
一、概要
商品系统作为电商中的核心系统之一,其重要性不言而喻。互联网业务上的高性能、高并发、高可用在商品系统上体现得淋漓尽致。除了引入分布式缓存以及分库分表的优化之外,本文从数据的角度阐述了商品系统的优化,以提高商品系统的并发能力和性能。
二、转转商品服务的现状
转转在业务架构的划分上采用的是大中台小业务的方式以实现业务的快速迭代,商品系统作为业务中台的核心系统之一,承载了所有业务方的商品业务。
在数据库的设计上,商品系统采用了分库分表的策略,共拆分了16库,每个库16表的策略来提高数据库并发操作能力。此外,也根据业务类型对商品表做了一个垂直拆分,以降低索引树高提高查询性能以及降低锁冲突概率提高更新性能。
同时引入分布式缓存,提高服务的并发能力。在缓存的使用方式上,采用的是Cache Aside Pattern策略。
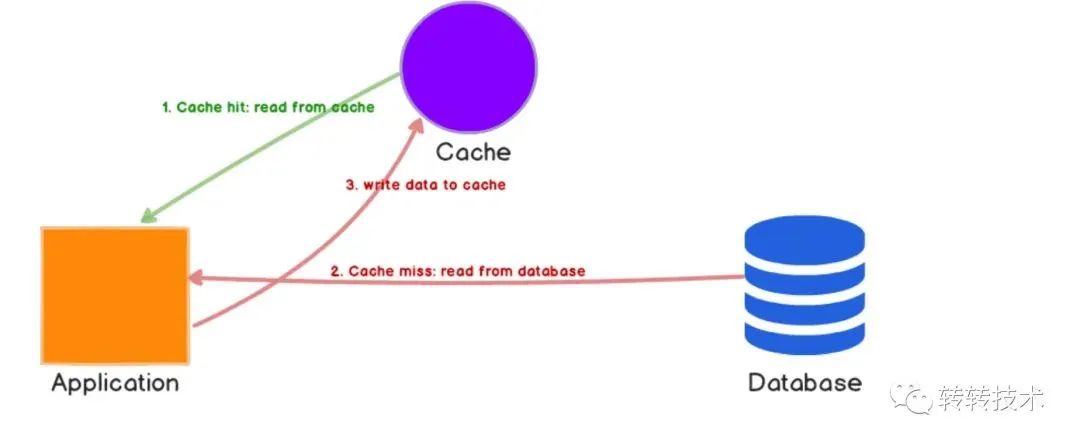
Cache Aside Pattern
三、背景及存在的问题
随着业务的发展,越来越多的业务方接入商品服务,不断拔高的QPS给系统带来的压力越来越大。同时转转作为全品类的二手闲置交易平台,其囊括了包含C2C、B2C、C2B、B2B、C2B2C等多种业务模式,在此场景下商品的数据模型要设计得足够通用化以承载不同的业务模式,而在一些模式下需要展示的信息较多,也就导致了单商品记录的数据比较大。
由此带来的三个矛盾越发突出,即:
不断拔高的QPS和系统高可用,高性能之间的矛盾
调用端的GC压力和商品数据较大之间的矛盾
加机器的成本与降本增效之间的矛盾
总的来说核心矛盾就是如何在尽量低的成本下提供更好、更快的服务。
