
众所周知,Metrics指标数据是可观测重要的基石之一,在2021年底的时候,B站基于Prometheus+Thanos方案,完成了统一监控平台的落地。但随着B站业务迅猛发展,指标数据级也迎来了爆炸式增长,不仅给现有监控系统的稳定(可用性, 云上监控数据质量等)带来冲击,也无法满足公司层面可观测稳定性建设(1-5-10)目标。当前架构面临的痛点总结如下:
稳定性差:由于当时告警计算是基于Prometheus本地计算的,target监控实例在调度时,一个应用的所有实例必须要被同一个Prometheus采集,每当一些大应用发布时,pod name 等一些元数据指标label就会发生变化,重新构建timeseries 索引时,会占用大量内存,导致Prometheus oom。
用户查询体验差:频发的oom告警,经常导致数据断点,再加上Prometheus+Thanos 查询性能性能有限,经常出现面板查询慢/超时,open api查询失败,误告警等。
云上监控数据质量差:由于我们使用了许多不同厂商的云主机,即使同一厂商也有多个账号和不同地域,有自建可用区和云上可用区打通的,也有不打通的,有专线的,也有非专线的,网络拓扑复杂,经常出现因网络不通导致无监控数据。同时每个账号下都是一套独立的Prometheus采集,因此存在多个云监控数据源,用户很难选择需要的云数据源。
设计思路
采集存储分离:由于Prometheus是采集存储一体的,导致我们在target监控实例调度分发时,很难快速弹性扩缩,同时也不太容易调度到不同的采集节点。所以要实现采集存储分离的架构,target实例可以动态调度,采集器可以弹性扩缩。
存算分离:由于Prometheus也是存算一体的,但随着业务发展,指标数据量级和计算需求往往不是线性关系的,比如在存储资源增加不到一倍的情况,计算资源(查询需求)需要两倍以上,因此,如果按照存算一体的方式采购服务器资源,势必造成一些资源浪费。所以要实现存算分离的架构,在写入,存储和查询都可以分别进行弹性扩缩。
时序数据库选型:我们了解到VictoriaMetrics(以下简称VM)已经被越来越多的公司做为时序数据库,同时经过我们的调研,在写入&查询性能,分布式架构,VM运维效率都满足我们的需求。(关于VM一些选型优势,本文不在讨论,下文会有介绍对VM的一些查询优化)
单元化容灾:由于我们是大多数场景(95%)基于pull模式的,每个target监控实例需要按照一定的调度规则,分配到不同的采集器。但是之前没有一个标准,有的场景按照cluster维度调度,有的场景按照idc调度,有的按照instance name维度,导致指标数据无法做到从采集->传输->存储→查询 整个链路单元内闭环。因此,我们制定了一个新标准,全部按照zone维度调度,可实现同zone下,全链路单元内容灾。
基于以上核心的设计思路,设计了监控2.0架构。首先先看下整体的功能架构:
功能架构概览
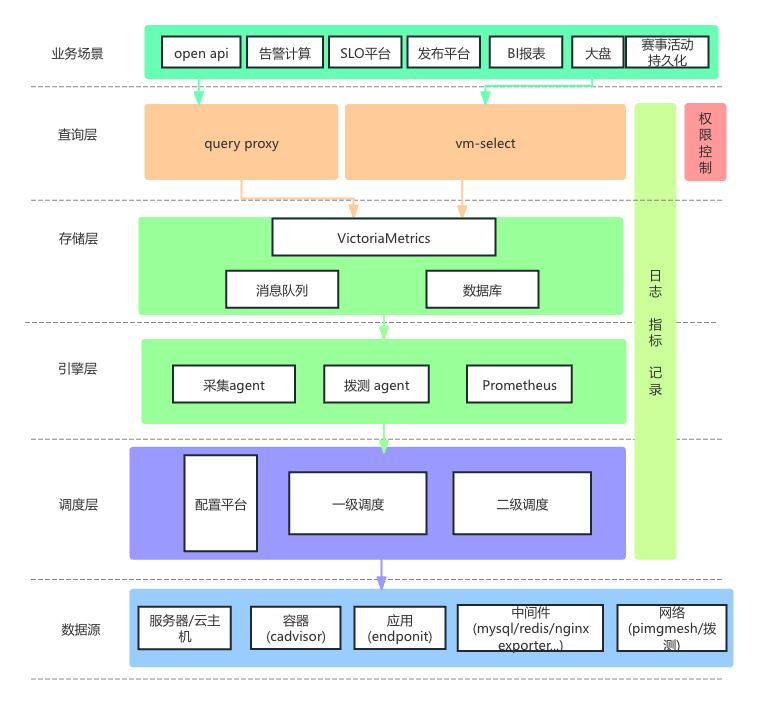
