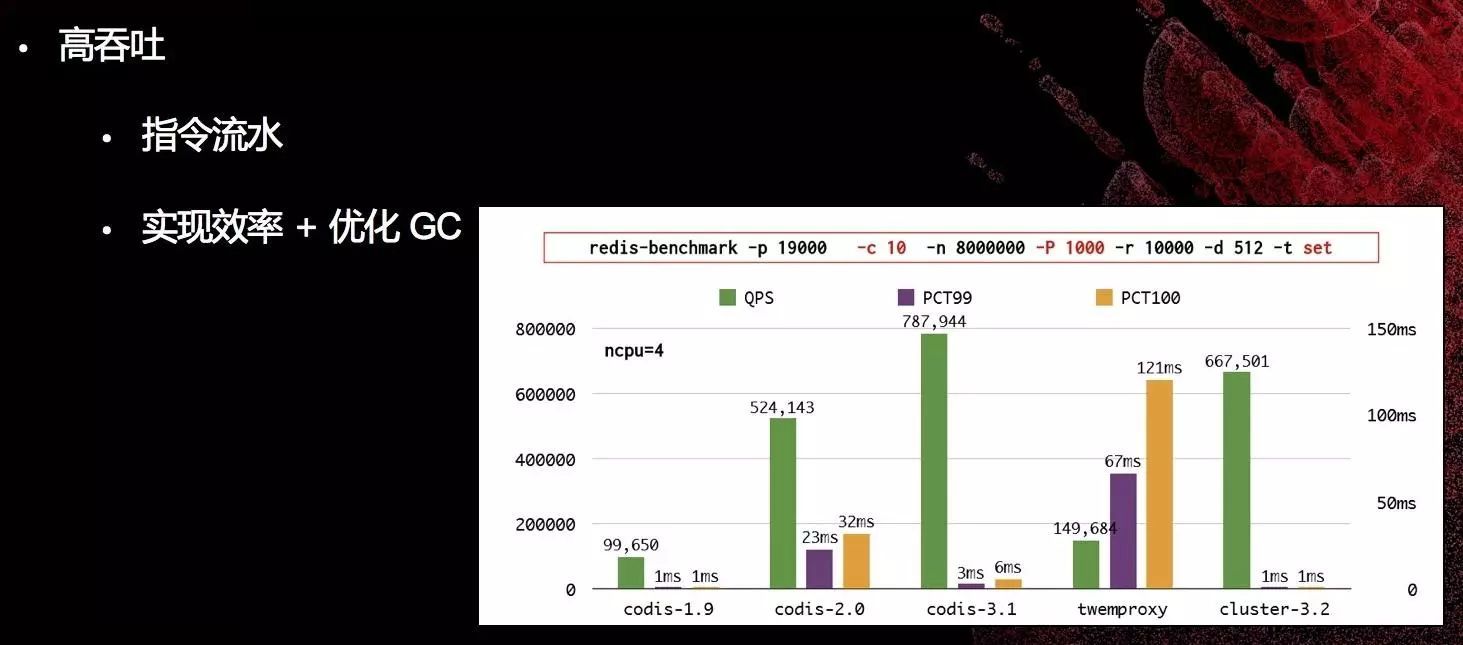
高吞吐
并发多连接
多DB支持
访问控制
读写分离 - 跨机房优化(默认是关闭的)
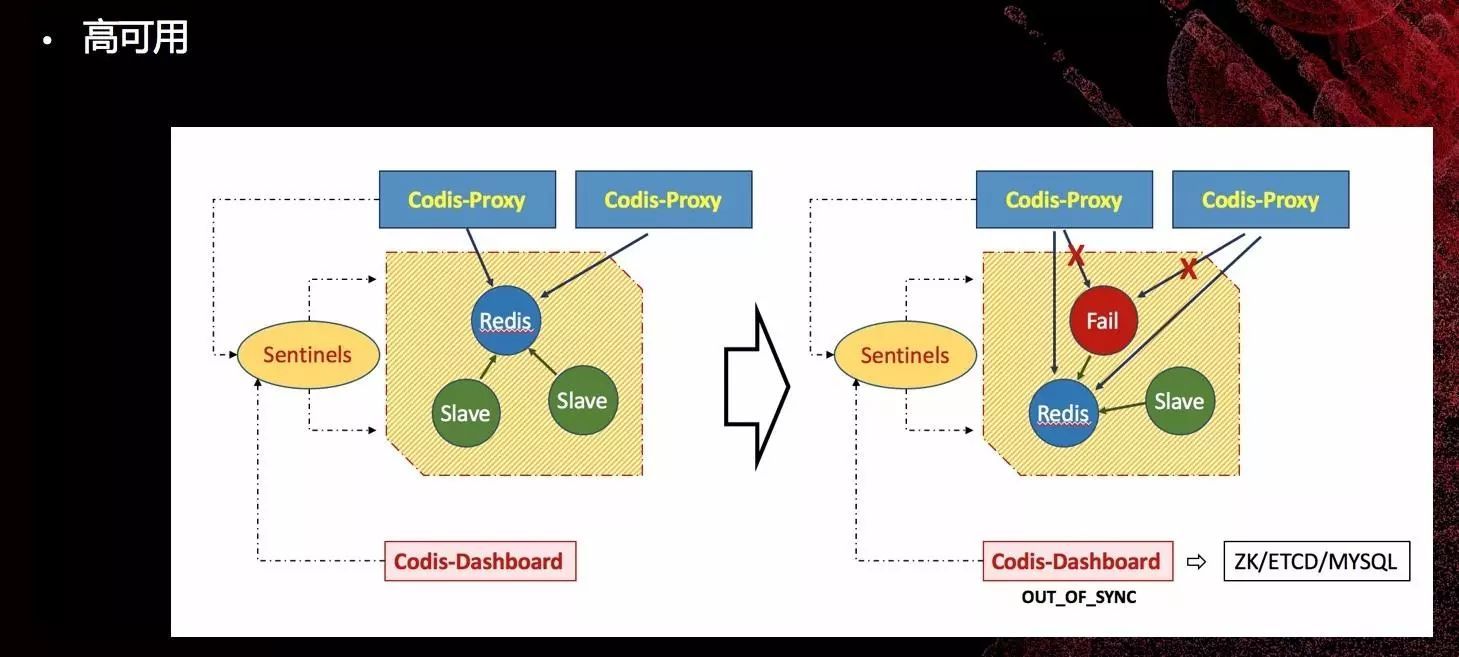
高可用
他还讲述了未来的规划,提到了有如下几点:
更大的挑战
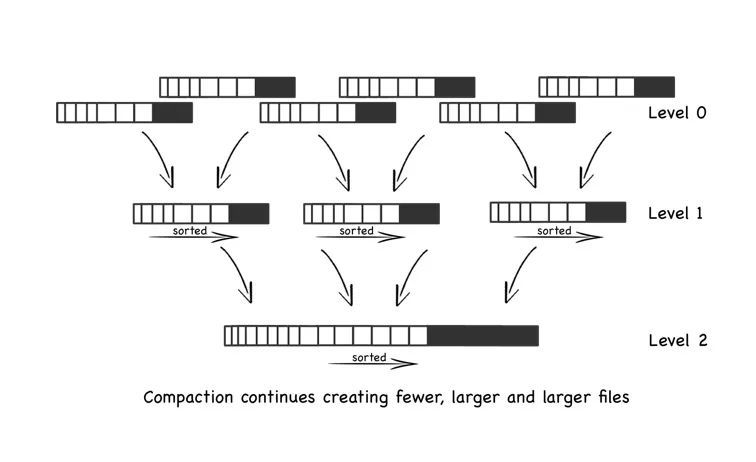
