
作者介绍
杨建荣,dbaplus社群联合发起人,竞技世界资深DBA,前搜狐畅游数据库专家,Oracle ACE,腾讯云TVP。具有十余年数据库开发和运维经验,目前专注于开源技术、运维自动化和性能调优。《Oracle/MySQL DBA工作笔记》作者,坚持通过微信、博客进行技术分享,已坚持2200多天。
最近对离线数仓体系进行了扩容和架构改造,也算是一波三折,出了很多小插曲,有一些改进点对我们来说也是真空地带,通过对比和模拟压测总算是得到了预期的结果,这方面尤其值得一提的是郭运凯同学的敬业,很多前置的工作,优化和应用压测的工作都是他完成的。
整体来说,整个事情的背景是因为服务器硬件过保,刚好借着过保服务器替换的机会来做集群架构的优化和改造。
一、集群架构改造的目标
在之前也总结过目前存在的一些潜在问题,也是本次部署架构改进的目标:
1、之前的GP segment数量设计过度,因为资源限制,过多考虑了功能和性能,对于集群的稳定性和资源平衡性考虑有所欠缺,在每个物理机节点上部署了10个Primary,10个Mirror,一旦1个服务器节点不可用,整个集群几乎无法支撑业务。
2、GP集群的存储资源和性能的平衡不够,GP存储基于RAID-5,如果出现坏盘,磁盘重构的代价比较高,而且重构期间如果再出现坏盘,就会非常被动,而且对于离线数仓的数据质量要求较高,存储容量相对不是很大,所以在存储容量和性能的综合之上,我们选择了RAID-10。
3、集群的异常场景的恢复需要完善,集群在异常情况下(如服务器异常宕机,数据节点不可用,服务器后续过保实现节点滚动替换)的故障恢复场景测试不够充分,导致在一些迁移和改造中,相对底气不足,存在一些知识盲区。
4、集群版本过低,功能和性能上存在改进空间。毕竟这个集群是4年前的版本,底层的PG节点的版本也比较旧了,在功能上和性能上都有一定的期望,至少能够与时俱进。
5、操作系统版本升级,之前的操作系统是基于CentOS6,至少需要适配CentOS 7 。
6、集群TPCH压测验收,集群在完成部署之后,需要做一次整体的TPCH压测验收,如果存在明显的问题需要不断调整配置和架构,使得达到预期的性能目标。
此外在应用层面也有一些考虑,总而言之,是希望能够解决绝大多数的痛点问题,无论是在系统层面,还是应用层面,都能上一个台阶。
二、集群规划设计的选型和思考
明确了目标,就是拆分任务来规划设计了,在规划设计方面主要有如下的几个问题:
1、Greenplum的版本选择,目前有两个主要的版本类别,一个是开源版(Open Source distribution)和Pivotal官方版,它们的其中一个差异就是官方版需要注册,签署协议,在此基础上还有GPCC等工具可以用,而开源版本可以实现源码编译或者rpm安装,无法配置GPCC。综合来看,我们选择了开源版本的6.16.2,这其中也询问了一些行业朋友,特意选择了几个涉及稳定性bug修复的版本。
2、数据集市的技术选型,在数据集市的技术选型方面起初我是比较坚持基于PostgreSQL的模式,而业务侧是希望对于一些较为复杂的逻辑能够通过GP去支撑,一来二去之后,加上我咨询了一些行业朋友的意见,是可以选择基于GP的方案,于是我们就抱着试一试的方式做了压测,所以数据仓库和和数据集市会是两个不同规模体量的GP集群来支撑。
3、GP的容量规划,因为之前的节点设计有些过度,所以在数量上我们做了缩减,每台服务器部署12个segment节点,比如一共12台服务器,其中有10台服务器是Segment节点,每台上面部署了6个Primary,6个Mirror,另外2台部署了Master和Standby,就是即(6+6)*10+2,整体的配置情况类似下面的模式。
