
蒋健,云趣网络科技联合创始人,Oracle ACE,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化、Oracle CBO及并行原理。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。
近期到客户现场拜访时,客户反馈刚好数据库前几天遇到了“bug”,希望我们能协助排查下。
客户反馈现象如下:有个非常核心的系统数据库,突然某天使用XXX schema登录后,运行的SQL都是并行状态跑的,而且DOP非常高,多次定位故障的无果的情况下,只能临时使用parallel_max_servers参数降低并发度至32,缓解下并发过高的压力。
先看下数据库前几天的情况,故障时段确实AAS确实很高。
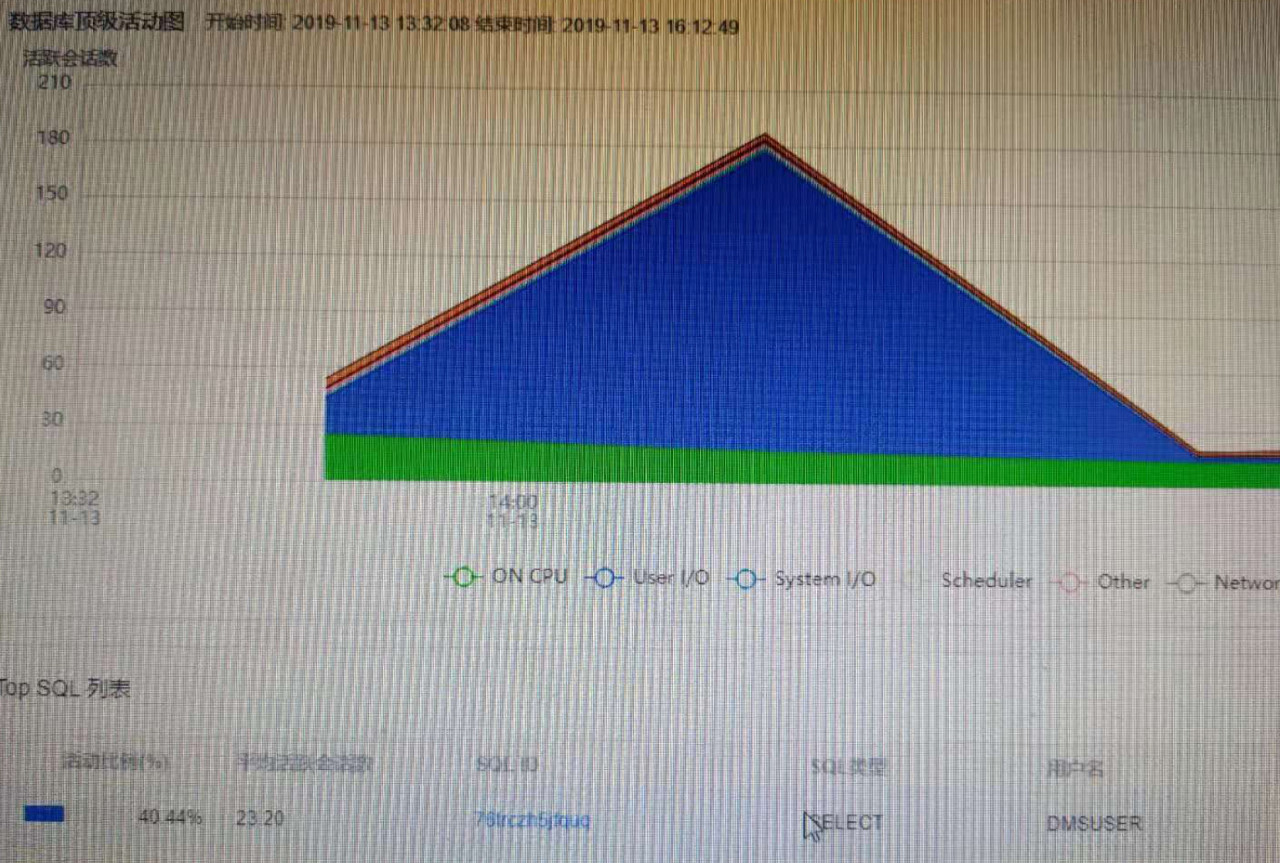
切换到单个SQL运行情况,DOP非常高,后被限制,与客户描述一致。
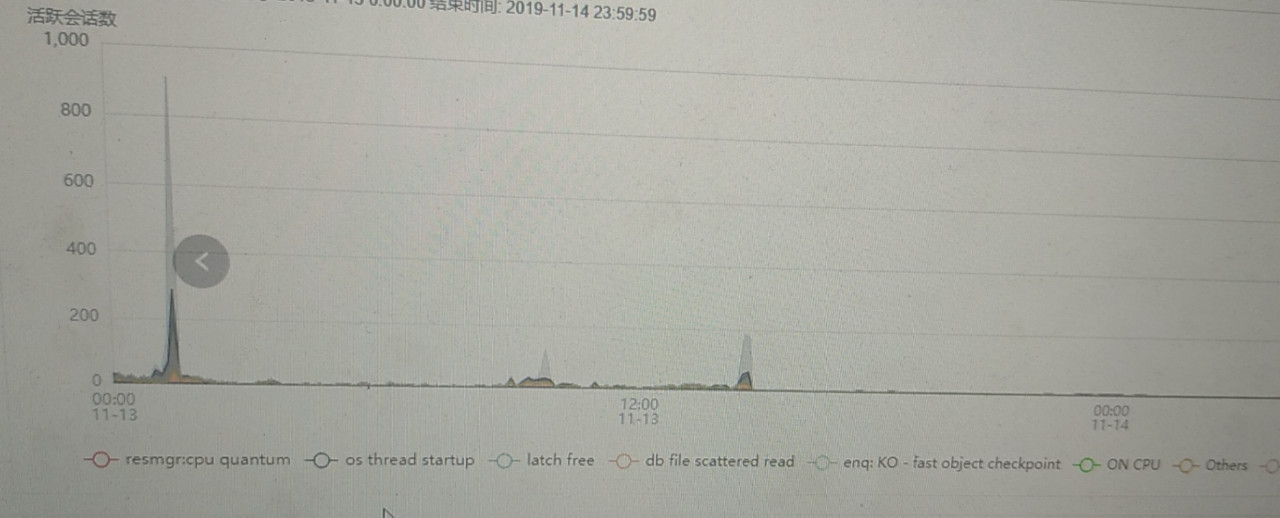
顺手打开了旁边的监视报告,DOP降级明显。
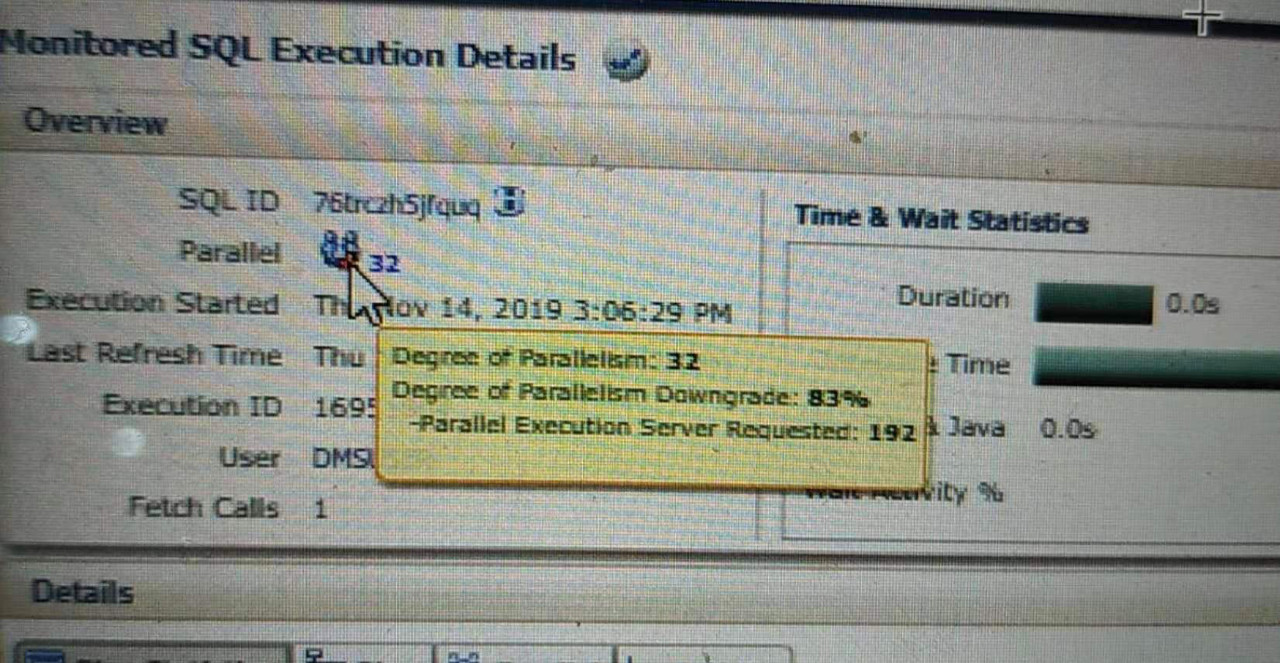
初始的并行度192比较抢眼,逻辑CPU为96,非常像自动并行时,数据库默认的并发度,当然数据库全库是肯定没开自动并行的。

在客户的带领下,确认了故障时段跟客户的描述是基本吻合的.单听描述,似乎是会话级别有调整并发的触发器或是与resource manager有关。
