
锦华,携程高级技术专家,超过10年互联网研发经验,2011年至今一直从事框架和中间件相关产品研发,对高并发、分布式中间件以及应用性能优化等有浓厚兴趣。
作为业界知名的应用监控产品,CAT 已经成功地为多家公司提供了完整的监控领域解决方案。2015 年 CAT 在携程落地,目前已经成为公司内部非常重要的监控基础设施,很好地支撑了来自 70000+ 客户端的 8000 亿条消息 / 天、900TB/ 天的实时监控流量。
本文将分享携程在 CAT 性能优化上的实践,并通过这些实践总结出一些普适性的性能优化思路与方法。

一、CAT 在携程的落地及发展情况
CAT 是大众点评开源的一个基于 Trace 的应用监控系统。2014 年底,携程开始引入 CAT 并落地。在这几年里,公司的数据量一直呈现着爆发式的增长,我们也不断地对 CAT 做了很多大大小小的优化,使得机器数目并没有像数据量那样呈现出指数级的增加。
到目前为止,有超过 7 万的客户端,每天处理的消息树超过8000 亿,每天处理的日志量超过 4 万亿行,峰值流量达到 1.5 亿行 / 秒。

二、CAT性能优化案例
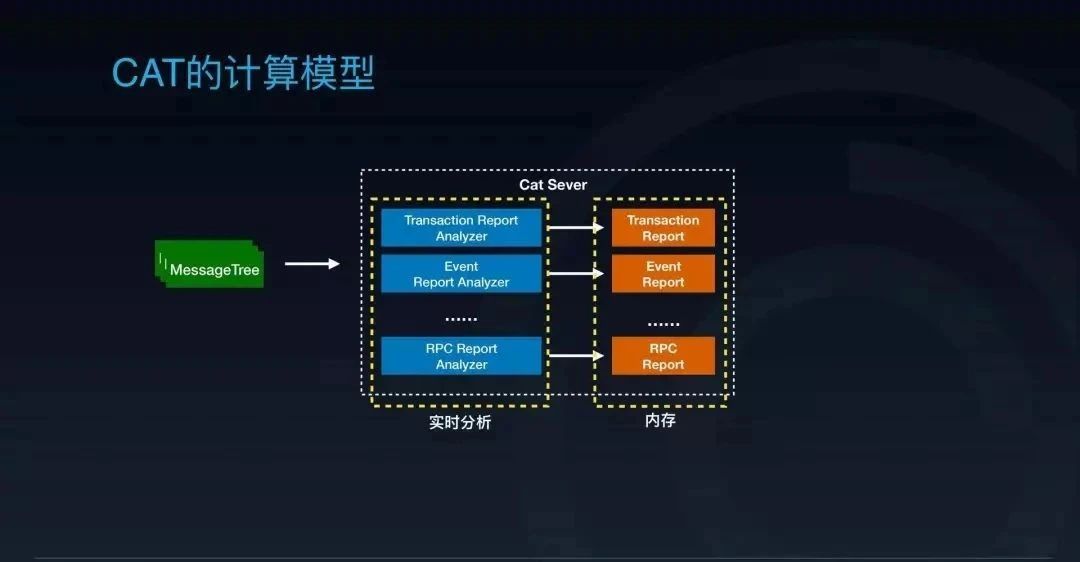
在介绍案例之前,我们简单介绍一下 CAT 的计算模型。
CAT 客户端的监控数据会组装成一种树状结构,也就是 CAT 里面的 MessageTree,然后发送到 CAT 服务端。CAT 服务端会把这份数据同时分发给多个不同用途的报表分析器进行实时计算,计算出来的结果会被存到服务端的内存报表里面。
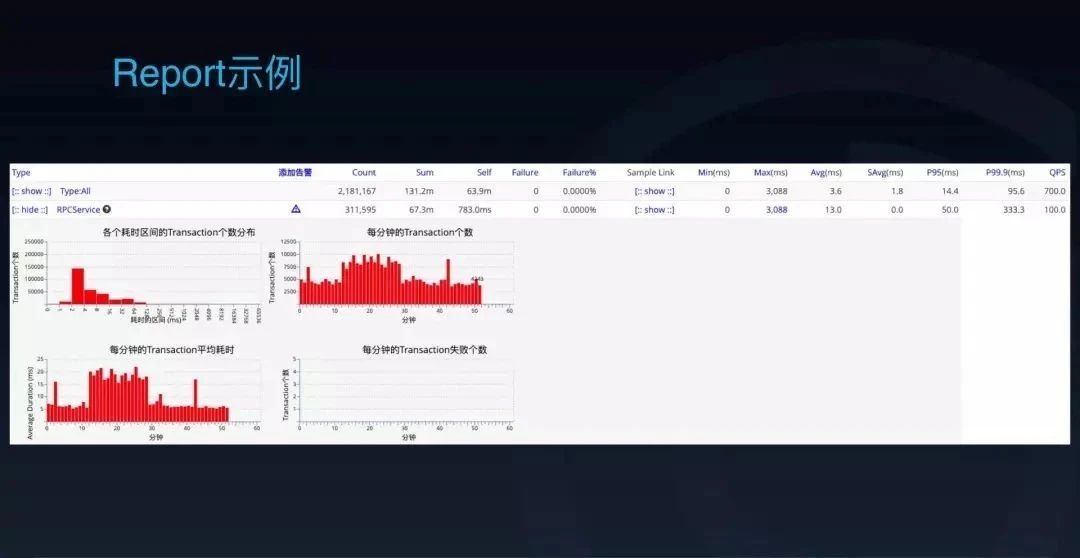
我们的报表是什么样子的?这里是一个 CAT 最基本的 Transaction 报表截图,可以把它简单理解成一段时间内的一些监控指标的聚合。这个例子里面展示的是 RPCService 这个 Transaction 在这一小时内每一分钟发生的次数、平均耗时、每分钟的失败以及这个小时的平均耗时,99 线、95 线。
下面看一下,CAT 服务端经常遇到什么样的问题。首先,从上面的计算模型可以看到,报表分析其实是一个 CPU 密集型的任务,所以 CPU 跑满是一个经常遇到的问题。另外,还是根据上面的计算模型,所有实时的报表数据都会放在内存里面,所以 GC 频繁也是经常遇到的一个问题。
1)CAT 线程模型
