
线上千万级的大表在新增字段的时候,一定要小心,我见过太多团队在千万级大表上执行DDL时翻车的案例。
很容易影响到正常用户的使用。
这篇文章跟大家一起聊聊线上千万级的大表新增字段的6种方案,希望对你会有所帮助。
一、为什么大表加字段如此危险?
核心问题:MySQL的DDL操作会锁表。
当执行ALTER TABLE ADD COLUMN时:
通过实验验证锁表现象:
-- 会话1:执行DDL操作
ALTER TABLE user ADD COLUMN age INT;
-- 会话2:尝试查询(被阻塞)
SELECT * FROM user WHERE id=1; -- 等待DDL完成
锁表时间计算公式:
锁表时间 ≈ 表数据量 / 磁盘IO速度
对于1000万行、单行1KB的表,机械磁盘(100MB/s)需要100秒的不可用时间!
如果在一个高并发的系统中,这个问题简直无法忍受。
那么,我们要如何解决问题呢?
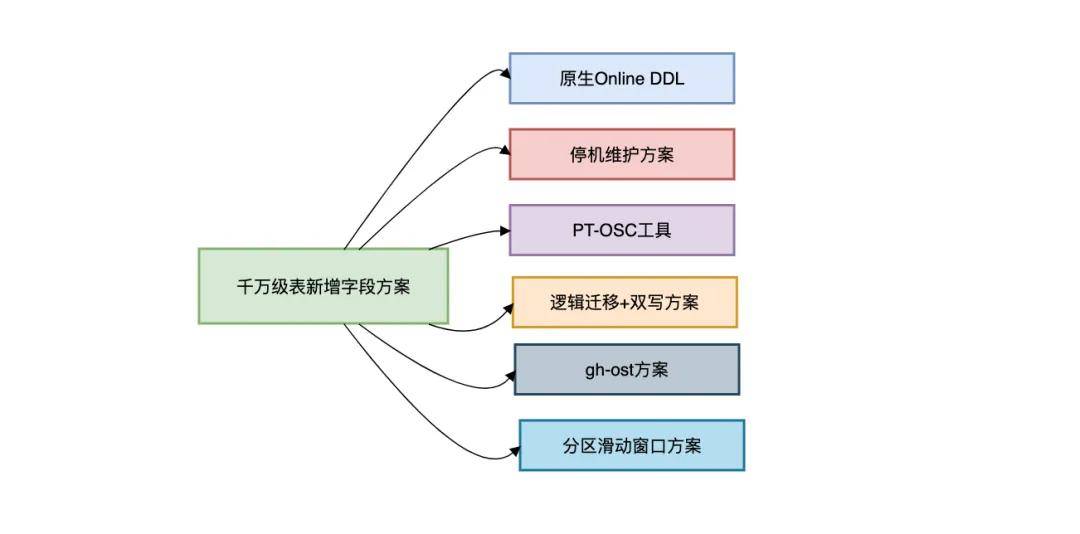
二、原生Online DDL方案
在MySQL 5.6+版本中可以使用原生Online DDL的语法。
例如:
ALTER TABLE user
ADD COLUMN age INT,
ALGORITHM=INPLACE,
LOCK=NONE;
实现原理:

致命缺陷:
三、停机维护方案
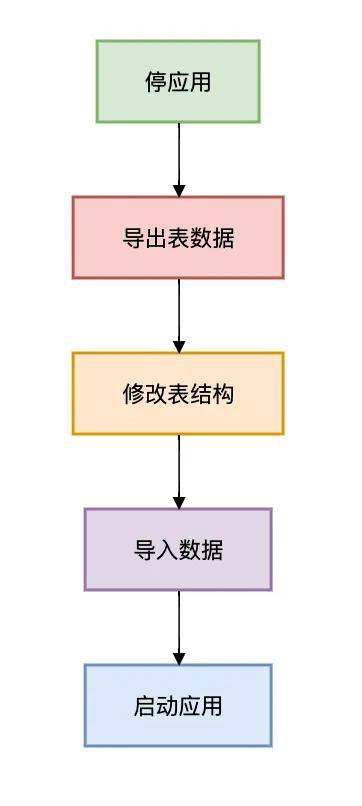
适用场景:
四、使用PT-OSC工具方案
Percona Toolkit的pt-online-schema-change这个是我比较推荐的工具。
工作原理:

操作步骤:
# 安装工具
sudo yum install percona-toolkit
# 执行迁移(添加age字段)
pt-online-schema-change \
--alter "ADD COLUMN age INT" \
D=test,t=user \
--execute
五、逻辑迁移 + 双写方案
还有一个金融级安全的方案是:逻辑迁移 + 双写方案。
适用场景:
实施步骤:
1、创建新表结构
-- 创建包含新字段的副本表
CREATE TABLE user_new (
id BIGINT PRIMARY KEY,
name VARCHAR(50),
-- 新增字段
age INT DEFAULT 0,
-- 增加原表索引
KEY idx_name(name)
) ENGINE=InnoDB;
2、双写逻辑实现(Java示例)
// 数据写入服务
publicclass UserService {
@Transactional
public void addUser(User user) {
// 写入原表
userOldDAO.insert(user);
// 写入新表(包含age字段)
userNewDAO.insert(convertToNew(user));
}
private UserNew convertToNew(User old) {
UserNew userNew = new UserNew();
userNew.setId(old.getId());
userNew.setName(old.getName());
// 新字段处理(从其他系统获取或默认值)
userNew.setAge(getAgeFromCache(old.getId()));
return userNew;
}
}
3、数据迁移(分批处理)
-- 分批迁移脚本
SET @start_id = 0;
WHILE EXISTS(SELECT1FROMuserWHEREid > @start_id) DO
INSERTINTO user_new (id, name, age)
SELECTid, name,
COALESCE(age_cache, 0) -- 从缓存获取默认值
FROMuser
WHEREid > @start_id
ORDERBYid
LIMIT10000;
SET @start_id = (SELECTMAX(id) FROM user_new);
COMMIT;
-- 暂停100ms避免IO过载
SELECTSLEEP(0.1);
ENDWHILE;
4、灰度切换流程

