
胡争(子毅),阿里巴巴技术专家,目前主要负责Flink数据湖方案的设计和开发工作,Apache Iceberg及Apache Flink项目的长期活跃贡献者,《HBase原理与实践》作者。
Apache Flink 是大数据领域非常流行的流批统一的计算引擎,数据湖是顺应云时代发展潮流的新型技术架构。那么当 Apache Flink 遇见数据湖时,会碰撞出什么样的火花呢?本次分享主要包括以下核心内容:
数据湖的相关背景介绍;
经典业务场景介绍;
为什么选择 Apache Iceberg;
如何通过 Flink+Iceberg 实现流式入湖
社区未来规划工作。
视频回顾:https://www.bilibili.com/video/BV14A411J7e6?p=4
数据湖是个什么概念呢?一般来说我们把一家企业产生的数据都维护在一个平台内,这个平台我们就称之为“数据湖”。
看下面这幅图,这个湖的数据来源多种多样,有的可能是结构化数据,有的可能是非结构数据,有的甚至是二进制数据。有一波人站在湖的入口,用设备在检测水质,这对应着数据湖上的流处理作业;有一批抽水机从湖里面抽水,这对应着数据湖的批处理作业;还有一批人在船头钓鱼或者在岸上捕鱼,这对应着数据科学家从数据湖中通过机器学习的手段来提取数据价值。
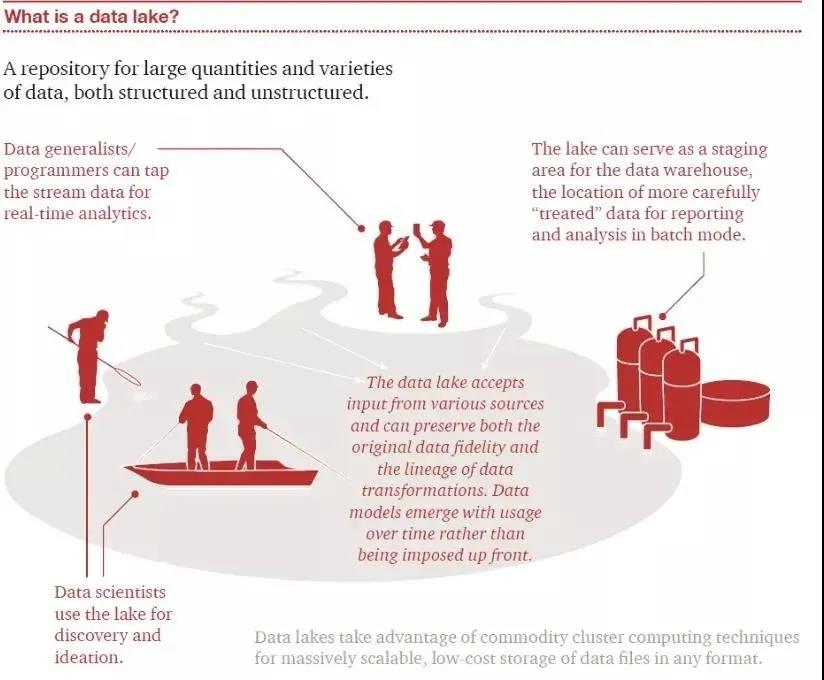
我们总结起来,其实数据湖主要有 4 个方面的特点:
第一个特点是存储原始数据,这些原始数据来源非常丰富;
第二个特点是支持多种计算模型;
第三个特点是有完善的数据管理能力,要能做到多种数据源接入,实现不同数据之间的连接,支持 schema 管理和权限管理等;
第四个特点是灵活的底层存储,一般用 ds3、oss、hdfs 这种廉价的分布式文件系统,采用特定的文件格式和缓存,满足对应场景的数据分析需求。

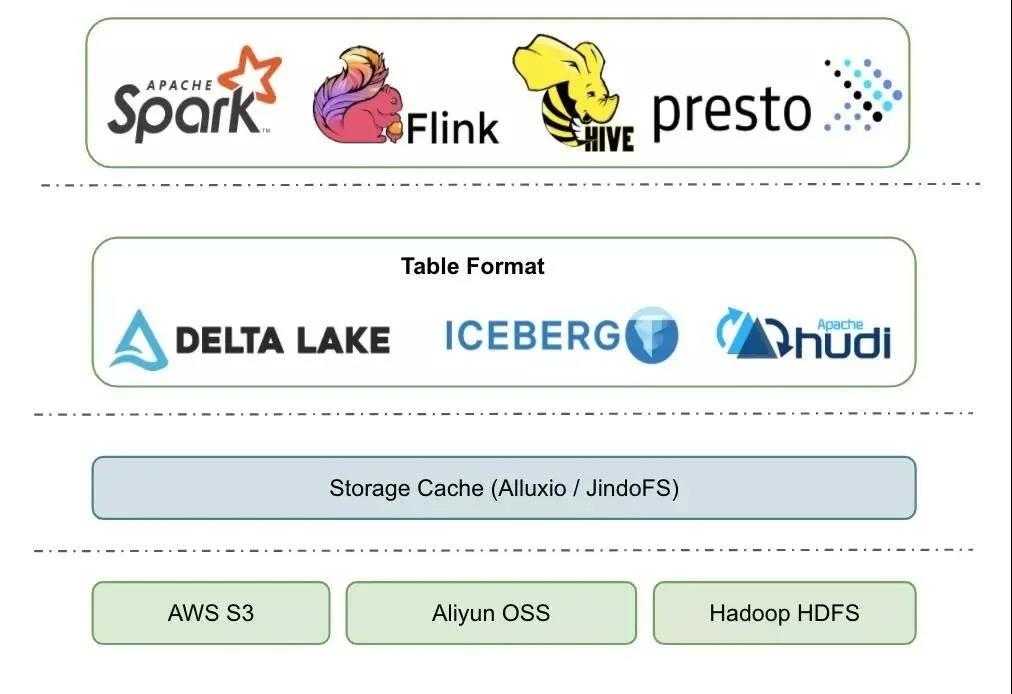
那么开源数据湖架构一般是啥样的呢?这里我画了一个架构图,主要分为四层:
最底下是分布式文件系统,云上用户 S3 和 oss 这种对象存储会用的更多一些,毕竟价格便宜很多;非云上用户一般采用自己维护的 HDFS。