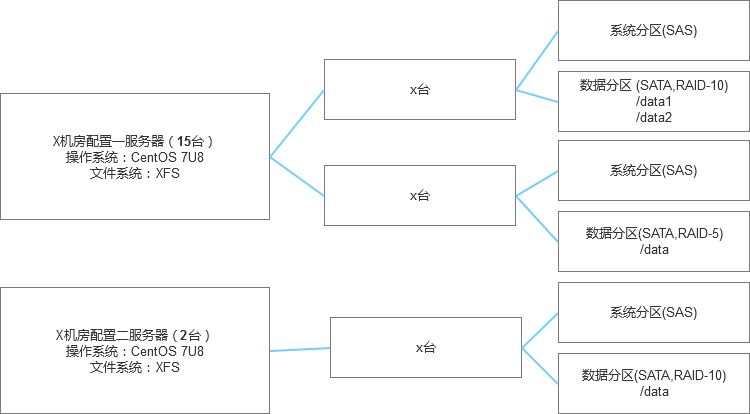
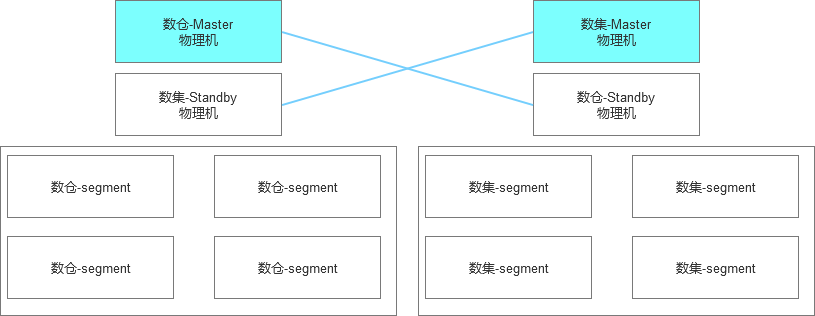
4、部署架构方案选型,部署架构想起来比较容易,但是落实起来有很多的考虑细节,起初考虑GP的Master和Standby节点如果混用还是能够节省一些资源,所以设计的数据仓库和数据集市的部署架构是这样考虑的,但是从走入部署阶段之后,很快就发现这种交叉部署的模式是不可行的,或者说有一些复杂度。
除此之外,在单个GP集群的部署架构层面,还有4类方案考虑。
方案1:Master,Standby和segment混合部署
方案2:Master,Standby和segment独立部署,整个集群的节点数会少一些
方案3:Segment独立部署,Master,Standby虚拟机部署
方案4:最小化单节点集群部署(这是数据集市最保底的方案)
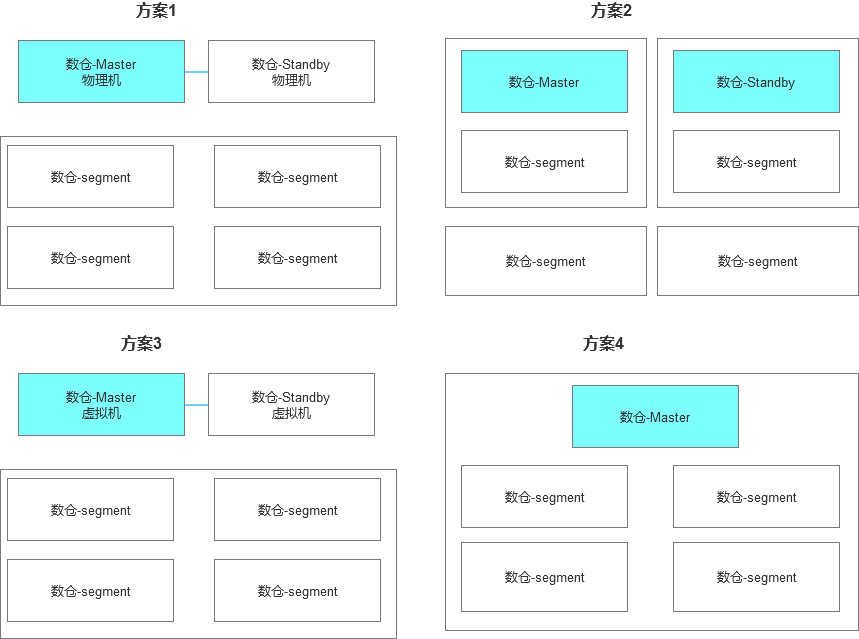
这方面存在较大的发挥空间,而且总体来说这种验证磨合的成本也相对比较高,实践给我上了一课,越是想走捷径,越是会让你走一些弯路,而且有些时候的优化其实我也不知道改怎么往下走,感觉已经无路可走,所以上面这4种方案其实我们都做了相关的测试和验证。
三、集群架构的详细设计和实践
1、设计详细的部署架构图
在整体规划之上,我设计了如下的部署架构图,每个服务器节点有6个Primary,6个Mirror,服务器两两映射。

2、内核参数优化
按照官方文档的建议和具体的配置情况,我们对内核参数做了如下的配置:
vm.swappiness=10vm.zone_reclaim_mode = 0vm.dirty_expire_centisecs = 500vm.dirty_writeback_centisecs = 100vm.dirty_background_ratio = 0 # See System Memoryvm.dirty_ratio = 0vm.dirty_background_bytes = 1610612736vm.dirty_bytes = 4294967296vm.min_free_kbytes = 3943084vm.overcommit_memory=2kernel.sem = 500 2048000 200 4096
四、集群部署步骤
1、首先是配置/etc/hosts,需要把所有节点的IP和主机名都整理出来。
2、配置用户,很常规的步骤
groupadd gpadminuseradd gpadmin -g gpadminpasswd gpadmin
3、配置sysctl.conf和资源配置
4、使用rpm模式安装
# yum install -y apr apr-util bzip2 krb5-devel zip# rpm -ivh open-source-greenplum-db-6.16.2-rhel7-x86_64.rpm
5、配置两个host文件,也是为了后面进行统一部署方便,在此建议先开启gpadmin的sudo权限,可以通过gpssh处理一些较为复杂的批量操作
6、通过gpssh-exkeys来打通ssh信任关系,这里需要吐槽这个ssh互信,端口还得是22,否则处理起来很麻烦,需要修改/etc/ssh/sshd_config文件
gpssh-exkeys -f hostlist
