

讲师介绍
张静,京东科技智能运维算法高级经理。硕士毕业于东北大学,持续深耕智能运维领域多年,带领团队致力于京东智能运维算法迭代,把智能算法能力落地京东线上横向业务场景,算法在监控、数据库、网络、资源调度等多个纵向场景取得突破,提升了产品和运维的技术竞争力。善于将实践中沉淀的技术与日常算法工作中积累的技术与创新总结成专利和IEEE论文,申请智能运维发明专利50余项,IEEE国际会议论文收录9篇。
分享概要
一、京东科技智能运维整体能力
二、运维算法赋能业务可观测性落地经验
三、运维算法赋能降本增效落地经验
一、京东科技智能运维整体能力
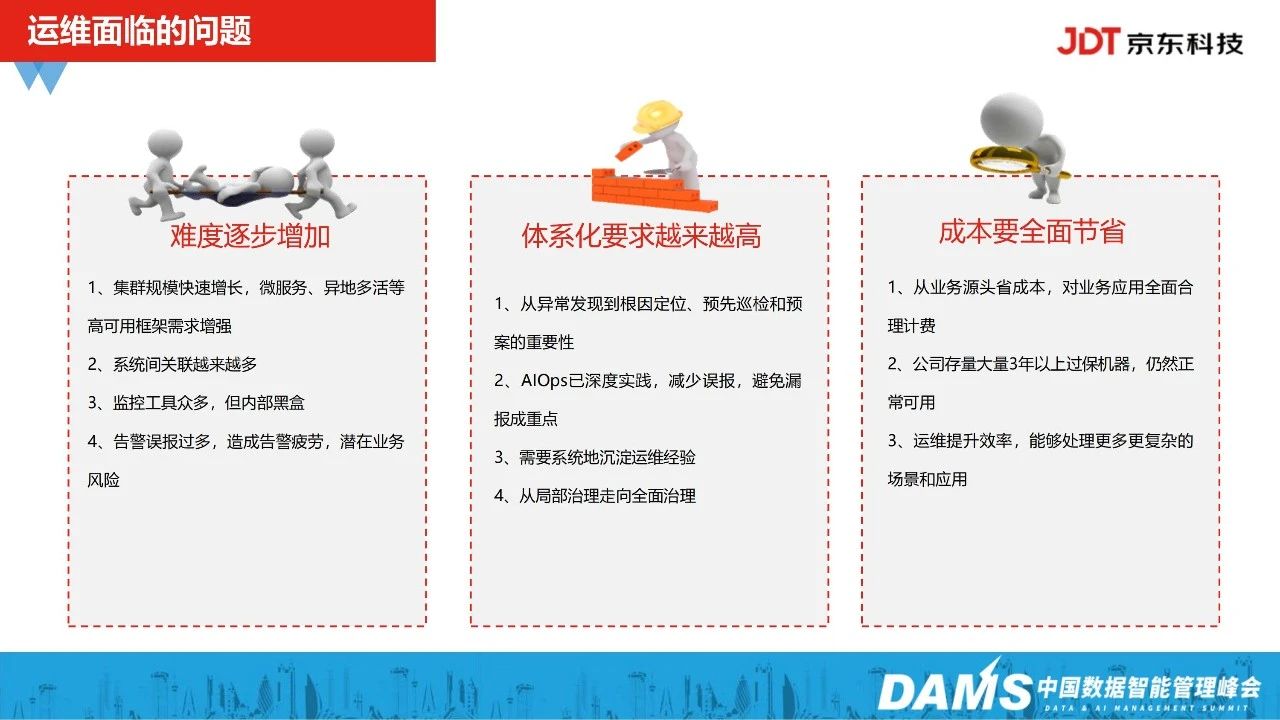
我们在2018年就开始建设了智能运维,针对京东科技内部,我们运维面临的问题主要是三点:
难度逐步增加
体系化要求越来越高
成本要全面节省
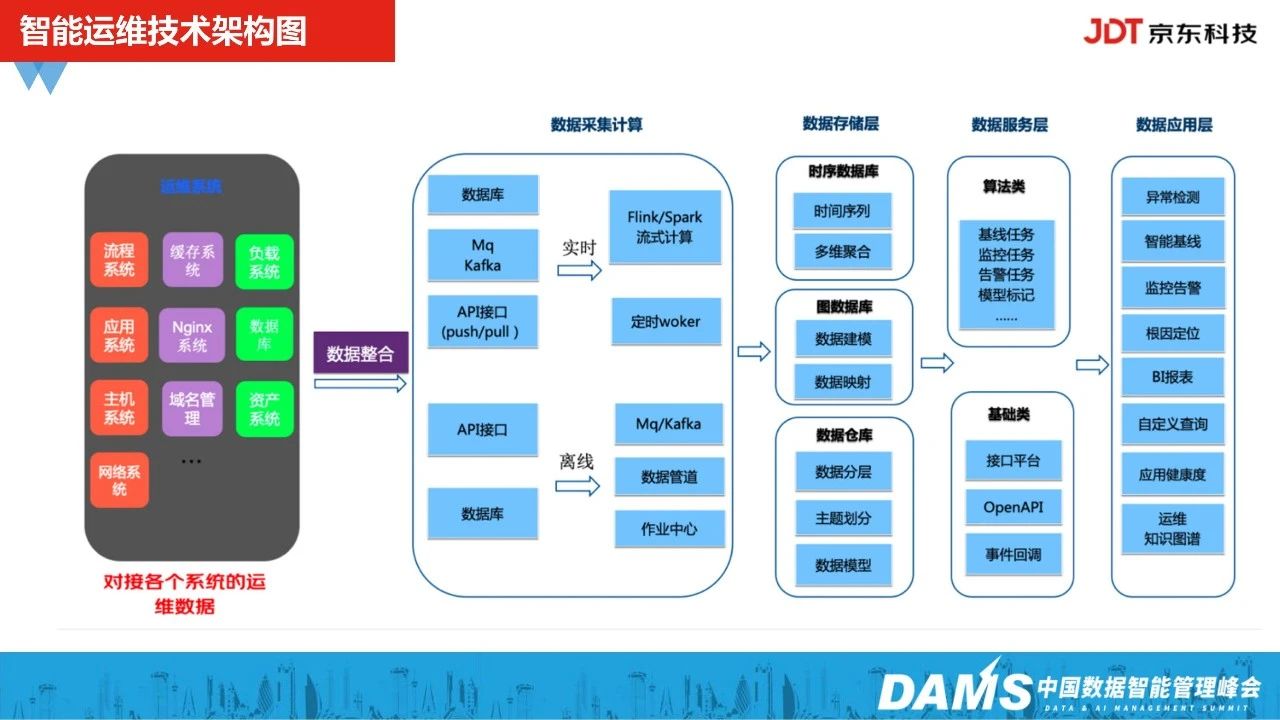
我们在建设智能运维的基本目标与业界是一致的,主要都是为了降低故障的平均修复时间,延长系统的无故障的运行的时间,以此提升系统的可用性以及运维效率。在京东内部,主要依托于三大技术底座:运维知识图谱、运维大数据处理技术、运维算法技术。

为赋能三大技术底座,我们主要做了两件事情:
一是通过运维算法技术,赋能我们的业务运维的监控,做到故障的快速发现和快速定位;
二是运维算法赋能智能调度,提升资源的利用率。以及在去年开始,我们在硬件故故障预测上也投入了研发,并实现了场景落地。