第二层是数据加速层。数据湖架构是一个存储计算彻底分离的架构,如果所有的数据访问都远程读取文件系统上的数据,那么性能和成本开销都很大。如果能把经常访问到的一些热点数据缓存在计算节点本地,这就非常自然的实现了冷热分离,一方面能收获到不错的本地读取性能,另一方面还节省了远程访问的带宽。这一层里面,我们一般会选择开源的 alluxio,或者选择阿里云上的 Jindofs。
第三层就是 Table format 层,主要是把一批数据文件封装成一个有业务意义的 table,提供 ACID、snapshot、schema、partition 等表级别的语义。一般对应这开源的 Delta、Iceberg、Hudi 等项目。对一些用户来说,他们认为Delta、Iceberg、Hudi 这些就是数据湖,其实这几个项目只是数据湖这个架构里面的一环,只是因为它们离用户最近,屏蔽了底层的很多细节,所以才会造成这样的理解。
最上层就是不同计算场景的计算引擎了。开源的一般有 Spark、Flink、Hive、Presto、Hive MR 等,这一批计算引擎是可以同时访问同一张数据湖的表的。
那么,Flink 和数据湖结合可以有哪些经典的应用场景呢?这里我们探讨业务场景时默认选型了 Apache Iceberg 来作为我们的数据湖选型,后面一节会详细阐述选型背后的理由。
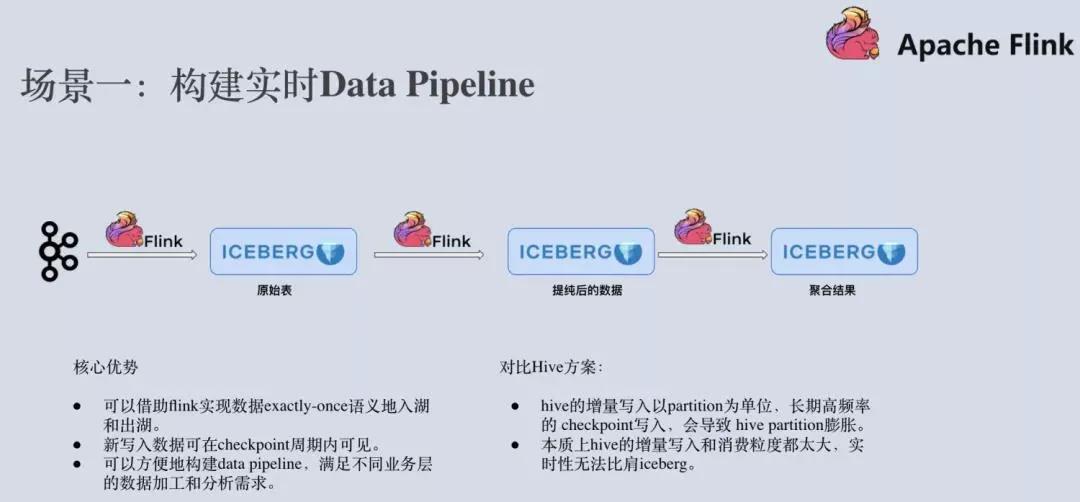
首先,Flink+Iceberg 最经典的一个场景就是构建实时的 Data Pipeline。业务端产生的大量日志数据,被导入到 Kafka 这样的消息队列。运用 Flink 流计算引擎执行 ETL后,导入到 Apache Iceberg 原始表中。
有一些业务场景需要直接跑分析作业来分析原始表的数据,而另外一些业务需要对数据做进一步的提纯。那么我们可以再新起一个 Flink 作业从 Apache Iceberg 表中消费增量数据,经过处理之后写入到提纯之后的 Iceberg 表中。
此时,可能还有业务需要对数据做进一步的聚合,那么我们继续在iceberg 表上启动增量 Flink 作业,将聚合之后的数据结果写入到聚合表中。
有人会想,这个场景好像通过 Flink+Hive 也能实现。Flink+Hive 的确可以实现,但写入到 Hive 的数据更多地是为了实现数仓的数据分析,而不是为了做增量拉取。
