
作者介绍
王磊(Ivan),现任光大银行科技部数据领域架构师,曾任职于IBM全球咨询服务部从事技术咨询工作,具有十余年数据领域研发及咨询经验。目前负责全行数据领域系统的日常架构设计、评审及内部研发等工作,对分布式数据库、Hadoop等基础架构研究有浓厚兴趣。个人公众号:金融数士。
随着大规模互联网应用的广泛出现,分布式数据库成为近两年的一个热门话题。同样,在银行业主推X86限制主机与小型机的背景下,传统的单机数据库逐渐出现了一些瓶颈,马上会面临是否引入分布式数据库的问题。
近期,我在个人公众号就“银行引入分布式数据库的必要性”做过一些展望,并收到了一些朋友的反馈,除了对分布式数据库具体技术探讨外,还有一类很有趣的建议,“能不能也讲讲Teradata、Greenplum这类MPP,这些也是分布式数据库,但老板总是认为OLTP场景下的才算数”。
的确,为了解决OLAP场景需求,其实很早就出现了分布式架构的产品和解决方案,其与目前的OLTP方案有很多共通的地方。而且我相信,今后OLAP和OLTP两个分支技术的发展也必然是交错前行,可以相互借鉴的。
鉴于此,本文会将OLAP类场景的分布式数据也纳入进来,从两个维度对“分布式数据库”进行拆解,第一部分会横向谈谈不同的“分布式数据库”,把它们分为五类并对其中OLAP场景的三类做概要分析;第二部分结合NoSQL与NewSQL的差异,纵向来谈谈OLTP场景“分布式数据库”实现方案的关键技术要点,是前文的延伸,也是分布式数据库专题文章的一个总纲,其中的要点也都会单独撰文阐述。
首先,我们从横向谈谈不同的“分布式数据库”:
一、万法同宗RDBMS
1990年代开始,关系型数据库(RDBMS)成为主流,典型的产品包括Sybase、Oracle、DB2等,同期大约也是国内IT产业的起步阶段。RDBMS的基本特征已有学术上的定义,这里不再赘述。
但从实际应用的角度看,我认为有两点最受关注:
内部以关系模型存储数据,对外支持ANSI SQL接口;
支持事务管理ACID特性,尤其是强一致性(指事务内的修改要么全部失败要么全部成功,不会出现中间状态)。
而后出现的各种“分布式数据库”,大多都是在这两点上做权衡以交换其他方面的能力。
“数据库”虽然有经典定义,但很多大数据产品或许是为了标榜对传统数据库部分功能的替代作用,也借用了“数据库”的名号,导致在实践中这个概念被不断放大,边界越来越模糊。本文一个目标是要厘清这些产品与经典数据库的差异与传承,所以不妨先弱化“数据库”,将其放大为“数据存储”。
那么怎样才算是“分布式数据存储”系统?
“分布式”是一种架构风格,用其实现“数据存储”,最现实的目的是为了打开数据库产品的性能天花板,并保证系统的高可靠,进一步展开,“分布式数据库”的必要条件有两点:
支持水平扩展,保证高性能
通过增加机器节点的方式提升系统整体处理能力,摆脱对专用设备的依赖,并且突破专用设备方案的性能上限。这里的机器节点,通常是要支持X86服务器。
廉价设备+软件,保证高可靠
在单机可靠性较低的前提下,依靠软件保证系统整体的高可靠,又可以细分为“数据存储的高可靠”和“服务的高可靠”。总之,任何单点的故障,可能会带来短时间、局部的服务水平下降,但不会影响系统整体的正常运转。
将这两点作为“分布式数据库”的必要条件,我大致归纳了一下,至少有五种不同的“分布式数据库”:
NoSQL
NewSQL
MPP
Hadoop技术生态
Like-Mesa
