
作者介绍
cd,携程资深后端开发工程师,度假商品系统研发,专注于后端系统性能提升。
在携程旅游度假的线路类商品系统中,由于商品结构复杂,涉及底层数据表上千张,在日常供应商以及业务维护过程中,每日产生6亿+的数据变动记录。这些数据的变动留痕,不但可供录入方查看,也对日常产研的排障起着至关重要的作用,同时也可以提供给BI做数据进一步分析。商品日志系统建设尤为重要,随着商品日志系统不断发展迭代,已经积累达到1700亿条日志。
本文将介绍线路商品日志系统的演进过程以及在其中遇到的问题。
一、发展轨迹
二、演进过程
V1.0 DB单表存储
V2.0 平台化
V3.0赋能
三、结语
一、发展轨迹
线路商品日志系统的发展大致可以分为以下三个阶段:
2019年以前:单表日志
在 2019 年以前,商品系统尚无统一的日志系统来记录商品的变更,在系统中使用DB日志表,该表以非结构化的方式记录商品基本信息的变动。
2020年~2022年:平台化
在系统改造过程中,建立统一的商品系统日志平台,通过配置的方式记录商品的数据变动日志,覆盖商品维护的全部流程。
2023年~2024年:开放
经过在线路商品系统的实践,商品系统日志平台经历百亿级数据的考验,并以灵活的配置方式记录数据变动日志,同时支持自定义索引字段,具有接入和使用成本较低的优势。为此,通过对商品系统日志进行改造,逐步向门票、用车等业务线开放使用。
二、演进过程
V1.0 DB单表存储
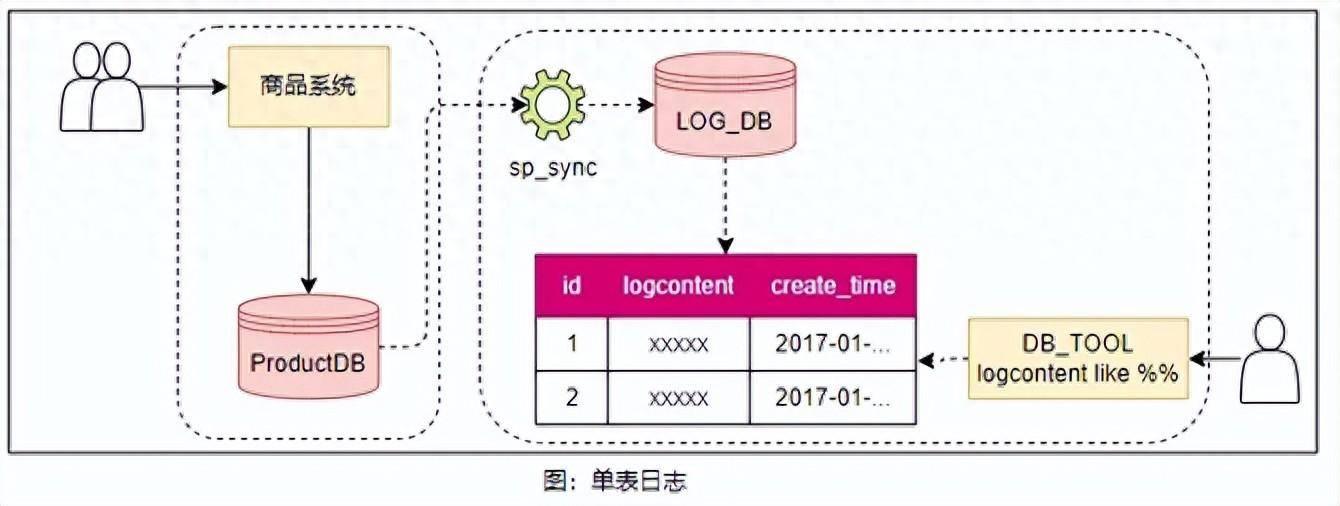
