

这里在MYSQL5.6,MYSQL.5.7上大部分的表还都是 utf8 , default charset =utf8 而在这些数据库升级的情况下,表基本上是照搬到MYSQL 8.0上的,但是后续会产生一个问题。建立新的表。此次我们采用MYSQL 最新的版本之一,MYSQL 8.030 来进行相关的问题的分析和查找。
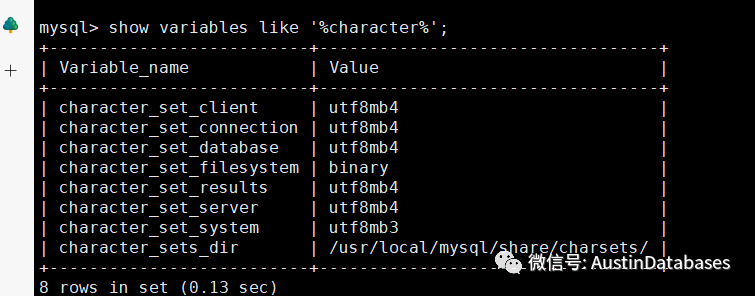
下面就是一个典型的例子,在创建一个MYSQL的表的情况下,如果开发部指定 default charset=utf8 则默认建立新表就是utf8mb4 ,而这样就会产生一个严重的问题。
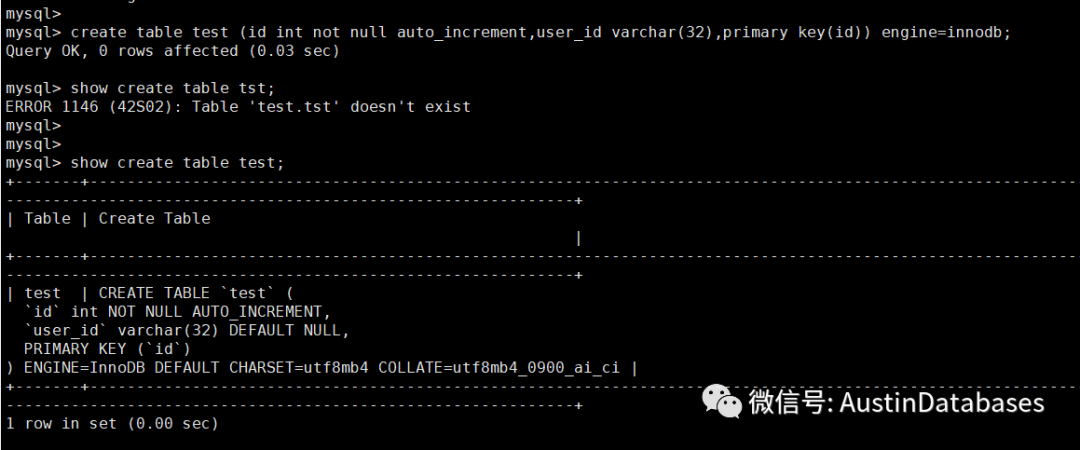
一个数据库中的表的字符集不一致。然后就会产生一个问题,两个表的字符集不同,如果两个表之间的查询是不关联的,这到不会造成什么严重的问题,而如果这两个表产生了之间的关联性那么问题就出现了。
我们创造一个奇怪的数据库,以及表,这里的表的字符集在 utf8 和 utf8mb4 之间混合着。
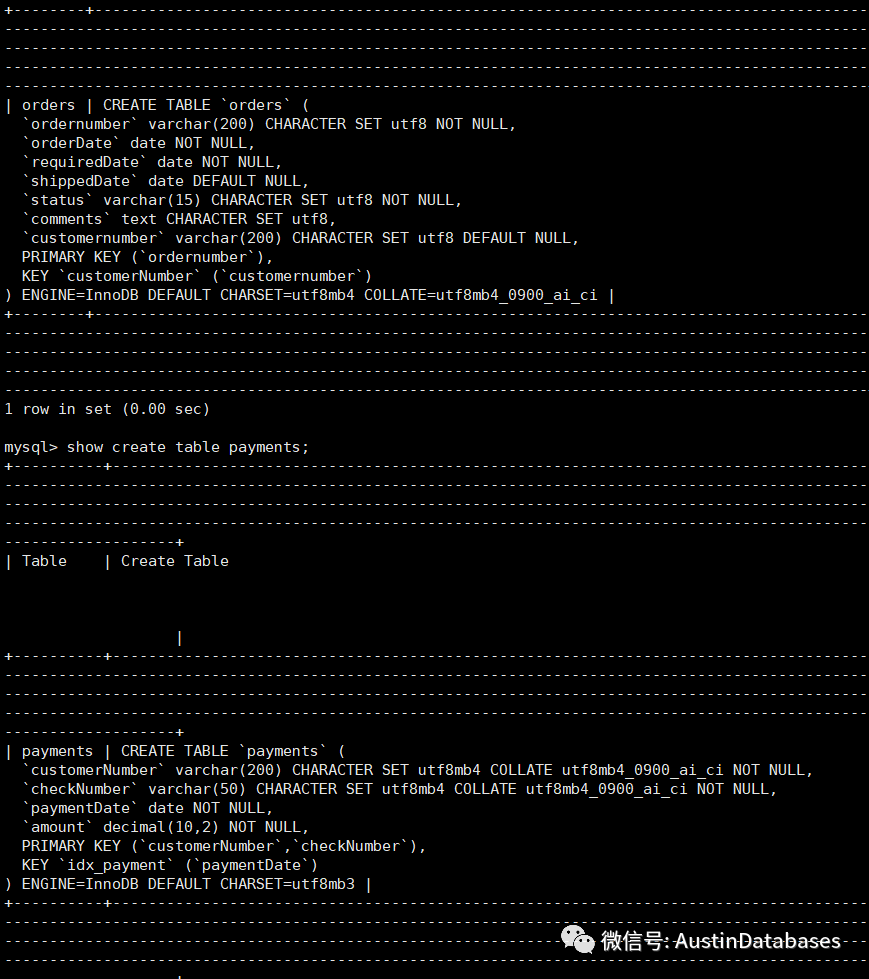
