
覃剑钊,香港大学博士,现任广发证券信息技术部资深工程师。
刘佳茜,广发证券实习生,中山大学在读硕士。
张汉林,广发证券信息技术部副总经理。
蒋荣,哥伦比亚大学博士、特许金融分析师(CFA),现任广发证券信息技术部总经理。曾任威灵顿管理公司(波士顿总部)董事总经理。
金融数据质量是金融公司提供服务的重要基础,也是公司正常运行的前提保障。随着移动互联网、大数据等金融科技的飞速发展,金融公司的数据量及多样性与日俱增。传统的数据质量监控方法与体系已无法满足现代证券公司数据质量监控的需求。
本文根据广发证券在智能化数据质量监控系统X-monitor的建设与运行经验,阐述一种智能化、自适应的多模金融数据质量监控实现路径。该系统利用自适应机器学习方法,将人工设定的数据质量监控规则与机器自学习生成的监控规则相结合,以提高金融数据质量监控的效率和准确度。系统同时支持监控模型的动态更新,以提高其动态适应性与灵活性。
关键字:数据质量监控;人工智能;机器学习;智能监控
一、引言
高质量的数据是金融证券公司提供服务、正常运行的前提基础。数据不稳定、缺失、异常等数据质量问题如果无法及时发现,将会导致证券公司在投资、理财、清算、风险管理、顾问等业务操作中出现问题,进而造成巨大的经济损失。
同时,随着大数据技术、人工智能技术在证券公司各项业务应用的不断深入,大量的系统、业务决策的正确性均需要依赖于高性能的数据质量监督与控制系统。
异常数据的产生原因是多样的,如供应商表结构变化导致后台应用读入不正确的数据、数据读取时意外中止导致的数据缺失等。异常数据的表现形式也有所不同,如数据缺失、数据准确度低、数据的一致性出现异常等。
一个完善的金融数据的质量监控系统需要针对各个数据类型、各种数据异常原因提出相应的解决方案。传统的数据监控模式需要开发人员和测试人员对不同数据制定不同的数据质量监控规则并编码实现,而面对海量的金融行情数据以及客户数据,这种人工监控方式不仅难以覆盖所有数据类型,还会消耗大量的人力和开发时间。同时人为制定的监控规则也会存在规则制定不合理,漏报、误报率高的缺点。
基于此,本文构建了一种智能化多模金融数据质量监控方法与系统实现方案。该方法提出一种适合于多类型金融数据的智能数据质量监控规则自生成以及自适应更新方法,以此最大限度的减少人工干预水平,提高数据监控效率与成功率。
另外,系统也支持人机结合模式,允许将人工设定的数据质量监控规则与机器自学习的监控规则相结合,以提高系统的灵活性和可控性。
本文分六章全面阐述了智能化多模金融数据质量监控的意义与系统实现方案。其中,第二章介绍了数据质量检测的意义及业内常用方法,第三章介绍了广发证券智能金融数据质量监控平台X-monitor的系统架构,第四章介绍了系统的具体实现方法,第五章中通过实验来验证本文提出的算法可行性以及系统实际应用效果。第六章进行总结和对未来工作的设想。
二、背景
对金融公司来说,高质量数据是公司业务正常运转的前提保障。例如,当数据的正确性与完整性缺失时,将会导致智能投资策略与客户投资建议等重要模块发生错误,进而导致客户投资发生损失。
当文本型数据如投资标的资讯、投资标的公告、产品说明等文本内容出现错误、缺失等异常时,将会影响到客户的投资决策,导致客户对公司的忠诚度下降。加强金融数据质量监控具有重大的意义,具体表现如下:
1)金融数据质量监控有助于提升证券公司数据治理水平的效率和质量
传统的数据监控模式需要耗费较多人力,且对开发人员与测试人员的业务经验有较强的依赖。这种监控模型会消耗大量的人力和开发时间,同时人为制定的监控规则也存在着规则制定不合理,漏报、误报率高等问题。
2)金融数据质量监控有助于提升证券公司各项业务水平及服务质量
目前证券公司的各条业务线数字化程度越来越高,传统经纪业务在向客户提供交易通道的同时,也向客户提供各种可交易证券的报价、新闻资讯等数据服务。
当前蓬勃发展的财富管理业务,包括基于大数据技术及人工智能技术的智能投顾业务均依赖于可靠稳定的行情数据及客户数据。证券自营业务、资管业务的量化交易系统也高度依赖数据产生投资决策。因此,一个高效、可靠的数据质量监控系统,可以提升证券公司各项业务线的业务水平及质量。
3)金融数据质量监控有助于提升证券公司对内的经营分析质量和风险控制质量
目前证券公司的经营分析与经营决策正快速向数据驱动型转变,分析与决策越来越依赖于大量的数据统计和分析结果,因此高度自动化、可靠的数据质量监控系统,将有助于提升证券公司的经营分析与决策水平。
风险控制是证券公司稳健经验的核心基础,而当前国际、国内成熟的风险控制模型无不依赖于大量的数据建模,因此高度自动化、可靠的数据质量监控系统,将有助于提升证券公司风险控制水平
随着各类大数据前沿技术的不断发展与在各应用的不断深入,各领域对数据质量的要求不断提高,数据质量监控的研究也成为业内的热门研究方向。
IBM提出一种数据质量监控的方法:
通过将加载数据的质量与预定的数据质量对比来实现数据监控;格泰科技有限公司提出一种数据质量网络监控管理产品。
该产品提供日常数据质量监控的信息采集、规则监控、问题告警、问题申告处理、质量报告、知识沉淀及任务调度等功能;集奥聚合科技公司提出的数据质量监控方法。
主要从四个方面实现:配置监控规则、传递监控规则、识别监控规则与输出监控数据;国家电网公司公开了一种电力大数据质量实时监控方法。
它将企业应用数据流实时输入并对数据流分批,采用DStreams与Spark分别完成流式计算与批处理执行转换、并使用Spark框架实现任务调度、内存管理和结果输出;江苏智通科技有限公司提出了一个包含监测模块、风险预警模块、数据核查模块、决策支持模块和参数配置模块的监测系统。
实现了对交通数据的质量监控。从业界近期公布的方法中,我们可以看到大数据分布式处理技术已经开始引入到数据监控系统中,然而数据监控规则的配置普遍仍然采用纯人工配置的方式,这种方式将无法满足证券公司日益增长的数据监控需求。
三、广发证券智能金融数据质量监控平台X-monitor概述
针对传统数据监控方法的不足,我们提出一种“平台化+智能化”的解决方案。该方案具有通用化、智能化、个性化的特点,可以及时、准确、高效的发现数据问题。其创新之处在于:
1)系统支持多项目管理、多类型数据源接入
具有灵活的监控调度,支持多种时间级别(分钟、小时、日、周等)监控调度和多层级报警,能够及时发现数据的隐患。
2)系统提供自学习监控策略自主生产监督规则
这不仅能够降低数据监控成本,还可以提高对数据异常问题监控的及时性与数据准确性。
