
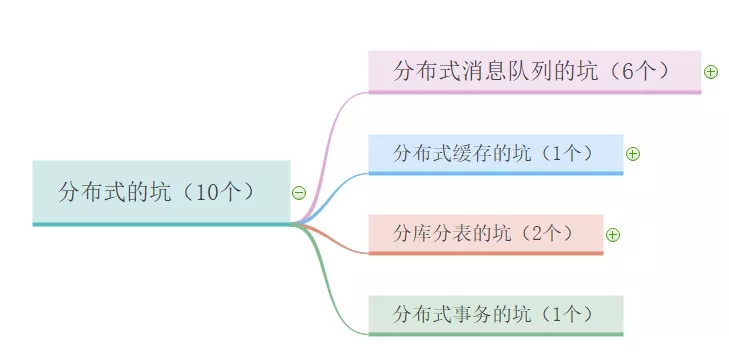
主要内容
前言
现在我们都在讨论分布式,特别是面试的时候。不管是招初级软件工程师还是高级,都会要求懂分布式,甚至要求用过。
传得沸沸扬扬的分布式到底是什么东东,有什么优势?

风遁·螺旋手里剑
看过火影的同学肯定知道漩涡鸣人的招牌忍术:多重影分身之术。这个术有一个特别厉害的地方,就是过程和心得(多个分身的感受和经历都是相通的)。
比如 A 分身去找卡卡西(鸣人的老师)请教问题,那么其他分身也会知道 A 分身问的什么问题。
漩涡鸣人还有另外一个超级厉害的忍术:风遁·螺旋手里剑,需要由几个影分身完成。这个忍术是靠三个鸣人一起协作完成的。
那么这两个忍术和分布式有什么关系?看下面:
分布在不同地方的系统或服务,是彼此相互关联的;
分布式系统是分工合作的。
案例:
比如 Redis 的哨兵机制,可以知道集群环境下哪台 Redis 节点挂了;
Kafka的 Leader 选举机制,如果某个节点挂了,会从 follower 中重新选举一个 leader 出来。(leader 作为写数据的入口,follower 作为读的入口)
那多重影分身之术有什么缺点?
会消耗大量的查克拉;
分布式系统同样具有这个问题,需要几倍的资源来支持。
是一种工作方式;
是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统;
将不同的业务分布在不同的地方。
宏观层面:多个功能模块糅合在一起的系统进行服务拆分,来解耦服务间的调用;
微观层面:将模块提供的服务分布到不同的机器或容器里,来扩大服务力度。
需要更多优质人才懂分布式,人力成本增加;
架构设计变得异常复杂,学习成本高;
运维部署和维护成本显著增加;
多服务间链路变长,开发排查问题难度加大;
环境高可靠性问题;
数据幂等性问题;
数据的顺序问题;
等等。
讲到分布式不得不知道 CAP 定理和 Base 理论,下面给不知道的同学做一个扫盲。
在理论计算机科学中,CAP 定理指出对于一个分布式计算系统来说,不可能通是满足以下三点:
一致性(Consistency):所有节点访问同一份最新的数据副本;
可用性(Availability):每次请求都能获取到非错的响应,但不保证获取的数据为最新数据;
分区容错性(Partition tolerance):不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在 C 和 A 之间做出选择)。
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的缩写。
BASE 理论是对 CAP 中 AP 的一个扩展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用来保证核心功能可用,允许数据在一段时间内是不一致的,但最终达到一致状态。
满足 BASE 理论的事务,我们称之为柔性事务:
基本可用 :分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如电商网址交易付款出现问题来,商品依然可以正常浏览;
软状态: 由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性。如订单中的“支付中”、“数据同步中”等状态,待数据最终一致后状态改为“成功”状态;
最终一致性: 最终一致是指的经过一段时间后,所有节点数据都将会达到一致。如订单的“支付中”状态,最终会变为“支付成功”或者“支付失败”,使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
一、分布式消息队列的坑
消息队列如何做分布式?