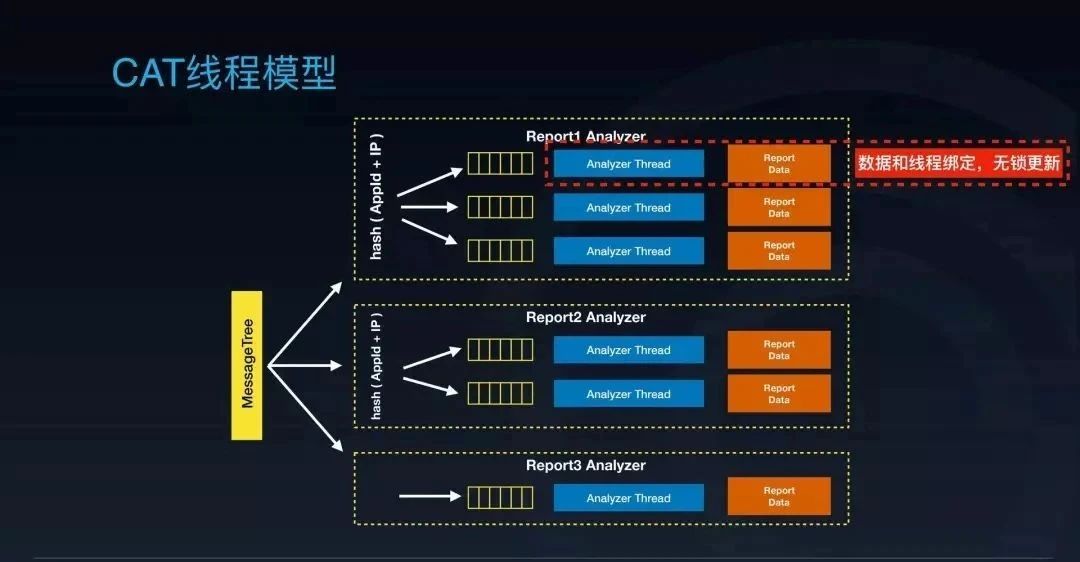
CAT 客户端的监控数据发送到服务端后,服务端会同时将这份数据分发给多个不同用途的报表分析器,报表分析器内部会根据这个监控数据的客户端信息(APP ID 和 IP)计算一个哈希值,然后再分发到报表分析器内部的一个队列里面。
这个队列后面会绑定一个线程进行实时分析,计算出来的结果会放到这个线程绑定的内存报表中。这种模型有一个好处,就是它把数据跟线程绑定在一起,使得对同一个客户端过来的监控数据的实时分析、计算和内存报表的更新都是无锁的。
2)遇到的问题
随着流量不断增加,我们发现,其实不同的应用和客户端发送过来的数据是非常不均的。数据的不均就会导致队列堆积,最终的结果就是某些堆积的队列对应的客户端监控数据丢失。对于数据不均的问题,天然的我们就会想到通过增加更多的队列,让哈希算法更加均匀就可以解决。
但是,在这种模型里面,增加队列同时意味着也要增加对应的处理线程。一开始我们一直是用这个方法去解决数据不均的问题,直到有一次发现当前的队列以及处理线程已经太多了,再加下去甚至还会出现处理能力的下降。
3)分析问题
于是就开始去分析,为什么处理能力反而下降了。查看监控指标之后,发现操作系统的上下文切换已经达到了每秒钟几百万次之多。这时候赶紧去看一下服务端的线程,发现经过前面的一顿操作,最后所有的报表加在一起已经有了几千个线程,非常的多。回过头来审视我们的模型,当数据不均的时候,核心需求是要通过增加队列来将数据进一步的打散,为什么处理线程也要随之增加呢?
所以,第一个想法就是把这模型里面的队列和线程做个解耦。
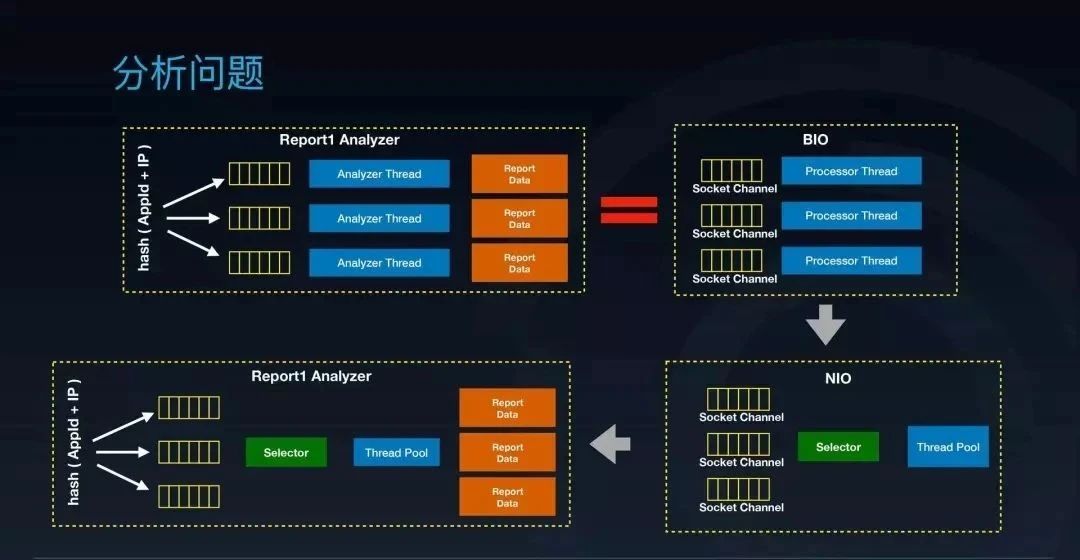
在谈及队列和线程解耦的模型时,第一想法就是 IO 模型。可以看看现在的线程模型,它跟 IO 里面最老的 BIO 模型是不是非常相似?它们都是每个队列或者 channel 后面有一个线程在阻塞等待数据的到来,然后去计算,所以会有非常多的线程。每个 channel 即使没有数据到达也需要有个线程在阻塞等待,非常浪费。
BIO 模型往下的一个演进就是 NIO 模型。NIO 通过引入一个 Selector 模块, 很轻量地就可以监听非常多的队列数据。于是我们就想,是不是也类似这样,通过引入一个 Selector 去监听多个队列来达到队列跟线程解耦的目的呢?
4)新线程模型

