
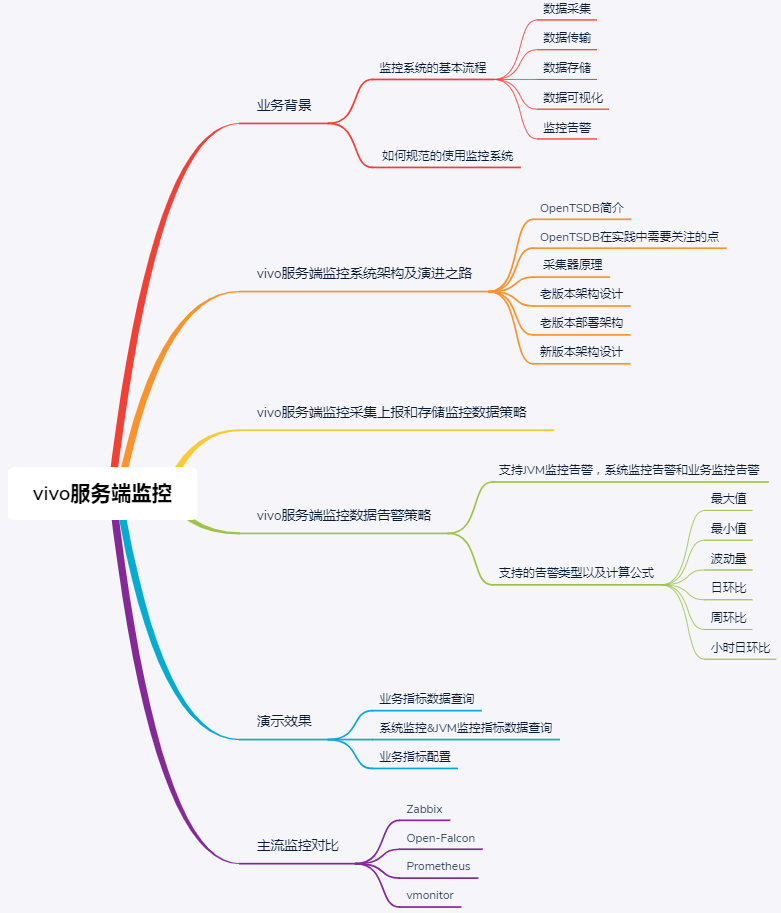
一、业务背景
当今时代处在信息大爆发的时代,信息借助互联网的潮流在全球自由的流动,产生了各式各样的平台系统和软件系统,越来越多的业务也会导致系统的复杂性。
当核心业务出现了问题影响用户体验,开发人员没有及时发现,发现问题时已经为时已晚,又或者当服务器的CPU持续增高,磁盘空间被打满等,需要运维人员及时发现并处理,这就需要一套有效的监控系统对其进行监控和预警。
如何对这些业务和服务器进行监控和维护是我们开发人员和运维人员不可忽视的重要一环,这篇文章全篇大约5000多字,我将对vivo服务端监控的原理和架构演进之路做一次系统性整理,以便大家做监控技术选型时参考。
vivo服务端监控旨在为服务端应用提供包括系统监控、JVM监控以及自定义业务指标监控在内的一站式数据监控,并配套实时、多维度、多渠道的告警服务,帮助用户及时掌握应用多方面状态,事前及时预警发现故障,事后提供详实的数据用于追查定位问题,提升服务可用性。目前vivo服务端监控累计接入业务方数量达到200+,本文介绍的是服务端监控,我司还有其他类型的优秀监控包括通用监控、调用链监控和客户端监控等。
无论是开源的监控系统还是自研的监控系统,整体流程都大同小异。
1)数据采集:可以包括JVM监控数据如GC次数,线程数量,老年代和新生代区域大小;系统监控数据如磁盘使用使用率,磁盘读写的吞吐量,网络的出口流量和入口流量,TCP连接数;业务监控数据如错误日志,访问日志,视频播放量,PV,UV等。
2)数据传输:将采集的数据以消息形式或者 HTTP 协议的形式等上报给监控系统。
3)数据存储:有使用 MySQL、Oracle 等 RDBMS 存储的,也有使用时序数据库OpenTSDB、InfluxDB 存储的,还有使用 HBase 直接存储的。
4)数据可视化:数据指标的图形化展示,可以是折线图,柱状图,饼图等。
5)监控告警:灵活的告警设置,以及支持邮件、短信、IM 等多种通知通道。
在使用监控系统之前,我们需要了解监控对象的基本工作原理,例如JVM监控,我们需要清楚JVM的内存结构组成和常见的垃圾回收机制;其次需要确定如何去描述和定义监控对象的状态,例如监控某个业务功能的接口性能,可以监控该接口的请求量,耗时情况,错误量等;在确定了如何监控对象的状态之后,需要定义合理的告警阈值和告警类型,当收到告警提醒时,帮助开发人员及时发现故障;最后建立完善的故障处理体系,收到告警时迅速响应,及时处理线上故障。