在2019年以前,记录线路商品的变动日志较为简单,在DB中建立一张日志表(id,LogContent)来记录日志,数据变动以非结构化的文本记录在LogContent字段内,且仅覆盖商品最基本的信息,在使用时通过数据库查询工具执行sql语句like关键字进行查询,这种方式带来的问题也显而易见:
数据量大,性能低
由于是单表文本字段存储,导致表的数量非常巨大,达到单表10亿+(370GB)的数据,查询超时问题严重,不得不进行定期归档。
可读性差,仅开发人员使用
由于日志内容以文本字段存储,在进行日志查询时,一般由开发人员使用 like 语句直接查询 DB,例如:select id, LogContent from log where LogContent like '%1234%'。查询速度缓慢,严重影响日常排障流程。
扩展性差
由于日志写入与业务代码强耦合,且采用非结构化存储。对于新增日志,需要对业务代码进行改动,在接入时存在一定的成本,且接入后无法直接提供给供应商或业务人员直接使用,最终仍需要开发人员进行查询转换。
V2.0 平台化
1、技术选型
针对 V1.0 遇到的问题,重点在于海量日志数据的存储与查询,业内解决海量日志数据存储与查询的方案一般有以下几个:
ES+Hbase
HBase 提供高并发的随机写和支持实时查询,是构建在 HDFS 基础上的 NoSql 数据库,适用于海量日志数据的存储,可支持到 PB 级别的数据存储。但其查询能力有所欠缺,支持 RowKey 快速查询,若有复杂查询则需要自建索引。ES 提供强大的搜索能力,支持各种复杂的查询条件,适合快速检索及灵活查询的场景。ES + HBase 的组合,利用各个组件的优势,结合起来解决海量日志数据存储及查询的问题,但架构较为复杂,需要保证两个组件间数据的一致性。
