
15 年前,GitHub 从一个使用一个 MySQL 数据库的 Ruby on Rails 应用程序起步。从那时起,GitHub 不断的演进着 MySQL 架构,以满足平台的扩展和弹性需求,包括构建高可用性、实施自动化测试和数据分片。如今,MySQL 仍是 GitHub 基础架构的核心部分,也是我们首选的关系型数据库。
以下是我们如何将 1200 多台 MySQL 主机从 5.7 版本升级到 8.0 的故事。在不影响我们 SLO 的情况下升级集群并非易事——规划、测试和升级本身就花费了一年多的时间,并且需要 GitHub 内部多个团队的通力协作。
一、升级的动机
为什么要升级到 MySQL 8.0?随着 MySQL 5.7 的生命周期即将结束,我们将我们的集群升级到了下一个主要版本 MySQL 8.0。我们还希望使用能够获得最新安全补丁、错误修复和性能增强的 MySQL 版本。我们还想测试 8.0 中的一些新功能并从中受益,包括在线 DDL、隐藏索引和压缩的 binlogs 等。
二、GitHub 的 MySQL 基础设施
在我们深入了解如何进行升级之前,让我们先从 10,000 英尺的高度看一下我们的 MySQL 基础设施:
我们的集群由 1200 多台主机组成。它是我们数据中心中的 Azure 虚拟机和裸机主机的组合。
我们存储超过 300 TB 的数据,并在 50 多个数据库集群中每秒处理 550 万次查询。
每个集群都配置了高可用的主备。
我们的数据是分片的。我们利用水平和垂直分片来扩展 MySQL 集群。我们有 MySQL 集群来存储特定产品领域的数据。我们还为大业务提供了水平分片的 Vitess 集群,这些业务的增长超出了单主 MySQL 集群的规模。
我们拥有一个庞大的工具生态系统,包括 Percona Toolkit、gh-ost、orchestrator、freno 和用于操作集群的内部自动化系统。
所有这些总结起来就是一个多样化且复杂的部署,需要在维护我们的 SLO 的同时进行升级。
三、准备工作
作为 GitHub 的主要数据存储,我们对可用性保持高标准。由于我们的集群规模和 MySQL 基础设施的重要性,我们对升级过程提出了一些要求:
我们必须能够升级每个 MySQL 数据库,同时遵守我们的 SLO 和 SLA。
我们无法在测试和验证阶段发现所有的潜在故障。因此,为了 SLO,我们需要能够回滚到之前的 MySQL 5.7 版本而不中断服务
我们 MySQL 集群中的工作负载非常多样化。为了降低风险,我们需要原子化地升级每个数据库集群,并穿插安排其他重大更改。这意味着升级过程将相当漫长。因此,我们从一开始就知道我们需要能够维持运行混合版本的环境。
升级准备工作于 2022 年 7 月开始,即使在升级第一个生产数据库之前,我们也需要实现几个里程碑。
我们需要为 MySQL 8.0 确定适当的默认值并执行一些基准性能测试。由于我们需要操作两个版本的 MySQL,因此我们的工具和自动化需要能够处理混合版本,并了解 5.7 和 8.0 之间新的、不同的或已弃用的语法。
