
一、背景
在日常开发中,通常为了方便调试、方便查问题,会打印很多 INFO 级别的日志。
随着访问量越来越大,一不小心,某个日志文件一天的 size 就大于了某个阈值(如 5G),于是,收到了优化日志大小的告警,一定时间内不优化反馈给你主管,囧...
日志过大容易导致一些运维操作消耗机器性能,如日志文件检索、数据采集、磁盘清理等。
那么,日志瘦身哪些常见的思路呢?本文结合某个具体案例谈谈我的看法。
二、日志瘦身方法论
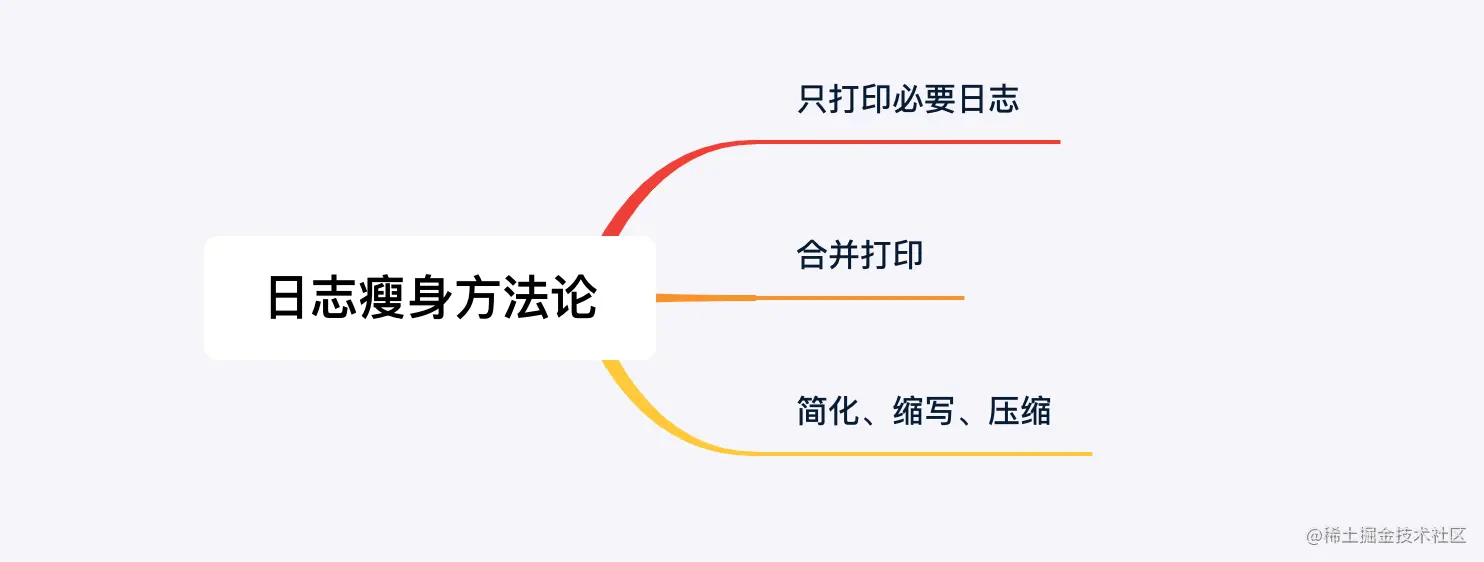
有时候为了方便测试,临时打印很多 INFO 级别日志。对于这种日志,等项目上线前,可以将非必要的日志删除或者调整为 DEBUG 级别。
但有些场景下有些日志可打印为 DEBUG 也可打印为 INFO,打印成 INFO 级别占空间,打印成 DEBUG 级别线上查问题的时候又需要用到,肿么办?

