
在刚过去的一个月,社群里都有过哪些被热议的技术问题?又踊跃出了哪些活跃的身影?11月之初,小编对过去一个月各微信群中提出的问题及群内专家和群友的解答进行择优筛选,整理成文,供大家一起学习。
同时,对于能切实解决到大家疑难的小伙伴们,我们将送出好书一本!具体获赠名单和领取方式已在文末等候多时,大家记得来领哦~
DBA+最话题·第二期
来自【DBA+DB2用户群】
黄海:SQL语句执行很慢,请大家帮帮忙。下面是问题详情:
SQL执行慢,去掉for update with rs后就正常http://www.db2china.net/Question/80551。
1、 SQL
select * from Wf_Task where ActivityPOID='A86468F97F00000123781AR2UCUJ89PG' for update with RS
返回记录500条左右。
2、 现象
2.1) 应用部署在WAS上,与数据库不是同一台服务器,执行该SQL时,平均需要9s。
2.2) 然后在本地通过dbVisualizer工具执行该SQL,平均需要9s。
2.3) 在数据库服务器上执行该SQL,平均耗时100ms左右。
2.4) 在本地通过dbVisualizer工具执行该SQL,如果去掉for update with rs,执行耗时100ms左右。
2.5) 在与该服务器相似的数据库服务器上执行该SQL,不管是WAS、本地,执行耗时平均100ms。
3、 解决过程
结合2.1、2.2,怀疑是网络传输耗时过长,就在数据库服务器本地执行该SQL,耗时结果如2.3所示:100ms。
但结合2.4,又能够判断出不是网络影响。
4、 分析材料
1db2exfmt.txt是该SQL语句的访问计划
1db2batch.txt是该SQL语句的执行时间分布
1mon_get_pkg_cache_stmt.xls是用表函数mon_get_pkg_cache_stmt描述的该SQL语句的执行时间分布。
hw.dbcfg.txt是问题SQL所在数据库的数据库参数。
hk.dbcfg.txt是相似数据库的数据库参数(SQL不管用哪种方式在该服务器上执行只需要100ms左右)
现在金额出现问题了,100减了两次30,还是70,用该方法可以解决。部署后,3个环境,境内、港行是运行很好,海外运行都在9秒左右。都是在测试环境,现在在解决这个问题。
翔宇(wxy_35):一般情况下,加上rs都是业务需求,如果说去掉rs速度就快,应该就是锁的问题。你去看看,执行9s的时候,db2top里面这个sql是不是真的一直在跑。可以通过这个来分析一下,rs情况下真实的执行时间。
杨小华:可以用db2top观察一下,如果在数据库服务器上就花了九秒,这个窗口足以在db2top里面查看到这条SQL以及锁的情况了。
翔宇(wxy_35):你现在这个观察到的情况,有矛盾的情况。还是先确认9s的情况,DB2是否真的跑了9s。
黄海:就是矛盾点太多。
开心小k:@黄海 看下快照,做两个batch看看差异,看时间花费在哪。
黄海:使用db2batch -d dbname -f 1.sql -i complete -o r -1 f -1 p 5 -car cc -iso rs -r 1db2batch.txt获取了执行时间分布。
* Prepare Time is: 0.000338 seconds
* Execute Time is: 0.000058 seconds
* Fetch Time is: 0.060426 seconds
* Elapsed Time is: 0.060822 seconds (complete)
洪烨:9s那个场景复现吗?抓个applicaiton的快照看看是不是时间是不是消耗在数据库里?
天涯(andrewdi):看下执行计划是不是没走索引?
开心小k:慢的那个呢?
黄海:编译、执行、fetch都很快。9s那个场景,只要是走WAS和本地dbVisualizer工具,是每次都如此。在服务器上就是上面的很快的结果。
杨小华:这个SQL单独跑的?跑的时候有别的应用同时跑吗?
天涯(andrewdi):这个如果是锁等待的话,有并发的时候容易发现,命令行跑比较难。
黄海:目前发现在客户端执行时间都耗在fetch上了。在服务器上执行,fetch就没有什么耗时了。
杨小华:所以执行是没有问题的,问题在Fetch。
孔再华:把forupdate去了,直接with rs试试。
黄海:嗯,执行没问题。在WAS上和dbVisualizer上都慢,这样就是耗在fetch上了,去掉for update,执行10ms。
孔再华:with rs也没问题是吧?
黄海:去掉for update 或者去掉for update with rs,执行都是10ms。加上for update with rs,执行都是9秒。
洪烨:连续抓9个stack看看?
