
国产数据库强势崛起
AI能力、多模态融合、存算分离架构多点突破
2025上半年,数据库行业持续深化技术革新与市场整合。国产数据库在核心场景的应用进一步扩大,技术成熟度显著提升;同时行业竞争格局逐渐明朗,头部厂商通过产品迭代与生态构建巩固领先地位。技术层面,AI深度融合、多模态数据处理、存算分离架构优化成为关键突破方向;产品层面,性能提升、企业级功能增强与安全合规能力建设成为各厂商发力的重点。
AI与数据库融合领域,技术结合呈现纵深化趋势。Oracle Exadata X11M、TiDB、PolarDB等产品均推出向量检索、大模型集成等能力,MySQL创新版新增JavaScript存储程序对AI工作流的原生支持。未来数据库将更深度嵌入AI推理与训练能力,实现从数据存储到智能分析的闭环。
多模态数据处理领域,Elasticsearch的BBQ向量压缩、StarRocks的混合检索等技术突破显著提升非结构化数据处理效率,传统关系型数据库通过扩展向量、JSON等数据类型,逐步构建统一的多模态数据平台。
架构创新领域,存算分离与融合架构成为新热点。存算分离方面,Flink 2.0的分离式状态管理、OceanBase的列存副本等技术通过资源解耦实现性能与成本的平衡。
湖仓一体领域,ClickHouse的Iceberg集成、Apache Doris的Catalog级缓存控制等优化,推动实时分析与离线批处理的深度融合。
在基础能力建设领域则聚焦三大方向:一是兼容性层面,达梦、金仓等产品持续增强对Oracle/MySQL语法的支持,TiDB企业版推出存储过程自动转换工具;二是易用性层面,SelectDB Studio等可视化工具降低使用门槛,OceanBase的ASH报告重构提升诊断效率;三是安全合规层面,火山引擎Redis的跨地域备份、崖山数据库的库级闪回等技术强化数据保护能力,满足等保三级等监管要求。
市场格局显现马太效应。国产数据库中头部趋势初显、行业洗牌加速,具备核心技术优势的头部厂商通过扩大生态合作,中小厂商则聚焦垂直领域差异化创新。分布式数据库进入精耕期,在原有能力基础上增加更多附加能力,如向量、AP分析;集中式数据库则更强调从兼容性及迁移等角度入手优化。各主流厂商开始聚焦LTS版本稳定性优化,通过智能运维工具链降低大规模集群管理复杂度,在AI领域开始做些尝试。出海布局仍处初期,仅少数厂商开展海外业务试点,全球化能力建设将成为下一阶段重点。
从未来技术演进上看呈现几个趋势:一是多模融合能力不断强化,如向量计算已成为标配;二是多架构统一成为必然,从分布式纷纷推出单机版本可见一斑;三是新的交互方式不断涌现,从自然语言交互实现数据查询到MCP流行对智能运维能力提升等等;四是集中式架构优势凸显,部分厂商开始在共享存储集群开始发力。预计下半年上述技术趋势将更为明显。
dbaplus社群携手一众数据库行业专家,汇总、梳理并提炼出主流数据库近半年的版本更迭、性能优化、功能提升等关键信息,希望对大家了解数据库发展趋势,以及数据库选型工作有所帮助和启发。
DB-Engines数据库排行榜
一、RDBMS
Oracle Exadata X11M正式推出
MySQL 2025上半年重要版本发布汇总
SQL Server 2025发布CTP 2.1版本
PostgreSQL发布18 Beta 1版本,含新异步I/O、UUIDv7等功能
OceanBase共发布5个版本,面向关键业务负载及实时分析(AP)场景
TiDB在AI与多模态能力上持续演进,企业版新增一站式运管与迁移工具
二、大数据生态圈
Elasticsearch发布两个重要版本
Apache Flink发布2.0.0版本
ClickHouse发布六个新版本
Apache Doris发布最新稳定版本2.1.10
SelectDB 2025上半年重要发布汇总
StarRocks发布3.4和3.5版本
ByteHouse云数仓发布2.3 GA版本
三、国产数据库
达梦数据库更新DM8.1版本
金仓数据库KingbaseES推出多项重大更新
GBase 8s发布3.6.5版本引入新存储引擎
巨杉分布式文档型数据库发布v5.8.5版本
爱可生发布多款AI4DB产品
崖山数据库YashanDB发布V23.4 LTS长期支持版本
四、云数据库
PolarDB 2025上半年版本更新汇总
百度智能云2025上半年数据库产品更新汇总
京东云2025上半年数据库产品更新汇总
火山引擎2025上半年数据库产品更新汇总
2024年度Newsletter回顾&下载
推出dbaplus Newsletter的想法
感谢名单
为方便阅读、重点呈现,本文对各板块内容进行了精简,需阅读完整版可点击文末【阅读原文】或登录以下链接进行下载:
https://pan.baidu.com/s/1JYJsEoCq4r2o0kOSDXOWkw?pwd=2507(提取码: 2507)
DB-Engines数据库排行榜
以下取自2025年7月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。
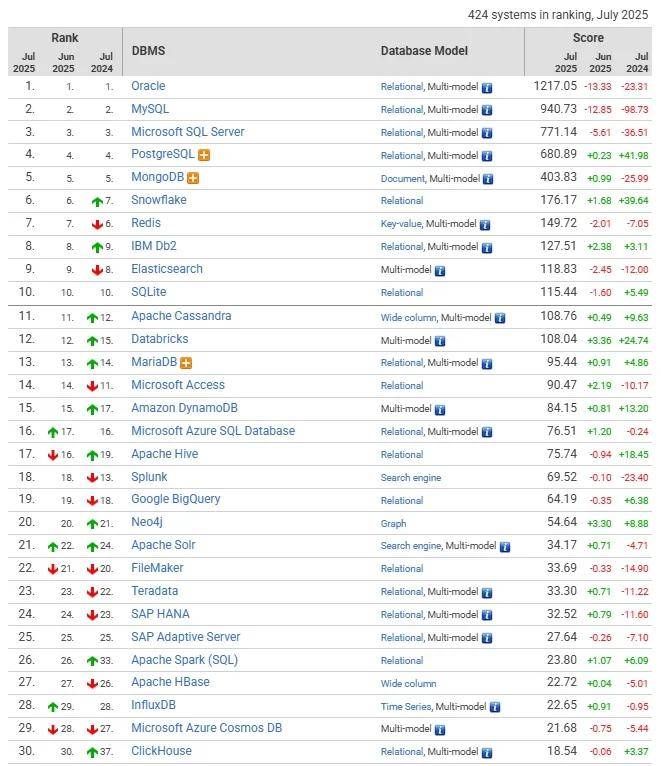
DB-Engines排名的数据依据5个不同的因素:
Google以及Bing搜索引擎的关键字搜索数量
Google Trends的搜索数量
Indeed网站中的职位搜索量
LinkedIn中提到关键字的个人资料数
Stackoverflow上相关的问题和关注者数
RDBMS
1、新一代Oracle Exadata X11M于2025年1月7日正式推出,支持客户在所需的位置进行灵活部署,包括本地环境、Cloud@Customer、Oracle Cloud和多云环境。数千家企业(包括全球大型金融、电信和零售企业)都使用Exadata来运行高需求的关键Oracle Database工作负载。第13代Exadata以数十年的工程技术为基础,可为全球关键任务AI、分析和OLTP工作负载提供支持。
2、Oracle和Google Cloud宣布计划实施开创性的合作伙伴计划,在Oracle Database@Google Cloud上推出Oracle Base Database Service,并推出新功能和区域。新的合作伙伴计划旨在让Oracle和Google Cloud能够共同为客户提供Oracle Database@Google Cloud。Oracle Database@Google Cloud现已支持Oracle Exadata X11M。
一、MySQL 8.0系列发布多个重要版本
MySQL 8.0系列发布了8.0.41和8.0.42,以及LTS长期支持版本8.4.4和8.4.5。这些版本主要专注于稳定性提升、性能优化和安全性增强,虽然没有重大功能创新,但在InnoDB存储引擎、复制机制、查询优化器等核心组件方面进行了大量重要修复和改进。特别是空间索引损坏修复、Group Replication死锁问题解决,以及SQL函数兼容性处理机制的引入,为生产环境的稳定运行提供了更强保障。
