
二马读书,曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监,15年电商互联网经历。
很多人在面试时,会被问到这样的问题:遇到过什么系统故障?怎么解决的?下面是笔者根据自己15年互联网研发经历总结的多个线上故障真实案例。
本文图不多,但内容很干!理解为主,学以致用!
故障一:JVM频繁FULL GC快速排查
在分享此案例前,先聊聊哪些场景会导致频繁Full GC:
内存泄漏(代码有问题,对象引用没及时释放,导致对象不能及时回收)。
死循环。
大对象。
尤其是大对象,80%以上的情况就是他。
那么大对象从哪里来的呢?
数据库(包括MySQL和MongoDB等NoSQL数据库),结果集太大。
第三方接口传输的大对象。
消息队列,消息太大。
根据多年一线互联网经验,绝大部分情况是数据库大结果集导致。
好,现在我们开始介绍这次线上故障:
在没有任何发布的情况下,POP服务(接入第三方商家的服务)突然开始疯狂Full GC,观察堆内存监控没内存泄漏,回滚到前一版本,问题仍然存在,尴尬了!!!
按照常规做法,一般先用jmap导出堆内存快照(jmap -dump:format=b,file=文件名 [pid]),然后用mat等工具分析出什么对象占用了大量空间,再查看相关引用找到问题代码。这种方式定位问题周期会比较长,如果是关键服务,长时间不能定位解决问题,影响太大。
下面来看看我们的做法:
先按照常规做法分析堆内存快照,与此同时另外的同学去查看数据库服务器网络IO监控,如果数据库服务器网络IO有明显上升,并且时间点吻合,基本可以确定是数据库大结果集导致了Full GC,赶紧找DBA快速定位大SQL(对DBA来说很简单,分分钟搞定,如果DBA不知道怎么定位,那他要被开除了,哈哈),定位到SQL后再定位代码就非常简单了。
按照这种办法,我们很快定位了问题。原来是一个接口必传的参数没传进来,也没加校验,导致SQL语句where后面少了两个条件,一次查几万条记录出来,真坑啊!这种方法是不是要快很多,哈哈,5分钟搞定。
当时的DAO层是基于Mybatis实现的,出问题的SQL语句如下:
<select id="selectOrders" resultType="com.***.Order" >
select * from user where 1=1
<if test=" orderID != null ">
and order_id = #{orderID}
</if >
<if test="userID !=null">
and user_id=#{userID}
</if >
<if test="startTime !=null">
and create_time >= #{createTime}
</if >
<if test="endTime !=null">
and create_time <= #{userID}
</if >
</select>
上面SQL语句意思是根据orderID查一个订单,或者根据userID查一个用户所有的订单,两个参数至少要传一个。但是两个参数都没传,只传了startTime和endTime。所以一次Select就查出了几万条记录。
所以我们在使用Mybatis的时候一定要慎用if test,一不小心就会带来灾难。后来我们将上面的SQL拆成了两个:
根据订单ID查询订单:
<select id="selectOrderByID" resultType="com.***.Order" >
select * from user where
order_id = #{orderID}
</select>
根据userID查询订单:
<select id="selectOrdersByUserID" resultType="com.***.Order" >
select * from user where
user_id=#{userID}
<if test="startTime !=null">
and create_time >= #{createTime}
</if >
<if test="endTime !=null">
and create_time <= #{userID}
</if >
</select>
故障二:内存泄漏
介绍案例前,先了解一下内存泄漏和内存溢出的区别。
内存溢出:程序没有足够的内存使用时,就会发生内存溢出。内存溢出后程序基本上就无法正常运行了。
内存泄漏:当程序不能及时释放内存,导致占用内存逐渐增加,就是内存泄漏。内存泄漏一般不会导致程序无法运行。不过持续的内存泄漏,累积到内存上限时,就会发生内存溢出。在Java中,如果发生内存泄漏,会导致GC回收不彻底,每次GC后,堆内存使用率逐渐增高。
下图是JVM发生内存泄漏的监控图,我们可以看到每次GC后堆内存使用率都比以前提高了:
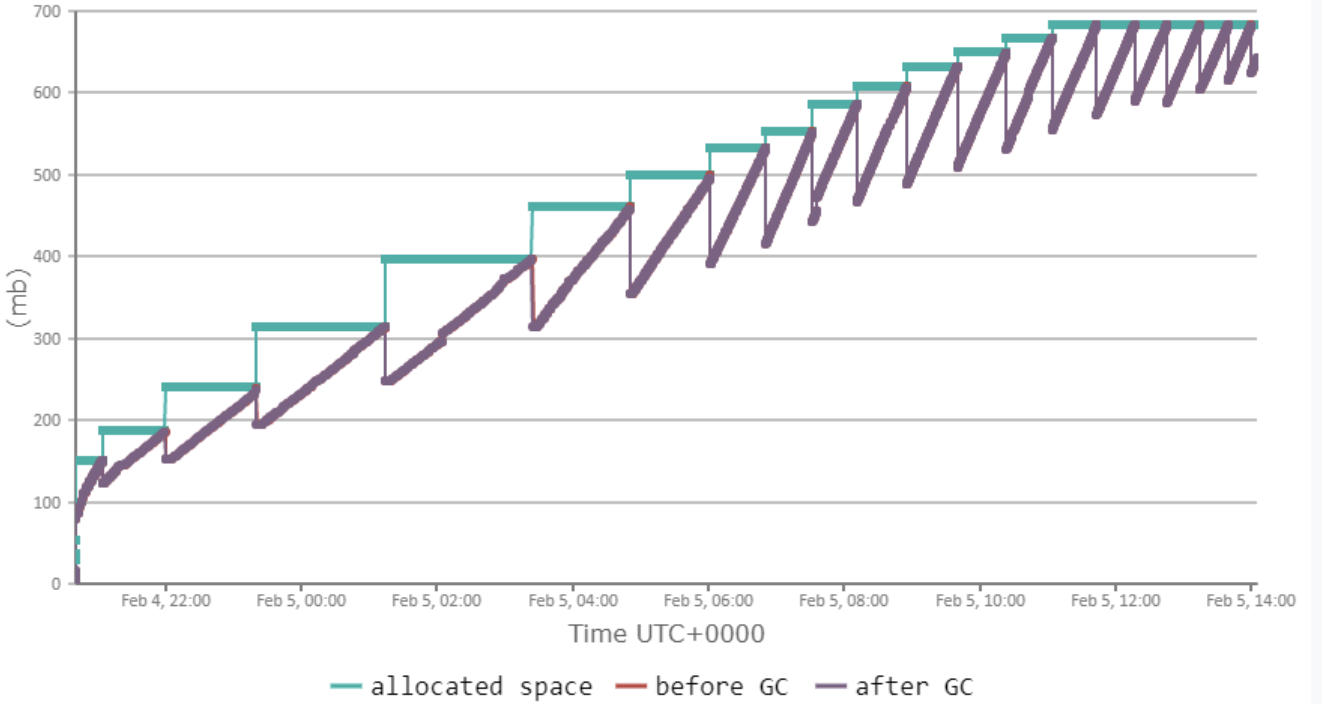
图片来源于网络
当时内存泄漏的场景是,用本地缓存(公司基础架构组自己研发的框架)存放了商品数据,商品数量不算太多,几十万的样子。如果只存热点商品,内存占用不会太大,但是如果存放全量商品,内存就不够了。
初期我们给每个缓存记录都加了7天的过期时间,这样就可以保证缓存中绝大部分都是热点商品。不过后来本地缓存框架经过一次重构,过期时间被去掉了。没有了过期时间,日积月累本地缓存越来越大,很多冷数据也被加载到了缓存。
直到有一天接到告警短信,提示堆内存过高。赶紧通过jmap(jmap -dump:format=b,file=文件名 [pid] )下载了堆内存快照,然后用eclipse的mat工具分析快照,发现了本地缓存中有大量的商品记录。定位问题后赶紧让架构组加上了过期时间,然后逐个节点重启了服务。
亏了我们加了服务器内存和JVM堆内存监控,及时发现了内存泄漏的问题。否则随着泄漏问题日积月累,如果哪天真的OOM就惨了。
所以技术团队除了做好CPU,内存等运维监控,JVM监控也非常重要。
故障三:幂等问题
很多年前,笔者在一家大型电商公司做Java程序员,当时开发了积分服务。当时的业务逻辑是,用户订单完结后,订单系统发送消息到消息队列,积分服务接到消息后给用户积分,在用户现有的积分上加上新产生的积分。
由于网络等原因会有消息重复发送的情况,这样也就导致了消息的重复消费。当时笔者还是个初入职场的小菜鸟,并没有考虑到这种情况。所以上线后偶尔会出现重复积分的情况,也就是一个订单完结后会给用户加两次或多次积分。
后来我们加了一个积分记录表,每次消费消息给用户增加积分前,先根据订单号查一遍积分记录表,如果没有积分记录才给用户增加积分。这也就是所谓的“幂等性”,即多次重复操作不影响最终的结果。
实际开发中很多需要重试或重复消费的场景都要实现幂等,以保证结果的正确性。例如,为了避免重复支付,支付接口也要实现幂等。