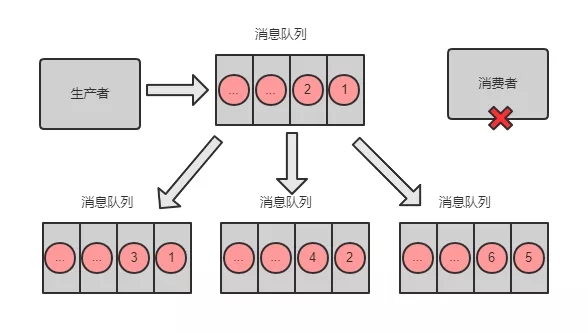
将消息队列里面的消息分摊到多个节点(指某台机器或容器)上,所有节点的消息队列之和就包含了所有消息。
1)幂等性概念
所谓幂等性就是无论多少次操作和第一次的操作结果一样。如果消息被多次消费,很有可能造成数据的不一致。
而如果消息不可避免地被消费多次,如果我们开发人员能通过技术手段保证数据的前后一致性,那也是可以接受的,这让我想起了 Java 并发编程中的 ABA 问题,如果出现了ABA问题,若能保证所有数据的前后一致性也能接受。
2)场景分析
RabbitMQ、RocketMQ、Kafka 消息队列中间件都有可能出现消息重复消费问题。这种问题并不是 MQ 自己保证的,而需要开发人员来保证。
这几款消息队列中间都是全球最牛的分布式消息队列,那它们肯定考虑到了消息的幂等性。我们以 Kafka 为例,看看 Kafka 是怎么保证消息队列的幂等性:
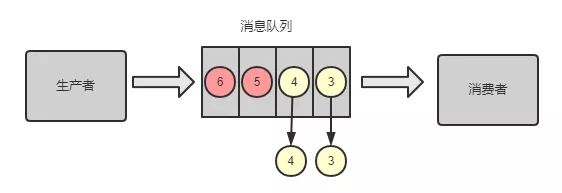
Kafka 有一个 偏移量的概念,代表着消息的序号,每条消息写到消息队列都会有一个偏移量。消费者消费了数据之后,每过一段固定的时间,就会把消费过的消息的偏移量提交一下,表示已经消费过了,下次消费就从偏移量后面开始消费。
坑:当消费完消息后,还没来得及提交偏移量,系统就被关机了,那么未提交偏移量的消息则会再次被消费。
如下图所示,队列中的数据 A、B、C,对应的偏移量分别为 100、101、102,都被消费者消费了,但是只有数据 A 的偏移量 100 提交成功,另外 2 个偏移量因系统重启而导致未及时提交。
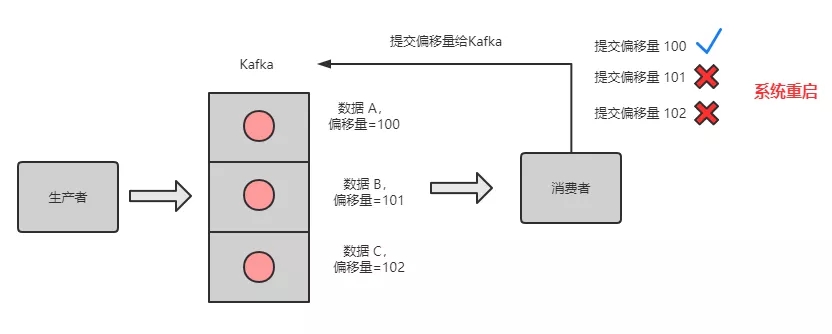
系统重启,偏移量未提交
重启后,消费者又是拿偏移量 100 以后的数据,从偏移量 101 开始拿消息。所以数据 B 和数据 C 被重复消息。
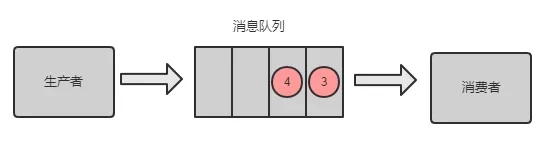
如下图所示:

重启后,重复消费消息
3)避坑指南
微信支付结果通知场景
微信官方文档上提到微信支付通知结果可能会推送多次,需要开发者自行保证幂等性。第一次我们可以直接修改订单状态(如支付中 -> 支付成功),第二次就根据订单状态来判断,如果不是支付中,则不进行订单处理逻辑。
插入数据库场景
每次插入数据时,先检查下数据库中是否有这条数据的主键 id,如果有,则进行更新操作。
写 Redis 场景
Redis 的 Set 操作天然幂等性,所以不用考虑 Redis 写数据的问题。
其他场景方案
生产者发送每条数据时,增加一个全局唯一 id,类似订单 id。每次消费时,先去 Redis 查下是否有这个 id,如果没有,则进行正常处理消息,且将 id 存到 Redis。如果查到有这个 id,说明之前消费过,则不要进行重复处理这条消息。
不同业务场景,可能会有不同的幂等性方案,大家选择合适的即可,上面的几种方案只是提供常见的解决思路。
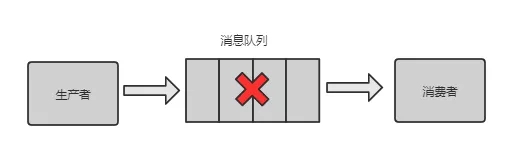
坑:消息丢失会带来什么问题?如果是订单下单、支付结果通知、扣费相关的消息丢失,则可能造成财务损失,如果量很大,就会给甲方带来巨大损失。
那消息队列是否能保证消息不丢失呢?
