
Q&A
Q1:请问DevOps与SRE是什么关系?
A:看来大家对DevOps vs SRE的问题还是比较热衷的,在很多场合下都会听到这样的问题。从我的理解来看,两者在工作范畴上是存在交叉重叠的,两者最本质的差异应该在于组织目标的侧重点上,即:效率 vs 稳定性。
Q2:如果维护对象质量太差,该怎么做SRE呢?
A:恩,这个问题还是略“尖锐”的哈。感觉可以从两个方面入手吧:
① SRE需要提升自己的掌控能力,尽可能用自己的掌控力去cover维护对象本身的质量问题;从另一个角度来看,不管你维护的对象本身质量如何,如果你都能够应对自如,这正是SRE的价值所在。
当然,上面这个状态是比较理想主义的,除此之外SRE还需要做到下面这点。
② 从SRE的角度给服务的研发、测试甚至是产品同学提出合理的建议,辅助提升产品的质量。这里就可以引用我们在直播中所讲到的“故障前的准备工作”的方法框架,比如柔性设计:这可能并不是所有的服务在设计之初都有考虑、实现的,然后这些特性却都是有助于我们更好地去保障服务的。这时候我们就可以提出相关的建设意见。
其实「服务质量」本身就是一个需要跨部门协作的事情,在统一好目标的前提下,去推动共同建设就好。
Q3:关于SRE团队组成,开发+运维的占比人数大概应该是怎样的一个组合呢?
A:这个还是要看具体的场景吧,看业务的复杂程度、看SRE团队的技术功力。像Google、Netflix等SRE理念落地成功的案例中,研发运维比就会比较高,比如Netflix只有个位数的核心SRE,支持着全球的业务。
Q4:石老师,请问那个架构图里标识出异常模块,是如何实现的?
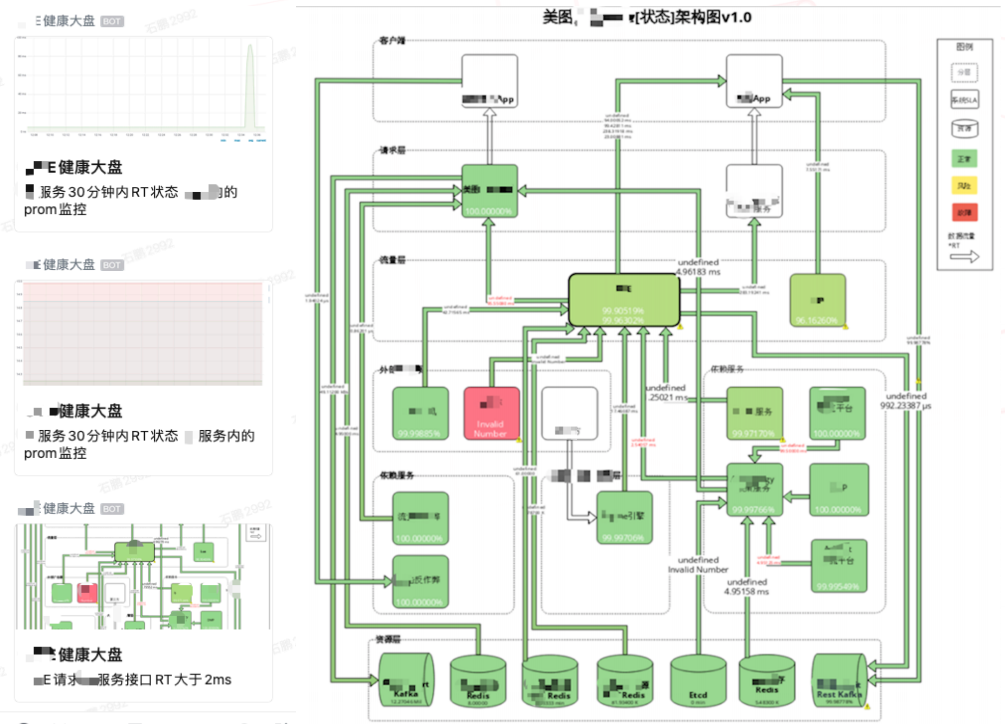
故障管理-监控告警
A:我简单说一下实现思路,有需要的可以自己去了解一下,网络上也有一些相关的资料。
用到的技术、工具主要有:Grafana、Grafana的一个插件Flowcharting、Grafana-images-render、draw.io在线绘图、企业微信机器人(钉钉、飞书等其他企业IM也是同样的)、用户发送告警的脚本或平台。
实现步骤:
① 实现图的动态数据功能
draw.io绘图(https://app.diagrams.net/)。
将draw.io绘制的图形源码(*.drawio 文件)完整copy到Grafana (Grafana → Visualization → FlowCharting → Source Content)。
为图形配置数据源。
将图形中的各个元素(图块、线条)跟对应的监控指标绑定。
② 实现告警发送功能
获取监控图的渲染地址,用Grafana-images-render渲染为公网可以访问的图片
编写告警脚本实现发送监控图到企业微信等IM工具的告警通道
配置Grafana的告警功能,在告警触发的时候调用上一步中的告警通道,把告警时刻的监控图图形发送给告警接收人
下面贴一些资料,供大家参考:
插件教程:https://algenty.github.io/flowcharting-repository/STARTED.html
在线演示:https://play.grafana.org/d/_J1UvKjWk/flowcharting-aws-cloud?orgId=1
插件源码:https://github.com/algenty/grafana-flowcharting
插件首页:https://algenty.github.io/flowcharting-repository/
插件安装:https://grafana.com/grafana/plugins/agenty-flowcharting-panel
插件效果:https://twitter.com/gf_flowcharting/status/1183386365175746562
插件交流:https://twitter.com/gf_flowcharting
Q5:请问新组建的SRE团队应该怎样快速成长,尽快成熟?从哪块入手比较好?