四、定位优化点
明确了核心矛盾之后,在优化点的定位上,遵循以下原则:
抓大放小。在服务治理平台上可以看到,商品读的调用量是远远大于商品写的,因此本次优化只针对商品读。
完成路径分析。在一次商品读的完成路径上,每个点都可以作为优化的点。
可行性分析。对优化点进行可行性分析,以保证优化的效果。
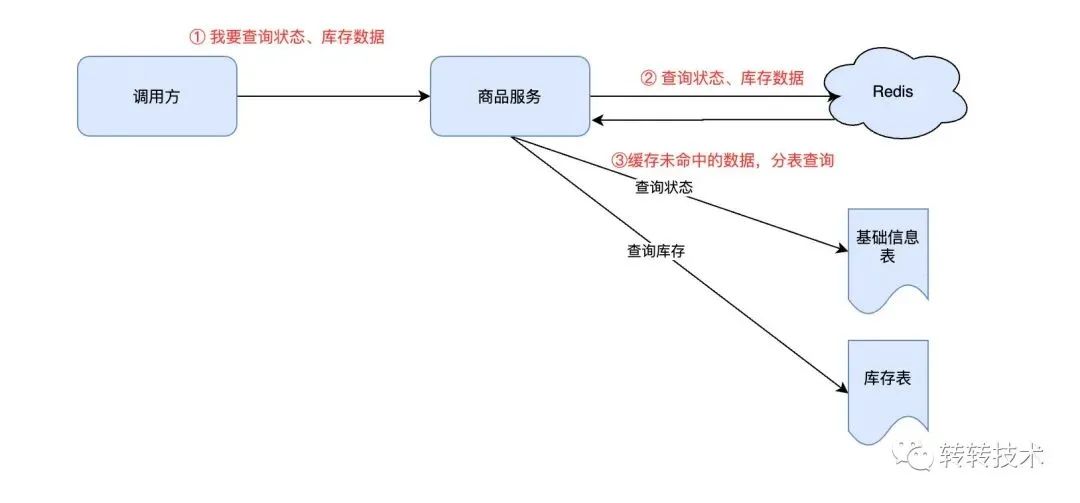
商品读的完成路径就是商品信息查询的一次RPC调用链路,其简化的流程如下图所示:
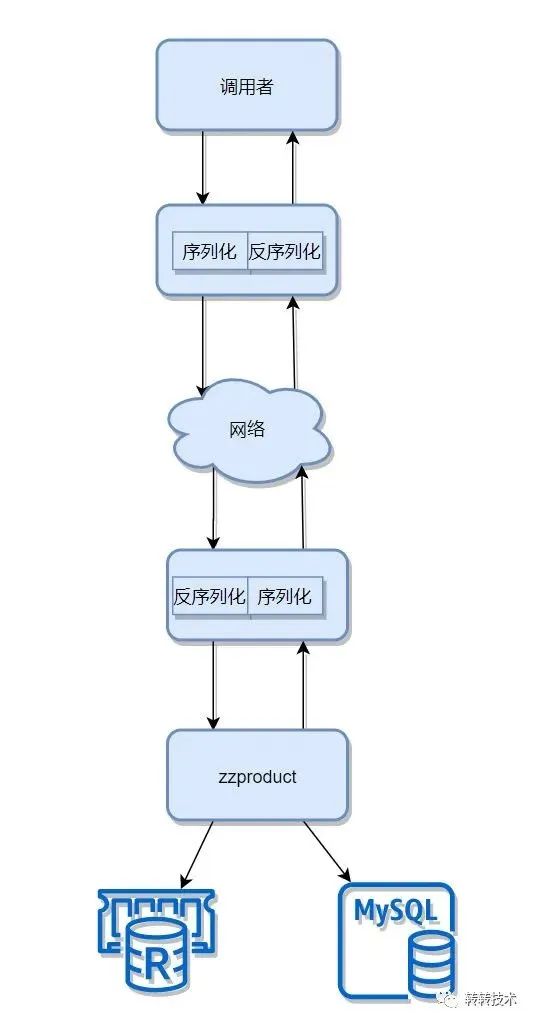
一次RPC调用,本质上就是数据的获取与流动,数据的获取上利用缓存以降低耗时,提高性能。那么在数据流动上,是否可以考虑降低数据包的大小以减少序列化和反序列化的耗时、数据传输耗时以及数据的内存占用呢?
如上图,Server收到Client的请求之后,从Redis获取商品数据流,反序列化成对象,接着序列化成数据流,传输到Client,Client获取到数据流之后,反序列化成对象,如果能降低数据包的大小,那么整个过程中Client、Redis、Server都将受益。
如何降低数据包的大小?关键的点有两个,那就是数据压缩和减少无效数据的传输。
在数据压缩上,可操作的空间已然不大,序列化的协议已经承担了很多。那么是否能考虑减少无效数据的传输以降低数据包的大小?换个说法来讲,就是Client的每次调用是用到了接口返回的全部字段数据?还是仅用到了部分字段数据?如果是仅用到部分字段数据的话,是否就可以只返回调用方使用到的字段数据从而减少无效数据的传输以降低数据包的大小?