7、较为复杂的一步是打包master的Greenplum-db-6.16.2软件,然后分发到各个segment机器中,整个过程涉及文件打包,批量传输和配置,可以借助gpscp和gpssh,比如gpscp传输文件,如下的命令会传输到/tmp目录下
gpscp -f /usr/local/greenplum-db/conf/hostlist /tmp/greenplum-db-6.16.2.tar.gz =:/tmp
或者说在每台服务器上面直接rpm -ivh安装也可以。
8、Master节点需要单独配置相关的目录,而Segment节点的目录可以提前规划好,比如我们把Primary和Mirror放在不同的分区。
mkdir -p /data1/gpdata/gpdatap1mkdir -p /data1/gpdata/gpdatap2mkdir -p /data2/gpdata/gpdatam1mkdir -p /data2/gpdata/gpdatam2
9、整个过程里最关键的就是gpinitsystem_config配置了,因为Segment节点的ID配置和命名,端口区间都是根据一定的规则来动态生成的,所以对于目录的配置需要额外注意。
10、部署GP集群最关键的命令是
gpinitsystem -c gpinitsystem_config -s 【standby_hostname】
其中文件gpinitsystem_config的主要内容如下:
MASTER_HOSTNAME=xxxxdeclare -a DATA_DIRECTORY=(/data1/gpdata/gpdatap1 /data1/gpdata/gpdatap2 /data1/gpdata/gpdatap3 /data1/gpdata/gpdatap4 /data1/gpdata/gpdatap5 /data1/gpdata/gpdatap6)TRUSTED_SHELL=sshdeclare -a MIRROR_DATA_DIRECTORY=(/data2/gpdata/gpdatam1 /data2/gpdata/gpdatam2 /data2/gpdata/gpdatam3 /data2/gpdata/gpdatam4 /data2/gpdata/gpdatam5 /data2/gpdata/gpdatam6)MACHINE_LIST_FILE=/usr/local/greenplum-db/conf/seg_hosts
整个过程大约5分钟~10分钟以内会完成,在部署过程中建议要查看后端的日志查看是否有异常,异常情况下的体验不是很好,可能会白等。
五、集群部署问题梳理
集群部署中还是有很多细节的问题,太基础的就不提了,基本上就是配置,目录权限等问题,我提另外几个:
1、资源配置问题,如果/etc/security/limits.conf的资源配置不足会在安装时有如下的警告:
gpinitsystem:xxxx:gpadmin-[WARN]:-Standby Master open file limit is 51200 should be >= 65535
2、网络问题,集群部署完成后可以正常操作,但是在查询数据的时候会抛出错误,比如SQL是这样的,看起来很简单:select count(*) from customer,但是会抛出如下的错误:
WARNING: interconnect may encountered a network error, please check your network (seg9 slice1 xxxx:6003 pid=268865)DETAIL: Failed to send packet (seq 1) to 127.0.0.1:3106 (pid 65933 cid 4) after 100 retries.WARNING: interconnect may encountered a network error, please check your network (seg6 slice1 xxxx:6000 pid=268862)