故障四:缓存雪崩
我们经常会遇到需要初始化缓存的情况。比如,我们曾经经历过用户系统重构,用户系统表结构发生了变化,缓存信息也要变。重构完成后上线前,需要初始化缓存,将用户信息批量存入Reids。
每条用户信息缓存记录过期时间是1天,记录过期后再从数据库查询最新的数据并拉取到Redis中。灰度上线时一切正常,所以很快就全量发布了。整个上线过程非常顺利,码农们也很开心。
不过,第二天,灾难发生了!到某一个时间点,各种报警纷至沓来。用户系统响应突然变得非常慢,甚至一度没有任何响应。查看监控,用户服务CPU突然飙高(IO wait很高),MySQL访问量激增,MySQL服务器压力也随之暴增,Reids缓存命中率也跌到了极点。
依赖于我们强大的监控系统(运维监控,数据库监控,APM全链路性能监控),很快定位了问题。原因就是Reids中大量用户记录集中失效,获取用户信息的请求在Redis中查不到用户记录,导致大量的请求穿透到数据库,瞬间给数据库带来巨大压力。同时用户服务和相关联的其他服务也都受到了影响。
这种缓存集中失效,导致大量请求同时穿透到数据库的情况,就是所谓的“缓存雪崩”。如果没到缓存失效时间点,性能测试也测不出问题。所以一定要引起大家注意。
所以,需要初始化缓存数据时,一定要保证每个缓存记录过期时间的离散性。例如,我们给这些用户信息设置过期时间,可以采用一个较大的固定值加上一个较小的随机值。比如过期时间可以是:24小时 + 0到3600秒的随机值。
故障五:磁盘IO导致线程阻塞
问题发生在2017年下半年,有一段时间地理网格服务时不常的会响应变慢,每次持续几秒钟到几十秒钟就自动恢复。
如果响应变慢是持续的还好办,直接用jstack抓线程堆栈,基本可以很快定位问题。关键持续时间只有最多几十秒钟,而且是偶发的,一天只发生一两次,有时几天才发生一次,发生时间点也不确定,人盯着然后用jstack手工抓线程堆栈显然不现实。
好吧,既然手工的办法不现实,咱们就来自动的,写一个shell脚本自动定时执行jstack,5秒执行一次jstack,每次执行结果放到不同日志文件中,只保存20000个日志文件。
Shell脚本如下:
#!/bin/bash
num=0
log="/tmp/jstack_thread_log/thread_info"
cd /tmp
if [ ! -d "jstack_thread_log" ]; then
mkdir jstack_thread_log
fi
while ((num <= 10000));
do
ID=`ps -ef | grep java | grep gaea | grep -v "grep" | awk '{print $2}'`
if [ -n "$ID" ]; then
jstack $ID >> ${log}
fi
num=$(( $num + 1 ))
mod=$(( $num%100 ))
if [ $mod -eq 0 ]; then
back=$log$num
mv $log $back
fi
sleep 5
done
下一次响应变慢的时候,我们找到对应时间点的jstack日志文件,发现里面有很多线程阻塞在logback输出日志的过程,后来我们精简了log,并且把log输出改成异步,问题解决了,这个脚本果真好用!建议大家保留,以后遇到类似问题时,可以拿来用!