来思考下,我们所要引入的这个 Selector 在 CAT 的服务端需要实现什么样的功能?首先,毫无疑问的是需要一个监听队列的功能。另外,还需要在上面实现一套调度策略,一方面可以让它充分利用后面的线程池,另一方面要保持我们的模型跟原来的模型一样,在同一个客户端,同一队列的更新是不需要加锁的。
这里有个小小的细节,实现 Selector 的时候并不是说直接开一个线程不断地空轮询所有的队列,这样会非常低效,你永远不知道哪个队列什么时候会有数据,只能一直空轮询。我们的实现方式是在数据进入队列的时候,反过来去 notify Selector,让 Selector 决定在这个时候是触发调度还是应该先 hold 一下,后面再调度。

把报表分析器的模型改造好后,把它放到整个 CAT 服务端去看。一个服务端会有很多报表分析器,会看到改造后在 CAT 服务端的每个报表分析器都有自己的 Selector 与线程池。
但真的需要这么多线程池吗?从这个模型就可以知道,其实我们的报表分析任务全都是计算密集型的,按理说整个系统里面应该只需要开 CPU 核数个的线程就可以充分利用所有的 CPU 资源,于是自然而然地就把我们的所有计算线程合并到同一个线程池中。
再看 Selector 模块。既然设计初衷就是让一个 Selector 可以非常轻量就可以监听非常多的队列,那么其实用一个跟用多个都是能达到同样的效果。另外,如果只用一个 Selector 的话,可以比较容易地实现一套优先级调度的策略。
为什么需要一套优先级调度的策略呢?因为监控数据其实也是有优先级的,我们会希望在系统负载比较高的时候,一些高优先级的报表和监控数据可以得到更多的资源,优先去计算。于是把 Selector 合并在一起,在它上面实现一套优先级的调度。这就是我们当前所使用的 CAT 服务端的线程模型。
5)小结
稍微总结一下,我们通过线程模型优化,从原来的像 BIO 一样的线程模型改造成了现在这种像 NIO 一样的线程模型。
首先它满足了初衷,让队列和线程做一个解耦。那么解耦之后,就可以设置非常多的队列,一方面很好解决数据均匀的问题,另外一方面,因为增加了队列,同时也减少了单个队列的锁竞争,那么只要开 CPU 核数个线程就可以了,不会像原来那样每个报表分析器都要开自己的线程,线程数减少了,相应地也能减少很多没有用的上下文切换。

另外,我们在这个新模型里还提供了一套比原来更加灵活的调度策略,可以实现优先级调度。这个模型上线后,我们从原来每台机器跑到超过 90% 的 CPU,最后还出现 5% 的丢失,优化到数据不丢 CPU 还下降到 70% 左右。
1)遇到的问题
经过之前的优化,CPU 已经利用得比较充分了。但随着流量进一步增加,我们最终还是把 CPU 全部用满,数据又开始丢了。
2)分析问题
现在的资源是不是真的不够了,是不是要进行机器的扩容?出于成本的考量,我们决定先进行优化,看能不能再节省一些 CPU 出来,从而能够在成本不变的情况下扛更大的流量。
经过分析,借鉴了当下的一些思路,决定将服务端的部分计算下放到客户端去。
那么到底什么样的计算比较适合放到客户端?首先,一定要是一个不变的,或者是变的很少的逻辑。否则每次更新计算逻辑都会需要更新客户端,这个过程会变得非常的漫长。其次,肯定要是一些在服务端占用 CPU 资源比较多的计算,否则花了很多力气去改造,最后却只能得到一个不是很划算的效果。
3)Transaction/Event Report 的 CPU 使用
说到不变的逻辑,自然就会想到 CAT 中的两份基本报表:Transaction 和 Event Report。这两份报表的分析计算非常简单,就是针对 Transaction 和 Event 这两个基本模型进行数据的聚合统计。这两个报表到底占用了多少服务端的资源呢?通过调整上述 Selector 模型提及的调度策略,我们将这两份报表的计算放到独立的线程池中进行,得到了如下的资源使用率:

从以上数据可以看到,服务端中, Transaction 报表的计算用了 7 个线程,分别都会占到 0.8、0.9 个核,所以这 7 个线程总共在服务端占了 5.3 个核。Event 报表有 4 个线程,每个线程也跑到百分之四五十、六十左右,加在一起也有 2.2 个核,这两张报表的分析在服务端就使用了一台机器中的 7.5 个核。如果机器是 32 核的话,相当于它占了 23% 的计算资源。如果能把这个计算挪到客户端,那会省下来很多的资源。
4)Transaction/Event Report 计算
来看这两份数据是怎么计算的。
首先,看一下服务端的计算方式。客户端会把一个个监控数据组织成 MessageTree ,以一种树状的结构发送到服务端。服务端会遍历所有发送来的 MessageTree,找到树里面嵌套的 Transaction 和 Event 结点,然后做一个数值的统计。这个计算量是非常大的,它不仅会跟客户端发送过来的 MessageTree 的个数有关系,还会跟每个 MessageTree 里面到底有多少个 Event 和 Transaction 也有关系。
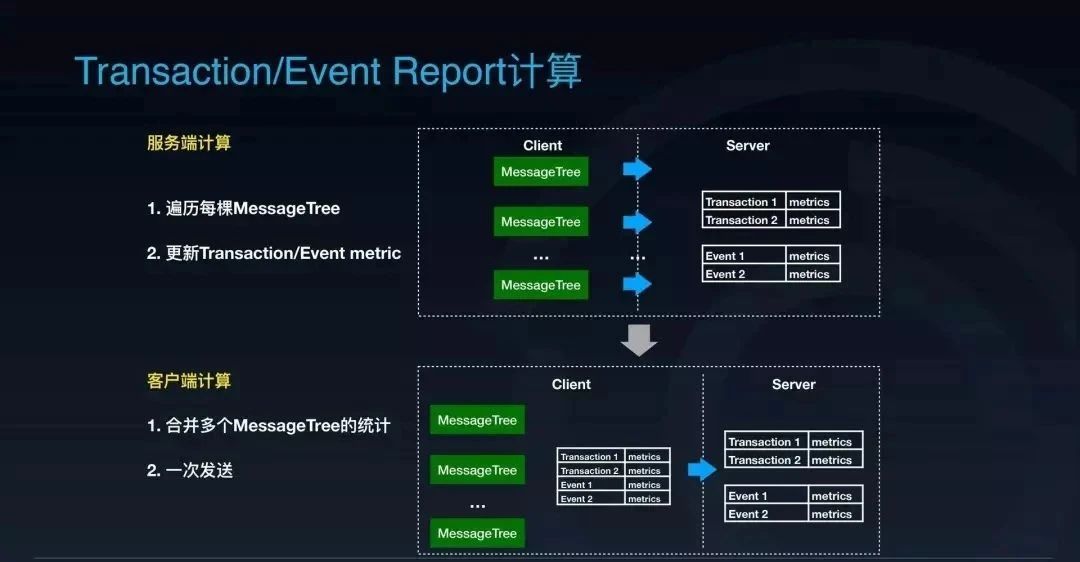
那怎么把它挪到客户端去呢?我们可以把客户端里多个 MessageTree 内的统计数据合并成一份,一次性把这个统计数据发送过来。这样的话服务端的计算量将会极大的减少。
这种计算方式下,计算量只会和客户端数量以及客户端发送这份统计数据的间隔时间有关系。看看最后改造出来的架构,客户端增加了两个用于进行统计的 Aggregator 分别来计算 Transaction 和 Event 的指标,然后再将这些数据定时发送到服务端去。
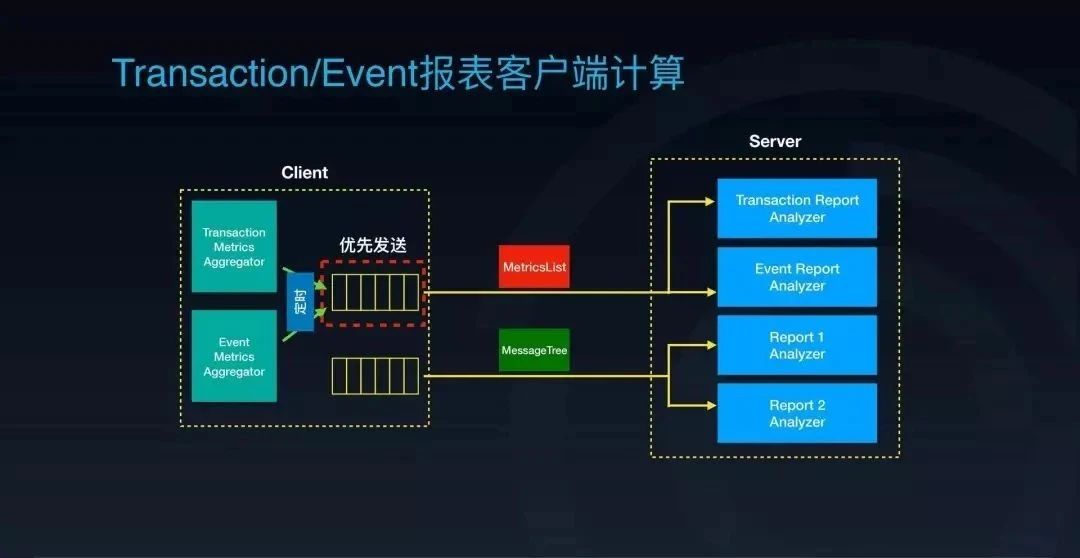
此外,我们做了一个小小的改动,把原来 CAT 的一个发送队列改造成了两个发送队列,一个队列用来发送原来的 MessageTree,另外一个则是用来发送客户端预聚合过的统计数据。统计量队列的发送优先级会稍微高一些,这样的话就可以保证客户端即使在整体负载偏高,数据来不及发送的情况下,也能优先把统计量发送到后端去,从而保证了监控系统统计量的准确性。
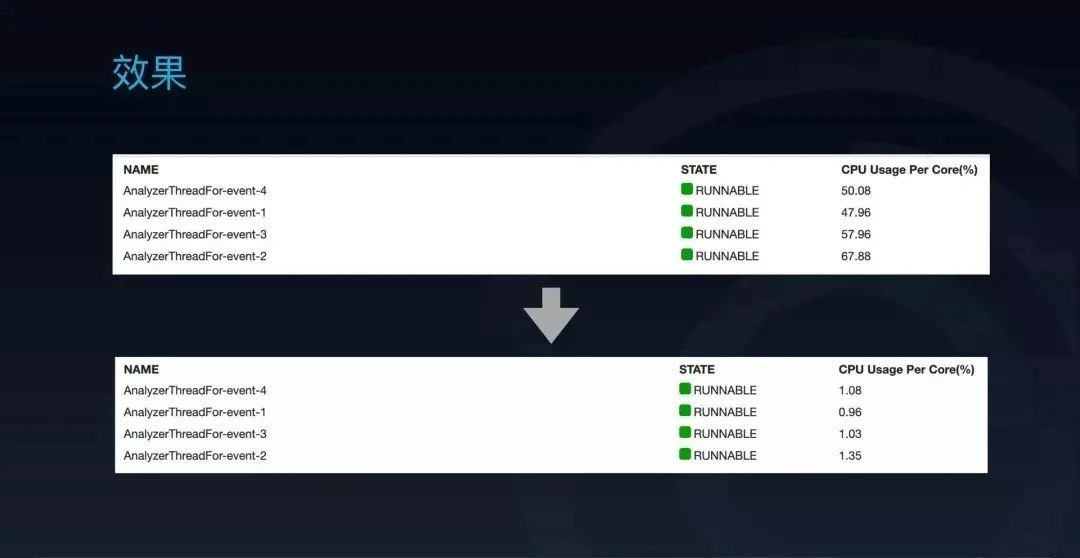
在这个架构上线后,可以看到 Transaction 报表从原来的 7 个线程占了五点几个核,下降到现在 7 个线程,每个线程只要 0.02 个核。

