
负载均衡具体分成两个方向,一个是前端负载均衡,另一个是数据中心内部的负载均衡。
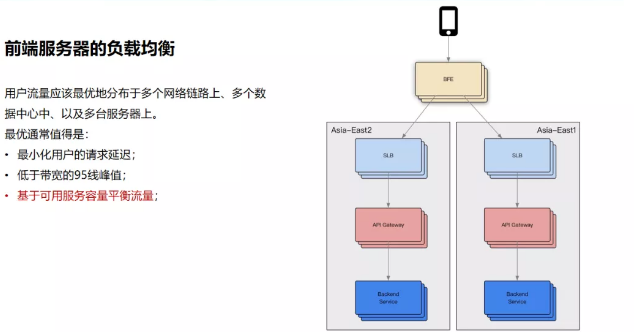
前端负载均衡方面,一般而言用户流量访问层面主要依据DNS,希望做到最小化用户请求延迟。将用户流量最优地分布在多个网络链路上、多个数据中心、多台服务器上,通过动态CDN的方案达到最小延迟。
以上图为例,用户流量会先流入BFE的前端接入层,第一层的BFE实际上起到一个路由的作用,尽可能选择跟接入节点比较近的一个机房,用来加速用户请求。然后通过API网关转发到下游的服务层,可能是内部的一些微服务或者业务的聚合层等,最终构成一个完整的流量模式。
基于此,前端服务器的负载均衡主要考虑几个逻辑:
第一,尽量选择最近节点;
第二,基于带宽策略调度选择API进入机房;
第三,基于可用服务容量平衡流量。
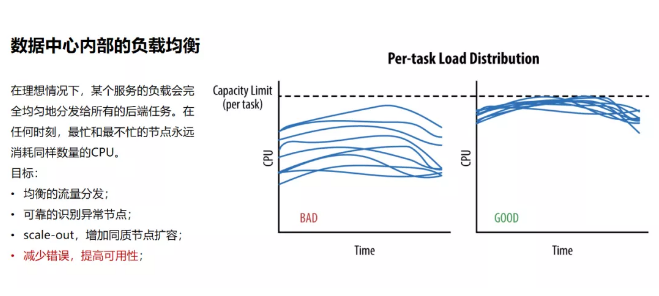
数据中心内部的负载均衡方面,理想情况下会像上图右边显示那样,最忙和最不忙的节点所消耗的CPU相差幅度较小。但如果负载均衡没做好,情况可能就像上图左边一样相差甚远。由此可能导致资源调度、编排的困难,无法合理分配容器资源。
因此,数据中心内部负载均衡主要考虑:
均衡流量分发;
可靠识别异常节点;
scale-out,增加同质节点以扩容;
减少错误,提高可用性。
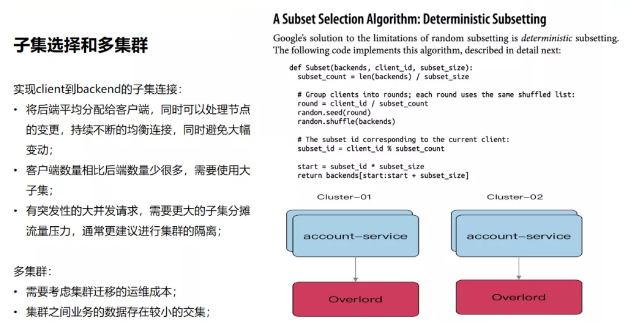
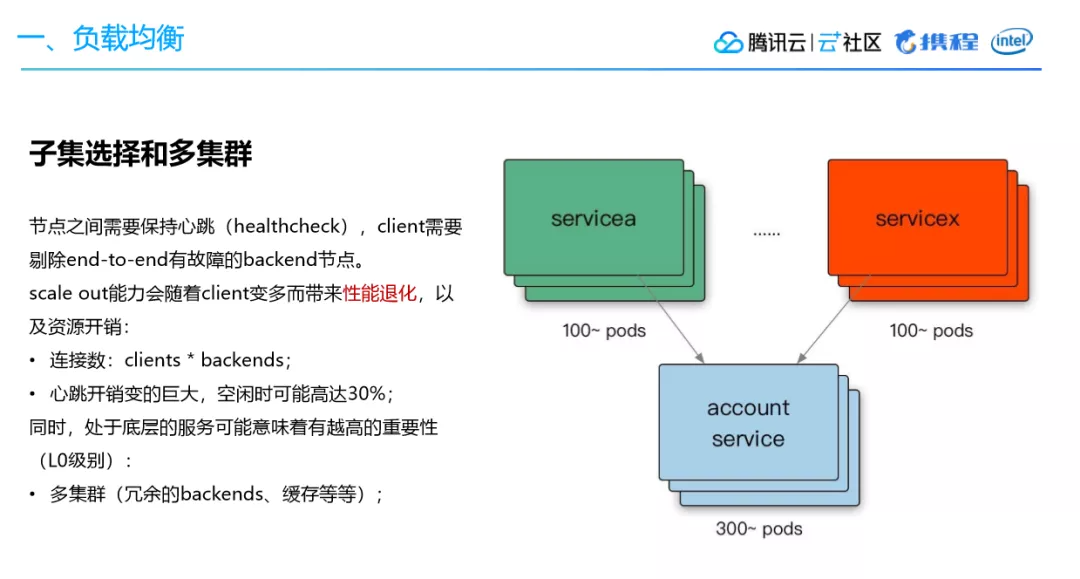