故障六:数据库死锁问题
在分析案例之前,我们先了解一下MySQL InnoDB。在MySQL InnoDB引擎中主键是采用聚簇索引的形式,即在B树的叶子节点中既存储了索引值也存储了数据记录,即数据记录和主键索引是存在一起的。
而普通索引的叶子节点存储的只是主键索引的值,一次查询找到普通索引的叶子节点后,还要根据叶子节点中的主键索引去找到聚簇索引叶子节点并拿到其中的具体数据记录,这个过程也叫“回表”。
故障发生的场景是关于我们商城的订单系统。有一个定时任务,每一小时跑一次,每次把所有一小时前未支付订单取消掉。而客服后台也可以批量取消订单。
订单表t_order结构大至如下:
|
id |
订单id,主键 |
|
status |
订单状态 |
|
created_time |
订单创建时间 |
id是表的主键,created_time字段上是普通索引。
聚簇索引(主键id)。
|
id(索引) |
status |
created_time |
|
1 |
UNPAID |
2020-01-01 07:30:00 |
|
2 |
UNPAID |
2020-01-01 08:33:00 |
|
3 |
UNPAID |
2020-01-01 09:30:00 |
|
4 |
UNPAID |
2020-01-01 09:39:00 |
|
5 |
UNPAID |
2020-01-01 09:50:00 |
普通索引(created_time字段)。
|
created_time(索引) |
id(主键) |
|
2020-01-01 09:50:00 |