下图是我们智能运维的一个技术架构图,主要包含数据采集计算层、数据存储层、数据服务层、数据应用层。
此外,我们也会在每年618双十一大促前,会对我们的业务应用进行应用健康度的体检,并对核心应用也会进行整改,整体能力依托于我们运维知识图谱的建设。

上图我们整个京东科技智能运维产品的一个全景图,主要包含数据层(脑)、学件层(心)、业务层(眼)。
二、运维算法赋能业务可观测性落地经验
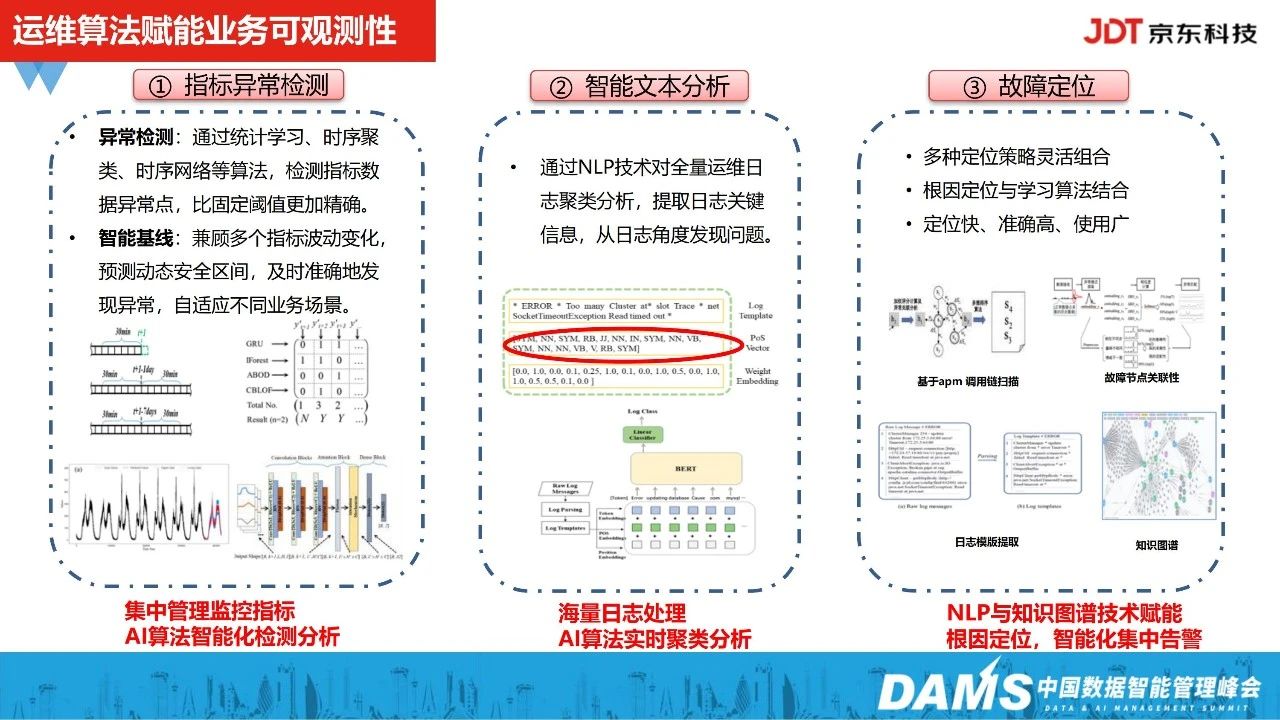
1、指标异常检测
指标异常检测主要是为实现集中管理监控指标,并通过运维算法技术自动化地对在线的时序监控指标进行异常诊断。
在日志分析上,我们能够对线上服务组件这类日志进行实时聚类分析,包括通过日志实时语义匹配转成指标等监控手段,从日志、指标层面的不足。
在故障定位上,主要分为两种,一是基于apm调用链的关联分析扫描全局的故障根因,二是将NLP日志模板提取技术,与运维图谱关系进行融合,集中对整体的故障根因进行扫描分析。
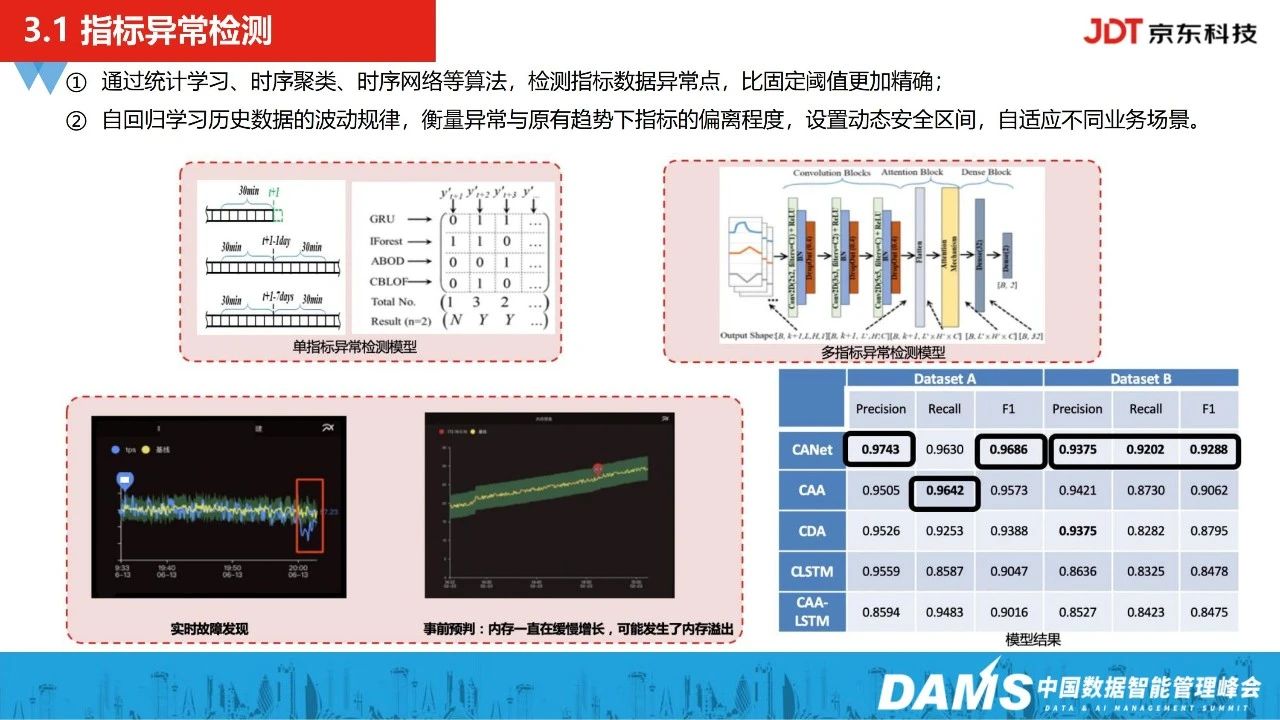
异常检测最开始引入了统计学习落地试点,后面则引入了时序聚类、时序网络等异常检测算法,相比于固定阈值,能否自适应去适配不同场景下的监控数据。除了异常检测外,我们还做了一套自回归动态基线的预测算法能力沉淀。在京东内部,主要落地了两个场景:
一是学习历史数据7-14天的指标波动规律性,对指标的未来趋势及动态波动区间做预测,当跌破动态区间时,就会实时发出这类告警;