我们将 MySQL 8.0 添加到了所有使用 MySQL 的应用程序的持续集成 (CI) 中。我们在 CI 中并行运行 MySQL 5.7 和 8.0,以确保在长时间的升级过程中不会出现 regression。我们检测到 CI 中的各种错误和不兼容性,帮助我们删除任何不再支持的配置或功能,并转义任何新的保留关键字。
为了帮助应用程序开发人员过渡到 MySQL 8.0,我们还启用了一个选项,可以在 GitHub Codespaces 中选择 MySQL 8.0 预构建容器进行调试,并提供 MySQL 8.0 开发集群以进行额外的预生产测试。
我们使用 GitHub Projects 创建滚动日历来在内部沟通和跟踪我们的升级计划。我们创建了问题模板来跟踪业务团队和数据库团队的清单,以协调升级。
四、升级计划
为了满足我们的可用性标准,我们采取了逐步升级策略,允许在整个过程中进行 checkpoint 和回滚。
我们首先升级单个副本并在其仍处于离线状态时进行监控,以确保基本功能稳定。然后,我们导入生产流量并继续监控查询延迟、系统指标和应用程序指标。我们逐渐将 8.0 副本上线,直到升级整个数据中心,然后继续升级其他数据中心。我们在线上保留了足够的 5.7 副本以便回滚,但我们不再导入生产流量,而是由 8.0 接管所有只读流量。
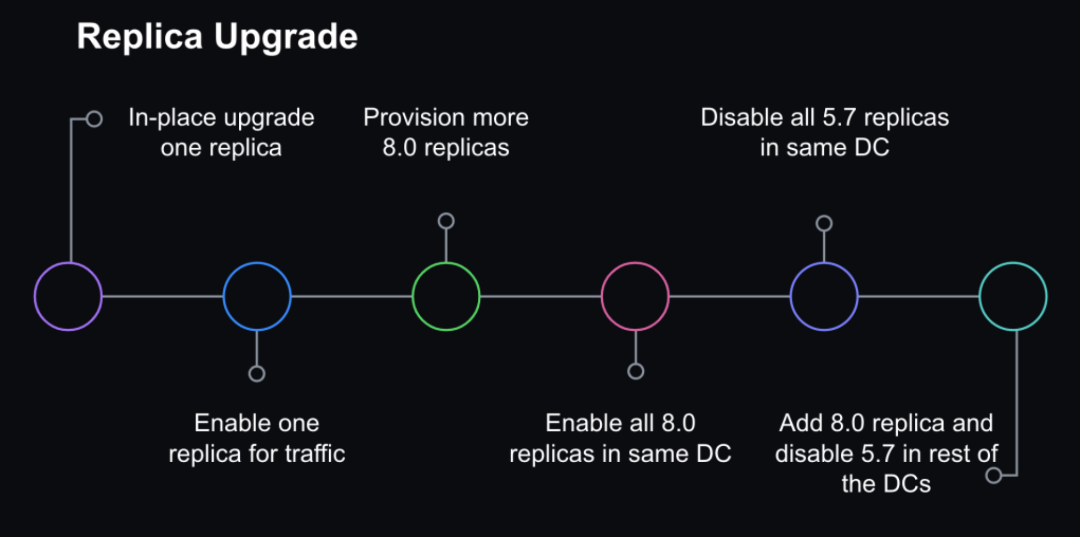
一旦所有只读流量都通过 8.0 副本提供服务,我们就调整了复制拓扑,如下所示:
8.0 主候选,配置为直接在当前 5.7 主下复制。
在该 8.0 副本的下游创建了两个复制链:
一组仅 5.7 个副本(不提供流量,但已准备好以防回滚)。
一组仅 8.0 副本(服务流量)。
拓扑仅在很短的时间内(最多几小时)处于这种状态,直到我们进入下一步。
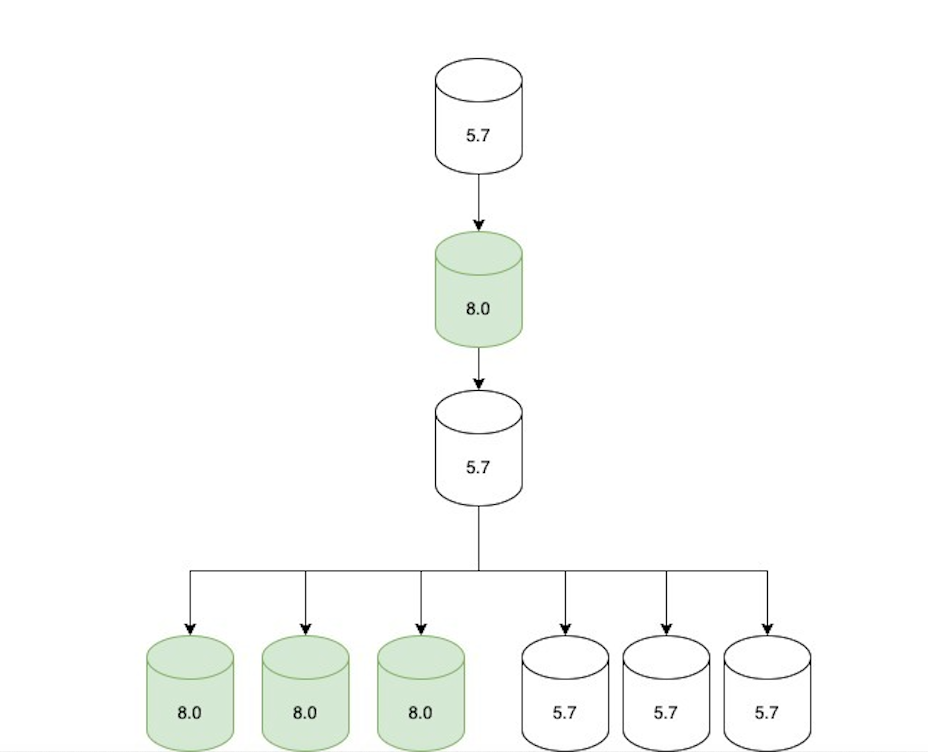
我们选择不在主数据库主机上进行直接升级。相反,我们将通过使用 Orchestrator, 执行 grace failover 将 MySQL 8.0 副本提升为主。此时,复制拓扑由一个 8.0 主数据库和两个附加到其上的复制链组成:一组用于回滚的离线 5.7 副本和一组提供在线服务的 8.0 副本。
Orchestrator 还配置为将 5.7 主机列入黑名单,防止其成为潜在的 failover 候选者,以防止在发生计划外 failover 时意外回滚。
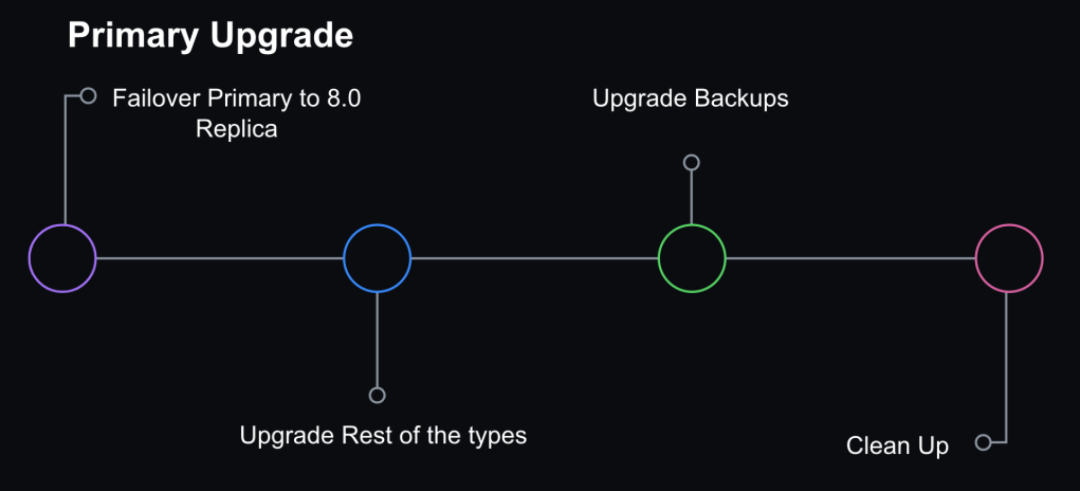
我们还有用于备份或非生产工作负载的 MySQL。这些也在后续被升级以保持一致性。
一旦我们确认集群不需要回滚并成功升级到 8.0,我们就删除了 5.7。验证包括至少一个完整的 24 小时流量周期,以确保在高峰流量期间不会出现问题。
五、回滚能力
确保升级策略安全的核心部分是保持回滚到 MySQL 5.7 版本的能力。对于只读副本,我们确保有足够的 5.7 副本保持在线状态来服务生产流量负载,如果 8.0 副本性能不佳,则通过禁用它们来启动回滚。对于主服务器,为了在不丢失数据或不中断服务的情况下回滚,我们需要能够维持从 8.0 复制数据到 5.7 的兼容性。