注:也许有些同学会提到Kafka、Zookeeper等,这些虽然也是分布式数据存储,但因为具有鲜明的特点和适用场景,无需再纳入“数据库”概念进行探讨。
这五类中,前两类以支持OLTP场景为主,后三类则以OLAP场景为主。我将按照时间线,主要对OLAP场景下的三类进行概要分析。
二、OLAP场景下的分布式数据库
1990-2000年代,随着应用系统广泛建设与深入使用,数据规模越来越大,国内银行业的“全国大集中”基本都是在这个阶段完成。这期间,RDBMS得到了广泛运用,Oracle也击败Sybase成为数据库领域的王者。
在满足了基本的交易场景后,数据得到了累积,进一步的分析性需求自然就涌现了出来。单一数据库内同时支持联机交易和分析需求存在很多问题,往往会造成对联机交易的干扰,因此需要新的解决方案。这就为MPP崛起提供了机会。
MPP(Massively Parallel Processing)是指多个处理器(或独立的计算机)并行处理一组协同计算[1]。
为了保证各节点的独立计算能力,MPP数据库通常采用ShareNothing架构,最为典型的产品是Teradata(简称TD),后来也出现Greenplum(简称GPDB)、Vertica、Netezza等竞争者。
架构特点:
MPP是多机可水平扩展的架构,符合“分布式”的基本要求,其中TD采用外置集中存储而GPDB直接使用本地磁盘,从这点来说GPDB是更彻底的Share Nothing架构。
考虑到TD商业策略上采用一体机方案,不具有开放性,而GPDB具有较高的开源程度,下文中通过分析后者架构特点来分析MPP工作机制。
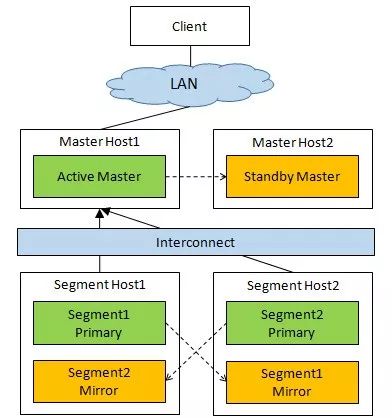
GPDB属于主从架构[2],Slave称为Segment是主要的数据加工节点,是在PostgreSQL基础上的封装和修改,天然具备事务处理的能力,可进行水平扩展;集群内有唯一Active状态的Master节点,除了元数据存储和调度功能外,同时承担一定的工作负载,即所有外部对集群的数据联机访问都要经过Master节点。
在高可靠设计方面,首先设置了Standby Master节点,在Master节点宕机时接管其任务,其次将Segment节点则细分为两类不同角色Primary和Mirror,后者是前者的备节点,数据提交时在两者间进行强同步,以此保证Primary宕机时,Mirror可以被调度起来接替前者的任务。
数据分析性需求对IT能力的要求包括:
复杂查询能力;
批量数据处理;
一定的并发访问能力。
MPP较好的实现了对上述能力的支撑,在前大数据时代得到了广泛的应用,但这个时期的数据总量相对仍然有限,普遍在TB级别,对应的集群规模也通常在单集群百节点以下。
随着数据价值关注度的不断提升,越来越多的数据被纳入企业分析范围;同时实际应用中考虑到数据存储和传输成本,往往倾向于将数据集中在一个或少数几个集群中,这样推动了集群规模的快速增长。
在大规模集群(几百至上千)的使用上,MPP从批处理和联机访问两个方面都显现了一些不足。以下内容主要借鉴了Pivotal(GPDB原厂)的一篇官方博客[3]。
注:有位同学给出的译文也具有较好的质量,推荐阅读[4]。
缺陷:
批处理
MPP架构下,工作负载节点(对GPDB而言是Segment节点)是完全对称的,数据均匀的存储在这些节点,处理过程中每个节点(即该节点上的Executor)使用本地的CPU、内存和磁盘等资源完成本地的数据加工。这个架构虽然提供了较好的扩展性,但隐藏了极大的问题——Straggler,即当某个节点出现问题导致速度比其他节点慢时,该节点会成为Straggler。