二是做事前的判断,比如内存使用率开始从20%增加到30%-40%时,不会引起运维同学的关注,但可能突然间10-15分钟会达到80%,这时候可能就会反应不归来,因此,我们会去提前发下这类数据的增长趋势,在故障真正发生的时候,争取故障处理的响应时间。
另外,在异常检测以及动态基线预测模型上,我们在内部多个数据集上的准确率评估有90%以上,目前这套模型也有被IEEE的国际论文所收录。
2、智能文本分析
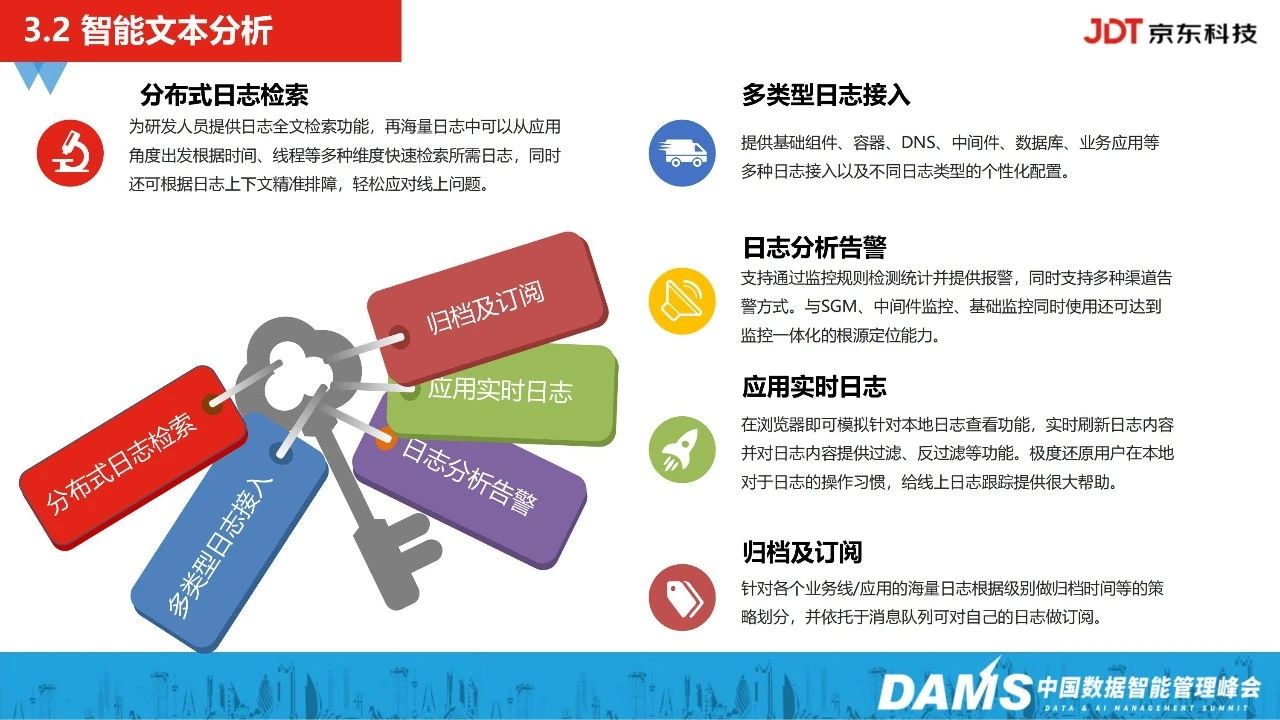
京东科技有一款自研产品能够支持包括基础组件、容器、中间件、数据库等多类型的日志接入,日志接入之后,能够支持分布式日志检索并进入智能分析层。因此,故障发生的时候,运维同学除了接收智能告警之外,还能通过平台快速查询,去看实时的日志。

在日志接入智能分析层后,会对运维日志进行模板的提取和预聚类,能及时发现一些线上未知的业务问题。此外,如果出现监控指标没有采集上来、配置的监控告警并不准确、告警没有及时发出等问题,我们也可以通过日志分析的手段,结合图谱关系定位到真正的根因。
智能文本分析主要引入了NLP的技术,对全量运维日志进行聚类分析,训练生成日志模板,运维、研发同学会在平台标注关心的问题,再生成模板库,在线实时匹配已知问题。也就是说,我们会将原始的运维日志,按照预定义好的类别进行语义匹配,并转成时序的监控指标,当一类问题日志突增时,我们也会及时发出告警。