答案:否。主要有三种场景会导致消息丢失。
消息队列之消息丢失
1)生产者存放消息的过程中丢失消息

解决方案:
事务机制(不推荐,异步方式)
对于 RabbitMQ 来说,生产者发送数据之前开启 RabbitMQ 的事务机制 channel.txselect,如果消息没有进队列,则生产者受到异常报错,并进行回滚 channel.txRollback ,然后重试发送消息;如果收到了消息,则可以提交事务 channel.txCommit 。但这是一个同步的操作,会影响性能。
confirm 机制(推荐,异步方式)
我们可以采用另外一种模式:confirm 模式来解决同步机制的性能问题。每次生产者发送的消息都会分配一个唯一的 id,如果写入到了 RabbitMQ 队列中,则 RabbitMQ 会回传一个 ack 消息,说明这个消息接收成功。如果 RabbitMQ 没能处理这个消息,则回调 nack 接口。说明需要重试发送消息。
也可以自定义超时时间 + 消息 id 来实现超时等待后重试机制。但可能出现的问题是调用 ack 接口时失败了,所以会出现消息被发送两次的问题,这个时候就需要保证消费者消费消息的幂等性。
事务模式 和 confirm 模式的区别:
事务机制是同步的,提交事务后悔被阻塞直到提交事务完成后;
confirm 模式异步接收通知,但可能接收不到通知。需要考虑接收不到通知的场景。
2)消息队列丢失消息
消息队列丢失消息
消息队列的消息可以放到内存中,或将内存中的消息转到硬盘(比如数据库)中,一般都是内存和硬盘中都存有消息。
如果只是放在内存中,那么当机器重启了,消息就全部丢失了。如果是硬盘中,则可能存在一种极端情况,就是将内存中的数据转换到硬盘的期间中,消息队列出问题了,未能将消息持久化到硬盘。
解决方案:
创建 Queue 的时候将其设置为持久化;
发送消息的时候将消息的 deliveryMode 设置为 2 ;
开启生产者 confirm 模式,可以重试发送消息。
3)消费者丢失消息
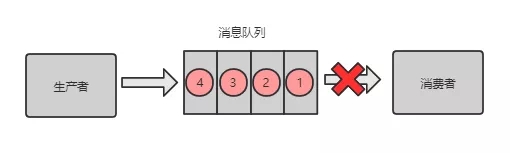
消费者刚拿到数据,还没开始处理消息,结果进程因为异常退出了,消费者没有机会再次拿到消息。
解决方案:
关闭 RabbitMQ 的自动 ack,每次生产者将消息写入消息队列后,就自动回传一个 ack 给生产者。
消费者处理完消息再主动 ack,告诉消息队列我处理完了。
问题:那这种主动 ack有什么漏洞了?如果 主动 ack 的时候挂了,怎么办?
则可能会被再次消费,这个时候就需要幂等处理了。
问题:如果这条消息一直被重复消费怎么办?
则需要有加上重试次数的监测,如果超过一定次数则将消息丢失,记录到异常表或发送异常通知给值班人员。
4)RabbitMQ 消息丢失总结
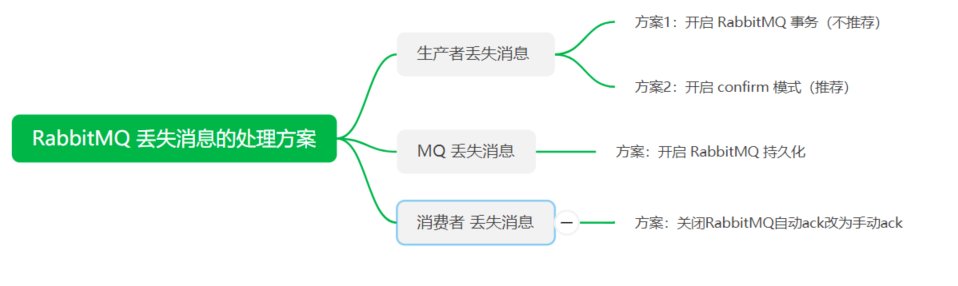
RabbitMQ 丢失消息的处理方案
5)Kafka 消息丢失
场景:
Kafka 的某个 broker(节点)宕机了,重新选举 leader (写入的节点)。如果 leader 挂了,follower 还有些数据未同步完,则 follower 成为 leader 后,消息队列会丢失一部分数据。