我们此前通过同质节点来扩容就发现,内网服务出现CPU占用率过高的异常,通过排查发现背后RPC点到点通信间的 health check 成本过高,产生了一些问题。另外一方面,底层的服务如果只有单套集群,当出现抖动的时候故障面会比较大,因此需要引入多集群来解决问题。
通过实现 client 到 backend 的子集连接,我们做到了将后端平均分配给客户端,同时可以处理节点变更,持续不断均衡连接,避免大幅变动。多集群下,则需要考虑集群迁移的运维成本,同时集群之间业务的数据存在较小的交集。
回到CPU忙时、闲时占用率过大的问题,我们会发现这背后跟负载均衡算法有关。
第一个问题,对于每一个qps,实际上就是每一个query、查询、API请求,它们的成本是不同的。节点与节点之间差异非常大,即便你做了均衡的流量分发,但是从负载的角度来看,实际上还是不均匀的。
第二个问题,存在物理机环境上的差异。因为我们通常都是分年采购服务器,新买的服务器通常主频CPU会更强一些,所以服务器本质上很难做到强同质。
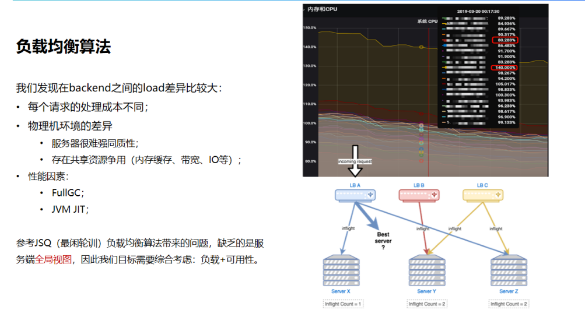
基于此,参考JSQ(最闲轮训)负载均衡算法带来的问题,发现缺乏的是服务端全局视图,因此我们的目标需要综合考虑负载和可用性。我们参考了《The power of two choices in randomized load balancing》的思路,使用the choice-of-2算法,随机选取的两个节点进行打分,选择更优的节点:
选择backend:CPU,client:health、inflight、latency作为指标,使用一个简单的线性方程进行打分;
对新启动的节点使用常量惩罚值(penalty),以及使用探针方式最小化放量,进行预热;