8.0.41、8.0.42、8.4.4和8.4.5版本主要更新包括:
1、InnoDB存储引擎优化
启动性能提升:改进了InnoDB启动时间
空间索引重大修复:修复了空间索引在几何最小边界矩形(MBR)微小变化后跟随删除操作时发生的损坏问题,升级时建议先删除空间索引再重建 (8.0.41/8.4.4);修复了包含空间索引和自增列的表使用INPLACE算法进行ALTER TABLE时可能导致损坏的问题 (8.0.41/8.4.4)
ALTER TABLE算法调整:对空表执行ADD COLUMN或DROP COLUMN操作现在默认使用INPLACE算法而非INSTANT算法,避免行版本递增 (8.0.41/8.4.4)
2、查询优化器增强
GROUP SKIP SCAN优化:修复了SELECT DISTINCT ... WHERE NOT IN(SELECT...)查询转换为antijoin后无法选择group skip scan导致的性能退化问题 (8.0.41/8.4.4) MySQL 8.0.41的这个更新确保了在查询优化过程中,即使进行了内部的连接转换,仍然能够在适当的情况下使用高效的组跳过扫描访问方法,从而恢复了这类查询在MySQL 5.7中的良好性能表现
UNION内存优化:通过在解析层面扁平化相等集合操作来减少UNION操作的过度内存消耗 (8.0.41/8.4.4) 这个优化通过在SQL解析的早期阶段就识别并扁平化连续的UNION操作,避免了创建深层嵌套的中间结构。这种方法显著减少了内存使用,特别是对于包含大量UNION操作的复杂查询。修复使得原本可能因内存不足而失败的查询能够正常执行,并且提升了整体性能
Hash Antijoin修复:修复了hash antijoin溢出到磁盘时跳过探测表中NULL值行导致的错误结果 (8.0.41/8.4.4)
3、复制和集群改进
大事务复制修复:解决了接收和应用大事务时使用STOP REPLICA无法正常停止复制通道的问题 (8.0.41/8.4.4)
Group Replication死锁修复:解决了添加新从节点导致现有从节点滞后,两个内部管理器之间产生死锁的严重问题 (8.0.41/8.4.4)
4、重要功能变更
SQL函数兼容性处理:引入--check-table-functions服务器选项,解决MySQL升级过程中的函数改进导致的表兼容性问题。默认ABORT模式确保升级安全性 (8.0.42/8.4.5)
安全更新:升级OpenSSL至3.0.16版本,修复安全漏洞 (8.0.42/8.4.5)
Performance Schema改进:修复了非root用户运行START REPLICA时前台复制线程被分配用户名而非system user的问题 (8.0.41/8.4.4)
二、MySQL创新版发布9.2.0和9.3.0两个重要版本
MySQL 9.2.0和9.3.0在JavaScript存储程序、组件架构、企业级功能等方面有重大创新和增强。特别是JavaScript对DECIMAL类型的完整支持、容器感知资源分配,以及多项企业版组件的引入,为现代化应用开发和企业级部署提供了强大支持。
9.2.0和9.3.0创新版本主要更新包括:
1、JavaScript支持重大增强(企业版支持功能)
DECIMAL类型完整支持:JavaScript存储程序现在完全支持DECIMAL类型及其别名NUMERIC,可用作输入参数、输出参数、预处理语句绑定参数和返回值 (9.3.0)
ENUM和SET类型支持:MySQL ENUM和SET类型现在支持作为JavaScript存储例程的参数 (9.2.0)
动态库导入:支持使用await操作符的JavaScript库动态导入 (9.3.0)
存储例程API增强:支持从JavaScript例程访问用户定义的函数、过程和变量,使用Schema方法getFunction()和getProcedure() (9.2.0)
事务API支持:提供JavaScript MySQL事务API,执行START TRANSACTION、COMMIT、ROLLBACK等操作 (9.2.0)
内置函数直接访问:支持直接访问MySQL内置函数RAND()、SLEEP()、UUID()和IS_UUID()等 (9.2.0)
国际化支持:提供数字、日期等值的本地化和国际化支持,支持Intl全局对象 (9.3.0)
可重用JavaScript库:支持创建包含可重用函数的JavaScript库,这些库中的函数可以被其他JavaScript存储程序调用(9.2.0)
2、组件新增和增强
Group Replication资源管理器组件:监控组复制中从库的应用通道延迟、恢复通道延迟和系统资源使用情况,驱逐超出限制的成员 (9.2.0企业版)
增加了Group Replication主选举组件:用于在Group Replication集群中实现基于最新数据的主节点选举算法,确保选择数据最完整的节点作为新的主节点(9.3.0企业版)
连接控制组件:新增component_connection_control组件替代连接控制插件 (9.2.0)
选项跟踪器增强:新增全局状态变量option_tracker_usage:feature_name提供功能使用计数 (9.3.0企业版)
3、InnoDB存储引擎创新
容器感知资源分配:支持容器感知资源分配,根据容器分配的逻辑CPU和物理内存计算默认配置值 (9.3.0)
恢复优化:在恢复期间,通过完全禁用恢复过程中的Insert Buffer合并,解决了数据库恢复时的死锁问题,显著提升了恢复速度和可靠性。 (9.2.0)
异步I/O优化:改进了模拟异步I/O处理器在高容量情况下的性能 (9.2.0)
4、查询优化器重大增强
子查询转换扩展:扩展subquery_to_derived优化,通过将子查询转换为派生表连接显著提升查询性能,支持所有量化比较操作(>ANY, >=ANY等),并支持在SELECT子句中转换 (9.3.0)
EXPLAIN增强:为基于迭代器的JSON格式EXPLAIN添加了lookup_references字段,提供与传统格式一致的索引查找引用信息,改善了执行计划分析的完整性 (9.2.0)
EXPLAIN FORMAT=TREE增强:MySQL 8.0.41修复了EXPLAIN FORMAT=TREE输出,现在完整显示ROR交集计划中的聚簇主键扫描步骤,提供更全面的查询执行可见性。 (9.2.0)
5、重要功能变更和弃用
FLUSH PRIVILEGES弃用:FLUSH PRIVILEGES语句现在已弃用,发出时会产生警告 (9.2.0)
降级限制:从9.3版本开始,即使在同一系列中,也无法在各个 MySQL 创新系列版本之间降级。例如,如果发布 9.3.1 版本,升级到该版本后,将无法从 MySQL 9.3.1 降级回 9.3.0(9.3.0)
系统变量移除:移除了innodb_undo_tablespaces、innodb_log_file_size、innodb_log_files_in_group等已弃用变量 (9.3.0)