但这个是客户的核心生产系统,猜想的调整理论上应该不可能。通过快速的排查,证实了猜想不正确。
初步排查完,忍不住怀疑,客户描述是否有问题。顶级活动按照用户做了次过滤,突然发现,并不是用户级别有并行,很多XXX用户下运行的SQL并没有开并行,其实只是有一个SQL并发度很高。这也说明,初始的排查方向走偏了。
这个SQL文本是没有hint的指定并行的,结合观察到的信息,有点怀疑,想找应用确认下近期是否有改动。甲方的另外一个DBA斩钉截铁地说,肯定没改过,不单没改过,他还怀疑是ORACLE的bug。
当他说可能是BUG的时候,我都想去申请权限上机器上做个trace了,话说出口的前,还是问了下他,为什么怀疑是bug。他说了句让我决心写文章记录下这个CASE的话:“因为之前这种SQL执行异常,他都会用SQL_PROFILE去固定SQL的执行计划,而这次固定了之后,完全没效果”
竟然有SQLPROFILE?让我惊讶的是,我为什么忽略的SQLPROFILE/SQL BASELINE的排查。
原因主要是之前给他们系统做过优化,深知他们核心做变更的难度很大,往往是是加条索引都需要详细论证加索引带来的收益,以及可能带来的危害,先在测试,准生产环境验证逻辑读降低比例,再论证被影响的SQL有哪些,并描述对REDO的影响。
拿着这些材料再去跟开发team(嗯,外资企业),约时间开会,得到N多邮件确认后,再排期上生产(每周只有某一天的凌晨可以上生产),上完生产的第二天,需要驻厂观察,保障生产库安全。