2、Redis异步迁移
听到这里时,还以为上面是重点,结果不是,重点下面才真正开始。
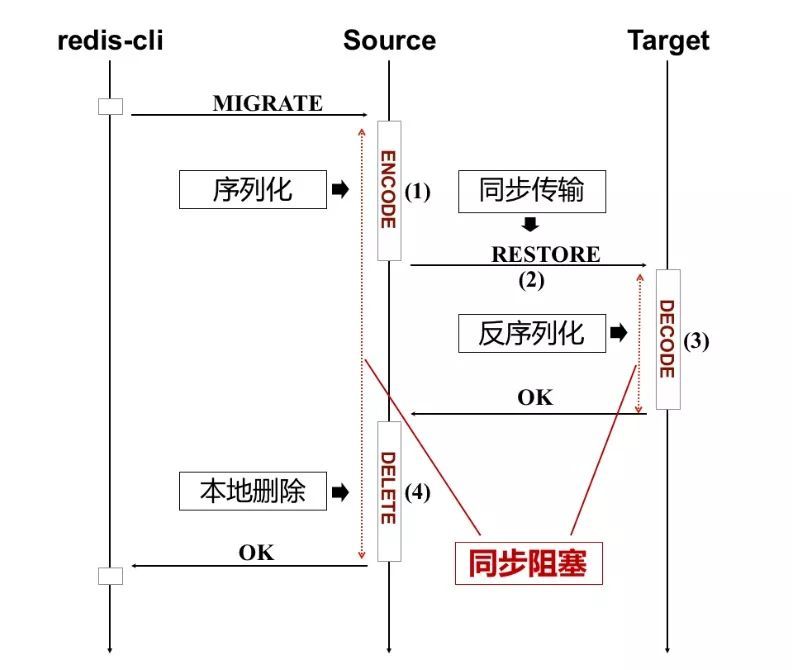
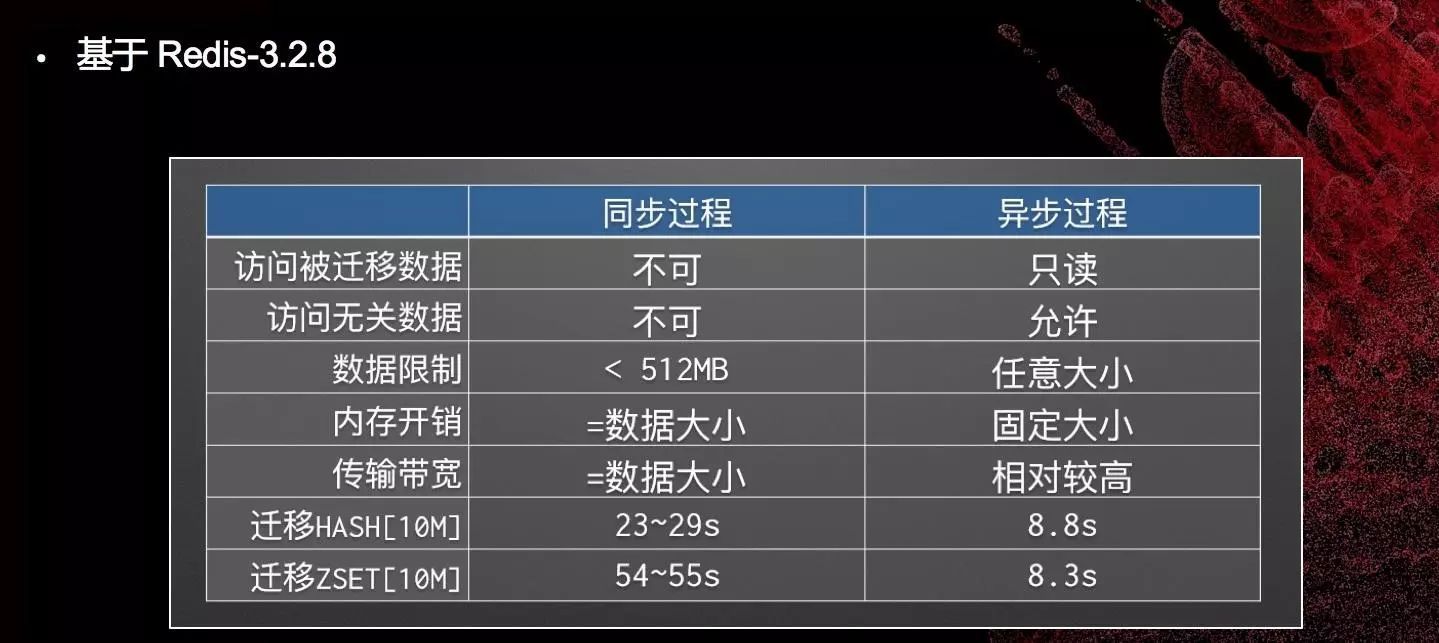
Redis同步迁移存在的问题:
降低服务质量
限制数据规模
迁移受网络质量(RTT)影响
增加错误处理难度
举个栗子:
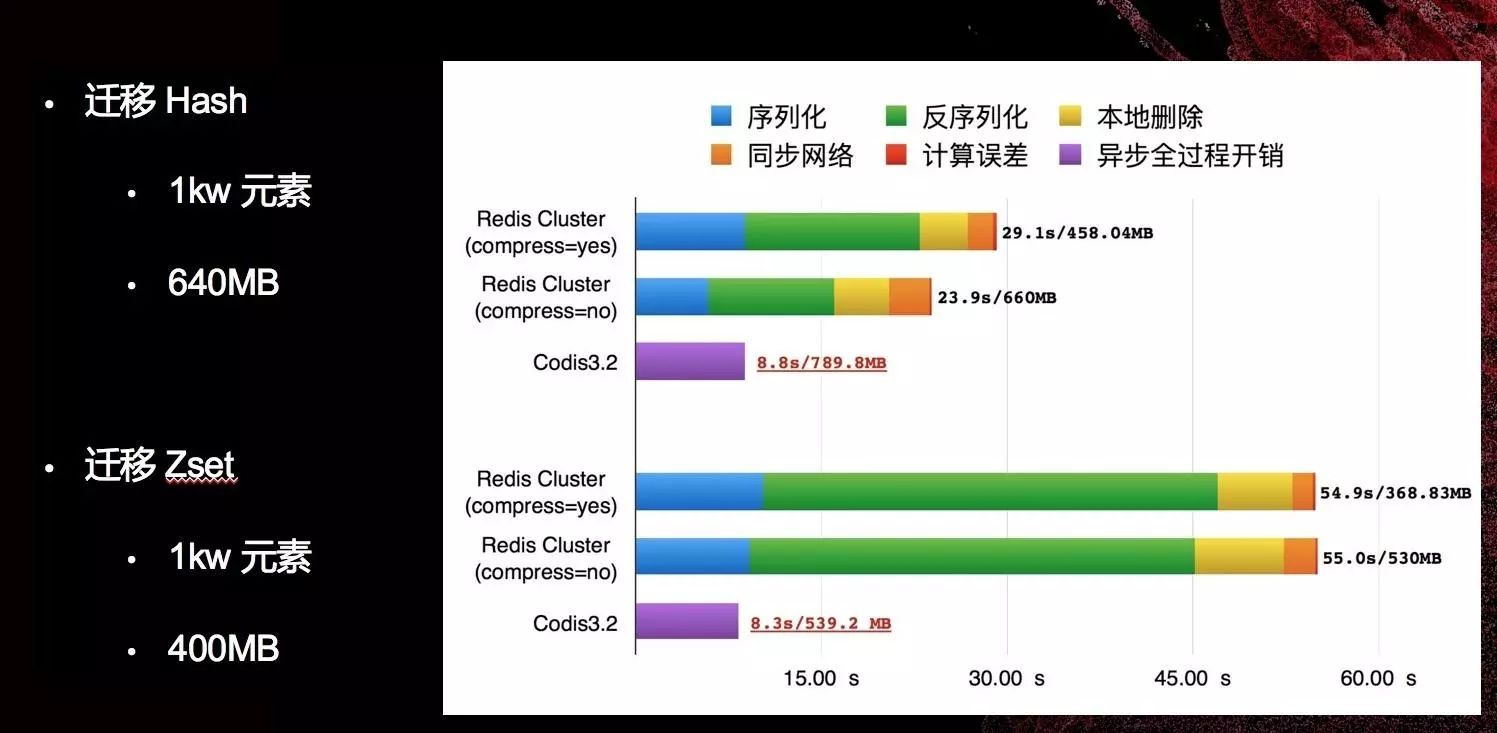
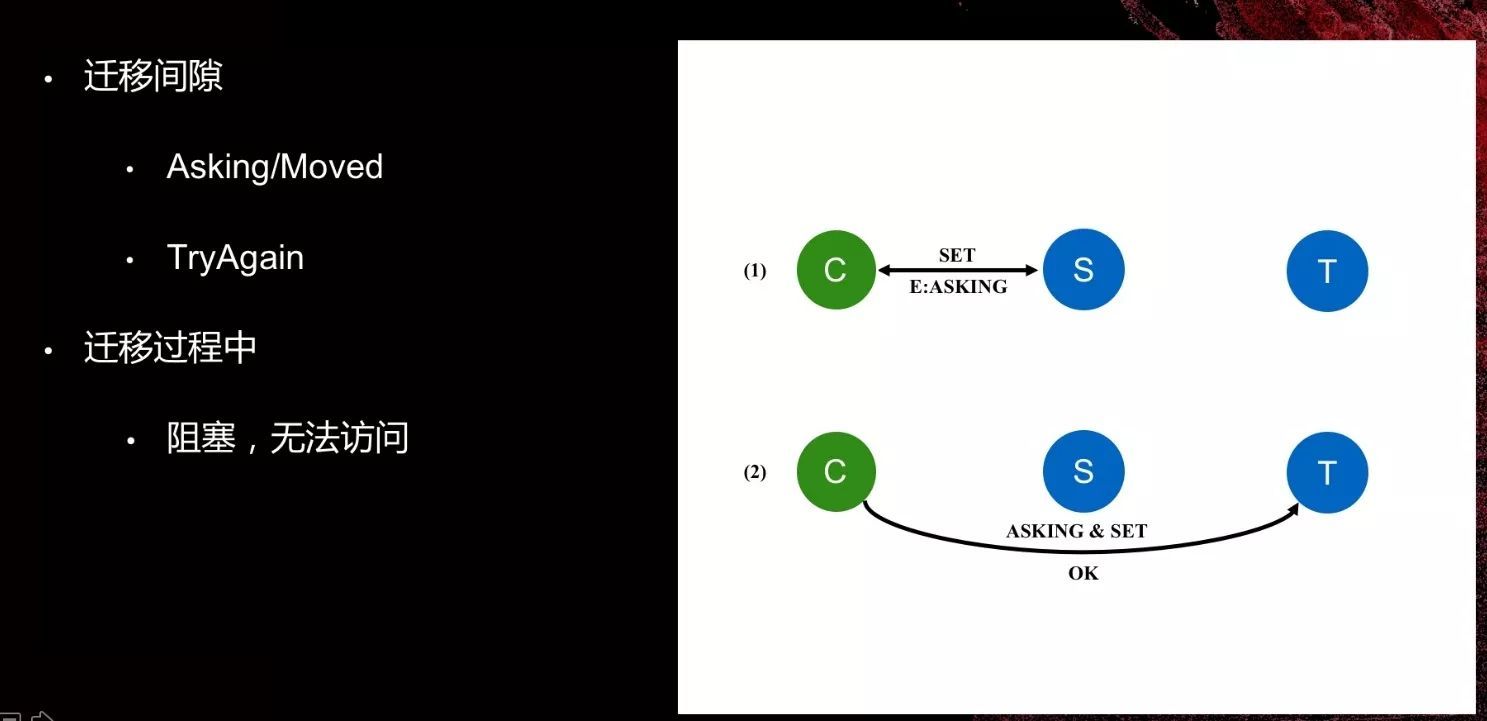
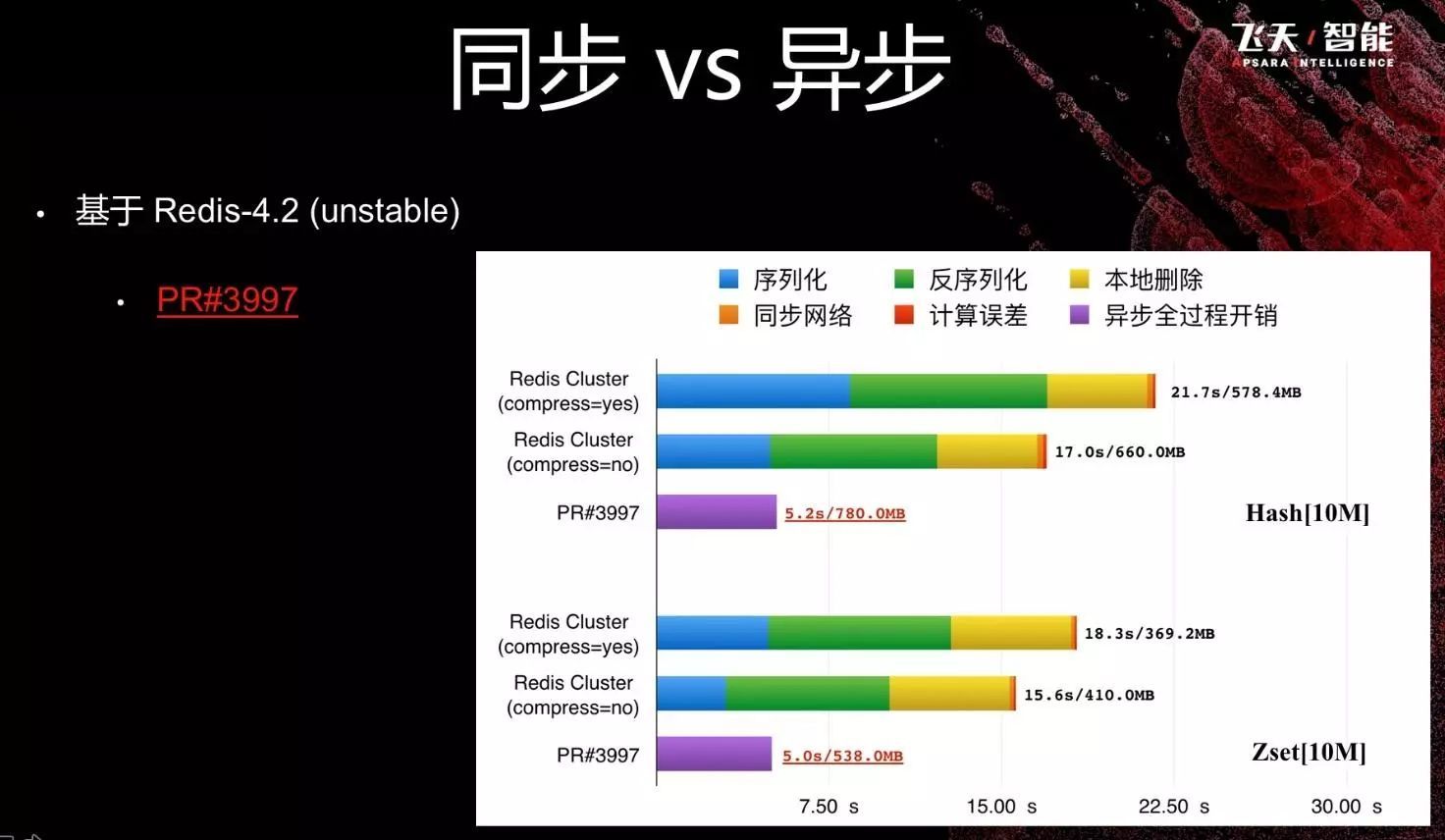
那么上述的问题的解决思路是什么呢?他继续分享到:
指令分解
异步IO + 指令流水
错误处理 - 脏数据处理
迁移状态机
访问冲突

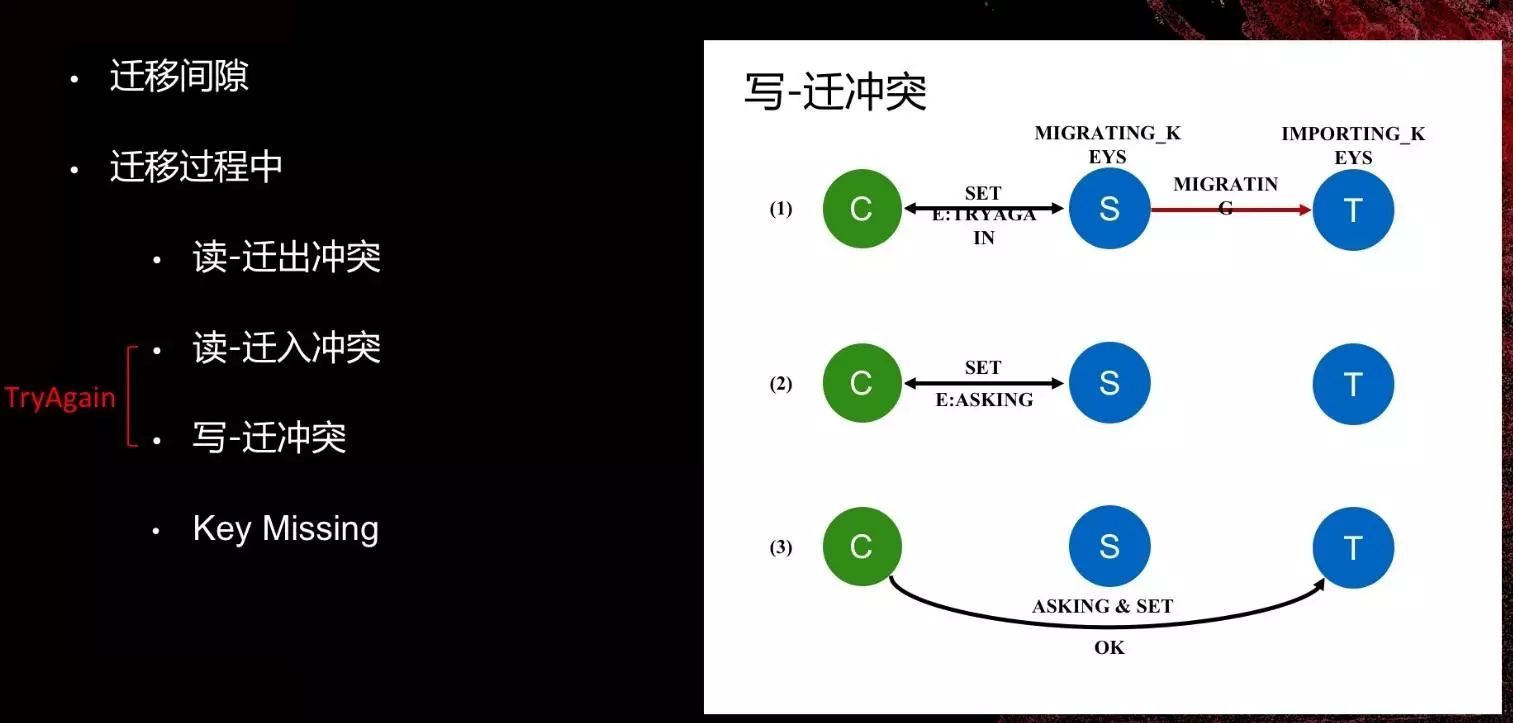