通过上面的功能架构图可以看出,Metrics 指标数据,不仅应用在大盘、告警等基础场景,一些业务场景、发布平台都会依赖指标数据,做一些流程决策。因此2.0架构的落地,存在以下几个方面的挑战:监控系统自身稳定性,数据可用性,查询性能,故障爆炸半径等。
整体架构
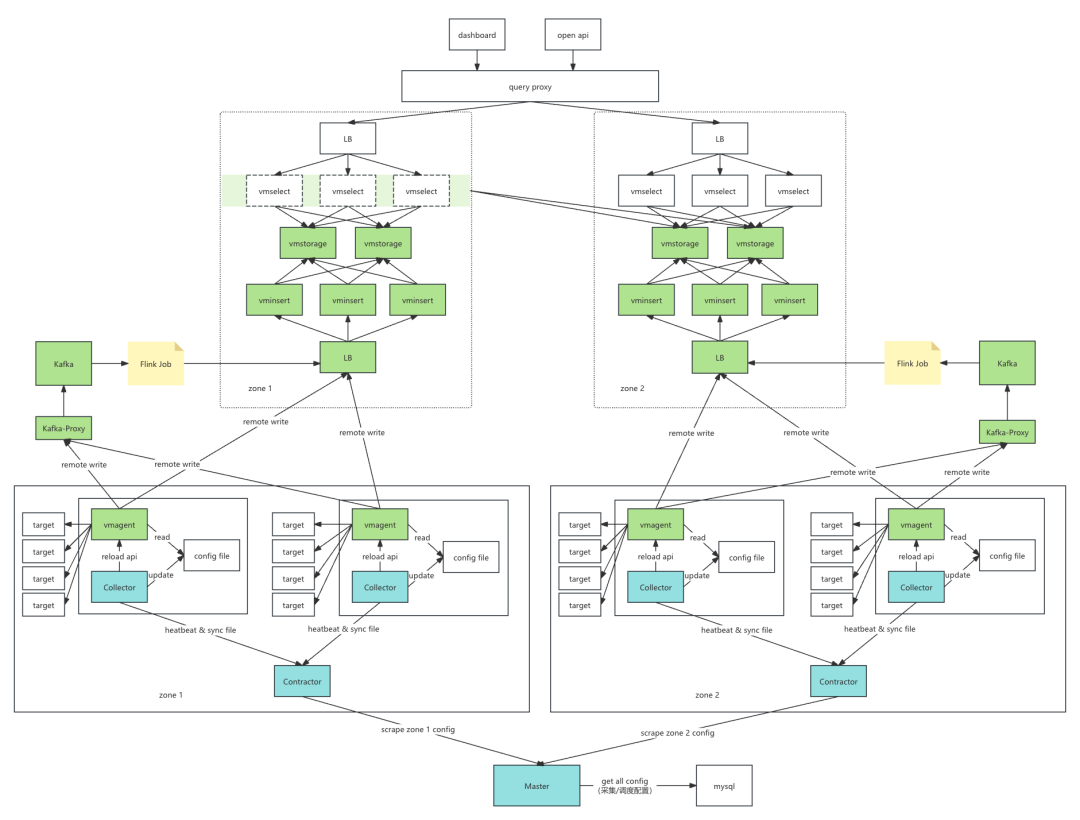
如上是整体的技术架构,下面重点从数据来源,数据采集,数据存储,和数据查询方面介绍:
1)数据来源
从大的分类来看,监控覆盖场景主要分为paas层(应用监控,在/离线组件和一些中间件监控)和iaas层(自建机房服务器/云主机,容器监控和网络监控)。由于之前是基于pull的方式发现target监控实例,主要存在两方面问题:
发现target监控实例存在延迟:因为pull的方式有一定的同步周期,比如30s, 当一个新的监控实例出现,需要30s才能发现,因此看监控指标要比预期晚30s。
运维成本较大:当pull 业务方提供的接口有问题时,业务方一般无法第一时间感知问题,需要我们去主动协同处理。
针对上面问题,我们将pull方式改成push方式,让业务方主动push 需要被监控的target实例。这样可以实时的push,解决因pull 方式存在的30s延迟,同时,为了让各个业务方更方面的管理target实例,在指标平台提供按集成任务申请监控接入,并且实时显示target实例采集状态,采集数量和采集耗时,进一步提升监控接入状态的可见性。
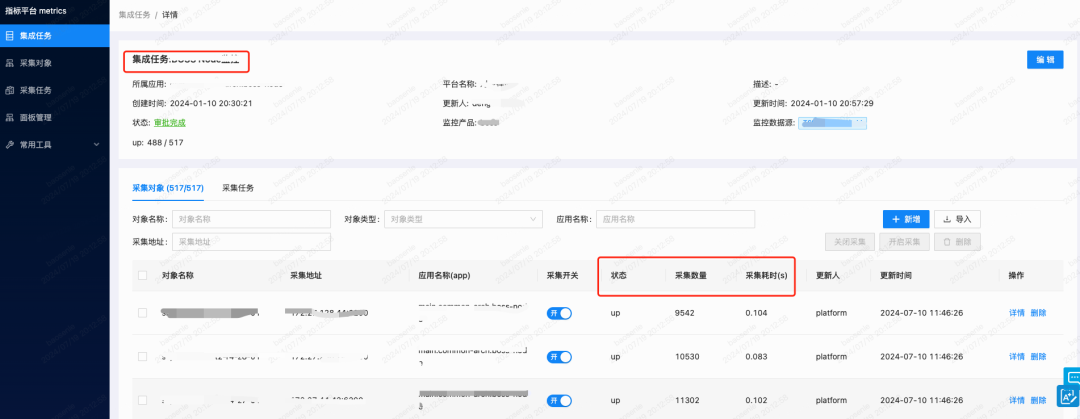
2)数据采集
调度层
调度层主要负责采集job配置的生成和target监控实例的分发。为了实现单元内链路全闭环,调度层分为一级调度(所有采集配置)和二级调度(本机房内采集配置)
一级调度(Master)
从数据库中,拿到全量的采集job配置和target监控实例。根据采集调度配置(zone维度调度),在内存中构建各个二级调度所需的采集配置。
为了保证Master数据高可用,当访问依赖数据库异常,内存快照数据不更新。同时在其他异常的场景下,我们也做了一些内存快照数据保护策略:如,当一次性删除>5k targets的job, 一次更新diff 量减少> 5k targets时,平台会拦截保护,做doubble check, 防止用户误操作。
目前通过一些手段,异步,内存cache, 多协程等方式,Master 全量调度时间从50s降低到10s内。
二级调度(Contractor)
根据采集集群名称+版本号定时去Master拿本机房的采集配置。设计多套二级调度,为了防止故障爆炸半径。
拿到本机房采集配置后,根据Collector 心跳,拿到当前health 采集节点(Collector),根据实例和容量维度进行调度,将采集配置分给对应的采集节点。
当Master采集配置或采集节点有更新时,会触发新一轮的调度。为了保证target不随机调度,在实现调度算法时,已经分配给某个采集节点的配置,下次调度时,还是会优先拿到该配置。
当Contractor应用发版,重启等场景时,怎么保证指标数据无断点或抖动呢?