我们在实践中也发现,不管是哪一种运维场景,对日志里面的动词、形容词、名词都是较关心的,所以为了提升整个日志分析模型的准确度,我们引入了词性分析技术,做了一部分特征增强。模型部分我们也是用Bert预训练模型,并对Bert模型进行微调。
和业界deep log、logclass等比较火的模型相比,我们这套模型的效果都是较优的,目前这套模型有被IEEE论文所收录。
大家在做运维日志NLP分析的时候,可能会面临一个问题:到底要标注对少日志,才算完成了模型学习?
针对这个问题,我们采用的是半监督的方式。比如运维、研发同学会定期收到告警通知,里面会详细记录新日志产生量、占比量及告知标注需要,他们就会进入智能运维平台,对所关心的问题进行定义,标注出来的部分则训练出基于词性标注的命名实体抽取模型,将其他相似文本中比较关系的实体抽取出来,再辅以运维、研发同学进行日志问题标注。
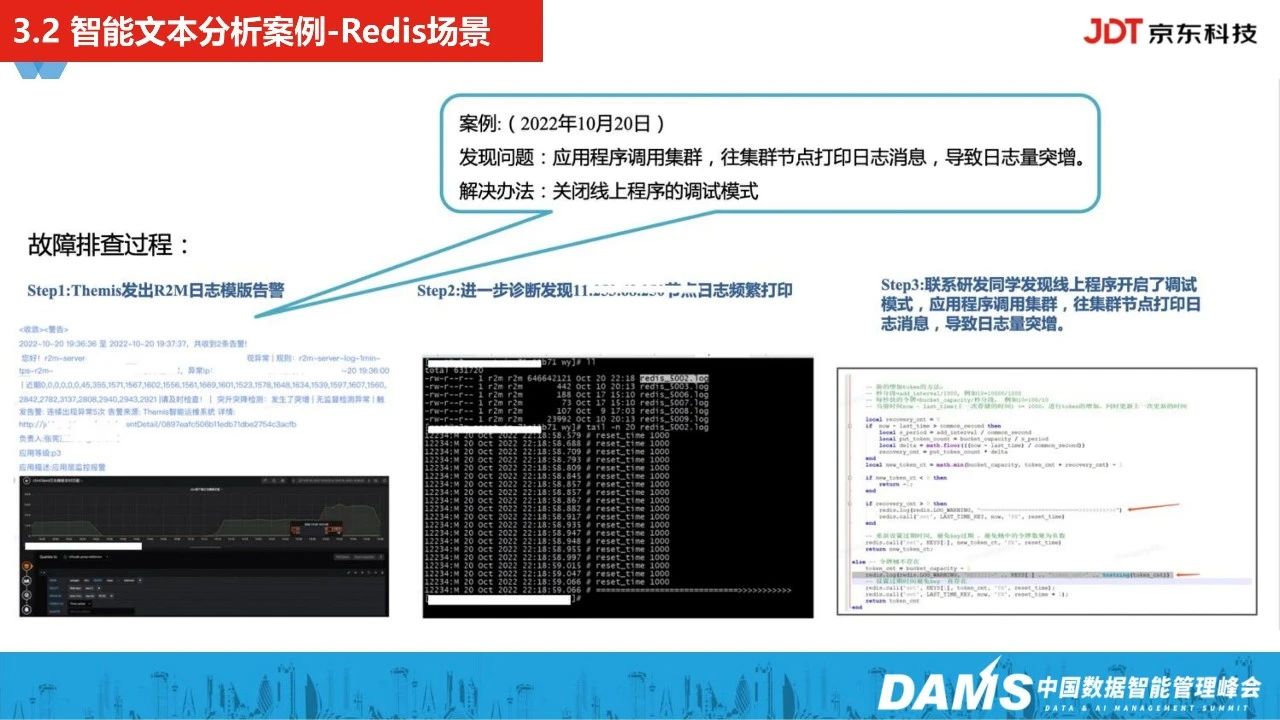
下面对京东科技内部的智能文本分析案例-k8s场景进行介绍:

我们通过k8s核心组件日志的实时聚类以及实时语义匹配,发现一些在指标层面发生不了的问题,比如日志占用文件句柄没释放、孤儿pod问题等。
上面是去年双十一大促备战前的案例,应用程序去调用集群时,我们发现它在往某一个集群缓存的节点频繁打印日志。自动触发诊断告警后,PE同学紧急排查,发现这个节点关联到的是大促比较核心的一个应用,联系应用研发同学后发现,确实是线上程序开启了调试模式,导致应用调用集群时,频繁往这个节点打印日志,调试模式关闭后,也规避了在大促中可能出现的计算瓶颈问题。