3.系统支持智能数据一致性检测
金融数据的一致性检测是发现隐藏数据质量问题的重要手段之一。传统数据质量检测方法的实现需要人工对数据的取值范围、数据空缺等参数进行手工设置和编码,但人工设置数据检测规则很容易忽视数据之间的一致性,导致一些数据问题只看单一数据字段没法发现。
即便考虑了不同数据字段数据一致性的问题,传统方法需要人工指定待一致性检查的数据字段,然后再定义相应的规则并编码实现。当面对海量的金融行情数据、客户数据,人工指定数据字段进行一致性监控规则将消耗大量的人力。同时,人为设定待一致性检测数据字段需要设置人员具备丰富的业务经验,否则容易产生遗漏。
为了解决这些问题,我们的数据质量监控系统支持自动发现需要进行一致性检测的数据字段,并且具备自动学习数据一致性检测规则的能力。
4)系统支持数值、文本、图像等多模态数据。
平台运用文本处理、图像识别等技术对不同类型的待监控数据进行特征提取,将文本类数值、图像类等非结构化数据进行向量化,转化成结构化数据,再利用数值型数据自动监控规则生成与更新方法对向量化后的非结构化数据进行自动监控与规则更新。
图1展示了X-monitor界面。首界面除了展示当前的总任务数与成功率外,还给出了各监控项目的状态、任务名、任务类型、运行时间等信息,并允许监控人员对调用接口、监控方向进行调整与配置。
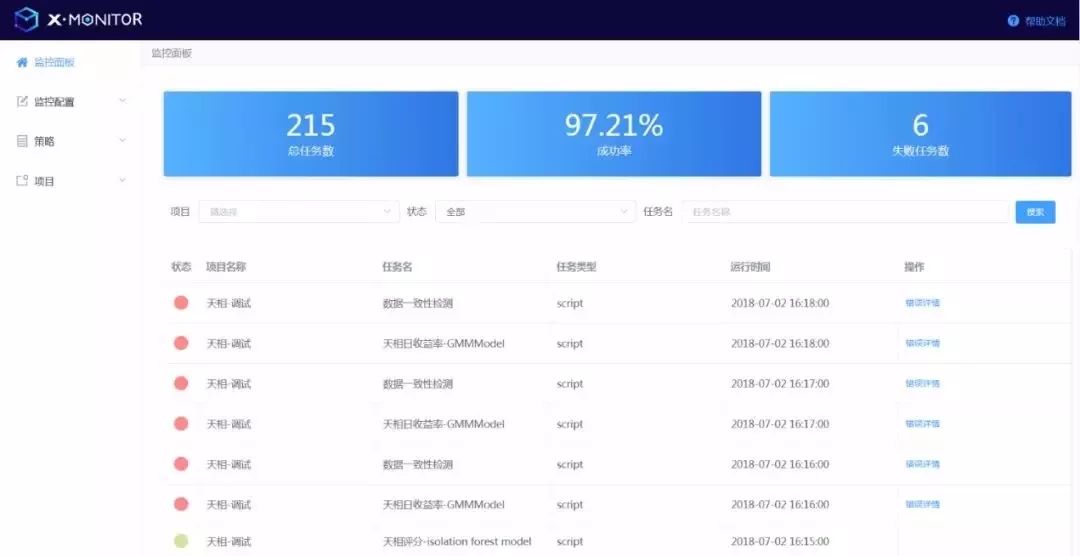
▲ 图1 智能金融数据质量监控平台(X-monitor)界面
X-monitor中的“策略”板块下展示了平台目前支持的智能策略。

▲ 图2 智能金融数据质量监控系统使用的模型
系统同时支持开发人员根据具体应用情景、反馈结果等信息对监控策略进行调整。如图3,在“策略”板块中,系统允许开发人员对不同智能策略的超参数进行设置。
▲ 图3 系统支付对智能策略的配置
四、智能金融数据质量监控系统实现
广发证券的智能数据监控系统X-monitor的主体架构如图4所示。
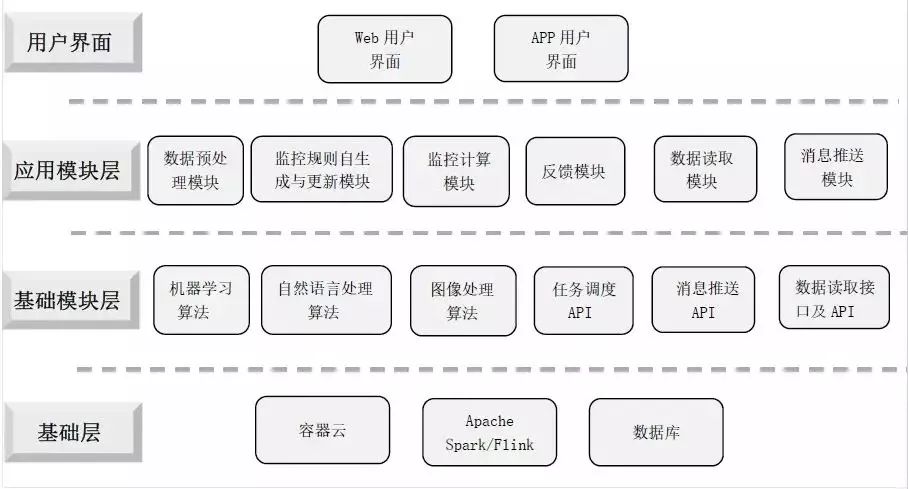
▲ 图4 系统架构图
基础层主要由容器云、基于Apache Spark/Flink的大数据计算平台及各类数据库组成。
其中,容器云具有可弹性扩展、容易维护、容易测试等特点,任务调度、消息推送、数据接口与数据API的监控计算任务、部分数据库数据的监控计算任务等后台应用通常运用容器云完成。
基于Apache Spark/Flink的分布式计算引擎通常负责分布式数据库数据的监控计算任务。而Mysql、Postgresql、Mongodb等各类数据库通常用于配置参数、系统参数、部分监控规则的存取。
基础模块层主要由机器学习算法、自然语言处理算法、图像处理算法、任务调度API、消息推送API、数据读取接口及API等通用模块组成。
机器学习算法模块为监控规则自学习功能提供基础机器学习算法支撑;
自然语言处理算法模块主要提供Word2vec、Fasttext、分词等常用自然语言处理算法,为文本数据的特征提取提供算法支撑;
图像处理算法模块主要为图像数据的向量化提供算法及模型基础;
任务调度API模块负责提供任务调动的常用接口;
消息推送API主要提供短信推送、微信推送、邮件推送等消息推送接口。