解决方案:
给 topic 设置 replication.factor 参数,值必须大于 1,要求每个 partition 必须有至少 2 个副本;
给 kafka 服务端设置 min.insyc.replicas 必须大于 1,表示一个 leader 至少一个 follower 还跟自己保持联系。
坑:用户先下单成功,然后取消订单,如果顺序颠倒,则最后数据库里面会有一条下单成功的订单。
1)RabbitMQ
① 场景
生产者向消息队列按照顺序发送了 2 条消息,消息1:增加数据 A,消息2:删除数据 A;
期望结果:数据 A 被删除;
但是如果有两个消费者,消费顺序是:消息2、消息 1。则最后结果是增加了数据 A。
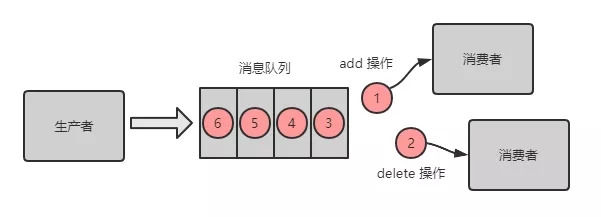
RabbitMQ消息乱序场景
② 解决方案
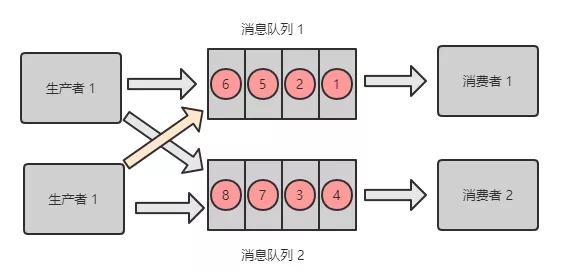
将 Queue 进行拆分,创建多个内存 Queue,消息 1 和 消息 2 进入同一个 Queue;
创建多个消费者,每一个消费者对应一个 Queue。
2)Kafka
① 场景
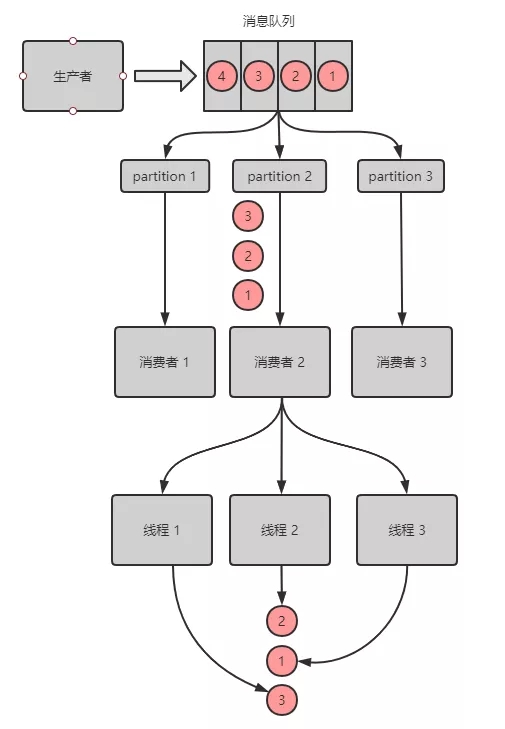
Kafka 消息丢失场景
创建了 topic,有 3 个 partition;
创建一条订单记录,订单 id 作为 key,订单相关的消息都丢到同一个 partition 中,同一个生产者创建的消息,顺序是正确的;
为了快速消费消息,会创建多个消费者去处理消息,而为了提高效率,每个消费者可能会创建多个线程来并行的去拿消息及处理消息,处理消息的顺序可能就乱序了。
② 解决方案
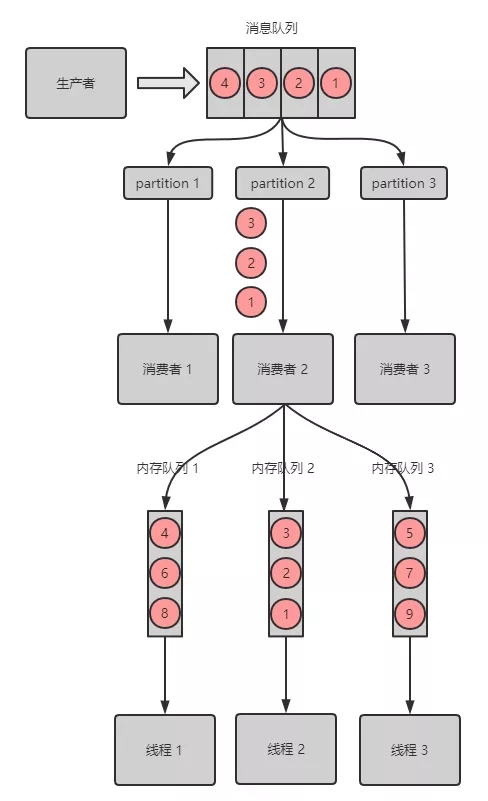
Kafka 消息乱序解决方案
解决方案和 RabbitMQ 类似,利用多个 内存 Queue,每个线程消费 1个 Queue;
具有相同 key 的消息 进同一个 Queue。
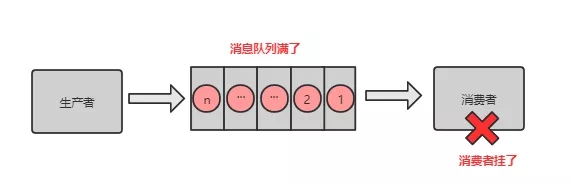
消息积压:消息队列里面有很多消息来不及消费。
场景:
消费端出了问题,比如消费者都挂了,没有消费者来消费了,导致消息在队列里面不断积压;
消费端出了问题,比如消费者消费的速度太慢了,导致消息不断积压。
坑:比如线上正在做订单活动,下单全部走消息队列,如果消息不断积压,订单都没有下单成功,那么将会损失很多交易。
解决方案:解铃还须系铃人
修复代码层面消费者的问题,确保后续消费速度恢复或尽可能加快消费的速度;
停掉现有的消费者;
临时建立好原先 5 倍的 Queue 数量;
临时建立好原先 5 倍数量的消费者;
将堆积的消息全部转入临时的 Queue,消费者来消费这些 Queue。
坑:RabbitMQ 可以设置过期时间,如果消息超过一定的时间还没有被消费,则会被 RabbitMQ 给清理掉。消息就丢失了。
解决方案:
准备好批量重导的程序;
手动将消息闲时批量重导。
坑:当消息队列因消息积压导致的队列快写满,所以不能接收更多的消息了。生产者生产的消息将会被丢弃。
解决方案:
判断哪些是无用的消息,RabbitMQ 可以进行 Purge Message 操作;
如果是有用的消息,则需要将消息快速消费,将消息里面的内容转存到数据库;
准备好程序将转存在数据库中的消息再次重导到消息队列;
闲时重导消息到消息队列。
二、分布式缓存的坑
在高频访问数据库的场景中,我们会在业务层和数据层之间加入一套缓存机制,来分担数据库的访问压力,毕竟访问磁盘 I/O 的速度是很慢的。
比如利用缓存来查数据,可能5ms就能搞定,而去查数据库可能需要 50 ms,差了一个数量级。而在高并发的情况下,数据库还有可能对数据进行加锁,导致访问数据库的速度更慢。
分布式缓存我们用的最多的就是 Redis了,它可以提供分布式缓存服务。
1)哨兵机制
Redis 可以实现利用哨兵机制实现集群的高可用,那什么是哨兵机制呢?
英文名:sentinel,中文名:哨兵;
集群监控:负责主副进程的正常工作;
消息通知:负责将故障信息报警给运维人员;
故障转移:负责将主节点转移到备用节点上;
配置中心:通知客户端更新主节点地址;
分布式:有多个哨兵分布在每个主备节点上,互相协同工作;
分布式选举:需要大部分哨兵都同意,才能进行主备切换;
高可用:即使部分哨兵节点宕机了,哨兵集群还是能正常工作。
坑:当主节点发生故障时,需要进行主备切换,可能会导致数据丢失。
2)异步复制数据导致的数据丢失
主节点异步同步数据给备用节点的过程中,主节点宕机了,导致有部分数据未同步到备用节点。而这个从节点又被选举为主节点,这个时候就有部分数据丢失了。
3)脑裂导致的数据丢失
主节点所在机器脱离了集群网络,实际上自身还是运行着的。但哨兵选举出了备用节点作为主节点,这个时候就有两个主节点都在运行,相当于两个大脑在指挥这个集群干活,但到底听谁的呢?这个就是脑裂。
那怎么脑裂怎么会导致数据丢失呢?如果发生脑裂后,客户端还没来得及切换到新的主节点,连的还是第一个主节点,那么有些数据还是写入到了第一个主节点里面,新的主节点没有这些数据。那等到第一个主节点恢复后,会被作为备用节点连到集群环境,而且自身数据会被清空,重新从新的主节点复制数据。而新的主节点因没有客户端之前写入的数据,所以导致数据丢失了一部分。
4)避坑指南
配置 min-slaves-to-write 1,表示至少有一个备用节点;
配置 min-slaves-max-lag 10,表示数据复制和同步的延迟不能超过 10 秒。最多丢失 10 秒的数据
注意:缓存雪崩、缓存穿透、缓存击穿并不是分布式所独有的,单机的时候也会出现。所以不算在分布式的坑里。
三、分库分表的坑
1)分库、分表、垂直拆分和水平拆分
分库:因一个数据库支持的最高并发访问数是有限的,可以将一个数据库的数据拆分到多个库中,来增加最高并发访问数;
分表:因一张表的数据量太大,用索引来查询数据都搞不定了,所以可以将一张表的数据拆分到多张表,查询时,只用查拆分后的某一张表,SQL 语句的查询性能得到提升;
分库分表优势:分库分表后,承受的并发增加了多倍;磁盘使用率大大降低;单表数据量减少,SQL 执行效率明显提升。
水平拆分:把一个表的数据拆分到多个数据库,每个数据库中的表结构不变,用多个库抗更高的并发。比如订单表每个月有500万条数据累计,每个月都可以进行水平拆分,将上个月的数据放到另外一个数据库;