Event 报表也从原来的 4 个线程,每个线程占 0.4、0.5 个核,变到现在 4 个线程,每个线程只能吃掉 0.01 个核。效果还是非常明显的,省了很多资源出来。
这样的一个计算,在客户端到底有多大的影响?在客户端的视角,内存的占用其实非常少。因为我们仅仅只是在客户端增加了几秒钟的统计数据的聚合,这个数据量非常少,而且过几秒钟后这份数据就会被送走了,所以不会对客户端的内存使用造成很大的影响。
根据我们的统计,整体的内存消耗只在 10M 以下,CPU 的占用则基本上可以忽略。服务端的计算需要对一棵棵监控树进行遍历然后去分析统计,但在客户端这个流程其实是反的。客户端是先有统计数据再组织成树,所以其实只要在产生监控数据的时候,在它埋点结束之后多加一个统计量,而省去了遍历一棵树的消耗,所以它对客户端 CPU 的影响几乎为 0。

5)小结
总结一下这个案例。我们之前很多时候会想让客户端做的比较薄,尽量让逻辑落到服务端来获得一些灵活性,但其实也可以考虑把一些相对简单且变更较少的计算逻辑挪到客户端去。
客户端相比服务端来说,有足够多的上下文信息,因而客户端的分析计算可能会比服务端计算简单得多。从这个例子里可以看到客户端计算的时候,它只要在你两个基本模型 Transaction、Event 埋点结束的时候多做两个统计的累加就好了。但在服务端就很麻烦,服务端需要把那棵树重新反序列化出来再去遍历它。

另外我们做了一个类似于批量处理发送的优化,从而让服务端的计算量变得只会跟客户端的数量和间隔时间有关系。这样做有一个非常大的好处就是服务端的计算会比较平滑,不会因为客户端这边突然间有个流量峰值过来,突然间发了很多监控数据,从而导致后端产生抖动影响。
1)遇到的问题
随着流量又进一步继续增加,我们发现一个比较奇怪的现象——每个小时切换的前几分钟都会发生一定的监控数据丢失。
看了一下网卡监控,发现网卡流量是平稳的,并不会出现每小时前几分钟会抖动的现象,因此排除了由于入口流量导致异常的推断。又看了服务端的应用监控指标,发现 Young GC 也是有着类似的趋势,每小时的前几分钟有个抖动,甚至在某一分钟里面出现了 60 秒钟里面有 10 秒钟在做 Young GC。于是就要去看 CAT 服务端里面到底是什么东西在用我们的内存。