根据上述的分析,我们定位到了减少无效数据返回的优化思路,下面对其可行性进行分析。
五、优化点可行性分析
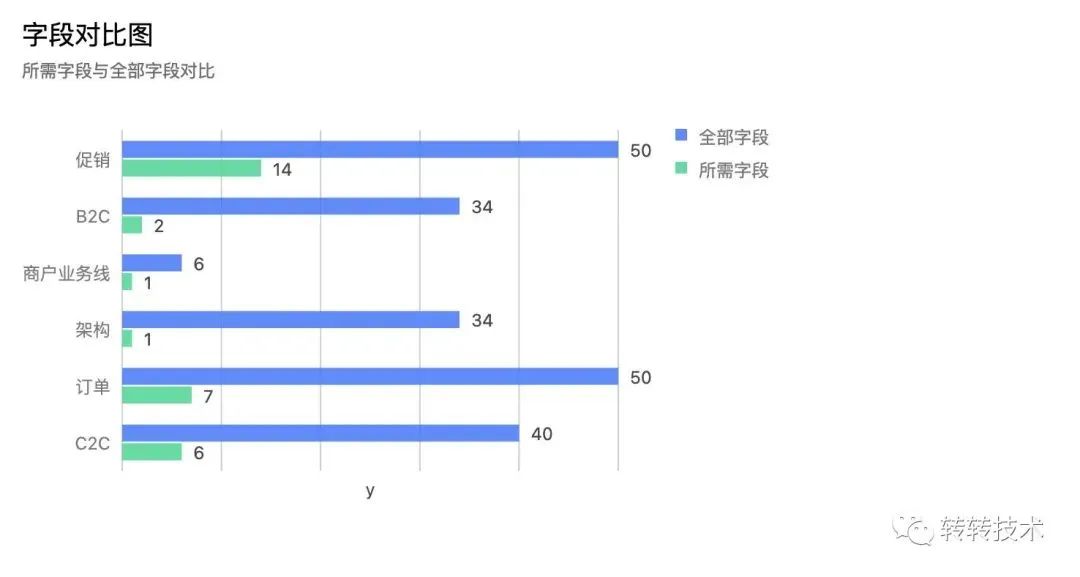
如下图列出了部分调用方查询商品信息所用到的字段数和接口返回的字段数。可见,大部分调用方用到的字段数实际上远远小于接口返回的字段数。也就是说调用方拿到了类似商品描述这样的大字符串,却没有使用到,这无疑增加了不少系统间的压力。
针对这一分析,下面提出两种优化方案。
六、优化方案
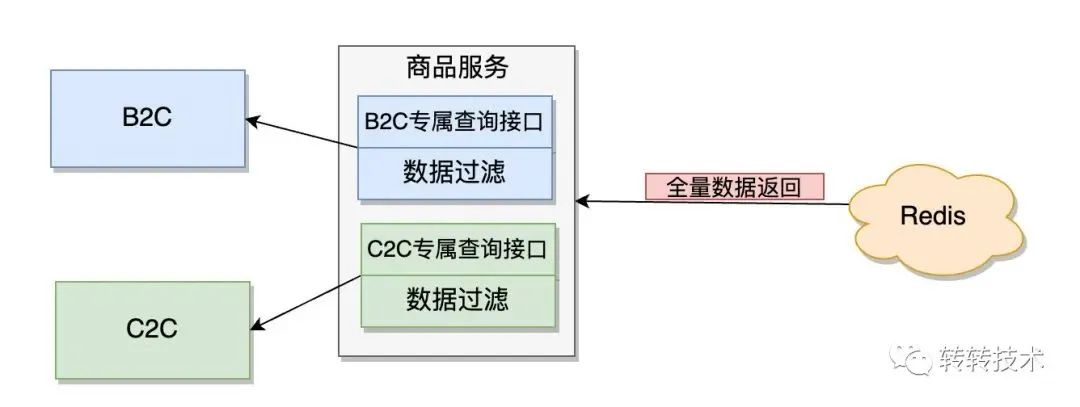
如上图,为TOP5调用量的调用方单独提供查询接口,在接口中对调用方不需要的字段数据进行过滤,只返回调用方需要的数据。
这里需要明确两个问题:
1)为什么只对TOP5调用量的调用方单独提供接口?