在Contractor 重启时, 内存会维护一个全局state变量,等待Collector全部上报targets完成后,才开始进行targets调度,当调度完成后,state设置为ready,Contractor接口才会对Collector提供访问。
采集器
采集器Collector 是基于vmagent封装了一层。主要有两个功能,一个是定时上报心跳给Contractor, 二是拿到相关采集配置,call reload api,触发vmagent开始采集。
当我们灰度了一些量后,发现vmagent占用的内存较高,通过heap pprof发现, 在每次pull 抓取上报的指标消耗内存较多,后面开启流式采集 promscrape.streamParse=true 后,内存降低20%左右。
vmagent 自身会有随机(采集间隔时间)平滑load机制。比如我们采集间隔配置了30s,当vmagent拿到配置时,一个target最慢要30s才会有指标数据。所以当Collector扩/缩容时,target会漂移到其他Collector采集时,会出现指标断点。因此我们设计了一个机制,Collector 监听到退出信号后,不立即退出,只是停止上报心跳,同时继续采集一个周期后,才会退出,这样可以保证指标无断点。
3)数据存储
我们通过 vmstorage 进行指标的存储。由于vmstorage涉及到存储细节比较多,这里主要介绍索引结构的存储。首先认识下 vmstorage 当中几个核心类型。
MetricName 存储 label kv 的变量,写入的时候会由 vminsert 将实际指标数据当中的 label 序列化成 MetricName 进行发起写入请求,同时在 vmselect 查询的时候,拿到的结果集当中的 label 信息也是由 MetricName 进行序列化存储,在实际的存储当中,MetricName 更类似 tv 的内容元信息。MetricName 在 vmstorage 落盘的序列化结构如下:
4 byte account id | 4 byte projectid | metricname(__name__) | 1 | tag1 k | 1 | tag1 v | 1 | .... | tagn k | 1 | tagn v | 1 | 2 |
MetricId 纳秒时间戳,一簇 ts 的唯一键,在一簇 ts 第一次在 vmstorage 入库的时候生成。8 byte。
TSID 也是一簇 ts 的唯一键。由指标的租户,指标名id,job instance labelvalue id 和 MetricId 组成。TSID 在 vmstorage 落盘的序列化结构如下
4 byte accountid | 4 byte projectid | 8 byte metricname(__name__) id | 4 byte job id | 4 byte instance id | 8 byte metricid
TSID 与 MetricId 都是一簇 ts 的唯一键,区别在与 MetricId 只是 8byte 的时间戳,而 TSID 的序列化信息在包含 MetricId 之外还包含其他非常多的标识信息,当 TSID 通过字典序排序之后,同租户相同名字的指标将会在分布上连续在一起,综合指标查询的特点,查询的结果总是集中在同一个租户下的同名指标,并且都会有相似的 label 条件。所以 TSID 实际上是 vmstorage 当中 data 目录下的 key, 在索引部分的查询核心是根据查询条件得到最后的 TSID。
在上述三个类型下,就能形成如下几个抽象索引结构:
MetricName -> TSID:0 | MetricName | TSID
MetricId -> MetricName:3 | 4 byte accountid | 4 byte projectid | MetricId | MetricName
MetricId -> TSID:2 | 4 byte accountid | 4 byte projectid | MetricId | TSID
同时核心的倒排索引结构抽象如下:
1 | 4 byte accountid | 4 byte projectid | metricname(__name__) | 1 | MetricId
1 | 4 byte accountid | 4 byte projectid | tag k | 1 | tag v | 1 | MetricId