一般来说,Hive 的增量写入以 partition 为单位,时间是 15min 以上,Flink 长期高频率地写入会造成 partition 膨胀。而 Iceberg 容许实现 1 分钟甚至 30秒的增量写入,这样就可以大大提高了端到端数据的实时性,上层的分析作业可以看到更新的数据,下游的增量作业可以读取到更新的数据。
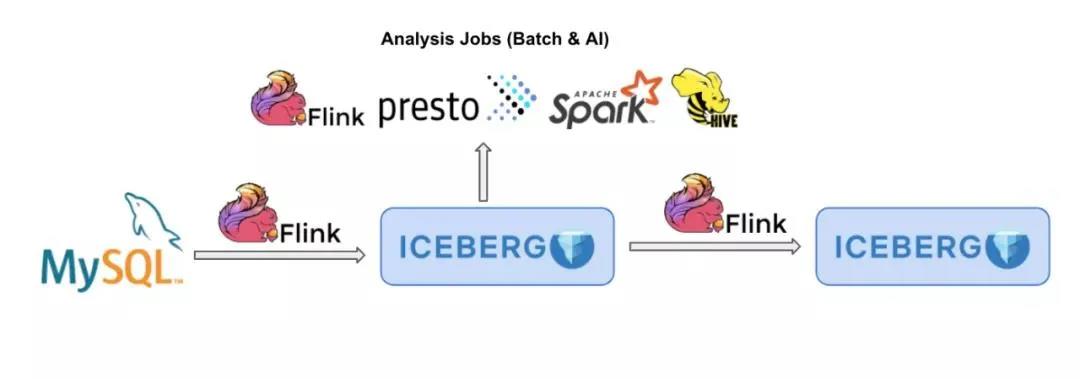
第二个经典的场景,就是可以用 Flink+Iceberg 来分析来自 MySQL 等关系型数据库的 binlog 等。
一方面,Apache Flink 已经原生地支持 CDC 数据解析,一条 binlog 数据通过 ververica flink-cdc-connector 拉取之后,自动转换成 Flink Runtime 能识别的 INSERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER 四种消息,供用户做进一步的实时计算。
另外一方面,Apache Iceberg 已经较为完善地实现了 equality delete 功能,也就是用户定义好待删除的 Record,直接写到 Apache Iceberg 表内就可以删除对应的行,本身就是为了实现数据湖的流式删除。在 Iceberg 未来的版本中,用户将不需要设计任何额外的业务字段,不用写几行代码就可以完成 binlog 流式入湖到 Apache Iceberg(社区的这个 Pull Request 已经提供了一个 flink 写入 CDC 数据的原型)。
此外,CDC 数据成功入湖 Iceberg 之后,我们还会打通常见的计算引擎,例如 Presto、Spark、Hive 等,他们都可以实时地读取到 Iceberg 表中的最新数据。

第三个经典场景是近实时场景的流批统一。在常用的 lambda 架构中,我们有一条实时链路和一条离线链路。实时链路一般由 Flink、Kafka、HBase 这些组件构建而成,而离线链路一般会用到 Parquet、Spark 等组件构建。这里面涉及到计算组件和存储组件都非常多,系统维护成本和业务开发成本都非常高。
有很多场景,他们的实时性要求并没有那么苛刻,例如可以放松到分钟级别,这种场景我们称之为近实时场景。那么,我们是不是可以通过 Flink + Iceberg 来优化我们常用的 lambda 架构呢?