5 |
|
2020-01-01 09:39:00 |
4 |
|
2020-01-01 09:30:00 |
3 |
|
2020-01-01 08:33:00 |
2 |
|
2020-01-01 07:30:00 |
1 |
定时任务每一小时跑一次,每次把所有一小时前两小时内的未支付订单取消掉,比如上午11点会取消8点到10点的未支付订单。SQL语句如下:
update t_order set status = 'CANCELLED' where created_time > '2020-01-01 08:00:00' and created_time < '2020-01-01 10:00:00' and status = 'UNPAID'
客服批量取消订单SQL如下:
update t_order set status = 'CANCELLED' where id in (2, 3, 5) and status = 'UNPAID'
上面的两条语句同时执行就可能发生死锁。我们来分析一下原因。
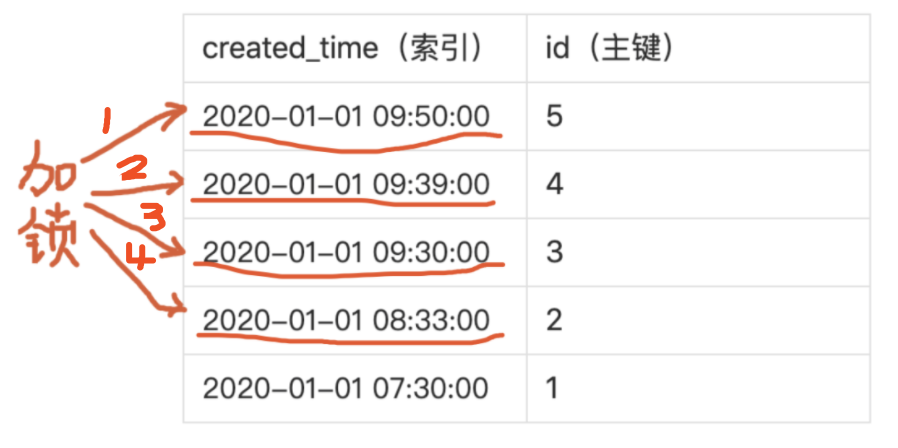
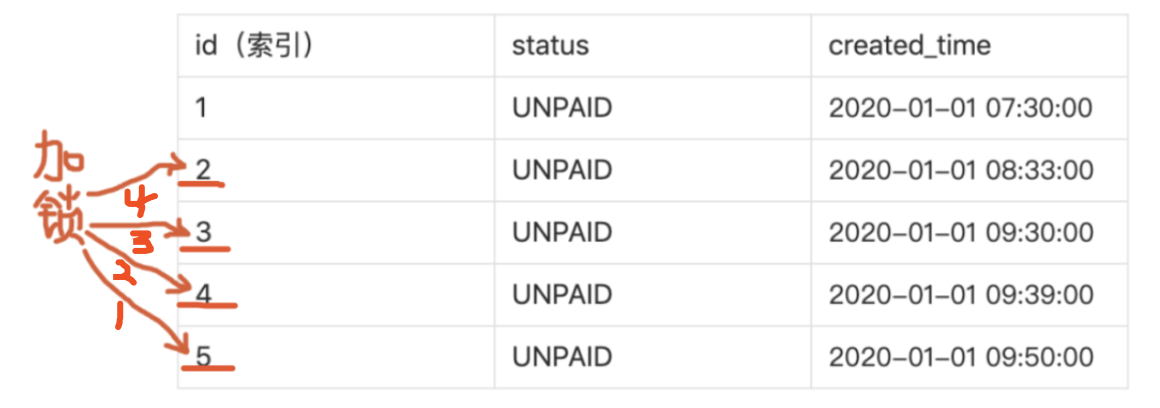
第一条定时任务的SQL,会先找到created_time普通索引并加锁,然后再在找到主键索引并加锁。
第一步,created_time普通索引加锁。
第二步,主键索引加锁。
第二条客服批量取消订单SQL,直接走主键索引,直接在主键索引上加锁。
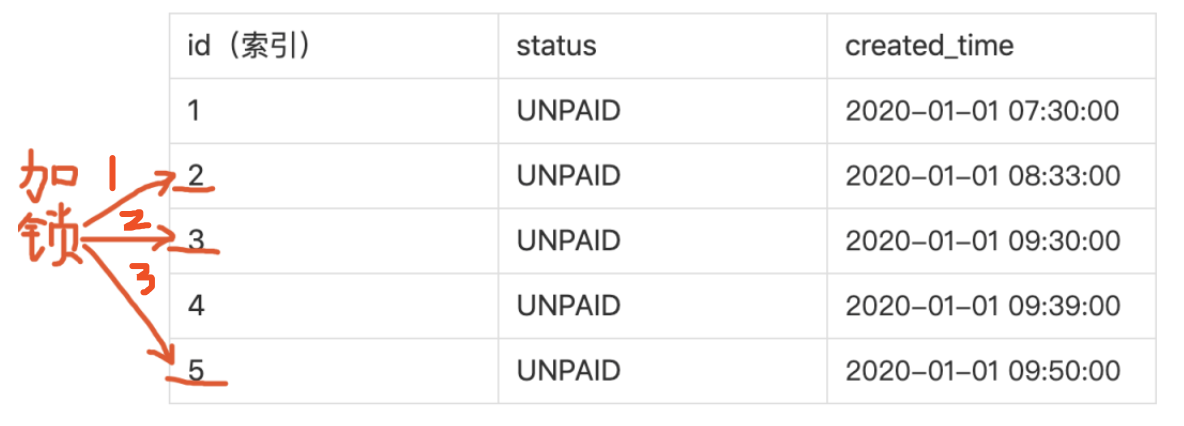