四、Redisson
Redisson是什么?以及Redisson专业版有哪些特性和优点?Redisson联合创始人顾睿从Redisson使用上,举例“如何利用Redisson分布式化传统web项目”的分享,算是对之前内容的一个很好的补充和论证。(Redisson项目地址:https://github.com/redisson/redisson)
传统Web项目的基本架构

传统Web项目的典型特征
什么是分布式系统?
分布式系统的特点
分布式化的实现方式有哪些呢?
分布式系统会遇到哪些挑战?



接着他分享了Redis以及Redisson的概念和特点的介绍,这里为了节省篇幅,省略N多文字,但为了后面的理解,多啰嗦一句:Redisson是操作最简单,功能最丰富的Redis智能客户端,为JVM提供基于Redis的高性能驻内存数据网格。那Redisson的智能化又是体现在哪些方面呢?


Redisson是如此智能的客户端,那相比其它的普通客户端又有怎样的差异和优势呢?

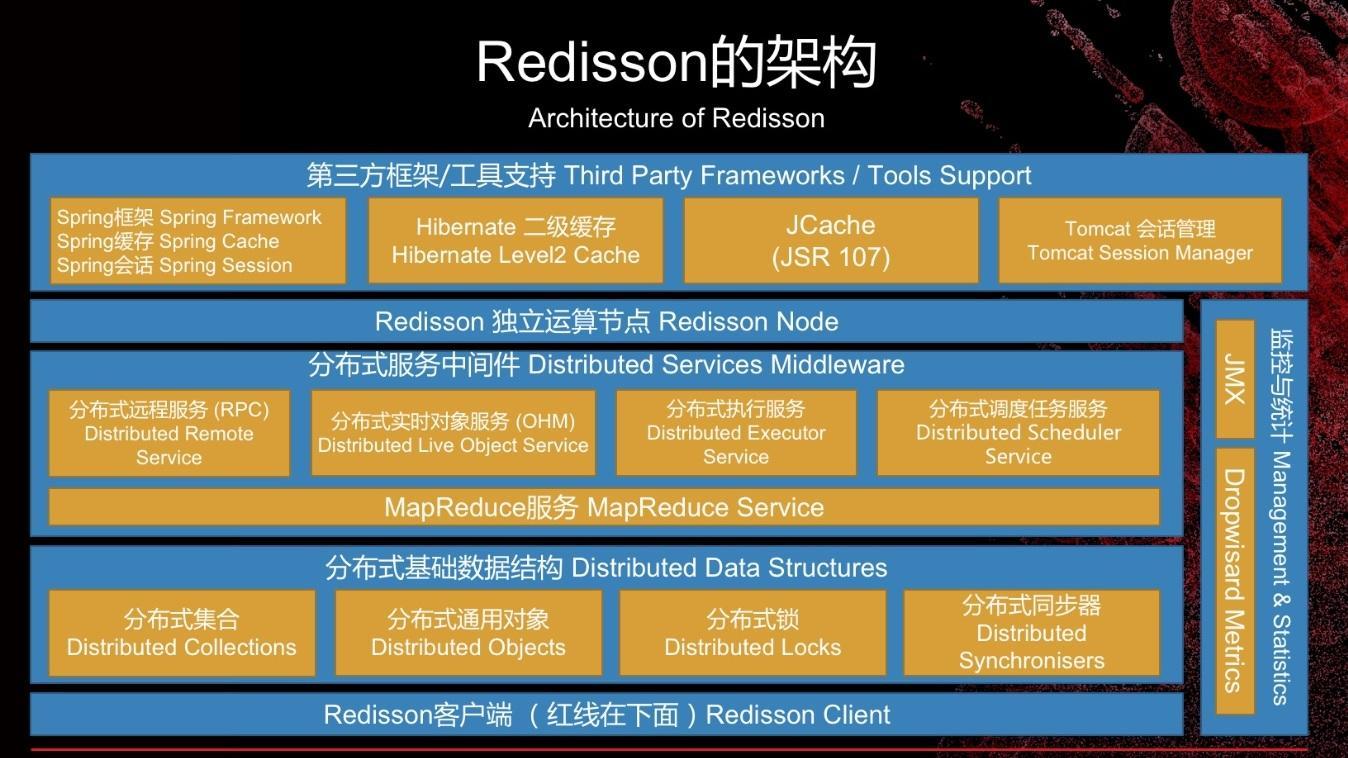
回到主题上,Redisson可以解决传统Web项目分布式化?那它是怎么做到的?当时由于时间的关系,Jack Gu只是从两个方面进行了讲解,相信能在更多的方面进行解决,这两个方面分别是从数据缓存的角度和分布式锁的角度进行分享。