二、vivo服务端
监控系统架构及演进之路
在介绍vivo服务端监控系统架构之前,先带大家了解一下OpenTSDB时序数据库,在了解之前说明下为什么我们会选择OpenTSDB,原因有以下几点:
1)监控数据采集指标在某一时间点具有唯一值,没有复杂的结构及关系。
2)监控数据的指标具有随着时间不断变化的特点。
3)基于HBase分布式、可伸缩的时间序列数据库,存储层不需要过多投入精力,具有HBase的高吞吐,良好的伸缩性等特点。
4)开源,Java实现,并且提供基于HTTP的应用程序编程接口,问题排查快可修改。
1)基于HBase的分布式的,可伸缩的时间序列数据库,主要用途就是做监控系统。譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储和查询,支持秒级数据采集,支持永久存储,可以做容量规划,并很容易地接入到现有的监控系统里,OpenTSDB的系统架构图如下:
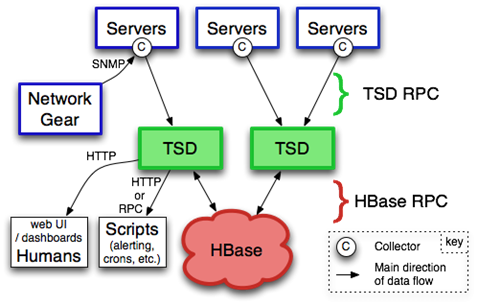
(来自官方文档)
存储结构单元为Data Point,即某个Metric在某个时间点的数值。Data Point包括以下部分:
Metric,监控指标名称;
Tags,Metric的标签,用来标注类似机器名称等信息,包括TagKey和TagValue;
Value,Metric对应的实际数值,整数或小数;
Timestamp,时间戳。
核心存储两张表:tsdb和tsdb-uid。表tsdb用来存储监控数据,如下图:
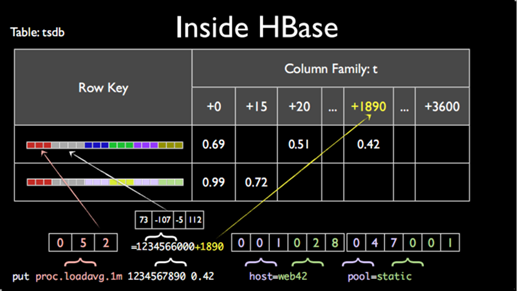
(图片出处:https://www.jianshu.com)
Row Key为Metric+Timestamp的小时整点+TagKey+TagValue,取相应的字节映射组合起来;列族t下的Qualifier为Timestamp的小时整点余出的秒数,对应的值即为Value。
表tsdb-uid用来存储刚才提到的字节映射,如下图:

(图片出处:https://www.jianshu.com)
图中的“001”表示tagk=hots或者tagv=static,提供正反查询。
2)OpenTSDB使用策略说明:
不使用OpenTSDB提供的rest接口,通过client与HBase直连;
工程端禁用compact动作的Thrd线程;
间隔10秒获取Redis缓冲数据批量写入OpenTSDB。
1)精确性问题