2)在优化上是否能满足预期?
对于第一个问题,实际上也是遵守了抓大放小的原则,TOP5的调用量占比全部调用量的50%以上,只对TOP5的调用方提供单独的查询接口,这可以在成本和效果之间取一个均衡。
对于第二个问题,是否满足预期从两个角度考虑:
无效数据是否被过滤?
由于商品信息存储在Redis采用的是String数据结构,只能整存整取,所以从Redis中获取的数据并非全为有效数据。然后从商品服务返回给调用方的数据经过了过滤,可以达到全部为有效数据的效果。
通用性与扩展性如何?
作为商品业务中台,在满足业务方业务的同时,也要保证能力的通用性与扩展性,避免与业务方强耦合从而疲于被动修改。单独给业务方提供接口,返回的字段需要和调用方商定,这显然已经与调用方发生了强耦合。如果调用方需要增加返回的字段信息,那么接口就得跟着改造。
这个方案的优点是实现简单,只需要在原有的接口上封装一层即可,但是后期维护成本高,且没有做成全链路的无效数据过滤。
GraphQL是一种用于API的查询语言,它可以不多不少的请求你所需要的数据,并且可以在一个请求中获取多个资源,这样一来,即使是比较慢的移动网络下,使用GraphQL的应用也能表现的足够迅速。
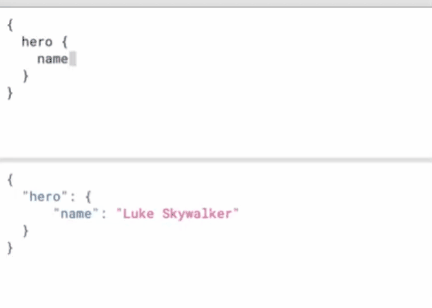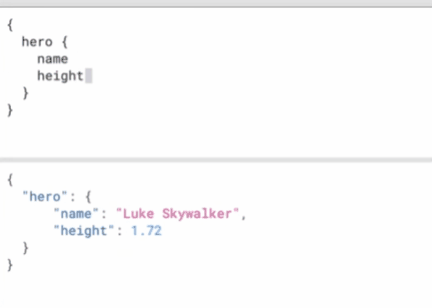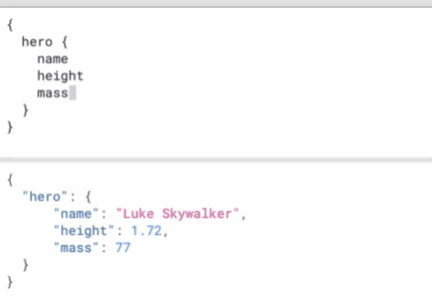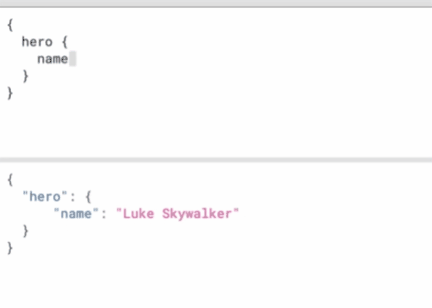
image-20220427104321298
参考这一设计理念,商品系统的设计方案如下
1)方案概要