打分比较低的节点,避免进入“永久黑名单”而无法恢复,使用统计衰减的方式,让节点指标逐渐恢复到初始状态(即默认值)。
通过优化负载均衡算法以后,我们做到了比较好的收益。
避免过载,是负载均衡的一个重要目标。随着压力增加,无论负载均衡策略如何高效,系统某个部分总会过载。我们优先考虑优雅降级,返回低质量的结果,提供有损服务。在最差的情况,妥善的限流来保证服务本身稳定。
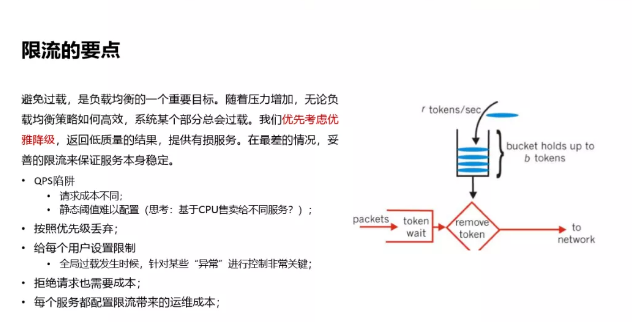
限流这块,我们认为主要关注以下几点:
针对qps的限制,带来请求成本不同、静态阈值难以配置的问题;
根据API的重要性,按照优先级丢弃;
给每个用户设置限制,全局过载发生时候,针对某些“异常”进行控制非常关键;
拒绝请求也需要成本;
每个服务都配置限流带来的运维成本。
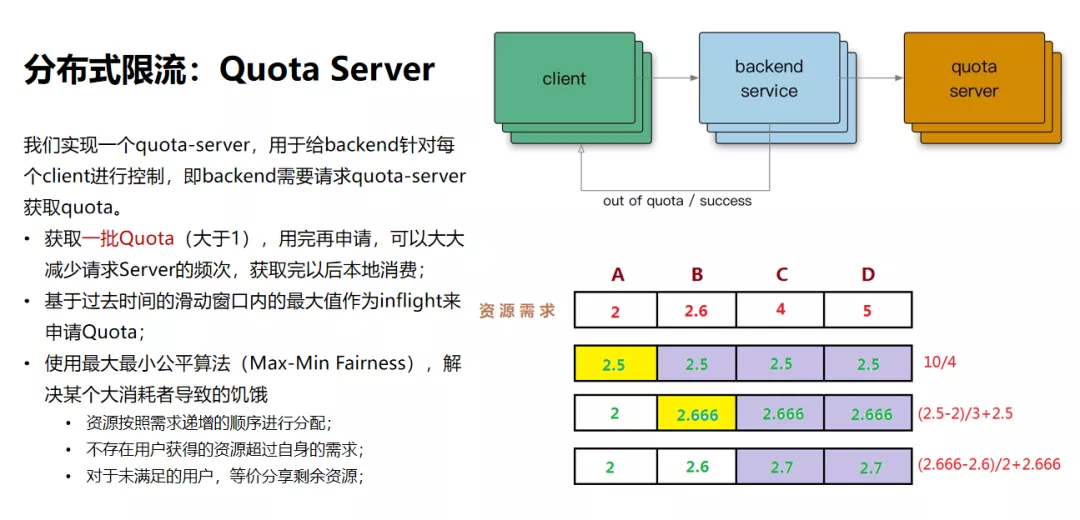
在限流策略上,我们首先采用的是分布式限流。我们通过实现一个quota-server,用于给backend针对每个client进行控制,即backend需要请求quota-server获取quota。
这样做的好处是减少请求Server的频次,获取完以后直接本地消费。算法层面使用最大最小公平算法,解决某个大消耗者导致的饥饿。

在客户端侧,当出现某个用户超过资源配额时,后端任务会快速拒绝请求,返回“配额不足”的错误,有可能后端忙着不停发送拒绝请求,导致过载和依赖的资源出现大量错误,处于对下游的保护两种状况,我们选择在client侧直接进行流量,而不发送到网络层。