String value = "0.51";float f = Float.parseFloat(value);int raw = Float.floatToRawIntBits(f);byte[] float_bytes = Bytes.fromInt(raw);int raw_back = Bytes.getInt(float_bytes, 0);double decode = Float.intBitsToFloat(raw_back);/*** 打印结果:* Parsed Float: 0.51* Encode Raw: 1057132380* Encode Bytes: 3F028F5C* Decode Raw: 1057132380* Decoded Float: 0.5099999904632568*/System.out.println("Parsed Float: " + f);System.out.println("Encode Raw: " + raw);System.out.println("Encode Bytes: " + UniqueId.uidToString(float_bytes));System.out.println("Decode Raw: " + raw_back);System.out.println("Decoded Float: " + decode);
如上代码,OpenTSDB在存储浮点型数据时,无法知悉存储意图,在转化时会遇到精确性问题,即存储"0.51",取出为"0.5099999904632568"。
2)聚合函数问题
OpenTSDB的大部分聚合函数,包括sum、avg、max、min都是LERP(linear interpolation)的插值方式,即所获取的值存在被补缺的现象,对于有空值需求的使用很不友好。详细原理参见OpenTSDB关于interpolation的文档。
目前vmonitor服务端监控使用的OpenTSDB是我们改造后的源码,新增了nimavg函数,配合自带的zimsum函数满足空值插入需求。
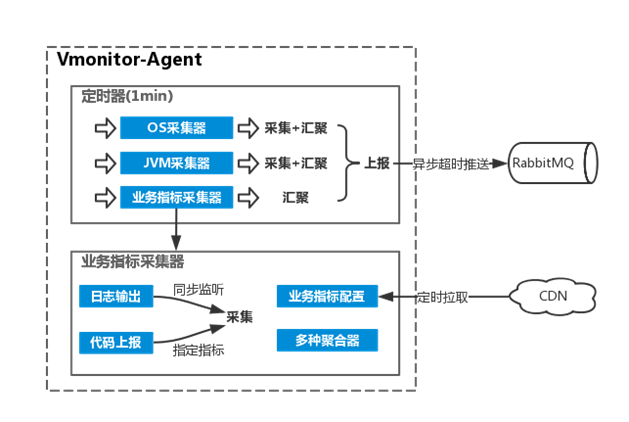
1)定时器
内含3种采集器:OS采集器、JVM采集器和业务指标采集器,其中OS及JVM每分钟执行采集和汇聚,业务指标采集器会实时采集并在1分钟的时间点完成汇聚重置,3份采集器的数据打包上报至RabbitMQ,上报动作异步超时。
2)业务指标采集器