MongoDB
支持多种查询,具有文档型及嵌套的数据结构,但其支持的数据量级一般在 10 亿级别,对比 HBase 要欠缺得多。如果想要处理 TB 级以上的数据量,需要进行适当的架构设计和优化,例如利用分片集群来水平扩展数据等,付出的成本会比较高。
ClickHouse
Clickhouse 是一个开源的列式数据库,采用列存储的数据组织方式,具有高性能、可伸缩性、容错性和低延迟查询等特点。查询性能出色,可实现秒级甚至毫秒级的查询性能,对于数据压缩和存储效率高,可节省成本。适用于海量数据的存储及查询场景。
通过对以上方案进行对比,我们的数据量级已经超过 MongoDB 一般的处理能力,因此该方案被淘汰。对比 ES + HBase 与 ClickHouse,这两个方案都比较适合海量日志的存储与查询,但是受限于内部成本控制,CK 集群的日志保存时长被控制在一定天数内,无法满足我们业务场景的需求。最终,我们选择 ES + HBase 的方案。
2、整体架构
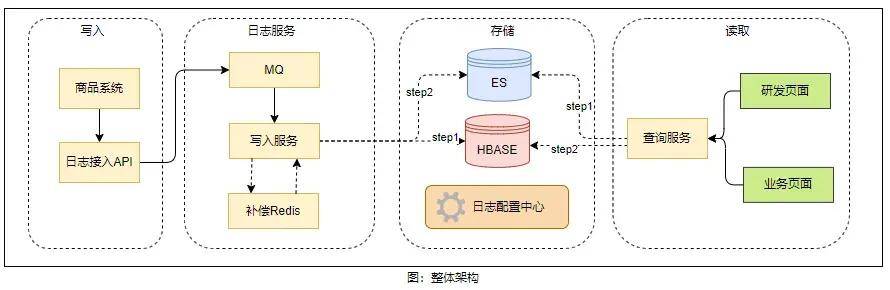
基本原理即利用 HBase 解决存储问题,利用 ES 解决搜索问题,并将 ES 的 DocID 与 HBase 的 RowKey 关联起来。通过发挥各个组件的优势,相互结合解决海量日志的存储与查询问题。如上图所示,在接入日志 API 后,所有日志均经过 MQ 进行异步处理,如此既能够将日志写入与业务代码的逻辑解耦,又能确保写入速度的平稳,避免高峰流量对整个 ES + HBase 集群的写入造成压力。