黄海:好的。
黄海:还有个问题啊,这样的语句:带for update with rs的,在其他两台服务器执行都是10ms,不管是本地还是中间件。
孔再华:嗯,这是游标读,估计是一条一条加锁并取到客户端的。看看stack是不是闲着等remotehost呢?
黄海:(经查明)SQL执行慢的原因是由于网络导致的,解决过程供各位参考。
(点击文末“阅读原文”,可获取该文件附录)
来自【DBA+北京1号群】
梁涛:遇到一个棘手的问题:
在用imp恢复数据,imp很慢,因为redolog太小 尝试加大的redo组,报错ORA-01156recovery or flashback in progress may need access to files
后台alert/smon一直报错ORACLE Instance dxtdb (pid =17) - Error 376 encountered while recovering transaction (375, 30) on object51799. drop这个对象51799以后,还是报错(五分钟一次)
shutdownimmediate,挂起因为有个active进程,发现是一个sqlplus,但serial#不断增加,并且kill的时候报错ORA-00030: User session ID does not exist. 原因是这个进程已经中断,trace文件显示pmon五分钟一次清理这个进程,每次都失败。[1011386.6]
有没有什么好办法, 比如怎么能加一个大的redo组, 或者怎么能kill那个无效的session? 这时候能不能shutdown abort?
忘忧草:redo增大,是先删除再添加一个size大的redo,先增加大 size的redo再删除旧的比较小的redo。
梁涛:是先增大,先增加,但报错ORA-01156。再问个问题,expdp或者crts怎么忽略offline的datafile?
忘忧草:expdp没有针对数据文件是否offline的参数,只有针对索引是否可用。
梁涛:找到办法了,用rowid区别一下就行。
Lastwinner:imp commit=y,这个可以不?
梁涛:不行。我开始只是想找个类似的event,来忽略offline的文件。就像忽略坏块一样。结果是没有的。现在算解决了, shutdown abort解决了问题3, 然后解决了问题1,然后使用rowid恢复数据,算解决了问题2。
来自【DBA+广州群】
Rock-联骏:请问有没有实现以下需求的工具介绍,谢谢!
现在我们的IT人员是通过SQLPLUS等tools直接connect DB操作的,听说现在市场上有一些类似Agent的工具,装上后,IT人员先要连接它才能连到DB,执行SQL命令时,也是通过它执行,而不是直接连DB执行。
即希望所有IT人员先连接到一台装有这个管理连接的软件的server,执行SQL操作,然后实际上是由这台server再连到oracle db server执行。
这样的好处是可以记录和管理连DB操作的client IP,执行过的命令等。不只是要审计功能,而是实现连接管理转发功能的。
Kamus:堡垒机可以实现。
Rock-联骏:请问有什么好介绍?
Kamus:堡垒机很多,齐治、帕拉迪,还有开源的Jumpserver。
来自【DBA+开源数据库1号群】
赵勇:有做过MySQL巡检的吗?巡检都巡检什么?
Q:我们绝大部分指标都在监控做了,定期巡检也就是看看达标数据量、自增值、主键、慢查询日志和各性能监控指标的趋势。
赵勇:什么监控软件?
Q:Zabbix。
段书峰:spotlight on MySQL。
赵勇:MySQLmtop,这个你们用过吗?
Q:没用过,不过我觉得什么监控工具不是最重要的,现在工具基本指标都有。关键要结合业务和公司整体的运维体系选。当然如果只是你自己看着那就选个用的顺手的就行。
来自【DBA+开源数据库1号群】
张玉亭:我在11g的数据库里面有一个全库备份,现在想把里面的一个用户导入一个10G的数据库,这件事可以吗?
天痕(liucjedward):exp imp。
张玉亭:嗯,用的就是imp。
心有所思:用dp可以指定数据库版本。
张玉亭:IMPDP ?
心有所思:先expdp再impdp,导出时加上version=10.*.*
张玉亭:还有个问题,我现在imp一直报错,我想停止,但是停不下来根本没反应怎么办?有什么快捷键吗?还是只能kill -9?
心有所思:kill吧。
来自【DAMS架构师2号群】
针对《一次SQL语句优化的反思:技术与业务脱离怎么解决?》一文。
司洋:案例中都是分区表查询返回数据量很大的情况:
第一种是db file sequential read等待事件,是单块读,速度比较慢。
第二种是direct path read等待事件,是多块读,速度会快一点。
分区表的设计:
先通过分区键(业务键 sbrx)过滤掉大部分的数据
再在sbrq上面建 global range partition或者是 local non-prefixed partition (这两个随便)
每次维护global的时候让dba操作,例如删除分区:
这样不会导致全局索引失效的问题。
个人觉得1000万的数据可以作为一个分区。
来自【DBA+鲁豫有约1号群】
堂堂同学:有哪位朋友知道这个是什么原因导致的吗?