业务指标采集方式有2种:日志输出过滤和工具类代码上报(侵入式),日志输出过滤是通过继承log4j的Filter,从而获取指标配置中指定的Appender输出的renderedMessage,并根据指标配置的关键词、聚合方式等信息进行同步监听采集;代码上报根据代码中指定的指标code进行message信息上报,属于侵入式的采集方式,通过调用监控提供的Util实现。业务指标配置每隔5分钟会从CDN刷新,内置多种聚合器供聚合使用,包括count计数、 sum求和、average平均、max最大值和min最小值统计。
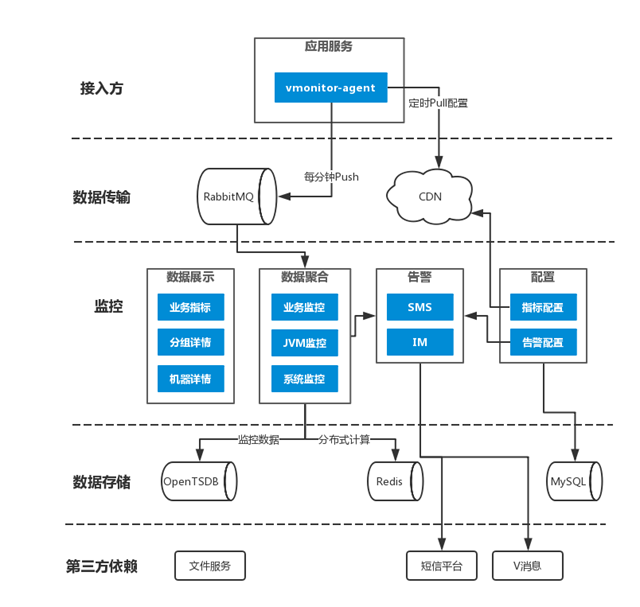
1)数据采集及上报
需求方应用接入的监控采集器vmonitor-agent根据监控指标配置采集相应数据,每分钟上报1次数据至RabbitMQ,所采用的指标配置每5分钟从CDN下载更新,CDN内容由监控后台上传。
2)计算及存储
监控后台接收RabbitMQ的数据,拆解后存储至OpenTSDB,供可视化图表调用,监控项目、应用、指标和告警等配置存储于MySQL;通过Zookeeper和Redis实现分布式任务分发模块,实现多台监控服务协调配合运作,供分布式计算使用。
3)告警检测
从OpenTSDB获取监控指标数据,根据告警配置检测异常,并将异常通过第三方依赖自研消息、短信发送,告警检测通过分布式任务分发模块完成分布式计算。
1)自建机房A
部署架构以国内为例,监控工程部署在自建机房A,监听本机房的RabbitMQ消息,依赖的Redis、OpenTSDB、MySQL、Zookeeper等均在同机房,需要上传的监控指标配置由文件服务上传至CDN,供监控需求应用设备调用。
2)云机房
云机房的监控需求应用设备将监控数据上报至云机房本地的RabbitMQ,云机房的RabbitMQ将指定队列通过路由的方式转发至自建机房A的RabbitMQ,云机房的监控配置通过CDN拉取。
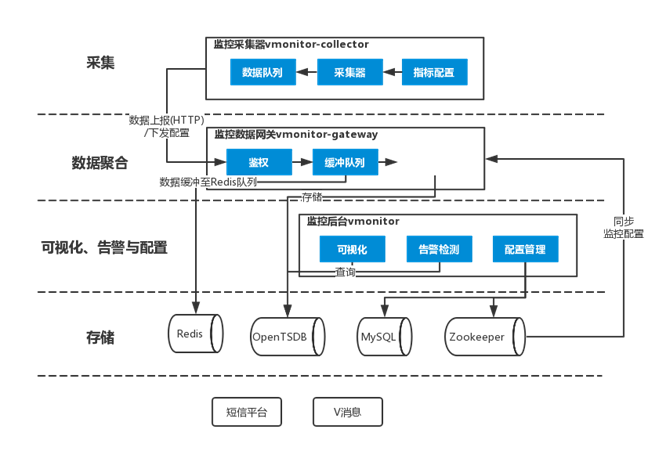
1)采集(接入方)
业务方接入vmonitor-collector,并在相应环境的监控后台配置相关监控项即完成接入,vmonitor- collector将定时拉取监控项配置,采集服务数据并每分钟上报。
2)数据聚合
老版本支持的是RabbitMQ将采集到的数据,路由至监控机房的RabbitMQ(同机房则不发生该行为),由监控后台服务消费;CDN负责承载各应用的配置供应用定时拉取。新版本vmonitor-gateway作为监控数据网关,采用http方式上报监控数据以及拉取指标配置,抛弃了之前使用的RabbitMQ上报以及CDN同步配置的途径,避免两者故障时对监控上报的影响。
