
如果你每天都在和 Kubernetes 打交道,那么你一定遇到过这些问题:
Pod 一直 Pending,到底卡在哪?
镜像明明没问题,为什么一直 CrashLoopBackOff?
Service 明明是通的,但就是访问不到?
Ingress 能访问本地,用域名就不行?
PVC 绑定了但 Pod 还是挂载不了?
Node 时不时 NotReady,到底怎么查?
你只要照着本文从上到下查,一定能快速定位绝大多数 K8S 问题,建议收藏起来慢慢看。
排查路径:
Pod → 容器 → 应用 → Service → Ingress → 存储 → Node → 网络
流程图如下:
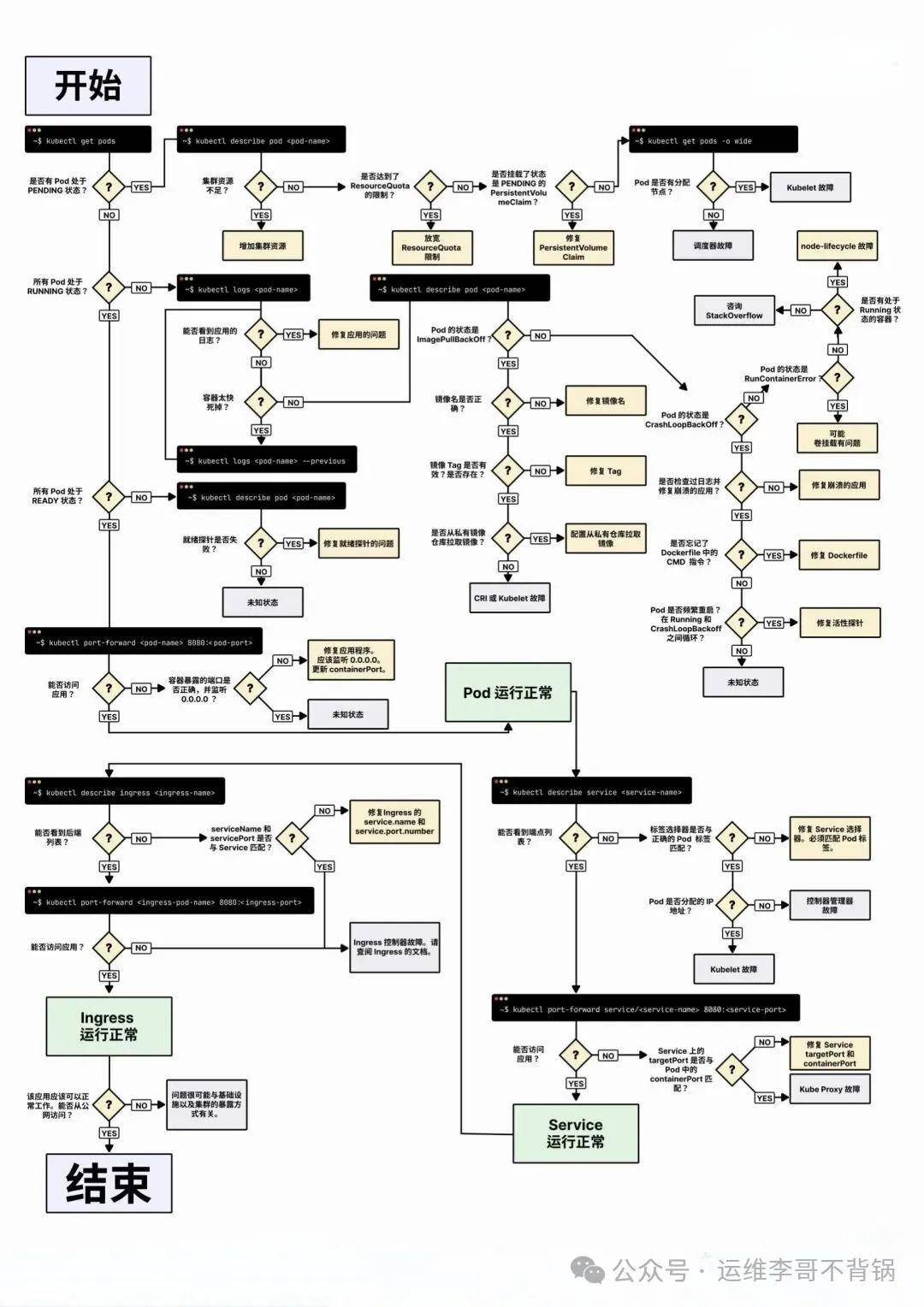
图片来源网络
一、Pod 故障排查
首先查看Pod状态,看看是否被成功调度。
kubectl get pods -o wide
如果你的 Pod 迟迟 Pending,那意味着:
调度器压根没把 Pod 扔到某个节点上。
很多人看到 Pending 就只盯着 Pod,实际上:
90% 的 Pending,最终都查到节点问题上。
检查:
kubectl get nodes
Node NotReady 的常见原因:
kubelet 掉线
容器运行时挂掉
节点磁盘满
CNI 网络插件崩
看事件:
kubectl describe pod <pod>
出现:
Insufficient CPU
Insufficient Memory
ephemeral-storage 不够
那就:
释放节点资源
调整 Pod request
减少同节点 Pod
扩容节点
如果Namespace 设置了限额:
kubectl describe quota -n <ns>
尤其是多人共用命名空间的公司,超限是常态。如果是配额不足,增加配额就行
只要涉及存储的 Pod,PVC 一挂,Pod 就 Pending。
查看:
kubectl get pvc
kubectl describe pvc
常见原因:
没有适配条件的 PV,创建PV
StorageClass 的 provisioner 不存在
云盘 zone 与 Node 不一致(经典)
还有可能设置了nodeAffinity
二、容器启动失败排查
如果 Pod 已调度但未进入 Running:
kubectl describe pod <pod>
常见状态:ImagePullBackOff / ErrImagePull
镜像拉取失败会出现:ImagePullBackOff状态
检查:
镜像 tag 拼错
registry 地址不对
私有仓库缺 secret
节点根本连不上仓库(最常发生在内网)
看事件:
kubectl describe pod
查看日志:
kubectl logs <pod>
kubectl logs <pod> --previous
常见情况:
空指针
依赖数据库连接失败
应用端口被占用
配置文件找不到
探针探一探就把你的服务杀了
CMD 写错命令
entrypoint 文件没执行权限
脚本少 #!/bin/sh
多阶段构建没把文件 copy 全
三、应用就绪失败排查
Pod Running 但 Ready=false 时:
Readiness 或 Liveness Probe 配置错误最常见:
path 错误(如 /health 实际为 /healthz)
端口错误
探针阈值过低导致频繁重启
测试本地端口:
kubectl exec -it <pod> -- curl localhost:<port>
kubectl exec <pod> -- netstat -tlnp