3、RowKey设计
RowKey设计原则:
唯一性:RowKey应保证每行数据的唯一性;
散列性:数据均匀分布,避免热点数据产生;
顺序性:可以提高查询性能;
简洁性:减少存储空间及提高查询性能;
可读性:以便人工查询及理解;
对于线路商品日志,对于直接可读性要求不高,查询的场景我们是从ES中先查出RowKey,再用RowKey去hbase查询日志原文,整个过程RowKey是人工不可见的,结合我们实际的场景,线路商品数据日志的RowKey由五部分构成{0}-{1}-{2}-{3}-{4}
{0}:传入的pk 转换为md5[pk]值16进制字符串,取前8为
{1}:tableId补0至8位
{2}:pk+4位随机值补0至24位
{3}:log类型补0至16位
{4}:时间戳

4、扩展
对于线路商品信息的维护分散于不同的模块中,例如录入模块、直连模块等。鉴于此,我们抽象出统一的数据写入服务,并提供统一的日志接入 API,API内部异步写入日志。在底层的数据写入服务中,将所有的写入操作接入日志 API。通过这个方式,将扩展性统一到日志配置中心。
写入流程
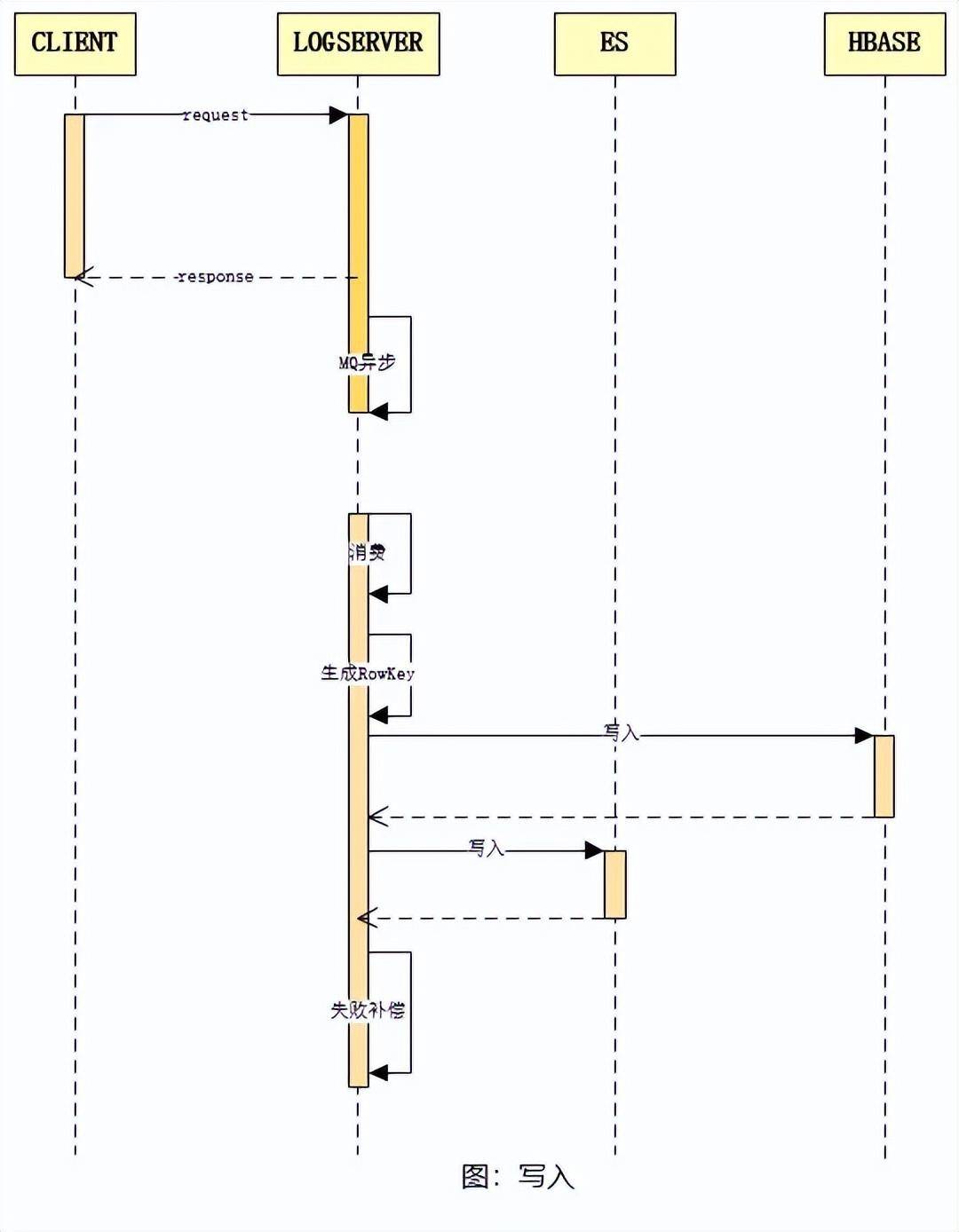
日志的写入流程如上图所示,客户端调用日志 API 以进行数据变动日志的写入操作。日志服务在接收到请求后,将其抛入 MQ,由后续的消费组进行消费处理。消费组件在接收到消息后,会进行相应的消费处理,并根据上述的RowKey生成策略为该条日志生成 RowKey,随后将日志文本内容写入 HBase,在写入成功之后,再将索引数据写入到 ES。其中,若 HBase 或 ES 中的任何一个写入失败,都会将此条日志写入补偿 redis 集群,再由补偿逻辑进行后续补偿,以确保整个日志的写入成功。