3)可视化并且支持告警与配置(监控后台vmonitor)
负责前台的数据多元化展示(包括业务指标数据,分机房汇总数据,单台服务器数据,以及业务指标复合运算呈现),数据聚合,告警(目前包括短信及自研消息)等。
4)数据存储
存储使用HBASE集群和开源的OpenTSDB作为聚合的中介,原始数据上报之后通过OpenTSDB持久化到HBase集群,Redis作为分布式数据存储调度任务分配、告警状态等信息,后台涉及的指标和告警配置存储于MySQL。
三、监控采集上报和存储监控数据策略
为降低监控接入成本以及避免RabbitMQ上报故障和CDN同步配置故障对监控体系带来的影响,将由采集层通过HTTP直接上报至代理层,并通过采集层和数据代理层的队列实现灾时数据最大程度的挽救。
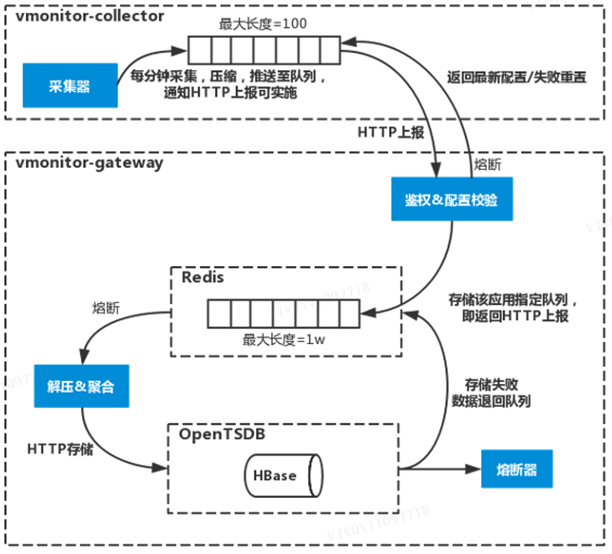
详细流程说明如下:
1)采集器(vmonitor-collector)根据监控配置每分钟采集数据并压缩,存储于本地队列(最大长度100,即最大存储100分钟数据),通知可进行HTTP上报,将数据上报至网关。
2)网关(vmonitor-gateway)接收到上报的数据后鉴权,认定非法即丢弃;同时判断当前是否下层异常熔断,如果发生则通知采集层重置数据退回队列。
3)网关校验上报时带来的监控配置版本号,过期则在结果返回时将最新监控配置一并返回要求采集层更新配置。
4)网关将上报的数据存储于该应用对应的Redis队列中(单个应用缓存队列key最大长度1w);存储队列完成后立即返回HTTP上报,表明网关已接受到数据,采集层可移除该条数据。
5)网关对Redis队列数据进行解压以及数据聚合;如果熔断器异常则暂停前一行为;完成后通过HTTP存储至OpenTSDB;如果存储行为大量异常则触发熔断器。
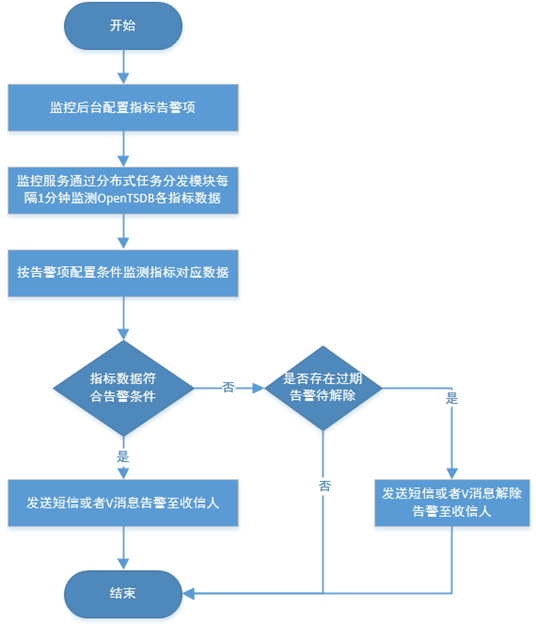
四、核心指标
将采集到的数据通过OpenTSDB存放到HBase中后,通过分布式任务分发模块完成分布式计算。如果符合业务方配置的告警规则,则触发相应的告警,对告警信息进行分组并且路由到正确的通知方。可以通过短信自研消息进行告警发送,可通过名字、工号、拼音查询录入需要接收告警的人员,当接收到大量重复告警时能够消除重复的告警信息,所有的告警信息可以通过MySQL表进行记录方便后续查询和统计,告警的目的不仅仅是帮助开发人员及时发现故障建立故障应急机制,同时也可以结合业务特点的监控项和告警梳理服务,借鉴行业最佳监控实践。告警流程图如下:
1)最大值:当指定字段超过该值时触发报警(报警阈值单位:number)。
2)最小值:当指定字段低于该值时触发报警(报警阈值单位:number)。
3)波动量:取当前时间到前15分钟这段时间内的最大值或者最小值与这15分钟内的平均值做浮动百分比报警,波动量需要配置波动基线,标识超过该基线数值时才做“报警阀值”判定,低于该基线数值则不触发报警(报警阈值单位:percent)。
计算公式:
波动量-向上波动计算公式:float rate = (float) (max - avg) / (float) avg;
波动量-向下波动计算公式:float rate = (float) (avg - min) / (float) avg;
波动量-区间波动计算公式:float rate = (float) (max - min) / (float) max;
4)日环比:取当前时间与昨天同一时刻的值做浮动百分比报警(报警阈值单位:percent)。
计算公式:float rate = (当前值 - 上一周期值)/上一周期值
5)周环比:取当前时间与上周同一天的同一时刻的值做浮动百分比报警(报警阈值单位:percent)。
计算公式:float rate = (当前值 - 上一周期值)/上一周期值
6)小时日环比:取当前时间到前一小时内的数据值总和与昨天同一时刻的前一小时内的数据值总和做浮动百分比报警(报警阈值单位:percent)。
计算公式:float rate = (float) (anHourTodaySum - anHourYesterdaySum) / (float) anHourYesterdaySum。
五、演示效果
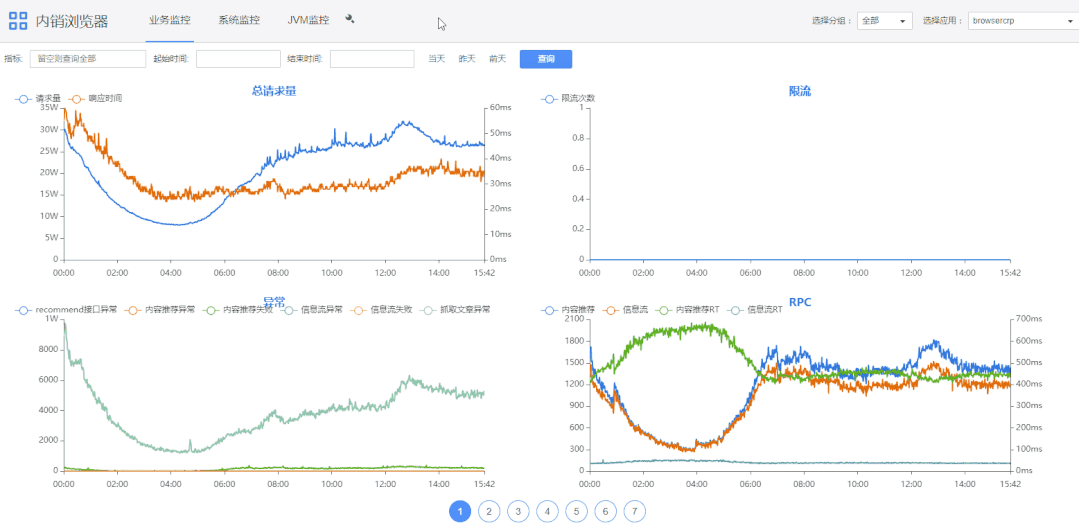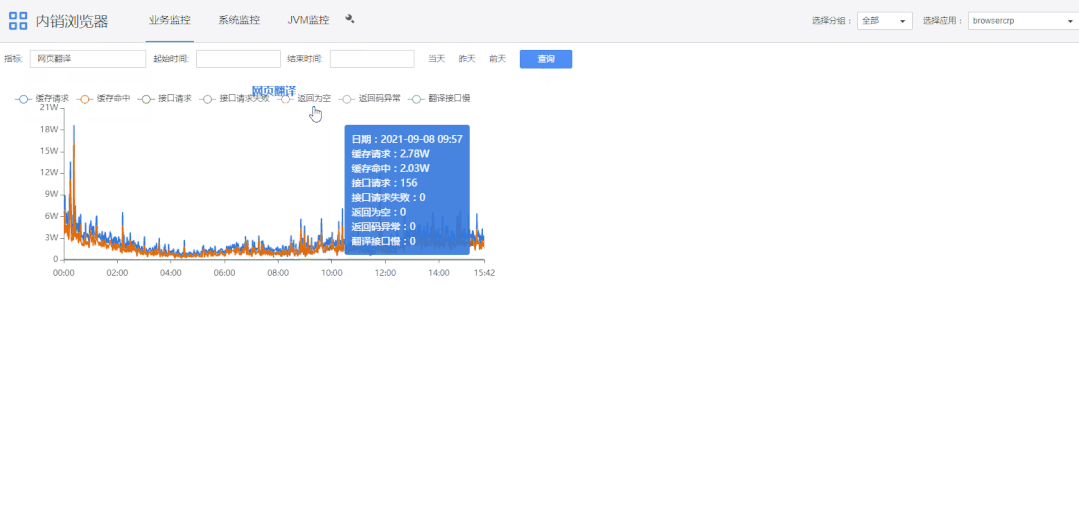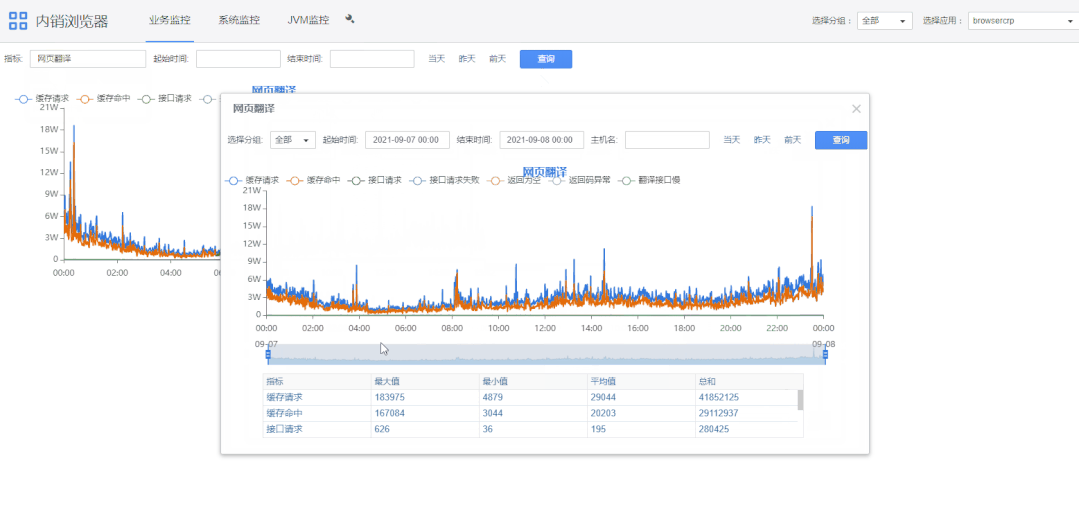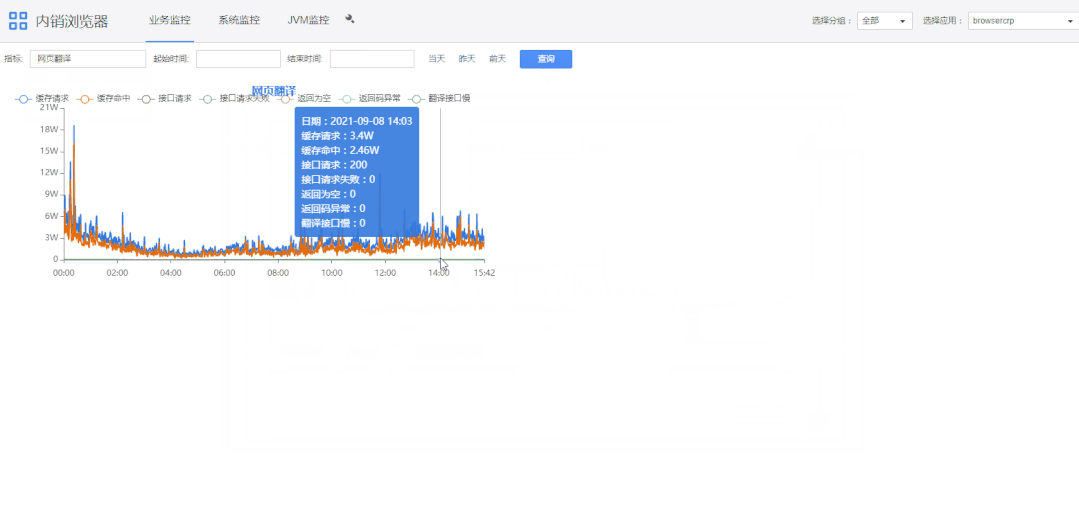
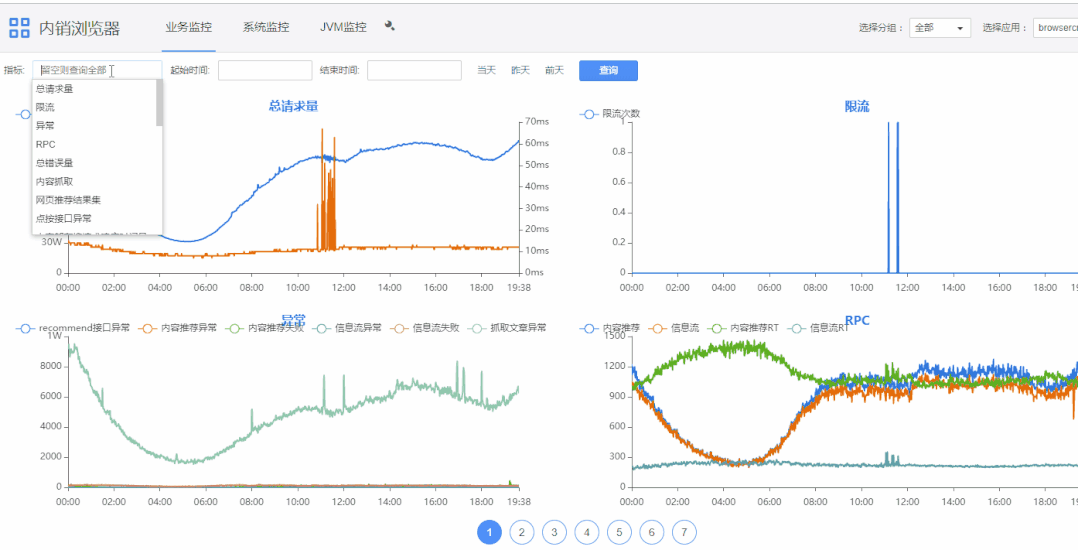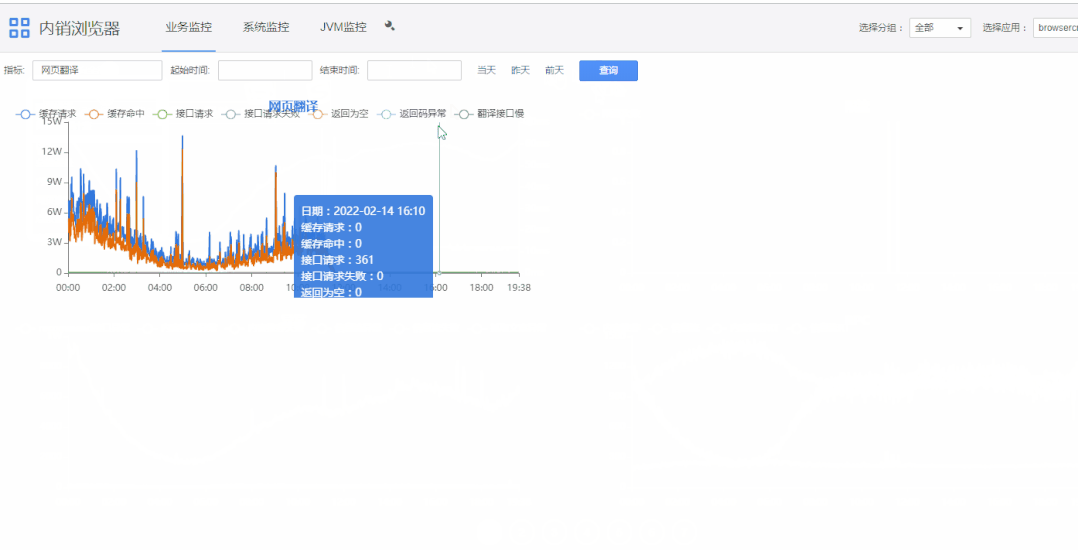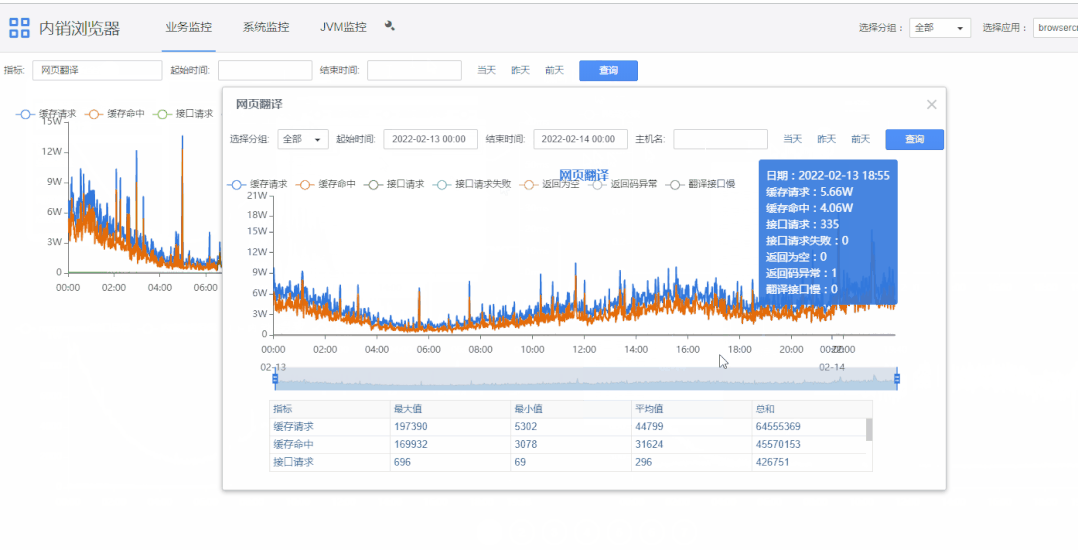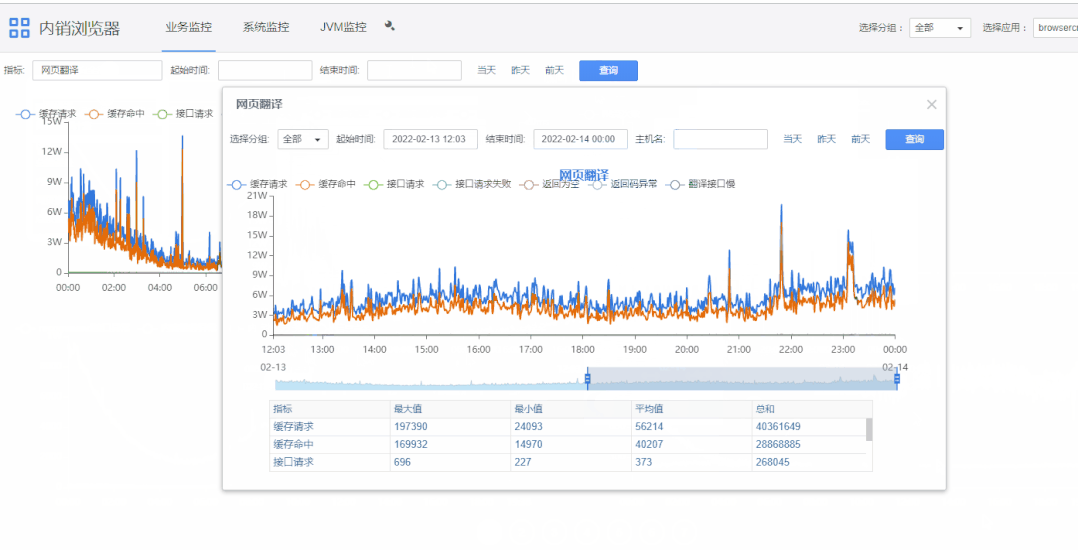