6、权限和安全增强
新增空间参考系统权限:添加了专门的CREATE_SPATIAL_REFERENCE_SYSTEM权限,替代SUPER权限进行空间参考系统管理,提供更精细和安全的权限控制 (9.2.0)
OpenSSL升级:升级OpenSSL库至3.0.16版本 (9.3.0)
7、工具和客户端改进
mysqldump用户账户转储:mysqldump新增--users选项,可以提供用户账户的逻辑转储 (9.3.0)
mysql客户端时间显示:mysql 客户端现在以三位小数的精度显示查询执行时间,以显示毫秒。 (9.3.0)
8、性能和监控增强
企业Linux 10支持:添加了Enterprise Linux 10 (EL10)支持 (9.3.0)
注:关于MySQL8.0.41、8.0.42、8.4.4和8.4.5版本,HeatWave云服务等产品更新的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
2025上半年,SQL Server主要发布了CTP 2.1版本,其中值得关注的更新如下:
1、发力AI方向:SQL Server 2025引入了Vector数据类型,用于处理向量数据,使用新的数据存储类型意味着要在企业级的数据库中完成强有力的支持AI。存储格式使用向量以优化后的二进制格式,方便开发者操作。每个向量最多支持1998个维度,正式版发布之后,应该会支持更多维度。提供了相关的向量函数,例如VECTOR_DISTANCE、VECTOR_NORM、VECTOR_NORMALIZE 等函数,用于计算向量之间的距离、范数和归一化操作。同时还支持向量索引vector index为快速相似性搜索提供性能保证。
示例SQL代码如下:
CREATE TABLE dbo.vectors (id INT PRIMARY KEY,v VECTOR(3) NOT NULL);INSERT INTO dbo.vectors (id, v) VALUES(1, '[0.1, 2, 30]'),(2, '[-100.2, 0.123, 9.876]');
2、变更事件流 change event steaming:有点类似SQL Server 2008推出的CDC的功能,但是事件变更流的功能完善了CDC的功能,已经支持向云产品发送变更事件流,同时也支持Azure event hubs或Kafka等产品发送数据库DML操作的整体工作变更流。
3、SSMS引入SQL AI功能 ,SQL Copilot辅助:新版本的SSMS将可以通过自然的语言来进行SQL代码的撰写,并且提供SQL查询优化的建议。
4、支持GraphQL:通过Data API Builder支持GraphQL,自动生成GraphQL架构,简化前后端的数据交互,提升开放效率。
5、通过Azure公有云实现云端敏捷性:SQL Server 2025正在变成数据分析系统,从整体的设计将包含了数据的提取、转换、标准化、并集存储等,SQL Server 2025将支持在微软的Fabric中进行数据库镜像,实现零提取,转换加载(ETL)等工作,把工作负载转换到Fabric中。SQL Server 2025的另一个特点就是本地数据云化,通过Azure Arc打造线下线上数据库一体化,本地云端批量部署的方式创造新的数据库概念和产品。
2025上半年,PostgreSQL持续推进技术迭代,于5月8日发布18 Beta 1版本 ,以一系列突破性功能升级,重塑数据库性能与开发体验。
1、全新异步I/O(AIO)子系统:本次版本最重磅的更新,是全新异步I/O(AIO)子系统。通过io_method服务器变量启用后,Linux环境可借助高性能的io_uring框架实现异步读写,其它操作系统则通过工作线程模拟,从底层提升I/O效率。官方测试显示,部分读取操作吞吐量提升2-3倍 ,延迟显著降低,尤其适配高并发、大数据量场景,为日志写入、数据备份等I/O密集型任务 “松绑”。新增系统视图pg_aios,可实时监控AIO文件句柄状态,助力运维精准排查性能瓶颈。
2、原生支持UUIDv7:PostgreSQL 18 Beta 1原生集成UUIDv7生成器 ,通过uuidv7()函数输出时间戳有序的UUID。相较于传统UUID,UUIDv7天然适配时间序列场景:在B-树索引中,按时间排序的特性可减少页面分裂,提升索引写入效率;缓存策略设计上,更易实现“热点数据优先保留”,配合分布式系统时,能通过时间戳快速溯源数据生成顺序,为微服务、事件溯源架构提供更高效的唯一标识方案。
3、EXPLAIN与约束语法升级:EXPLAIN命令迎来智能增强,默认自动附加BUFFERS输出,同时新增WAL写入量、CPU耗时、平均读取统计 ,让查询性能分析从 “黑盒” 变 “透明”。开发者无需额外参数,即可一键获取查询的I/O压力、计算开销全貌,优化SQL更具针对性。
2025上半年,OceanBase共发布5个版本迭代,包括面向关键业务负载的全新里程碑版本4.2.5 LTS BP4,以及面向实时分析(AP)场景的LTS版本4.3.5 BP2,其中值得关注的特性包括:
一、面向关键业务负载:OceanBase 4.2.5 LTS
OceanBase 4.2.5 LTS持续在系统稳定性、执行性能和诊断易用性方面提升,进一步增强关键业务场景下的处理能力与运维效率。
1、系统稳定性与可靠性:引入租户级异构Zone,支持不同Zone配置不同的UNIT NUM,提升故障恢复灵活性和扩缩容的可控性。优化高TPS场景下事务表的空间回收策略,降低I/O压力。Oracle模式常用系统视图支持等值查询索引加速,提升管理类操作性能。备份支持并行补偿日志,加快备份任务执行。
2、执行性能与资源调度优化:并行DML(PDML)适用范围扩大,提升复杂关联更新语句的执行效率。异构Zone支持在Follower副本上完成扩容或迁移后,再平滑切换Leader,降低扩缩容对业务的影响,实现更灵活的资源调度。
3、安全性与易用性:MySQL模式下支持外键引用非唯一索引列,放宽字段类型限制,禁用环状自引用及级联更新,增强兼容性与一致性保障。ASH报告结构重构,支持多维度分析并结合WR仓库生成更长时间段的运行报告。新增I/O诊断、事务统计和SQL执行阶段采集能力,配合展示优化与内存开销降低,提升可观测性与诊断效率。SQL执行计划缺失时可回溯查询WR中的历史记录,完善性能调优与问题定位闭环。
二、面向实时分析(AP)场景:OceanBase 4.3.5 LTS
针对AP场景推出列存副本能力进行大幅性能优化,推出向量检索及混合检索能力,实现SQL + AI一体化,进一步满足客户在实时分析及AI场景的数据管理需求,加速RAG、智能推荐、多模态搜索等业务场景的落地。
1、多模态数据支持:进一步扩展复杂数据类型的处理能力,新增Array类型,并对Roaringbitmap类型数据的计算性能进行了优化,为企业处理多样化数据结构提供更高的灵活性。