我们在Google SRE里学到了一个有意思的公式,max(0, (requests- K*accepts) / (requests + 1))。通过这种公式,我们可以让client直接发送请求,一旦超过限制,按照概率进行截流。
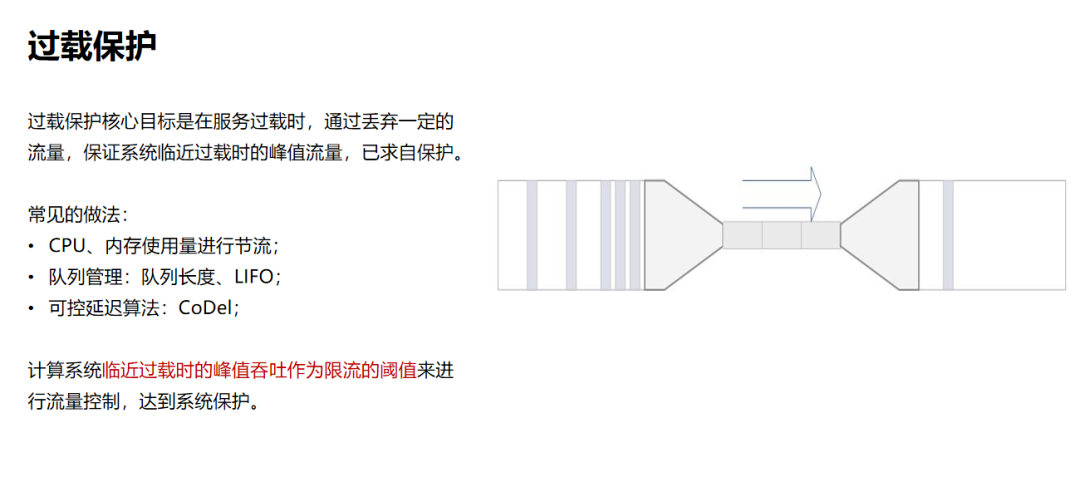
在过载保护方面,核心思路就是在服务过载时,丢弃一定的流量,保证系统临近过载时的峰值流量,以求自保护。常见的做法有基于CPU、内存使用量来进行流量丢弃;使用队列进行管理;可控延迟算法:CoDel 等。
简单来说,当我们的CPU达到80%的时候,这个时候可以认为它接近过载,如果这个时候的吞吐达到100,瞬时值的请求是110,我就可以丢掉这10个流量,这种情况下服务就可以进行自保护,我们基于这样的思路最终实现了一个过载保护的算法。
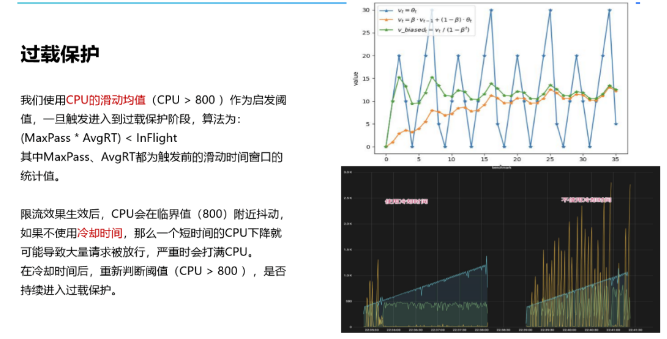
我们使用CPU的滑动均值(CPU > 800 )作为启发阈值,一旦触发就进入到过载保护阶段。算法为:(MaxPass * AvgRT) < InFlight。其中MaxPass、AvgRT都为触发前的滑动时间窗口的统计值。
限流效果生效后,CPU会在临界值(800)附近抖动,如果不使用冷却时间,那么一个短时间的CPU下降就可能导致大量请求被放行,严重时会打满CPU。在冷却时间后,重新判断阈值(CPU > 800 ),是否持续进入过载保护。
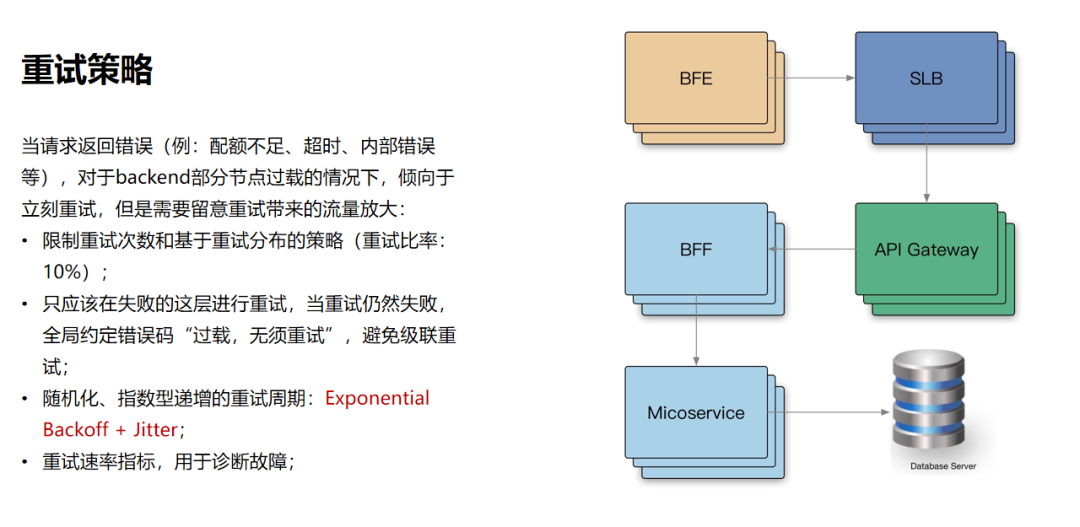
流量的走向,一般会从BFE到LB(负载均衡)然后经过API网关再到BFF、微服务最后到数据库,这个过程要经过非常多层。在我们的日常工作中,当请求返回错误,对于backend部分节点过载的情况下,我们应该怎么做?