应用层由实现系统核心功能的主体模块组成。具体包括数据预处理、监控规则自生成与更新、监控计算、监控结果反馈、数据读取、消息推送等功能模块。
用户交互层主要实现Web端、移动App端的交互功能。
系统主体模块关系图如图5所示。
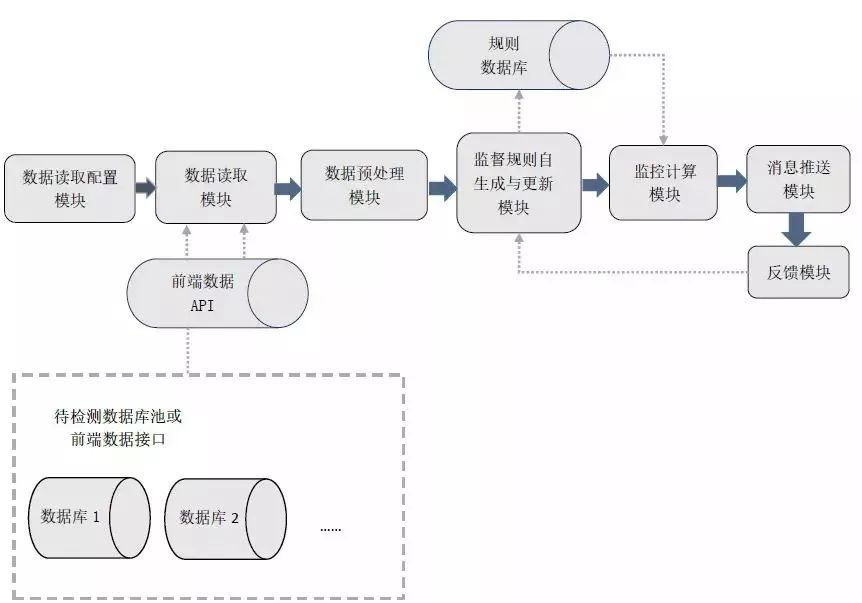
▲ 图5 系统主体模块关系图
金融数据质量监控系统的主体功能主要由以下模块组成:数据读取配置模块、数据读取模块、数据预处理模块、监控规则生成与配置模块、监控计算模块、消息推送模块、反馈模块。
数据读取配置模块对待监控数据的读取调用进行配置。该模块允许用户通过用户界面(如Web或移动App)对待监控数据的数据源或者待监控数据的前端读取接口进行配置,同时也可以支持用户输入符合系统设计标准的数据读取源代码进行数据读取。
当用户在用户界面设置完成并确认后,设置的内容将通过应用服务器将设置内容写入应用数据库,其中应用数据库可选取MySQL、PostgreSQL、MongoDB等。
数据读取模块实现对数据的读取。该模块根据已配置的读取方式对待监控数据、待监控数据的历史正常数据进行读取。数据读取模块根据用户输入的数据库类型、IP地址、用户、密码、待监控数据所在的数据表、表中字段名等参数对数据进行读取。
为了支持更丰富的数据读取方式,该模块也支持用户输入符合规范的数据读取代码模块以供计算服务单元调用获取数据。
数据预处理模块利用数据智能预处理层的策略对待监控数据进行处理。该模块将文本类、图像类、音频类等非结构化数据转化成结构化数值后,再标准化成生成监控规则所需要的数据格式。
同时该模块也需要自动筛选出强相关的数据字段对,为一致性检测提供待检测数据。
监控规则生成与配置模块将智能策略自动生成的监控规则与人工规则结合,以实现对监控规则库的不断更新与完善。
该模块在对智能监控规则模型的超参数进行配置后,利用标准化的待检测数据与选定的机器学习方法对监控规则进行自学习,或者根据更新的待检测数据对监控规则进行自动更新,最后将学习或更新后的监控规则存入规则数据库。
同时,该模块还支持人工对自生成的监控规则进行修改、调整或添加新的规则。由于机器学习产生的数据监控规则在历史正常数据较少的情况下,容易出现监控规则不够完善的情况,故此设计提高了系统的灵活性及适应性。
监控计算模块利用最终配置完成的监控规则对新增待监控数据进行计算,根据输出的结果判断该新增数据是否触发数据异常报警。
消息推送模块将输出的数据质量监控报警信息利用消息推送系统推送给客户,消息推送系统可包括微信、短信、应用App等渠道。
例如:App推送可通过MQTT、XMPP等协议实现,也可以调用阿里云移动推送、腾讯信鸽推送等第三方平台实现。
反馈模块负责接收运维人员对数据监控报警的反馈信息,并将该反馈信息反馈给监控规则生成与配置模块。数据开发、测试人员根据反馈结果对监控数据进行人工调整和优化。
如果反馈发出报警的信号为假信号,则需要反馈给监控规则生成与配置模块,根据具体原因及时进行监控规则调整。
1)数值型金融数据监控规则
金融产品行情收益率的分布通常可近似认为服从高斯模型或高斯混合模型。因此该类数据的监控规则可利用高斯模型、高斯混合模型来建立。一维数据的高斯模型数学表达式为:
$p(x)=\frac{1}{\sqrt{2\pi\delta ^{2}}}e^{-\frac{(x-\mu )^{2}}{z\delta ^{2}}}$
其中参数μ,δ 分别为训练数据的均值和标准差。多维数据的高斯混合模型的数学表达式为:
$p(x)=\sum _{i=1}^{K}\frac{\omega _{i}}{\sqrt{2\pi \sigma _{i}^2}}e^{(-\frac{(x-\mu _{i})^2}{z\sigma _i^2})}$
其中,$\sum _{i=1}^{K}\omega _i=1$,K为高斯模型的数目,$ω_i$,$μ_i$,$σ_i$分别为第i个高斯模型的权重、均值和标准差。这些参数可以利用历史正常数据,采用EM(Expectation Maximization)算法进行估计。
当待监控数据的分布模型未知时,可以采用One-Class SVM或Isolation Forest对待监控数据进行建模。One-Class SVM模型在异常数据检测中被广泛使用,它通过历史正常数据构造支撑超平面,以此判断待监控数据是否为正常数据。
Isolation Forest模型也是一种无需事先知道数据分布模型的方法,由于异常数据具有在生成树中经过的路径(即树的节点个数)较短的特点,Isolation Forest利用该特性实现异常数据的检测。
2)文本型金融数据监控规则
文本数据是金融数据的重要组成部分,这些数据包括投资标的相关新闻、投资标旳公告、金融产品说明以及金融公司内部文档交互等。这些文本数据是金融公司提供客户服务的重要基础,也是公司正常运行的重要基础。
要完成文本数据监控规则的自动生成,首先需要把文本数据映射成数值向量,然后利用上述数值型监控规则自动生成方法完成规则的生成。我们采用以下方法将文本向量化:
① 首先建立分词模型和词向量模型。
由于金融类文本包含了大量金融专业术语和独特的金融产品名称,采用通用分词模型容易导致文本分词结果错误。因此,在进行分词模型训练前,需要人工(或结合新词发现的方法)进行词库扩充。
完成词库扩充后,再利用更新后的词库进行分词模型的训练。常用的分词模型有隐马科夫(HMM),条件随机场(CRF)等模型。在进行词向量模型训练时需要采集wiki、金融资讯、金融公告等文本数据,并利用训练好的分词模型对这些文本数据进行分词。
得到文本数据的分词后,利用word2vec算法或Fasttext方法建立词向量模型。
其中,Fasttext中的词向量训练与word2vec相似,主要有两种方案:
一种是通过中心词w_t来预测周边词$w_{(t-2)}$,$w_{(t-1)}$,$w_{(t+1)}$,$w_{(t+2)}$,称为Skip-gram模型;
另一种是通过周边词$w_{(t-2)}$,$w_{(t-1)}$,$w_{(t+1)}$,$w_{(t+2)}$来预测中心词$w_t$,称为CBOW(Continuous Bag-Of-Words),即连续的词袋模型。
二者都是通过计算单词之间的共现关系来实现训练,即把相关词汇映射到词向量空间的模型。
② 得到训练好的分词模型后,需要用该模型对待监控历史文本数据进行分词,接着采用词向量模型把文本数据的分词结果映射到词向量空间。