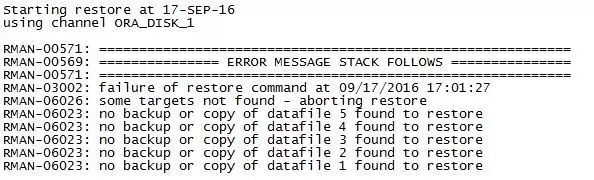
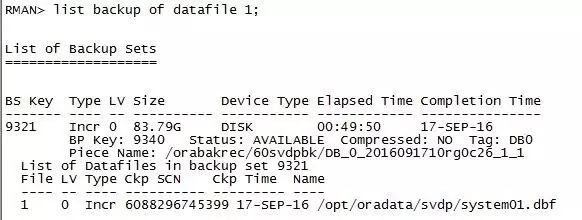
张庆增:尝试恢复下控制文件。
Sky:也可以restore时指定下备份文件。
堂堂同学:就是先恢复的控制文件。
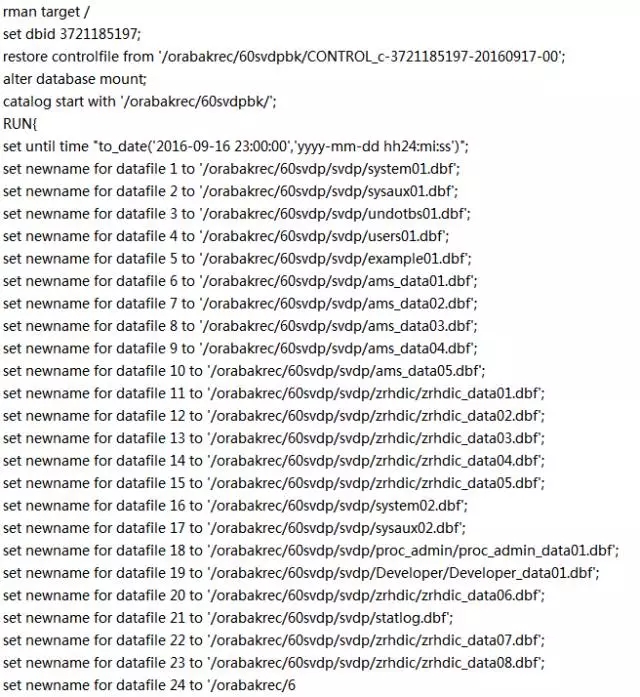
脚本如上。
为了让备份能够确实有效,我还做了:
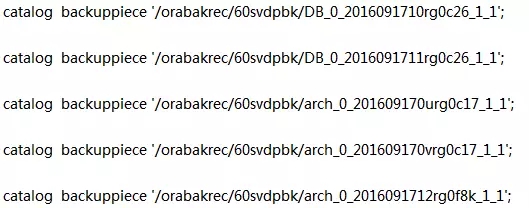
目前备份可以list到,但是恢复的时候就回报找不到的错误。
刘燕海:控制文件。
杨士贤:List到的信息都是从控制文件读取的,上面的命令一点点执行。
来自【DBA+DB2用户群】
Steve25:请教一下,SQL中使用like %与使用=的效率为什么有那么大的不同?使用同样的index,like要花不少的时间,而=则很快,一个160sec,一个less than 1 sec。
X-Man:=,范围定界索引运算符,直按读少数几块索引页。一次随机io及1次连续ioLike,触发全索引叶子节点扫描。1次随机io及多次连续io。
Steve25:多谢。是不是使用text search可以加快查询?好想有个contain函数!
X-Man:索引越大,效率差距越明显。
Steve25:是啊,差别确实大!即使用了index。
X-Man:textsearch没怎么研究过;如果索引列不是宽列,不建议用textsearch,textsearch应针对长、大文本字段。还要看那个like中%放的位置,如果放最后,效率比放前、中好多了。
来自【DBA+上海1号群】
花花:请问一下,有客户用sqlserver 2008 r2,因为性能低下,数据库特别慢,删除大部分老的业务数据,但是没有感觉速度明显提升,是不是删了之后数据库还要做一些处理?
卢艳明:删了后高水位索引重建统计信息收集,Oracle是这样。剩下的就是SQL的优化。
山寨DBA:查查索引是不是要,统计信息更新下,SQL语句和过程重编译下(如果数据量变更比较大,建议你直接清空所有缓存得了。
卢艳明:历史归档表能改造分区改成分区。
山寨DBA:分区,不切实际。
花花:统计信息更新是下面这个吗?清空缓存?