垂直拆分:把一个有很多字段的表,拆分成多张表到同一个库或多个库上面。高频访问字段放到一张表,低频访问的字段放到另外一张表。利用数据库缓存来缓存高频访问的行数据。比如将一张很多字段的订单表拆分成几张表分别存不同的字段(可以有冗余字段)。
分库、分表的方式:
1. 根据租户来分库、分表;
2. 利用时间范围来分库、分表;
3. 利用 ID 取模来分库、分表。
坑:分库分表是一个运维层面需要做的事情,有时会采取凌晨宕机开始升级。可能熬夜到天亮,结果升级失败,则需要回滚,其实对技术团队都是一种煎熬。
2)怎么做成自动的来节省分库分表的时间?
双写迁移方案:迁移时,新数据的增删改操作在新库和老库都做一遍;
使用分库分表工具 Sharding-jdbc 来完成分库分表的累活;
使用程序来对比两个库的数据是否一致,直到数据一致。
坑:分库分表看似光鲜亮丽,但分库分表会引入什么新的问题呢?
3)垂直拆分带来的问题
依然存在单表数据量过大的问题;
部分表无法关联查询,只能通过接口聚合方式解决,提升了开发的复杂度;
分布式事处理复杂。
4)水平拆分带来的问题
跨库的关联查询性能差;
数据多次扩容和维护量大;
跨分片的事务一致性难以保证。
1)为什么分库分表需要唯一 ID
如果要做分库分表,则必须得考虑表主键 ID 是全局唯一的。比如有一张订单表,被分到 A 库和 B 库。如果 两张订单表都是从 1 开始递增,那查询订单数据时就错乱了,很多订单 ID 都是重复的,而这些订单其实不是同一个订单;
分库的一个期望结果就是将访问数据的次数分摊到其他库,有些场景是需要均匀分摊的,那么数据插入到多个数据库的时候就需要交替生成唯一的 ID 来保证请求均匀分摊到所有数据库。
坑:唯一 ID 的生成方式有 n 种,各有各的用途,别用错了。
2)生成唯一 ID 的原则
全局唯一性
趋势递增
单调递增
信息安全
3)生成唯一 ID 的几种方式
数据库自增 ID:每个数据库每增加一条记录,自己的 ID 自增 1
①多个库的 ID 可能重复,这个方案可以直接否掉了,不适合分库分表后的 ID 生成;
②信息不安全。
适用 UUID 唯一 ID
①UUID 太长、占用空间大;
②不具有有序性,作为主键时,在写入数据时,不能产生有顺序的 append 操作,只能进行 insert 操作,导致读取整个 B+ 树节点到内存,插入记录后将整个节点写回磁盘,当记录占用空间很大的时候,性能很差。
获取系统当前时间作为唯一 ID。
①高并发时,1 ms内可能有多个相同的 ID。
②信息不安全
Twitter 的 snowflake(雪花算法):Twitter 开源的分布式 id 生成算法,64 位的 long 型的 id,分为 4 部分

snowflake算法
① 基本原理
1 bit:不用,统一为 0;
41 bits:毫秒时间戳,可以表示 69 年的时间;
10 bits:5 bits 代表机房 id,5 个 bits 代表机器 id。最多代表 32 个机房,每个机房最多代表 32 台机器;
12 bits:同一毫秒内的 id,最多 4096 个不同 id,自增模式。