查询流程
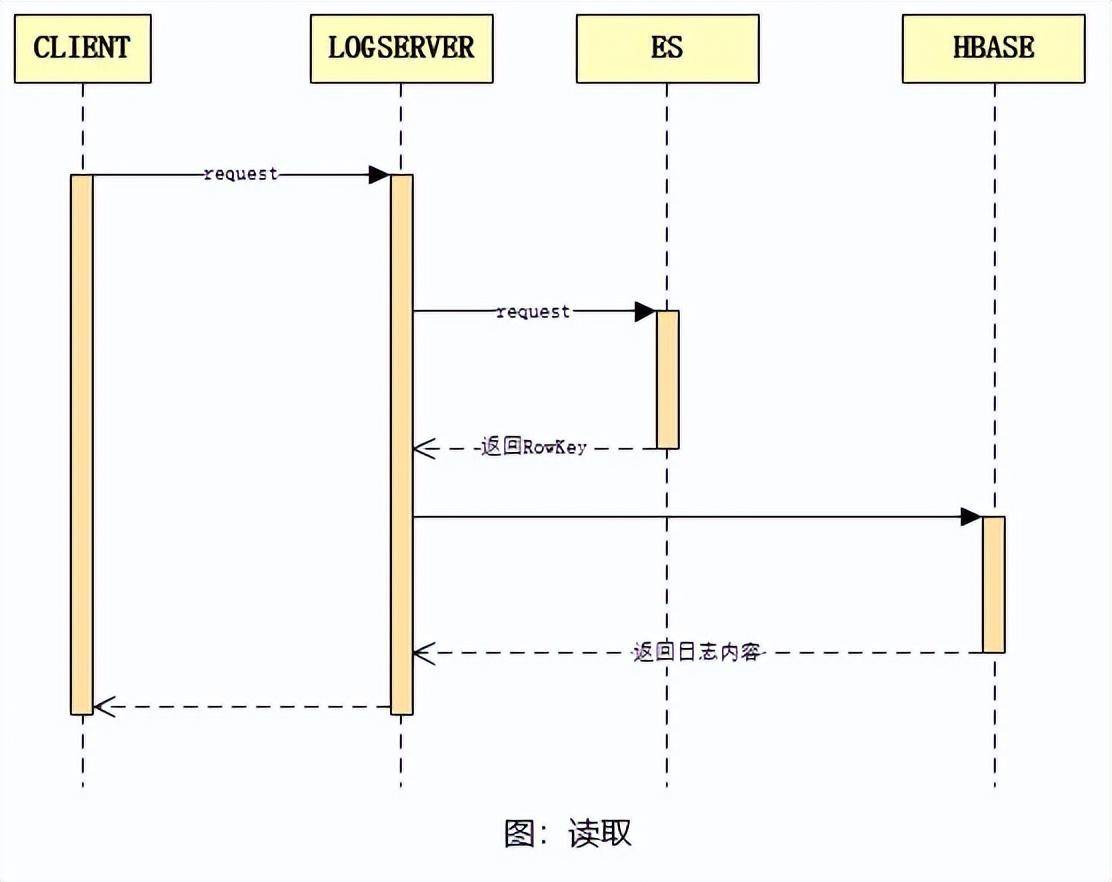
日志的查询流程如上图所示:客户端调用查询 API 并传入查询参数,日志服务接收到请求参数后,将其转换为 ES 分页查询请求,从 ES 集群中查出 RowKey,再汇总 RowKey 并从 HBase 中批量查出日志全文内容。
此外,我们利用上述查询 API,建立一个日志查询页面,供研发人员使用。在该页面,相关开发人员可以便捷地进行数据变动日志的查询。上述日志平台的建立,相对完美地解决线路商品海量数据变动日志的存储及查询问题。同时,抽象日志的配置中心,解决一定的扩展性问题。
整个系统的优点在于:基于表级别日志的商品日志记录,覆盖全面,配置灵活,索引结构化存储,支持海量日志数据的存储及查询。
缺点是:对于使用方而言存在一定的局限性,过于“技术化”,开发人员使用较为方便,但供应商与业务人员使用困难。
V3.0赋能
1、业务赋能
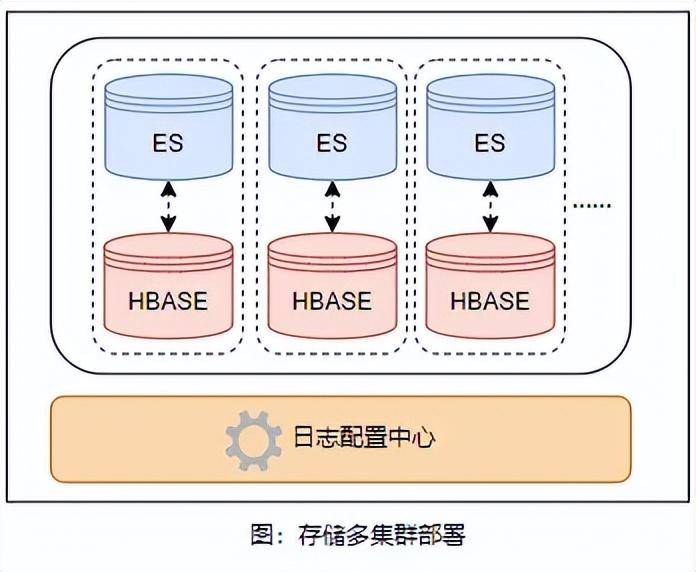
存储能力
随着日志写入量的增加,日志查询效率逐渐下降,对 ES 和 HBase 的拆分势在必行。如下图所示,我们对 ES 和 HBase 进行横向的拆分与扩容,并在日志配置中心制定匹配规则,根据接入日志类型的不同,将其匹配到不同的集群进行写入。此外,对于接入方,我们也支持独立集群申请,使用方可以根据自身情况决定是使用独立的集群部署,还是使用公用集群。