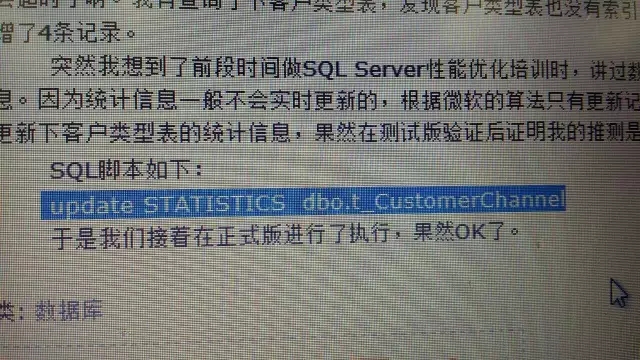
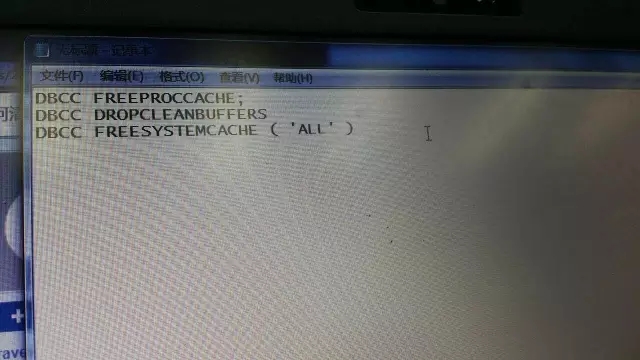
山寨DBA:是的。
来自【DBA+东北1号群】
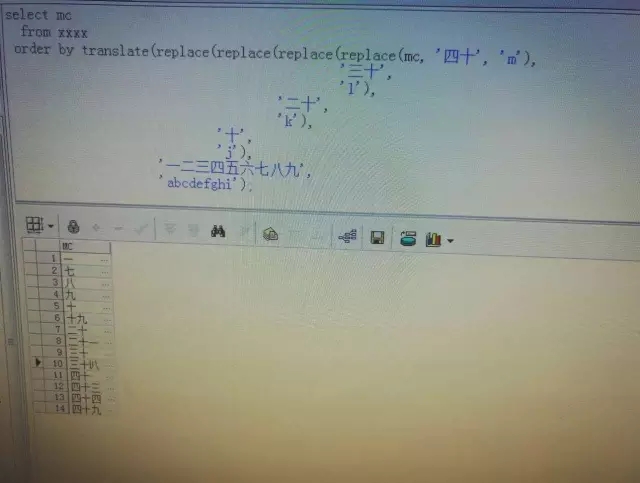
杨旭辉:一 二 三……四十五有没这样的按照数字大小排序的SQL?
于华君:生成数据?
消老师:挺麻烦的,试试translate函数。
杨旭辉:好多中文,中间夹杂这些中文数字。据说阿里巴巴的一个朋友是用Java实现的,也用SQL实现过。但SQL比较麻烦。
消老师:可以用translate试试,不过要处理数字十。
杨旭辉:translate里面第一个字符串要用replace替换,替换的话要嵌套好多……
selectMC from xxxx ORDER BY translate(replace(replace(mc,'十一','n'),‘十二’,'o'),'一二三四五六七八九十','cdefhijklm')
这样一直把十一到最后的大数一直替换下去……
selectMC from xxxx ORDER BY translate(replace(replace(replace(replace(mc,'十','h'),‘二十’,'i'),'三十','j'),'四十','k'),'一二三四五六七八九','abcdefg')
这样好像就行,你们觉得呢? 我没Oracle环境试验……
消老师:到百和千了咋整?
杨旭辉:哈哈,先以项目的心态来,反正数据没有再大的。有时间了再搞通用的……大家有没有简便通用的方法?
德德:最大有多大?
杨旭辉:我这儿只有四十多的数据,万一以后业务的数据更复杂呢?
德德:写个函数吧。一劳永逸。
杨旭辉:嗯,好的。
特别鸣谢 & 赠书名单

感谢所有提问和解答的群友与专家!经过筛选,以上11位小伙伴的问答最给力,均可获得本期送出的技术好书一本~请将你的姓名、地址和手机号回复至“dbaplus”订阅号,小编会尽快给你送上!
没上榜的小伙伴也不要失落,每月一期的【DBA+最话题】会持续奖励积极答疑解惑的你~如果其他群友对以上问题有更好的答案或建议,欢迎在本文微信订阅号(dbaplus)评论区留下你的真知灼见,在本周五(11月4日)中午12点前成为点赞数最多的前2名,同样可获得好书一本!
最后,特别鸣谢清华大学出版社为本次活动提供图书赞助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721