首先我们需要限制重试的次数,以及基于重试分布的策略;
其次,我们只应该在失败层进行重试,当重试仍然失败时,我们需要全局约定错误码,避免级联重试;
此外,我们需要使用随机化、指数型递增的充实周期,这里可以参考Exponential Backoff和Jitter;
最后,我们需要设定重试速率指标,用于诊断故障。

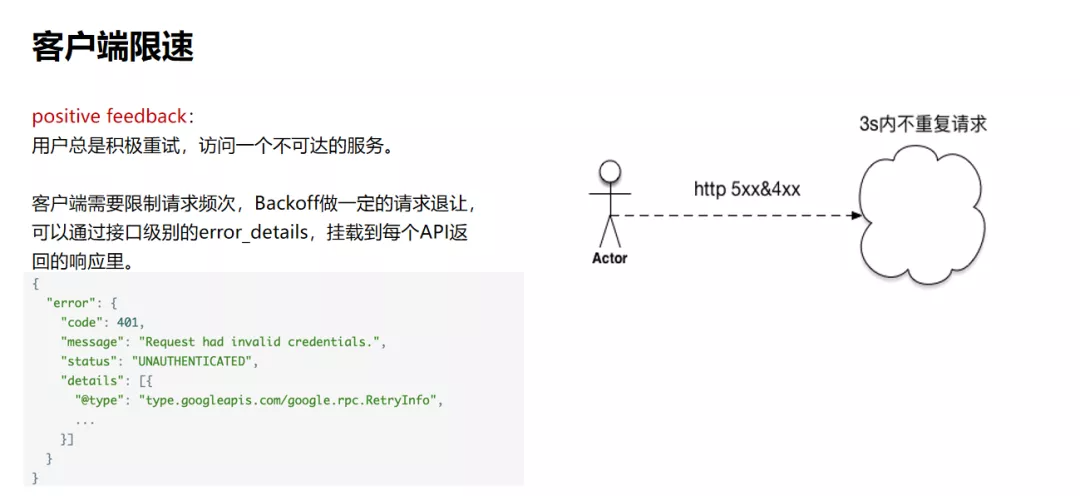
而在客户端侧,则需要做限速。因为用户总是会频繁尝试去访问一个不可达的服务,因此客户端需要限制请求频次,可以通过接口级别的error_details,挂载到每个API返回的响应里。
我们之前讲过,大部分的故障都是因为超时控制不合理导致的。首当其冲的是高并发下的高延迟服务,导致client堆积,引发线程阻塞,此时上游流量不断涌入,最终引发故障。所以,从本质上理解超时它实际就是一种Fail Fast的策略,就是让我们的请求尽可能消耗,类似这种堆积的请求基本上就是丢弃掉或者消耗掉。
另一个方面,当上游超时已经返回给用户后,下游可能还在执行,这就会引发资源浪费的问题。
再一个问题,当我们对下游服务进行调优时,到底如何配置超时,默认值策略应该如何设定?生产环境下经常会遇到手抖或者错误配置导致配置失败、出现故障的问题。所以我们最好是在框架层面做一些防御性的编程,让它尽可能让取在一个合理的区间内。
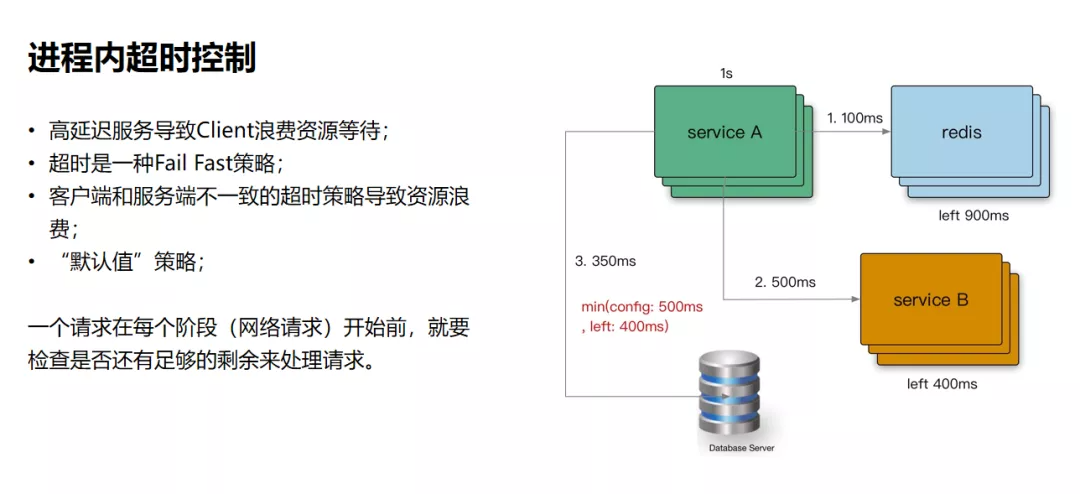
进程内的超时控制,关键要看一个请求在每个阶段(网络请求)开始前,检查是否还有足够的剩余来处理请求。另外,在进程内可能会有一些逻辑计算,我们通常认为这种时间比较少,所以一般不做控制。
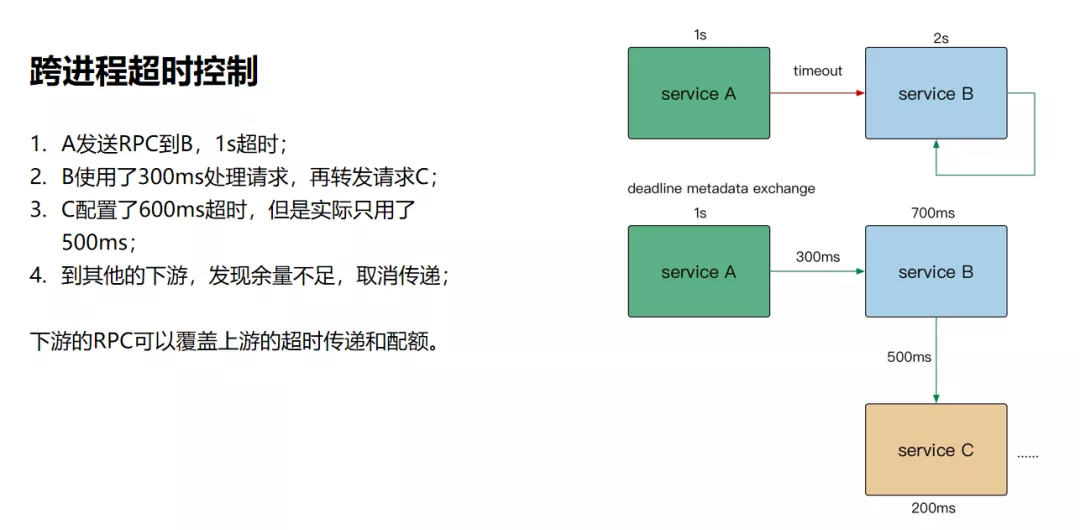
现在很多RPC框架都在做跨进程超时控制,为什么要做这个?跨进程超时控制同样可以参考进程内的超时控制思路,通过RPC的源数据传递,把它带到下游服务,然后利用配额继续传递,最终使得上下游链路不超过一秒。