2、向量融合查询能力:新增向量检索能力,支持向量数据类型和向量索引,并基于向量索引提供强大的搜索能力。用户可通过SQL及Python SDK等方式灵活调用OceanBase的向量检索能力,同时结合对海量数据的分布式存储能力、多模数据类型及多类型索引的支持,极大简化AI应用技术栈。在这个版本中,AI向量检索方面持续演进,基于VectorDBBench基准测试,在Performance768D1M数据集上性能已达开源向量数据库的行业领先水平,全面支持向量类型存储、向量索引、近似最近邻(ANN)搜索等功能。
3、多工作负载:对AP(分析处理)场景进行大幅性能优化,尤其是在海量数据分析时,能够提供更短的响应时间和更高的吞吐能力。通过列存副本形态,实现满足TP和AP负载的物理资源强隔离,确保系统在处理事务型负载时,不受分析型负载的影响,特别是在实时数据分析和决策场景中,能够保持系统的高性能与稳定性。
一、在AI与多模态数据处理能力上再度演进
2025上半年,TiDB继去年全面支持向量搜索后,其生态工具PyTiDB现已原生支持MCP协议,让用户能以更安全、可控的方式将TiDB接入AI工具,通过自然语言直接进行数据查询与分析。同时,作为多模态数据底座的另一块拼图,全文搜索(Beta)功能也已在TiDB Cloud Serverless上线。
TiDB发布了v8.5.2 LTS及v7.5.6 LTS版本,在性能、易用性与稳定性方面获得了显著增强,部分亮点包括:
性能方面:TiFlash现已支持利用向量索引加速查询,并优化了TTL表的GC开销。
易用性方面:数据导入工具Lightning增加了关键检查,提升了大规模数据导入的稳定性。
二、TiDB企业版更新:新增白屏化管控与一站式迁移工具
对于企业级用户,基于最新TiDB内核的TiDB企业版v7.1现已发布。新版本继承了向量搜索、JSON多列值索引等内核能力,并推出了两大企业级工具:
TiDB Enterprise Management:提供覆盖集群全生命周期的白屏化管控能力,集成了监控告警、SQL审核、备份恢复、权限管控等功能,大幅简化了运维复杂度。
TiDB Migration System:支持从Oracle/MySQL的一站式迁移,提供兼容性评估、数据校验,并创新性地引入AI能力,可将存储过程自动转换为Java代码,显著降低迁移成本。
大数据生态圈
Elasticsearch在2025上半年主要发布了两个重大版本,8.18.x与9.0.x,带来了诸多新的功能特性,如ES|QL支持索引联合查询LOOKUP JOIN;在性能上有大幅度提升,如Lucene 9升级到Lucene 10,BBQ(Better Binary Quantization)向量搜索技术。另外,针对7.17.x、8.16.x、8.17.x发布了多个修复版本,便于用户升级更新。
Elasticsearch 8.18.x应该是ES 8系列最后一个版本,之后ES 8 不会有新的大版本发布,后续会持续发布多个修复版本,为迁移升级到ES 9做适配。
Elasticsearch 7.17.x发布了一些修复版本,修复已知问题,为迁移升级ES 8做适配。

Elasticsearch 2025 上半年版本发布情况
1、LOOKUP JOIN多索引联合查询
LOOKUP JOIN在ES 8.18正式发布,在历史版本中,想在ES上实现宽表查询,需要在三方平台完成宽表拼接或者借助ES Ingest Enrich完成,这些方式都有一定的局限性,特别是查询数据实时性问题。
LOOKUP支持宽表查询,但是必须使用ES|QL查询语法,其它查询语法无法完成,ES|QL是新的查询引擎,性能上相较于过去有大幅度提升。
LOOKUP虽然支持多个索引联合查询,带来了诸多便利性,但跨多数据表联合查询依然会有性能瓶颈,在强调查询为主的场景下,宽表依然是最佳的解决方案。
2、Better Binary Quantization二进制量化
Better Binary Quantization(BBQ)是一种高效的向量压缩与搜索技术,首次出现在8.16预览版本中,在ES 8.18正式发布。
BBQ核心原理是通过binary二进制来替代float32量化存储,相比原有float32节约了95%的存储量,是一种极致的量化压缩技术手段。
BBQ在存储时量化速度同比快10倍以上,查询速度同比快2倍以上,非常适合大规模AI向量应用场景。
3、Semantic text语义文本字段类型
新增semantic_text语义文本字段类型,通过指定推理模型,直接将文本转换为向量类型,相比原有的dense_vector稠密向量与sparse_vector稀疏向量,在操作性上带来了一些便利,如向量转换、向量查询场景。
# 配置语义字段类型,指定推理模型{"mappings": {"properties": {"inference_field": {"type": "semantic_text","inference_id": "my-elser-endpoint-for-ingest","search_inference_id": "my-elser-endpoint-for-search"}}}}
4、Rank Vectors多组向量字段类型
新增rank_vectors多组向量字段类型,容许给文档存储多组向量,而不是单个dense_vector稠密向量值,这些向量在检索阶段用于第二轮重排序,采用max-sim相似度函数完成,ES目前内置maxSimDotProduct脚本函数。
rank_vectors适合第一次用HNSW或BBQ做粗排,再用多向量maxSim做精排的场景。
# 单一字段配置多组稠密向量{"dbaplus_vector" : [[0.5, 10, 6], [-0.5, 10, 10]]}
5、Lucene 10
Elasticsearch内核全面升级到Lucene 10。
并行化索引分段(segments)文件搜索。
并行化I/O预读取机制,通过预读取阶段,避免搜索主线程阻塞,导致查询收到I/O研制。
稀疏索引模式(sparse idexing),基于索引排序规则,可以节约大量的数据存储、减少CPU查询消耗。
6、JDK 24
Elasticsearch运行环境全面升级到jdk 24,以获得更好的性能。
jdk 24拥有诸多新功能特性,都是Elasticsearch需要使用的,如:结构化并发与虚拟线程,ES可以更好地控制任务并发;更强的native支持,可以更直接地获得原生操作系统与硬件的性能。
7、Elasticsearch MCP Server
Elasticsearch发布了官方的标准MCP Server,提供了比较简单的tools,基于NodeJS运行,非常便利AI场景使用,如果期望更多的使用MCP,可以基于此分支开发晚上更多特定的场景。
8、docs文档风格变化
Elasticsearch官方文档风格变化巨大,ES 9基于整体解决方案的思路,设计文档查看方式,相比ES 8更注重应用场景的解决方案能力,对于新手来说,是一个不小的挑战。