②优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的;
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的;
可以根据自身业务特性分配bit位,非常灵活。
③缺点:
强依赖机器时钟,如果机器上时钟回拨(可以搜索 2017 年闰秒 7:59:60),会导致发号重复或者服务会处于不可用状态。
百度的 UIDGenerator 算法
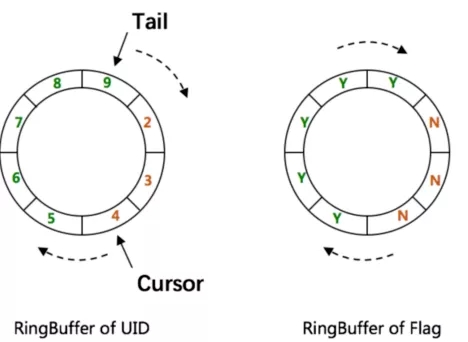
UIDGenerator 算法
①基于 Snowflake 的优化算法;
②借用未来时间和双 Buffer 来解决时间回拨与生成性能等 问题,同时结合 MySQL 进行 ID 分配。
③ 优点:解决了时间回拨和生成性能问题。
④缺点:依赖 MySQL 数据库。
美团的 Leaf-Snowflake 算法
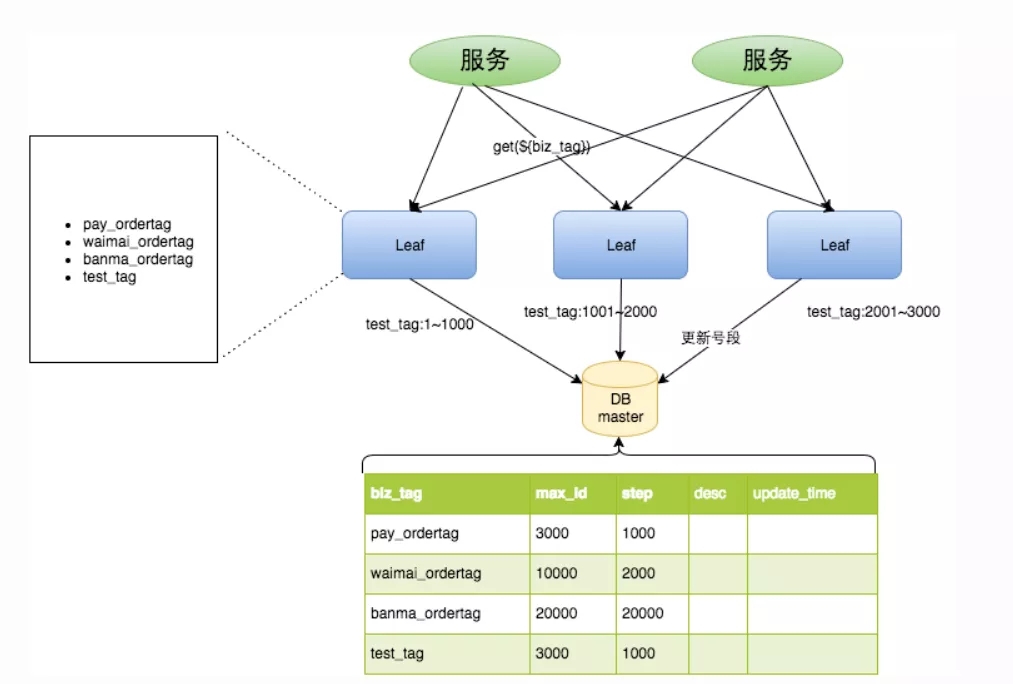
图片来源于美团
① 获取 id 是通过代理服务访问数据库获取一批 id(号段);
② 双缓冲:当前一批的 id 使用 10%时,再访问数据库获取新的一批 id 缓存起来,等上批的 id 用完后直接用;
③优点:
Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景;
ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求;
容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务;
可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来;
即使DB宕机,Leaf仍能持续发号一段时间;
偶尔的网络抖动不会影响下个号段的更新。
④ 缺点:
ID号码不够随机,能够泄露发号数量的信息,不太安全。
怎么选择?一般自己的内部系统,雪花算法足够,如果还要更加安全可靠,可以选择百度或美团的生成唯一 ID 的方案。
四、分布式事务的坑
事务可以简单理解为要么这件事情全部做完,要么这件事情一点都没做,跟没发生一样;
在分布式的世界中,存在着各个服务之间相互调用,链路可能很长,如果有任何一方执行出错,则需要回滚涉及到的其他服务的相关操作。比如订单服务下单成功,然后调用营销中心发券接口发了一张代金券,但是微信支付扣款失败,则需要退回发的那张券,且需要将订单状态改为异常订单。
坑:如何保证分布式中的事务正确执行,是个大难题。
XA 方案(两阶段提交方案)
TCC 方案(try、confirm、cancel)
SAGA 方案
可靠消息最终一致性方案
最大努力通知方案
XA 方案原理
1)XA方案原理
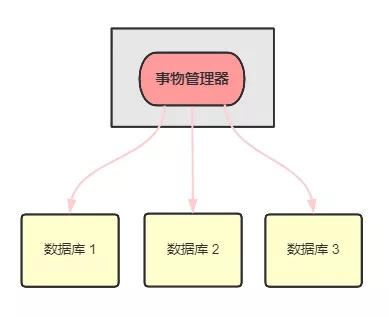
事务管理器负责协调多个数据库的事务,先问问各个数据库准备好了吗?如果准备好了,则在数据库执行操作,如果任一数据库没有准备,则回滚事务;
适合单体应用,不适合微服务架构。因为每个服务只能访问自己的数据库,不允许交叉访问其他微服务的数据库。