此时,无论集群规模多大,批处理的整体执行速度都由Straggler决定,其他节点上的任务执行完毕后则进入空闲状态等待Straggler,而无法分担其工作。导致节点处理速度降低的原因多数是磁盘等硬件损坏,考虑到磁盘本身的一定故障率(根据Google统计前三个月内2%损坏率,第二年时达到8%)当集群规模达到一定程度时,故障会频繁出现使straggler成为一个常规问题。
并发
由于MPP的“完全对称性”,即当查询开始执行时,每个节点都在并行的执行完全相同的任务,这意味着MPP支持的并发数和集群的节点数完全无关。根据该文中的测试数据,4个节点的集群和400个节点的集群支持的并发查询数是相同的,随着并发数增加,这二者几乎在相同的时点出现性能骤降。
传统MPP的联机查询主要面向企业管理层的少数用户,对并发能力的要求较低。而在大数据时代,数据的使用者从战略管理层转向战术执行层乃至一线人员,从孤立的分析场景转向与业务交易场景的融合。对于联机查询的并发能力已经远超MPP时代,成为OLAP场景分布式数据库要考虑的一个重要问题。
除上述两点以外,GPDB架构中的Master节点承担了一定的工作负载,所有联机查询的数据流都要经过该节点,这样Master也存在一定的性能瓶颈。同时,在实践中GPDB对数据库连接数量的管理也是非常谨慎的。在我曾参与的项目中,Pivotal专家给出了一个建议的最大值且不会随着集群规模扩大而增大。
综上,大致可以得出结论,MPP(至少是GPDB)在集群规模上是存在一定限制的。
2000-2010年代,大多数股份制以上银行和少部分城商行都建立了数据仓库或ODS系统,主要采用了MPP产品。可以说,这十余年是MPP产品最辉煌的时代。到目前为止,MPP仍然是银行业建设数据仓库和数据集市类系统的主要技术选择。为了规避MPP并发访问上的缺陷以及批量任务对联机查询的影响,通常会将数据按照应用粒度拆分到不同的单体OLTP数据库中以支持联机查询。
MPP在相当长的一段时期内等同于一体机方案(以TD为代表),其价格高昂到普通企业无法承受,多数在银行、电信等行业的头部企业中使用。2010年代,随着大数据时代的开启,Hadoop生态体系以开源优势,获得了蓬勃发展和快速普及。
Hadoop技术体系大大降低了数据分析类系统的建设成本,数据分析挖掘等工作由此步入“数据民主化”时代。在Hadoop生态体系中,分析需求所需要的能力被拆分为批量加工和联机访问,通过不同的组件搭配实现。批量加工以MapReduce、Tez、Spark等为执行引擎,为了获得友好的语义支持,又增加了Hive、SparkSQL等组件提供SQL访问接口。
联机访问部分,则从早期Hive过渡到Impala、Hawk以及Kylin、Presto等方案逐渐降低了访问延时。
架构特点:
Hadoop生态体系下HDFS、Spark、Hive等组件已经有很多文章介绍,本文不再赘述。总的来说,其架构的着力点在于数据高吞吐处理能力,在事务方面相较MPP更简化,仅提供粗粒度的事务管理。
缺陷:
Hadoop也有其明显的缺陷,主要是三点:
批量加工效率较低
MPP的拥护者往往会诟病Hadoop计算引擎执行效率低。的确,在同等规模的集群执行相同的数据加工逻辑,即使与Spark对比,MPP所耗费的时间也会明显更少些[3],其主要的原因在于两者对于数据在磁盘和内存中的组织形式不同。