A:回归到IT管理的3要素上,人员、流程、技术:
可以先从意识层面入手,让大家的目标、思路能够基本保持一致;也就是人。
然后约定一些必要的流程、规范、协助工具;约定统一的“语言体系”、沟通机制;在前面的基础上小步快跑,逐步校正和迭代;这个事情不可能一蹴而就,在实际工作需求中练兵;及时沟通、反馈,多反思、复盘;这个点各更偏流程。
技术的话,作为一个基础点,可以从先业务需求入手,让团队把必备的技能拉齐到一个理想的水平线行,先做到能hold住服务;在这个目标达成之后就可以考虑做更长远的技术规划和更深的技术探索了。
Q6:现在SRE在美图发展的怎么样,工具平台是否都能自己团队搞定?
A:还是看具体的需求场景,注定有些需求是无法由单一团队完成的,这时候就需要借助外力来辅助或共建。
这里可以对齐一个理解和认知:全能全知的人是不存在的,依靠团队的力量可以让一群人的能力得到互补和延展,但同样也没有任何一个团队可以做到全能全知;这时候就需要有更高维的能力补充,跨团队协作就是最常见的方式之一。
所以,我们需要明确好我们的目标是什么,是解决具体的需求,还是要打造一个全能的团队;怎么选择会更具可行性、ROI会更好,这个或许就见仁见智了。
Q7:对于Trace系统选型和实践,美图是怎么做的呢?
A:基于开源的产品做了封装和适配。如果是小团队的话,建议直接使用开源的产品,目前这块的很多产品都是比较成熟的。
Q8:请问服务降级、熔断通过什么技术手段可以实现?
A:一般可以从3个层次来做实现:
业务代码。
业务框架。
运维(基础)架构。
个人感觉这个更多的还是要有相关的意识和理念,在产品设计之初就考虑到这些点,目前业界比较有名的技术应该是Hystrix。
Q9:请问美图的SRE团队规模有多大,是否还有专业组团队,比如DBA团队,基础架构团队?
A:SRE归属于运维部,运维部内部是有职能划分的,DBA、大数据SRE、安全团队、基础SRE、产品SRE等;我目前负责产品SRE团队,七八人左右,还有HC,欢迎有意向的同学来聊。此外,我们也有单独的基础架构团队,跟运维部是兄弟部门。
Q10:我们SRE太偏向业务,缺少系统、或基础运维类,后期会不会因为太稳定了,自己干掉自己?
A:NoOps是会实现的,但是SRE最终是基于什么样的原因被“干掉”可能会有很多种可能性,我更倾向于相信是AI。但是没有必要因此而焦虑,因为焦虑不能解决实际的问题,我们能做到的就是警醒精进、奋力前行,与君共勉。
Q11:什么是SRE运维?从事SRE需要哪些技术知识点/SRE需要什么技术栈?SRE运维与DesOps运维有哪些差异?
A:这个问题可以参考Q1,关于知识点和技术栈,这个结合当下的大趋势,建议大家从“云原生”的角度切入来打造自己的技术体系。
Q12:美图不同的产品线,都会定制特定的监控项目吗?
A:如果这里的“监控项目”指的是“监控系统”,是不会的,我们有提供统一的、可以覆盖绝大多数场景的监控方案。如果确实有不满足需求的情况,我们可以做一些个性化的适配然后做接入,当然不同的业务是可以基于这些统一的监控方案来建设自己的“监控大盘”的。
Q13:对于中间件这块的也是SRE在负责吗?
A:不一定,不同的组件可能会由不同的团队维护,有部分是SRE团队在负责的。
Q14:像微服务的架构,需要对每个服务都单独设定SLO吗?
A:理论上,应该是这样的;因为不同的服务的核心程度是不一样的,不同的服务的可用性目标也会有所差异。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721