如上图,调用方标记需要用到的字段,这些字段可以跨表,然后商品系统根据调用方标记的字段去Redis或Mysql去查询,其返回字段的决定权由调用方决定,商品系统只提供通用的查询能力。
可以看到这种方案的优点为:
减少定制化开发接口带来的成本
按需查询,按需返回,减少链路中无效数据传输和GC带来的时间成本
多表字段路由,调用方无需调用多个接口来拼接数据
缺点就是需要标记请求的字段,这在一定程度上增加了请求数据包大小,下面聊聊该方案的实现细节。
2)请求字段的标记
标记一个字段,一个较为可读的表示方式就是传入该字段的名称,但字符串占用内存相对较大,在数据传输和序列化上对性能都会有一定的损耗。针对这一问题,我们采用另一种利用bit位标记一个字段的方式。
如下图,long型共64位,前2位表示组的信息,后62位表示字段的信息,这就可以表示4*62=248个字段的信息,完全满足接口当前以及未来的需要。
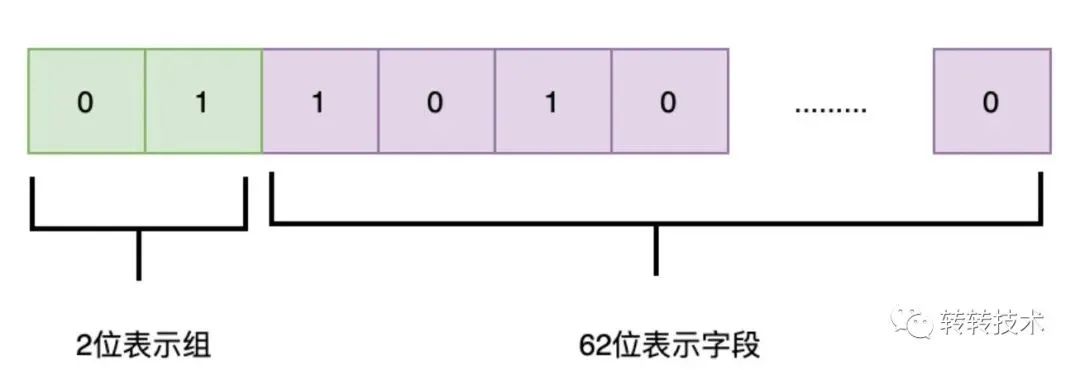
当前商品系统共用到57个标记位。
举个例子,用long型右数第一位表示商品状态,右数第二位表示商品标题,那么字段表示如下:
long status = 1;long title = 1 <<< 1;
若调用方请求标记了商品状态和商品标题两个字段,就可以这么计算:
long result = status | title;
如此便可让long型的右数第一位和和右数第二位皆为1,当商品系统拿到这个组合long型值的时候,也就知晓了调用方的所需字段。
当然用bit位标记字段有一定的复杂性,为保证正确性和易用性,这里可以利用建造者设计模式隔离构造的复杂性,让调用方更方便的使用,如下所示:
BitProductFieldRepresentation fieldRepresentation = new BitProductFieldBuilder().actTypeId().infoType().brandIdNew().build();
3)按需查询的实现
要实现按照标记的字段查询数据,在商品信息的请求链路中,需要分两部分来讨论,即Redis的按需查询和Mysql的按需查询。
Redis的按需查询
目前商品信息在Redis中存储的数据结构是String,其中key为商品id,value是序列化后的整个商品信息,String数据结构是整存整取,无法按需查询。
Redis String数据结构适用于每次需要访问大量的字段且存储结构具有多层嵌套的场景,而Hash数据结构更适用于在多数情况下只需要访问少量字段的场景,且需要知道访问哪些字段。
在我们的业务场景下,Hash数据结构显然更为合适,因此将商品存储在Redis的数据结构修改为Hash类型,即可实现按需查询字段信息。
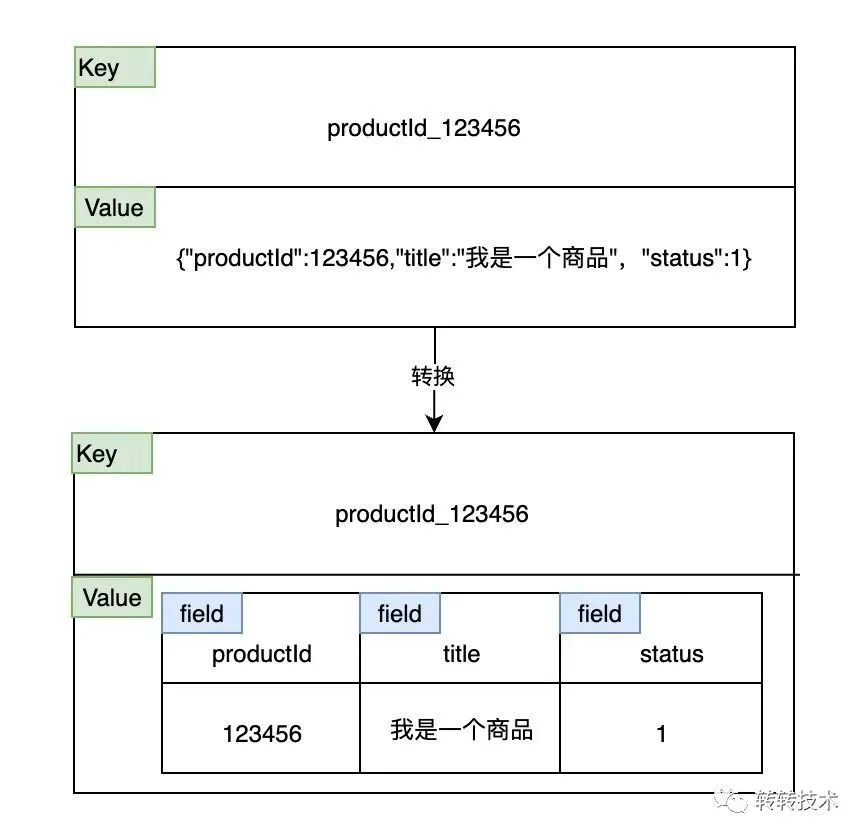
image-20220427104444335
Mysql的按需查询
根据统计,在请求中,Redis的命中率可达98.5%以上,Mysql的命中率仅为1.5%,Mysql的命中率较低,对其做按需查询所带来的优势不大。
并且Mysql的查询性能不及Redis,因此这里放弃做Mysql的按需查询,避免降低Redis命中率,增大数据库压力。
4)表路由
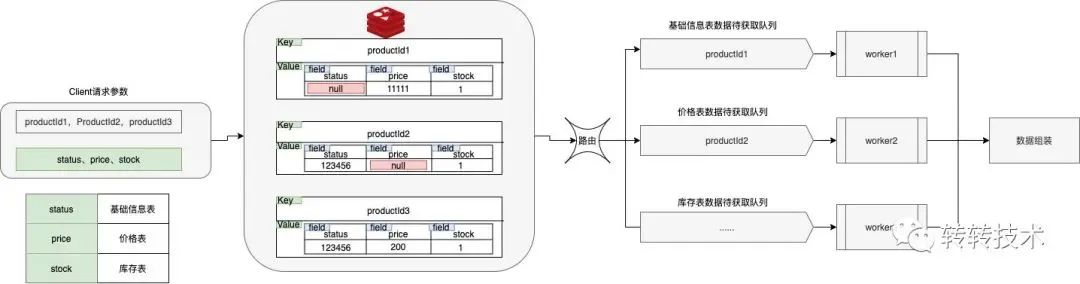