结合我们上面讲到的四个方面,应对连锁故障,我们有以下几大关键点需要考虑。

第一,我们需要尽可能避免过载。因为节点一个接一个挂了的话,最终服务会雪崩,有可能机群都会跟着宕掉,所以我们才提到要做自保护。
第二,我们通过一些手段去做限流。它可以让某一个client对服务出现高流量并发请求时进行管控,这样的话服务也不容易死。另外,当我们无法正常服务的时候,还可以做有损服务,牺牲掉一些非核心服务去保证关键服务,做到优雅降级。
第三,在重试策略上,在微服务内尽可能做退避,尽可能要考虑到重试放大的流量倍数对下游的冲击。另外还要考虑在移动端用户用不了某个功能的情况下,通常会频繁刷新页面,这样产生的流量冲击,我们在移动端也要进行配合来做流控。
第四,超时控制强调两个点,进程内的超时和跨进程的传递。最终它的超时链路是由最上层的一个节点决定的,只要这一点做到了,我觉得大概率是不太可能出现连锁故障的。
第五,变更管理。我们通常情况下发布都是因为一些变更导致的,所以说我们在变更管理上还是要加强,变更流程中出现的破坏性行为应该要进行惩罚,尽管是对事不对人,但是还是要进行惩罚以引起重视。
第六,极限压测和故障演练。在做压测的时候,可能压到报错就停了。我建议最好是在报错的情况下,仍然要继续加压,看你的服务到底是一个什么表现?它能不能在过载的情况下提供服务?在上了过载保护算法以后,继续加压,积极拒绝,然后结合熔断的话,可以产生一个立体的保护效果。经常做故障演练可以产生一个品控手册,每个人都可以学习,经常演练不容易慌乱,当在生产环境中真的出现问题时也可以快速投入解决。
第七,考虑扩容、重启、消除有害流量。

如上图所示的参考,就是对以上几个策略的经典补充,也是解决各种服务问题的玄学。
Q1:请问负载均衡依据的 Metric是什么?