在京东内部落地时,除了有按场景的服务组件日志,还有缓存、大数据、MySQL、网络设备的日志。另外,近两年做的比较多的k8s的node日志分析,实现了快速发现线上未知故障,发现了之前通过监控发现不了的那些问题。
另外,运维日志分析落地到了不同场景,包括日志聚类、模板训练提取、语义分析和日志分类等,我们也做了部分的模型蒸馏,这部分的实践目前IEEE论文收录了5项。
另外,我们也做了应用告警日志的MySQL、Redis根因分析。
3、健康度巡检
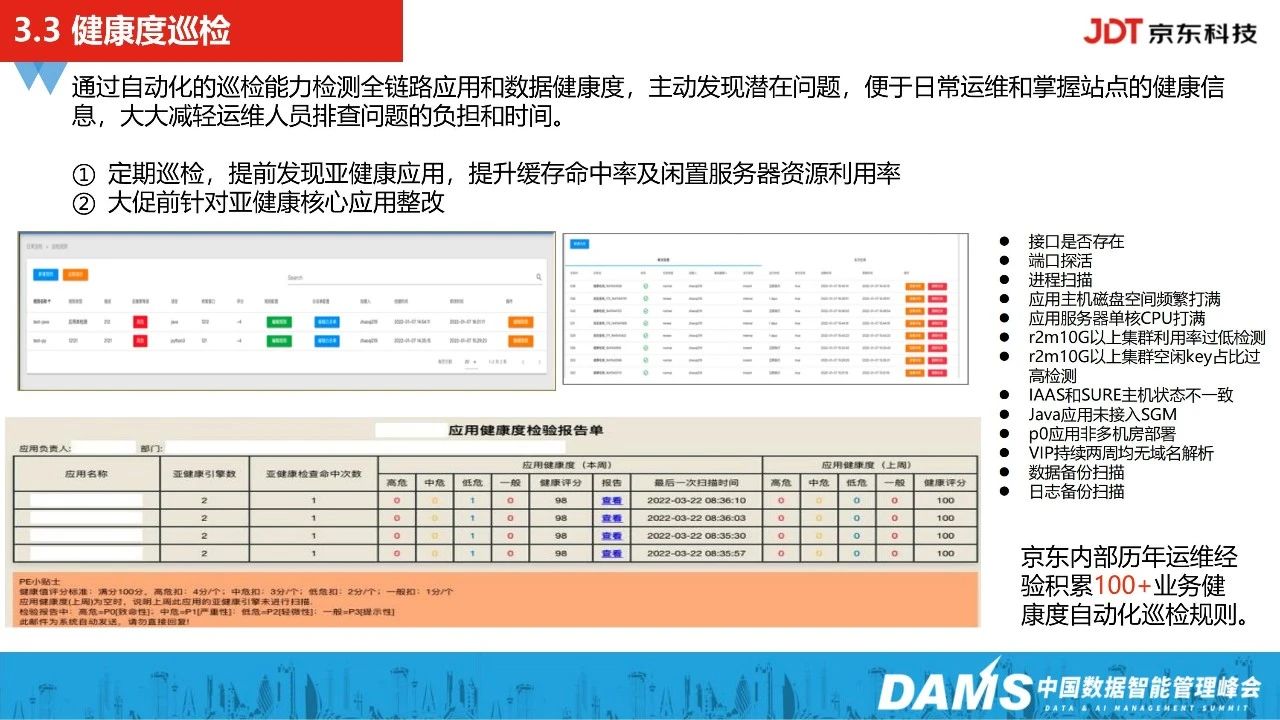
接下来是健康度巡检,其主要方式是结合运维专家排障制定巡检的规则及异常检测的能力,主动对线上核心的应用进行巡检,去发现一些潜在问题,并分析数据健康度等,并且在大促重保之前,我们会对这些亚健康的应用进行核心整改。
另外,通过这套自动化巡检能力,我们也能够提升缓存的命中率,提升闲置服务器资源的使用率,经过历年运维场景的经验积累,我们目前有100+的应用业务巡检规则。
4、全链路监控体系
接下来全链路故障定位落地实践,其中包括移动端、前端、服务端等监控。
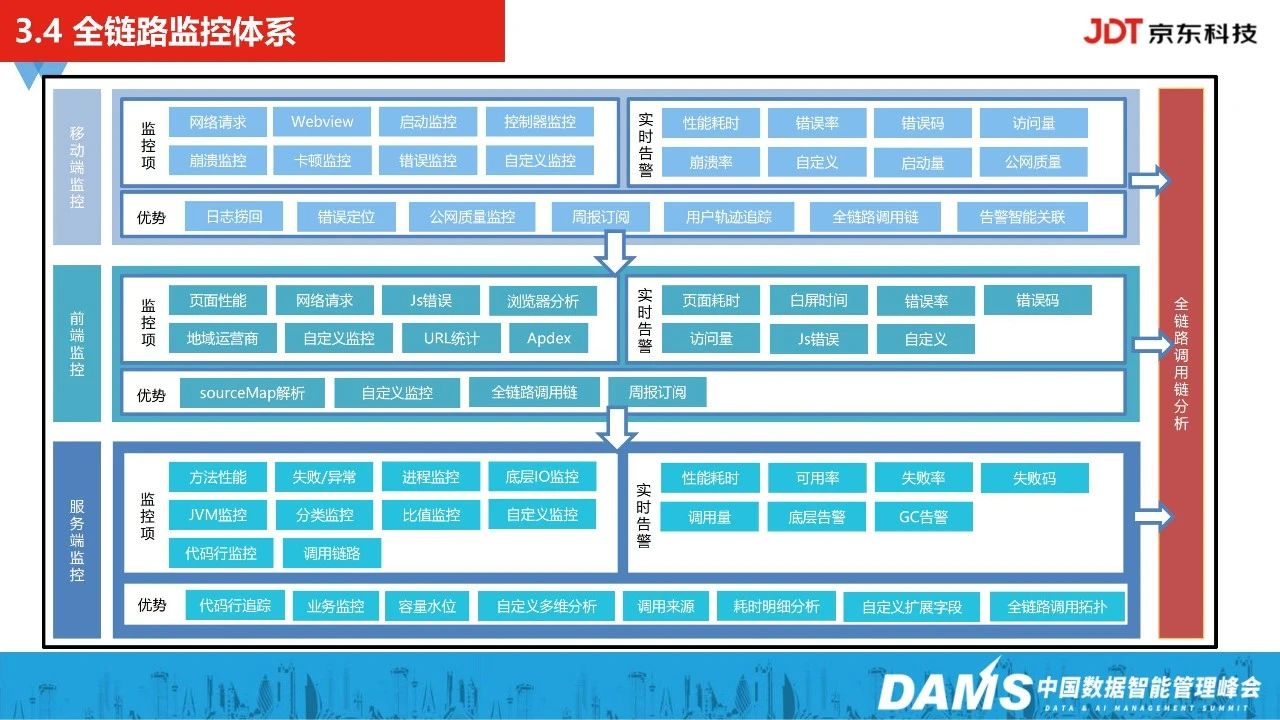
服务一旦发生瓶颈,可以综合分析调用链、接口耗时、返回状态码、异常日志,网络日志等,快速诊断问题。
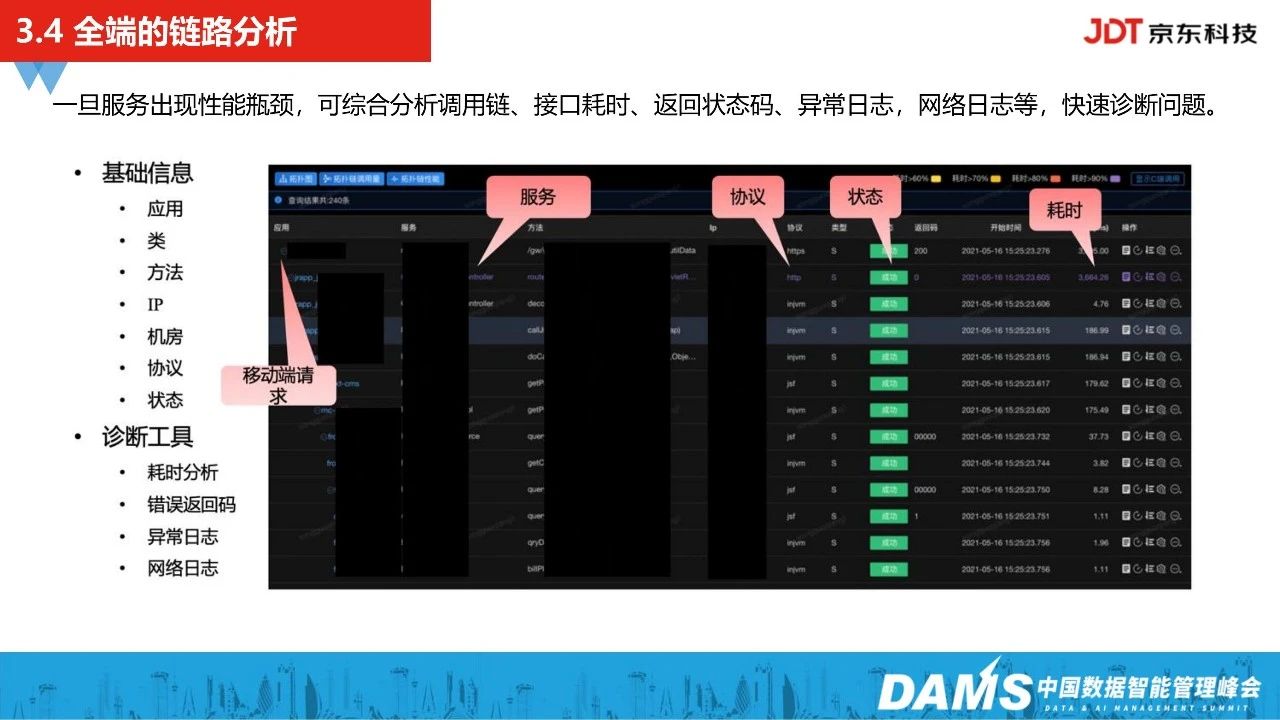
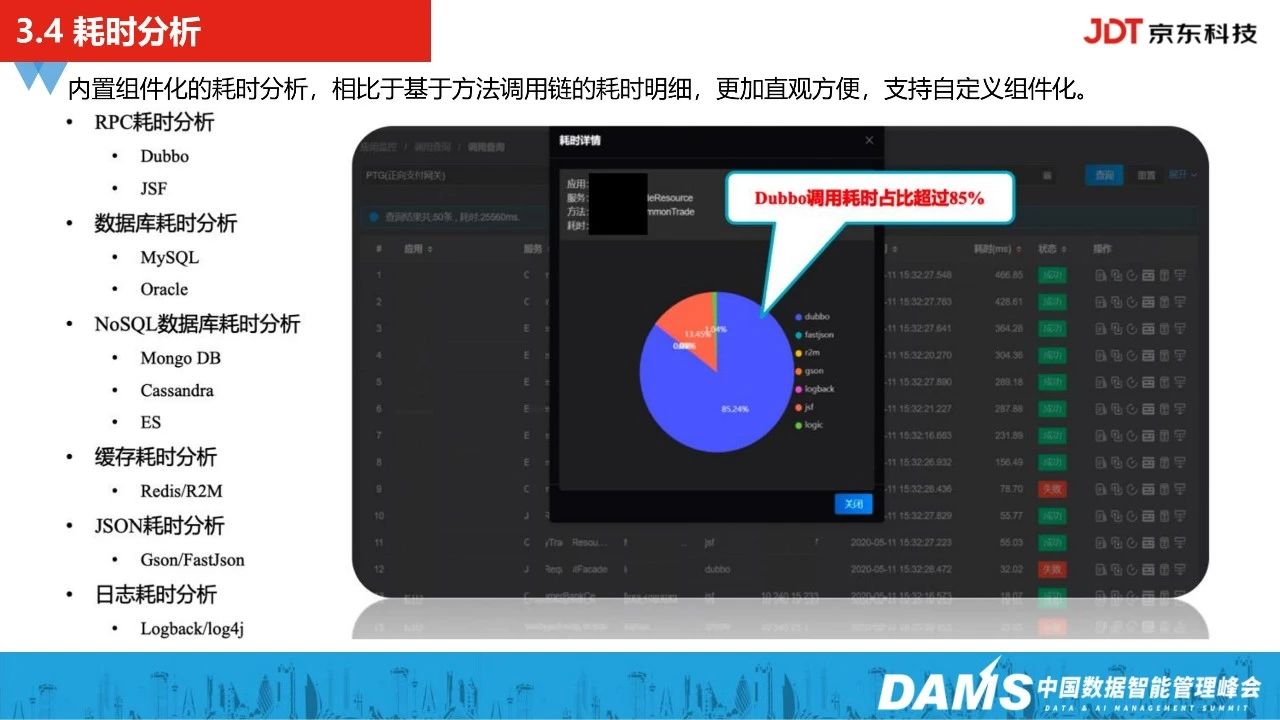
同时,我们还能通过这套全链路监控的追踪能力,去看每一块节点的耗时占比情况。
