
和大家分享前段时间一个凌晨的真实案例,这篇文章也是我事后临时写出来的,处理事情的过程有点无语,又有点气愤!
事情的背景是这样的:一个朋友今年年初新开了一家公司,自己是公司的老板,不懂啥技术,主要负责公司的战略规划和经营管理,但是他们公司的很多事情他都会过问。手下员工30多人,涵盖技术、产品、运营和推广,从成立之初,一直在做一款社交类的APP。平时,我们一直保持联系,我有时也会帮他们公司处理下技术问题。
今天凌晨,我被电话铃声吵醒了,一看是这个朋友打来的,说是他们公司数据库服务器CPU被打满了,并且一直持续这个状态,他说拉个群,把他们后端Java同事拉进来一起沟通下,让我帮忙看看是什么问题,尽快处理下。说话语气很急,听的出来事态很严重,因为目前正在加大力度推广,周末使用人数也比较多,出现这种问题着实让人着急。
后面我加了那个朋友拉的微信群,开始了解服务器出现问题的具体情况,下面就是一些处理的经过了。
注:聊天内容已经获得授权公布。
他们后端Java把运维发的监控截图发出来了,咱继续跟他沟通。
为啥我说CPU占用高呢?大家看下他们运维发的图就知道了。
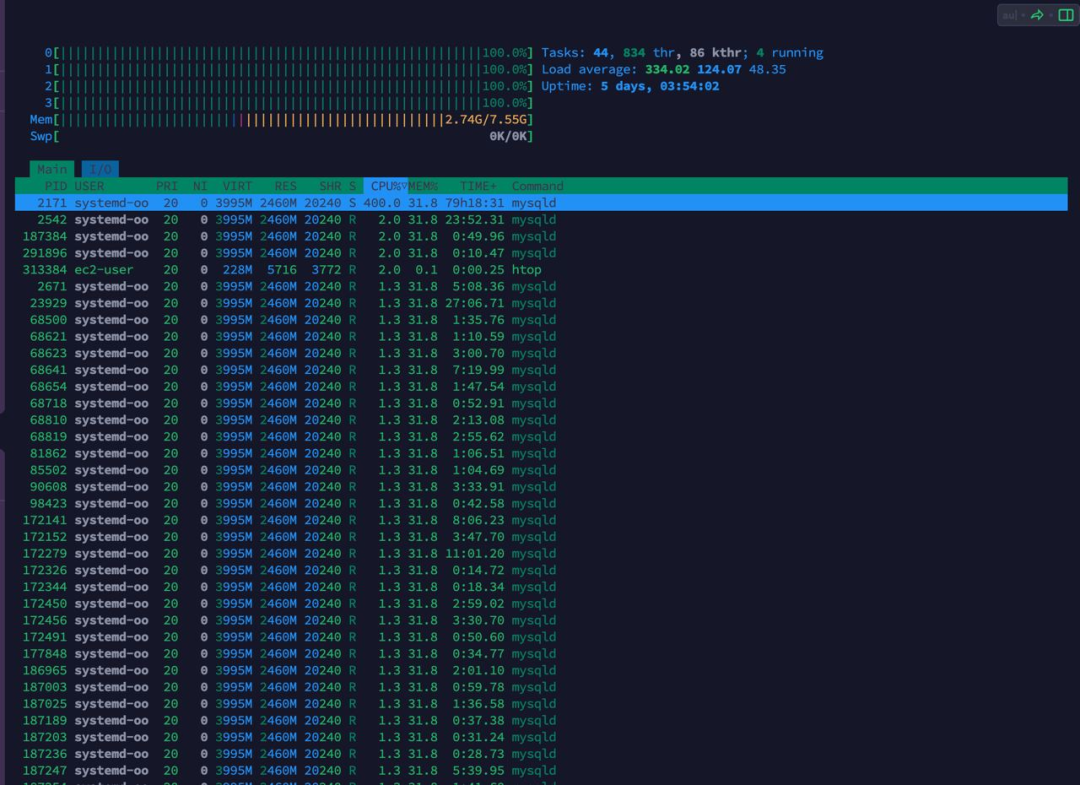
CPU已经飙升到了400%了,数据库服务器基本已经卡死。拿到他给我发的SQL后,我跟他们老板要了一份他们的数据库表结构,在我电脑上执行了下查询计划。
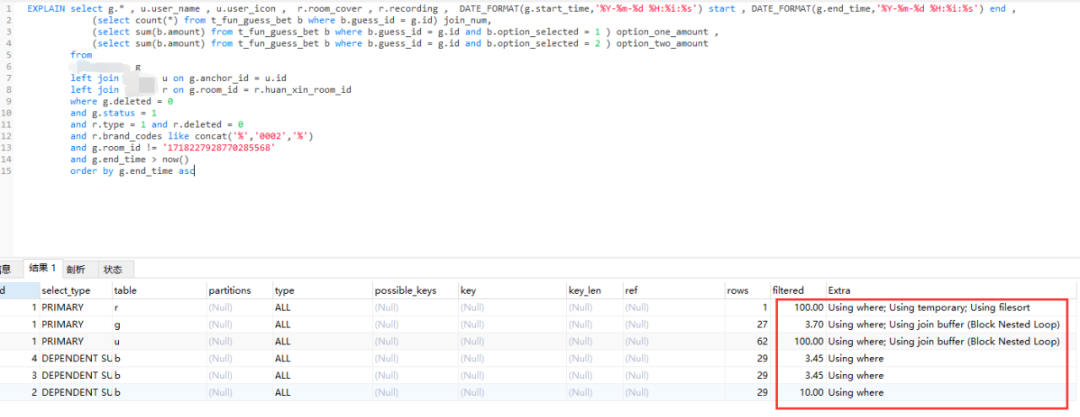
这不看不知道,一看吓一跳,一个C端频繁访问的接口SQL性能极差,Using temporary、Using filesort、Using join buffer、Block Nested Loop全出来了。