③ 最后,系统将计算历史文本数据的词向量分布以形成文本数据的数值向量表达。得到文本数据的数值向量表达后,即可采用数值型监控规则自生成方法中采用的高斯模型、高斯混合模型、One-Class SVM等模型完成监控规则的自动生成。
3)图像数据监控规则
证券公司投资银行业务在对公司进行实地调研与持续督导过程中,通常会通过拍摄、复印、扫描等方式获取待调研待督导公司相关资料。公司本身也会通过图像方式(如证明材料的扫描件)来提交材料。
图像数据监控规则的自动生成首先需要把图像数据映射为数值向量,然后利用上述数值型监控规则自动生成方法完成规则的生成。
我们在系统实现中采用了以下方法完成图像数据向量化:
首先,将大量通用图像数据与证券行业特有图像数据相结合进行深度学习模型Autoencoder的训练。
然后,通过训练好的Autoencoder模型将图像数据映射到数值向量空间。
最后,采用数值型监控规则自生成方法中的高斯模型、高斯混合模型、One-Class SVM等模型完成监控规则的自生成。
4)智能数据一致性监控
数据内容的一致性指的是两个线性相关的数据字段的数据应该保持其线性相关性。
例如,当一只基金的评分越高时,其对应的评级也应该越好。由于金融数据体量庞大,人工设定需要进行一致性检测的字段是不现实的,所以我们提出一种自动发现需要进行一致性检测的数据字段的方法:
首先计算相关字段数据的协方差矩阵$Σ=E[(x-u)'(x-u)]$,得到字段数据间的相关性度量。其中,x为多数据字段数据组成的向量,u为这些向量的均值。
然后设置相关度的阈值,以筛选出强相关数据字段。完成字段对筛选后,利用一个字段对另一个字段的线性回归,计算出回归值与待检测值的差值。
最后利用数值型检测规则自生成中的高斯模型、高斯混合模型、One-Class SVM等模型对差值建立监控规则。
五、系统评估
为验证智能策略在数据监控中的性能,我们设计实验检验三种智能监控规则生成方法(GMM,Isolation Forest与One-Class SVM)对异常数据的检出效果。
实验选取天相基金数据作为数据集,抽取了100支基金,共20100个净值数据来训练各模型。实验根据各基金的数据分布情况模拟生成异常数据,将其标记后混入正常数据,用训练好的模型输出检测到的异常数据,以此比较各模型的检测性能。
测试过程中使用的评估指标包括召回率、准确率与F1值。
本实验主要分为两部分:各模型最优参数的确定与模型的对比。前者显示,各模型在其最优参数下对异常数据均有优秀的检测能力。
其中,One-Class SVM与isolation Forest的召回率与精确率均可达到100%,GMM效果相对逊色,但也达到了99.8%的召回率与100%的精确率。
为对比各模型对异常数据的检测能力,我们调整异常数据的生成方式以增大异常数据的甄别难度。
结果显示,One-Class SVM的综合表现最佳,它在数据检出率与时间效能上都表现突出,其次是GMM模型,它在F1值与isolation Forest相差无几的情况下具有更低的时间复杂度。
不过尽管One-Class SVM的表现相对较弱,其对异常数据的检测率仍然可达到令人满意的程度。模型对比的统计结果如下:

▲ 图6 三种模型在异常数据检测实验中的结果
具体数据如下表:
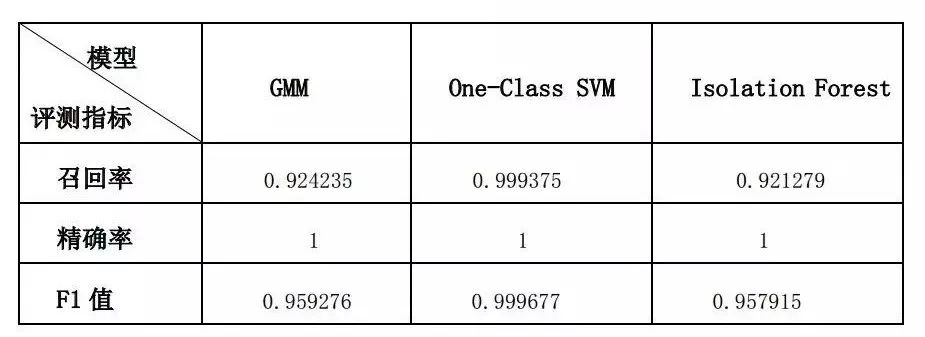
▲ 表1 实验结果
实验验证了三种模型在异常数据检测上的优越性能,进而证实了统计模型及机器学习模型用于监控规则生成的可行性,模型生成与更新的高效性更为海量金融数据的处理带来了便利。
目前平台在广发证券贝塔牛、广发证券财富管理平台、交易测试柜台等系统中进行了监控测试,运行了上千次监控任务。初步验证了平台的有效性与实用性。
▲ 图7 广发证券X-monitor平台应用于贝塔牛、财富管理平台等项目
六、结论与展望
对金融数据的分析处理一直是金融证券公司提供服务的重要基础。随着大数据技术与人工智能在证券公司的不断拓展应用,金融数据的质量监控成为维系公司业务正常运行的前提保障。
本文针对金融数据的质量监控,根据广发证券智能数据监控平台X-monitor的实现路径,介绍了一套“平台化+智能化”的解决方案。
最终搭建的监控平台不仅支持对数据库进行实时数据监控,也允许配置API支持与大部分周边系统的对接。与传统的人工设置监控规则不同,该平台利用机器学习方法,将智能监控策略与人工规则结合。
这不仅降低了数据监控成本,更提高了对异常数据的监控及时性与准确性。从测试与运行结果来看,该平台具有明显的有效性与实用性。
尽管本文构建的金融数据质量监控系统在性能上已经取得不错的成效,但随着数据规模与复杂度的不断提升,金融公司中各业务对数据质量要求也在不断提高。后续工作中,我们将继续提高平台的智能化水平。
本文目前仅在数据质量的监控规则建立时利用人工智能技术,未来将考虑将智能策略融入数据监控的其他方面,如数据的自动平稳化、数据地图的自动生成、异常数据源的智能定位等方向。
参考文献
[1] M·奥伯霍菲尔,J·塞弗特,Y·赛勒特,S·尼尔克. 用于数据质量监控的系统和方法.欧洲专利:201210225743X. 2013-01-02.
[2] 何万军. 一种数据质量网络监控管理产品. 中国专利:2015108035291,2017-05-31
[3] 何良均,张翼等. 一种数据质量监控的方法及系统. 中国专利:2016108322820, 2017-02-15
[4] 魏智博等, 一种电力大数据质量实时监控方法, 中国专利: 2016104937192,2018-01-05
[5] 吕伟韬等, 交通数据质量监控系统, 中国专利:2016108051886,2017-01-25
[6] Krizhevsky A, Hinton G E. Using very deep autoencoders for content-based image retrieval.[C]. the european symposium on artificial neural networks, 2011
注:本文选自《交易技术前沿》总第三十三期文章(2018年12月)广发证券股份有限公司
作者:覃剑钊、刘佳茜、张汉林、蒋荣
来源:上交所技术服务(ID:SSE-TechService)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721