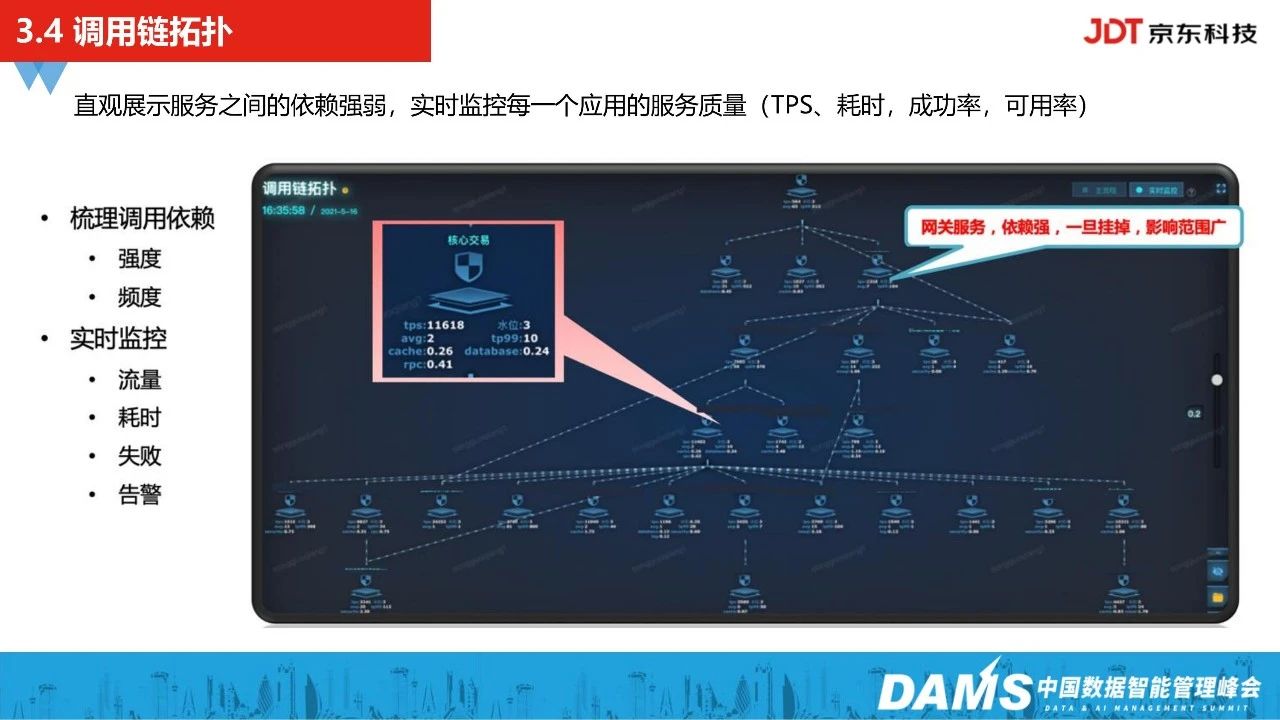
另外,我们自动化生成了调用链拓扑关系,直观展示服务之间的依赖强弱,实时监控每一个应用的服务质量(TPS、耗时、成功率、可用率)。
再者,将整个全链路的监控数据,统一地收集起来输入到智能运维监控中心,再做全局的根因定位。

在京东内部,主机问题定位及排查、操作变更、网络/数据库等场景,都覆盖了这套全链路监控,大促等重保期间都会投入使用,出现问题故障时,运维、研发用都较依赖于这套全链路监控体系。
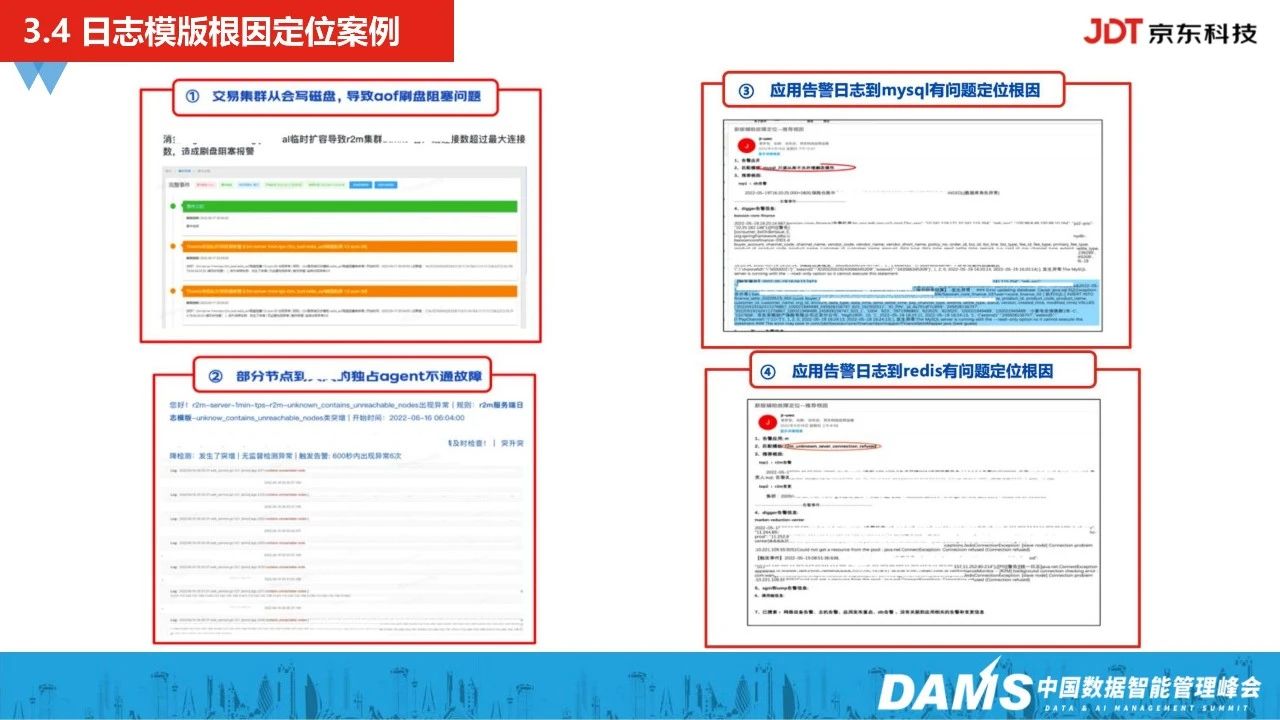
上图关于日志模板根因定位的一个案例,在2022年618大促期间,我们从缓存服务端的组件层面发现一类日志模板大量突增,是一个AOF盘阻塞问题,恰好该问题直接关联到业务营销应用,关联到的客户端连接数超过最大连接数限制,造成刷盘阻塞的报警,关联到的业务成功率也有下跌,当时业务监控告警没有提前发出,所以重保团队非常关注,最后我们通过这套能力及时发现了这类问题。
5、多维指标根因定位
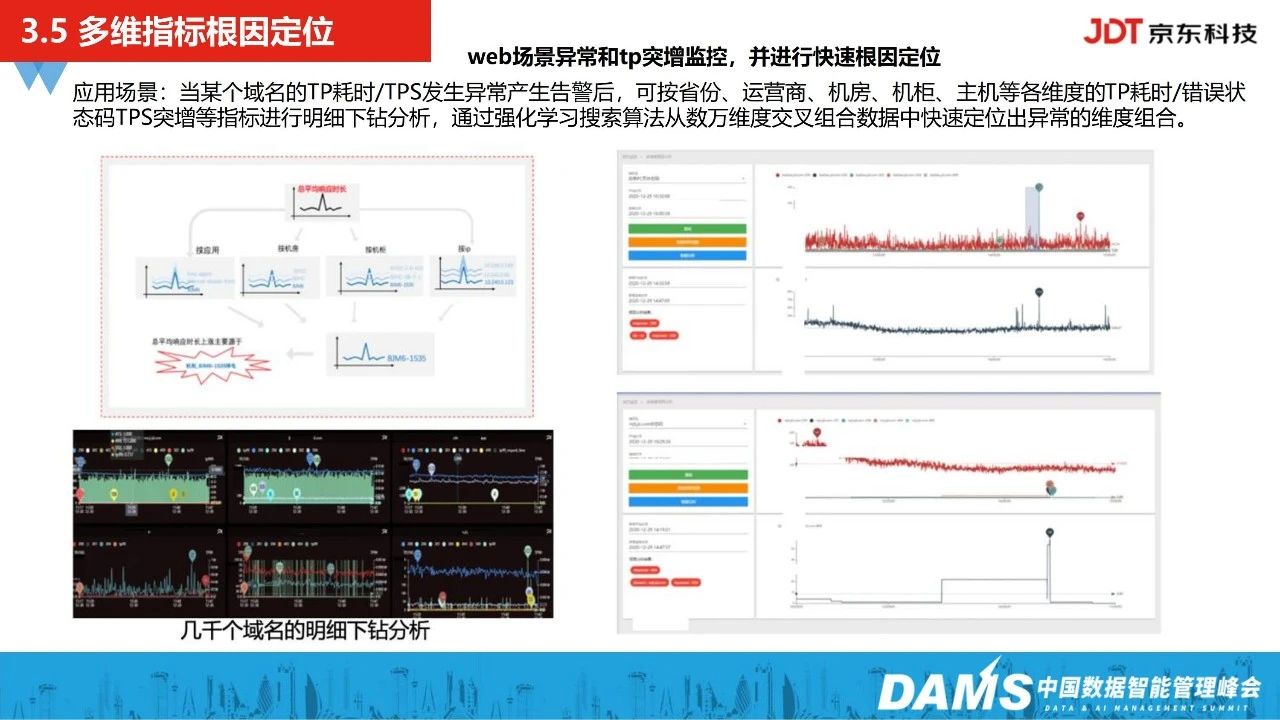
除此之外,我们做了多维指标明细的根因定位,主要是定位web场景的异常,当某个域名的TP耗时/TPS发生异常产生告警后,可按省份、运营商、机房、机柜、主机等各维度的TP耗时/错误状态码TPS突增等指标进行明细下钻分析,通过强化学习搜索算法从数万维度交叉组合数据中快速定位出异常的维度组合。