2025年3月24日,Apache Flink 2.0.0发布,引入了多项重要功能,具体如下:
1、分离式状态管理
Flink 2.0引入了分离式状态管理,提供了从运行时到SQL算子层的端到端体验,显著提升了性能和云原生支持。
异步执行模型:
无序数据处理:解耦状态访问和计算,实现并行执行。
异步状态API:支持非阻塞性状态操作,减少延迟并提高资源利用率。
语义保持:确保核心语义(如水位传播、定时器处理)不变,用户无需担心行为变化。
更强大的SQL算子:
重新实现了七个关键SQL算子(如Join和Aggregates),支持异步状态访问,提升吞吐量。
用户可通过table.exec.async-state.enabled参数启用该功能。
ForSt分离式状态后端:
专为云原生设计,解耦状态存储与计算,支持并行I/O操作,降低延迟。
集成DFS,确保数据持久化和容灾能力,优化读写性能。
性能评估:
在Nexmark基准测试中,重I/O的有状态查询吞吐量提升显著(75%-120%)。
状态较小的查询性能平均下降不超过10%,展现了分离式架构的高效性。
2、流批统一
Flink 2.0在流批统一处理方面取得重要进展,提升了生产级可操作性和性能。
物化表:
支持表结构和查询语句的更新,无需重新处理历史数据。
原生支持YARN和Kubernetes集群,便于生产环境集成。
与Paimon集成,实现流批计算与高性能ACID事务的结合。
自适应批处理执行:
自适应Broadcast Join:动态切换Join策略,提升执行效率。
自动优化数据倾斜:动态拆分倾斜数据分区,缓解长尾延迟。
性能提升:
在10TB TPC-DS基准测试中,性能提升8%-16%。
3、流式湖仓
Flink与Paimon的深度集成,提升了流式湖仓的实时处理能力。
Paimon数据源增强:
支持嵌套投影下推,减少I/O开销。
Lookup Join性能提升,减少数据检索量。
Paimon维护操作:
通过Flink SQL的CALL语句轻松执行维护操作,支持命名参数。
4、人工智能支持
Flink 2.0加强了与人工智能的集成,支持实时数据处理与AI模型结合。
Flink CDC 3.3:
引入动态调用AI模型的能力,支持OpenAI模型。
实现RAG技术在实时场景中的应用。
Flink SQL增强:
支持定义和调用AI模型,无缝集成复杂数据处理逻辑。
5、API改进
DataStream V2 API:
提供基础构建块和高级扩展,如窗口和Join。
当前处于实验阶段,建议在生产环境中谨慎使用。
SQL Gateway:
支持Application模式执行SQL作业,取代Per-Job模式。
SQL语法增强:
支持C风格转义字符串。
新增QUALIFY子句,简化窗口函数过滤。
6、非兼容性变更
Flink 2.0移除了多个旧API和功能,包括:
移除的API:
DataSet API、Scala DataStream和DataSet API。
SourceFunction、SinkFunction、Source和Sink V1。
TableSource和TableSink。
配置调整:
移除旧版配置文件flink-conf.yaml,采用新格式config.yaml。
Java最低版本提升至Java 11,不再支持Java 8。
其他变更:
状态兼容性不再保证,需重新设计状态管理。
移除Per-Job部署模式,推荐使用Application模式。
7、其他优化
序列化改进:
引入更高效的集合类型序列化器。
Kryo升级至5.6版本,提升性能和兼容性。
连接器适配计划:
Kafka、Paimon、JDBC和ElasticSearch连接器将率先适配新API。
2025上半年,ClickHouse主要发布了24.12、25.1、25.2、25.3、25.4、25.5六个新版本,其中25.3是LTS版本,值得关注的更新具体如下:
1、JSON动态列作为表主键:在24.12 中,ClickHouse将每个唯一JSON路径的值以真正的列式存储方式进行存储,这种方式不仅提供了出色的数据压缩,还能保持与传统数据类型相同的查询性能。
2、Join的持续优化和改进:从24.12到25.5,ClickHouse通过指定并行Hash作为默认算法,自动重新排序,Join表达式优化,支持非等值JOIN等一些列功能演进,得到了TPCH结果的巨大优化。
3、ANN Vector Search in Beta:ClickHouse 25.5中的向量相似度索引功能现已从实验阶段升级为Beta阶段,并新增了对混合搜索中前置过滤和后置过滤策略的支持。
4、数据湖的集成:在24.12中,ClickHouse引入了对查询Apache Iceberg REST目录的支持。同时支持的还有Unity和Polaris目录,在之后的几个版本中又新增了对Delta RUST的内核集成以及支持AWS Glue and Unity。在25.4中,ClickHouse开始支持用户在外部托管的、持续更新数据集上运行无限数量的阅读器,这非常适合数据共享和发布,另外,ClickHouse也可以在Iceberg的历史快照中执行查询。
5、其他优化:
提升查询性能:查询条件缓存(25.3),延迟物化(25.4),外部数据的自动化并行处理 (25.3)等。
便捷使用:增加了Minmax Indice(25.1),表级别的默认压缩编码器(25.4)等。
企业化功能:支持备份数据库引擎(25.2)。
2025上半年,Apache Doris发布了最新稳定版本2.1.10,该版本持续在查询执行引擎、湖仓一体等方面进行改进提升与问题修复,其中值得关注的新功能有:
1、查询执行引擎:支持了更多的GEO类型的计算函数ST_CONTAINS,ST_INTERSECTS,ST_TOUCHES,GeometryFromText,ST_Intersects,ST_Disjoint,ST_Touches;支持years_of_week函数。
2、湖仓一体:Hive Catalog支持Catalog级别的分区缓存开关控制;Paimon、Iceberg版本依赖升级至最新。
2025上半年,SelectDB发布了SelectDB Enterprise Core 2.1.8-2.1.10、3.0.5、SelectDB Enterprise Manager 24.1.4-24.1.5、24.2.0、24.3.0-24.3.1,以及全新免费管理工具SelectDB Studio 1.0.0、1.1.0-1.1.1。其中值得关注的新功能有:
1、SelectDB Enterprise Core
湖仓一体:FE Metrics新增Catalog/Database/Table数量监控指标;MaxCompute Catalog支持Timestamp类型
查询执行:新增URL处理函数:top_level_domain、first_significant_subdomain、cut_to_first_significant_subdomain;新增year_of_week函数,兼容Trino语法实现;percentile_array函数支持Float和Double数据类型