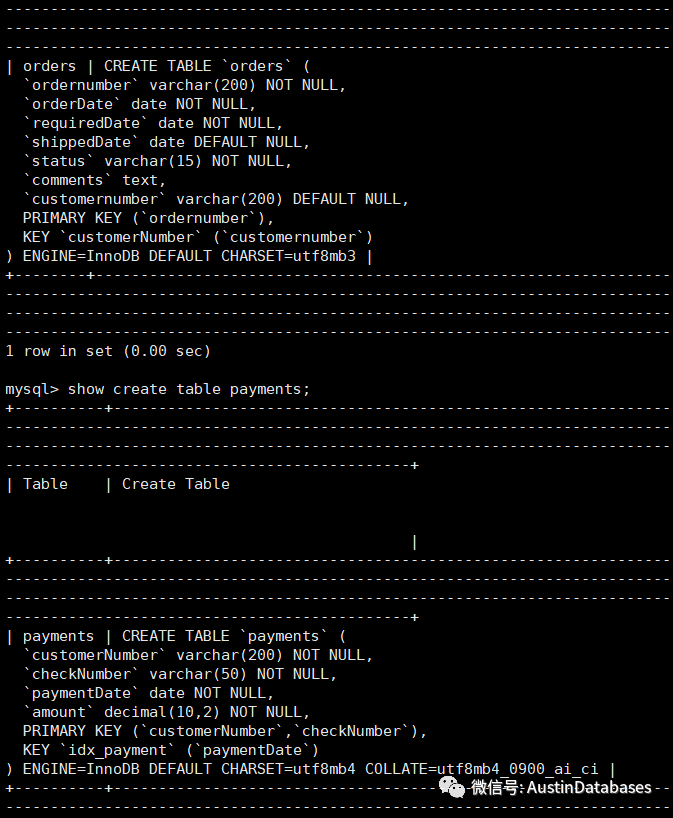
在这样的情况下,会产生如下一些假设,下面是一些表的表结构,其中orders的表,是UTF8MB4 格式 排序是 utf8mb4_9000_ai_ci ,而我们的payments表是utf8mb3 的格式。
CREATE TABLE `orders` (`ordernumber` varchar(200) CHARACTER SET utf8 NOT NULL,`orderDate` date NOT NULL,`requiredDate` date NOT NULL,`shippedDate` date DEFAULT NULL,`status` varchar(15) CHARACTER SET utf8 NOT NULL,`comments` text CHARACTER SET utf8,`customernumber` varchar(200) CHARACTER SET utf8 DEFAULT NULL,PRIMARY KEY (`ordernumber`),KEY `customerNumber` (`customernumber`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE TABLE `payments` (`customerNumber` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`checkNumber` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`paymentDate` date NOT NULL,`amount` decimal(10,2) NOT NULL,PRIMARY KEY (`customerNumber`,`checkNumber`),KEY `idx_payment` (`paymentDate`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
1 使用 left join 的时候,两个表,谁在前谁在后,优化器是否能正确运行相关结果。
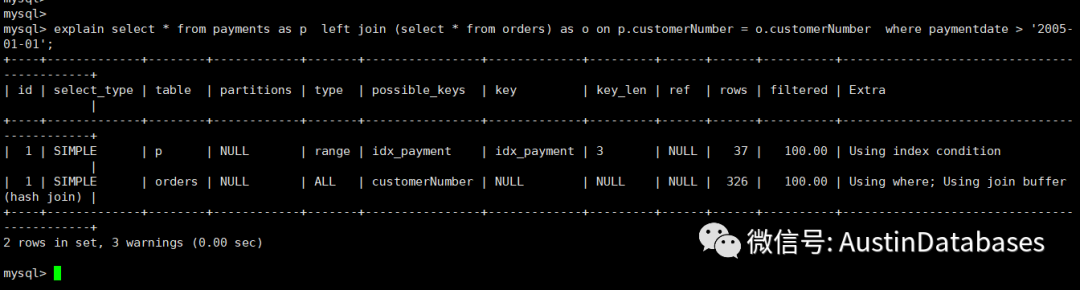
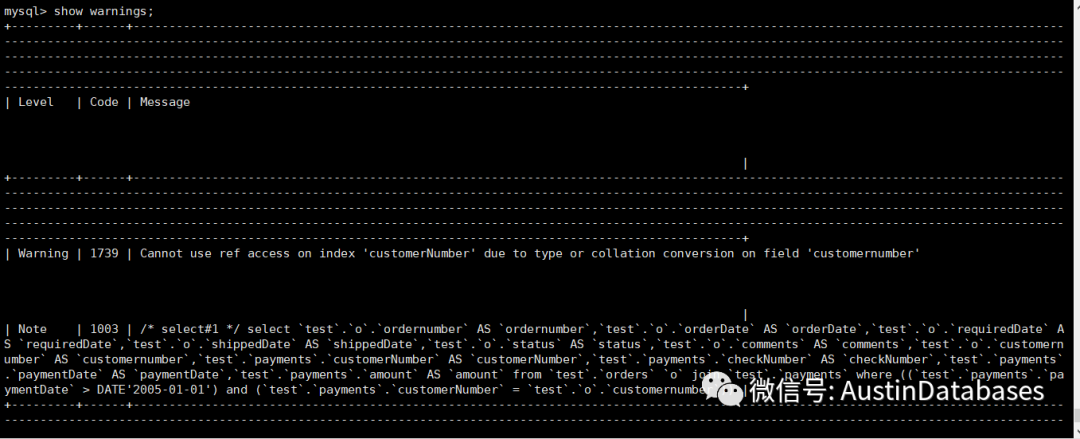