这套方案适合10亿上的表新增字段,不过操作起来比较麻烦,改动有点大。
六、使用gh-ost方案
gh-ost(GitHub's Online Schema Transmogrifier)是GitHub开源的一种无触发器的MySQL在线表结构变更方案。
专为解决大表DDL(如新增字段、索引变更、表引擎转换)时锁表阻塞、主库负载高等问题而设计。
其核心是通过异步解析binlog,替代触发器同步增量数据,显著降低对线上业务的影响。
1、与传统方案对比
1)触发器方案(如pt-osc)
在源表上创建INSERT/UPDATE/DELETE触发器,在同一事务内将变更同步到影子表。
痛点:
2)gh-ost方案
关键流程:

全量拷贝:按主键分块(chunk-size控制)执行INSERT IGNORE INTO _table_gho SELECT ...,避免重复插入
增量同步:
原子切换(Cut-over):
典型命令示例:
gh-ost \
--alter="ADD COLUMN age INT NOT NULL DEFAULT 0 COMMENT '用户年龄'" \
--host=主库IP --port=3306 --user=gh_user --password=xxx \
--database=test --table=user \
--chunk-size=2000 \ # 增大批次减少事务数
--max-load=Threads_running=80 \
--critical-load=Threads_running=200 \
--cut-over-lock-timeout-seconds=5 \ # 超时重试
--execute \ # 实际执行
--allow-on-master # 直连主库模式
2、监控与优化建议
进度跟踪:
echo status | nc -U /tmp/gh-ost.sock # 查看实时进度
延迟控制:
切换安全:
七、分区表滑动窗口方案
适用场景:
核心原理: 通过分区表特性,仅修改最新分区结构。
操作步骤:
修改分区定义:
-- 原分区表定义
CREATETABLElogs (
idBIGINT,
log_time DATETIME,
contentTEXT
) PARTITIONBYRANGE (TO_DAYS(log_time)) (
PARTITION p202301 VALUESLESSTHAN (TO_DAYS('2023-02-01')),
PARTITION p202302 VALUESLESSTHAN (TO_DAYS('2023-03-01'))
);
-- 添加新字段(仅影响新分区)
ALTERTABLElogsADDCOLUMN log_level VARCHAR(10) DEFAULT'INFO';
创建新分区(自动应用新结构):
-- 创建包含新字段的分区
ALTER TABLE logs REORGANIZE PARTITION p202302 INTO (
PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01')),
PARTITION p202303 VALUES LESS THAN (TO_DAYS('2023-04-01'))
);
历史数据处理:
-- 仅对最近分区做数据初始化
UPDATE logs PARTITION (p202302)
SET log_level = parse_log_level(content);
八、千万级表操作注意事项
SHOW SLAVE STATUS;
-- 确保Seconds_Behind_Master < 10
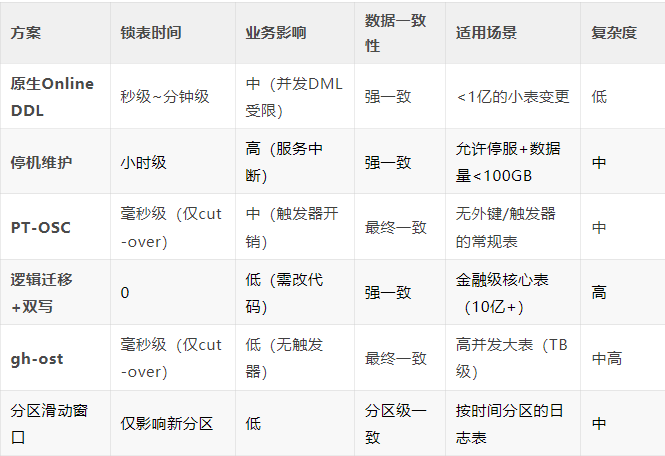
九、各方案对比
以下是针对千万级MySQL表新增字段的6种方案的对比。
总结
1、常规场景(<1亿行):
2、高并发大表(>1亿行):
3、金融核心表:
4、日志型表:
5、紧急故障处理:
给大家一些建议:
加字段前优先使用 JSON字段预扩展(ALTER TABLE user ADD COLUMN metadata JSON)
万亿级表建议 分库分表 而非直接DDL
所有方案执行前必须 全量备份(mysqldump + binlog)
流量监测(Prometheus+Granfa实时监控QPS)
在千万级系统的战场上,一次草率的ALTER操作可能就是压垮骆驼的最后一根稻草。
作者丨苏三
来源丨公众号:苏三说技术(ID:susanSayJava)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721