搜索能力
搜索能力的提升主要由以下两个部分:
索引字段扩展:支持的索引字段更多。前期我们绝大部分场景的日志的索引条件是产品id或者资源ID,随着接入的日志变多,索引字段也变的丰富起来。对于日志搜索场景我们进行梳理,预留10个可支持不同查询的索引字段(其中四个数值型、4个字符型,2个日期型)供使用方使用,覆盖绝大多数的查询场景。

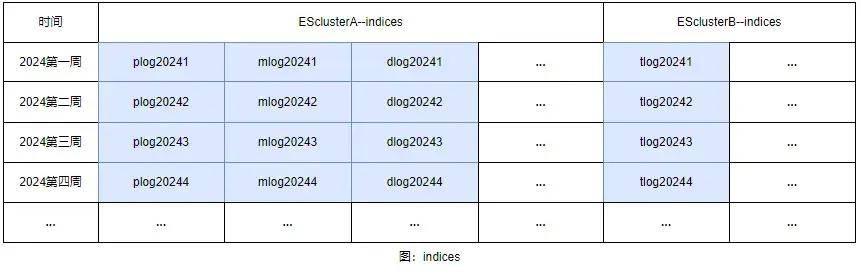
ES索引分区:随着接入的日志增多,单个索引文件也愈发庞大,直接影响日志的查询性能。一般而言,对于日志类型数据,常见的方案是依据时间建立索引,该方案的优势如下:
1)提升查询性能。若日志携带时间范围进行查询,则可仅搜索特定时间段的索引,避免全量索引的查询开销。
2)便于数据管理。可以按照时间删除旧的索引,从而节省存储空间。
通过对日志进行分类,主要包括商品信息、开关班、价格库存等模块。随后结合业务使用场景、每天产生的增量数据以及服务器资源进行评估,最终决定按周建立索引,且索引数据保留一年。
1)利用定时任务在每周一时创建下一周的索引;
2)利用定时任务每周删除已过期的索引;
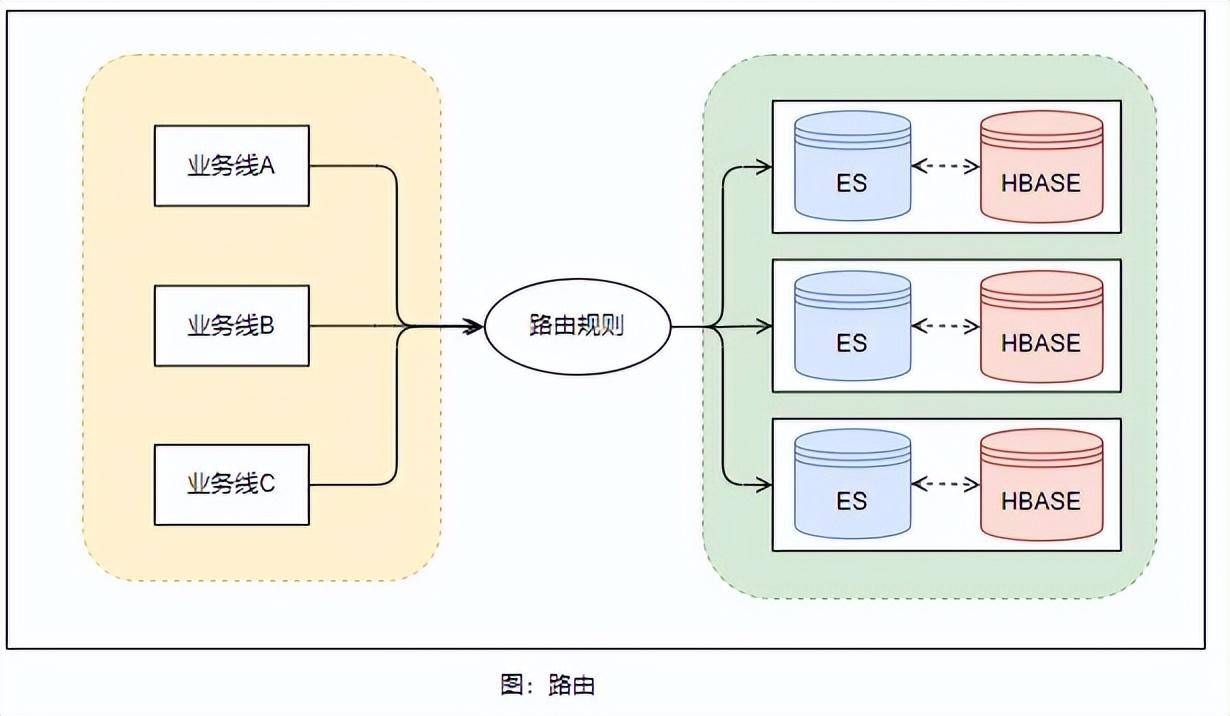
基于以上存储能力与搜索能力的扩展提升之后,我们在日志配置中心定制了【业务线<-->日志集群】的路由规则,来决定接入的其它业务线日志最终存储的日志集群,提供了更加灵活与具有弹性的业务线接入能力。
2、供应商赋能
展示能力
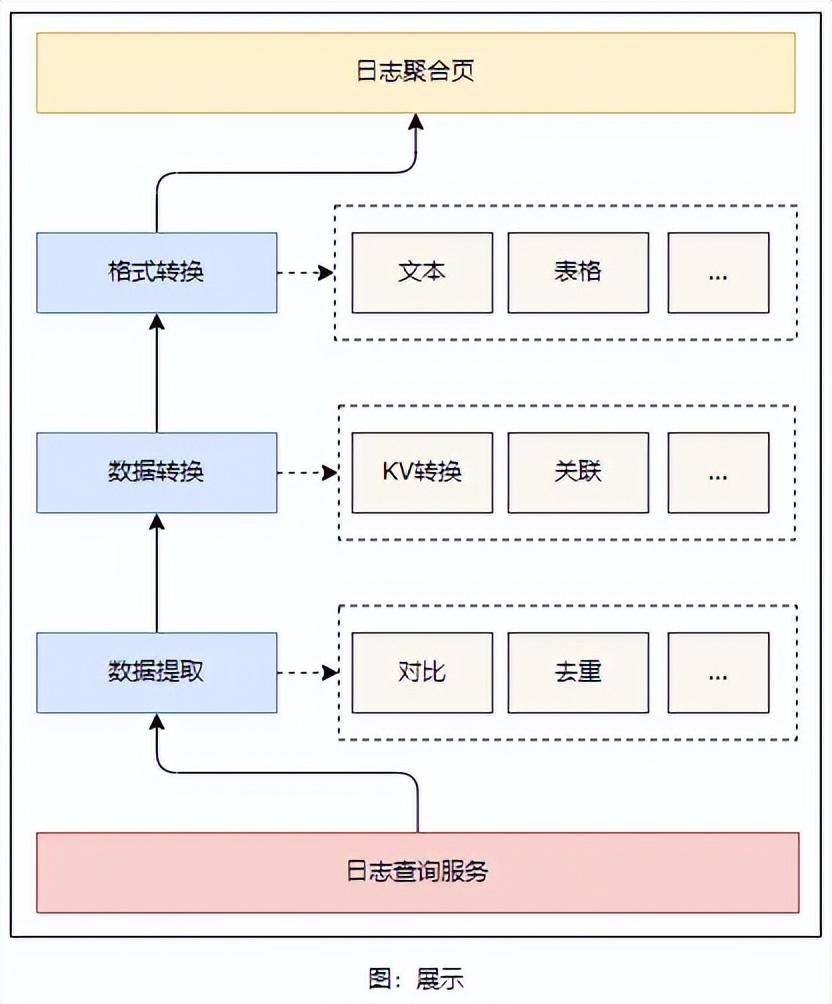