存算分离支持重命名计算组(Rename Compute Group)
2、Enterprise Manager
集群巡检功能Preview版本
Manager部署、升级等任务重构优化
节点前置检查增加对JAVA_HOME有效性的检测
节点启动、重启、批量重启增加前置检查
主机监控的IO-Util和磁盘吞吐量按照具体磁盘显示
集群升级备份数据提示文案优化
Studio支持获取版本号
Studio跳转提示优化
新建集群优化节点元数据、存储、日志等目录生成逻辑
主机界面新增Agent部署端口和路径的展示
集群为非运行状态时,也允许设置自动拉起和FE代理地址
优化Manager日志结构,去掉manager.out日志
3、SelectDB Studio
发布了Windows版本和Mac Intel芯片版本,对SQL控制台做了较大的更新,以及一些Bug修复和功能优化:
SQL控制台支持多行SQL查询
Profile支持原始Text格式显示
支持REFRESH CATALOG
支持白名单限制部分用户登录(Server 版本,运行在Cloud BYOC仓库上)
用户/角色管理增加COMMENT
StarRocks在2025上半年发布了3.4与3.5两个版本,持续提升性能与体验,并带来多项关键功能更新,覆盖AI场景支持、存算分离、数据湖优化等多个方向。
1、更强的AI场景支持
引入Vector Index,支持IVFPQ和HNSW两种主流索引类型
新增Python UDF,便于数据预处理、模型推理
支持Arrow Flight协议,加速大批量查询结果传输,提升系统间协作效率
2、分区管理优化
支持时间表达式分区合并
支持通用分区表达式TTL,支持基于分区表达式定义分区的生命周期管理策略
3、ETL增强
新增多语句事务(Multi-statement Transaction),实现完整的原子性和一致性保障
4、存算分离
新增集群级Snapshot快找功能,提升灾备能力
引入了批量导入优化功能,减少导入后查询波动及Compaction成本
优化主键表内部修复逻辑
5、物化视图
支持多列分区表达式
支持分区级 TTL 策略
透明查询改写增强
6、数据湖
Iceberg v2 equality delete读取优化,避免重复读,提升性能
支持异步查询片段投递
引入SLRU缓存淘汰策略,缓解缓存污染,提升命中率
还优化了Data cache的自适应I/O策略
新增Query Feedback功能,识别慢查询并给出调优建议
查询模式优化,涵盖主外键裁剪、聚合下推、多列OR谓词下推等
7、湖仓生态
支持Iceberg Time Travel功能,允许用户创建或删除BRANCH和TAG,并通过指定TIMESTAMP或VERSION来查询特定分支或标签的数据
一、ByteHouse云数仓
2025上半年,ByteHouse云数仓主要发布了2.3 GA版本,其中值得关注的重点特性有:
负载弹性,通过实时感知负载,动态调配资源,高峰期自动扩容保障响应,低谷期智能缩容降低成本,避免资源瓶颈及浪费,实现计算资源动态优化,保障业务流畅并降本30%;
Binlog,通过实时数据订阅构建事件驱动的实时数仓,实现业务数据变更的瞬间同步与分析,助力企业提升决策效率、降低数据延迟损失并优化运维成本;
向量检索,高效存储与检索文本/图片/视频等多模态非结构化数据的向量特征,实现向量/文本/标量数据混合检索;助力以图搜图转化率提升20%、跨模态搜索转化率提升40%,打破数据壁垒驱动AI应用落地;
文本检索,支持多语言分词、倒排索引及关键词/词组/语义相似度检索;促进企业知识库检索效率提升30%、知识复用率提高40%,有效驱动企业知识管理与智能服务效率升级;
AI日志检索,通过AI模型自动分类日志问题、提供诊断修复建议及自动生成SQL精准检索日志,促进日志分析效率提升5倍,开发测试中问题定位效率提升80%,全面提升企业运维效率与故障应对能力。
二、ByteHouse企业版
2025上半年,ByteHouse企业版主要发布了25.3、25.4及25.5 GA版本,其中值得关注的新特性有:
MCP Server支持基于Faas Remote部署,实现LLM + ByteHouse对接与协同。可为ByteHouse数据开发、查询优化、集群运维提供全生命周期智能化服务;
智能巡检功能可实现集群重点指标按需配置关注,并自动生成巡检报告;
Auto MV支持单表或多表异步物化, 数据处理链路效率大幅提升;
集群扩容能力便捷性显著提升,体验更加流畅;
非结构化数据向量检索场景能力不断增强,在性能、便捷性和易用性方面表现更优;
支持为集群设置白名单以管理集群访问权限,实现精细化访问控制;
新增支持表统计信息收集功能。该功能通过收集集群内表的统计信息,助力用户查看、分析集群中的表信息,用户可依据这些信息采取优化措施,实现集群性能的提升。
国产数据库
2025上半年,达梦数据库主要更新了DM8.1版本,其中值得关注的新特性和新改进有:
1、表连接类型过滤条件优化;
2、DSC故障重启流程优化;
3、PL/SQL 功能改进;
4、DPI接口功能改进;
5、V$LOCK 、V$DICT_CACHE_ITEM 视图功能增强;
6、inject hint功能增强;
7、分析函数、系统函数、聚集函数功能改进和性能优化;
8、部分系统视图功能改进和性能优化,新增视图支持用户创建与系统对象重名的表/视图对象;
9、部分系统包功能改进;
10、DBLINK功能改进;
11、针对SQL涉及contains、update、in list + distinct、 delete、 like、hint等的操作进了行功能改进和性能优化;
12、主备集群、DSC集群和DPC集群功能改进,性能优化;
13、DTS工具数据迁移功能改进,兼容性增强;
14、dexp与dexpdp 导出功能改进;
15、对Oracle、MySQL和SQL Server的兼容性增强。
注:关于达梦数据库DM8.1版本更新的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
2025上半年,金仓数据库发布了四大核心版本及产品,主要更新如下:
1、KingbaseES V9R3C11 MySQL兼容版:全面兼容MySQL语法、PL/SQL、数据类型(如BIT/ENUM/SET)及高级功能(如REPLACE、ON DUPLICATE KEY),支持基于MySQL协议的应用可无缝迁移;单机性能表现出色,单机单表10GB大对象导入仅需57秒,导出25秒;X86架构下TPCC性能指标达240万。
2、KingbaseES V9R4C12 SQL Server兼容版:深度融合SQL Server语法,兼容全局临时表、IDENTITY列等特性。通过ICU库优化字符串处理性能,支持跨平台迁移与零代码修改,显著降低迁移成本。