我们可以对日志工具类进行改造,支持上下文传递某个开关时(正常调用没有这个开关,通过公司的 Tracer 或者 RPC上下文传递),可以临时将 DEBUG日志提升为 INFO级别。伪代码如下:
if(log.isDebugEnable()){log.debug(xxx);}else if(TracerUtils.openDebug2Info()){log.info("【debug2info】"+xxx);}
这样,可以将一些纠结是否要打印成 INFO 日志的 log 打印成 DEBUG 级别,查问题时自动提升为INFO 日志。为了避免误会,区分 DEBUG 提升 INFO 的日志和普通 INFO 日志,加上 类似【debug2info】 日志前缀。

当然,你也可以搞一些其他骚操作,这里只是举个例子,请自行举一反三。
有些可以合并的日志,可以考虑合并。
如在同一个方法前后都打印了 INFO 日志:
INFO [64 位traceId] XXXService 执行前 size =10 INFO [64 位traceId] XXXService 执行后 size =4
可以合并成一条:
INFO [64 位traceId] XXXService 执行前 size =10 执行后 size =4
某个日志非常有必要,但是打印的对象有些大,如果可以满足问题排查需求的情况下,我们可以:
选择只打印其 ID。
创建一个只保留关键字段的日志专用对象,转化为日志专用对象,再打印。
可以用缩写,如 write 简化为 w, read 简化为 r, execute 简化为e 等;比如 pipeline 中有 20个核心 bean ,打印日志时可以使用不同的编号替代 bean 全称,如 S1,S2 ,虽然没那么直观,但既可以查问题,又降低了日志量。
三、优化案例
一个业务场景涉及很多 bean, 为了复用一些通用逻辑,这些 bean 都继承自某个抽象类。
在抽象类中,定义了执行 bean 前后的一些通用逻辑,如执行前后打印当前 pipeline 中 item 的数量。最后一个 bean 执行完结果转换后需要打印出结果。
1)只打印必要日志
由于当前 bean 执行前 相当于前一个 bean 执行后,因此只打印执行后的日志就可以,执行前的INFO 日志可以删除或者改为 DEBUG (只打印必要日志)