MySQL 支持从一个版本到下一个更高版本的复制,但不明确支持反向操作。当我们在临时集群上测试将 8.0 主机升级为主主机时,我们发现所有 5.7 副本上的复制都中断了。我们需要克服几个问题:
在 MySQL 8.0 中,utf8mb4 是默认字符集,并使用更现代的 utf8mb4_0900_ai_ci 排序规则作为默认值。MySQL 5.7 的早期版本支持 utf8mb4_unicode_520_ci 排序规则,但不支持最新版本的 Unicode utf8mb4_0900_ai_ci。
MySQL 8.0 引入了管理权限的角色,但 MySQL 5.7 中不存在此功能。当 8.0 实例变为集群中的主实例时,我们遇到了问题。我们的配置管理正在扩展某些权限集以包含角色语句并执行它们,这破坏了 5.7 副本中的下游复制。我们通过在升级窗口期间临时调整受影响用户的定义权限来解决此问题。
为了解决字符排序规则不兼容的问题,我们必须将默认字符编码设置为 utf8,将排序规则设置为 utf8_unicode_ci。
对于 GitHub.com 整体,我们的 Rails 配置确保了字符排序规则的一致性,并使数据库的客户端配置标准化变得更加容易。因此,我们非常有信心能够为最关键的应用程序维持向低版本的复制兼容性。
六、遇到的挑战
在我们的测试、准备和升级过程中,我们也遇到了一些技术挑战。
我们使用 Vitess 来水平分片关系数据。在大多数情况下,升级我们的 Vitess 集群与升级 MySQL 集群没有太大区别。我们已经在 CI 中运行 Vitess,因此我们能够验证查询兼容性。在我们的分片集群升级策略中,我们一次升级一个分片。VTgate(Vitess 代理层)通告 MySQL 的版本,某些客户端行为取决于此版本信息。例如,一个应用程序使用的 Java 客户端禁用了 5.7 服务器的查询缓存,因为查询缓存在 8.0 中被删除,因此它会报错。因此,一旦单个 MySQL 主机针对给定的键空间进行了升级,我们就必须确保我们还更新了 VTgate 设置以通告 8.0。
我们使用只读副本来扩展读可用性。GitHub.com 需要低复制延迟才能提供最新数据。
在我们的早期测试中,我们遇到了 MySQL 中的复制错误,该错误已在 8.0.28 上修补。
由于这个错误已经在上游修复,我们只需要确保部署高于 8.0.28 的 MySQL 版本即可。
我们还观察到,导致复制延迟的大量写入在 MySQL 8.0 中更加严重。这使得我们避免大量写入变得更加重要。在 GitHub,我们使用 freno 根据复制延迟来对限流写请求。
我们知道我们不可避免地会在生产环境中遇到新问题,因此我们采取了逐步升级副本的策略。我们遇到过已经通过 CI,但在生产环境中遇到实际工作负载时会失败的查询。最值得注意的是,我们遇到了一个问题,即带有大型 WHERE IN 子句的查询会使 MySQL 崩溃。我们有包含数万个值的大型 WHERE IN 查询。在这些情况下,我们需要在继续升级过程之前重写查询。查询采样有助于跟踪和检测这些问题。在 GitHub,我们使用 Solarwinds DPM (VividCortex)(一种 SaaS 数据库性能监视器)来实现查询可观察性。