3、金仓向量数据库:扩展KES关系型数据库的向量处理能力,支持关系、文档、GIS及时序数据一体化计算,继承KES的高性能、高可用与高安全特性,为AI大模型提供一站式开发方案。
4、云数据库一体机KXData-M:深度融合数据库、超融合平台与高性能硬件,搭载AI运维大模型实现全生命周期智能管理,赤兔引擎V1.0使综合性能提升超30%,并构建原生安全体系满足等保三级与密评合规要求。
注:关于金仓数据库产品更新的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
2025上半年,南大通用发布了GBase 8s V8.8_3.6.5版本,引入了新的存储引擎,其中值得关注的更新有:
1、通过内存化MVCC实现了快照隔离,即读不阻塞写,写不阻塞读;
2、实现极速主备切换,压测负载情况下,实现了RPO=0,RTO<3s;
3、基于新存储引擎,在压测场景下,数据库支持上万会话并发执行;
4、从节点一致性读,解决读写分离的纠结;
5、基于新存储引擎,实现极速闪回;
6、支持DDL online,降低了DDL操作对生产业务的阻塞;
7、JDBC接口新增支持4.0以上标准规范;
8、新增python接口驱动;
9、支持异构dblink对Oracle进行读写操作。
注:关于南大通用GBase 8s产品更新的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
2025上半年,巨杉分布式文档型数据库发布了v5.8.5版本,值得关注的更新如下:
1、稳定性提升:修复访问计划评估、索引平衡异常等问题,优化通信机制和容错机制,新增多个慢查询指标,提升整体系统稳定性和可观测性;
2、性能提升:优化索引加锁机制和Lob写操作,提升整体系统的写入性能;
3、内存优化:新增索引缓存清理机制,优化集合空间内存,内存使用减少50%;
4、空间回收:新增删除记录空间自动回收机制,减少磁盘空间浪费;
5、容灾能力提升:完善位置集容灾机制,实现异地中心完全异步容灾机制和紧急切换模式,确保RTO为秒级,RPO为0;
6、管理工具提升:新增元数据一致性检测工具,可以检测元数据不一致的索引和集合,并自动生成修复脚本;数据库文件检测工具新增多个检测指标,检测性能提升50%。
2025上半年,爱可生发布了多款AI4DB产品,包括企业级SQL方言智能转换平台SQLShift、AI智能质量评估平台问简和大语言模型SQL能力测评框架SCALE(开源)。同时,ChatDBA和ActionOMS也带来重大更新,具体如下:
1、ChatDBA发布2.2版本:新增支持PostgreSQL,排查图逻辑一致化与检索系统全面优化;
2、SQLShift发布:企业级SQL方言智能转换平台,支持多款数据库存储过程转换;
3、问简智验平台发布:带着业务视角理解测试任务的AI智能质量评估平台;
4、SCALE发布:一款面向专业级任务的大语言模型SQL能力的开源评测框架;
5、Action OMS更新:支持OceanBase备库数据同步,释放主库压力更高效。
2025上半年,崖山数据库正式发布YashanDB V23.4 LTS版本,两地三中心、库级闪回重磅特性上线,生产级可用性再升级。核心更新包括:
1、高可用能力强化:主备复制集群的“两地三中心”能力升级,实现生产中心内RPO=0,RTO<10秒、同城双中心RPO=0,RTO<10秒、异地灾备中心RPO=<0.1秒、RTO<30秒的极致容灾能力;支持集群节点秒级扩容,线性拓展比高达0.7。
2、智能运维能力提升:在支持对象级和语句级闪回功能的基础上,重磅推出库级闪回技术,进一步强化系统的高可用保障能力;同时,全新推出执行计划追踪功能及执行计划固化技术,辅助DBA精准诊断SQL性能瓶颈及风险防御。
3、兼容性再升级:持续提升与Oracle、MySQL的兼容性,覆盖数据类型、语法、高级特性等全维度,支持企业应用平滑迁移。
4、复杂查询性能大幅提升:通过缓存机制演进、算子下推及批量处理加速技术,实现关键场景的优化规则增强和执行性能提升。
云数据库
2025上半年,PolarDB发布了一系列新版本和新功能,其中值得关注的版本及功能有:
1、PolarDB MySQL版
重磅发布内置大模型的PolarDB for AI新版本,支持模型算子化(Model as an Operator)形态;
发布智能搜索引擎(PolarSearch);
开源发布MCP Server;
发布文件系统PFS2.0版本;
发布分布式内存池(DMP);
列存索引支持向量HNSW索引;
支持单主集群一键迁移至多主集群(Limitless)。
2、PolarDB PostgreSQL版
发布固定规格集群的Serverless功能;
发布分布式版集群;
发布PostgreSQL 17版本;
新增Polar_AI扩展;
新增支持向量化引擎;
时空引擎(GanosBase)升级至7.4版本;
发布AI应用(Supabase版)。
3、PolarDB分布式版
新增支持高性能多版本索引Panda Index;
支持列存索引与冷数据归档表共用;
存储节点支持运行时内存最小化输出;
支持列存索引巡检任务;
全局二级索引(GSI)支持前缀索引。
1、VectorDB
支持GoLang,Node.js,Java SDK
发布VectorDB Lite版,支持x86环境本地部署单机版
发布VectorDB CLI 2.1版本,支持RBAC操作
支持管控平台数据可视化管理工具,方便客户访问
支持备份恢复功能,增强数据的灾备能力
支持资源计算器,方便用户计算资源
支持多可用区部署,提供集群的容灾能力
内核:支持稀疏向量、二进制向量、JSON字段类型,基于规则的索引等特性
2、MongoDB
控制台提供DBSC智能分析能力,支持会话管理、空间分析
新增DiskI/OWaitTime监控
审计日志可设置保留时间
支持账号管理和数据库功能
支持IP白名单组 & IP白名单模板
3、GaiaDB
发布一键迁移功能,支持一键从RDS实例同步数据至新的GaiaDB集群
新增独享型和通用型计算节点规格以及88核等超大规格
优化体验,支持在创建普通账号的过程中,同时针对该账号进行相应的数据库授权操作
优化购买页,支持当默认VPC无可用子网时,预置子网并创建集群
4、Redis
Redis内存型7.2版本内核支持多线程
Redis内存型支持按时间点恢复数据
Redis内存型支持清理过期key数据
Redis内存型支持大版本升级
Redis容量型存储支持本地盘
5、DBSC
数据开发新增支持PostgreSQL、VectorDB、MongoDB、PegaDB数据库
诊断优化新增支持PostgreSQL、MongoDB、SQL Server数据库
安全审计新增支持PostgreSQL数据库
MySQL新增支持异常诊断、数据库巡检功能
GaiaDB新增支持异常诊断功能
6、DTS
支持Milvus->VectorDB
支持MySQL->OceanBase
支持PostgreSQL间数据一致性校验
7、RDS