三、运维算法赋能降本增效落地经验
1、智能调度

我们会将master、node等监控数据统一输入到智能调度器,对应用资源使用情况及未来使用情况进行预测,将在线、离线应用进行合理的混合部署调度,以此提升资源利用率。
京东云在支持京东全线业务正常运行下,超大规模集群的CPU资源利用率提升3倍,单位订单资源成本下降30%,内存平均使用率提升57%,目前这套模型也有被IEEE论文所收录。
2、硬件故障预测
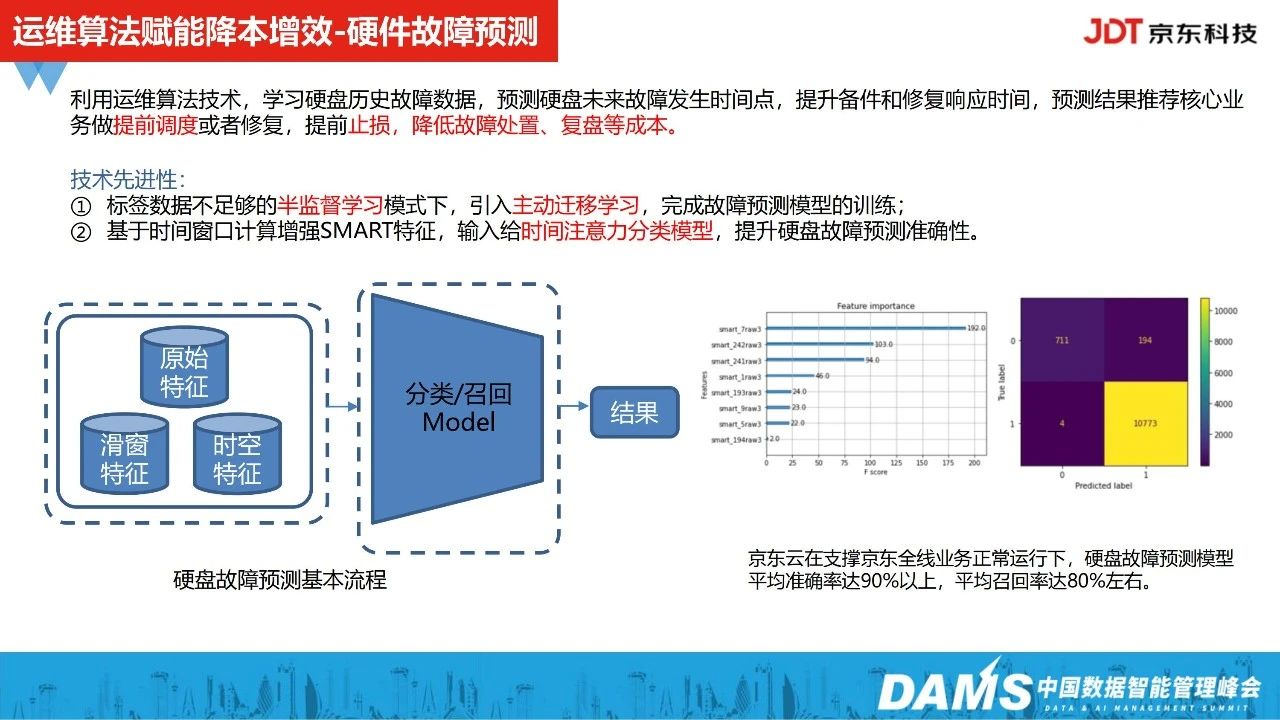
2022年开始,我们把运维算法落地到了硬件故障预测场景,和业界实践同样面临着标签不充分的问题。
因此,我们引入了半监督学习的方式,去扩充硬盘的故障数据;另我们基于时间窗口计算增强smart特征,输入给时间注意力分析模型,让模型得以充分训练,提升硬盘故障预测准确性。
在支撑京东全线业务正常运行下,硬盘故障预测模型平均准确率达90%以上,平均召回率达80%左右,在业界处在靠前的水平。
3、运维算法
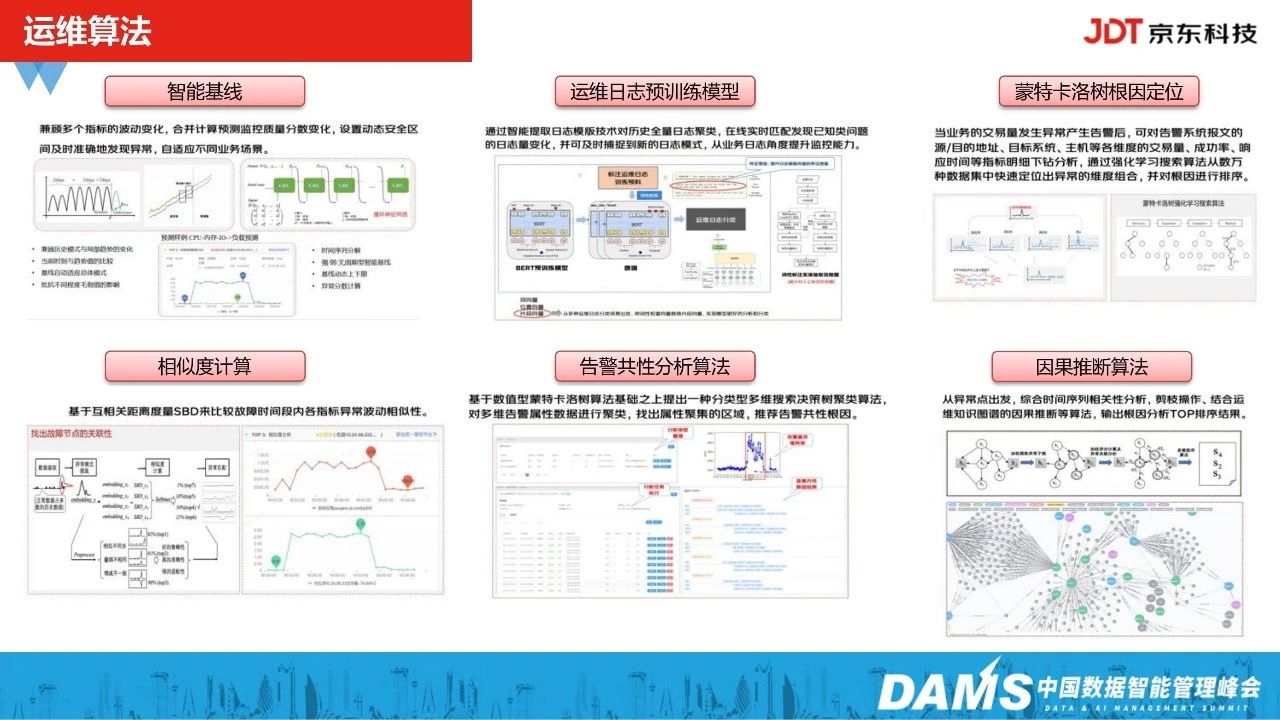
从2018年开始,我们开始沉淀智能运维算法能力,比如动态基线预测、运维日志预训练模型、蒙特卡洛树根因定位、相似度计算、告警共性分析算法、因果推断算法等。
以告警共性分析算法为例,在内部落地比较核心的就是pingmesh场景(网络场景)。在源和目的IP相互ping的时候,会有大量的延时以及丢包的指标监控,当延时和丢包大量突增时,中间经过的网络设备共性的路径是什么?这个时候,我们就是通过告警共性分析算法去分析解决的。