在请求标记法中,可以标记不同表的字段,以实现跨表查询。在批量查询商品信息的逻辑中,需要根据缓存的命中情况,对商品id进行路由,对没有命中缓存的商品id,路由到相应的队列中从数据库中进行数据获取。
如下图,status位于基础信息表、price位于价格表、stock位于库存表,在查询三个商品ID的status、price、stock的数据时,在Redis中product1未命中status的数据,product2未命中price的数据,product3均命中,那么就会将product1路由到基础信息表数据待获取队列中,product2路由到价格表数据待获取队列中,后续由单独的线程去对应的数据表并发查询数据,然后组装结果返回。
5)扩展性
这里参考Spring的BeanFactoryPostProcessor,BeanPostProcessor提供了一些扩展点,在无需改动主流程情况下,提供扩展能力。如下图,在接收到请求参数之后,参数的校验以及bit位请求字段的解析都是放在扩展类中实现的
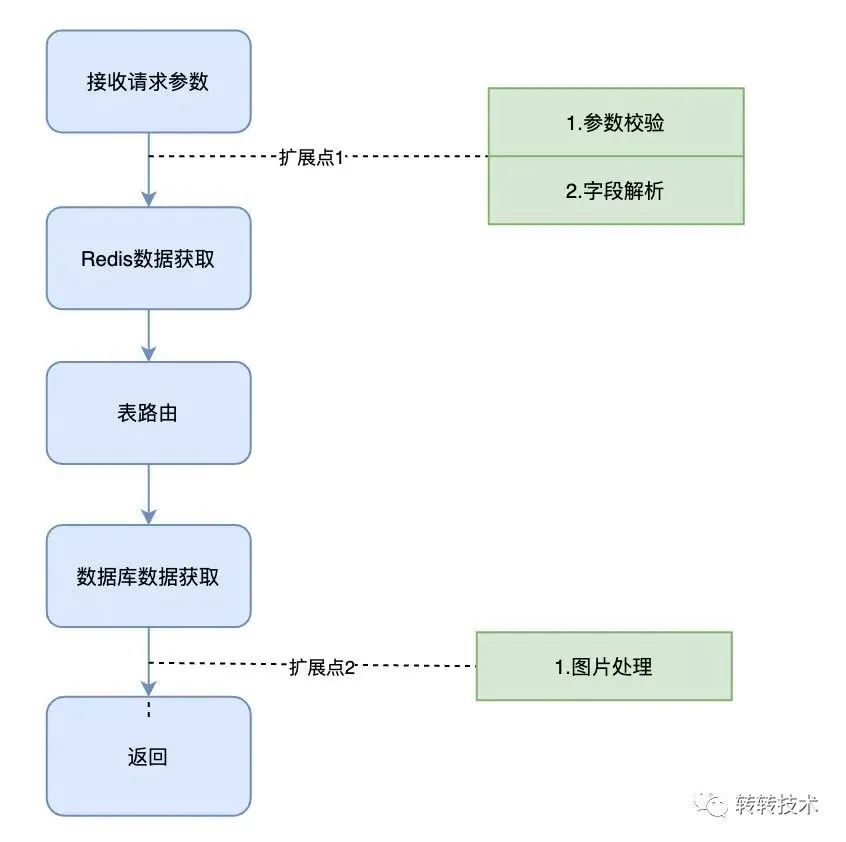
扩展点
七、优化效果
从四个角度来看优化的效果,即调用端GC情况,服务端GC次数和GC耗时,网卡流量,接口耗时。
此数据是在促销调用的场景下,TPS为3500,调优化后的接口返回14个字段的数据与调优化前接口返回50个字段的数据得出。
需要注意的是促销使用的14个字段在3张不同的表中,在完成一个事务的情况下,需要调用3个原接口。
调用端调用优化前接口单位时间内发生547次GC,耗时1.74s
调用端调用优化后接口单位时间内发生176次GC,耗时561ms
约3倍的提升

优化前调用端GC

优化后调用端GC
调用端调用优化前接口,服务端单位时间内发生10次YGC