1)查询条件栏“指标”可选择指定指标。
2)双击图表上指标名称可展示大图,底部是根据起始时间的指标域合计值。
3)滚轮可以缩放图表。
1)每分钟页面自动刷新。
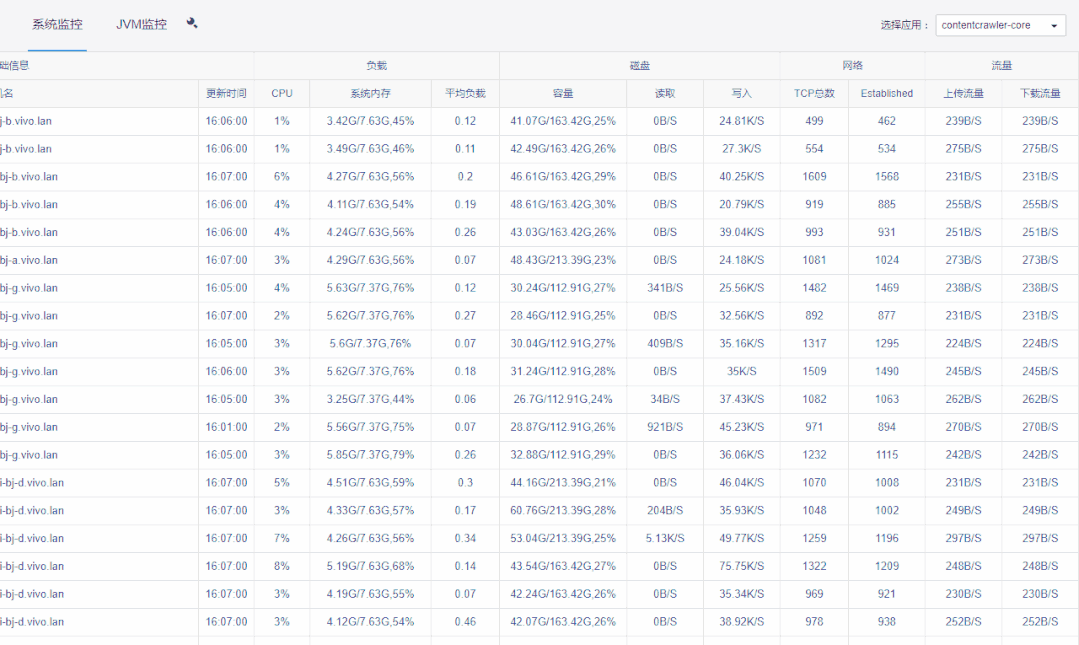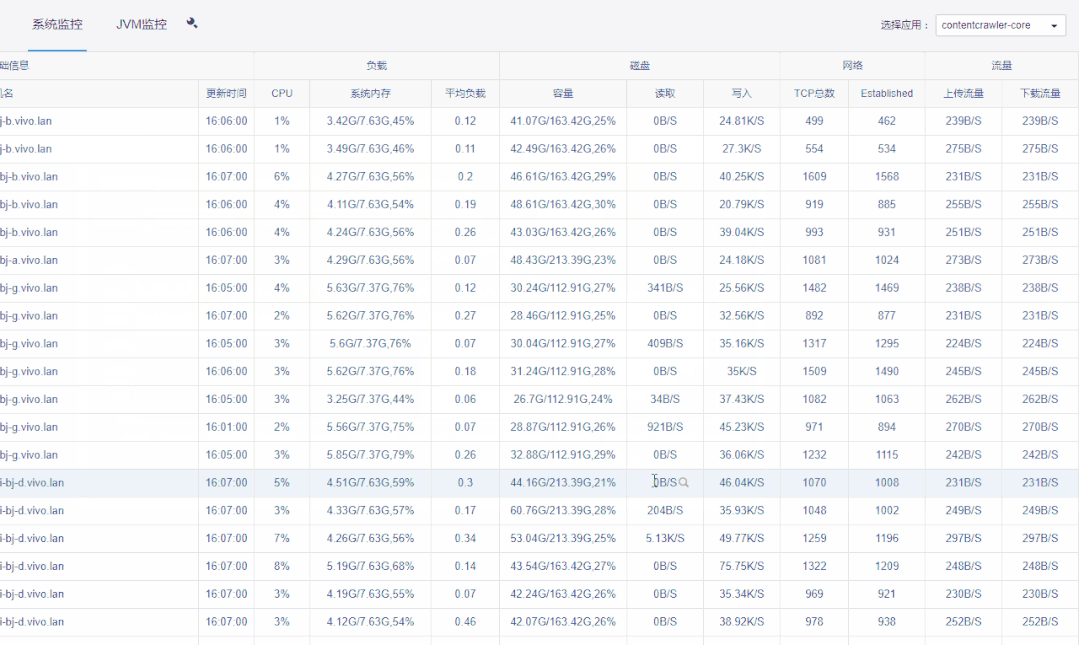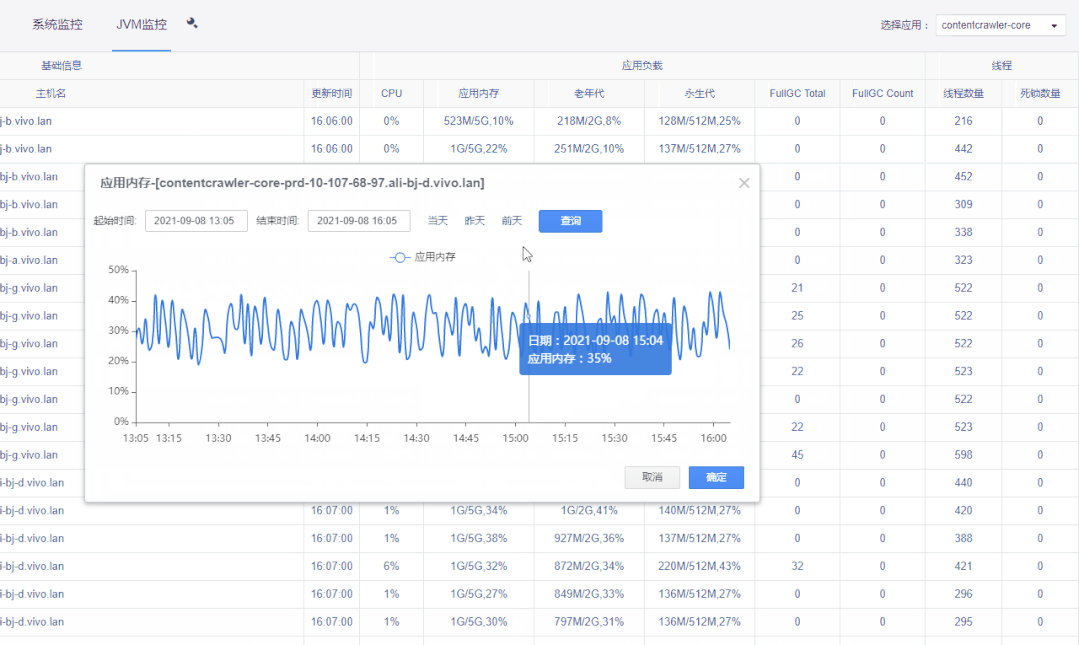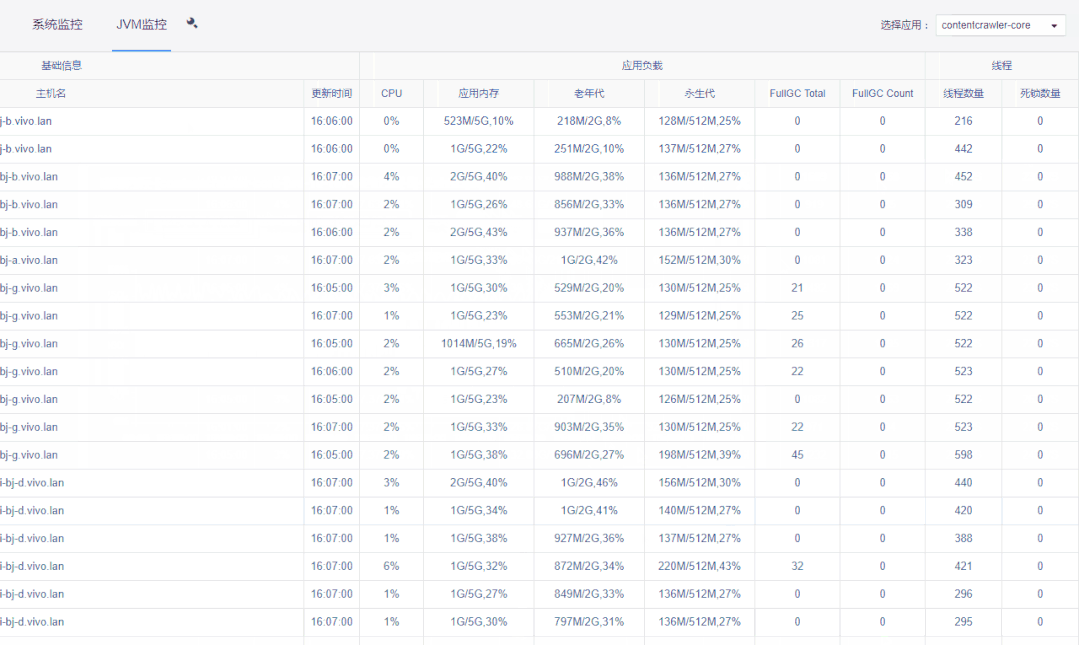
2)如果某行,即某台机器整行显示红色,则代表该机器已逾半小时未上报数据,如机器是非正常下线就要注意排查了。
3)点击详情按钮,可以对系统&JVM监控数据进行明细查询。
单个监控指标(普通)可以针对单个指定Appender的日志文件进行数据采集。
【必填】【指标类型】为“普通”、“复合”两种,复合是将多个普通指标二次聚合,所以正常情况下需要先新增普通指标。
【必填】【图表顺序】正序排列,控制指标图表在数据页面上的展示顺序。
【必填】【指标代码】默认自动生成UUID短码。
【可选】【Appender】为log4j日志文件的appender名称,要求该appender必须被logger的ref引用;如果使用侵入式采集数据则无需指定。
【可选】【关键字】为过滤日志文件行的关键词。
【可选】【分隔符】是指单行日志列分割的符号,一般为","英文逗号或其它符号。
六、主流监控对比
Zabbix 于 1998 年诞生,核心组件采用 C 语言开发,Web 端采用 PHP 开发,它属于老牌监控系统中的优秀代表,能够监控网络参数,服务器健康和软件完整性,使用也很广泛。
Zabbix采用MySQL 进行数据存储,所有没有OpenTSDB支持 Tag的特性,因此没法按多维度进行聚合统计和告警配置,使用起来不灵活。Zabbix 没有提供对应的 SDK,应用层监控支持有限,也没有我们自研的监控提供了侵入式的埋点和采集功能。
总体而言Zabbix 的成熟度更高,高集成度导致灵活性较差,在监控复杂度增加后,定制难度会升高,而且使用的MySQL关系型数据库,对于大规模的监控数据插入和查询是个问题。

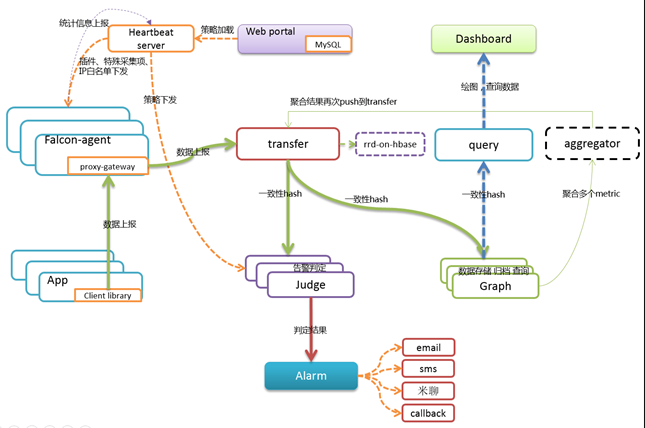