explain select *from payments as pleft join (select * from orders) as o on p.customerNumber = o.customerNumberwhere paymentdate > '2005-01-01';explain select *from orders as oleft join (select * from payments) as p on p.customerNumber = o.customerNumberwhere paymentdate > '2005-01-01';
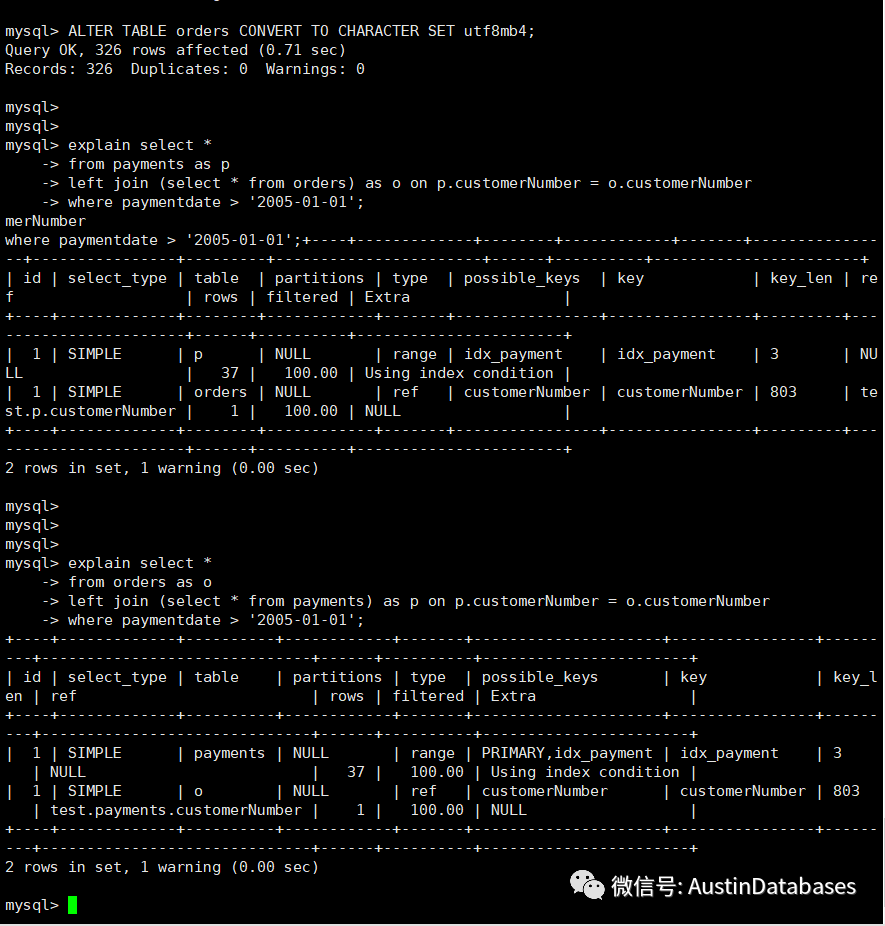
语句如上,第一个语句为 utf8 作为驱动表,可以明显看到因为两个表的字符集和collation的不同,导致无法走索引进行查询,这里也就是 payments 的主键与order 的主键无法进行正确的连接和比对,而数据库没有办法,走了另外的优化方式,通过HASH JOIN 的方式进行处理。
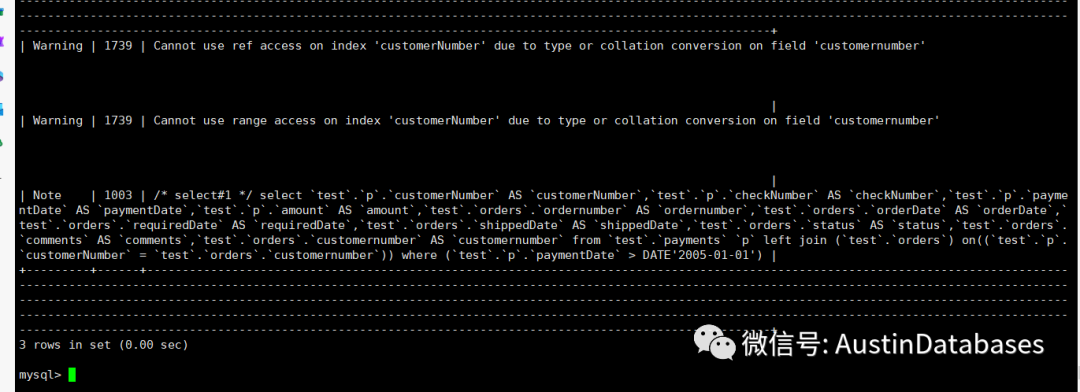