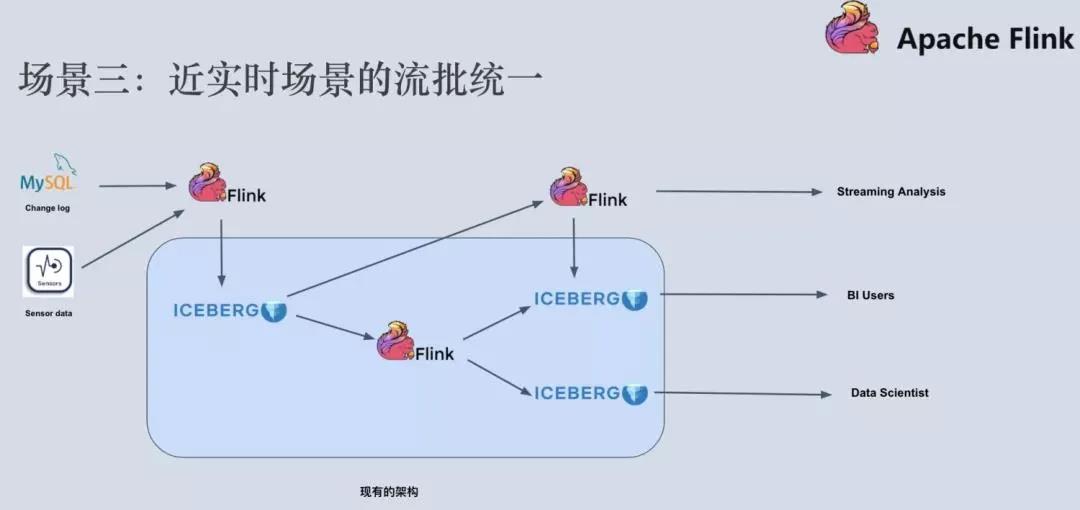
我们可以用 Flink+Iceberg 把整个架构优化成上图所示。实时的数据通过 Flink 写入到 Iceberg 表中,近实时链路依然可以通过flink计算增量数据,离线链路也可以通过 flink 批计算读取某个快照做全局分析,得到对应的分析结果,供不同场景下的用户读取和分析。经过这种改进之后,我们把计算引擎统一成了 Flink,把存储组件统一成了 Iceberg,整个系统的维护开发成本大大降低。
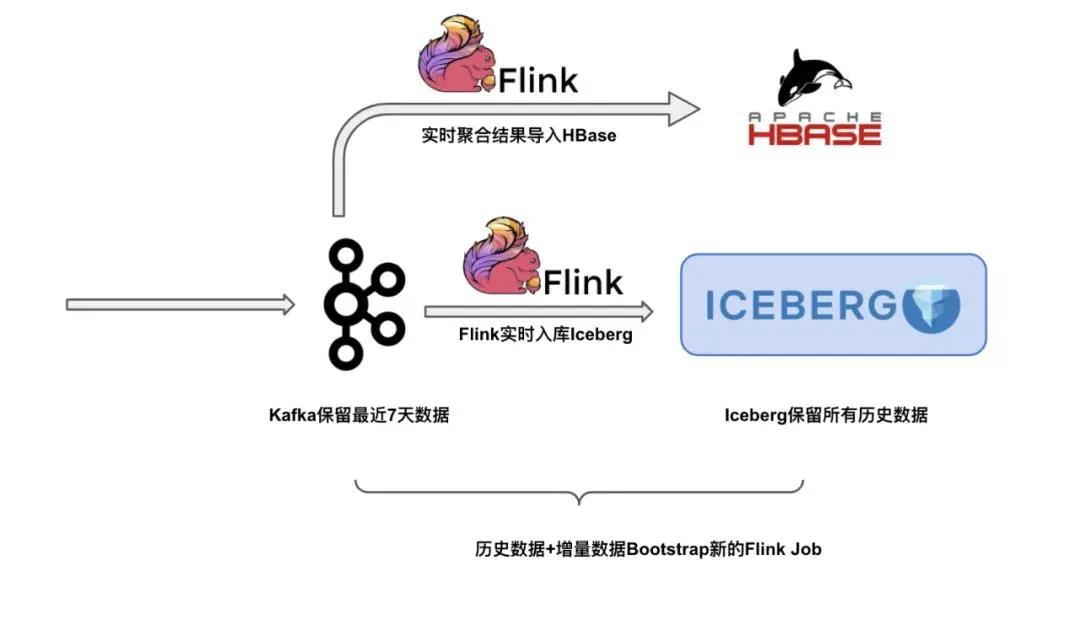
第四个场景,是采用 Iceberg 全量数据和 Kafka 的增量数据来 Bootstrap 新的 Flink 作业。我们现有的流作业在线上跑着,突然有一天某个业务方跑过来说,他们遇到一个新的计算场景,需要设计一个新的 Flink 作业,跑一遍去年一年的历史数据,跑完之后再对接到正在产生的 Kafka 增量数据。那么这时候应该怎么办呢?
