
如果你是一位后端工程师,你一定明白,从能写一手熟练的SQL,到能驾驭一个高并发、海量数据的系统,中间隔着一道巨大的鸿沟。这道鸿沟,就是“架构设计能力”。
在如今的面试中,尤其是高级岗位的面试,面试官早已不满足于考察你是否知道“索引为什么用B+树”。他们更想知道,当流量的洪水涌来时,你是否能筑起一道坚固的堤坝。
下面,我们就来完整拆解一个源自真实业务的高压面试场景。它不是孤立的知识点问答,而是一场对系统设计能力的终极考验。
场景降临:一个无法回避的挑战
想象一下,你走进面试室,在和面试官进行了简短的交流后,他抛出了这样一个问题:
“我们来聊个有挑战的场景。假设你来负责一个核心系统的数据库架构设计,这个系统有几个鲜明的特点:
业务:一个国民级App的计费日志系统,或者类似朋友圈的动态(Feed)流。
写入:压力极大,核心单表每天的新增数据会达到1亿条。
读取:同样惊人,高峰QPS预计会摸高到10万次/秒,读请求占绝对大头。
数据:典型的时序数据,持续增长,几乎没有更新和删除。查询维度通常是用户ID和时间范围。
很明显,单体MySQL在这里撑不过一天。现在,请你从数据库架构师的角度,给出一个完整的优化方案,并告诉我们,你为什么这么设计。”

这个问题一出,气氛立刻变得严肃起来。这不再是“纸上谈兵”,而是一场真刀真枪的架构攻防战。
关卡拆解:五大核心问题的深度拷问
一个经验丰富的面试官,会通过一系列追问,层层递进,探知你的技术深度。
“每天1亿的新增数据,单表扛不住是肯定的。要解决存储瓶颈,你是打算用分区表(Partitioning)还是水平分表(Sharding)?说说你的选择和理由。”
这个问题看似是二选一,实则是一道“送命题”。
一个优秀的回答应该毫不犹豫地选择水平分表(Sharding)。理由很简单:分区表本质上只是将一个大表的数据块按规则(如按月)存放在不同的物理文件中,但它所有的数据和索引依然在同一台服务器上。面对每天1亿、一年超365亿的增量,任何单机的磁盘I/O和容量都会被迅速打穿。分区表解决不了物理极限的问题,而水平分表,才是将数据和压力分散到不同服务器的“屠龙之术”。
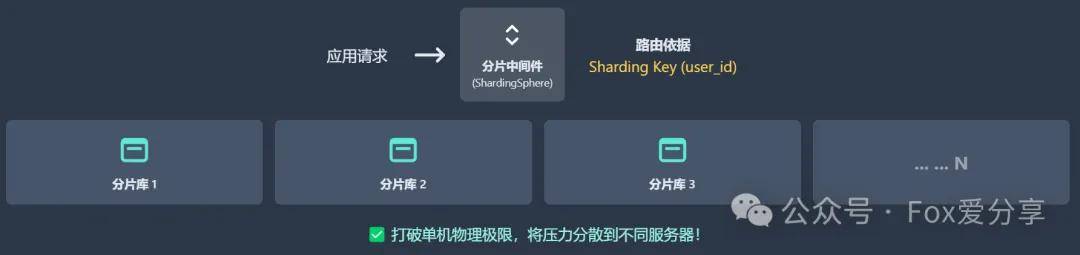
如果你能进一步指出分区表在超大数据量下,其元数据管理本身也会成为新的瓶颈,那无疑会是一个加分项。
“好,既然定了水平分表。那具体怎么做?分片键(Sharding Key)怎么选?大概要分多少个片?用客户端分片还是中间件分片?”
这个问题将考察点从“做什么”推向了“怎么做”,直击落地细节。
一个经得起推敲的回答需要包含以下几点:
1)分片键
紧扣“查询多基于用户ID”的线索,选择user_id作为分片键是顺理成章的。这能保证同一个用户的数据落在同一个库里,完美避免了代价高昂的跨库查询。更进一步,你还需要考虑到潜在的“数据倾斜”问题(如大V用户的数据量远超普通人),并给出初步的应对思路。
2)分片数量
这不是一个凭感觉的数字,而是一个需要量化估算的过程。可以这样推算:业界普遍认为MySQL单表在5000万到1亿行时性能较好。那么一年就需要(1亿/天 * 365天) / 5000万 ≈ 730个分片。考虑到业务增长和扩容的便利性,设计一个支持1024或2048个分片的方案会是更具前瞻性的选择。
3)架构选型
你需要清晰地对比两种主流方案的利弊。是选择在业务代码中集成的客户端分片(如Sharding-JDBC),它性能损耗小但与业务耦合;还是选择独立的中间件分片(如MyCAT),它对应用透明但增加了架构的复杂度和运维成本。这里的选择没有绝对的对错,关键在于你能否结合团队技术栈和业务发展阶段,给出合理的权衡。
“写入和存储解决了,但还有10万的读取QPS。数据库肯定扛不住,你打算怎么设计来支撑这么高的读取性能?”
这是对系统整体吞吐能力的核心拷问。
答案必然指向两大经典武器:读写分离和多级缓存。你的回答不应只是名词的堆砌,而应该是一幅清晰的流量走向图:
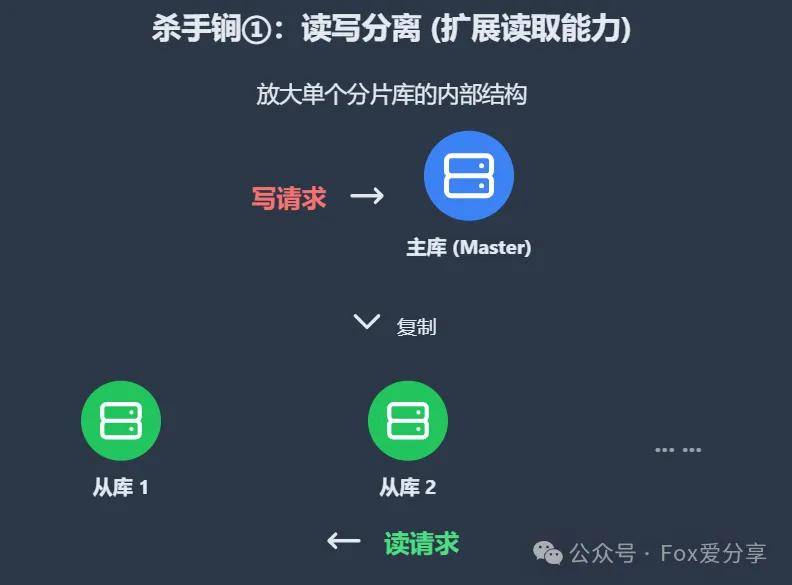
1)读写分离
在每一个分片库的内部,再构建一主多从(Master-Slave)的集群。写请求只打到主库,而海量的读请求则由多个从库来分担。从库不够?加!这是水平扩展读取能力最直接的手段。
2)多级缓存
这是抵挡10万QPS的第一道,也是最强大的防线。一个请求的旅程应该是这样的:
首先访问应用服务器的本地缓存(L1 Cache, 如Caffeine),速度最快。
若未命中,则访问分布式缓存集群(L2 Cache, 如Redis)。绝大部分的读请求应该在这里被终结。
只有当两级缓存全部“失守”,请求才被允许“穿透”到最后的数据库层。