PG支持自动备份(设置备份策略)
SQLServer支持数据库粒度备份下载
PG支持热活实例组
PG支持参数模版
PG支持暂停实例
MySQL支持大版本升级(5.6->5.7;5.7->8.0)
MySQL支持安全组管理
MySQL支持闪回查询
MySQL支持云盘转本地盘
1、云数据库MySQL
新增通用型实例,CPU轻微复用资源价格更低
新增本地盘实例自定义存储空间,支持对磁盘空间更细粒度调整
2、云数据库PostgreSQL
新增存储类型云盘
新增账号管理,控制台可视化操作账号和权限管理
新增库管理,控制台可视化操作数据库增删改查
3、分布式数据库TiDB
新增数据库审计功能,增强数据库安全性
4、分析型云数据库ClickHouse
新增错误日志功能
5、数据库自治服务SmartDBA
新增MariaDB实例性能分析能力
6、数据传输服务DTS
新增设置标签资源组,简化实例批量管理
新增MySQL到MySQL的快速数据校验
2025上半年,火山引擎多款数据库产品发布了新版本和新功能,其中值得关注的版本及功能有:
1、缓存数据库Redis版
数据容灾与备份增强。新增跨地域备份功能,支持通过OpenAPI设置或修改跨地域备份策略,可在指定地域直接恢复数据至新实例。
内核能力扩展。新增自研Proxy命令(如ISCAN、IMONITOR等)及扩展数据结构(ExString、ExTimeSeries)。
精细化连接管理。支持连接级读写分离策略(clientsetopt read_priority);支持升级域名后缀,升级后域名后缀自动集成地域标识,且支持跨地域解析;开放公网访问端口自定义能力。
运维管控强化。大Key分析新增Stream类型支持,非String类型的Key支持内存估算;RDB分析覆盖Stream、Function、Lua类型数据。支持取消用户触发的计划内事件;白名单纳入项目资源体系,实现权限统一管控。
灵活参数管理。新增TransactionSplit参数;支持控制台直接修改appendonly-switch参数来启停AOF;支持参数模板导出为TXT文件,便于快速复用。
监控与告警体系升级。节点监控页新增单命令级QPS监控;监控数据OpenAPI接口支持消费更多类型监控指标;新增只读节点故障摘流(ReadOnlyNodeDrop)事件告警。
实例与安全增强。新建实例支持免密访问及参数模板预配置。未启用分片集群实例新增支持512MiB小规格实例;提升Lua脚本Key参数上限至1,000;扩展密码字符长度。
Redis企业版内核版本升级。默认使用的数据库内核版本由7.2升级至7.4,支持了更多命令,可以兼容社区版7.0、7.1、7.2及6.x版本。
2、云数据库MySQL版
提供新的实例类型——多节点实例。多节点实例采用一主多备的集群架构,支持自动故障切换和手动切换。备节点可访问,最多可扩展至8个备节点以实现读能力的扩展。
最大支持8T存储空间,对于本地盘实例,支持为实例配置最大8T的存储空间。
支持极速恢复。在恢复数据至原实例和批量回档场景下,支持极速恢复,加速恢复任务,提升整体恢复效率。
新增事务拆分功能。支持将一个事务中的请求进行拆分,将第一个写请求之前的读请求路由到只读节点,减小主节点的负载。
支持Sequence Engine,用于在实例中获取唯一递增序列值。
支持闪回查询,仅通过简单的SQL语句即可在MySQL 8.0实例中查询误操作前的历史数据。
支持Statement outline,可将SQL的执行计划与SQL查询模板绑定,用户无需修改SQL即可固化查询计划,避免SQL的执行计划发生非预期变化而造成稳定性风险。
3、文档数据库MongoDB版
文档数据库MongoDB版灰度发布MongoDB 7.0版本,MongoDB 7.0版本支持副本集和分片集群两种实例架构,在慢查询日志、serverStatus输出扩展等可观测性与诊断能力,以及分片元数据诊断、数据迁移监控精细化等分片集群运维方面均有增强。
参数管理优化。新增oplogMinRetentionHours参数,动态控制节点级Oplog保留窗口;调整transactionLifetimeLimitSeconds参数上限,规避事务内存膨胀风险
运维管控增强。支持Oplog保留窗过小的事件监控告警;支持更多监控指标;支持在事件中心查看恢复新实例相关操作事件中新实例和原实例的信息。
实例生命周期管理灵活化。支持包年包月实例转为按量计费实例;支持原实例一次恢复到多个新实例;优化实例列表页的搜索功能;支持设置默认白名单;批量创建实例时支持自动生成有序名称。
4、云数据库PostgreSQL版
支持为指定数据库创建逻辑备份,并支持下载逻辑备份到本地。
支持从逻辑备份将数据恢复到现有实例。
支持创建PostgreSQL 17实例。
支持插件:pg_partman、pg_jobmon、pg_bigm、pg_ivm、pg_hint_plan 和 pg_profile。
5、云搜索服务
支持更多产品版本和存储类型。新增支持ES 6.8.23版本和ESSD-TL0存储类型。
AI生态功能优化。ML服务更名为AI搜索,模型管理中预置豆包大模型,创建推理服务时可以直接关联豆包大模型;推理服务详情页增加调用示例。
数据面功能增强。OpenSearch 2.9.0版本支持数据面审计;数据节点支持选择一个或多个节点进行重启。
6、向量数据库Milvus版
正式发布向量数据库Milvus版,在北京地域开放免费邀测。火山引擎向量数据库Milvus版集成开源Milvus,在云上提供托管形态。当前邀测版本支持例如实例生命周期管理、备份恢复、监控报警等一系列运维服务能力。
注:关于火山引擎更多数据库产品更新的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
2024年度Newsletter回顾&下载
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时序数据库、大数据生态圈、国产数据库、云数据库等几个版块。
我们不以商业宣传为目的,不接受商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎监督指正。
下期Newsletter计划时间是2025年12月22日~12月31日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后:
欢迎提供Newsletter信息,
发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,
发送至邮箱:editor@dbaplus.cn
↓ 点击下载本期完整版(提取码:2507)
https://pan.baidu.com/s/1JYJsEoCq4r2o0kOSDXOWkw?pwd=2507#list/path=%2F








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721