我们依然可以采用常见的 lambda 架构,离线链路通过 kafka->flink->iceberg 同步写入到数据湖,由于 Kafka 成本较高,保留最近 7 天数据即可,Iceberg 存储成本较低,可以存储全量的历史数据(按照 checkpoint 拆分成多个数据区间)。启动新 Flink 作业的时候,只需要去拉 Iceberg 的数据,跑完之后平滑地对接到 kafka 数据即可。
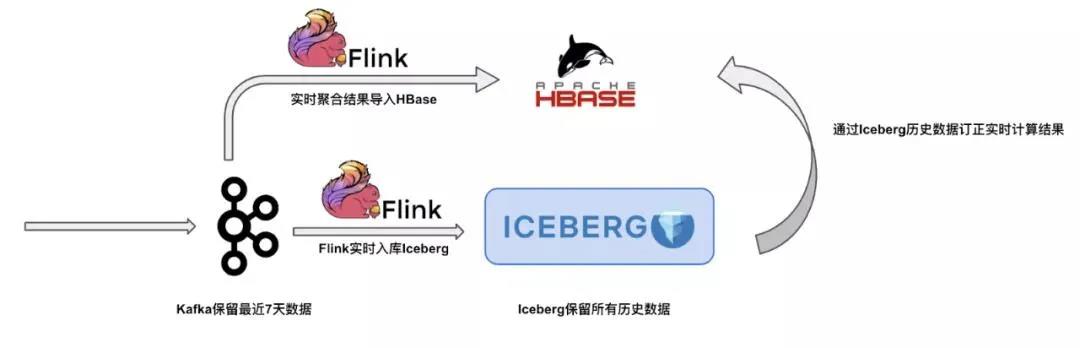
第五个场景和第四个场景有点类似。同样是在 lambda 架构下,实时链路由于事件丢失或者到达顺序的问题,可能导致流计算端结果不一定完全准确,这时候一般都需要全量的历史数据来订正实时计算的结果。而我们的 Iceberg 可以很好地充当这个角色,因为它可以高性价比地管理好历史数据。
回到上一节遗留的一个问题,为什么当时 Flink 在众多开源数据湖项目中会选择 Apache Iceberg 呢?