结合倒排索引和索引3就可以得到这么一条流程:
根据查询携带的租户信息和指标名称与 label 信息,就可以组成所需要的倒排索引前缀,在字典序排序的索引下,就可以通过二分查找查得所需要的 MetricId 集合。将多个条件从倒排索引中查询到的 MetricId 求交集,就能得到符合 label 查询条件的 MetricId 集合,就能通过索引3组装成响应的索引前缀查询到最后符合条件的 TSID。在 vmstorage 中执行查询时,索引部分的核心目标就是根据条件求得最后所需要的 TSID 集合。
结合以上的抽象索引,vm 通过基于前缀的压缩进行存储来达到减少磁盘占用的目的。因此相比于Prometheus,磁盘存储成本大概有40%的降幅。
在正常的 vmstorage 使用中,vmstroage 提供了十分优秀的性能,以某一个集群为例子,单台 48c 256g 的 vm stroage 日常足够支撑每秒 40w 点的写入, 2w qps 的查询。在这一过程中,通过调整应用的 gogc 来平衡 cpu 占比来优化 vm 的资源使用。默认情况下,vmstorage 的 gogc 的值给到了 30,可能会存在比较频繁的 gc,在查询写入饱和的情况下,如果与指标点的 merge 发生在一起,那么查询将会在短时间内存在比较大的握手延迟而导致失败。在内存够用的情况下,调大 vmstorage 的 gogc ,可以以一定的内存为代价换来更稳定 vmstorage 运行。
4)数据查询
promql 自动替换增强
在我们通过 grafana 访问 victoriametrics 进行日常指标查询的过程中,经常会遇到某些 panel 返回数据过慢或者是直接返回了查询覆盖的数据量太大而直接失败。这部分的 panel 常常在尽可能优化了查询条件后,仍旧无法通过正常手段查询。
在这里以一个 promql 语句作为例子:
histogram_quantile(0.99, sum(rate(grpc_server_requests_duration_ms_bucket{app="$app",env=~"$env"}[2m])) by (le, method))
这条语句用来查询某个env 下的某个 app 下的所有 grpc 接口调用 p99 耗时。在这条语句中,假设一个存在 app A,其下包含 2000 个实例,20 个接口, 50 个调用方,5 个 le 桶,以 30s 为间隔进行一次上报,单个时间上的点符合条件的点就有 1000 w,这条语句还包括一个 2m 的时间窗口统计,那么本次查询总体上符合点的数量就为 4000w。这样的查询语句,即使能够避开查询的容量限制,也会影响整体的查询数据源的稳定性。在常规的 grafana 使用习惯上,我们将会对这条语句的整体进行一次预聚合,但是在这个语句的场景下,b 站处于活跃状态的 app 数量为大几千,而这条语句中只有两位数的应用存在查询性能问题,如果直接对这条语句进行预聚合的话,就会存在比较大的资源浪费。同时,在这条语句中,如果将第一个参数分别修改为 0.5 和 0.9,那么可以直接查询得到当相应的 p50 和 p90 指标,对着这条的优化并不能帮助到 p50 和 p90的查询,单次聚合的产出也不理想。因此,在这思考一个方式,能不能通过仅聚合存在性能问题的部分来解决包含这个语句的 panel 的查询问题。
首先,从 vmselect 执行这个语句的流程入手,这条语句在 vmselect 执行的过程中,将会被解析成如下的一颗执行树:
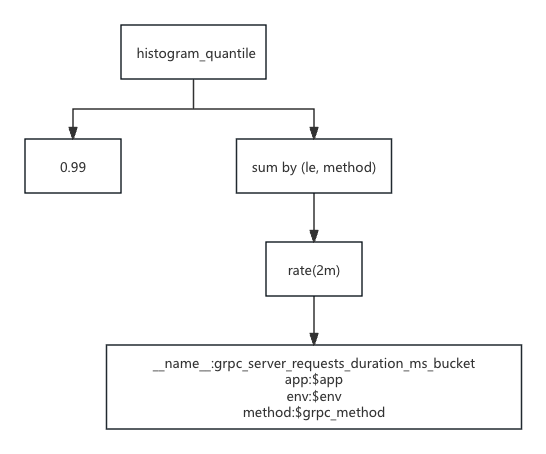
首先来描述一下该语句的执行流程,在解析得到这棵执行树之后,将会通过深度优先的方式依次来执行各个节点。具体流程如下
指标数据查询:在叶子节点处,根据指标名称和 label 的筛选条件从 vmstorage 当中进行分布式查询得到需要的原始指标数据
rate 函数执行:从第1步中查询到的指标数据根据 label 相同的指标分为一个指标簇,对相同的指标簇内的2m时间窗口中的最后一个点和第一个点相减,并除以他们之间的距离,得到 rate 函数的结果
sum 聚合函数执行:最后根据 sum 的group by 分区键将第2步中的数据根据 le + method 的分区键进行分区,之后对分到同一个区内的指标进行 sum 操作
histogram_quantile 函数执行:最后遍历第3步中得到的每个分区的数据进行 p99 的计算,得到最后需要的耗时分布的结果