“聊到缓存,就避不开一致性。当数据发生变更时,你如何确保缓存和数据库的数据一致?另外,如果出现某个大V用户被频繁访问,形成了热点,你的缓存架构要如何应对?”
如果说前面的问题考验的是广度,那么这个问题考验的就是深度。
1)一致性
你需要熟练地阐述Cache-Aside Pattern(旁路缓存)这个经典模式:读时,先读缓存,没有再读库,然后回写缓存;写时,先更新数据库,然后删除缓存。为什么是删除而不是更新?因为删除操作更轻量,且能避免复杂场景下的数据不一致。
2)热点难题
这几乎是所有高并发系统的“阿喀琉斯之踵”。你需要像一位经验丰富的老兵,准确地识别并拆解三大“敌人”:
缓存穿透(查不存在的数据):用布隆过滤器在入口处进行拦截。
缓存击穿(热点Key突然失效):用分布式锁,确保在缓存重建时,只有一个线程去请求数据库。
缓存雪崩(大量Key同时失效):通过给缓存过期时间增加随机值,打散失效时间点来避免。
“几年后,数据会达到PB级。那些3年前的日志,访问频率极低,但一直放在MySQL里成本很高。你会怎么处理这些冷数据?另外,万一业务需要加个字段,你怎么在这么多分片上做DDL操作?”
这个问题考察的是架构师的远见、成本意识和在“高速飞行的飞机上换引擎”的能力。
1)冷热分离
你需要展现出数据生命周期管理的思维。将超过一定期限(如一年)且访问频率极低的“冷数据”,从昂贵的MySQL集群中归档到成本更低的存储系统,如HBase、ClickHouse或是云厂商的对象存储(OSS/S3)。这既是为核心库“减负”,也是为公司“省钱”。

2)在线DDL
直接在分片大表上执行ALTER TABLE是一个灾难性的操作。你必须知道,这需要借助gh-ost或pt-online-schema-change这样的专业工具,通过创建“影子表”的方式,在不锁主表、不影响线上业务的前提下,完成平滑的表结构变更。

结语:从“答题者”到“架构师”
如果你能一路过关斩将,清晰且有条理地回答完以上所有问题,那么你所展示的,早已不是一个“代码实现者”的技能,而是一位优秀架构师所必备的全局视野、权衡能力和实战经验。
在技术的道路上,真正的成长,往往就体现在这些从点到面的思考跃迁中。而卓越的系统,也正是在对每一个“如果……”的深思熟虑中,被精心打磨出来的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721