我把这个图发出去了,也结合他们团队的实际情况,给出了优化的目标建议:SQL中不要出现Using filesort、Block Nested Loop,尽量不要出现Using join buffer和Using temporary,把Using where尽量优化到Using Index级别。
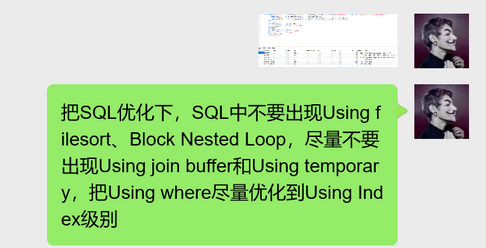
说是尽量不要出现Using join buffer和Using temporary,把Using where尽量优化到Using Index级别,就是怕他们做不到这点,优先把Using filesort、Block Nested Loop优化掉。但是这货后面说的话实属把我震惊到了。
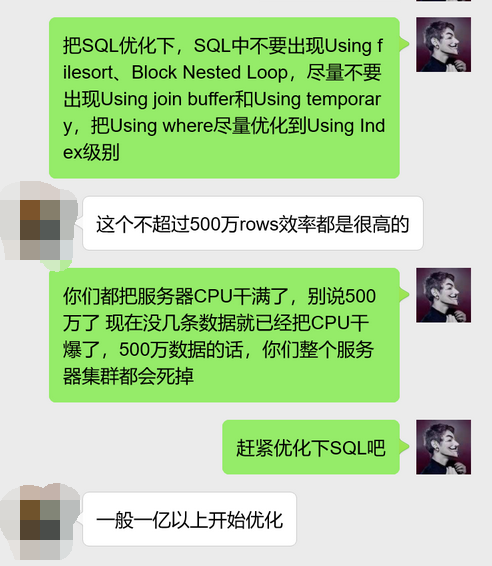
我看完他的回复,直接有点无语:卧槽,不超过500万rows效率很高?你这SQL 500万数据效果很高?更让我无语的是这货说MySQL一般一亿以上数据量开始优化,这特么不是完全扯淡吗?他说这话时,我大概就知道这货的水平了……
后面我就问他说的这些数据的依据是哪里来的。
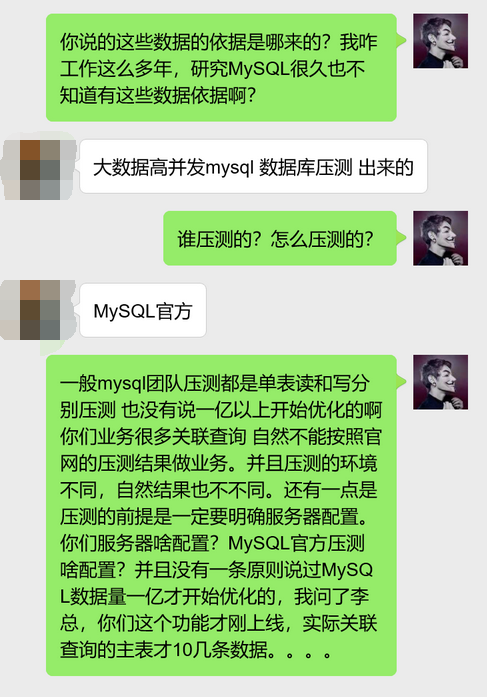
这货说是什么大数据高并发MySQL数据库压测出来的,稍微有过压测经验的应该都知道,压测一个很重要的前提就是要明确压测的环境,最起码要明确压测环境服务器的CPU核数和内存,直接来句MySQL一亿数据是大数据高并发MySQL数据库压测出来的结果,这还是MySQL官方的数据……
不知道是不是因为群里有他们老板的缘故,这货后面还在狡辩。
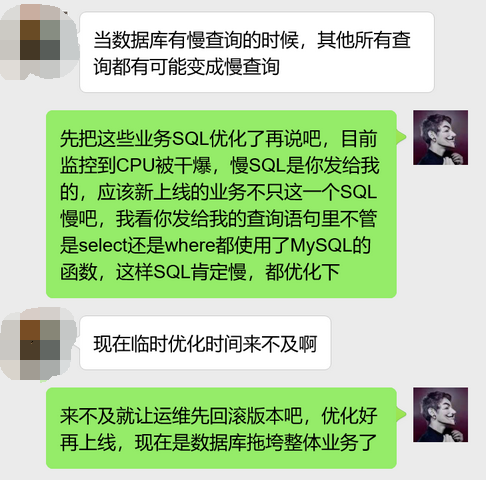
沟通到这里,我特么有种想打人的冲动,生产环境所有业务快被数据库拖死了,数据库服务器CPU被干爆了,监控到慢SQL,并且查看这些慢SQL的执行计划,性能非常低下,SQL里不管是select部分还是where部分大量使用了MySQL自带的函数,这不慢才怪啊。看这货处理问题的态度,要是我下面的人,早就让他卷铺盖走人了。