4、模型工厂
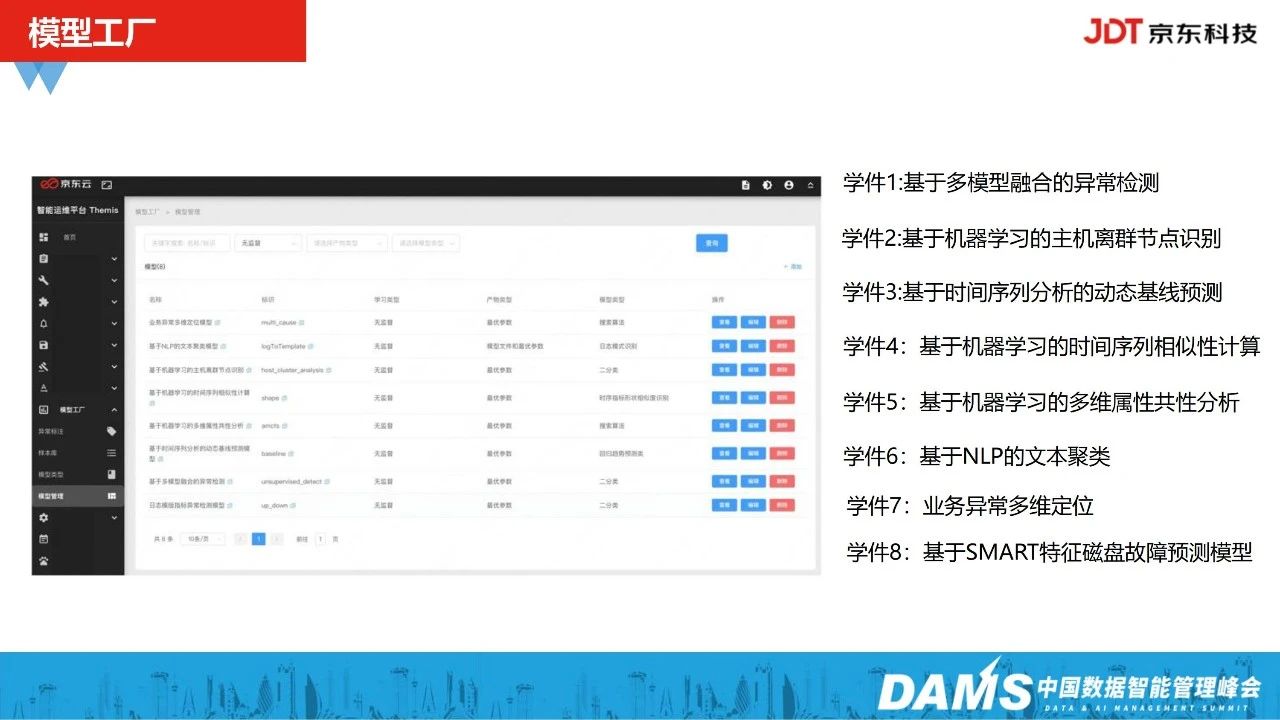
模型工厂主要用以整个智能运维算法学件的数据集快速增量学习,帮助运维算法迭代更新及再训练,这其中包含前面介绍的8大组件。
5、运维监控可视化大屏
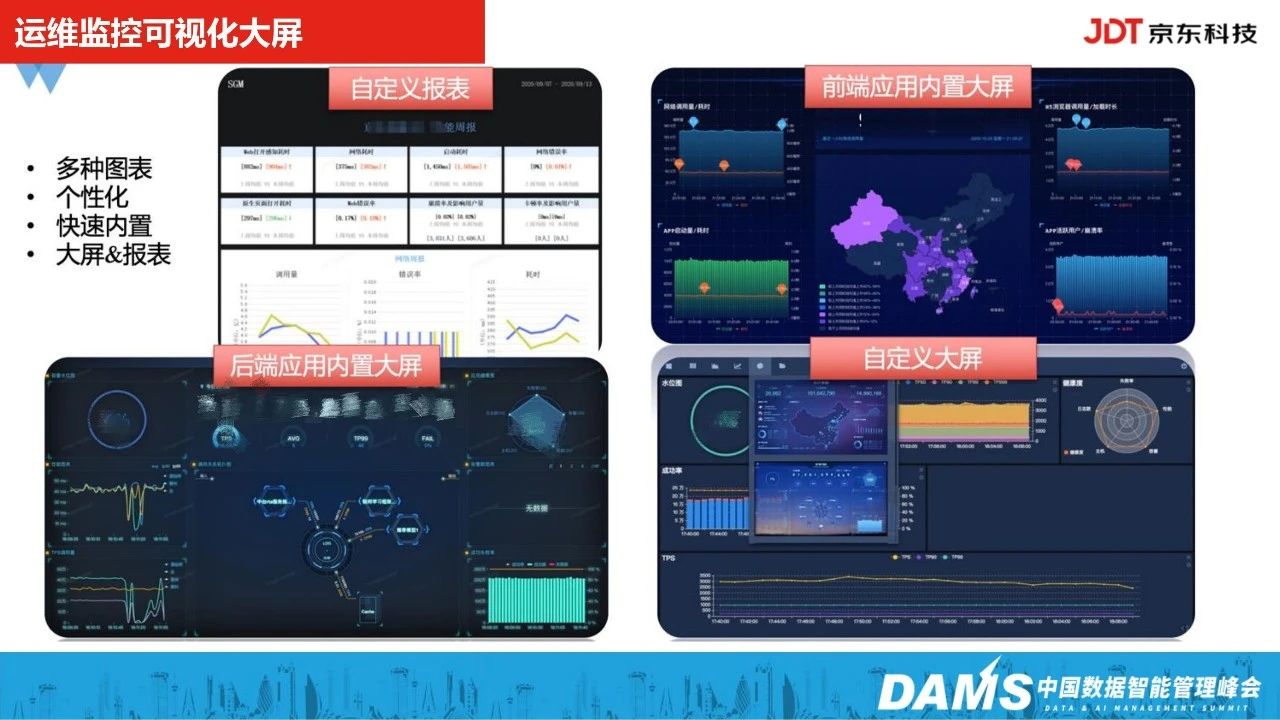
除了以上功能,我们整个智能运维平台也支持可视化。
做可观测性实践,一部分要做到快速定位,还要做到分布式的全链路追踪,快速发现并响应,还有一部分是可视化,实现全局数据概览。
Q&A
Q1:在实现全链路监控的时候,您的APM数据和NPM数据是如何匹配的?
A1:我们现在的话就是智能化的根因定位这块的话,主要是用到的是APM的监控数据。
Q2:您提到每次重大事件之前,会有一个专门的健康体检。那7×24小时实时监控系统的健康状态,和重大事件的健康体检差别是在哪里呢?
A2:日常的话,我们确实是7×24会有一些健康体检,但生成的体检报告是汇总式的;大促期间有一些定制化的巡检规则项,主要是针对我们核心的业务应用,参与本次大促的运维、研发同学会额外关心的这些规则项,结合我们异常检测的能力,做一个大大促前的业务应用的健康体检。
Q3:您提到的聚类分析是基于深度学习的算法,然后做的模型是吗?
A3:是的,主要用的是Bert预训练这一块。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721