按照我对他们流程的了解,这个SQLPROFILE的失察,我自己都差点要原谅我自己了。看了下SQL对应的执行计划,果然有个SQLPROFILE,而且还是SYS打头的,这种一般都是addm/sql tune出来的。
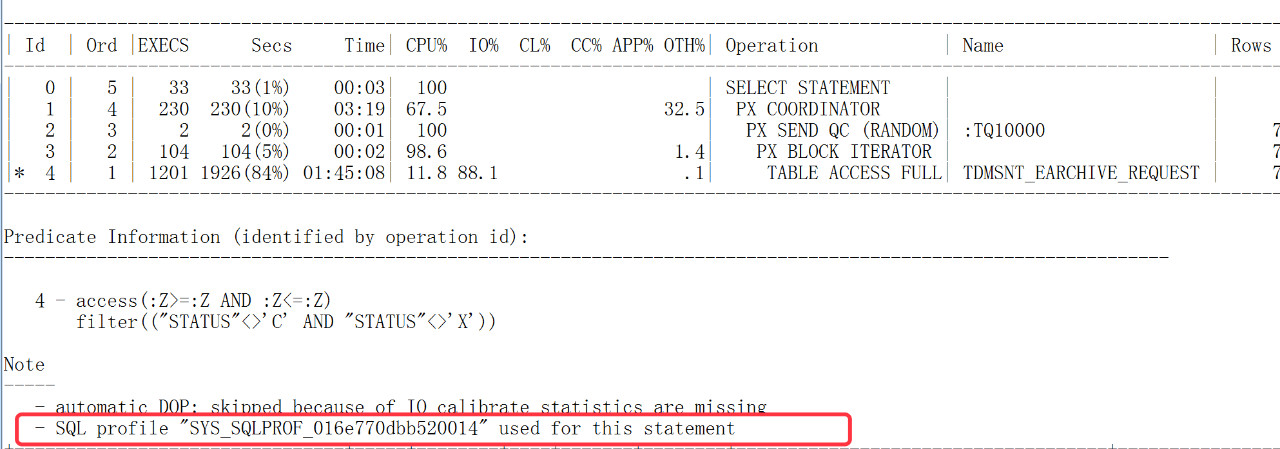
确认了这个,问题基本就定位出来了,马上验证下,果然是这个SYS的SQLPROFILE让SQL使用了高并行,并且让客户的DBA新生成的SQLPROFILE没生效,结合审计等信息,后面也确认了确实是甲方的另外一个DBA夜间运行了addm报告,并看到了报告给出的建议收益,非常诱人,于是快速采纳了建议,并休假了几天。
这个案例技巧上并不强,也有比较多的点值得反思,但我感触最深的是系统/数据库运维中对运维人员/DBA的运维行为的监管严重不足。而正是这种高权限又不受监管的运维频频带来故障,而且是相对难排查的故障,至少常常是甲方DBA自己难以定位处出来的故障。
历史的文章中都有不少这种案例,例如偷偷收集了系统统计信息的,加盘命令漏写的,改参数不重启,重启后出故障的等等。这种故障亡羊补牢的办法就是变成规则加入巡检当中,那有没有什么好的做法能料敌先机,防患于未然呢?有成熟的做法或是关注这类问题的朋友都欢迎在评论区交流。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721