那么我们如果反过来进行查询的话情况是不是有变化,有些文章中提到变换驱动表关系,可以在有些版本上可以解决由于字符集不同的问题,导致的索引失效的问题。
那么我们变换一下驱动表的位置,整体的查询计划进行了变化,相关的执行计划的效率稍有提高。

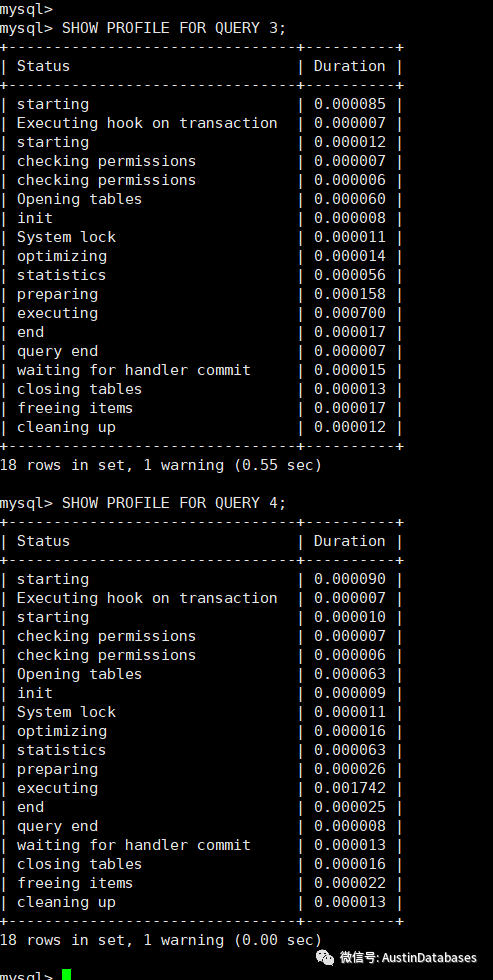
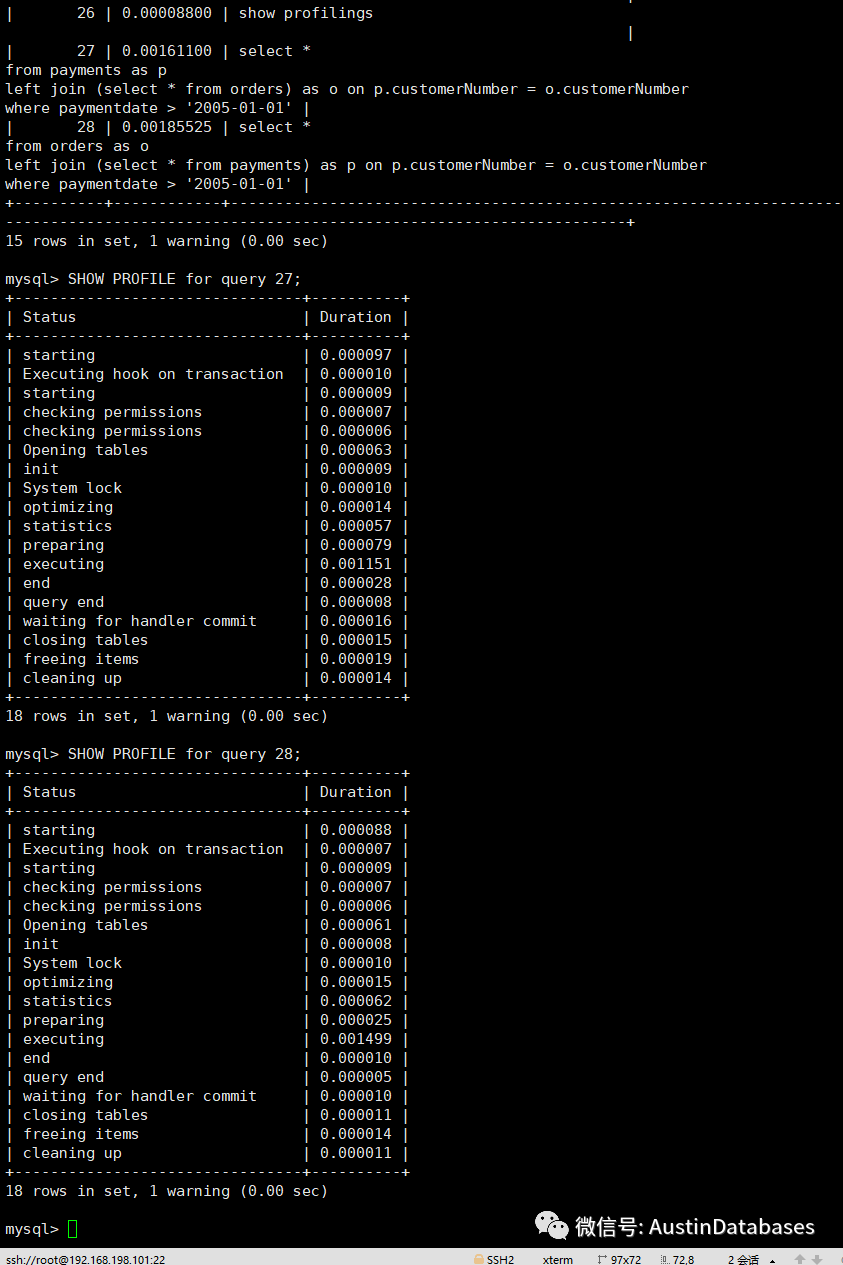
我们将语句实际执行,并查看profilings ,这里可以看到的是,我们将payments 放到上面的情况下 executing 为 700 而将ORDER 放到驱动表的情况下,execute 变为 1742
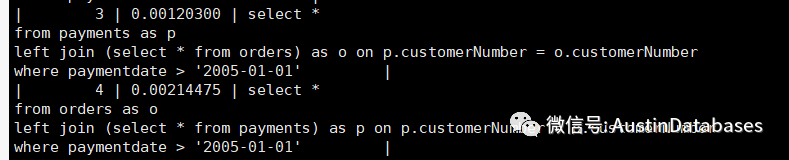
因为怕测试中的一些查询与表的行数等特征影响,我们在变化一下两个表的coding .
ALTER TABLE orders CONVERT TO CHARACTER SET utf8;Query OK, 0 rows affected, 1 warning (0.01 sec)Records: 0 Duplicates: 0 Warnings: 1mysql>ALTER TABLE payments CONVERT TO CHARACTER SET utf8mb4;Query OK, 0 rows affected (0.01 sec)Records: 0 Duplicates: 0 Warnings: 0
这里我们再次做相关的测试,发现调整后,

我看可以看到,实际上经过以上的操作和分析,如果作为驱动表,表小并且是utf8mb4的情况下,要比驱动表大并且是 utf8 的情况略好。
但如何,都不如统一的字符集让数据库的查询更能良好的运行。在我们统一字符到 utf8mb4 后,整体的查询正常了
所以以上列子中,主要是说明在MYSQL 5.7 迁移过来的表大部分都是 UTF8MB3 ,而如果MYSQL 8 不做任何处理,则新建的表是 UTF8MB4 ,所以,希望MYSQL 的同学注意以上问题,注意这样的情况,尽量避免。
另外还有一些事情,需要深入,有的时候即使字符集不同,collation的排序在某些情况下,在字符集不同的情况下还可以走索引。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721