MPP从RDBMS而来(例如Vertica和GPDB都是基于PostgreSQL开发),对数据的组织形式更贴近传统方式,按区、段、块等单位组织,对数据进行了预处理工作以提升使用时的效率;Hadoop生态体系以HDFS文件存储为基础,HDFS并不像传统数据库那样独立管理一块连续的磁盘空间,而是将数据表直接映射成不同的数据文件,甚至表分区也以目录、文件等方式体现。
HDFS最简单的txt格式干脆就是平铺的数据文件,处理过程难免要简单粗暴一些,但随着Avro、ORCFile、Parquet等很多新的存储格式相继被引入,基于HDFS的批处理也更加精细。从整体架构来看,Hadoop更加看重大数据量批量处理的吞吐能力。
同时,Hadoop具备MPP所缺失的批量任务调整能力,数据的多副本存储使其具有更多“本地化”数据加工的备选节点,而且数据加工处理与数据存储并不绑定,可以根据节点的运行效率动态调整任务分布,从而在大规模部署的情况下具有整体上更稳定的效率。相比之下,MPP在相对较小的数据量下具有更好的执行效率。
不能无缝衔接EDW实施方法论
在长期的实践中,企业级市场的主流集成商针对EDW项目沉淀了一套固定的实施方法,与MPP特性相匹配,但Hadoop并不能与之无缝对接。一个最典型的例子是历史数据的存储,传统方法是采用“拉链表”的形式,即对于当前有效的数据会记录其生效的起始时间,在数据被更改或删除后,在该行记录的另外一列记录失效时间。这样,当前数据即变更为历史数据,通过这种增量的表述方式,节省了大量的存储空间和磁盘IO。
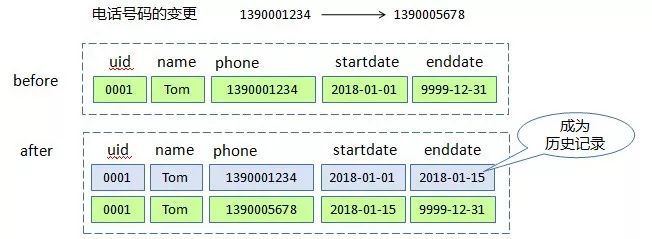
可以看出,拉链表的设计思想其实与基于时间戳的MVCC机制是相同的。
HDFS作为Hadoop的存储基础,其本身不提供Update操作,这样所有在数据操作层面的Update最终会被转换为文件层面的Delete和Insert操作,效率上显著降低。据我所知,在很多企业实践中会将这种增量存储转换为全量存储,带来大量数据冗余的同时,也造成实施方法上的变更。
联机查询并发能力不足
对于联机查询场景,最常见的是SQL on Hadoop方案,将Impala、HAWQ等MPP引擎架设在HDFS基础上,批量数据与联机查询共用一份数据。MPP引擎借鉴了MPP数据库的设计经验,相对Hive等组件提供了更低的延迟。但存在一个与MPP相同的问题,即并发能力不足。
通过一些项目测试中,我发现在大体相同的数据量和查询逻辑情况下, Impala并发会低于GPDB。其原因可能是多方面的,不排除存在一些调优空间,但在系统架构层面也有值得探讨的内容。例如在元数据读取上,Impala复用了Hive MetaStore,但后者提供的访问服务延时相对较长,这也限制了Impala的并发能力[7]。
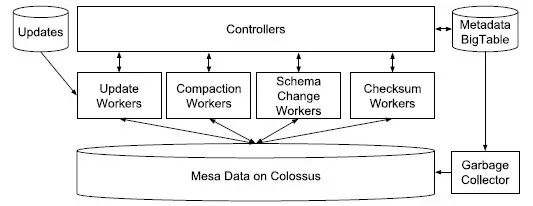
Mesa是Google开发的近实时分析型数据仓库,2014年发布了论文披露其设计思想[5],其通过预聚合合并Delta文件等方式减少查询的计算量,提升了并发能力。
Mesa充分利用了现有的Google技术组件,使用BigTable来存储所有持久化的元数据,使用了Colossus (Google的分布式文件系统)来存储数据文件,使用MapReduce来处理连续的数据。
Mesa相关的开源产品为Clickhouse[6](2016年Yandex开源)和Palo[7](2017年百度开源)。
特点:
目前ClickHouse的资料仍以俄语社区为主,为便于大家理解和进一步研究,下面主要以Palo为例进行说明。