我们可以看到,定时任务SQL对主键加锁顺序是5,4,3,2。客服批量取消订单SQL对主键加锁顺序是2,3,5。当第一个SQL对3加锁后,正准备对2加锁时,发现2已经被第二个SQL加锁了,所以第一个SQL要等待2的锁释放。
而此时第二个SQL准备对3加锁,却发现3已经被第一个SQL加锁了,就要等待3的锁释放。两个SQL互相等待对方的锁,也就发生了“死锁”。
解决办法就是从SQL语句上保证加锁顺序一致。或者把客服批量取消订单SQL改成每次SQL操作只能取消一个订单,然后在程序里多次循环执行SQL,如果批量操作的订单数量不多,这种笨办法也是可行的。
故障七:域名劫持
先看看DNS解析是怎么回事,当我们访问www.baidu.com时,首先会根据www.baidu.com到DNS域名解析服务器去查询百度服务器对应的IP地址,然后再通过http协议访问该IP地址对应的网站。
而DNS劫持是互联网攻击的一种方式,通过攻击域名解析服务器(DNS)或者伪造域名解析服务器,把目标网站域名解析到其他的IP。从而导致请求无法访问目标网站或者跳转到其他网站。如下图:
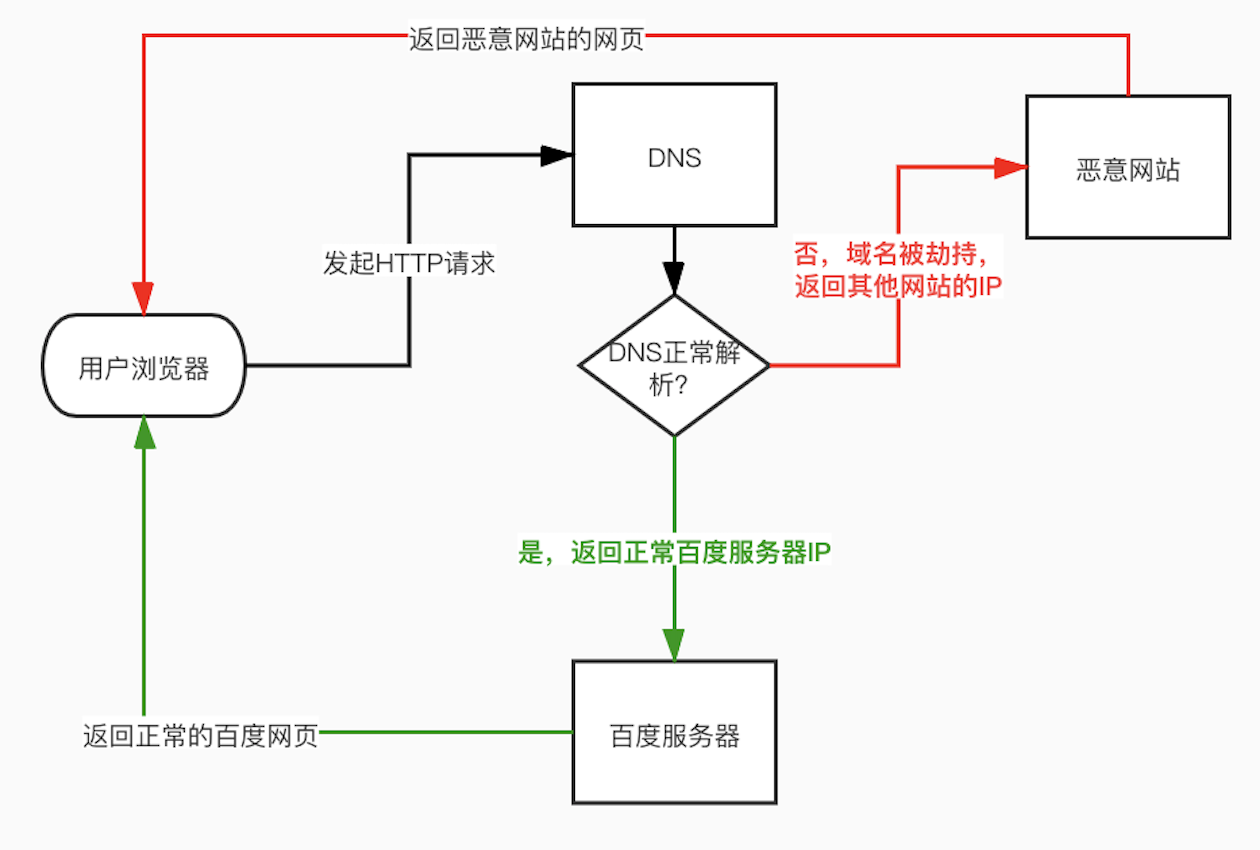
下面这张图是我们曾经经历过的DNS劫持的案例:
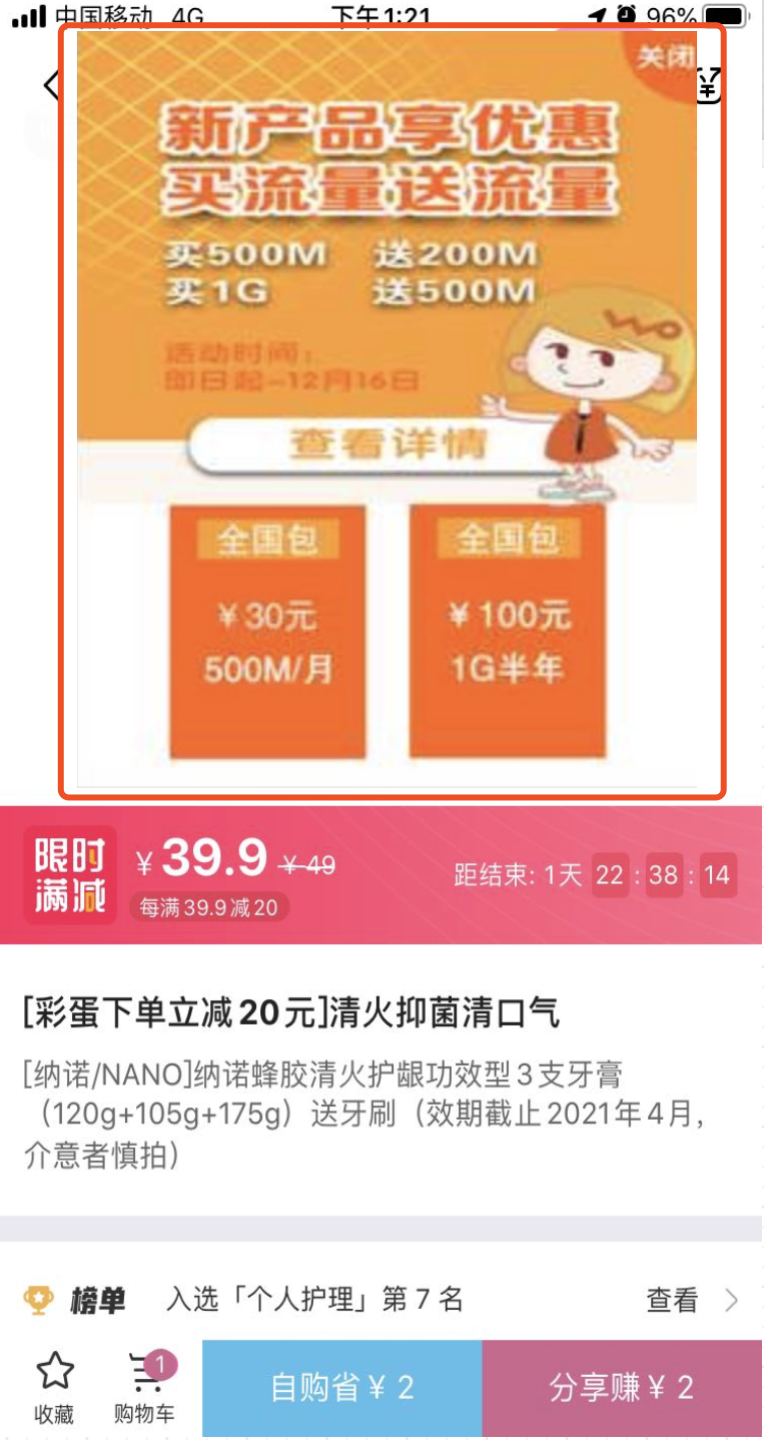
看图中的红框部分,本来上方的图片应该是商品图片,但是却显示成了广告图片。是不是图片配错了?不是,是域名(DNS)被劫持了。