A1:我们用服务端的话,主要是用CPU,我觉得CPU是最能体现的。从客户端角度,我是用的健康度,健康度指的是连接的成功率。延迟也是一个很重要的指标,另外我们要考虑到每一个client往不同的back end发了多少个请求。
Q2:BFE到CLB是走公网还是专线?
A2:这个其实有公网也有专线。
Q3:如果client就几千量级,每10s pingpong 一下,其实也就几百 qps?会造成蛮高的cpu开销?
A3:如果你的client是几千,但上游你的各种服务加起来client实际上是非常多的可能过万。所以它是会造成蛮高的CPU开销的,因为好多个不同的应用来healthcheck,其实这个量就非常大了。
Q4:多集群的成本是怎么考虑的?
A4:分集群。前文提到的多集群更多是在同一个机房内布置多套机群,那么这个多套集群,首先它肯定资源是冗余和翻倍的。这个确实是需要一定成本,所以我们也不是所有服务都会来做这种冗余,只会针对核心服务。所以本质上就是花些钱,做些冗余,来尽可能提升我们的可用性,因为你越底层的服务一旦故障,它的故障面真的是扩散非常大。
Q5:超时传递是不是要求太严格了,如果有一个节点出问题就不行了。
A5:这个策略就是超时传递,我们默认是传递的,那么在有一些case情况下,即便超时仍然要继续运行,这个行为实际上是可以通过我们的context上下文把它覆盖掉,所以还是看你代码的逻辑处理。
Q6:用户的接入节点的质量和容量是怎么平衡的?
A6:取决于调度的策略。通常来讲需要先看你的服务是什么用途,如果是那种面向用户体验型的,或者功能型的,我觉得质量是优先考虑的。其次,在你转发的机房不过载的情况下,尽可能交付到最近的节点,那么极端情况下有可能你机房过载,那么这种情况下其实是不得已通过接入节点来转发到其他的核心机房。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721