
一、前言
线上问题排查相比于coding,是一个低频的工作,很多人不会经常遇到。一旦需要进行问题排查的时候,往往是重要且紧急的,因此问题排查的效率,就显得尤为重要。有些线上问题,比较直观,比如磁盘使用率高、网络流量高这种,借助合适的工具很快能定位到原因;但对于一些复杂的问题,如系统Load高、RSS占用高、内存溢出等,需要结合多方面的数据才能定位到原因。这时候,需要有正确的解题思路,并辅以合适的工具,才能高效地解决问题。
目前业界排查问题的优秀工具还是挺多的,比如国内阿里开源的Arthas、PerfMa开源的为终结性能问题而生的xPocket,Java官方的JMC(JDK Mission Control)、Eclipse的MAT(Memory Analyzer Tooling),以及我一直很推崇的神器Async-Profiler。上述只是列举了一些比较流行的开源工具,商业工具如jProfiler、YourKit等也都建立了稳定的用户群体,这些工具功能各有差异。当然这不是本文描述的重点,就不详细展开了。
在对这些工具进行横向对比时我们发现,他们的目标都是为了解决一些特定的问题,如果我们有清晰的问题排查思路,结合这些工具,可以很快解决问题。
而对于一些复杂场景,尤其是一些陌生的复杂问题,在没有头绪的情况下,纵然有各种神兵利器,也无计可施。线上问题排查犹如开车,老司机驾轻就熟,新手则手忙脚乱。当然如果新手有老司机加以指点,也可能很快地解决问题。
但问题是,这种老司机并不常见,也不可能时刻都能帮你。我们可以去网上查阅其他人总结的问题排查套路,再结合我们自己的场景,去尝试解决问题,我也是经常这么干的。但这种方式效率依然不高,原因有三个:
1)信息检索的成本:我们需要花时间去翻阅资料,去跟自己的场景匹配以判断是否适合自己;
2)试错的成本:有些资料不适合我们的场景,我们按照资料去尝试,有可能被带沟里去,浪费时间;
3)问题排查需要借助于一些第三方工具,而这些工具在生产环境需要安装、配置和使用,也需要花较多的时间成本。
针对线上问题排查的特点和现状,我们是否可以构建一个系统,这个系统会针对各种线上问题的排查形成一个知识(套路)库,针对每一种问题,都有对应的套路和自动化工具帮助我们去定位问题。本文将结合一个比较有代表性的线上问题的排查过程,来探讨这种方式的可行性。
二、问题排查的套路化