Redisson映射
防缓存穿透,在Redisson上做了一些改进:

Redisson映射数据缓存的两种方案:
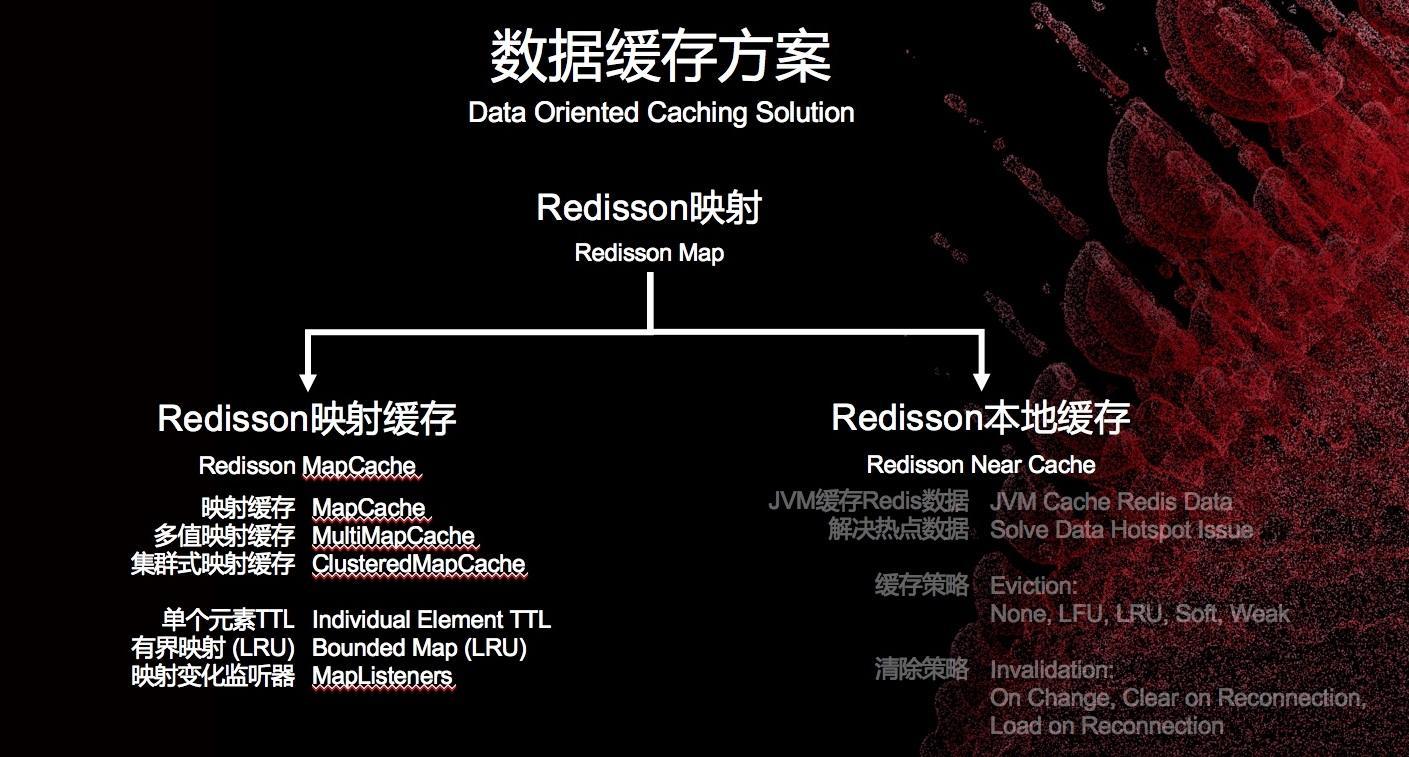
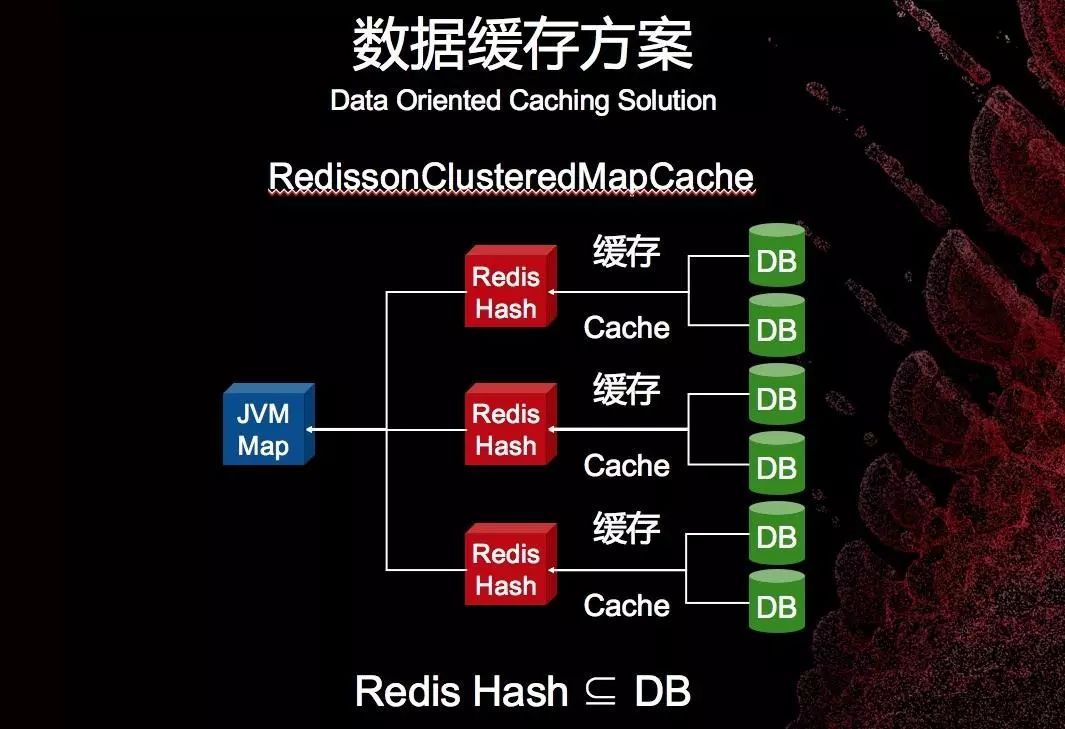


在锁上Redisson又做了哪些改进来满足分布式的需求呢?

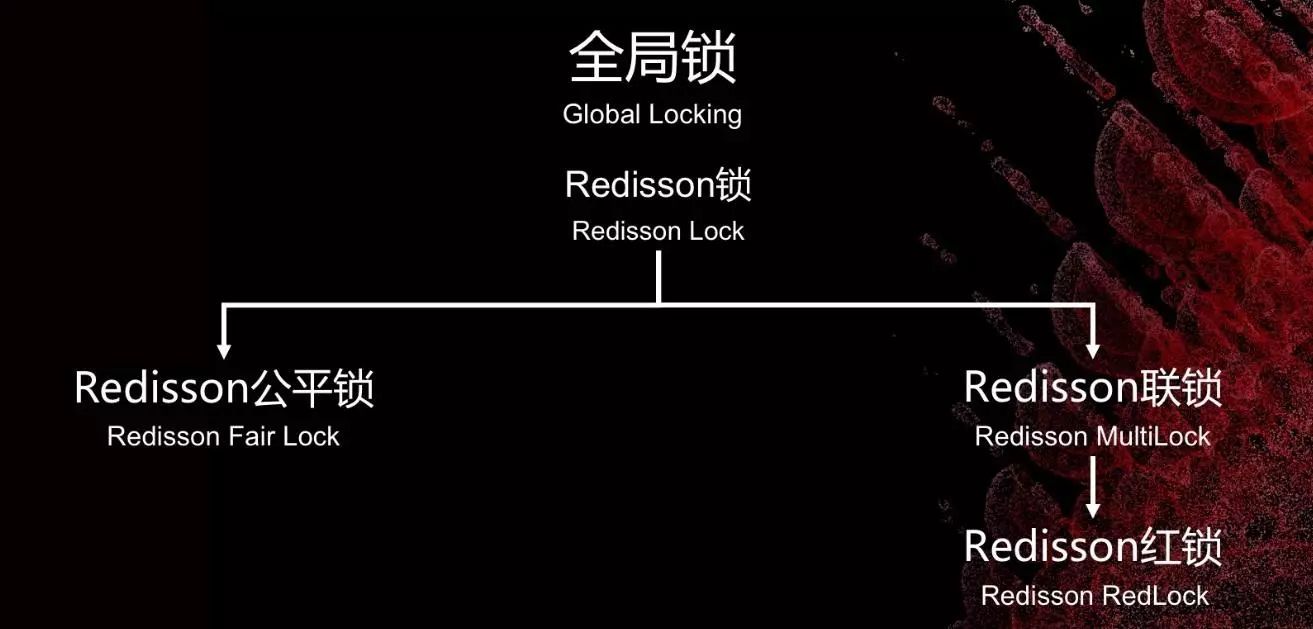


看着上面的简单描述,各种名词似曾相识吧?真正要用起来,还是需要花些时间慢慢消化的。Redisson在一定程度上减少了使用的复杂性,提高了业务性能,提升了开发效率,可以尝试一下。
特别说明:以上内容整理自云栖大会的分享,版权归演讲作者以及云栖大会所有。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721