这个问题的主要原因还是和防火墙配置相关,其实不光需要配置INPUT的权限,还需要配置OUTPUT的权限。
对于数据节点可以开放略大的权限,如:
入口的配置:
-A INPUT -p all -s xxxxx -j ACCEPT
出口的配置:
-A OUTPUT -p all -s xxxxx -j ACCEPT
3、网络配置问题,这个问题比较诡异的是,报错和上面是一样的,但是在排除了防火墙配置后,select count(*) from customer;这样的语句是可以执行的,但是执行的等待时间较长,比如表lineitem这表比较大,过亿的数据量,,在10个物理节点时,查询响应时间是10秒,但是4个物理节点,查询响应时间是在90秒,总体删感觉说不过去。
为了排查网络问题,使用gpcheckperf等工具也做过测试,4节点和10节点的基础配置也是相同的。
gpcheckperf -f /usr/local/greenplum-db/conf/seg_hosts -r N -d /tmp$ cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6#127.0.0.1 test-dbs-gp-128-230xxxxx.128.238 test-dbs-gp-svr-128-238xxxxx.128.239 test-dbs-gp-svr-128-239
其中127.0.0.1的这个配置在segment和Master,Standby混部的情况是存在问题的,修正后就没问题了,这个关键的问题也是郭运凯同学发现的。
六、集群故障恢复的测试
集群的故障测试是本次架构设计中的重点内容,所以这一块也是跃跃欲试。
整体上我们包含两个场景,服务器宕机修复后的集群恢复和服务器不可用时的恢复方式。
第一种场景相对比较简单,就是让Segment节点重新加入集群,并且在集群层面将Primary和Mirror的角色互换,而第二种场景相对时间较长一些,主要原因是需要重构数据节点,这个代价基本就就是PG层面的数据恢复了,为了整个测试和恢复能够完整模拟,我们采用了类似的恢复方式,比如宕机修复使用了服务器重启来替代,而服务器不可用则使用了清理数据目录,类似于一台新配置机器的模式。
1、服务器宕机修复后集群恢复
重启前检查
重启服务器
检查集群节点状态
select * from gp_segment_configuration where status!='u';
修复集群节点
gprecoverseg -o ./recov
切换集群节点角色
gprecoverseg -r
检查复核
select * from gp_segment_configuration where status='u'
2、服务器不可用时集群恢复
重启前检查,主要包括系统配置,存储的检查
重启服务器
重建数据目录
重建数据节点
gprecoverseg -F
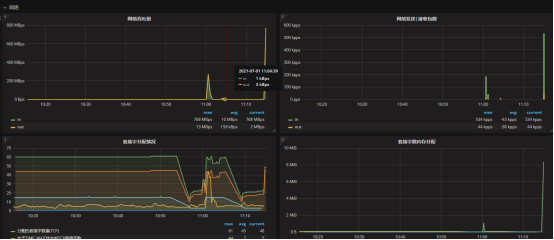
重构数据节点的过程中,总体来看网络带宽还是使用很充分的。
检查复核
select * from gp_segment_configuration where status='u'select * from gp_segment_configuration where status='u' and role!=preferred_role;