2)CAT 服务端内存使用
从计算模型可以看到, CAT 服务端会接收大量的客户端发送过来的实时监控数据。这部分数据到了服务端,接下来就要被分发去做实时的报表统计分析,所以这部分数据会占用服务端很多内存。另外,根据 CAT 的计算模型也可以看到 ,CAT 服务端会将大量的当前小时的实时报表数据放在内存中,所以当前小时的报表也是内存占用的一大来源。
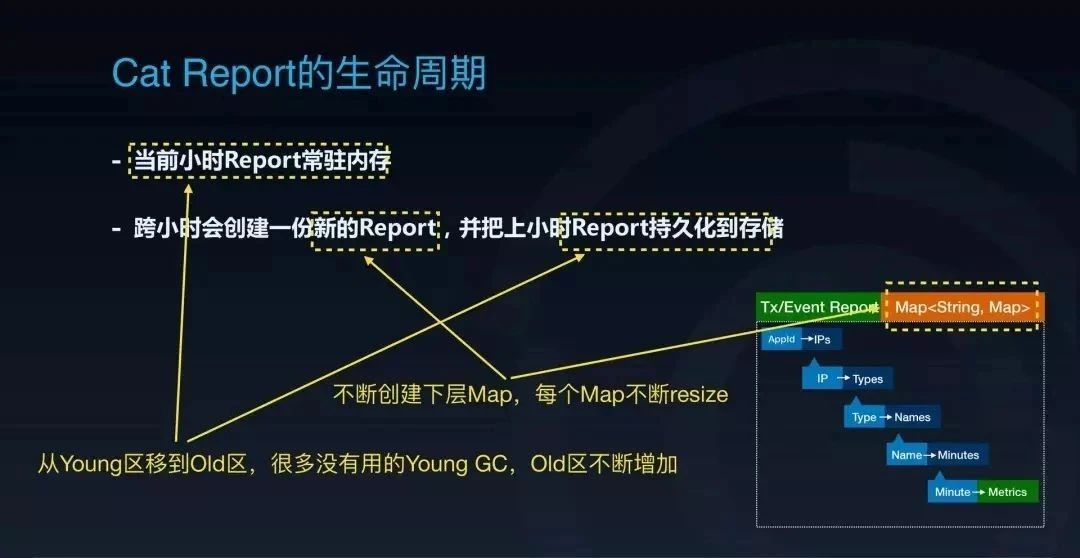
3)CAT Report 的生命周期
要看报表的问题,需要先看一下 CAT 报表的生命周期是怎么样的。首先, CAT 会把当前小时的报表存在内存里面,跨小时的时候重新创建一份新的空报表供下个小时用。小时切换后,上个小时的内存报表在被持久化到存储之后基本就没有用了,等待被下一次的 GC 释放。
报表在内存里面的树结构是怎么样的?CAT 报表基本上结构比较相似,我这边举两个基本的 Transaction 和 Event 报表。
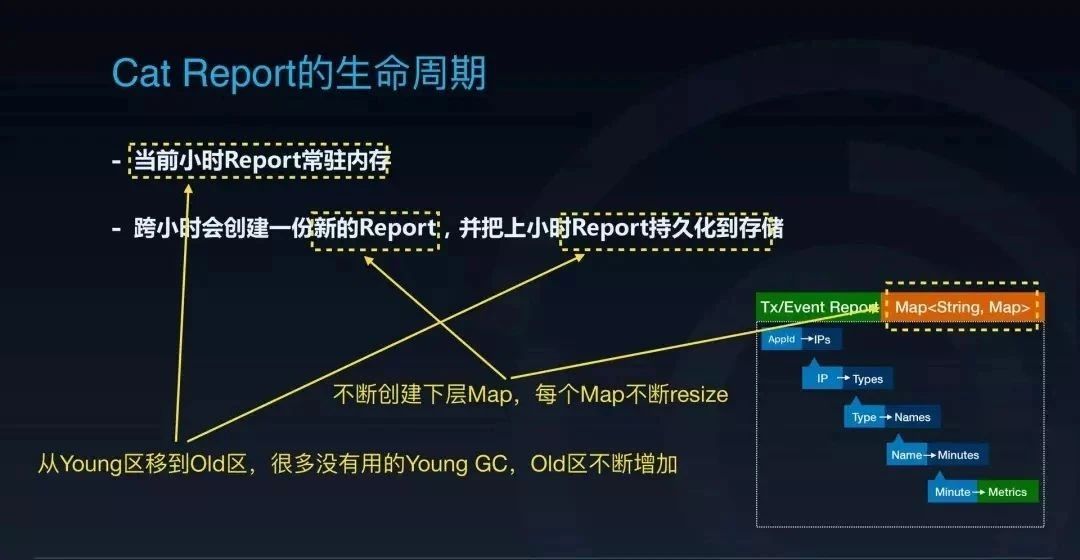
我们可以把这两份报表简单理解成以字符串为 key,Map 作为 value 的一个 Map 套 Map 的结构。比如这个例子里面,它第一层 Map 就是通过 AppId 作为 key, 去找到这个 AppId 对应的所有 IP 的数据构成的一个子 Map。然后通过 IP 列表的 Map 再往下逐层寻找,直到最后找到对应条件在某个时间点的指标数据。
从这个生命周期里面可以看到,这样的使用方式第一个问题,就是每小时它都会创建一份新的报表,而这份报表在刚创建出来的时候,由于驻留索引的缺失以及新的数据的不断投递,它会被不断地填充,这个报表会不断地创建对应的下层的 Map。在不断地填充过程中,你会发现这个 Map 还会不断地需要去 resize,扔掉一些之前已经使用的内存,非常浪费。
我们看到 CAT 的当前小时的报表是常驻在内存里面的,到下个小时持久化完它就可以释放掉了。从这个地方我们可以看到报表生命周期的第二个问题,一个报表一开始创建时在 Young 区,随着监控指标不断过来,报表会不断扩大。这个报表会不断地被 Young GC 扫描到,但是由于这个报表是常驻内存一小时的,所以其实这些 Young GC 都是没有用的。当 GC 次数达到阈值后, Young GC 还会把它搬到 Old 区。那么这份 Old 区里面的报表到了下个小时完成持久化之后,就会变成一份没有用的报表,导致 Old 区里面就无缘无故多了一份没有用的数据。
4)分析问题
我们可以从这个生命周期里面看到好几个问题。
针对 Map 会不断地被 Resize 的问题,很自然会想到,一个公司的监控系统里面的监控指标应该是基本稳定的,所以是不是可以在跨小时的时候直接 clone 上个小时的报表,按照上个小时的报表的索引以及 size 去创建。但我们发现其实 clone 并没有解决第二个问题,在 clone 的过程中还是会一直在创建下层的 map,而且依然还是在 Young 区产生一份报表,然后慢慢搬到 Old 区,最后还是要丢弃掉,内存的结构并没有发生变动,所以这个 clone 的方法肯定是不行的。
另外一个方法,能不能直接创建两份报表,一直轮换着使用。这两份报表因为一开始就创建好了,它很快就会到 Old 区,然后在轮换使用时,这份报表其实就一直在 Old 区根本就没有任何的浪费,它也不需要被创建。
那么我们把报表的生命周期改造成了现在的样子:一开始直接创建两份报表,它们一直就在 Old 区里面轮换着使用。为了保证这个 Map 不会在经过长时间运行之后慢慢充斥着很多无用的监控指标项目,我们加一个定时清理的策略,把一些内存中里面,比如说两三个小时已经没有再接收到的监控数据清除掉。
5)效果
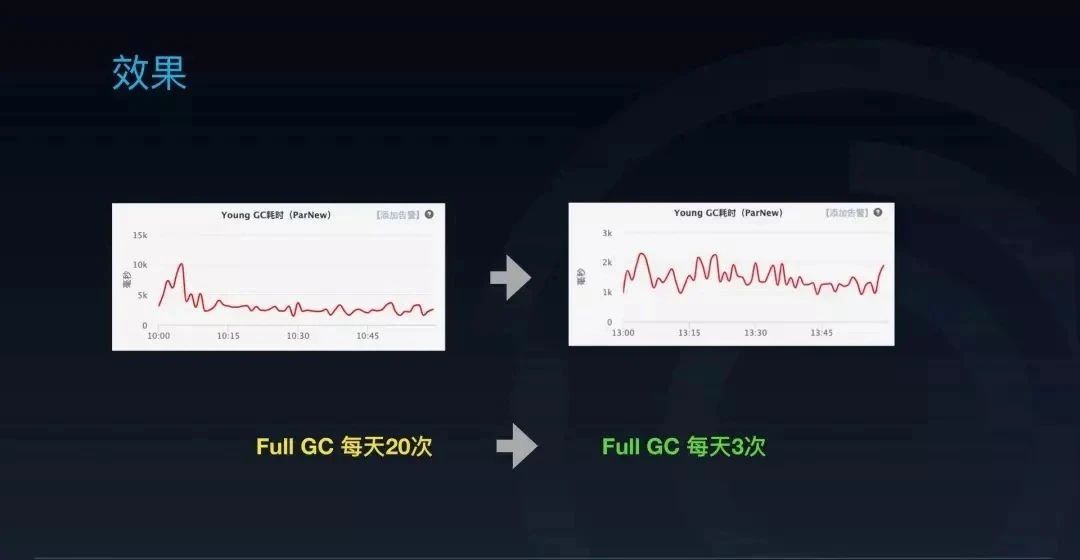
可以看到首先 Young GC 已经达到最开始的期望,达到了稳定的状态,而且因为它根本不用搬动这份大的数据到 Old 区,也不用扫这份大的内存,GC 速度也快了很多。此外,我们的 Full GC 也从每天的 20 次降到了每天的 3 次。
6)小结
对于 GC 问题可能会想到要去调参数让效果好一点,但实际上根本问题是需要考虑尽量少分配内存,因为不分配内存才是根本诉求。如果一定要把内存创建出来,就得考虑是否可以复用这份内存。
第四个案例,我这边起名成字符串,是因为我们在 CAT 里面做了一系列字符串相关的优化。先看一下为什么要做字符串优化。
这是从服务端抓出来的一份 Flight Recorder 的数据。可以看到,我们这里一分钟内创建的 String,Char[] 以及 UTF_8Decoder 对象总共有 60 多 G,相当于每秒钟有 1 个 G 的对象产生。如果能把这部分的内存节省下来,系统能够运行得更好。