在 V2.0 版本中,日志页面仅限于研发人员使用,底层数据过于技术化,业务与供应商难以理解。通常情况下,如果能将日志的查询前置到供应商及业务环节,将极大地减少研发人员平时工作中的排障时间。
为此,我们提供 B 端的日志查询页面,给供应商及业务人员平时排查问题使用。我们对日志内容进行格式化的转换处理,将其转换为供应商和业务人员能够理解的信息,包括行转列、新旧对比、KV 转换、关联数据查询等。日志内容不再是抽象的文本,而是展示为与平时使用的商品系统相对应的内容。这对业务和供应商更加友好。
扩展能力
基于上一步展示能力的提升,对于新接入的日志如何能快速为业务及供应商提供 B 端的页面进行查看,这一步将大幅节省开发排查时间。对底层日志数据需要转换为业务及供应商能看懂的信息的场景进行分析,并总结 7 种数据展示的方式,分别如下:
1)文本字段类:此种展示内容最为简易,无需进行转换,用户可直接理解日志记录的内容,前端展示的即为此内容。

2)数据关联类:此类日志内容中记录的是一个 id,但实际内容存在于另一个关联表的数据中,例如 id:1 表示的是跟团游,不能将 id:1 的日志展示给用户,而需转换为“跟团游”,这就需要进行一步关联 db 表的查询转换。
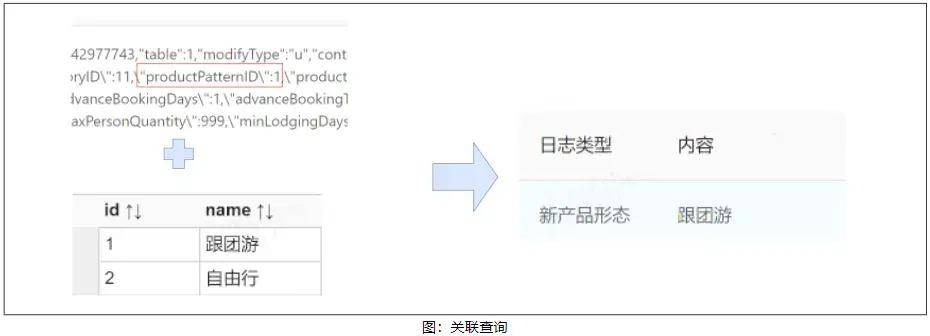
3)枚举类:此类日志内容记录的是一个 key 值,实际用户能理解的是该 key 值所代表的含义,例如产品钻级:0,就需要转换为:“不分级”,这就需要关联枚举值的配置文件进行查询转换。

4)位存储类:此类日志内容记录的是一种计算后的结果数值。例如支付方式是通过按位与计算然后累加的结果。这种情况就需要按照一定的计算方式将其还原回去。

