
前言:最近几年用MYSQL数据库挺多的,发现了一些非常有用的小玩意,今天拿出来分享到大家,希望对你会有所帮助。
1.group_concat
在我们平常的工作中,使用group by进行分组的场景,是非常多的。
比如想统计出用户表中,名称不同的用户的具体名称有哪些?
具体sql如下:
select name from `user`group by name;
但如果想把name相同的code拼接在一起,放到另外一列中该怎么办呢?
答:使用group_concat函数。
例如:
select name,group_concat(code) from `user`group by name;
执行结果:
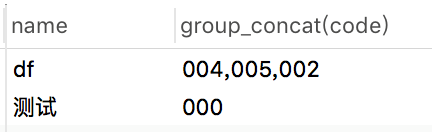
使用group_concat函数,可以轻松的把分组后,name相同的数据拼接到一起,组成一个字符串,用逗号分隔。
2.char_length
有时候我们需要获取字符的长度,然后根据字符的长度进行排序。
MYSQL给我们提供了一些有用的函数,比如:char_length。
通过该函数就能获取字符长度。
获取字符长度并且排序的sql如下:
select * from brand where name like '%苏三%'order by char_length(name) asc limit 5;
执行效果如图所示:
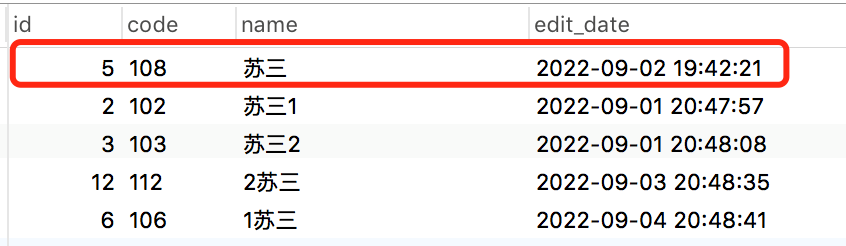
name字段使用关键字模糊查询之后,再使用char_length函数获取name字段的字符长度,然后按长度升序。
3.locate
有时候我们在查找某个关键字,比如:苏三,需要明确知道它在某个字符串中的位置时,该怎么办呢?
答:使用locate函数。
使用locate函数改造之后sql如下:
select * from brand where name like '%苏三%'order by char_length(name) asc, locate('苏三',name) asc limit 5,5;
执行结果:
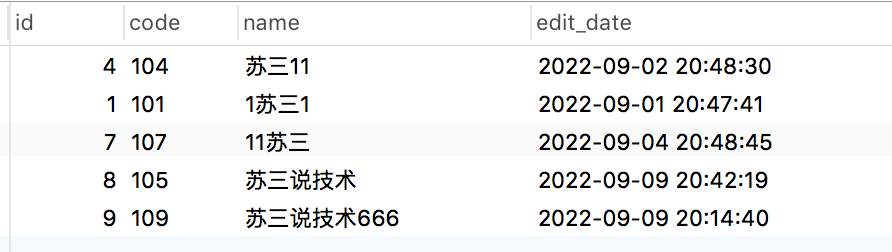
先按长度排序,小的排在前面。如果长度相同,则按关键字从左到右进行排序,越靠左的越排在前面。
除此之外,我们还可以使用:instr和position函数,它们的功能跟locate函数类似,在这里我就不一一介绍了,感兴趣的小伙伴可以找我私聊。
4.replace
我们经常会有替换字符串中部分内容的需求,比如:将字符串中的字符A替换成B。
这种情况就能使用replace函数。
例如:
update brand set name=REPLACE(name,'A','B')where id=1;
这样就能轻松实现字符替换功能。
也能用该函数去掉前后空格:
update brand set name=REPLACE(name,' ','') where name like ' %';update brand set name=REPLACE(name,' ','') where name like '% ';
使用该函数还能替换json格式的数据内容,真的非常有用。
5.now
时间是个好东西,用它可以快速缩小数据范围,我们经常有获取当前时间的需求。
在MYSQL中获取当前时间,可以使用now()函数,例如:
select now() from brand limit 1;
返回结果为下面这样的:
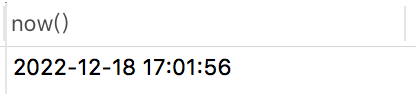
它会包含年月日时分秒。
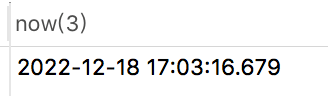
如果你还想返回毫秒,可以使用now(3),例如:
select now(3) from brand limit 1;
返回结果为下面这样的:
使用起来非常方便好记。
6.insert into ... select
在工作中很多时候需要插入数据。
传统的插入数据的sql是这样的:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)VALUES (5, '108', '苏三', '2022-09-02 19:42:21');
它主要是用于插入少量并且已经确定的数据。但如果有大批量的数据需要插入,特别是是需要插入的数据来源于,另外一张表或者多张表的结果集中。
这种情况下,使用传统的插入数据的方式,就有点束手无策了。
这时候就能使用MYSQL提供的:insert into ... select语法。
例如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)select null,code,name,now(3) from `order` where code in ('004','005');
这样就能将order表中的部分数据,非常轻松插入到brand表中。
7.insert into ... ignore
不知道你有没有遇到过这样的场景:在插入1000个品牌之前,需要先根据name,判断一下是否存在。如果存在,则不插入数据。如果不存在,才需要插入数据。
如果直接这样插入数据:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)VALUES (123, '108', '苏三', now(3));
肯定不行,因为brand表的name字段创建了唯一索引,同时该表中已经有一条name等于苏三的数据了。
执行之后直接报错了:

这就需要在插入之前加一下判断。
当然很多人通过在sql语句后面拼接not exists语句,也能达到防止出现重复数据的目的,比如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)select null,'108', '苏三',now(3)from dual where not exists (select * from `brand` where name='苏三');
这条sql确实能够满足要求,但是总觉得有些麻烦。那么,有没有更简单的做法呢?
答:可以使用insert into ... ignore语法。
例如:
INSERT ignore INTO `brand`(`id`, `code`, `name`, `edit_date`)VALUES (123, '108', '苏三', now(3));
这样改造之后,如果brand表中没有name为苏三的数据,则可以直接插入成功。
但如果brand表中已经存在name为苏三的数据了,则该sql语句也能正常执行,并不会报错。因为它会忽略异常,返回的执行结果影响行数为0,它不会重复插入数据。
8.select ... for update
MYSQL数据库自带了悲观锁,它是一种排它锁,根据锁的粒度从大到小分为:表锁、间隙锁和行锁。
在我们的实际业务场景中,有些情况并发量不太高,为了保证数据的正确性,使用悲观锁也可以。
比如:用户扣减积分,用户的操作并不集中。但也要考虑系统自动赠送积分的并发情况,所以有必要加悲观锁限制一下,防止出现积分加错的情况发生。
这时候就可以使用MYSQL中的select ... for update语法了。
例如:
begin;select * from `user` where id=1for update;//业务逻辑处理update `user` set score=score-1 where id=1;commit;
这样在一个事务中使用for update锁住一行记录,其他事务就不能在该事务提交之前,去更新那一行的数据。
需要注意的是for update前的id条件,必须是表的主键或者唯一索引,不然行锁可能会失效,有可能变成表锁。
9.on duplicate key update
通常情况下,我们在插入数据之前,一般会先查询一下,该数据是否存在。如果不存在,则插入数据。如果已存在,则不插入数据,而直接返回结果。
在没啥并发量的场景中,这种做法是没有什么问题的。但如果插入数据的请求,有一定的并发量,这种做法就可能会产生重复的数据。
当然防止重复数据的做法很多,比如:加唯一索引、加分布式锁等。
但这些方案,都没法做到让第二次请求也更新数据,它们一般会判断已经存在就直接返回了。
这种情况可以使用on duplicate key update语法。
该语法会在插入数据之前判断,如果主键或唯一索引不存在,则插入数据。如果主键或唯一索引存在,则执行更新操作。
具体需要更新的字段可以指定,例如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)VALUES (123, '108', '苏三', now(3))on duplicate key update name='苏三',edit_date=now(3);
这样一条语句就能轻松搞定需求,既不会产生重复数据,也能更新最新的数据。
但需要注意的是,在高并发的场景下使用on duplicate key update语法,可能会存在死锁的问题,所以要根据实际情况酌情使用。
10.show create table
有时候,我们想快速查看某张表的字段情况,通常会使用desc命令,比如:
desc `order`;
结果如图所示:

确实能够看到order表中的字段名称、字段类型、字段长度、是否允许为空,是否主键、默认值等信息。
但看不到该表的索引信息,如果想看创建了哪些索引,该怎么办呢?
答:使用show index命令。
比如:
show index from `order`;
也能查出该表所有的索引:

但查看字段和索引数据呈现方式,总觉得有点怪怪的,有没有一种更直观的方式?
答:这就需要使用show create table命令了。
例如:
show create table `order`;
执行结果如图所示:

其中Table表示表名,Create Table就是我们需要看的建表信息,将数据展开:图片我们能够看到非常完整的建表语句,表名、字段名、字段类型、字段长度、字符集、主键、索引、执行引擎等都能看到。
非常直接明了。
11.create table ... select
有时候,我们需要快速备份表。
通常情况下,可以分两步走:
创建一张临时表
将数据插入临时表
创建临时表可以使用命令:
create table order_2022121819 like `order`;
创建成功之后,就会生成一张名称叫:order_2022121819,表结构跟order一模一样的新表,只是该表的数据为空而已。
接下来使用命令:
insert into order_2022121819 select * from `order`;
执行之后就会将order表的数据插入到order_2022121819表中,也就是实现数据备份的功能。
但有没有命令,一个命令就能实现上面这两步的功能呢?
答:用create table ... select命令。
例如:
create table order_2022121820select * from `order`;
执行完之后,就会将order_2022121820表创建好,并且将order表中的数据自动插入到新创建的order_2022121820中。
一个命令就能轻松搞定表备份。
12.explain
很多时候,我们优化一条sql语句的性能,需要查看索引执行情况。
答:可以使用explain命令,查看mysql的执行计划,它会显示索引的使用情况。
例如:
explain select * from `order` where code='002';
结果:

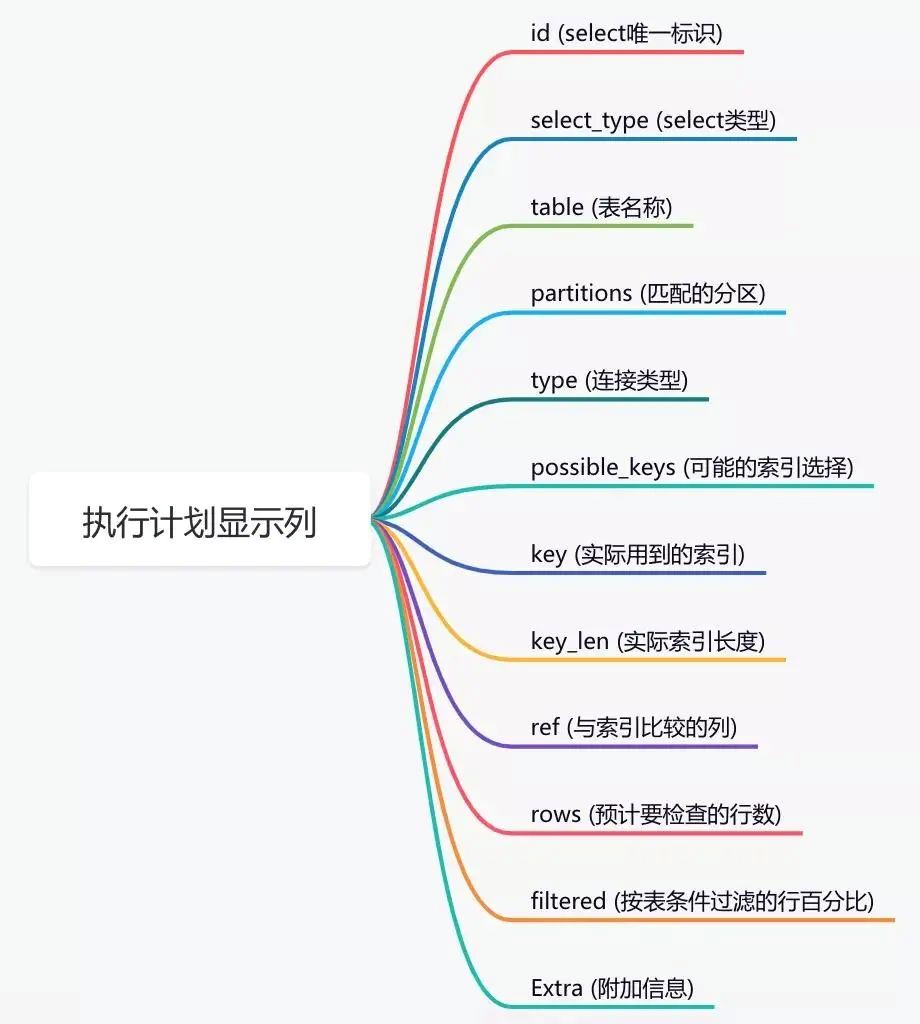
通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:
说实话,sql语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。
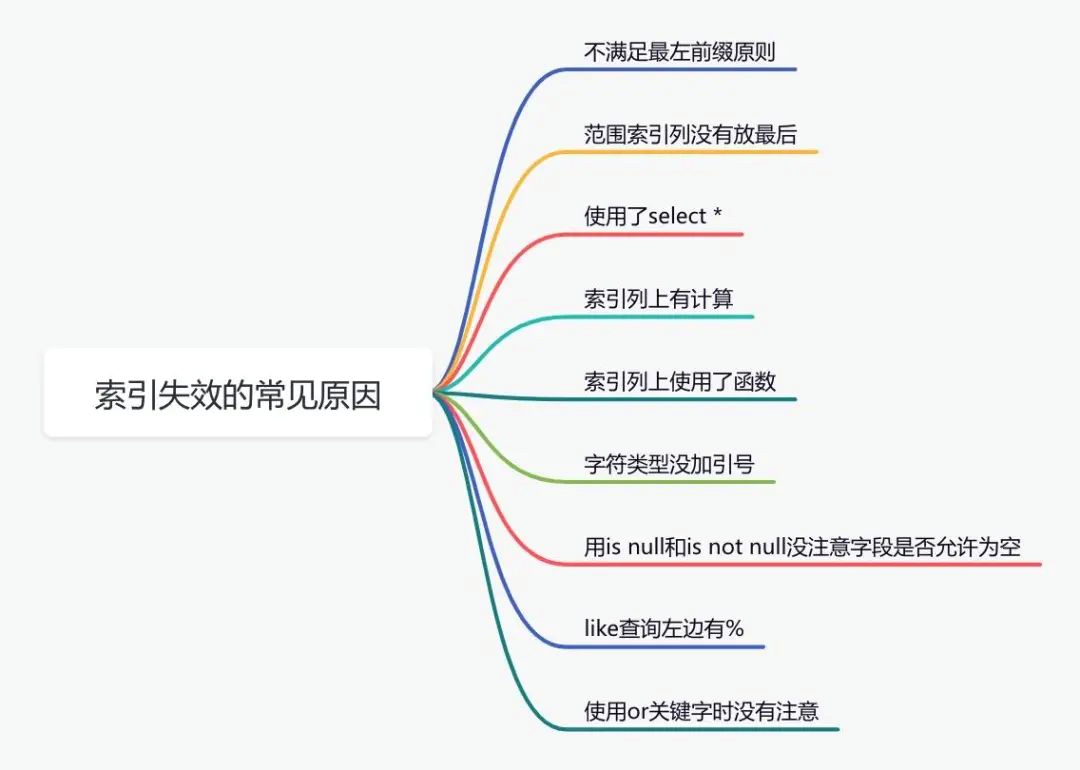
下面说说索引失效的常见原因:
如果不是上面的这些原因,则需要再进一步排查一下其他原因。
13.show processlist
有些时候我们线上sql或者数据库出现了问题。比如出现了数据库连接过多问题,或者发现有一条sql语句的执行时间特别长。
这时候该怎么办呢?
答:我们可以使用show processlist命令查看当前线程执行情况。
如图所示:

从执行结果中,我们可以查看当前的连接状态,帮助识别出有问题的查询语句。
id 线程id
User 执行sql的账号
Host 执行sql的数据库的ip和端号
db 数据库名称
Command 执行命令,包括:Daemon、Query、Sleep等。
Time 执行sql所消耗的时间
State 执行状态
info 执行信息,里面可能包含sql信息。
如果发现了异常的sql语句,可以直接kill掉,确保数据库不会出现严重的问题。
14.mysqldump
有时候我们需要导出MYSQL表中的数据。
这种情况就可以使用mysqldump工具,该工具会将数据查出来,转换成insert语句,写入到某个文件中,相当于数据备份。
我们获取到该文件,然后执行相应的insert语句,就能创建相关的表,并且写入数据了,这就相当于数据还原。
mysqldump命令的语法为:mysqldump -h主机名 -P端口 -u用户名 -p密码 参数1,参数2.... > 文件名称.sql
备份远程数据库中的数据库:
mysqldump -h 192.22.25.226 -u root -p123456 dbname > backup.sql








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721