若应用监听8000,但 containerPort 配置8080 → 必失败。
kubectl port-forward <pod> 8888:<pod-port>
如果这样访问仍不通 → 应用内部问题(非 K8S 问题)。
port-forward 能访问
Service 不能访问
那问题一定不在 Pod,而可能在 Service。
四、Service问题排查
你能猜到多少人在这里栽? 80%。
kubectl describe svc <name>
如果看到:
Endpoints: <none>
说明 selector 未找到 Pod。Service 压根没找到任何对应上的Pod。
解决方法:
修正 selector
或修正 Pod labels
kubectl get pod --show-labels
必须保证三者一致:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
不一致即无法访问。
极少出现,但一旦出现影响面巨大。
如果 Service 仍不通:
Kube-proxy 异常
iptables 规则损坏
CNI 网络不通
可检查:
systemctl status kube-proxy
kubectl get po -A |grep kube-proxy
iptables -t nat -L
ipvsadm -Ln
五、Ingress问题排查
Ingress 能本地通但域名不通的花,很可能规则写错了。
查看:
kubectl describe ingress
检查:
是否匹配 host?
path 是否精确匹配?
serviceName 是否写错?
servicePort 是否写错?
例如 NGINX ingress:
kubectl get pods -n ingress-nginx
没有 controller → Ingress 根本不会生效。
如果:
Pod 正常
Service 正常
Ingress port-forward 正常
域名访问不通
那就一定是:
域名没解析
LB 没创建
防火墙没开端口
这是最常见的“锅不在 K8S,而在外部”。
六、存储问题
存储问题是 K8S 故障中最容易被忽略,但也最致命。
如果你的 Pod 涉及挂载(数据库、文件服务、日志、缓存等),你必须看这部分。
查看:
kubectl get pvc
kubectl describe pvc
常见原因:
没有满足要求的 PV
StorageClass 无效
静态 PV 无法分配
zone / region 不一致
Pod 事件会显示:
MountVolume.WaitForAttach failed
Could not mount device
原因:
云硬盘已挂载到其他节点
存储系统权限不足
ceph/NFS server 不可达
Secret 缺失(Ceph/RBD 常见)
进入pod检查
kubectl exec -it <pod> -- df -h
kubectl exec -it <pod> -- ls /mnt/path
很多时候 Pod 起不来只是因为文件系统炸了。
Pod 会因临时存储耗尽而重启:
kubectl describe node <node>
事件中若有:
evicted: ephemeral storage
解决:
扩容节点磁盘
清理 /var/lib/docker 或 containerd 数据
调整 Pod 的 ephemeral-storage request/limit








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721