本章将以RSS占用高为例来对问题排查的套路化进行说明。RSS占用高是很多人遇到过的问题,这个问题涉及的因素比较多,比较有代表性。当然在开启了Swap的运行环境中,Swap高也是RSS高的一种表象,殊途同归。
RSS是Resident Set Size(常驻内存大小)的缩写,用于表示进程使用了多少内存(RAM中的物理内存)。如果我们遇到进程RSS接近服务器的物理内存,那就意味着你需要关注应用的健康程度了,这意味着应用后面很有可能出现OOM的问题,比如进程被OOM killer杀死,或者容器重启,或者因使用Swap而速度变慢。
针对RSS高的问题,首先我们需要知道的是,Java进程消耗的内存绝不仅仅是你设置的Xmx或堆内存的用量这么简单,Java进程占用的内存主要分为2大部分:on-heap(堆内内存)和off-heap(堆外内存)。而堆外内存又包含JVM自身消耗的内存、JVM外的内存。所以,后续的排查思路我们也是按照堆内内存、JVM内存、JVM外内存3个方向来顺序展开。
1. 堆内存是否太大
首先要确认一下Java应用的堆内存是否太大,因为JVM自身也会消耗一些内存,所以你至少需要预留出部分内存存给JVM使用。如果应用涉及较多的网络通信,那还需要预留一些内存给堆外使用,所以一般来说你的堆内存最多为服务器物理内存的75%(经验值,需依据应用自身特点调整),如4G内存服务器,那么堆内存最大为3G。
堆内存用量的查看手段非常多,相信各个公司的基础架构团队都提供了可视化的监控手段,当然也可以通过原生命令jcmd <pid> GC.heap_info查看,如图1所示:

图1
如果Java进程的堆内存用量已接近或超过物理内存的75%,那么基本可以确定堆内存用量过大。这时可以调小Xmx来控制堆内存用量。如果Xmx不能减小,可以通过dump堆内存+MAT或JFR(Java Flight Recorder)+ JMC(JDK Mission Control)来分析内存占用/分配情况,通过程序调优来减少堆内存用量。
如果到此RSS占用呈稳定趋势,我们就可以告一段落了,否则要继续后面的步骤。
2. 是否存在大量ARENA区
如果堆内存不大,那么继续排查非堆内存。首先去看一下ARENA区,在高并发的应用中,往往ARENA区占用的内存会比较多。为什么先看ARENA区的内存占用呢?是因为这个步骤是不需要重启JVM进程就可以完成的。
接下来我们直接进入排查问题环节。执行如下命令:
sudo -u <user> pmap -x <pid>|sort -gr -k2 |less
如果存在大量大小为65536或60000左右的内存区域,则很大可能是ARENA区域占用了太多的内存,如图2所示:
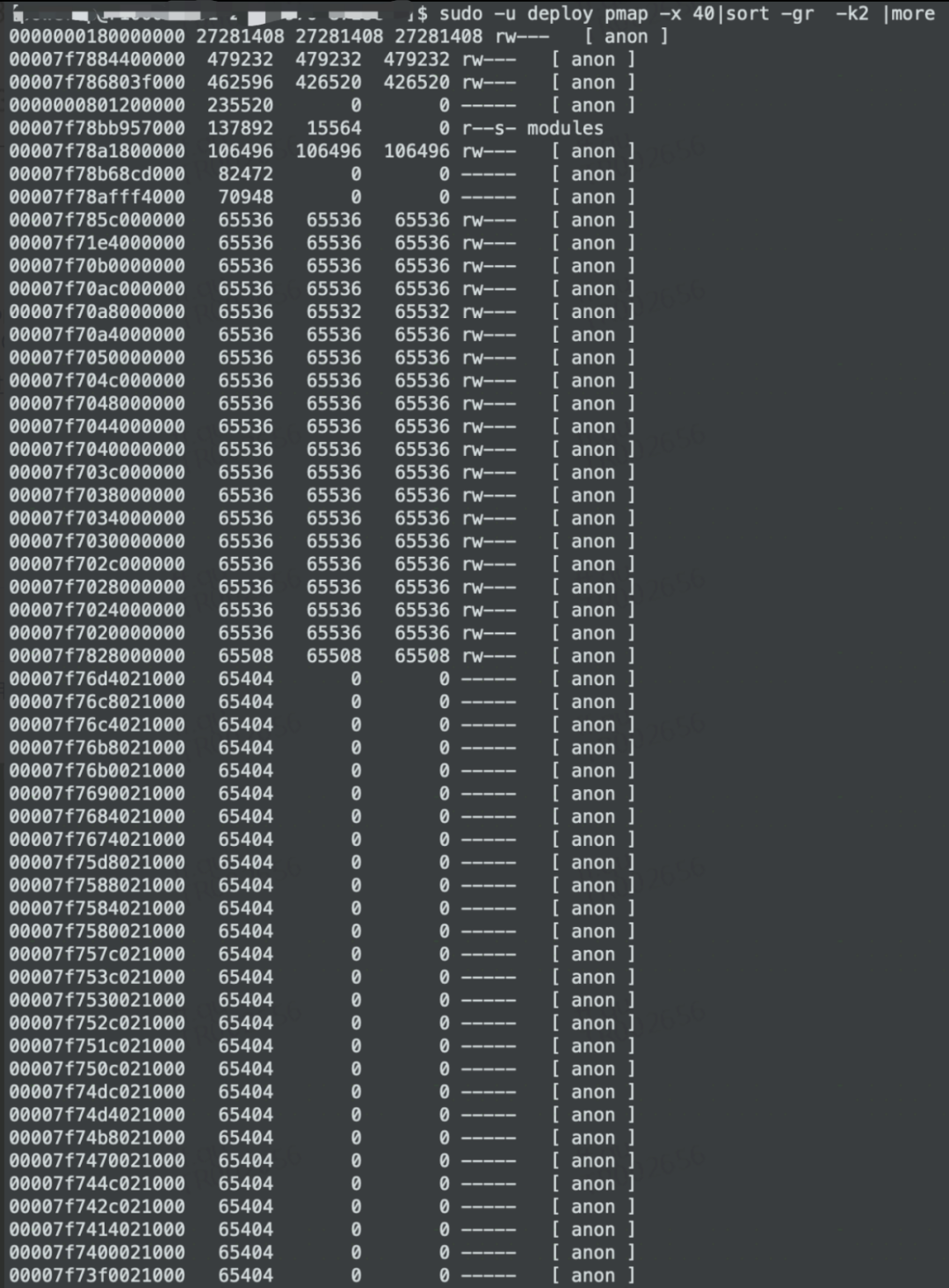
图2
这种情况下,最简单粗暴的办法是在JVM启动参数中增加配置:
export MALLOC_ARENA_MAX=1
需要注意的是,上述的数值只能是1,其他大于1的数值经实践证明是无法控制ARENA数量的。
3. 非堆内存是否开销过大
如果前面2个步骤过后都没有发现问题,还有很多内存你不知道消耗在哪里了,那么我们开始第3步:开启Native Memory Tracking。前面说过,Java应用的执行,JVM自身也需要消耗一些内存的,通过开启Native Memory Tracking,我们就能知道JVM自身消耗了多少内存。
书归正传,通过修改JVM参数并重启Java进程开启NativeMemory Tracking:
-XX:NativeMemoryTracking=detail
进程重启后,可以通过NMT的一些子命令(summary/detail/baseline/diff)查看Native Memory的占用情况:
sudo -u <user>jcmd <pid> VM.native_memory detail
图3是在使用baseline建立了基线的情况下用detail.diff看到的各内存区的变化情况:
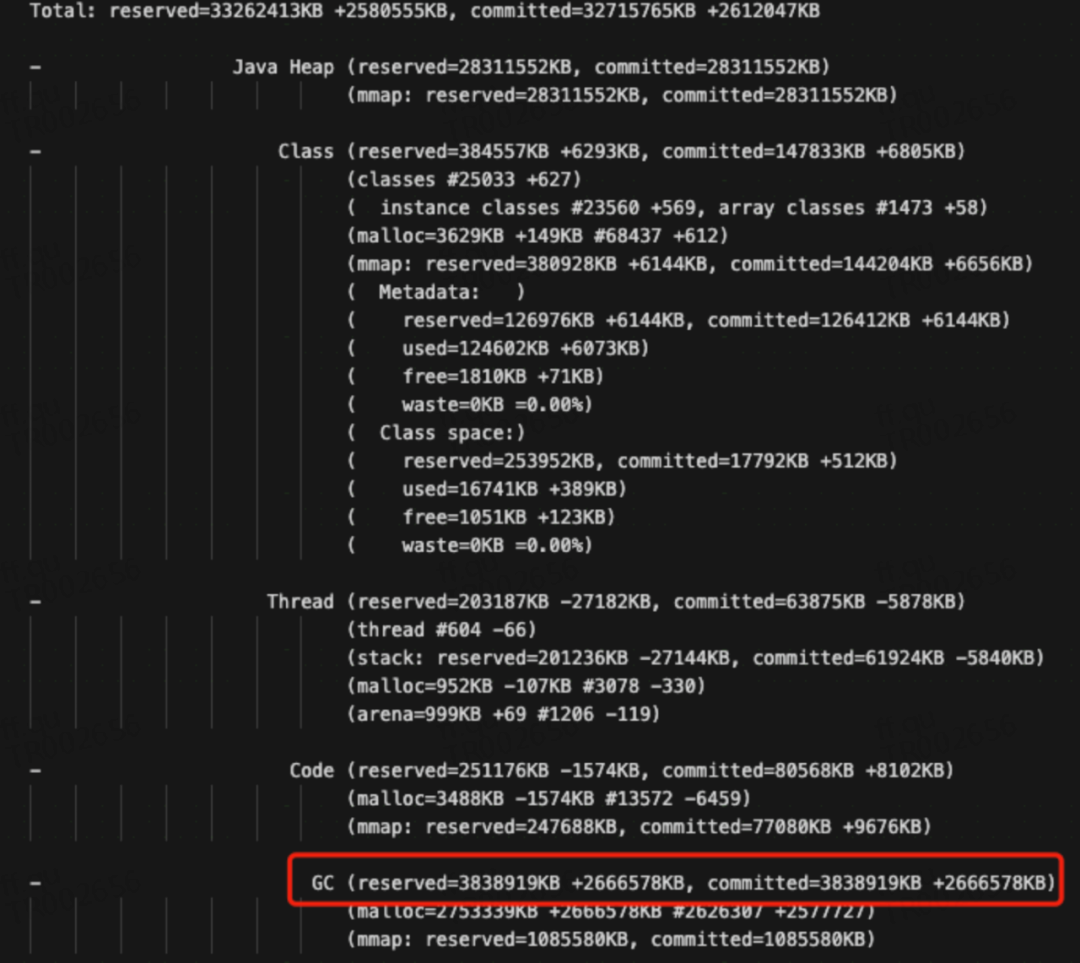
图3
通过上图,可以看到JVM各个区域所使用的内存大小,主要包含了Java Heap、Class、Thread、Code、GC、Compiler、Internal、Other、Symbol等,各部分作用如下:
1)Class:加载的类与方法信息,其实就是 metaspace,包含两部分:一是 metadata,被-XX:MaxMetaspaceSize限制最大大小,另外是 class space,被-XX:CompressedClassSpaceSize限制最大大小;
2)Thread:线程与线程栈占用内存,每个线程栈占用大小受-Xss限制,但是总大小没有限制。在x64的JVM中,Xss默认为1024K,所以如果你的应用开启了1000个线程,那么这个Thread区占用将是1024M,所以一般我们会把Xss设置为256K即满足要求;