1)MessageTree 的传输
这个问题得先看一下 CAT 里面 MessageTree 的传输过程。首先它会从客户端把 MessageTree 序列化成一个字节流,通过网络传输到服务端,然后服务端会把这个字节流完全的反序列化复原成原来的 MessageTree 再分发给报表分析器去计算。
MessageTree 其实就是由 CAT 两大模型,Transaction 和 Event 组成的树状嵌套结构。
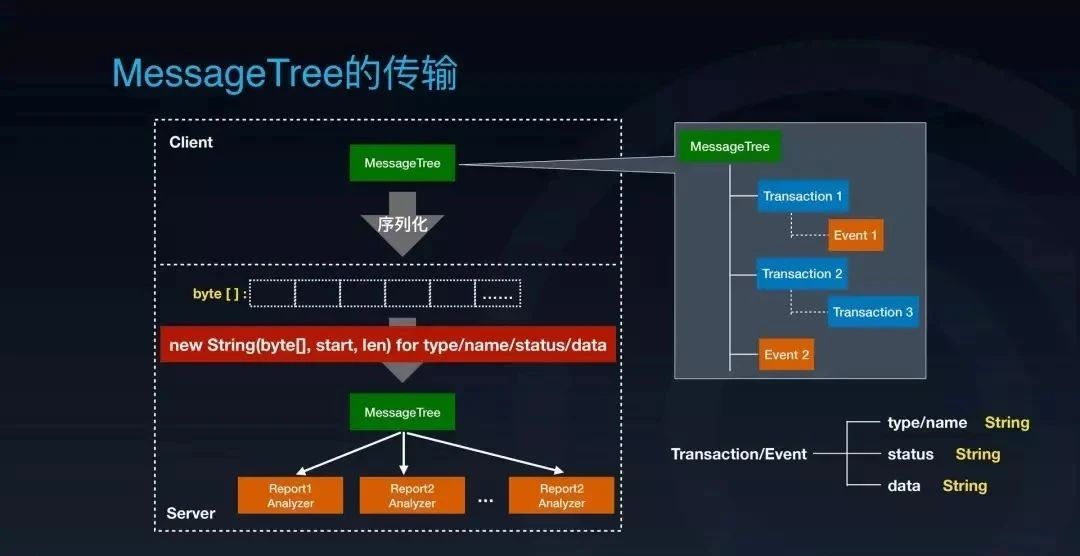
可以看到这 Transaction 和 Event 里面有四个字段都是字符串的: type,name,status,data。字节流反序列化成 MessageTree 的过程中会把这个 Tree 里面的每个 Transaction 和 Event 里的这几个字段做一次反解的操作。
这个操作到底有多大的损失?翻看一下 JDK 代码就可以发现,就这么一个简单的字符串构造,看起来很简单的一个构造函数,实际上它里面做了两次 Char 数组的分配,还做了一次字符集的解码,将字节流变成 UTF_8 编码的 Char。所以仅仅只是这么一个简单的构造函数,既消耗内存和也消耗 CPU。
2)byte[] —> String

那么就要看,刚刚分析出来这几个字符串字段是不是都需要做这样的一个反序列化操作。首先看 data,data 我们可以把它简单理解成 Transaction 和 Event 的一个附加信息。大部分时候我们的报表分析其实根本不关心这个附加信息,附加信息一般都是用来给用户查问题的时候,他点开这个 MessageTree 去看,但实时分析大部分情况不会用到的。所以这个 data 我们是完全可以按需的解开就好了。

然后再来看第二个字段,status。它是用来描述 Transaction 和 Event 成功与否的状态,如果失败的话,它会把失败原因放进去。所以可以想象,如果它失败的话,status 里面有可能是一个非常大的字符串。
大部分情况下我们的报表只关心状态到底是成功还是失败,具体的失败原因一般也是用户点开的时候才关心,它分析的时候是不关心的。所以对于这个字段可以简单地特殊处理一下,在序列化的时候多引入一个字节去描述它是成功还是失败,具体失败原因可以放到后面去,也是一个字符串,但是后面那个字符串基本上也是按需解开即可。
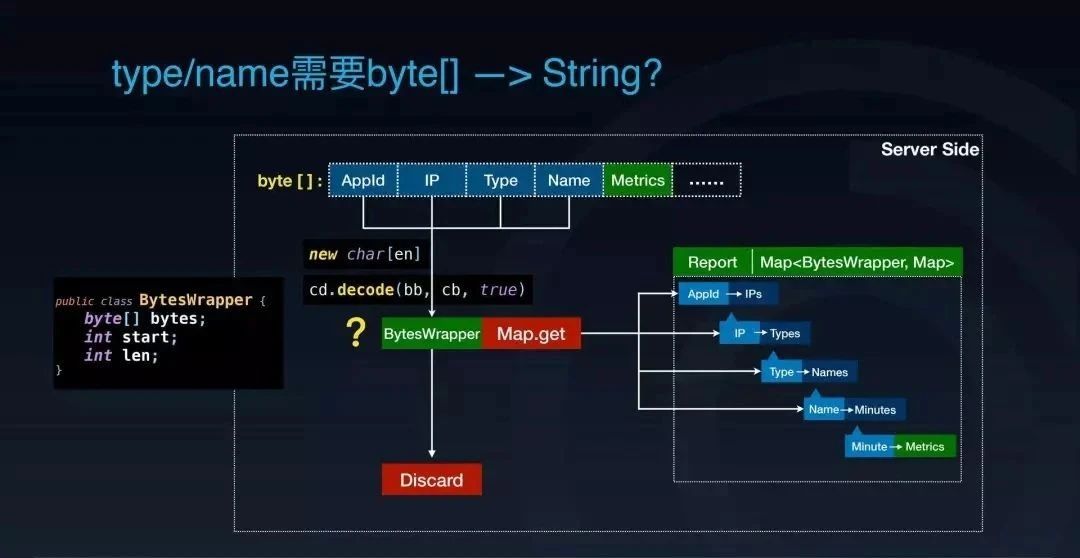
3)type/name 需要 byte[] —> String?
我们来看 type/name 这两个字段。这两个字段会稍微复杂一些,我们需要单独拿出来看。首先,我们来看一下为什么会用到 type/name 这样的东西。一个 MessageTree 通过序列化变成字节流传输到服务端之后,服务端要更新的值其实就是这个字节流里面的 Metrics 部分。报表的内存结构类似于 Map 套 Map 的结构,AppId,IP,Type 和 Name 其实就是一个个的索引 Key,最终的目的就是为了定位并更新他们对应的指标值。