5)字段组合:此类日志记录的是分散的数据,但实际需要将数据结合在一起查看才会更具业务意义,例如资源适用人档,日志中分为最大、最小记录。实际展示时需要结合到一起展示范围。

6)外部接口:此类日志记录的是一种依赖外部接口的值,例如日志记录的是城市 id:2,代表的是上海,这就需要调用外部接口将 2 转换为上海。

7)差异对比类:此类日志需对结果进行解析以作对比,从而使用户能够更为直观地理解。通常存在两种情形:其一,日志内容所记录的即为两份对比数据,此种情况仅需依循规则予以解析即可;其二,若日志数据属于当次的快照数据,则需与前一次快照数据进行对比,以找出差异。最终达成如下图所示的展示效果。

针对以上这些日志解析的场景,我们最终构建一个日志转换配置。对于新加入的日志,在绝大多数场景下,我们只需修改底层的数据提取及转换配置,便可较为快速的配置出日志查询页面,提供给供应商使用。
三、结语
本文详细介绍度假商品日志平台的演进历程,以及在各个阶段遇到的问题及解决方案。在整个演进过程中,针对海量日志数据存储与搜索的技术挑战,我们采取一系列措施,实现千亿级数据查询在 500ms 内的响应。
同时将日志系统开放,将问题查询解决前置到供应商及业务人员,极大降低一些数据变动查询需求的复杂度,减轻研发及TS同事重复性的工作。此外,我们还对日志平台进行横向的扩容配置,以支持更多的业务线可以接入。截至目前,多个业务线总数据存储量达到千亿级别。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721