通常问题只出现在执行前后 size 不一致的情况下,因此执行后打印日志前可以加个判断,如果执行前后 size 相同则不打印。(只打印必要日志) 伪代码如下:
if(sizeBefore != sizeAfter){log.info("service:{}, 前size:{},后size:{}", getName(),sizeBefore, sizeAfter)}
这招效果很明显,因为大多数 bean 的执行前后 size 是相同的,就不会打印这条日志。而假设之前有 20 个,这条日志就需要打印 20次,改进后可能只需要打印 2-3 次。
2)日志合并
为了方便查问题还需要打印执行前的 size ,那么将执行前的 size 记录在内存中,打印执行后日志时多打印出执行前的 size。(合并打印) 伪代码如下:
log.info("service:{}, 执行前size:{}", getName(),sizeBefore)log.info("service:{}, 执行后size:{}", getName(),sizeBefore, sizeAfter)
合并后:
log.info("service:{}, 前size:{},后size:{}", getName(),sizeBefore, sizeAfter)
3)日志精简
对于最终结果,将结果对象(如 XXDTO)转化为只包括关键信息,如 id, title 的日志对象(XXSimpleLogDTO),转化为日志对象后再打印。
log.info("resultId:{}",result.getId());
或者
log.info("result:{}",toSimpleLog(result));
该日志一天产生 5 G 左右,这里百分之80% 左右都是打印执行前后的 size,10%左右是打印最终结果, 还有一些其他的日志。
经过上述方法优化后,每天日志量不足 1G。
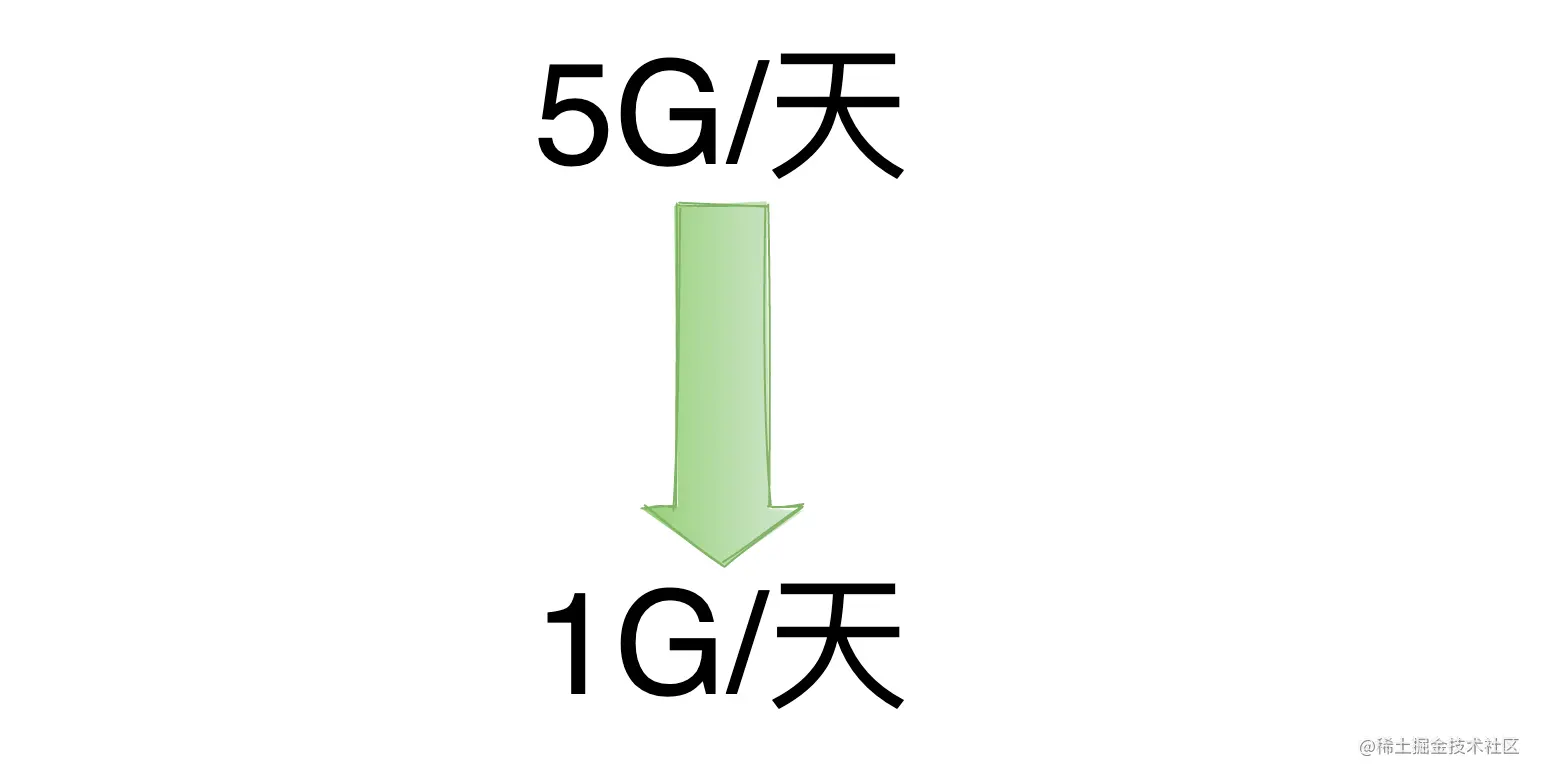
在满足排查问题的需要,又实现日志瘦身之间进行了取舍。
四、总结
日志瘦身需要进行权衡,保留排查问题的必要日志情况下尽可能精简。
可以采用删除不必要日志,合并日志,日志简化等方式进行优化。
我们还可以进行一些骚操作,支持线上 DEBUG 临时提升 INFO (当然也可以使用 arthas )来辅助我们查问题。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721