我们在这里继续用前文提到的 app 举例子,其下包含 2000 个实例,20 个接口, 50 个调用方,5 个 le 桶,以 30s 为间隔进行一次上报,在第一步中查询需要得到的指标点数量就达到了 4000w。该 4000w 的数据在第二步会在时间 rate 函数的时间窗口计算当中被减少到 1000w。到第三步的时候,这 1000w 的数据会根据 le + method 的分区键被分成 100 个分区,最后输出的结果相应的被缩减到 100 个。第 4 步的结果和输入的数量相同。因此我们可以看到,在整颗树的执行过程中,第 1 步往往会成为真正执行过程中的性能瓶颈,第 2 步虽然在输出上大大减少了数量,但是仍会存在巨大的指标输出,并没有根本解决性能问题。而如果能针对第 3 步的输出结果去进行预聚合并将预聚合的结果用到查询中,该查询将会直接变成一个查询 20 个指标点的简单查询。同时,再考虑一点,无论是 p50 p90 p99 的计算,到第 3 步的指标输出为止,底层的计算逻辑是完全一致的,那么如果我们将第 3 步的结果进行预聚合并持久化下来,完全可以复用到任何参数的 histogram_quantile 计算分位耗时计算当中,一次预聚合的性价比达到了相当大的价值。
那么,我们假设已经通过实时或者定时的方式将 app A 的这条 promql 进行预聚合并将上述这个表达式的结果转化为了指标 test_metric_app_A。
sum(rate(grpc_server_requests_duration_ms_bucket{app="A"}[2m])) by (le, method)
那么我们实际执行查询 app A 的 p99 分位耗时的时候,希望真正执行的查询语句如下
histogram_quantile(0.99, test_metric_app_A)
但是,在 grafana 的 panel 配置当中,一个 panel 对应原始查询语句和多个这样的优化查询的话,实际查询时体验将会变得非常奇怪,甚至对整体体验会达到负优化的效果,那么回到一开始原始语句的查询执行树:
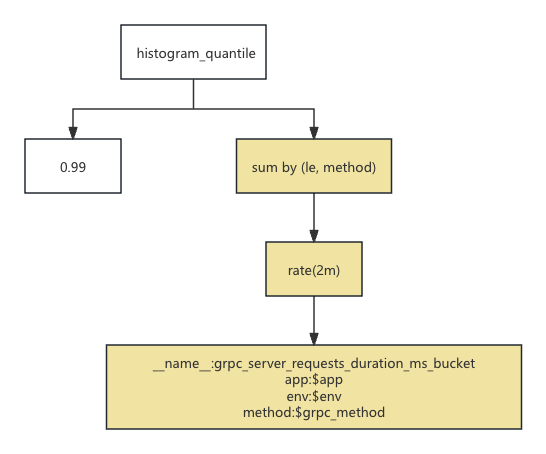
如果我们把黄色的部分的子树,直接替换成 test_metric_app_A 的查询树就可以无缝完成查询的优化了。那么我们需要在 vmselect 上面在查询之前就构建如下的一个映射关系:
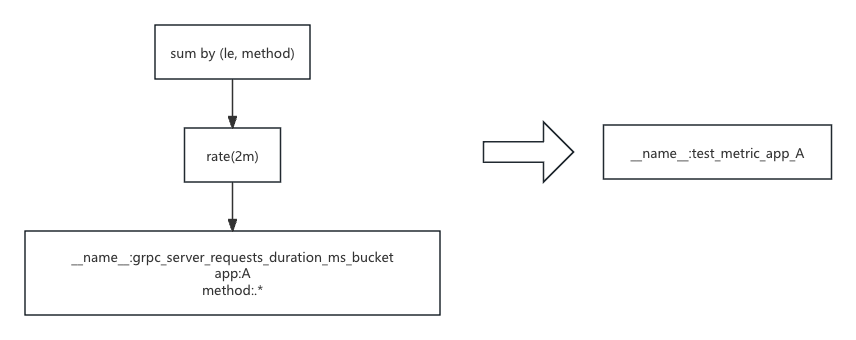
在正式执行查询的时候,我们在执行树解析完成的时候,从执行树的根节点就可以开始依次检查收否存在完全满足映射条件的 key 的执行树的子树,只要符合,就可以将原始查询语句的子树替换成映射的 value 树。
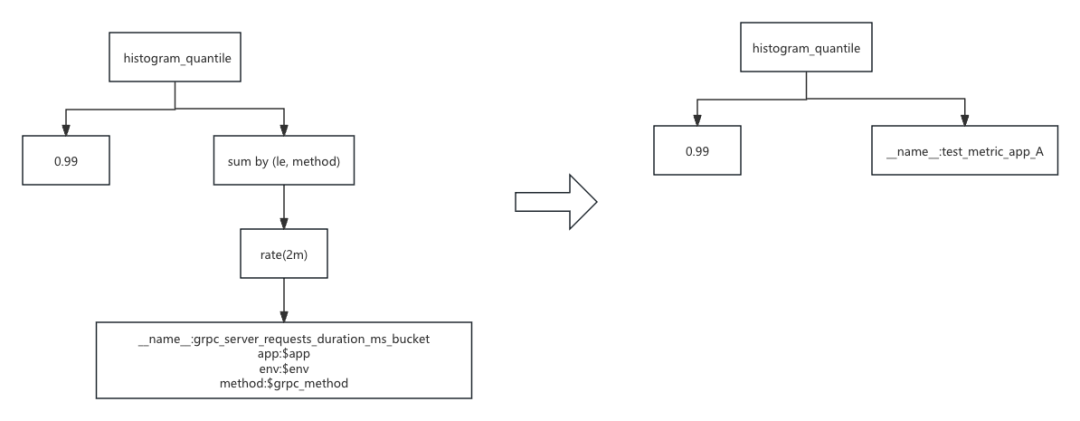
这样看似是一个非常合适的方案,但是实际的查询过程中的替换还是存在问题。首先我们的原始语句当中,用到了 env 作为查询条件,但是我们预聚合的结果采用的分区键是 le + method,在我们预聚合的结果指标当中并没有 env,直接那这里的预聚合指标进行替换,会直接丢失掉查询 env 的能力,因此此处的替换是不符合实际查询的要求的。那么我们的预聚合语句应该修改为:
sum(rate(grpc_server_requests_duration_ms_bucket{app="A"}[2m])) by (le, method, code)
这样的预聚合,当我们想重新将查询语句的执行树进行替换的时候,显然就不能单纯的将替换关系直接套在查询的执行树上,反之,在聚合函数外层应该加上一层新的聚合函数节点。
重新思考当前的场景,当我们存在如上的预聚合之后,我们需要的是在预聚合的基础上自动增加一层聚合函数,就能够达到我们需要的目的。
我们新的映射关系变成下面的样子:
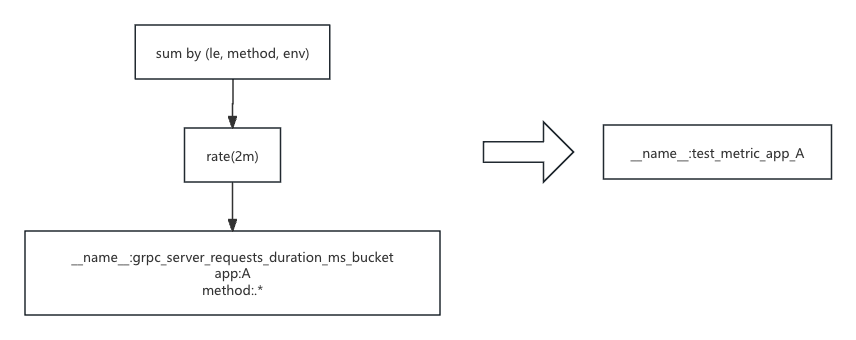
当我们得到这个映射关系之后,我们重新开始从根节点开始进行遍历的时候,会发现在 sum 这一层的分区键上存在不匹配的关系,但是,查询的分区键集合(le, method)是映射的分区键(le, method, env)的一部分,直接使用也对语句的执行没有任何影响。在这个基础上,可以直接在替换子树的时候把新的子树挂在这一层的聚合函数下面。替换结果如下:
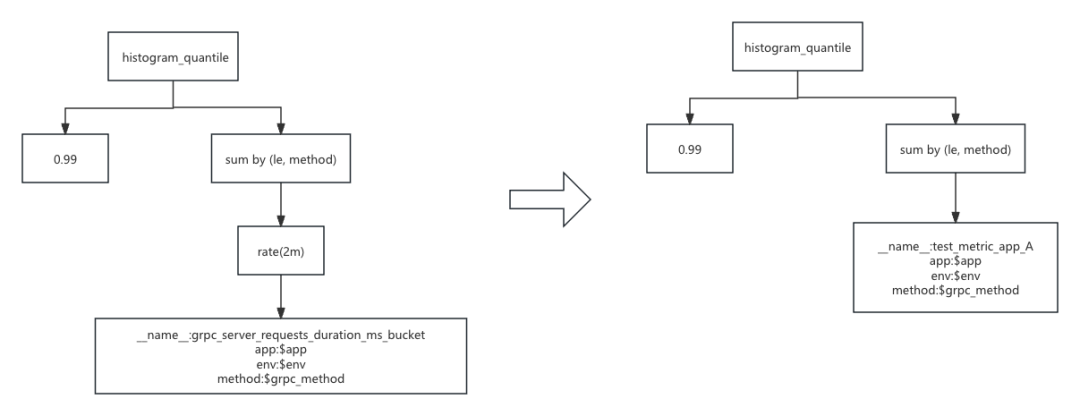