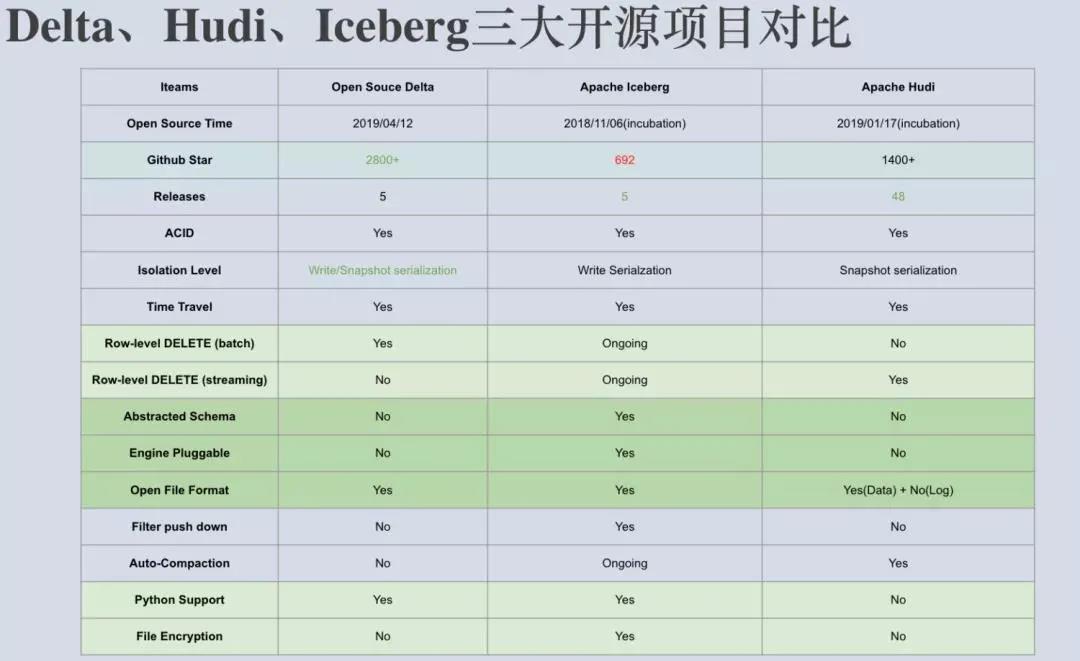
我们当时详细地调研了 Delta、Hudi、Iceberg 三个开源项目,并写了一篇调研报告。我们发现 Delta 和 Hudi 跟 Spark 的代码路径绑定太深,尤其是写入路径。毕竟当时这两个项目设计之初,都多多少少把 Spark 作为的他们默认的计算引擎了。而Apache Iceberg 的方向非常坚定,宗旨就是要做一个通用化设计的 Table Format。
因此,它完美地解耦了计算引擎和底下的存储系统,便于接入多样化计算引擎和文件格式,可以说正确地完成了数据湖架构中的 Table Format 这一层的实现。我们认为它也更容易成为 Table Format 层的开源事实标准。
另外一方面,Apache Iceberg 正在朝着流批一体的数据湖存储层发展,manifest 和snapshot 的设计,有效地隔离不同 transaction 的变更,非常方便批处理和增量计算。而我们知道 Apache Flink 已经是一个流批一体的计算引擎,可以说这二者的长远规划完美匹配,未来二者将合力打造流批一体的数据湖架构。
最后,我们还发现 Apache Iceberg 这个项目背后的社区资源非常丰富。在国外, Netflix、Apple、Linkedin、Adobe 等公司都有 PB 级别的生产数据运行在 Apache Iceberg 上;在国内,腾讯这样的巨头也有非常庞大的数据跑在 Apache Iceberg 之上,他们最大的一个业务每天有几十T的增量数据写入到 Apache Iceberg。社区成员同样非常资深和多样化,拥有来自其他项目的 7 位 Apache PMC,1 为 VP。
体现在代码和设计的 review 上,就变得非常苛刻,一个稍微大一点的 PR 涉及 100+ 的comment 很常见。在我个人看来,这些都使得 Apache Iceberg 的设计+代码质量比较高。
正是基于以上考虑,Apache Flink 最终选择了 Apache Iceberg 作为第一个数据湖接入项目。
目前,我们已经在 Apache Iceberg 0.10.0 版本上实现 Flink 流批入湖功能,同时还支持 Flink 批作业查询 Iceberg 数据湖的数据。具体关于 Flink 如何读写 Apache Iceberg 表,可以参考 Apache Iceberg 社区的使用文档,这里不再赘述。
https://github.com/apache/iceberg/blob/master/site/docs/flink.md
下面来简要阐述下 Flink iceberg sink 的设计原理:由于 Iceberg 采用乐观锁的方式来实现 Transaction 的提交,也就是说两个人同时提交更改事务到 Iceberg 时,后开始的一方会不断重试,等先开始的一方顺利提交之后再重新读取 metadata 信息提交 transaction。考虑到这一点,采用多个并发算子去提交 transaction 是不合适的,容易造成大量事务冲突,导致重试。