OpenFalcon 是一款企业级、高可用、可扩展的开源监控解决方案,提供实时报警、数据监控等功能,采用 Go 和 Python 语言开发,由小米公司开源。使用 Falcon 可以非常容易的监控整个服务器的状态,比如磁盘空间,端口存活,网络流量等等。基于 Proxy-gateway,很容易通过自主埋点实现应用层的监控(比如监控接口的访问量和耗时)和其他个性化监控需求,集成方便。
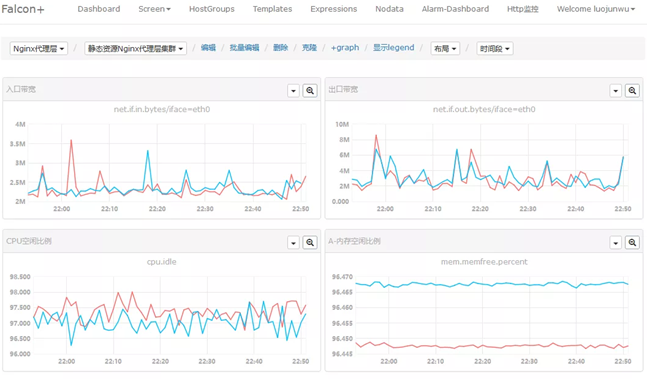
官方的架构图如下:
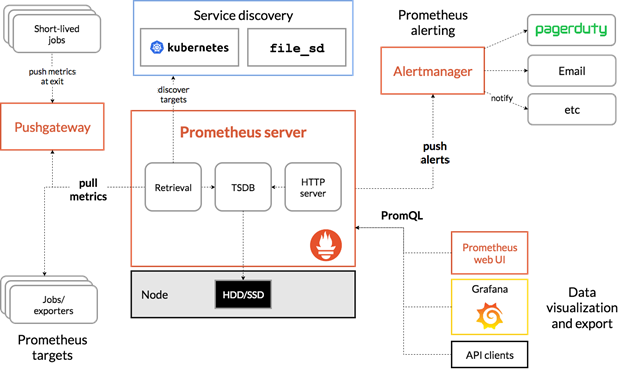
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB),Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
和小米的Open-Falcon一样,借鉴 OpenTSDB,数据模型中引入了 Tag,这样能支持多维度的聚合统计以及告警规则设置,大大提高了使用效率。监控数据直接存储在 Prometheus Server 本地的时序数据库中,单个实例可以处理数百万的 Metrics,架构简单,不依赖外部存储,单个服务器节点可直接工作。
官方的架构图如下:
vmonitor作为监控后台管理系统,可以进行可视化查看,告警的配置,业务指标的配置等,具备JVM监控、系统监控和业务监控的功能。通过采集层(vmonitor-collector采集器)和数据代理层(vmonitor-gateway网关)的队列实现灾时数据最大程度的挽救。
提供了SDK方便业务方集成,支持日志输出过滤和侵入式代码上报数据等应用层监控统计,基于OpenTSDB时序开源数据库,对其源码进行了改造,新增了nimavg函数,配合自带的zimsum函数满足空值插入需求,具有强大的数据聚合能力,可以提供实时、多维度、多渠道的告警服务。
七、总结
本文主要介绍了vivo服务端监控架构的设计与演进之路,是基于java技术栈做的一套实时监控系统,同时也简单列举了行业内主流的几种类型的监控系统,希望有助于大家对监控系统的认识,以及在技术选型时做出更合适的选择。
监控体系里面涉及到的面很广,是一个庞大复杂的体系,本文只是介绍了服务端监控里的JVM监控,系统监控以及业务监控(包含日志监控和工具类代码侵入式上报),未涉及到客户端监控和全链路监控等,如果想理解透彻,必须理论结合实践再做深入。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721