切换集群节点角色
gprecoverseg -r
检查复核
select * from gp_segment_configuration where status='u' and role!=preferred_role;
经过测试,重启节点到数据修复,近50G数据耗时3分钟左右
七、集群优化问题梳理
1、部署架构优化和迭代
对于优化问题,是本次测试中尤其关注,而且争议较多的部分。
首先在做完初步选型后,数仓体系的部署相对是比较顺利的,采用的是第一套方案。

数据集市的集群部分因为节点相对较少,所以就选用了第二套方案
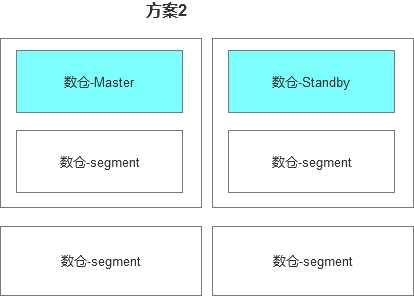
实际测试的过程,因为配置问题导致TPCH的结果没有达到预期。
所以这个阶段也产生了一些疑问和怀疑,一种就是折回第一种方案,但是节点数会少很多,要不就是第三种采用虚拟机的模式部署,最保底的方案则是单节点部署,当然这是最牵强的方案。
这个阶段确实很难,而在上面提到的修复了配置之后,集群好像突然开悟了一般,性能表现不错,很快就完成了100G和1T数据量的TPCH测试。
在后续的改造中,我们也尝试了第三套方案,基于虚拟机的模式,通过测试发现,远没有我们预期的那么理想,在同样的数据节点下,Master和Standby采用物理机和虚拟机,性能差异非常大,这个是出乎我们预料的。比如同样的SQL,方案3执行需要2秒,而方案2则需要80秒,这个差异我们对比了很多指标,最后我个人理解差异还是在网卡部分。
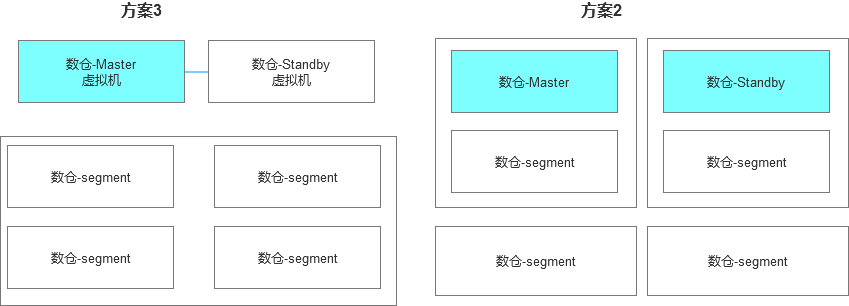
所以经过对比后,还是选择了方案2的混合部署模式。
2、SQL性能优化的分析
此外整个过程的TPCH也为集群的性能表现提供了参考。比如方案2的混合部署模式下,有一条SQL需要18秒,但是相比同类型的集群,可能就只需要2秒钟左右,这块显然是存在问题的。
在排除了系统配置,硬件配置的差异之后,经典的解决办法还是查看执行计划。
性能较差的SQL执行计划:
# explain analyze select count(*)from customer;QUERY PLAN=0.00..431.00 rows=1 width=8) (actual time=24792.916..24792.916 rows=1 loops=1):1 (slice1; segments: 36) (cost=0.00..431.00 rows=1 width=1) (actual time=3.255..16489.394 rows=150000000 loops=1)=0.00..431.00 rows=1 width=1) (actual time=0.780..1267.878 rows=4172607 loops=1): 4.466 ms: 680K bytes.: 218K bytes avg x 36 workers, 218K bytes max (seg0).: 2457600kBOptimizer: Pivotal Optimizer (GPORCA): 24832.611 msrows)Time: 24892.500 ms
性能较好的SQL执行计划:
# explain analyze select count(*)from customer;QUERY PLAN=0.00..842.08 rows=1 width=8) (actual time=1519.311..1519.311 rows=1 loops=1):1 (slice1; segments: 36) (cost=0.00..842.08 rows=1 width=8) (actual time=634.787..1519.214 rows=36 loops=1)=0.00..842.08 rows=1 width=8) (actual time=1473.296..1473.296 rows=1 loops=1)=0.00..834.33 rows=4166667 width=1) (actual time=0.758..438.319 rows=4172607 loops=1): 5.033 ms: 176K bytes.: 234K bytes avg x 36 workers, 234K bytes max (seg0).: 2457600kBOptimizer: Pivotal Optimizer (GPORCA): 1543.611 msrows)Time: 1549.324 ms
很明显执行计划是被误导了,而误导的因素则是基于统计信息,这个问题的修复很简单:
analyze customer;
但是深究原因,则是在压测时,先是使用了100G压测,压测完之后保留了原来的表结构,直接导入了1T的数据量,导致执行计划这块没有更新。
3、集群配置优化
此外也做了一些集群配置层面的优化,比如对缓存做了调整。
gpconfig -c statement_mem -m 2457600 -v 2457600gpconfig -c gp_vmem_protect_limit -m 32000 -v 32000
八、集群优化数据
最后来感受下集群的性能:
1、10个物理节点,(6+6)*10+2
tpch_1t=# \timing onTiming is on.tpch_1t=# select count(*)from customer;count-----------150000000(1 row)Time: 1235.801 mstpch_1t=# select count(*)from lineitem;count------------5999989709(1 row)Time: 10661.756 ms
2、6个物理节点,(6+6)*6
# select count(*)from customer;count-----------150000000row)Time: 1346.833 ms# select count(*)from lineitem;count------------5999989709row)Time: 18145.092 ms
3、4个物理节点,(6+6)*4
# select count(*)from customer;count-----------150000000row)Time: 1531.621 ms# select count(*)from lineitem;count------------5999989709row)Time: 25072.501 ms
4、TPCH在不同架构模式下的性能比对,有19个查询模型,有个别SQL逻辑过于复杂暂时忽略,也是郭运凯同学整理的列表。
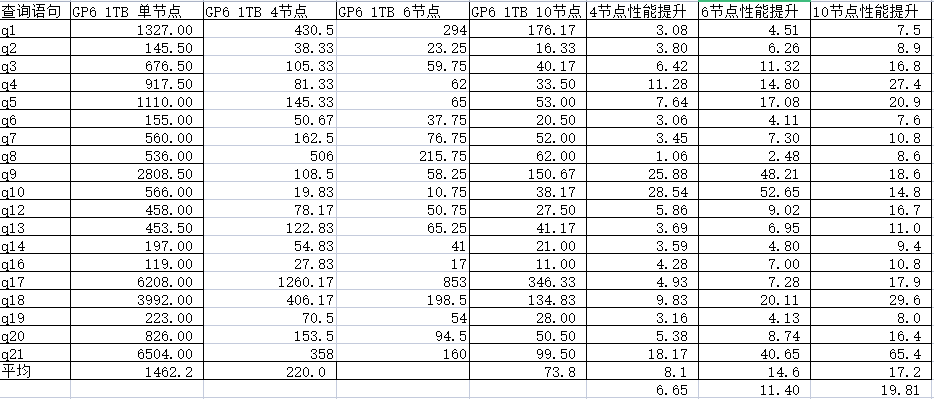
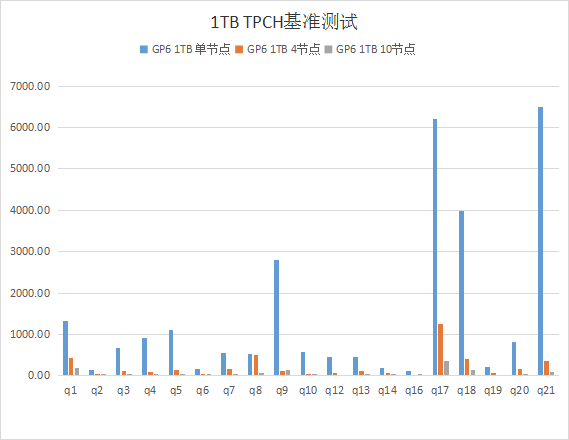
在1T基准下的基准测试表现:
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721