所以,我们把 Flink 写入流程拆成了两个算子,一个叫做 IcebergStreamWriter,主要用来写入记录到对应的 avro、parquet、orc 文件,生成一个对应的 Iceberg DataFile,并发送给下游算子;另外一个叫做 IcebergFilesCommitter,主要用来在 checkpoint 到来时把所有的 DataFile 文件收集起来,并提交 Transaction 到 Apache iceberg,完成本次 checkpoint 的数据写入。
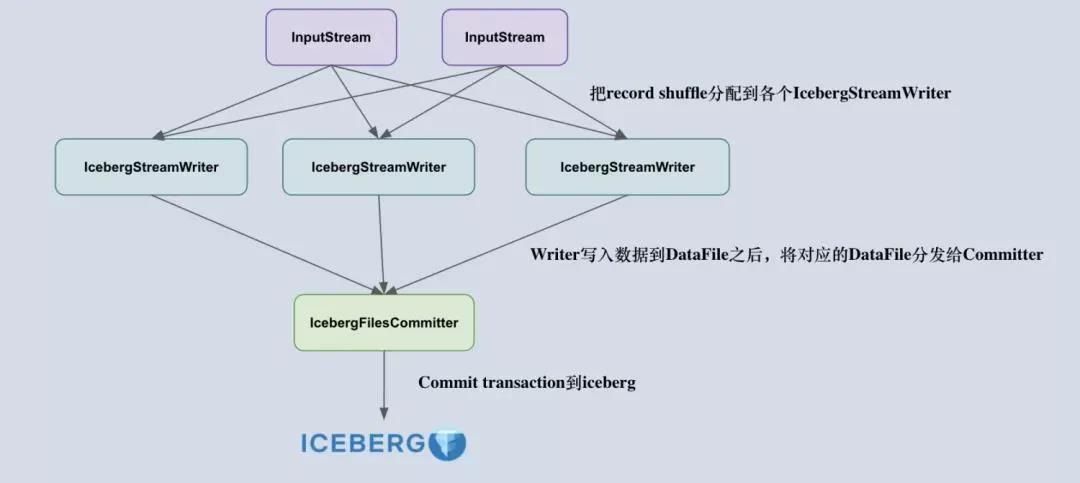
理解了 Flink Sink 算子的设计后,下一个比较重要的问题就是:如何正确地设计两个算子的 state ?
首先,IcebergStreamWriter 的设计比较简单,主要任务是把记录转换成 DataFile,并没有复杂的 State 需要设计。IcebergFilesCommitter 相对复杂一点,它为每个checkpointId 维护了一个 DataFile 文件列表,即 map<Long, List<DataFile>>,这样即使中间有某个 checkpoint的transaction 提交失败了,它的 DataFile 文件仍然维护在 State 中,依然可以通过后续的 checkpoint 来提交数据到 Iceberg 表中。
Apache Iceberg 0.10.0 版本的发布,已经拉开集成 Flink 和 Iceberg 的序幕。在未来的 Apache Iceberg 0.11.0 和 0.12.0 版本中,我们规划了更多高级功能及特性。
对于 Apache 0.11.0 版本来说,主要解决两个问题:
第一个事情是小文件合并的问题,当然 Apache Iceberg 0.10.0 版本已经支持了Flink 批作业定时去合并小文件,这个功能还相对较为初级。在 0.11.0 版本中,我们将设计自动合并小文件功能,简单来说就是在 Flink checkpoint 到达,触发 Apache Iceberg transaction 提交后,有一个专门的算子,专门负责处理小文件的合并工作。
第二个事情是 Flink streaming reader 的开发,目前我们已经在私有仓库做了一些 PoC 工作,在未来的时间内我们将贡献到 Apache Iceberg 社区。
对于 0.12.0 版本来说,主要解决 row-level delete 的问题。如前面提到,我们已经在 PR 1663 中实现 Flink UPSERT 更新数据湖的全链路打通。后续在社区达成一致之后,将逐步推动该功能到社区版本。到时候用户将能通过 Flink 完成 CDC 数据的实时写入和分析,也可以方便地把 Flink 的聚合结果 upsert 到 Apache Iceberg 内。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721