达成如上的执行树替换之后,就可以在语义无损的前提下完成 promql 的自动替换。同时,在这个转换的支持下,对于预聚合的指标我们可以在不影响预聚合输出数量的前提下尽可能的增加一些聚合的维度,这样预聚合的结果可以作为子查询用在更多的场景下。而这里的查询转换,对于用户层面在使用 grafana 进行查询的时候,是完全无感知的。在查询中对于使用了预聚合的 app,将会自动对解析后的执行树进行替换,而对于本身就不需要进行优化的查询条件的时候,将会直接根据原始查询语句去进行查询,在尽可能节省预聚合所消耗的资源的前提下,对存在性能瓶颈的查询语句进行了优化。再者,即使用户修改了查询语句,只要语句中包含预聚合了的子查询,都能够起到优化的效果,达到了预聚合资源消耗的最大回报。
ps:(avg 聚合函数会存在一定的语义损耗,但是在大部分场景下的误差可以忽略不计)
基于 promql 的flink 指标预聚合
对于前文中提到的预聚合,B站原本主要的预聚合都是通过定时的批量查询来进行预聚合。这样的查询聚合对存储侧 vmstroage 和查询侧 vmselect 都有比较大的压力,从而可能会影响到正常的指标查询需求。在预聚合的角度来看,执行原生的 promql 聚合存在一定的内存浪费,以上文提到的一条 promql 为例子:
sum(rate(grpc_server_requests_duration_ms_bucket{app="A"}[2m])) by (le, method, code)
在这个预聚合语句当中,vmselect 将会从 vmstorage 当中全量捞出符合 grpc_server_requests_duration_ms_bucket{app="A"} 的指标并在内存当中保留全部的标签,直到全部的分布式查询完成后,进行计算,在最后的 sum 部分才会根据 group by 的 le,method,code 进行 label 收敛再得到最后的结果。这个过程中,vmselect 的内存常常在执行 sum 之前,就遇到了瓶颈,尤其是这里的 rate 函数,设置了 2m 的时间窗口计算,这部分进一步扩大了 vmselect 的压力。同时,这样的查询往往会成为慢查询,这部分数据的聚合也会出现明显的延迟。同理,定时的大批量查询也会增加 stroage 的压力。
为了避免查询请求对 vm 集群的压力,同时尽可能保证预聚合的实效性,我们尝试采用 flink 来进行基于 promql 的指标预聚合。
前文提到了 promql 在 vmselect 当中的执行方式。类似 sum(rate(grpc_server_requests_duration_ms_bucket{app="A"}[2m])) by (le, method, code) 这样的表达式,将会在 vmselect 当中解析成如下的执行树。
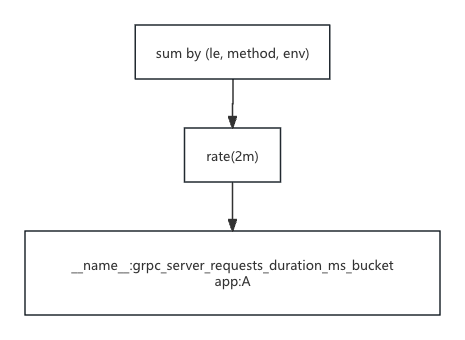
我们在 flink 预聚合的配置侧就可以类似的对这个 promql 进行相应的解析,解析成如上的执行树。在 flink 那一侧就不需要关心原始 promql 语句的构成,只需要得到这颗执行树的 json 即可,同时在配置侧需要关心的是在解析期间得到的其中的时间窗口信息作为元数据保存在一起,flink 的 job 将会各自配置的时间窗口配置从配置中选取符合条件的预聚合配置执行。
对于这颗执行树,我们站在 flink 的角度去进行设计执行流程。
数据过滤阶段
这个阶段类比我们进行 vm 查询指标,和实际vm查询执行一样,用到的都是执行的叶子节点,在配置时我们就根据每棵树的叶子节点的指标名称 label 构建 key,初步筛选实时 kafka 流中的指标数据,并在初步筛选完毕之后,进一步根据剩余的指标 label 过滤条件进行过滤,在第一阶段只需要 check 执行树的叶子结点就可以从实时指标流中得到所有符合 promql 查询的指标原始数据
数据分区阶段
sum(rate(grpc_server_requests_duration_ms_bucket{app="A"}[2m])) by (le, method, code) 的时候,我们常常在执行这个 2m 的时间窗口聚合的时候需要在内存中持有 2m 内的全量原始数据而存在压力,通常情况下,一个指标点的label集合就将达到1-2k,对于预聚合是非常大的内存压力。优化执行聚合过程中,内存中时间窗口中持有的指标点的内存是最核心的优化方向。