3)Code:JIT 即时编译后(C1C2 编译器优化)的代码占用内存,受-XX:ReservedCodeCacheSize限制;
4)GC:垃圾回收占用内存,例如垃圾回收需要的 CardTable,标记数,区域划分记录,还有标记 GC Root 等等,都需要内存。这个不受限制,一般不会很大,但也有例外,图3是27G的堆内存,使用G1垃圾回收器,你能看到GC区居然占用了3.8G的内存;
5)Compiler:C1 C2 编译器本身的代码和标记占用的内存,这个不受限制,一般不会很大;
6)Internal:命令行解析,JVMTI 使用的内存,这个不受限制,一般不会很大;
7)Symbol: 常量池占用的大小,字符串常量池受-XX:StringTableSize个数限制,总内存大小不受限制;
我们需要需要注意的是Class、Thread、GC几个区域的大小。图4是各种JVM垃圾回收器消耗内存的比例,注意这部分内存是堆内存之外的:
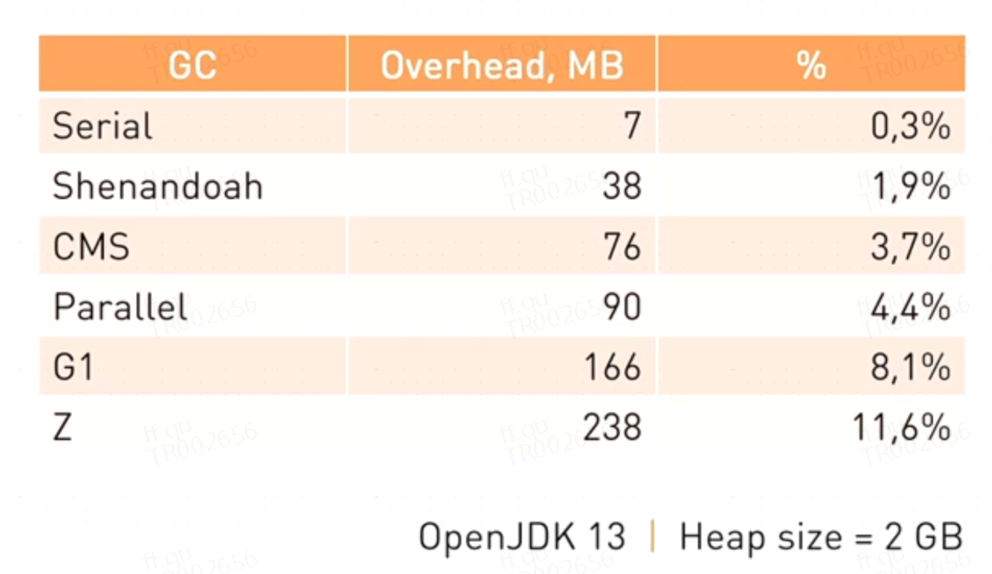
图4
实践证明,G1的内存开销甚至能占到堆内存的20%,当然这不是本文要讨论的内容,感兴趣的读者可以去阅读《JVM G1源码分析和调优》一书查看相关内容。
针对上面的各个区域大小做加法,看一下是否接近于RSS的大小,如果是,恭喜你可以到此结束了。后续你需要做的就是针对内存占用比较大的JVM区去做优化,这里就不详细介绍了。
如果不是,很遗憾,你进入到了最难啃的环节,继续往下看吧。
注:开启NativeMemoryTracking会造成5%的性能下降,用完记得修改JVM参数并重启永久关闭,或者可以通过以下命令临时关闭:jcmd vm.native_memory stop <pid>。
4. 堆外内存是否用量太多
堆外内存也是比较容易被忽略的一个区域,尤其是网络通信非常频繁的应用,这种应用往往大量使用Java NIO,而NIO为了提高效率,往往会申请很多的堆外内存。确认这个区域用量是否过大,最直接的方法是先查看是否是DirectByteBuffer或者MappedByteBuffer使用了较多的堆外内存。
如果你的服务器已经开启了远程JMX,你可以通过ops提供的jmx查询工具去查询,也可以通过jdk自带的工具(比如jconsole、jvisualvm)查询,如图5所示:
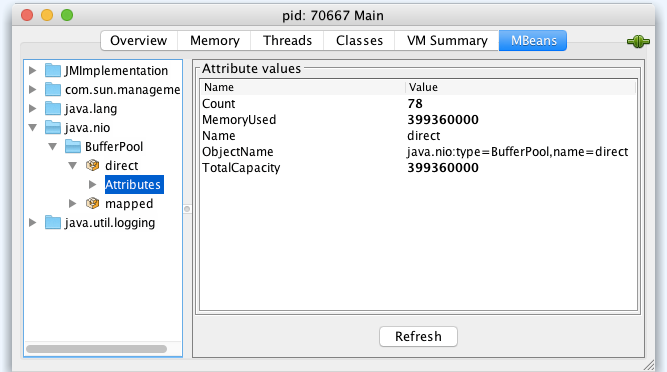
图5
如果未开启远程JMX,可以通过jmxterm(https://docs.cyclopsgroup.org/jmxterm)工具在本地模式下查询以下两项内容确认用量:
java.nio:name=direct,type=BufferPool
java.nio:name=mapped,type=BufferPool
如果确认上述堆外内存使用过多,那么可以通过在jvm参数中设置-XX:MaxDirectMemorySize这个参数控制一下,因为通过DirectByteBuffer分配的堆外内存,默认是不会控制这个区域的内存用量的。
如果上述内存用量不大,那我们就需要祭出终极杀器jemalloc来做进一步分析了。这里涉及的内容比较多,受限于文章篇幅限制,就不展开描述了。
通过jemalloc的收集到的数据,我们基本能够定位到堆外内存问题的原因。
5. 总结
上述的4个步骤,基本能够解决大多数的RSS占用高的问题了。当然事无绝对,没有一种药是包治百病的。我们追求的基本目标是,通过问题排查的套路化,帮助工程师理清思路,少走弯路,以提高问题排查的效率。
三、问题排查的工具化
1. 流程梳理
先来梳理工具的执行流程以及每个步骤需要做的事情,与第二节保持一致性,本节也划分成4个子步骤。
1)确认堆内存是否太大
第一步要做的事情比较多,梳理如下:
Java进程pid:使用jps -v列出java进程列表,由用户选择具体的进程;
获取运行环境的物理内存和剩余内存(free -m)
Java进程的堆内存用量(jcmd GC.heap_info)
Java进程GC情况(jstat-gcutil);
获取到上述信息后,判断堆内存是否太大。
2)是否存在大量ARENA区
通过pmap命令获取内存分配列表,辅以awk命令提取内存信息,据此判断是否存在大量ARENA区。
3)非堆内存是否开销过大
此步骤需要在JVM启动脚本中增加启动参数并重新启动进程,对于标准化的运行环境来说,在知道了启动脚本位置和启动命令的情况下,是可以通过工具来完成参数的修改和进程启动。如果不能知道启动脚本所在位置,我们可以复制当前进程的JVM参数来完成进程的启动。
当JVM进程启动完成,再次进入工具,我们就能借助于Native Memory Tracking的结果来判断当前环节是否存在问题。