原本应该显示存储在CDN上的商品图片,但是被劫持之后却显示了其他网站的广告链接图片。由于当时的CDN图片链接采用了不安全的http协议,所以很容易被劫持。后来改成了https,问题就解决了。
当然域名劫持有很多方式,https也不能规避所有问题。所以,除了一些安全防护措施,很多公司都有自己的备用域名,一旦发生域名劫持可以随时切换到备用域名。
故障八:带宽资源耗尽
带宽资源耗尽导致系统无法访问的情况,虽然不多见,但是也应该引起大家的注意。来看看,之前遇到的一起事故。
场景是这样的。社交电商每个分享出去的商品图片都有一个唯一的二维码,用来区分商品和分享者。所以二维码要用程序生成,最初我们在服务端用Java生成二维码。
前期由于系统访问量不大,系统一直没什么问题。但是有一天运营突然搞了一次优惠力度空前的大促,系统瞬时访问量翻了几十倍。问题也就随之而来了,网络带宽直接被打满,由于带宽资源被耗尽,导致很多页面请求响应很慢甚至没任何响应。
原因就是二维码生成数量瞬间也翻了几十倍,每个二维码都是一张图片,对带宽带来了巨大压力。
怎么解决呢?如果服务端处理不了,就考虑一下客户端。把生成二维码放到客户端APP处理,充分利用用户终端手机,目前Andriod,IOS或者React都有相关生成二维码的SDK。
这样不但解决了带宽问题,而且也释放了服务端生成二维码时消耗的CPU资源(生成二维码过程需要一定的计算量,CPU消耗比较明显)。
外网带宽非常昂贵,我们还是要省着点用啊!
本文分享的案例都是笔者的亲身经历,希望对各位读者有所帮助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721