Palo没有完全照搬Mesa的架构设计的思路,其借助了Hadoop的批量处理能力,但将加工结果导入到了Palo自身存储,专注于联机查询场景,在联机查询部分主要借鉴了Impala技术。同时Palo没有复用已有的分布式文件系统和类BigTable系统,而是设计了独立的分布式存储引擎。虽然数据存储上付出了一定的冗余,但在联机查询的低延迟、高并发两方面都得到了很大的改善。
Palo在事务管理上与Hadoop体系类似,数据更新的原子粒度最小为一个数据加载批次,可以保证多表数据更新的一致性。
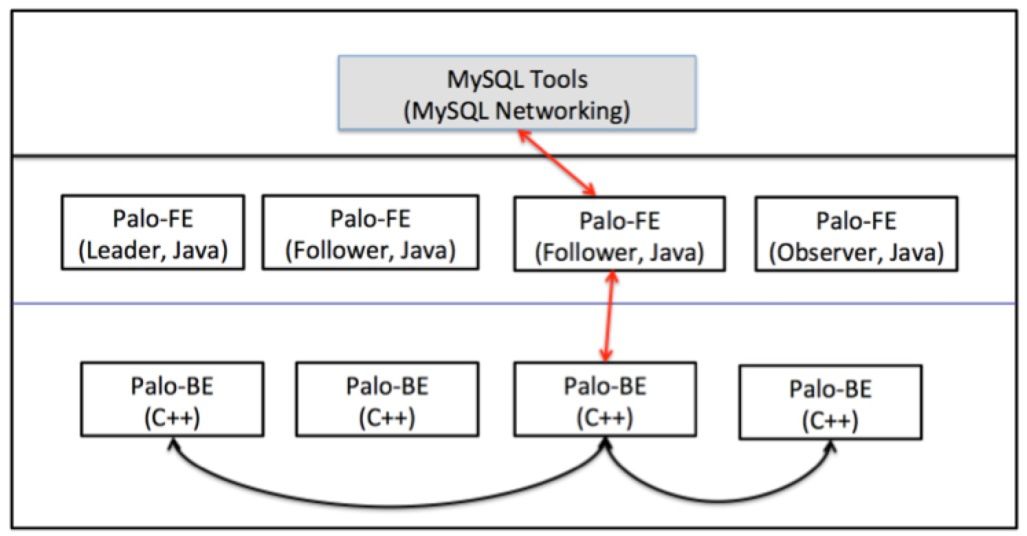
整体架构由Frontend和Backend两部分组成,查询编译、查询执行协调器和存储引擎目录管理被集成到Frontend;查询执行器和数据存储被集成到Backend。Frontend负载较轻,通常配置下,几个节点即可满足要求;而Backend作为工作负载节点会大幅扩展到几十至上百节点。数据处理部分与Mesa相同采用了物化Rollup(上卷表)的方式实现预计算。
Palo和ClickHouse都宣称实现了MPP Data Warehouse,但从架构上看已经与传统的MPP发生很大的变化,几乎完全舍弃了批量处理,专注于联机部分。
ClickHouse和Palo作为较晚出现的开源项目,还在进一步发展过程中,设定的使用场景以广告业务时序数据分析为主,存在一定局限性,但值得持续关注。
以上是我对OLAP场景“分布式数据库”横向的概要分析,我们两个拆解维度中的第一部分,对不同的“分布式数据库”的横向探讨至此就告一段落了,其中还有很多有趣的话题,我们可以留待后续文章继续讨论。
至于第二部分——对“分布式数据库”的纵向探讨,我将结合NoSQL与NewSQL的差异,纵向来谈谈OLTP场景“分布式数据库”实现方案的关键技术要点。感兴趣的同学敬请继续关注DBAplus社群后续文章的发布。
文献参考:
[1] http://en.wikipedia.org/wiki/Massively_parallel
[2] http://greenplum.org/gpdb-sandbox-tutorials/introduction-greenplum-database-architecture/#ffs-tabbed-11
[3] Apache HAWQ: Next Step In Massively Parallel Processing,
https://content.pivotal.io/blog/apache-hawq-next-step-in-massively-parallel-processing
[4] 对比MPP计算框架和批处理计算框架,
http://blog.csdn.net/rlnLo2pNEfx9c/article/details/78955006
[5] A. Gupta and et al., “Mesa: Geo-replicated, near real-time, scalabledata warehousing,”PVLDB, vol. 7, no. 12, pp. 1259–1270, 2014.
[6] http://clickhouse.yandex
[7] http://github.com/baidu/palo








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721