七、经验和教训
从测试、性能调整到解决已发现的问题,整个升级过程花费了一年多的时间,并涉及来自 GitHub 多个团队的工程师。我们将整个集群升级到 MySQL 8.0,包括临时集群、支持 GitHub.com 的生产集群以及支持内部工具的实例。此次升级凸显了我们的可观察性平台、测试计划和回滚能力的重要性。测试和逐步升级策略使我们能够及早发现问题并减少主要升级遇到新故障类型的可能性。
虽然有逐步升级的策略,但我们仍然需要能够在每一步进行回滚,并且需要可观察性来识别信号以指示何时需要回滚。启用回滚最具挑战性的方面是保持从新的 8.0 主副本到 5.7 副本的复制兼容性。我们了解到,Trilogy 客户端库中的一致性使我们在连接行为方面具有更高的可预测性,并使我们确信来自主 Rails 应用的流量不会破坏兼容性。
然而,对于我们的一些 MySQL 集群来说,这些集群具有来自不同框架/语言的多个不同客户端的连接,我们发现向复制兼容性在几个小时内就被打破了,这缩短了回滚的机会窗口。幸运的是,这些情况很少,而且我们没有遇到在需要回滚之前复制中断的情况。但对我们来说,这是一个教训,即了解已知且易于理解的客户端连接配置是有好处的。它强调了制定指导方针和框架以确保此类配置的一致性的价值。
之前对数据进行分片的努力得到了回报——它使我们能够针对不同的数据域进行更有针对性的升级。这很重要,因为一个失败的查询会阻止整个集群的升级,并且对不同的工作负载进行分片允许我们进行零碎升级并减少在此过程中遇到的未知风险的影响范围。为此付出的代价是,我们 MySQL 集群的增长。
上次 GitHub 升级 MySQL 版本时,我们有 5 个数据库集群,现在我们有 50 多个集群。为了成功升级,我们必须投资可观察性、工具和集群管理的建设。
总结
MySQL 升级只是我们必须执行的一种日常维护工作——对于我们在集群上运行的任何软件来说,拥有一个升级路径至关重要。作为升级项目的一部分,我们开发了新的流程和操作能力来成功完成 MySQL 版本升级。然而,我们在升级过程中仍然有太多需要手动干预的步骤,我们希望减少完成未来 MySQL 升级所需的工作量和时间。
我们预计,随着 GitHub.com 的发展,我们的集群将继续增长,并且我们的目标是进一步对数据进行分片,这将随着时间的推移增加 MySQL 集群的数量。构建操作任务的自动化和自我修复功能可以帮助我们在未来扩展 MySQL 操作。我们相信,只有投资可靠的集群管理和自动化,才能使我们能够扩展 GitHub, 并跟上所需的维护,从而提供更具可预测性和弹性的系统。
该项目的经验教训为我们的 MySQL 自动化奠定了基础,并为将来在保持服务能力的前提下,更高效地进行升级,铺平道路。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721