2)TCC方案
Try 阶段:对各个服务的资源做检测以及对资源进行锁定或者预留;
Confirm 阶段:各个服务中执行实际的操作;
Cancel 阶段:如果任何一个服务的业务方法执行出错,需要将之前操作成功的步骤进行回滚。
应用场景:
跟支付、交易打交道,必须保证资金正确的场景;
对于一致性要求高。
缺点:
但因为要写很多补偿逻辑的代码,且不易维护,所以其他场景建议不要这么做。
3)Sega方案
基本原理:
业务流程中的每个步骤若有一个失败了,则补偿前面操作成功的步骤。
适用场景:
业务流程长、业务流程多;
参与者包含其他公司或遗留系统服务。
优势:
第一个阶段提交本地事务、无锁、高性能;
参与者可异步执行、高吞吐;
补偿服务易于实现。
缺点:
不保证事务的隔离性;
4)可靠消息一致性方案
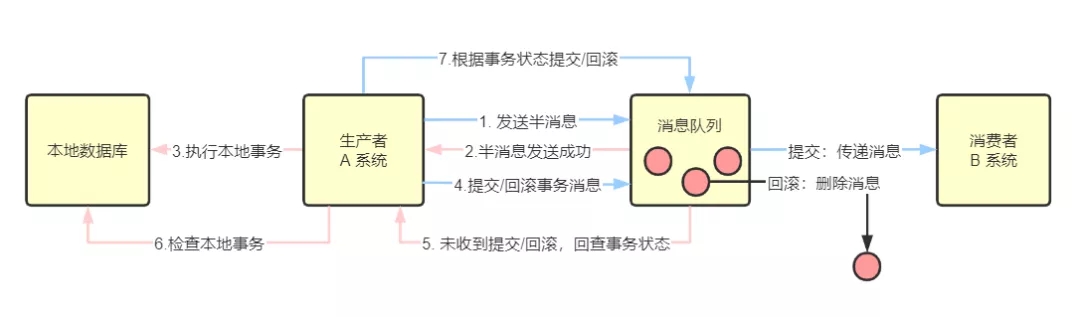
基本原理:
利用消息中间件 RocketMQ 来实现消息事务:
第一步:A 系统发送一个消息到 MQ,MQ将消息状态标记为 prepared(预备状态,半消息),该消息无法被订阅;
第二步:MQ 响应 A 系统,告诉 A 系统已经接收到消息了;
第三步:A 系统执行本地事务;
第四步:若 A 系统执行本地事务成功,将 prepared 消息改为 commit(提交事务消息),B 系统就可以订阅到消息了;
第五步:MQ 也会定时轮询所有 prepared的消息,回调 A 系统,让 A 系统告诉 MQ 本地事务处理得怎么样了,是继续等待还是回滚;
第六步:A 系统检查本地事务的执行结果;
第七步:若 A 系统执行本地事务失败,则 MQ 收到 Rollback 信号,丢弃消息。若执行本地事务成功,则 MQ 收到 Commit 信号;
B 系统收到消息后,开始执行本地事务,如果执行失败,则自动不断重试直到成功;或 B 系统采取回滚的方式,同时要通过其他方式通知 A 系统也进行回滚;
B 系统需要保证幂等性。
5)最大努力通知方案
基本原理:
系统 A 本地事务执行完之后,发送消息到 MQ;
MQ 将消息持久化;
系统 B 如果执行本地事务失败,则最大努力服务会定时尝试重新调用系统 B,尽自己最大的努力让系统 B 重试,重试多次后,还是不行就只能放弃了。转到开发人员去排查以及后续人工补偿。
跟支付、交易打交道,优先 TCC;
大型系统,但要求不那么严格,考虑 消息事务或 SAGA 方案;
单体应用,建议 XA 两阶段提交就可以了;
最大努力通知方案建议都加上,毕竟不可能一出问题就交给开发排查,先重试几次看能不能成功。
写在最后
分布式还有很多坑,这篇只是一个小小的总结,从这些坑中,我们也知道分布式有它的优势也有它的劣势,那到底该不该用分布式,完全取决于业务、时间、成本以及开发团队的综合实力。后续我会继续分享分布式中的一些底层原理,当然也少不了分享一些避坑指南。
参考资料
美团:《 Leaf-Snowflake 算法》
百度:《 UIDGenerator 算法》
《 Advanced-Java 》








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721