后续我跟他们老板要了一个代码只读权限的账号,将代码拉取下来后,好家伙,到处都是这种SQL查询,要是一两处还好,把SQL修改并优化下,关联的业务逻辑调整下,再把功能测试下,接口压测下,没啥问题就可以发版上线了。
但是,如果到处都是这种SQL的话,那优化SQL就要花费一定的时间了,甚至是新发布的重大功能逻辑都要重写。最终,我跟他们老板说的是回滚版本吧,最新的功能还是先下线,把新功能的SQL、缓存、业务逻辑、接口都优化好,压测没问题后再重新上线。
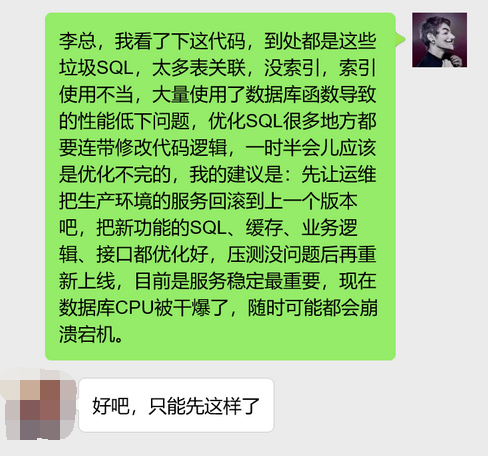
无论什么时候,生产环境一旦出现致命问题,第一时间要优先恢复生产环境正常访问,随后再认真排查、定位和解决问题,毕竟生产环境一旦出现问题,每一秒流失的都是真金白银。
搭建技术团队一定要找靠谱的人,最起码团队的核心人员要靠谱,像我朋友团队的这个技术,在他的认知里,MySQL执行计划出现Using temporary、Using filesort、Using join buffer、Block Nested Loop,500W rows效率都很高,殊不知他们生产环境实际主表数据才10几条,要是真达到500W量级就别查询了,数据库直接就趴下了。还有这个MySQL一般一亿以上开始优化,这个依据我也不知道这货是从哪里看到的,并且还说了大数据高并发MySQL数据库压测出来的,这不纯属扯淡吗?
更离谱的是我事后悄悄问了他们老板,他的工作年限是多久,据说工作10多年了,是位80后。
顿时让我想到了一句话:人的认知有几个层次:不知道自己不知道,知道自己不知道,知道自己知道,不知道自己知道。
最后,大家对这次事件有什么看法,欢迎评论区留言讨论。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721