调用端调用优化后接口,服务端单位时间内发生3次YGC(高点4次,低点2次)
约3倍的提升
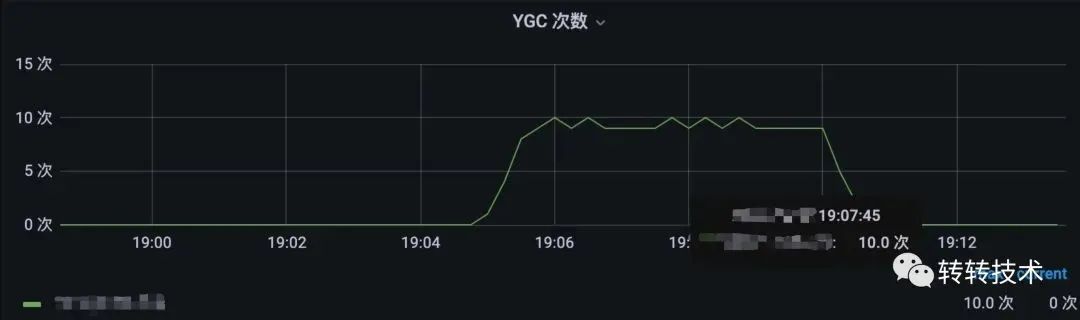
优化前GC次数
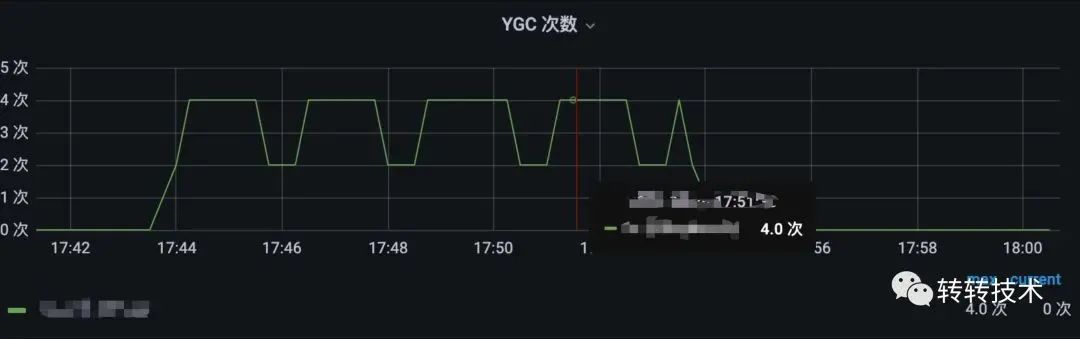
优化后GC次数
调用端调用优化前接口,服务端单位时间内约120ms的GC时间
调用端调用优化后接口,服务端单位时间内约40ms的GC时间
约3倍的提升
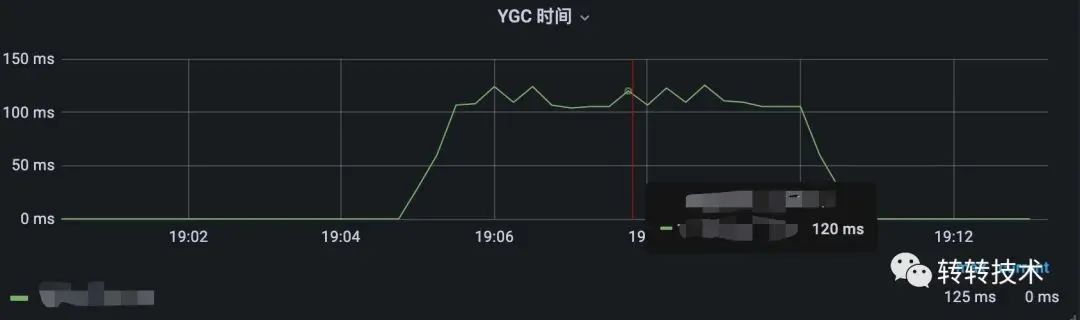
优化前GC时间
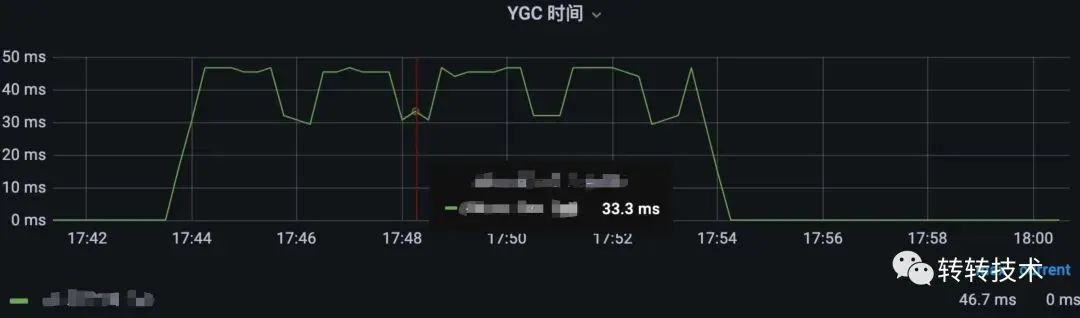
优化后GC时间
调用端调用优化前接口,服务端机器单位时间内经过网卡的流量为90.62MB
调用端调用优化后接口,服务端机器单位时间内经过网卡的流量为11.95MB
约8倍的提升

优化前流量

优化后流量
调用优化前三个接口,接口平均耗时分别为:1.17ms、1.52ms、1.23ms
调用优化后接口,接口平均耗时1.30ms

优化前性能

优化后性能
八、总结
本文从数据的角度对商品系统进行了优化,从分析思路到具体实现做了一些简单的介绍。
参考资料
https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
http://hessian.caucho.com/doc/hessian-serialization.html/
https://graphql.cn









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721