在我们通过 flink 进行分区时间窗口聚合的时候,我们正好需要依赖的就是执行树中的 sum 节点, sum 的 group by 键正是 flink 当中需要的分区键,我们完全可以复用这里的逻辑,将指标中对应的label 提取作为分区键,将数据点作为 value 进行缓存在 flink 当中的时间窗口当中进行聚合。但是,此处就存在了与 vmselect 执行语句的一样的内存瓶颈。我们回顾这条语句,grpc_server_requests_duration_ms_bucket 这个指标,其实除了分区键当中涉及的le method code之外的label,在执行过程中实际都不是我们需要考虑的label,我们完全可以在此处对剩余的label全部丢弃掉,只保留一个 label 集合统一的 uuid 用来在 rate 的时候能够 hash 到一个分桶里进行聚合即可。同时对于分区键的组合,我们甚至可以直接丢弃掉label key的部分,因为我们的分区键全部都是按照顺序排列的,我们的分区键只需要保留这两个label 的具体value, 而对 label 的 key 直接进行丢弃,在执行的时候按照 promql 声明的顺序顺序取即可,具体为promql id 和 label value,而我们的具体指标数据也只需要保留点的label 集合uuid 和时间数值即可。此处的优化可以直接解决聚合当中的内存压力。
以这条语句所涉及的一个指标为例子,一个指标所生成的分区键为"promqlid(四字节 需要在时间窗口中定位具体的执行树) + le value + method value + code value",需要缓存在时间窗口的指标点的内容为 "label set uuid (四字节) + time(八字节) + value(八字节)"。
最后一个点在内存中固定的内存占用为 20 字节,而相同分区键下的点之间共享的分区键大小也只有4字节 + 必须要的value串,达到了最小的内存消耗。
时间窗口执行阶段
当我们完成数据的筛选和分区之后进入时间窗口的算子阶段,我们只需要在这个阶段对这颗执行树进行一次深度优先的调用即可。
这个阶段中,由于 flink 的时间窗口限制,在具体的函数实现上会和 vm 存在一些细微的区别。
最明显的例子为 increase 函数,在 vm 对于该参数的实现中,是通过当前时间窗口的最后一个点和前一个时间窗口的最后一个点进行相减得到的结果,在flink中,由于已经定死了缓存2分钟的实时数据,这个实现将会造成额外的内存消耗,同时,在别的函数的实现上也会需要考虑额外的存储所带来的实现成本,因此我们选择了 prometheus 的 increace 实现来达到我们的目的。在 prometheus 的 increase 实现中,通过同一窗口内最后一个点和最后一个点在时间坐标轴的一次函数的k值,来根据时间窗口的长度来预估这个期间的增量。
类似如此的场景,由于 vm 相比 prometheus 在很多涉及时间窗口的函数中引入了前一个时间窗口的数据来参与计算让数据更加精准,这样的优化在 flink 将会导致额外的资源,所有类似的函数 flink 将会参考prometheus 的设计来实现。
同时,由于我们在上一个阶段中对绝大部分的label进行了丢弃,在这里类似 topk 这样需要前后保留原始label 信息的函数也存在不支持的场景。
数据上报阶段
在前一个阶段得到的预聚合指标数据就是我们所需要的结果,可以直接 flink 的 sink 当中通过 remotewrite 协议写到 vminsert上。
经过以上的设计,我们基于 promql 的 flink 预聚合可以快速根据实际存在查询瓶颈的 promql 进行快速配置生效,在实际场景下 100c 400g的 flink job 配置即可满足每2分钟3亿个指标点的时间窗口缓存和计算需求,相比定时预聚合,大大减少了预聚合的资源需求,这里的实现也满足我们在透明查询当中对资源利用最大化的期望。
查询优化收益
查询的自动优化加上 flink 的专项预聚合,可以针对实际情况下的查询情况,对特定的 promql 的集中进行治理优化,在非常小的资源消耗下,日均使 20s 以上的慢查询减少了百分之90,查询数据源资源减少百分之50,以非常小的代价带来非常高的收益。
5)数据可视化
目前我们主要使用grafana构建监控大盘,由于历史原因,grafana使用的一直是比较老的版本(v6.7.x),但是新版grafana有非常多的功能迭代和性能优化,因此我们决定升级grafana版本到v9.2.x。但版本升级存在如下挑战:
v6.7.x升级到v9.2.x存在多个break change(除了官方描述的一些break change,同时也包括一些自定义数据源/pannel 插件存在break change)。
老版本grafana部署成本高:之前是物理机部署,且部署方式相对黑盒,同时我们增加nginx+grafana auth服务做auth proxy 认证,因此部署运维成本进一步提高。
面对版本升级存在的挑战和问题,我们做了以下事项:
在升级前,我们做了大量的测试和验证,通过一些脚本fix因为break change造成的一些数据不兼容,通过opensearch数据源插件替换新版本再支持的es插件。
在部署方式上,首先用git仓库管理整个grafana部署编译脚本,让每次版本变更不再黑盒,同时将nginx+grafana auth+grafana构建成all-in-one镜像, 实现容器化部署,进一步降低部署成本。
新版本的grafana, 如果prometheus数据源使用版本>v2.37.x,变量的获取方式默认从series api改成 label values api, 查询性能会提升10倍左右(2s->200ms)。
升级完成后,面板加载性能和整体用户查询体验大幅提升。
6)整体收益
从Prometheus全部切到VM架构后, p90查询耗时降低10倍以上
目前支持了170w+ 采集对象,全部按照zone维度调度, 采集, 实现单元内容灾
仅增加磁盘资源情况下, 应用监控全量采集间隔从60s调整到30s,实现1-5-10中的1分钟发现
指标断流、oom告警等异常,降低90%以上
目前写入吞吐44M/s,查询吞吐48k/s, 通过查询优化, 查询再加速,p90查询耗时降低到ms级(300ms)
云监控方案
当前云上监控存在以下痛点:
因有各个云厂商,或者同一个云厂商,因地域不同造成网络环境不通,导致采集失败,出现无监控数据的情况。
每个账号下都是一套独立的Prometheus采集,因此存在多个云监控数据源,用户很难选择需要的云数据源。
云监控方案整体和idc采集方案类似,为了方便用户统一数据源查询和统一告警计算,我们将Prometheus采集的云上数据,通过remote write回源到idc存储集群。架构如下:
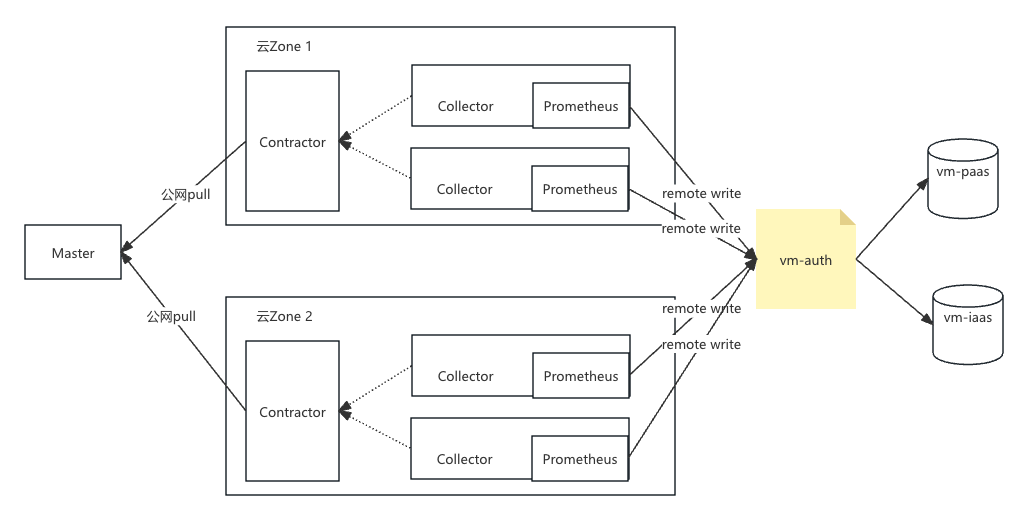
比较idc采集方案,云上监控有以下几点不同:
Contractor支持从公网pull本zone所需的采集配置。
为什么使用Prometheus而不是vmagent采集?
改造成本低:历史上云上数据,都是Prometheus采集的,同时当前Collector实现层面,采集器是可插拔的,使用Prometheus采集覆盖成本低。
Prometheus本地数据:当前云上采集数据,一份通过remote write 回源到idc存储集群,同时本地会存1d 数据,当remote write 出现故障的时候,可查询本地数据。
为什么要引入vm-auth 组件?
因为云上数据回源到idc, 走的是公网,直接回源remote write 到vm-insert,会存在安全风险,所以我们加了vm-auth,对回源流量做租户认证和流量调度。vm-auth配置如下:

收益
云上监控全部按照zone调度后,云上数据质量大幅提升,云上监控无数据等oncall 降低90%以上。
统一数据源查询,20+ 云上数据源收敛到1个。
支持更长时间Metrics指标数据存储:当前数据默认存储时间是15d, 希望给业务方提供更长时间的数据, 用作分析,复盘,资源预估等场景。
支持更细粒度的指标埋点:目前应用监控默认是30s一个点, 少部分场景支持了5s,希望后面提供更细粒度的埋点,覆盖更多的场景,为业务可观测、排障助力。
自监控能力增强:目前有一套自监控链路,跟运维平台联动,提供了基础的监控自身系统的监控和告警,希望后面可以覆盖全所有的自监控场景&运维SOP。
指标平台迭代:目前指标平台主要提供了监控接入,采集配置管理和监控对象查询等基础能力,未来规划增加写入/查询封禁、白名单等能力,同时希望后面可以借助大模型的能力,通过指标元信息增强,实现text2promql(自然语言翻译成PromQL,以及自动生成PromQL注释)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721