4)堆外内存是否用量太多
此步骤的自动执行,需要安装第三方工具如jxmterm、jemalloc。在生产环境访问外网受限的情况下,可以通过搭建内网资源服务器的方式来解决这个问题。通过一键安装脚本,我们能快速完成所依赖工具的安装和配置,剩下的就是让工具来收集和分析数据定位问题了。
2. 工具实现
目前公司内部很多运维工具,都是采用C+B/S的方式实现,这种方式工程师不需要申请目标服务器权限就能够实现很多运维操作。但这种实现方式比较复杂,而我们的工具是带有实验性质,所以暂时使用shell+工具包的方式实现,即使用shell脚本将主流程串起来,各节点使用的工具如果有缺失,yum能安装使用yum安装,yum不能安装的则提前下载内置到工具包中。
所有的准备工作完成后,编写脚本的工作就相对简单了,当然这需要用到很多的shell和linux、java命令,此处就不赘述了。脚本的最终运行效果如下:

四、总结
通过针对RSS占用高问题的排查套路和排查工具的梳理,我们实现了一个简单的问题快速排查脚本。当然在这个过程中可以发现,很多问题的排查,都可以使用类似的思路来工具化,日积月累,就形成了一个问题排查的工具包。
以内存问题排查举例,我们积累了以下的快速工具,如图:
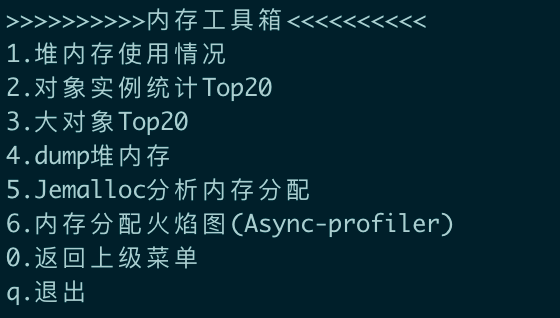
这只是工具包的一部分,针对CPU、磁盘、网络、GC等问题,借助于Arthas、Async-Profiler等优秀的开源工具,我们都积累了很多快速工具,期望能帮工程师提高问题排查的效率。
如前面所讲,这种完全基于shell的方式,由于需要登录到目标服务器上操作,多数功能还需要有sudo权限,这有些许的不方便。另外,某些公司生产环境严格受限,那shell的方式就无法使用了。所以在此基础上,可以扩展成Client+Server+Browser的模式,让工程师在不登录到服务器的情况下,就能完成问题的排查。
到此,本文的内容就结束了,但我们的工具还在不断地积累中,在此也欢迎感兴趣的同学帮我们提供场景,我们不断丰富这个工具库。同时,受限于作者水平,文中内容难免有不当之处,也欢迎提出意见和建议。
作者丨丰富
来源丨公众号:携程技术(ID:ctriptech)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721