那么为了完成这个 Map 套 Map 结构的报表的计算过程,需要把这些字段一个一个反序列成字符串,然后去跟报表里面的每一层 Map Key 进行比较,一直往下找,找到最下层的 Map 后再去更新 Metrics 的值。而这些字符串基本都是在完成了比较后就会被丢弃。
这里的每一个操作,每一次字符串转化都会引入刚刚说的两次损失。看着这个图思考一下,其实每一次的字符串转化都只是为了用于在 Map 中进行逐层的寻找和比较,这个过程是不是一定要用字符串呢?
既然监控数据的完整字节流已经过来了,能不能直接在字节流上面做比较,而不用创建出来的字符串去比较?基于这个想法,我们写了一个 BytesWrapper,它其实就是引用了完整的字节流,通过成员变量标记了对应的字段在这个字节流里面的一个起始位置和长度。我们在定位 Map Value 的时候就可以通过这个 BytesWrapper 来直接进行字节流的比较,从而省掉字符串创建的损失。
4)进一步思考
这样是不是就已经完美了?我们知道其实每个 Java 对象创建,既使是再小的对象,都会有对象头的损失,有时候还会有字节对齐的损失。我们可以看到我们这个 BytesWrapper 在 64 位机器,而且打开压缩指针的情况下,它首先会占掉前面 16 个字节的对象头,中间有三个 4 字节的字段,最后因为要做 8 字节对齐,它还有 4 字节。整体算上来,它需要用到 32 个字节。
在这个比较里面,虽然我们能够优化掉字符串比较,但是实际上我们还是要创建一个 BytesWrapper,而且这个 BytesWrapper 依然是不能避免创建出来还是要被扔掉的命运。

其实我们就是为了想直接用字节流里面的数据来做比较,为什么要创建这样一个对象呢?关键的问题就在这里。因为 HashMap 需要一个 Object,通过这个 Object 里面的 Equals 和 HashValue 来做比较。那如果我有这样一个 Map,它的 get 方法直接接受一个字节流,以及对应的 offset 和 length ,它可以直接帮你进行比较、寻值,是不是就可以避免这个创建对象的损失了?

因此,我们针对这个场景重写了一个 HashMap ,它内部通过字节流以及它的 offset 和 length 来计算它的 hashcode 和 equals。这个时候就可以把刚刚这个模型变成了报表里面只有一 BytesHashMap 作为它的结构,我们完全就可以在计算时直接在网络传输而来的字节流上做比较,不会有多引入任何一个对象创建,当然也不会有 discard 操作。现在再回过来看 type/name 这两个字段,它其实也是不需要进行字符串转换的,只要把报表改成 BytesHashMap 这样一个结构,就能够直接利用原始的字节流来完成操作。
改动上线后可以看到, Young GC 减少了 40%。

5)小结
我们一定要去关注代码中大量使用的对象,以及它的创建过程究竟会有多大损失。即使是这个例子中里面这么简单的字符串构造函数,实际上它对我们的内存和 CPU 也有一定的消耗。在这个例子里面,我们通过直接引用网络传输而来字节流进行计算处理就可以避免这些损耗了。
三、总结和思考

最后一部分,性能优化的一些思考。
对于 CPU 问题,第一个要想到的是减少额外的损失,额外损失是代码直接引入的消耗以外的损失。比如说例子里面就是优化线程模型。一方面是减少了上下文切换,另一方面还减少锁竞争。在 Java 中,一般来说锁的实现在前面几次的比较中使用的是 spin lock 的方式,所以你会发现其实减少锁竞争对的 CPU 也是有着一定的好处。
把额外损失减少之后,还得考虑优化自己的代码实现,减少不必要的操作。看一下每行代码,比如说例子中减少字符串的构建就可以减少掉没有必要的字符集的解码。除此之外,还可以考虑一下把一些计算逻辑从服务端移到客户端,帮我们分摊计算。

对于 GC 问题,根本上应该是要减少不必要对象的创建。这几个案例里面,第一个是减少了创建字符串,直接复用字节流。还有就是案例里面通过复用内存减少了报表的重复创建、填充还有 resize。
突破运维转型困局,9月11日在北京,让Gdevops全球敏捷运维峰会给你新思路:
《浙江移动AIOps实践》浙江移动云计算中心NOC及AIOps负责人 潘宇虹
《云时代下,传统行业的运维转型,如何破局?》新炬网络运维产品部总经理 宋辉
《数据智能时代:构建能力开放的运营商大数据DataOps体系》中国联通大数据基础平台负责人/资深架构师 尹正军
《银行日志监控系统优化手记》中国银行DevOps负责人 付大亮 & 中国银行高级软件工程师 李晓宁
《民生银行智能运维平台实践之路》民生银行智能运维平台负责人/应用运维专家 张舒伟
《建设敏捷型消费金融中台及云原生下的DevOps实践》中邮消费金融总经理助理 李远鑫









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721